【Python爬虫学习-案例练习(2)】:re库爬取"淘宝商品"
1、爬取网址:https://www.taobao.com/
2、分析
第1步:登录淘宝网,在搜索栏输入“python”进行搜索
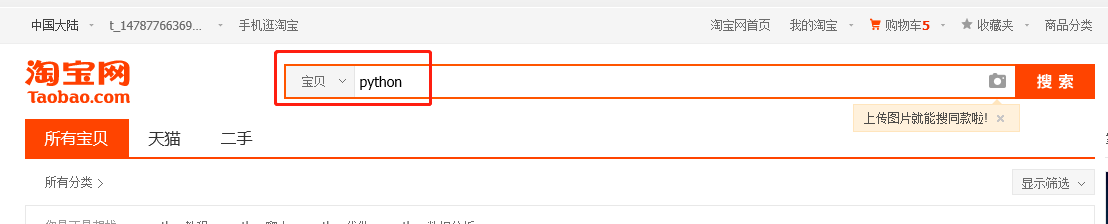
第2步:页面滑动到最底部,先点击“2”跳转到第2页,然后滑动到最底部,点击“1”,跳转至第1页,复制URL到文本中
第3步:页面滑动到最底部,点击“2”跳转到第2页,复制URL到文本中
第4步:页面滑动到最底部,点击“3”跳转到第3页,复制URL到文本中

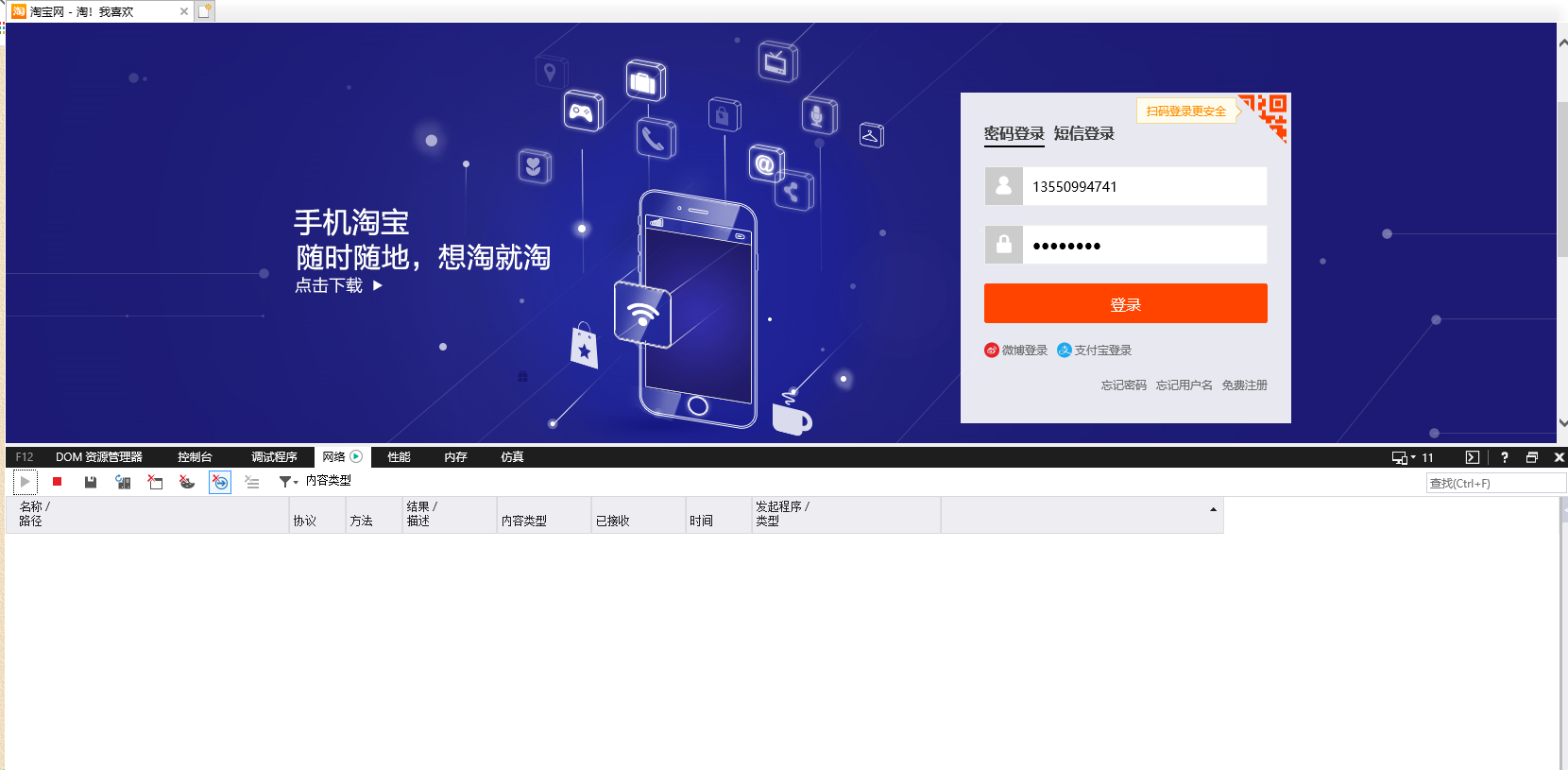
第5步:新开浏览器,发现直接输入网址“https://s.taobao.com/search?q=python”会直接跳转到淘宝的登录界面,所以可知在未登录的情况下,无法搜索淘宝商品
因此这里需要获取登录的cookie
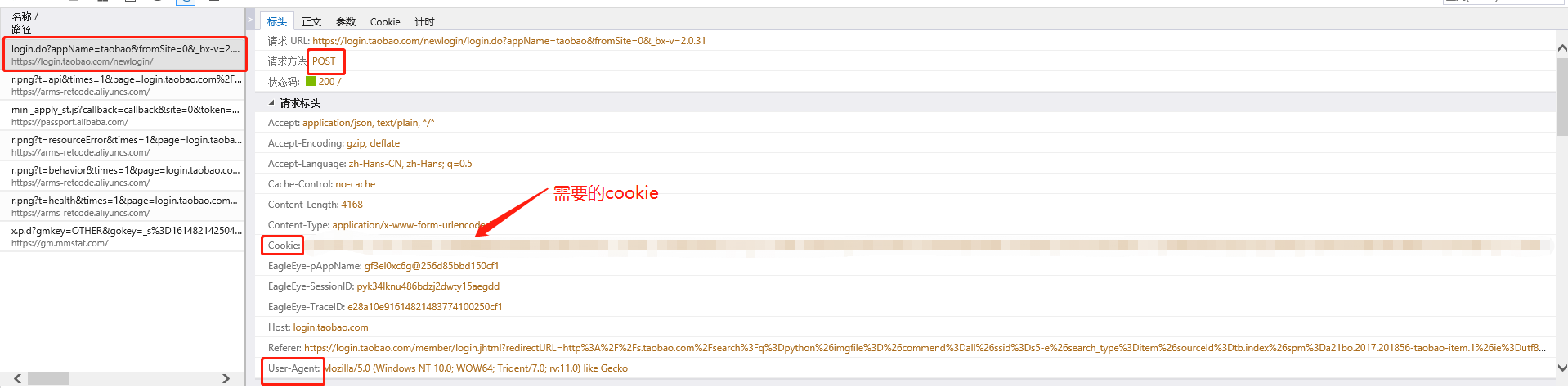
第6步:分析商品的名称、价格、多少人付款对应的参数。如下图,在页面右键-查看源代码,g_page_config部分,可以看到raw_title参数表示商品的名称,view_price表示商品的价格,view_sales表示有多少人付款。
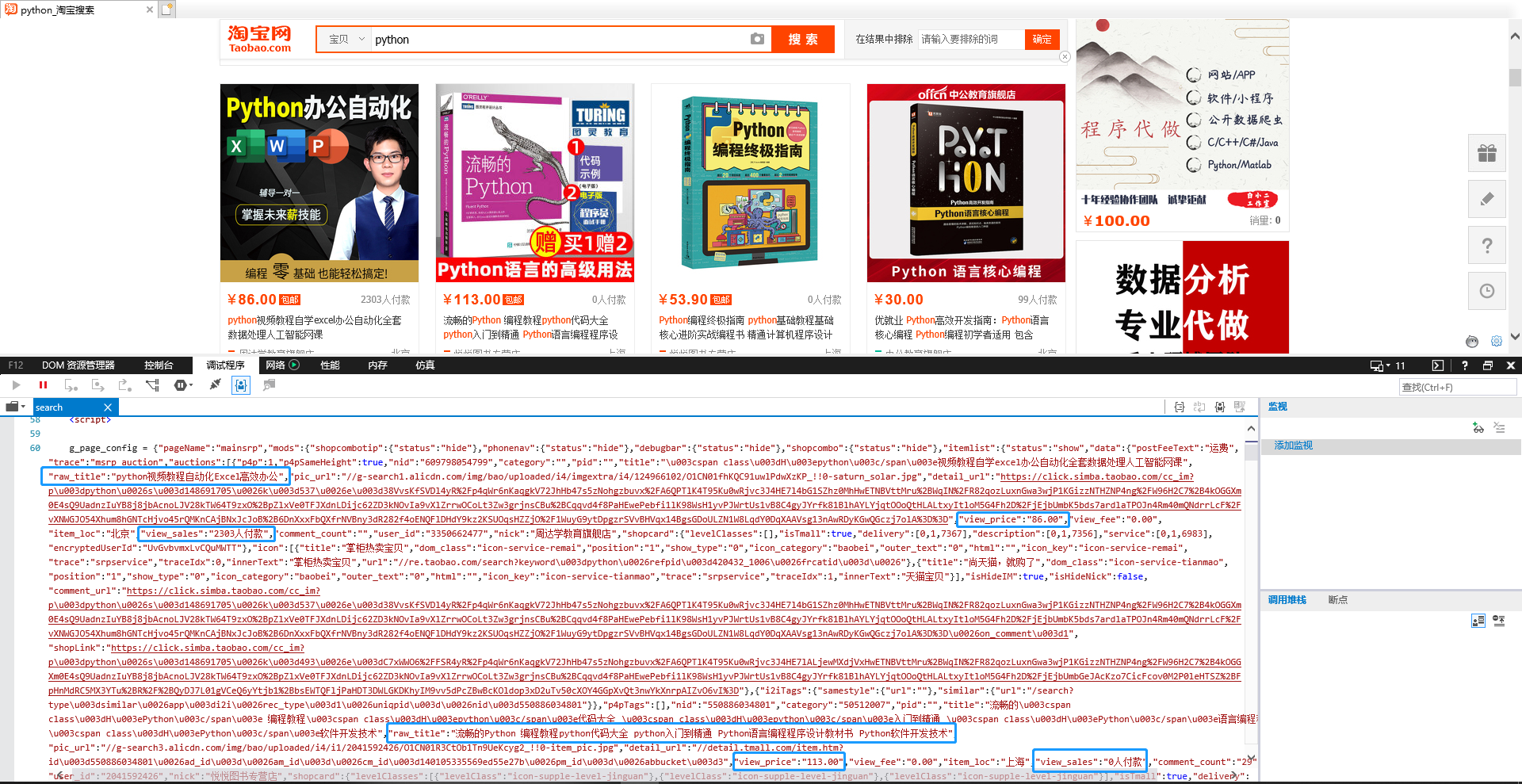
第7步:写个小demo如下
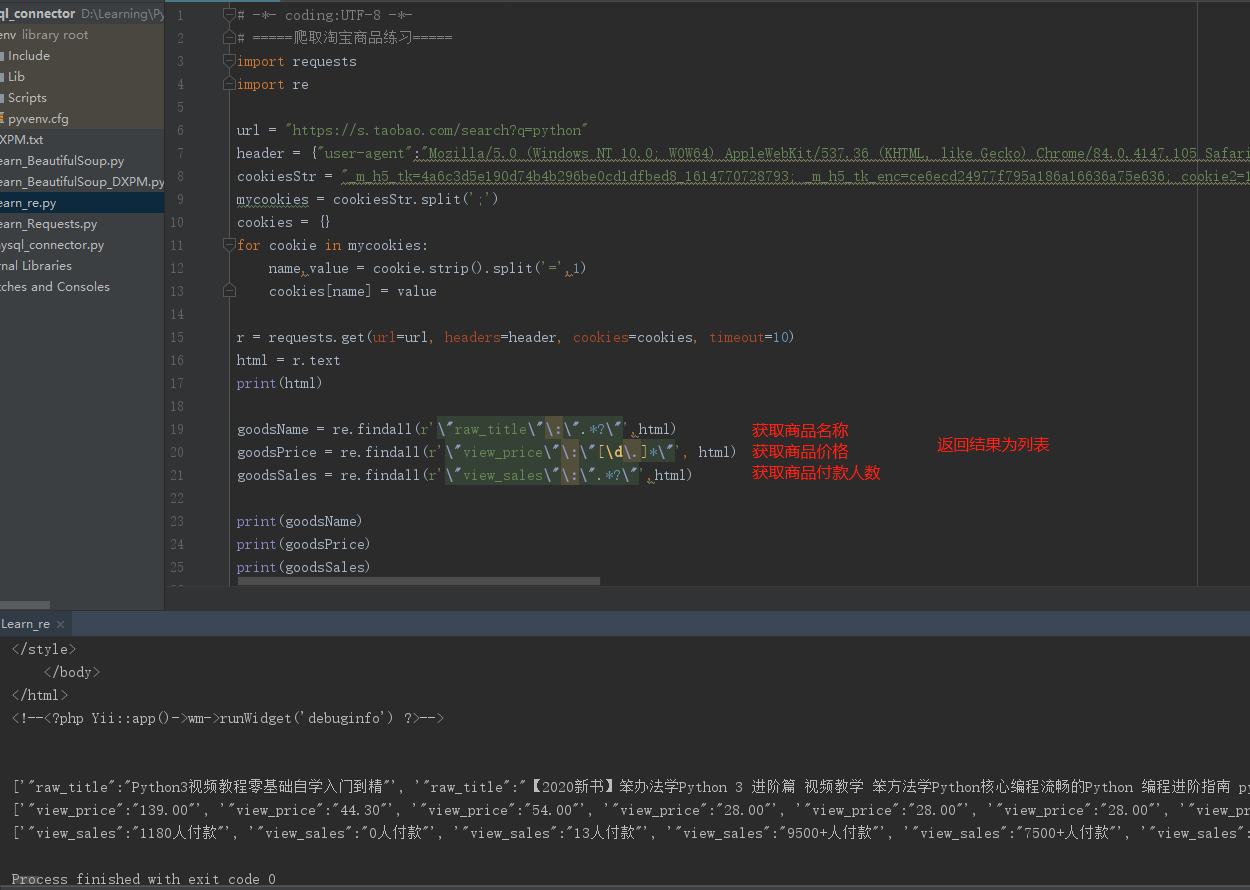
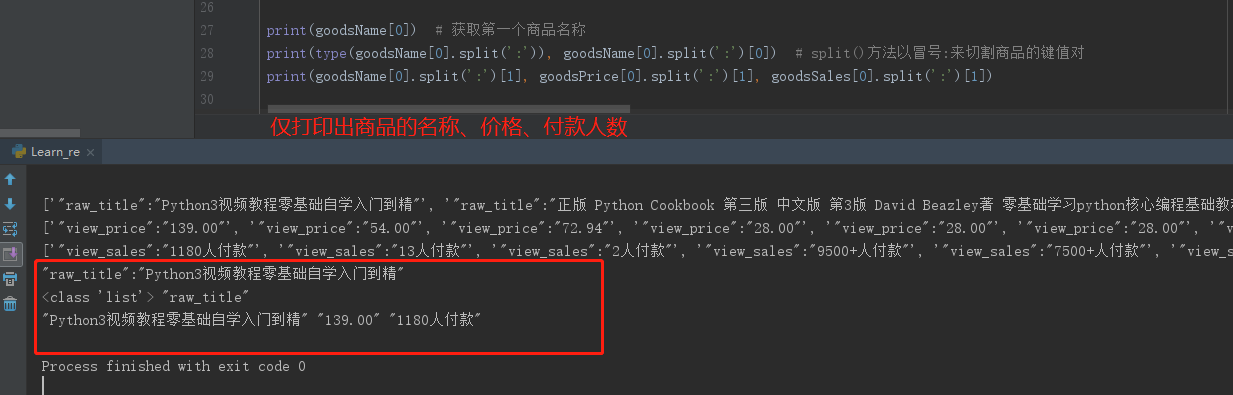
仅提取商品的名称、价格、付款人数,如下图
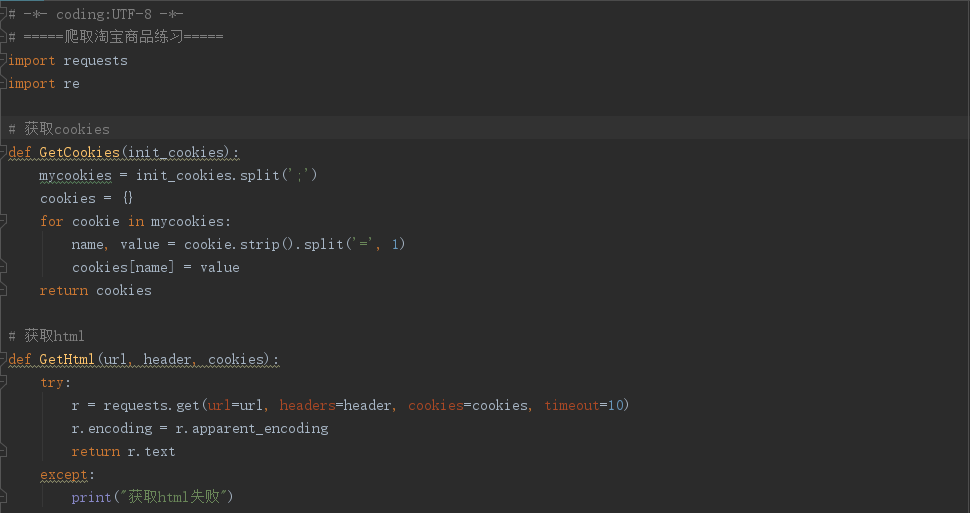
3、完整代码(加上深度爬取)

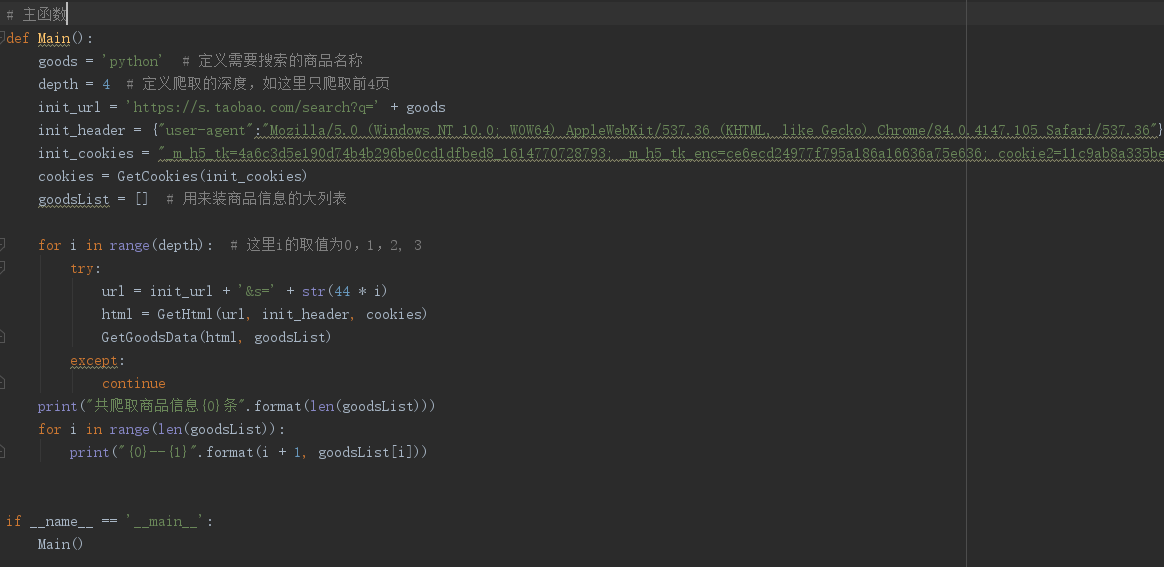
运行结果:
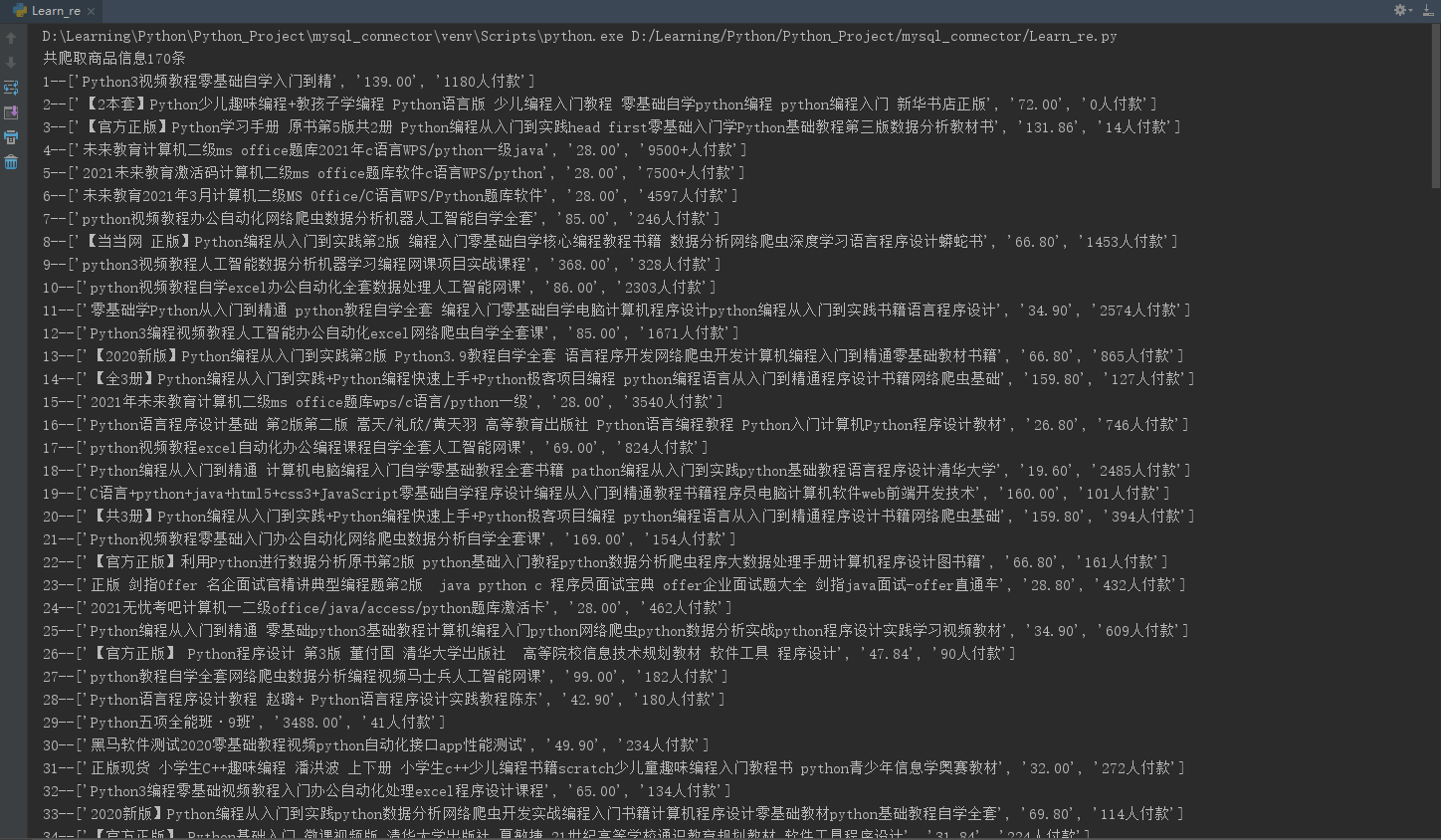
----------结束----------
