Python爬取网站返回的内容为乱码解决方法
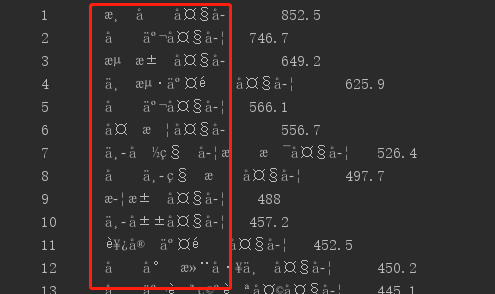
1、爬取某网站内容时,返回的结果为乱码,如图:
2、写在前面的解释
Requests会基于HTTP头部响应的编码做出有根据的推测,当访问r.text时,Requests会使用其推测的文本编码。
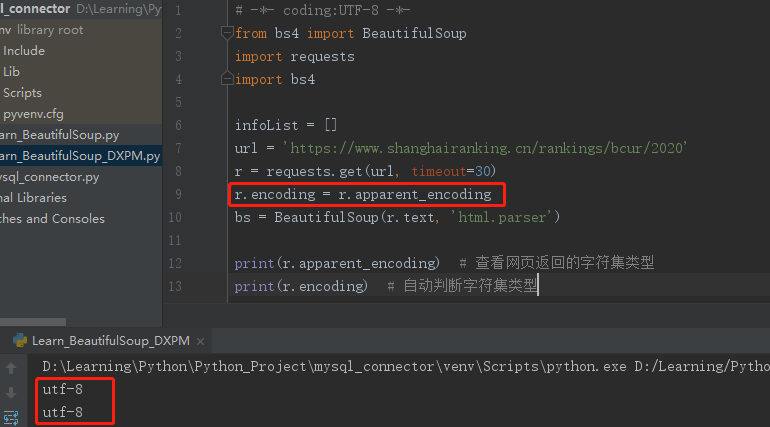
查看网页返回的字符集类型:r.apparent_encoding
查看自动判断的字符集类型:r.encoding
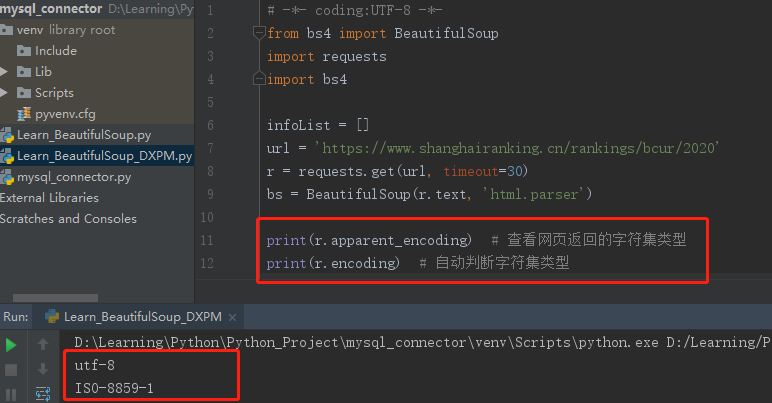
可以看到Requests推测的文本编码(ISO-8859-1)与源网页编码(utf-8) 不一致,因此会导致乱码问题的出现。
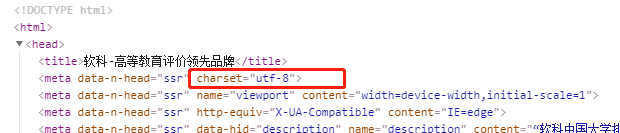
注:源网页也能直接查看编码格式,如下图:
3、解决方法
这里要注意顺序,需要先指定r.encoding的编码格式,再访问r.text。即第9行代码必须写在第10行代码之前。
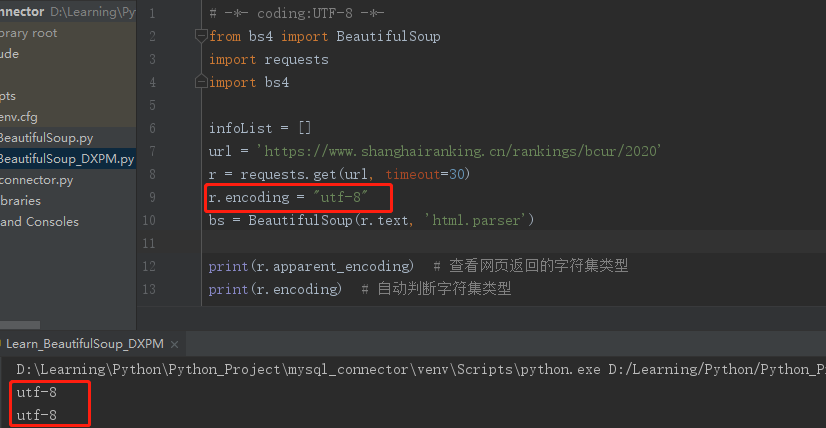
(1)方法一:直接指定r.encoding为源网页的编码格式
r.encoding="utf-8"
(2)方法二:通过r.apparent_encoding属性来指定,直接将其值赋给r.encoding
r.encoding = r.apparent_encoding
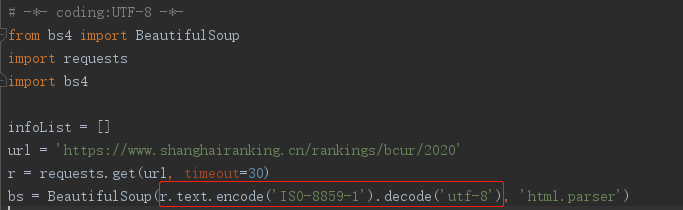
(3)方法三:通过编码、解码的方式
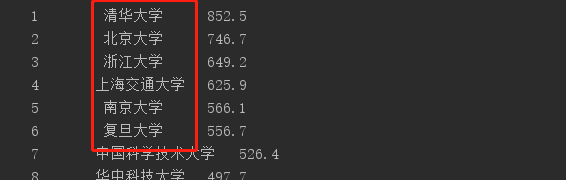
4、乱码问题解决
--------结束----------
分类:
Python


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具