

Spark sql
Spark SQL
SchemaRDD/DataFrame
介绍
- 用于结构化数据
Spark SQL运行原理 Catalyst
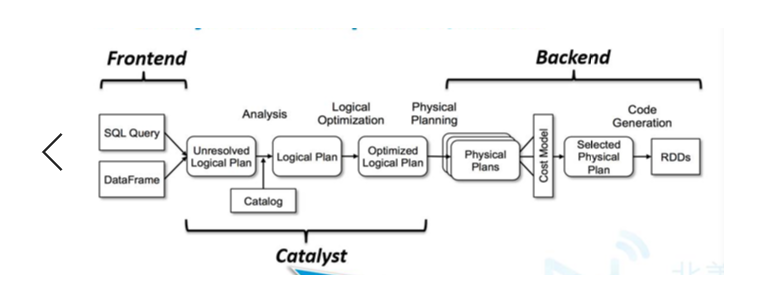
- 优化器:将逻辑计划转化成物理计划
逻辑计划:全表扫描——>投影——>过滤——>投影
优化:减少资源的使用,提高查询的效率
1)投影上检查是否有过滤器是否下压:
2)全表扫描——>过滤——>投影——>投影
物理计划:全表扫描——>过滤——>投影
Spark SQL API-1重点
SparkContext
- Spark SQL的编程入口
SparkSession
- 合并了SQLContext与HiveContext
- 提供与Spark功能交互单一入口点,并允许使用DataFrame和Dataset API对Spark进行编程
val spark = SparkSession.builder .master("master") .appName("appName")
.getOrCreate()
Dataset
- 存储一些强类型的集合
Dataset=RDD+Schema
===========================================================
例子一:创建Dataset
scala> val cc=Seq(("SS",12),("CC",33)).toDF("name","age")
scala> cc.show
+----+---+
|name|age|
+----+---+
| SS| 12|
| CC| 33|
+----+---+
例子二:创建Dataset
val ds=spark.createDataset(1 to 10)
val ds=spark.createDataset(List(("a"->1)))
ds.show()//表结构
ds.where(ds("_2")>10).show
============================================================
例子二:运用样式类创建dataset
case class student(name:String,age:Int)
val rdd=sc.makeRDD(List(student("jc",19),student("jk",17)))
val ds1=rdd.toDS//转成DS
ds1.where(ds1("age")===19).show
===========================================================
scala> case class Order(id:String,customerId:String)
scala> case class OrderItem(orderid:String,subTotal:Double)
scala> val ordersRDD=sc.textFile("/text/orders.csv")
scala> val orderDS=ordersRDD.map(line=>{val cols=line.split(",");Order(cols(0),cols(2))}).toDS
scala> orderDS.show(2)
+---+----------+
| id|customerId|
+---+----------+
| 1| 11599|
| 2| 256|
+---+----------+
Spark SQL API-4 DataFrame数据表格
import org.apache.spark.sql.Row
val row=Row(1,1.0,"abc")
row.get(0)
Spark SQL API-6 创建DataFrame
val df=spark.read.json("/text/users.json")
df.show
df.printSchema()//输出数据结构信息
DataFrame中的数据结构信息,即为schema。
- 将json文件转成DataFrame
方法一:关键spark.read.json
scala> val df=spark.read.json("/text/users.json")
scala> df.show
+----+-------+
| Age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
scala> df.select("name").show
scala> df.select(col("name")).show
scala> df.select(column("name")).show
scala> df.select($"name").show
scala> df.select('name).show
+-------+
| name|
+-------+
|Michael|
| Andy|
| Justin|
+-------+
//首先注册成一张表(运用临时表:registerTempTable)
scala> df.registerTempTable("Test")
//使用sql语句查询
scala> spark.sql("select * from Test").show
+----+-------+
| Age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
withColumn:常用
scala> df.withColumn("Age11",col("Age")+1).show
+----+-------+-----+
| Age| name|Age11|
+----+-------+-----+
|null|Michael| null|
| 30| Andy| 31|
| 19| Justin| 20|
+----+-------+-----+
—————————————————————————————————————————————————————————————————
//数据自己写方法
scala> spark.sql("select explode(array(1,2,3)) as name").show
+----+
|name|
+----+
| 1|
| 2|
| 3|
+----+
Spark SQL API-8
- RDD->DataFrame
- 关键是将文件toDF,然后再进行show
scala> import org.apache.spark.sql.types._
scala> val dfs2=Seq(("js",19),("jk",18)).toDF("name","age")
dfs2: org.apache.spark.sql.DataFrame = [name: string, age: int]
scala> dfs2.show
+----+---+
|name|age|
+----+---+
| js| 19|
| jk| 18|
+----+---+
scala> val df3=Seq(1 to 10 :_*).toDF
df3: org.apache.spark.sql.DataFrame = [value: int]
scala> df3.show
+-----+
|value|
+-----+
| 1|
| 2|
| 3|
| 4|
| 5|
| 6|
| 7|
| 8|
| 9|
| 10|
+-----+
//转成rdd
case class student(name:String,age:Int)
scala> dfs2.as[student].rdd
res39: org.apache.spark.rdd.RDD[student] = MapPartitionsRDD[84] at rdd at <console>:32
Spark SQL操作外部数据源-1
//将文件存到hdfs
scala> val df=spark.read.json("/text/users.json")
df.write.save("/data/20190801")
df.write.parquet("/data/20190801")
Spark SQL操作外部数据源-3
- Hive 元数据存储MySql:对于数据的直接访问
Spark 连接hive 元数据库(mysql)
1)打开Hive metastore
[root@head42 ~]# hive --service metastore &
netstat -ano|grep 9083 ???
2)开启spark连接Mysql
[root@head42 ~]# spark-shell --conf spark.hadoop.hive.metastore.uris=thrift://localhost:9083
3)scala> spark.sql("show tables").show
spark.sql("select * from database_name.table_name")//访问其他数据库
+--------+--------------+-----------+
|database| tableName|isTemporary|
+--------+--------------+-----------+
| default| customer| false|
| default|text_customers| false|
+--------+--------------+-----------+
这样就Ok了!
在scala中查看hive表数据
hive> create table toronto(
> full_name string,
> ssn string,
> office_address string);
hive> insert into toronto(full_name,ssn,office_address)values("jc","ssss","1111");
scala> spark.sql("use databases")
val df=spark.table("hive_table")
df.printSchema
df.show
Spark SQL操作外部数据源-4??
- RDBMS表
val url = "jdbc:mysql://localhost:3306/mysql"
val tableName = "TBLS"
// 设置连接用户、密码、数据库驱动类
val prop = new java.util.Properties
prop.setProperty("user","hive")
prop.setProperty("password","mypassword")
prop.setProperty("driver","com.mysql.jdbc.Driver")
// 取得该表数据
val jdbcDF = spark.read.jdbc(url,tableName,prop)
jdbcDF.show
//DF存为新的表
jdbcDF.write.mode("append").jdbc(url,"t1",prop)
Spark SQL 函数
函数的调用方法一:
scala> import org.apache.spark.sql.functions
scala> val lower=functions.udf((x:String)=>{x.toLowerCase})//转换为小写
scala> val df=Seq("ABc","DEF").toDF("name")
scala> df.show
+----+
|name|
+----+
| ABc|
| DEF|
+----+
scala> df.select(lower(df("name"))).show
+---------+
|UDF(name)|
+---------+
| abc|
| def|
+---------+
方法二
scala> import org.apache.spark.sql.SparkSession
scala> spark.udf.register("upper",(x:String)=>{x.toUpperCase})
scala> spark.sql("""select upper("abc")""").show


