

Spark 分布式计算原理
Spark 分布式计算原理
Spark Shuffle
1)在数据之间重新分配数据
2)(将父RDD重新定义进入子RDD)每一个分区里面的数据要重新进入新的分区
3)每一个shuffle阶段尽量保存在内存里面,如果保存不下到磁盘
4)在每个shuffle阶段不会改变分区的数量
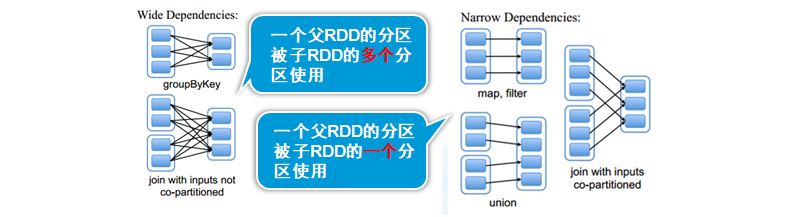
RDD的依赖关系-1(lineage)
1) 宽依赖:一个夫RDD的分区被子RDD的多个分区使用
发生宽依赖一定shuffle()
(相当于超生)
2) 窄依赖:一个父RDD的分区被子RDD的一个分区使用
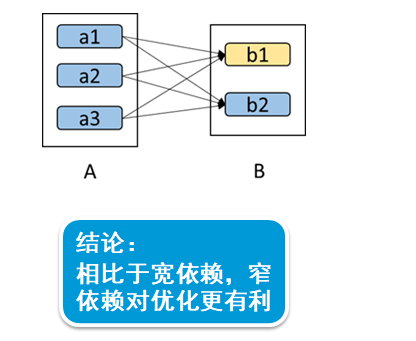
RDD的依赖关系-2(lineage)?? 宽依赖对比窄依赖
DAG工作原理
- 根据RDD之间的依赖关系,形成一个DAG(有向无环)
1)从后往前,遇到宽依赖切割为新的Stage
2)每个Stage由分区一组并行的Task组成
每个Task共享归类内存,堆外内存Task数据在进行交换
提前聚合,避免shuffle,将数据先进行去重
RDD持久化-1
cache:
- 间数据写入缓存
- cache()不能再有其他的算子
val rdd=sc.makeRDD(1 to 10)
val rdd2=rdd.map(x=>{println(x);x}
rdd2.cache
rdd2.collect
RDD共享变量-1
- 广播变量(要定义的是Array)
val rdd=sc.makeRDD(1 to 10)
val j=sc.broadcast(Array(0))
rdd.map(x=>{j.value(0)=j.value(0)+1;println(j.value(0));x}).collect
RDD共享变量-2
- 累加器:只允许added操作,常用于实现计数
val accum = sc.accumulator(0,"My Accumulator")
sc.parallelize(Array(1,2,3,4)).foreach(x=>accum+=x)
accum.value
RDD分区设计
- 分区大小限制为2GB
分区太小
1)分区承担的责任越大,内存压力越大
分区过多
1)shuffle开销越大
2)创建任务开销越大
装载CSV数据源
方法一:使用SparkContext
System.setProperty("hadoop.home.dir", "D:\\hadoop-2.7.3")//防止hadoop报错
val conf=new SparkConf()
.setMaster("local[2]")
.setAppName("hello")
val sc=SparkContext.getOrCreate(conf)
val lines = sc.textFile("file:///d:/users.csv")
val fields = lines.mapPartitionsWithIndex((idx, iter) => if (idx == 0) iter.drop(1) else iter).map(l => l.split(",")).foreach(x=>println(x.toList))
————————————————————————————————————————————————————————————————————————————————————————————————
方法二:使用SparkSession
val df = spark.read.format("csv").option("header", "true").load("file:///home/kgc/data/users.csv")
装载JSON数据源
方法一:使用SparkContext
val lines = sc.textFile("file:///home/kgc/data/users.json")
//scala内置的JSON库
import scala.util.parsing.json.JSON
val result=lines.map(l=>JSON.parseFull(l))
————————————————————————————————————————————————————————————————————————————————————————————————
还有一种使用SparkSession方法:API
var spark=SparkSession.builder().master("local[2]")
.appName("hello").getOrCreate();
val rdd=spark.read.json("file:///d:/date.json")
print(rdd)
————————————————————————————————————————————————————————————————————————————————————————————————
方法二:使用SparkSession
val df = spark.read.format("json").option("header", "true").load("file:///home/kgc/data/users.json")
RDD数据倾斜*
- 数据分配的不均匀
- 通常发生在groupBy,join等之后
1)在执行shuffle操作的时候,是按照key,来进行values的输出、拉取和聚合2)同一个key的values,一定是分配到一个reduce task进行处理的
3)如果是很多相同的key对应的values被分配到了一个task上面去执行,而另外的task,可能只分配了一些
4)这样就会出现数据倾斜问题
解决方法:
方案一:聚合源数据
通过一些聚合的操作,比如grouByKey、reduceByKey就是拿到每个key对应的value,对每个key对应的values执行一定的计算
方案二:过滤导致倾斜的key
在sql中用where条件,过滤某几个会导致数据倾斜的key
——————————————————————————————————————————————————
为什么要划分Stage?
spark划分stage思路:
1)从后往前推,一个job拆分为多组task,每组的任务被称为一个stage
2)stage里面的Task的数量对应一个partition,而stage又分为两类,
一类是shuffleMapTask,一类是resltTask,DAG的最后一个阶段为每个partition生成一个resultask,
其余阶段都会生成ShuffleMapTask,他将自己的计算结果通过shuffle传到下一个stage中。
——————————————————————————————————————————————————


