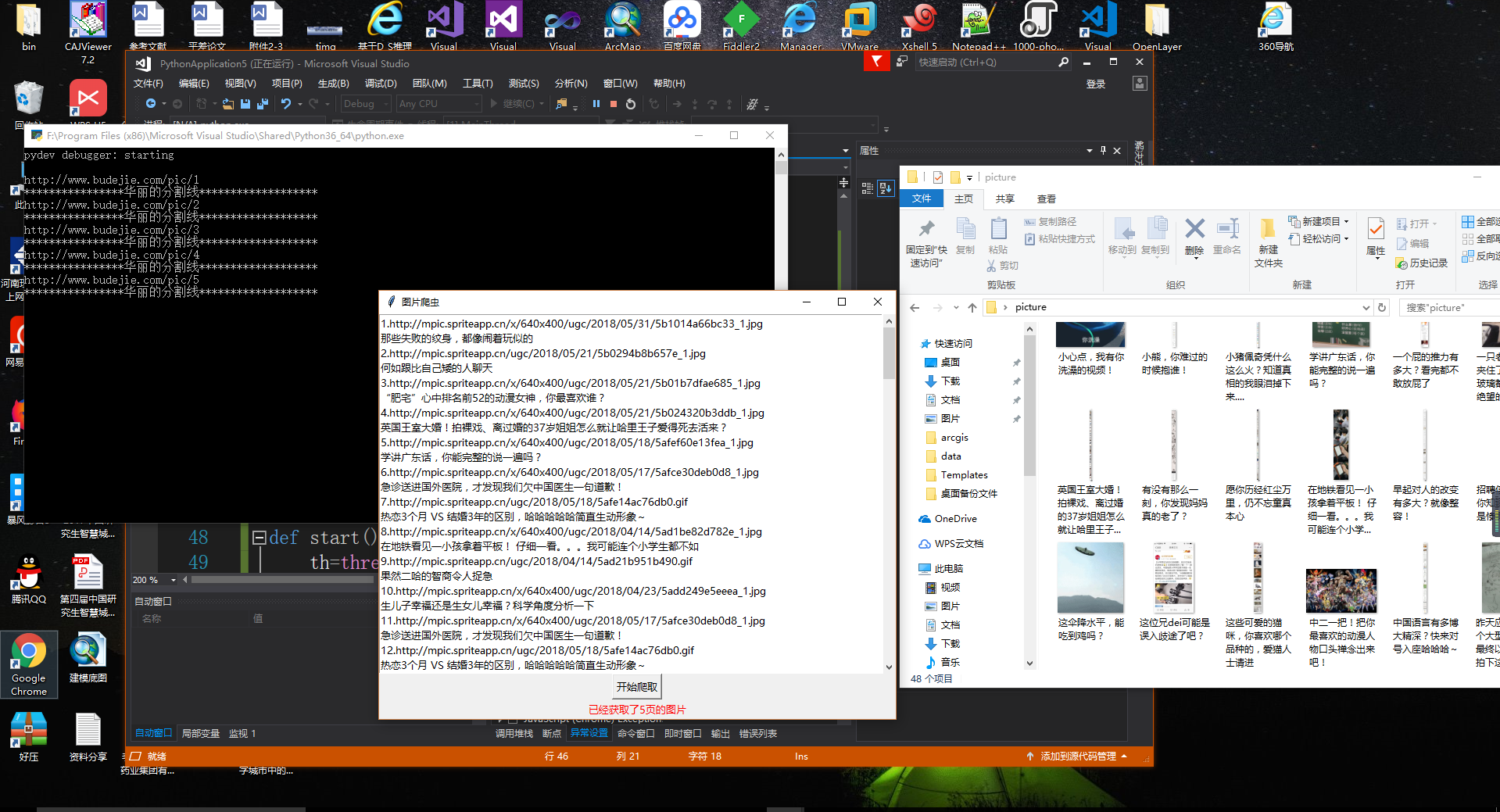
Python爬去百思不得其解的图片(VS2017)
一、引用的命名空间(C#用多了喜欢称为命名空间)(我没有休息主要是爬取得图片太少了,理论上应该休息一下)
import re
import requests
import threading#多线程
import time
from tkinter import *
from tkinter.scrolledtext import ScrolledText
import urllib.request二、变量
id=1#图片的个数
a=1#页数
url_name=[]三、获取图片的名称和网址函数
def get(a):
hd={'User-Agent':'Mozilla/5.0 (Windows NT 10.0;) Gecko/20100101 Firefox/60.0'}
url='http://www.budejie.com/pic/'+str(a)
print(url)
var1.set('已经获取了%s页的图片'%(a))
html=requests.get(url,headers=hd).text
#<div class="j-item">(.*?)</div>
# <img src="http://mpic.spriteapp.cn/x/640x400/ugc/2018/05/31/5b1014a66bc33_1.jpg" title="那些失败的纹身,都像闹着玩似的" alt="那些失败的纹身,都像闹着玩似的">
url_content=re.compile(r'(<div class="j-r-list-c-img">.*?</div>)',re.S)#匹配换行符
url_contents=re.findall(url_content,html)
print("****************华丽的分割线*******************")
for i in url_contents:
url_reg=r'data-original="(.*?)" title=".*?" alt=".*?"/>'
SS=re.compile(url_reg,re.S)
url_item=re.findall(SS,i)
if url_item:#如果图片存在匹配名字
name_reg=re.compile(r'title="(.*?)"',re.S)
name_content=re.findall(name_reg,i)
#print(name_content)
for i,k in zip(url_item,name_content):
url_name.append([i,k])
return url_name 四、写入文件夹函数
def write():
global id
global a
while id<100:
url_name=get(a)#调用获取图片+名字
for i in url_name:
urllib.request.urlretrieve(i[0],'C:\\Users\\你若成风618\\Desktop\\picture\\%s.jpg' %(i[1]))#下载.encode('gbk')
text.insert(END,str(id)+'.'+i[0]+'\n'+i[1]+'\n')
url_name.pop(0)
id+=1
a+=1
var1.set("图片爬取成功")五、线程函数
def start():
th=threading.Thread(target=write)
th.start()#运行线程六、窗口的创建
root=Tk()#实例化一个变量
root.title('图片爬虫')
root.geometry()
text=ScrolledText(root,font=('微软雅黑',10))
text.grid()#实现布局方法
button=Button(root,text='开始爬取',font=('微软雅黑',10),command=start)
button.grid()
var1=StringVar()#通过tk方法绑定一个变量
label=Label(root,font=('微软雅黑',10),fg='red',textvariable=var1)
label.grid()
var1.set('准备爬取.........')
root.mainloop()#创建窗口指令七、汇总代码
import re
import requests
import threading#多线程
import time
from tkinter import *
from tkinter.scrolledtext import ScrolledText
import urllib.request
url_name=[]
def get(a):
hd={'User-Agent':'Mozilla/5.0 (Windows NT 10.0;) Gecko/20100101 Firefox/60.0'}
url='http://www.budejie.com/pic/'+str(a)
print(url)
var1.set('已经获取了%s页的图片'%(a))
html=requests.get(url,headers=hd).text
#<div class="j-item">(.*?)</div>
# <img src="http://mpic.spriteapp.cn/x/640x400/ugc/2018/05/31/5b1014a66bc33_1.jpg" title="那些失败的纹身,都像闹着玩似的" alt="那些失败的纹身,都像闹着玩似的">
url_content=re.compile(r'(<div class="j-r-list-c-img">.*?</div>)',re.S)#匹配换行符
url_contents=re.findall(url_content,html)
print("****************华丽的分割线*******************")
for i in url_contents:
url_reg=r'data-original="(.*?)" title=".*?" alt=".*?"/>'
SS=re.compile(url_reg,re.S)
url_item=re.findall(SS,i)
if url_item:#如果图片存在匹配名字
name_reg=re.compile(r'title="(.*?)"',re.S)
name_content=re.findall(name_reg,i)
#print(name_content)
for i,k in zip(url_item,name_content):
url_name.append([i,k])
return url_name
id=1#图片函数
a=1#页数
def write():
global id
global a
while id<100:
url_name=get(a)#调用获取图片+名字
for i in url_name:
urllib.request.urlretrieve(i[0],'C:\\Users\\你若成风618\\Desktop\\picture\\%s.jpg' %(i[1]))#下载.encode('gbk')
text.insert(END,str(id)+'.'+i[0]+'\n'+i[1]+'\n')
url_name.pop(0)
id+=1
a+=1
var1.set("图片爬取成功")
def start():
th=threading.Thread(target=write)
th.start()#运行线程
root=Tk()#实例化一个变量
root.title('图片爬虫')
root.geometry()
text=ScrolledText(root,font=('微软雅黑',10))
text.grid()#实现布局方法
button=Button(root,text='开始爬取',font=('微软雅黑',10),command=start)
button.grid()
var1=StringVar()#通过tk方法绑定一个变量
label=Label(root,font=('微软雅黑',10),fg='red',textvariable=var1)
label.grid()
var1.set('准备爬取.........')
root.mainloop()#创建窗口指令
八、效果图