C++基础
内存结构相关
C++的内存结构是怎样的
- 栈区:编译器自动分配释放的区域,局部变量和函数参数就储存在栈区,离开作用域自动释放
- 堆区:程序员手动申请的区域,比如new和malloc。可能会出现内存泄漏和内存碎片的问题
- 全局区:全局变量和静态变量存放的区,程序结束后才释放
- 常量存储区:存储常量
- 代码区:存放程序的二进制代码
类的大小
成员函数储存在代码区,不列入计算。静态成员变量储存在全局区,也不列入计算
New和Malloc的区别
最基本的,new是C++风格的内存申请,它是经过包装的,是操作符,比malloc更安全。
- 使用
new不需要指定需要分配多少空间,而malloc需要,需要指定申请多少B new返回的是申请的对象的指针,而malloc返回的是void*,需要使用者自行转换,这是不安全的,而new是类型安全的- 如果
new分配失败了会抛出bad_alloc异常,而malloc失败了会返回NULL。如果new的是一个对象的话那么他还会调用到它的构造函数
调用new/delete的过程
首先new会调用operator new来分配内存,然后会使用static_cast进行转型,最后利用转型后的指针来调用一次构造函数
operator new是一个可重载的函数,他的内部会调用malloc,若失败了抛出异常,成功了则分配一个指定的内存空间,并返回void*
delete的话会先执行析构函数,然后再执行operator delete
memcpy和strcpy的区别?
- mencpy能拷贝任意类型的数据,而strcpy只能拷贝字符串
- mencpy需要显示指定拷贝的长度,而strcpy不需要,当他遇到/0的时候会自动停止,这种就可能会导致内存溢出
常量储存在内存中的什么区域
对于局部变量p而言,p存放在栈区,Hello\0存放在常量区
const char* p = "Hello";
对于全局常量,可能会优化至符号表中以提高速度
const int data = 10;
内存对齐
- 结构体的总大小是结构体内最宽基本类型成员的整数倍
- 每个成员的偏移值是它们自身大小的整数倍(第一个元素偏移是0)
// 大小是16
union U
{
int arr[3];
double d;
};
// 大小是24
struct S1
{
int arr[3];
double d;
};
// 大小是12
struct S2
{
char c1;
int i;
char c2;
};
C++11中的新特性,强制对齐alignas
- 可以用于
class,struct,union的声明 - 可用于非位域数据成员的声明
- 可用的对齐方式有8, 16, 32,64, 128等等
// 大小是16
struct alignas(16) MyStruct
{
char c;
int i1;
int i2;
};
// 大小是16 + 16 = 32
struct MyStruct
{
char c;
alignas(16)
int i;
int i2;
};
位域
深拷贝与浅拷贝
指针传递与引用传递的区别
指针传递的本身是值传递,意味着在进行函数调用的时候会在栈上创建一个指针的拷贝,但它们都是指向同一块内存区域
引用传递本质上也会在栈上开辟一个内存空间,但内存空间中存放的是实参的地址。因此函数中对形参的操作都将被处理为间接寻址,即通过栈中存放的地址访问实参本身。因此在函数中对形参的任何操作都会影响到实参本身
指针和引用的区别
指针使用的时候可以不需要初始化,引用需要初始化
// 必须提供有参构造函数进行初始化
class MustInitClass
{
public:
MustInitClass(int& _data) : ref_data(_data) {}
int& ref_data;
};
引用的本质可以看作是指针常量,因为它引用的目标不能更改,但是指针可以
指针和引用都能实现多态
在编译阶段,编译器会将指针以“指针名-指针本身的地址”形式添加到符号表中,因此当然可以修改指针的指向,也可以修改指针指向的数据的值。而引用只是一个别名,编译器会将引用以“引用名-引用对象的地址”形式添加到符号表中,因为符号表是不能更改的,因此引用对象的地址也不能更改,自然而然的引用也不能更改指向了,并且需要在创建时初始化
类的初始化顺序
首先是初始化列表和类内赋值最先初始化,然后是构造函数体。其中初始化的顺序和初始化列表中的顺序无关,而是与类成员的声明顺序有关。如下图,由于NormalStruct_Int先声明,因此在执行构造函数的时候会先构造int_data,然后再构造str_data
class TestCtor
{
public:
TestCtor() : str_data() {}
NormalStruct_Int int_data;
NormalStruct_Str str_data;
};
但是初始化列表的优先级更高,当初始化列表中没有指定初始化时,才会去类成员中寻找。如以下情况,会调用int_data和str_data的无参构造函数
class TestCtor
{
public:
TestCtor() : str_data() {}
NormalStruct_Int int_data = NormalStruct_Int();
NormalStruct_Str str_data = NormalStruct_Str("123");
};
基础关键字
static_cast和dynamic_cast的区别
static_cast可以说是C风格的转换的替换版,比如说double到float,转换int到char等等。上行转化安全,下行转化不安全,因此适用于非多态场景。转化失败了结果是错误意义的指针,无法判断转化是否成功
dynamic_cast用于多态类型的转换(如果类不含有虚函数那么编译会报错),只能用于类指针和类引用以及void*的转换。对于指针类型若失败会返回nullptr,对于引用类型失败会抛出bad_cast异常,因此使用dynamic_cast一定要注意检查返回值
两者都在编译器层面都不支持无效的类型转换,编译时都会出错
static_cast和reinterpret_cast的区别
reinterpret_cast将重新解释内存中的数据,支持无效的类型转化
class TestClass {};
int main(){
TestClass* t = new TestClass();
// 编译出错
// int* p = static_cast<int*>(t);
int* rp = reinterpret_cast<int*>(t);
delete t;
}
另外的,对数据进行reinterpret_cast能保证其地址内数据不会被改变,假设我需要得到一个内存和float f一样的int然后对其进行位操作,那么我们需要这么做
// f的地址中的数据为00 00 80 3f
float f = 1.0f;
// a的地址中的数据为01 00 00 00, a的值为1
int a = static_cast<int>(f);
// b的地址中的数据为00 00 80 3f, b的值为1065353216
int b = *(reinterpret_cast<int*>(&f));
NULL与nullptr的区别
C++中的NULL是一个宏,它是0,nullptr是一个关键字,代表空指针
C++中不允许void*类型的指针隐式转换为其他类型的指针,因此当有指针类型和整形类型的重载函数时,由于不支持隐式转化,因此会调用到整形的重载版本,NULL被解释为0
nullptr的类型是nullptr_t,并不是void*
typedef decltype(nullptr) nullptr_t;
static
静态局部变量:该变量会存储在全局区(静态存储区),生命周期到程序结束为止,且重复声明不会覆盖其值
静态全局变量,静态全局函数:它们都是单文件使用的,不能通过extern跨文件查找,static缩小了了它们的作用域
静态成员变量和静态成员函数:
-
生命周期比类长,归属于类本身,而不是每个类实例
-
类内非静态成员函数可以访问静态成员函数和变量,但是类内静态成员函数不能访问类内静态成员变量与函数,因为静态成员函数没有this指针,无法访问非静态类成员以及非静态类成员函数
-
静态成员变量需要在类外进行初始化
class StaticTest { public: const static int data; const static float score; static int age; constexpr static double time = 3.14; }; const int StaticTest::data = 2; const float StaticTest::score = 2.0f; int StaticTest::age = 100; -
静态成员函数不能与
virtual同时使用,因为静态成员函数并没有this指针,而虚函数依靠this指针访问实例类的虚函数指针,通过指针访问到其指向的虚函数表,然后再通过表访问到指定的虚函数
const
修饰变量:代表创建之后不能修改其值。常量类只能调用到其中的常函数
class TestConst
{
public:
void non_const_func() {}
void const_func() const {}
};
int main()
{
const TestConst t;
// 编译出错
// t.non_const_func();
}
修饰指针:顶层const(指针常量,int* const),指向的方向不能更改。底层const(常量指针,const int*),指向的值不能更改
修饰函数参数
void func(const std::string& name, const int age, int* const arr);
修饰函数返回值
-
以值返回
const并没有特别的意义const int get_age() { return age; }以下代码是合法的
const int origin = 20; int copy = origin; -
返回常量指针同样没有太大意义,同样会被编译期优化掉
int* const get_arr() { return nullptr; }以下代码是合法的
int* const p = new int(); int* p2 = p; delete p; -
通常以const-reference返回,代表避免拷贝的同时不允许修改原来的值
const std::string& get_name();返回常量指针同理
const int* get_arr() { return nullptr; }
修饰函数:
- 常函数的
const是上层const,对于指针而言仅仅代表指针的指向不能修改,但还是能够修改指针所指向地址的数据。常函数仍然可以修改参数,不受影响 - 在调用成员函数时,会隐式的在形参列表的最前面加入一个this指针,理所应当的,这是一个
T* const,它的指向不能修改。对于常函数而言,它隐式构造的this指针类型为const T* const。这同时也证明了为什么const类示例无法调用non-const成员函数了
struct和class
默认成员访问权限,public和private;默认继承权限,public和private
class可用于模板中替代typename
其实现版本的C++中struct和class已经几乎一致了,说使用区别的话那应该是为了兼容C语言。struct可以成为一个单纯的数据集合,或者说是POD,而类要担负的就更多,比如做数据处理等等
强枚举类型
普通的枚举类型是不限定作用域的,即在同一个namespace中,是不能出现重名的,且能够被隐式转换为int等类型的值
而强枚举类型(enum class)的枚举类型是唯一的,但仍可以显示强转为int,unsigned int等类型
enum class my_enum : unsigned int
{
value1, // 0
value2, // 1
value3 = 100,
value4 = 200,
value5, // 201
};
强枚举类型的底层默认是int,不限作用域的枚举没有默认的底层类型,由编译器选择一个合适的值
inline
声明和定义都在类内的成员函数默认是inline
内联函数在调用时与宏调用一样展开,不需要函数调用时参数的压栈操作,减少了调用开销
Union
union中的数据类型是不允许具有构造函数的,可以允许POD的存在。Union中的数据存在于同一片内存中,至于提取出来什么值看你使用什么方法去解释它
union U
{
int a;
char c;
};
int main()
{
U u;
u.c = '1';
cout << u.c << endl; // '1'
u.a = 100;
cout << u.c << endl; // 'd'
}
封装继承多态
public和protected和private三种继承有什么区别
三种继承方式对于子类来说没有区别,但是对于子类的实例化对象来讲有区别。但是只分为两种,public一种和protected,private一种。后者会使子类的实例化对象无法访问到基类的public成员。
protected和private会影响到子类的子类,即影响到孙子类。如果是protected继承,那么结果和public继承一样,public和protected属性都能够访问,如果是private继承,那么孙子类无法访问到基类的所有属性,因为对他来说这些属性在继承至子类的时候已经变成了private
public继承可以视为是is-a关系,而private继承类似复合(has-a),但是又比复合更接近第一层
重载重写和重定义
-
重载:overload。C语言中没有函数重载,因为C语言的函数签名不包含函数参数,更别提参数顺序
double get_add(int data1, double data2) { return data1 + data2; } double get_add(double data1, int data2) { return data1 + data2; } -
重写:override,对应virtual。重写不关心访问限定符,基类可以是public,派生类可以是private,反之仍然成立(虽然并没有什么实际用途)。最终能不能在外界通过多态实例调用看实例的类型所对应的限定符
class Father { public: virtual void Func() {} }; class Son : public Father { private: void Func() override {} }; -
重定义:以下情况发生了重定义(隐藏),父类的
Init()被隐藏,无法通过Son的实例化对象进行访问,这是我们不想要的结果struct Father { void Init() {} }; struct Son : public Father { void Init(int data) {} };
友元
友元函数
友元全局函数
class A
{
friend void globalVisit();
int data = 100;
int showData() { return data; }
};
void globalVisit()
{
A a;
a.showData();
}
其实这个函数写在类A中也是可以的,但是它同样不能直接访问A对象的private或protected对象
void globalVisit()
{
// 不行
cout << data << endl;
}
友元成员函数
首先B中被当成朋友的函数得是public的,其次该函数需要在类A声明后再实现
class B
{
public:
void visitFriend();
};
class A
{
friend void B::visitFriend();
int data = 100;
int showData() { return data; }
};
void B::visitFriend()
{
A a;
a.showData();
}
友元类
顺序需要是先朋友再主人
class B
{
void visitFriend()
{
A a;
a.showData();
}
};
class A
{
friend B;
int data;
int showData() { return data; }
};
工程问题
How c++ works
首先我们会有自己的代码文件,包括.cpp,.h,.hpp等,编译器将会处理这些文件,然后编译成二进制文件(可能是库,也可能是可执行的exe文件)
首先看下面这段代码
#include<iostream>
int main()
{
std::cout << "Hello World" << std::endl;
}
#include是预处理指令,他会将iostream文件中的所有代码拷贝并粘贴到当前文件中
main函数是程序的入口,它的返回值是int,main函数是个特例,我们并不需要显示返回一个值,默认的它会返回0
那么把这份cpp代码变成一个exe程序,需要经理以下步骤
- 预处理阶段:这个阶段会把
iostream头文件中的内容复制粘贴到本份cpp文件中 - 编译阶段:这一阶段编译器会将代码转换成机器码。只有cpp文件会被编译,头文件不会被编译。cpp文件会被逐个编译,每个cpp文件都会被编译成object文件(
.obj) - 链接:将各个object文件链接起来,形成exe文件
设想一个分文件编写的例子
// main.cpp
void Log(const char*);
int main()
{
Log("Hello World");
}
// log.cpp
#include<iostream>
void Log(const char* message)
{
std::cout << message << std::endl;
}
在main.cpp文件中对void Log(const char*)做出声明,这意味着告诉编译器在编译阶段,有这么一个函数可供调用
在log.cpp文件中给出了void Log(const char*)的实现,这能让链接器在链接阶段找到函数对应的实现,让main函数中能成功调用
How the c++ compiler works
这小节主要讲解编译器是如何将代码文本转换为object文件的,这主要包含两个阶段
- 预处理阶段:预处理阶段会处理所有的预编译指令,常见的有
include,define,if,ifdef等,如include和define执行的都是复制粘贴替换的操作 - 编译阶段:每个cpp文件都会编译成一个object文件(假设各个cpp文件不互相
include的话),其中记录的是机器码(二进制码)
以下方代码为例,证明include只是完成复制粘贴的操作
// EndBrace.h
}
// math.cpp
int add()
{
return 2 * 5;
#include "EndBrace"
在经过预处理阶段侯,代码会变成如下格式
// math.i
int add()
{
return 2 * 5;
}
然后在经过编译阶段,形成了object文件,将其中的二进制数翻译过来就是

我们发现这里编译器做出了优化,它在编译阶段计算出了2 * 5的结果,在汇编代码中直接将10移到寄存器eax中,减少了运行时期的开销。这就是所谓的常量折叠
静态编译和动态编译
静态编译就是在编译的时候把需要用的链接进可执行程序中,动态编译就是在编译的时候记录一个位置,然后在调用的时候去对应的dll中寻找
静态链接库与动态链接库
它们的本质区别就是:是否会被链接进可执行文件中
静态链接库(.lib)
静态链接库在链接时会直接整合进目标程序中,优点是在运行程序的时候可以独立运行,不需要从外部读取函数库的内容。缺点就是比较占空间,如果函数库更新,则程序需要重新编译才能生效
动态链接库(.dll)
在链接的时候,可执行文件仅会保存一个“指向”的位置,当发生函数调用的时候,才回去动态链接库中查找对应的代码。优点是程序本体小,不会占用太大的空间,同时函数库更新也不需要重新编译程序。缺点是如果缺少对应的dll库,那么程序将无法运行
内存泄漏的检测
其他
函数调用的过程
首先入栈操作栈顶指针下移(地址减小),出栈操作栈顶指针上移(地址增大)
int func(int param1, int param2, int param3) {
int var1 = param1;
int var2 = param2;
int var3 = param3;
return param1 + param2 + param3;
}
int result = func(1,2,3);
首先当程序执行到func(1, 2, 3)时,会对函数参数进行压栈操作,顺序从右往左,param3,param2,param1依次入栈,然后返回地址入栈,返回地址能让函数调用结束后重新回到int result = 处继续执行
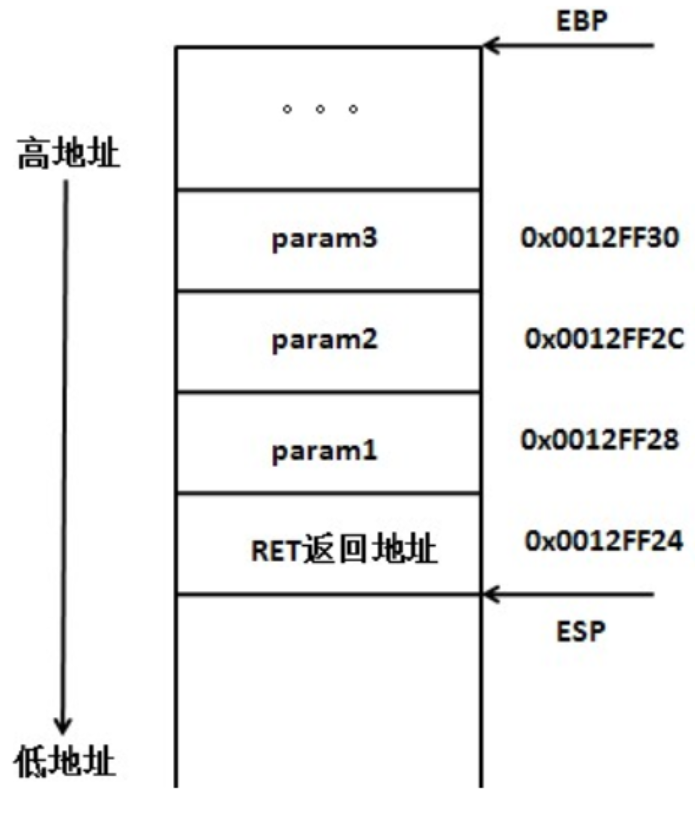
然后接下来函数调用call指令生效,此时进入func函数体。然后EBP入栈,接着修改EBP的值为ESP,此时栈顶指针和栈底指针指向同一处
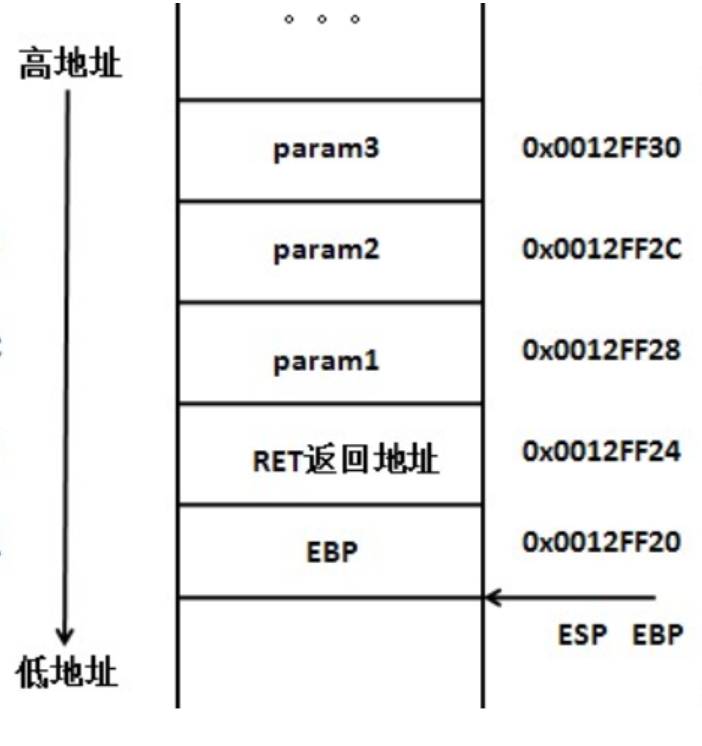
接着是函数内的局部变量入栈,即var1,var2,var3入栈
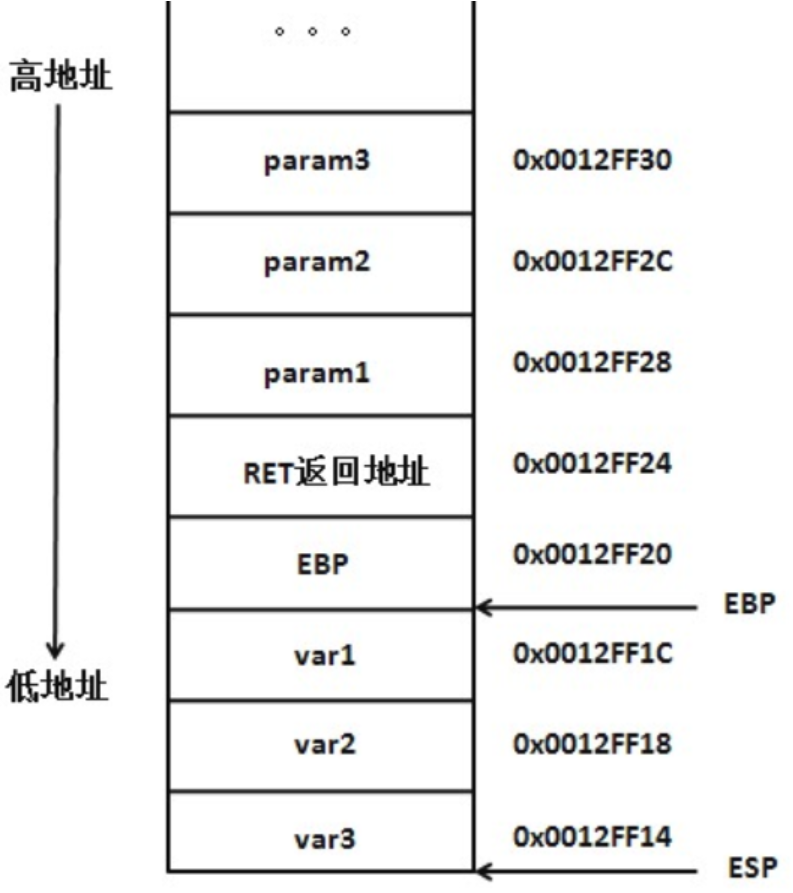
在函数调用结束后,var3,var2,var1依次出栈,EBP出栈,栈底指针恢复原值。然后函数返回地址出栈,此时程序回到函数调用处,最后param1,param2,param3出栈,函数调用至此结束
函数签名
函数名 函数参数 函数参数顺序 所在的类 所在的名称空间
C语言的函数签名不包含函数参数和参数顺序,所以C语言没有函数重载
函数指针
函数指针本质上是一个指针,它可以为nullptr。在编译时每个函数都有一个入口地址,函数指针的指向就是对应函数的入口地址
不带捕获的lambda表达式可以转换为函数指针
extern与include
如果要使用别的文件的变量或函数有两个办法,一个是通过extern声明,一个是通过include。extern查找的是其他cpp文件中的数据
相比直接include,extern能加速程序编译过程,节省时间
define与const
define是在预编译阶段进行展开,使用不得当很可能产生边缘效应
如这个例子中,得到的结果是2,而不是1.5
#define data 1 + 2
auto result = data / 2;
而const就不一样了,const有类型,有类型检查,也存在地址,define只是单纯的替换
const代表的是运行时常量,constexpr代表的是编译期常量,因此编译器可以对constexpr最初更大程度的优化
#define PI 3.14
const float PI = 3.14f;
constexpr float PI = 3.14f;

