
KVM之CPU虚拟化
1.1 为什么要虚拟化CPU
虚拟化技术是指在x86的系统中,一个或以上的客操作系统(Guest Operating System,简称:Guest OS)在一个主操作系统(Host Operating System,简称:Host OS)下运行的一种技术。这种技术只要求对客操作系统有很少的修改或甚至根本没有修改。x86处理器架构起先并不满足波佩克与戈德堡虚拟化需求(Popek and Goldberg virtualization requirements),这使得在x86处理器下对普通虚拟机的操作变得十分复杂。在2005年与2006年,英特尔与AMD分别在它们的x86架构上解决了这个问题以及其他的虚拟化困难。
1.2 关于CPU的Ring0、Ring1···
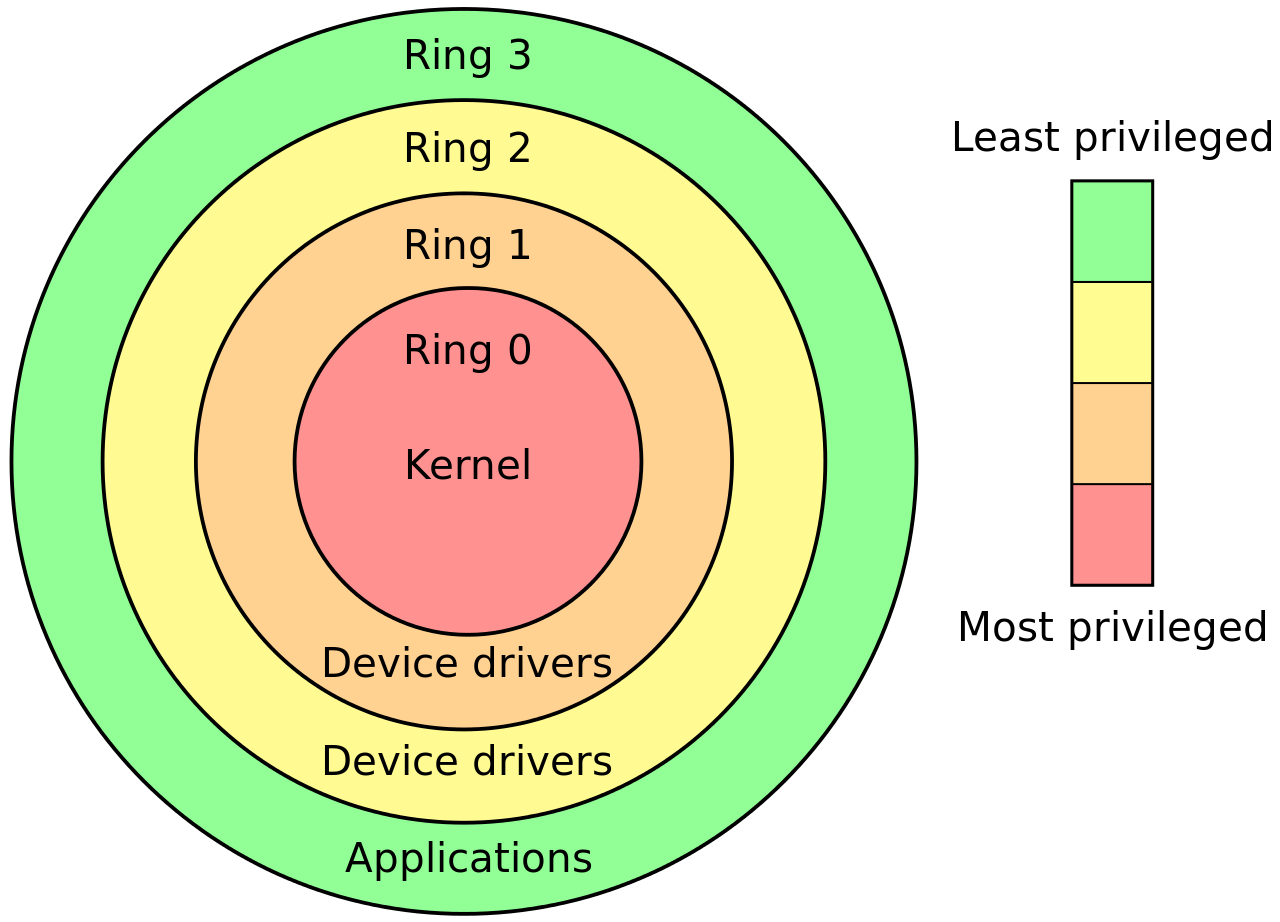
ring0是指CPU的运行级别,ring0是最高级别,ring1次之,ring2更次之…… 拿Linux+x86来说, 操作系统(内核)的代码运行在最高运行级别ring0上,可以使用特权指令,控制中断、修改页表、访问设备等等。 应用程序的代码运行在最低运行级别上ring3上,不能做受控操作。如果要做,比如要访问磁盘,写文件,那就要通过执行系统调用(函数),执行系统调用的时候,CPU的运行级别会发生从ring3到ring0的切换,并跳转到系统调用对应的内核代码位置执行,这样内核就为你完成了设备访问,完成之后再从ring0返回ring3。这个过程也称作用户态和内核态的切换。
那么,虚拟化在这里就遇到了一个难题,因为宿主操作系统是工作在ring0的,客户操作系统就不能也在ring0了,但是它不知道这一点,以前执行什么指令,现在还是执行什么指令,那肯定不行啊,没权限啊,玩不转啊。所以这时候虚拟机管理程序(VMM)就要避免这件事情发生。 (VMM在ring0上,一般以驱动程序的形式体现,驱动程序都是工作在ring0上,否则驱动不了设备) 一般是这样做,客户操作系统执行特权指令时,会触发异常(CPU机制,没权限的指令,触发异常),然后VMM捕获这个异常,在异常里面做翻译,模拟,最后返回到客户操作系统内,客户操作系统认为自己的特权指令工作正常,继续运行。但是这个性能损耗,就非常的大,你想想原来,简单的一条指令,执行完,了事,现在却要通过复杂的异常处理过程。
这时候半虚拟化就来了,半虚拟化的思想就是,让客户操作系统知道自己是在虚拟机上跑的,工作在非ring0状态,那么它原先在物理机上执行的一些特权指令,就会修改成其他方式,这种方式是可以和VMM约定好的,这就相当于,我通过修改代码把操作系统移植到一种新的架构上来,就是定制化。所以像XEN这种半虚拟化技术,客户机操作系统都是有一个专门的定制内核版本,和x86、mips、arm这些内核版本等价。这样以来,就不会有捕获异常、翻译、模拟的过程了,性能损耗非常低。这就是XEN这种半虚拟化架构的优势。这也是为什么XEN只支持虚拟化Linux,无法虚拟化windows原因,微软不改代码啊。
可以后来,CPU厂商,开始支持虚拟化了,情况有发生变化,拿X86 CPU来说,引入了Intel-VT 技术,支持Intel-VT 的CPU,有VMX root operation 和 VMX non-root operation两种模式,两种模式都支持Ring 0 ~ Ring 3 这 4 个运行级别。这下好了,VMM可以运行在VMX root operation模式下,客户OS运行在VMX non-root operation模式下。也就说,硬件这层做了些区分,这样全虚拟化下,有些靠“捕获异常-翻译-模拟”的实现就不需要了。而且CPU厂商,支持虚拟化的力度越来越大,靠硬件辅助的全虚拟化技术的性能逐渐逼近半虚拟化,再加上全虚拟化不需要修改客户操作系统这一优势,全虚拟化技术应该是未来的发展趋势。
XEN是最典型的半虚拟化,不过现在XEN也支持硬件辅助的全虚拟化,大趋势,拗不过啊。。。 KVM、VMARE这些一直都是全虚拟化。
1.3 虚拟化技术分类
当前的虚拟化技术主要分为三种:
1.平台虚拟化
平台虚拟化是针对计算机和操作系统的虚拟化,也就是大家最常见的一种虚拟化技术,Hyper-V,Xen,VMware等产品都是应用这类虚拟化技术。
2.资源虚拟化
资源虚拟化是指对特定的计算机系统资源的虚拟化,例如对内存、网络资源等等。
3.应用程序虚拟化
应用程序虚拟化的一个最典型的应用就是JAVA,生成的程序在指定的VM里面运行。
1.3.1 平台虚拟化
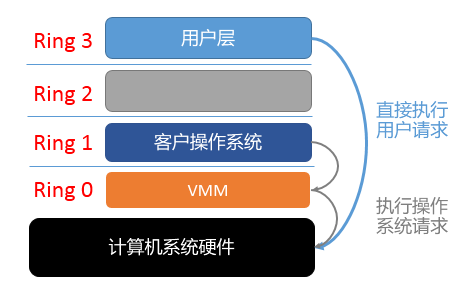
全虚拟化指的是虚拟机完完全全的模拟了计算机的底层硬件,包括处理器,物理内存,时钟,各类外设等等。这样呢,就不需要对原有硬件和操作系统进行改动。
在虚拟机软件访问计算机的物理硬件就可以看做软件访问了一个特定的接口。这个接口是由VMM(由Hypervisor技术提供)提供的既VMM提供完全模拟计算机底层硬件环境,并且这时在计算机(宿主机)上运行的操作系统(非虚拟机上运行的操作系统)会被降级运行(Ring0变化到Ring1)。
简单地说,全虚拟化的VMM必须运行在最高权限等级来完全控制主机系统,而Guest OS(客户操作系统)降级运行,不进行特权等级操作,Guest OS原有的特权等级操作交由VMM代为完成。
全虚拟化在早期的x86平台上也无法实现。直到2006年前后,AMD和Intel分别加入了AMD-V和Intel VT-x扩展。Intel VT-x采用了保护环的实现方式,以恰当地控制虚拟机的内核模式特权。然而在此之前许多x86上的平台VMM已经非常接近于实现全虚拟化,甚至宣称支持全虚拟化。比如 Adeos、Mac-on-Linux、Parallels Desktop for Mac、Parallels Workstation、VMware Workstation、VMware Server、VirtualBox、Win4BSD和Win4Lin Pro。
1.3.2 半虚拟化
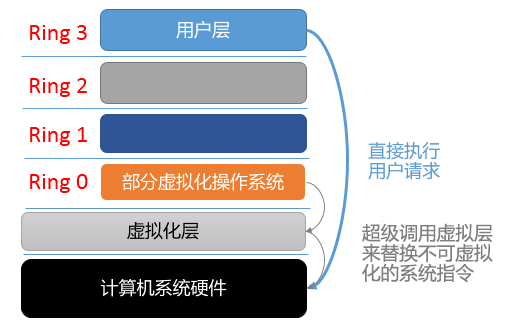
半虚拟化又叫超虚拟化,它是通过修改Guest OS部分特权状态的代码,以便与VMM交互。此类虚拟化技术的虚拟化软件性能都 非常好。 半虚拟化通过修改操作系统内核,替换掉不能虚拟化的程序,通过超级调用直接与底层的虚拟化层来通讯。由虚拟化层来进行内核操作。
半虚拟化的典型就是VMware Tools,该程序的VMware Tools服务为虚拟化层提供了后门服务,通过该服务可以进行大量的特权等级操作。 使用半虚拟化技术的软件有:Denali、Xen等。(Xen可以使用全虚拟化和半虚拟化两种状态)
1.3.3 硬件辅助虚拟化
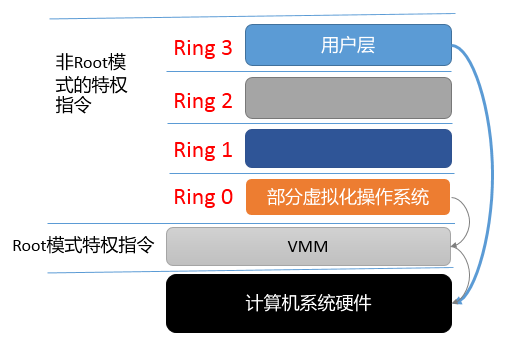
硬件辅助虚拟化(hardware-assisted virtualization)指的就是通过处理器提供的特殊指令来实现高效的全虚拟化,例如Intel-VT技术和AMD-V技术。
有了Intel-VT技术和AMD-V技术,Guest OS和VMM被完全隔离开来,同时,CPU虚拟化技术给CPU增加了新的Root模式,这样就实现了Guest OS和VMM的隔离。
在硬件辅助虚拟化中,硬件提供结构支持帮助创建虚拟机监视并允许客户机操作系统独立运行。硬件辅助虚拟化在1972年开始运行,它在IBM System/370上运行,使用了第一个虚拟机操作系统VM/370。在2005年与2006年,Intel和AMD为虚拟化提供了额外的硬件支持。支持硬件辅助虚拟化的有 Linux KVM, VMware Workstation, VMware Fusion, Microsoft Virtual PC, Xen, Parallels Desktop for Mac,VirtualBox和Parallels Workstation。
1.3.4 操作系统虚拟化

操作系统虚拟化(Operating system–level virtualization)更多的应用在VPS上,在传统的操作系统中,所有用户进程本质上是在同一个操作系统实例中运行,因此,操作系统的内核存在缺陷,那么势必会影响到其他正在运行的进程。
操作系统虚拟化是一种在服务器操作系统中使用的轻量级虚拟化技术,很简单,也很强大。
此类技术是内核通过创建多个虚拟的操作系统实例(N多内核和库)来隔离进程。不同实例中运行的程序无法知晓其他实例中运行了什么进程,也无法进行通讯。
在类Unix操作系统中,这个技术最早起源于标准的chroot机制,再进一步演化而成。除了将软件独立化的机制之外,内核通常也提供资源管理功能,使得单一软件容器在运作时,对于其他软件容器的造成的交互影响最小化。
应用这类技术最常见的就是OpenVZ了,但是OpenVZ的存在的超售问题一直受到很多草根站长的诟病。
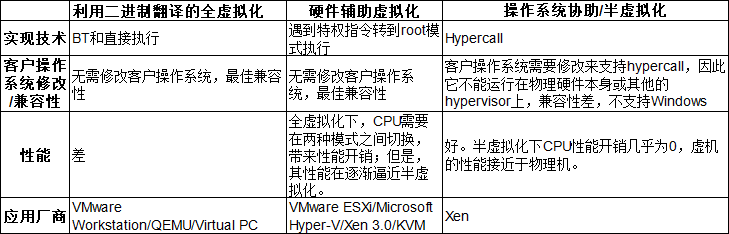
1.3.5 各类虚拟化技术对比
1.3.6 cgroups
cgroups,其名称源自控制组群(control groups)的简写,是Linux内核的一个功能,用来限制,控制与分离一个进程组群的资源(如CPU、内存、磁盘输入输出等)。
这个项目最早是由Google的工程师(主要是Paul Menage和Rohit Seth)在2006年发起,最早的名称为进程容器(process containers)。在2007年时,因为在Linux内核中,容器(container)这个名词有许多不同的意义,为避免混乱,被重命名为cgroup,并且被合并到2.6.24版的内核中去。自那以后,又添加了很多功能。
cgroups的一个设计目标是为不同的应用情况提供统一的接口,从控制单一进程(像nice)到操作系统层虚拟化(像OpenVZ,Linux-VServer,LXC)。cgroups提供:
- 资源限制:组可以被设置不超过设定的内存限制;这也包括虚拟内存。
- 优先级:一些组可能会得到大量的CPU[5] 或磁盘IO吞吐量。
- 结算:用来衡量系统确实把多少资源用到适合的目的上。
- 控制:冻结组或检查点和重启动。
1.4 KVM CPU 虚拟化
KVM 是基于CPU 辅助的全虚拟化方案,它需要CPU虚拟化特性的支持。
1.4.1 CPU 物理特性
使用numactl命令查看主机上的CPU 物理情况:
[root@clsn.io /root] # numactl --hardware available: 1 nodes (0) node 0 cpus: 0 1 2 3 4 5 12 13 14 15 16 17 node 0 size: 12276 MB node 0 free: 7060 MB node distances: node 0 0: 10 21
要支持 KVM, Intel CPU 的 vmx 或者 AMD CPU 的 svm 扩展必须生效了:
[root@clsn.io /root] # egrep "(vmx|svm)" /proc/cpuinfo flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx
fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology
nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid dca sse4_1
sse4_2 popcnt aes lahf_lm arat epb dts tpr_shadow vnmi flexpriority ept vpid
1.4.2 多 CPU 服务器架构:SMP,NMP,NUMA
从系统架构来看,目前的商用服务器大体可以分为三类:
- 多处理器结构 (SMP : Symmetric Multi-Processor):所有的CPU共享全部资源,如总线,内存和I/O系统等,操作系统或管理数据库的复本只有一个,这种系统有一个最大的特点就是共享所有资源。多个CPU之间没有区别,平等地访问内存、外设、一个操作系统。SMP 服务器的主要问题,那就是它的扩展能力非常有限。实验证明, SMP 服务器 CPU 利用率最好的情况是 2 至 4 个 CPU 。
- 海量并行处理结构 (MPP : Massive Parallel Processing) :NUMA 服务器的基本特征是具有多个 CPU 模块,每个 CPU 模块由多个 CPU( 如 4 个 ) 组成,并且具有独立的本地内存、 I/O 槽口等。在一个物理服务器内可以支持上百个 CPU 。但 NUMA 技术同样有一定缺陷,由于访问远地内存的延时远远超过本地内存,因此当 CPU 数量增加时,系统性能无法线性增加。MPP 模式则是一种分布式存储器模式,能够将更多的处理器纳入一个系统的存储器。一个分布式存储器模式具有多个节点,每个节点都有自己的存储器,可以配置为SMP模式,也可以配置为非SMP模式。单个的节点相互连接起来就形成了一个总系统。MPP可以近似理解成一个SMP的横向扩展集群,MPP一般要依靠软件实现。
- 非一致存储访问结构 (NUMA : Non-Uniform Memory Access):它由多个 SMP 服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。其基本特征是由多个 SMP 服务器 ( 每个 SMP 服务器称节点 ) 通过节点互联网络连接而成,每个节点只访问自己的本地资源 ( 内存、存储等 ) ,是一种完全无共享 (Share Nothing) 结构。
[root@clsn.io /root] #uname -a Linux clsn.io 2.6.32-431.23.3.el6.x86_64 #1 SMP Thu Jul 31 17:20:51 UTC 2014 x86_64 x86_64 x86_64 GNU/Linux
注:本机器为SMP架构
1.5 KVM 虚机的创建过程
1.5.1 KVM启动环境概述
支持虚拟化的 CPU 中都增加了新的功能。以 Intel VT 技术为例,它增加了两种运行模式:VMX root 模式和 VMX nonroot 模式。通常来讲,主机操作系统和 VMM 运行在 VMX root 模式中,客户机操作系统及其应用运行在 VMX nonroot 模式中。因为两个模式都支持所有的 ring,因此,客户机可以运行在它所需要的 ring 中(OS 运行在 ring 0 中,应用运行在 ring 3 中),VMM 也运行在其需要的 ring 中 (对 KVM 来说,QEMU 运行在 ring 3,KVM 运行在 ring 0)。
CPU 在两种模式之间的切换称为 VMX 切换。从 root mode 进入 nonroot mode,称为 VM entry;从 nonroot mode 进入 root mode,称为 VM exit。可见,CPU 受控制地在两种模式之间切换,轮流执行 VMM 代码和 Guest OS 代码。
对 KVM 虚机来说,运行在 VMX Root Mode 下的 VMM 在需要执行 Guest OS 指令时执行 VMLAUNCH 指令将 CPU 转换到 VMX non-root mode,开始执行客户机代码,即 VM entry 过程;在 Guest OS 需要退出该 mode 时,CPU 自动切换到 VMX Root mode,即 VM exit 过程。可见,KVM 客户机代码是受 VMM 控制直接运行在物理 CPU 上的。QEMU 只是通过 KVM 控制虚机的代码被 CPU 执行,但是它们本身并不执行其代码。也就是说,CPU 并没有真正的被虚级化成虚拟的 CPU 给客户机使用。
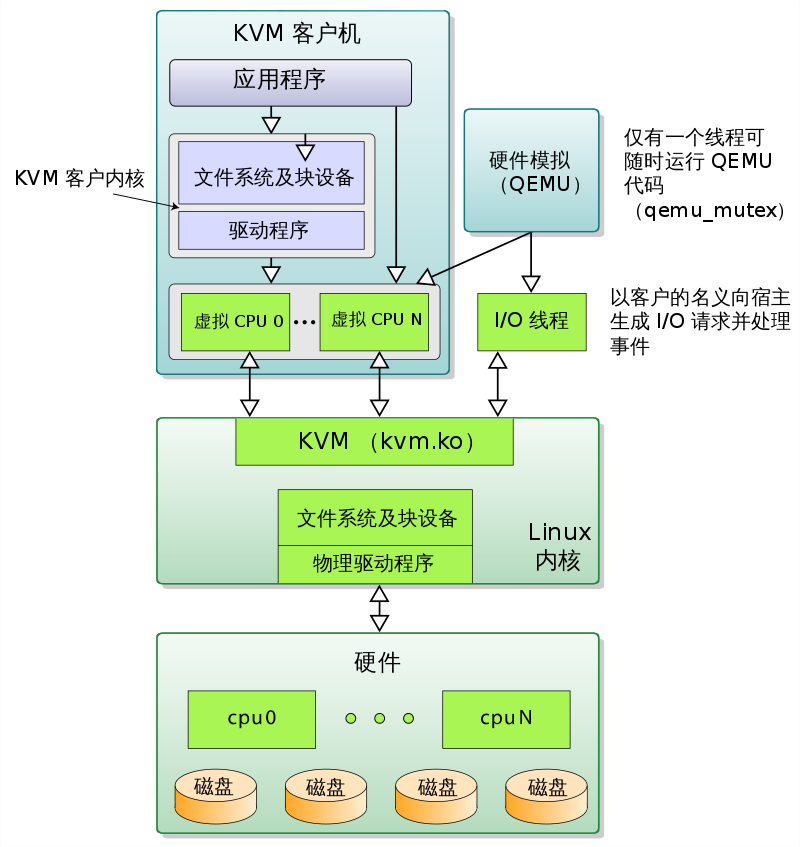
由上可见 :
- qemu-kvm 通过对 /dev/kvm 的 一系列 ICOTL 命令控制虚机
- 一个 KVM 虚机即一个 Linux qemu-kvm 进程,与其他 Linux 进程一样被Linux 进程调度器调度。
- KVM 虚机包括虚拟内存、虚拟CPU和虚机 I/O设备,其中,内存和 CPU 的虚拟化由 KVM 内核模块负责实现,I/O 设备的虚拟化由 QEMU 负责实现。
- KVM户机系统的内存是 qemu-kvm 进程的地址空间的一部分。
- KVM 虚机的 vCPU 作为 线程运行在 qemu-kvm 进程的上下文中。
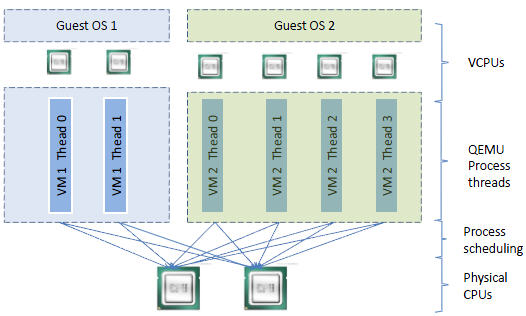
1.6 VM中代码是如何运行
一个普通的 Linux 内核有两种执行模式:内核模式(Kenerl)和用户模式 (User)。
为了支持带有虚拟化功能的 CPU,KVM 向 Linux 内核增加了第三种模式即客户机模式(Guest),该模式对应于 CPU 的 VMX non-root mode。
1.6.1 KVM kernel mode
KVM 内核模块作为 User mode 和 Guest mode 之间的桥梁:
- User mode 中的 QEMU-KVM 会通过 ICOTL 命令来运行虚拟机
- KVM 内核模块收到该请求后,它先做一些准备工作,比如将 VCPU 上下文加载到 VMCS (virtual machine control structure)等,然后驱动 CPU 进入 VMX non-root 模式,开始执行客户机代码
三种模式的分工为: - Guest 模式:执行客户机系统非 I/O 代码,并在需要的时候驱动 CPU 退出该模式
- Kernel 模式:负责将 CPU 切换到 Guest mode 执行 Guest OS 代码,并在 CPU 退出 Guest mode 时回到 Kenerl 模式
- User 模式:代表客户机系统执行 I/O 操作
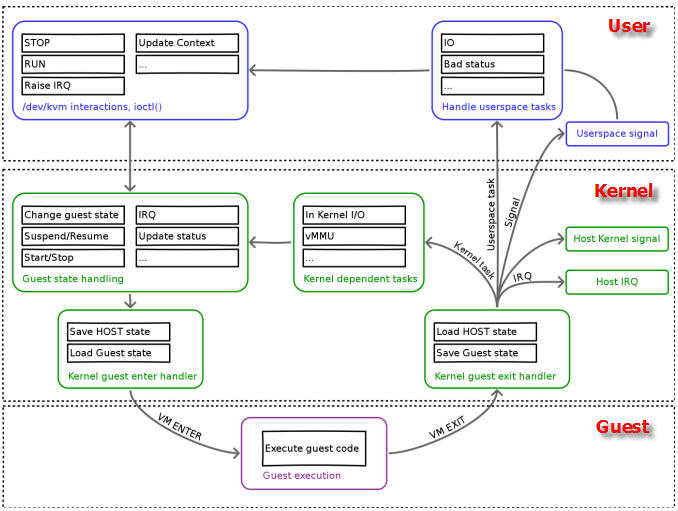
1.6.2 KVM processing
QEMU-KVM 相比原生 QEMU 的改动:
- 原生的 QEMU 通过指令翻译实现 CPU 的完全虚拟化,但是修改后的 QEMU-KVM 会调用 ICOTL 命令来调用 KVM 模块。
- 原生的 QEMU 是单线程实现,QEMU-KVM 是多线程实现。
主机 Linux 将一个虚拟视作一个 QEMU 进程,该进程包括下面几种线程: - I/O 线程用于管理模拟设备 vCPU 线程用于运行 Guest 代码
- 其它线程,比如处理 event loop,offloaded tasks 等的线程
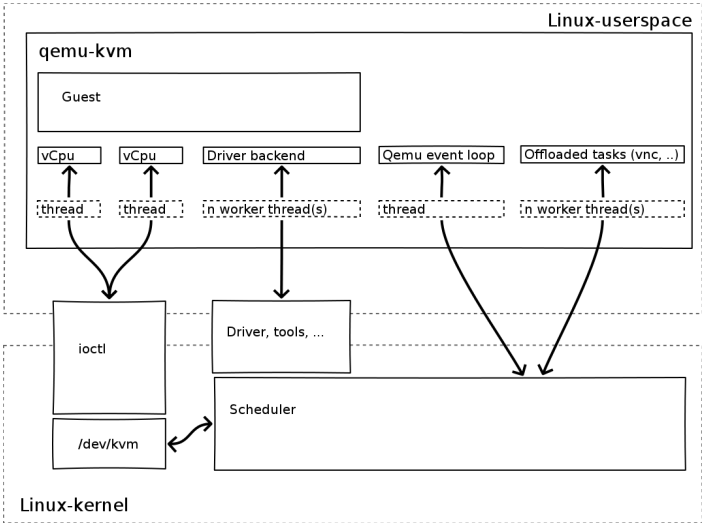
1.7 宿主机CPU结构和模型
KVM 支持 SMP 和 NUMA 多CPU架构的主机和客户机。对 SMP 类型的客户机,使用 “-smp”参数:
kvm -smp <n>[,cores=<ncores>][,threads=<nthreads>][,sockets=<nsocks>][,maxcpus=<maxcpus>]
对 NUMA 类型的客户机,使用 “-numa”参数:
kvm -numa <nodes>[,mem=<size>][,cpus=<cpu[-cpu>]][,nodeid=<node>]
CPU 模型 (models)定义了哪些主机的 CPU 功能 (features)会被暴露给客户机操作系统。为了在具有不同 CPU 功能的主机之间做安全的迁移,qemu-kvm 往往不会将主机CPU的所有功能都暴露给客户机。其原理如下:
你可以运行qemu-kvm -cpu ?命令来获取主机所支持的 CPU 模型列表。
[root@clsn.io /root] #kvm -cpu ? x86 Opteron_G5 AMD Opteron 63xx class CPU x86 Opteron_G4 AMD Opteron 62xx class CPU x86 Opteron_G3 AMD Opteron 23xx (Gen 3 Class Opteron) x86 Opteron_G2 AMD Opteron 22xx (Gen 2 Class Opteron) x86 Opteron_G1 AMD Opteron 240 (Gen 1 Class Opteron) x86 Haswell Intel Core Processor (Haswell) x86 SandyBridge Intel Xeon E312xx (Sandy Bridge) x86 Westmere Westmere E56xx/L56xx/X56xx (Nehalem-C) x86 Nehalem Intel Core i7 9xx (Nehalem Class Core i7) x86 Penryn Intel Core 2 Duo P9xxx (Penryn Class Core 2) x86 Conroe Intel Celeron_4x0 (Conroe/Merom Class Core 2) x86 cpu64-rhel5 QEMU Virtual CPU version (cpu64-rhel5) x86 cpu64-rhel6 QEMU Virtual CPU version (cpu64-rhel6) x86 n270 Intel(R) Atom(TM) CPU N270 @ 1.60GHz x86 athlon QEMU Virtual CPU version 0.12.1 x86 pentium3 x86 pentium2 x86 pentium x86 486 x86 coreduo Genuine Intel(R) CPU T2600 @ 2.16GHz x86 qemu32 QEMU Virtual CPU version 0.12.1 x86 kvm64 Common KVM processor x86 core2duo Intel(R) Core(TM)2 Duo CPU T7700 @ 2.40GHz x86 phenom AMD Phenom(tm) 9550 Quad-Core Processor x86 qemu64 QEMU Virtual CPU version 0.12.1 Recognized CPUID flags: f_edx: pbe ia64 tm ht ss sse2 sse fxsr mmx acpi ds clflush pn pse36 pat cmov mca
pge mtrr sep apic cx8 mce pae msr tsc pse de vme fpu f_ecx: hypervisor rdrand f16c avx osxsave xsave aes tsc-deadline popcnt movbe x2apic
sse4.2|sse4_2 sse4.1|sse4_1 dca pcid pdcm xtpr cx16 fma cid ssse3 tm2 est smx vmx ds_cpl monitor dtes64 pclmulqdq|pclmuldq pni|sse3 extf_edx: 3dnow 3dnowext lm|i64 rdtscp pdpe1gb fxsr_opt|ffxsr fxsr mmx mmxext nx|xd
pse36 pat cmov mca pge mtrr syscall apic cx8 mce pae msr tsc pse de vme fpu extf_ecx: perfctr_nb perfctr_core topoext tbm nodeid_msr tce fma4 lwp wdt skinit xop
ibs osvw 3dnowprefetch misalignsse sse4a abm cr8legacy extapic svm cmp_legacy lahf_lm
每个 Hypervisor 都有自己的策略,来定义默认上哪些CPU功能会被暴露给客户机。至于哪些功能会被暴露给客户机系统,取决于客户机的配置。qemu32 和 qemu64 是基本的客户机 CPU 模型,但是还有其他的模型可以使用。你可以使用 qemu-kvm 命令的 -cpu 参数来指定客户机的 CPU 模型,还可以附加指定的 CPU 特性。"-cpu" 会将该指定 CPU 模型的所有功能全部暴露给客户机,即使某些特性在主机的物理CPU上不支持,这时候QEMU/KVM 会模拟这些特性,因此,这时候也许会出现一定的性能下降。
RedHat Linux 6 上使用默认的 cpu64-rhe16 作为客户机 CPU model,可以指定特定的 CPU model 和 feature:
[root@clsn.io /root] #qemu-kvm -cpu Nehalem,+aes
更多详情可参考:https://clsn.io/clsn/lx194.html
1.8 vCPU 数目的分配方法
不是客户机的 vCPU 越多,其性能就越好,因为线程切换会耗费大量的时间;应该根据负载需要分配最少的 vCPU。
主机上的客户机的 vCPU 总数不应该超过物理 CPU 内核总数。不超过的话,就不存在 CPU 竞争,每个 vCPU 线程在一个物理 CPU 核上被执行;超过的话,会出现部分线程等待 CPU 以及一个 CPU 核上的线程之间的切换,这会有 overhead。
将负载分为计算负载和 I/O 负载,对计算负载,需要分配较多的 vCPU,甚至考虑 CPU 亲和性,将指定的物理 CPU 核分给给这些客户机。
1.8.1确定 vCPU 数目的步骤
假如我们要创建一个VM,以下几步可以帮助确定合适的vCPU数目
(1)了解应用并设置初始值
该应用是否是关键应用,是否有Service Level Agreement。一定要对运行在虚拟机上的应用是否支持多线程深入了解。咨询应用的提供商是否支持多线程和SMP(Symmetricmulti-processing)。参考该应用在物理服务器上运行时所需要的CPU个数。如果没有参照信息,可设置1vCPU作为初始值,然后密切观测资源使用情况。
(2)观测资源使用情况
确定一个时间段,观测该虚拟机的资源使用情况。时间段取决于应用的特点和要求,可以是数天,甚至数周。不仅观测该VM的CPU使用率,而且观测在操作系统内该应用对CPU的占用率。
特别要区分CPU使用率平均值和CPU使用率峰值。
假如分配有4个vCPU,如果在该VM上的应用的CPU使用峰值等于25%, 也就是仅仅能最多使用25%的全部CPU资源,说明该应用是单线程的,仅能够使用一个vCPU (4 * 25% = 1 )
平均值小于38%,而峰值小于45%,考虑减少 vCPU 数目
平均值大于75%,而峰值大于90%,考虑增加 vCPU 数目
(3)更改vCPU数目并观测结果
每次的改动尽量少,如果可能需要4vCPU,先设置2vCPU在观测性能是否可以接受。
1.9 参考文献
https://clsn.io/clsn/lx194.html
http://www.cnblogs.com/popsuper1982/p/3815398.html
http://frankdenneman.nl/2013/09/18/vcpu-configuration-performance-impact-between-virtual-sockets-and-virtual-cores/
https://www.dadclab.com/archives/2509.jiecao
https://zh.wikipedia.org/zh-hans/%E5%88%86%E7%BA%A7%E4%BF%9D%E6%8A%A4%E5%9F%9F
https://www.cnblogs.com/cyttina/archive/2013/09/24/3337594.html
https://www.cnblogs.com/sammyliu/p/4543597.html
http://www.cnblogs.com/xusongwei/archive/2012/07/30/2615592.html
https://blog.csdn.net/hshl1214/article/details/62046736

