环境篇:Kylin3.0.1集成CDH6.2.0
环境篇:Kylin3.0.1集成CDH6.2.0

Kylin是什么?
Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它能在亚秒内查询巨大的表。
Apache Kylin™ 令使用者仅需三步,即可实现超大数据集上的亚秒级查询。
- 定义数据集上的一个星形或雪花形模型
- 在定义的数据表上构建cube
- 使用标准 SQL 通过 ODBC、JDBC 或 RESTFUL API 进行查询,仅需亚秒级响应时间即可获得查询结果

如果没有Kylin
大数据在数据积累后,需要计算,而数据越多,算力越差,内存需求也越高,询时间与数据量成线性增长,而这些对于Kylin影响不大,大数据中硬盘往往比内存要更便宜,Kylin通过与计算的形式,以空间换时间,亚秒级的响应让人们爱不释手。
注:所谓询时间与数据量成线性增长:假设查询 1 亿条记录耗时 1 分钟,那么查询 10 亿条记录就需 10分钟,100 亿条记录就至少需要 1 小时 40 分钟。
1 Kylin架构
Kylin 提供与多种数据可视化工具的整合能力,如 Tableau,PowerBI 等,令用户可以使用 BI 工具对 Hadoop 数据进行分析
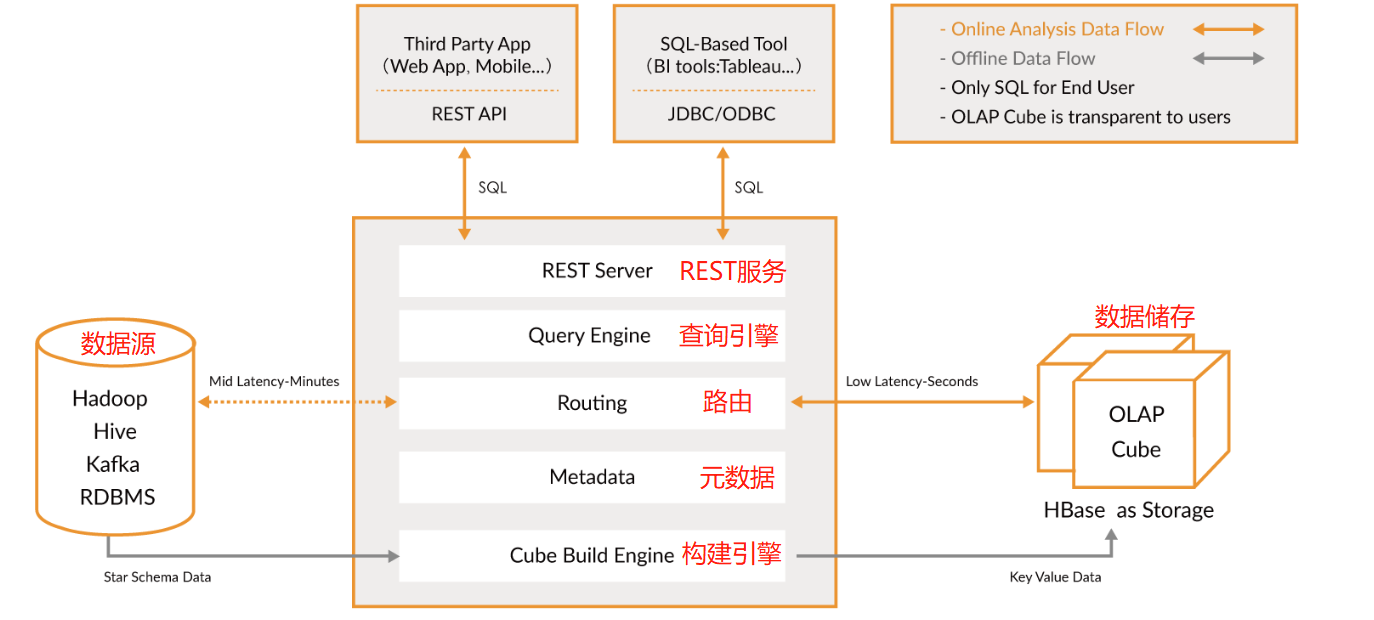
- REST Server REST Server
是一套面向应用程序开发的入口点,旨在实现针对 Kylin 平台的应用开发 工作。 此类应用程序可以提供查询、获取结果、触发 cube 构建任务、获取元数据以及获取 用户权限等等。另外可以通过 Restful 接口实现 SQL 查询。
- 查询引擎(Query Engine)
当 cube 准备就绪后,查询引擎就能够获取并解析用户查询。它随后会与系统中的其它 组件进行交互,从而向用户返回对应的结果。
- 路由器(Routing)
在最初设计时曾考虑过将 Kylin 不能执行的查询引导去 Hive 中继续执行,但在实践后 发现 Hive 与 Kylin 的速度差异过大,导致用户无法对查询的速度有一致的期望,很可能大 多数查询几秒内就返回结果了,而有些查询则要等几分钟到几十分钟,因此体验非常糟糕。 最后这个路由功能在发行版中默认关闭。
- 元数据管理工具(Metadata)
Kylin 是一款元数据驱动型应用程序。元数据管理工具是一大关键性组件,用于对保存 在 Kylin 当中的所有元数据进行管理,其中包括最为重要的 cube 元数据。其它全部组件的 正常运作都需以元数据管理工具为基础。 Kylin 的元数据存储在 hbase 中。
- 任务引擎(Cube Build Engine)
这套引擎的设计目的在于处理所有离线任务,其中包括 shell 脚本、Java API 以及 MapReduce 任务等等。任务引擎对 Kylin 当中的全部任务加以管理与协调,从而确保每一项任务 都能得到切实执行并解决其间出现的故障。
2 Kylin软硬件要求
- 软件要求
- Hadoop: 2.7+, 3.1+ (since v2.5)
- Hive: 0.13 - 1.2.1+
- HBase: 1.1+, 2.0 (since v2.5)
- Spark (optional) 2.3.0+
- Kafka (optional) 1.0.0+ (since v2.5)
- JDK: 1.8+ (since v2.5)
- OS: Linux only, CentOS 6.5+ or Ubuntu 16.0.4+
- 硬件要求
- 最低配置:4 core CPU, 16 GB memory
- 高负载场景:24 core CPU, 64 GB memory
3 Kylin单机安装
3.1 修改环境变量
vim /etc/profile
#>>>注意地址指定为自己的
#kylin
export KYLIN_HOME=/usr/local/src/kylin/apache-kylin-3.0.1-bin-cdh60
export PATH=$PATH:$KYLIN_HOME/bin
#cdh
export CDH_HOME=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373
#hadoop
export HADOOP_HOME=${CDH_HOME}/lib/hadoop
export HADOOP_DIR=${HADOOP_HOME}
export HADOOP_CLASSPATH=${HADOOP_HOME}
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#hbase
export HBASE_HOME=${CDH_HOME}/lib/hbase
export PATH=$PATH:$HBASE_HOME/bin
#hive
export HIVE_HOME=${CDH_HOME}/lib/hive
export PATH=$PATH:$HIVE_HOME/bin
#spark
export SPARK_HOME=${CDH_HOME}/lib/spark
export PATH=$PATH:$SPARK_HOME/bin
#kafka
export KAFKA_HOME=${CDH_HOME}/lib/kafka
export PATH=$PATH:$KAFKA_HOME/bin
#<<<
source /etc/profile
3.2 修改hdfs用户权限
usermod -s /bin/bash hdfs
su hdfs
hdfs dfs -mkdir /kylin
hdfs dfs -chmod a+rwx /kylin
su
3.3 上传安装包解压
mkdir /usr/local/src/kylin
cd /usr/local/src/kylin
tar -zxvf apache-kylin-3.0.1-bin-cdh60.tar.gz
cd /usr/local/src/kylin/apache-kylin-3.0.1-bin-cdh60
3.4 Java兼容hbase
- hbase 所有节点
vim /opt/cloudera/parcels/CDH/lib/hbase/bin/hbase(注意为环境里设置的hbase路径)
在CLASSPATH=${CLASSPATH}:$JAVA_HOME/lib/tools.jar后添加
>>---
:/opt/cloudera/parcels/CDH/lib/hbase/lib/*
<<---
- Kylin节点添加jar包
cp /opt/cloudera/cm/common_jars/commons-configuration-1.9.cf57559743f64f0b3a504aba449c9649.jar /usr/local/src/kylin/apache-kylin-3.0.1-bin-cdh60/tomcat/lib
这2步不做会引起 Could not find or load main class org.apache.hadoop.hbase.util.GetJavaProperty
3.5 启动停止
./bin/kylin.sh start
#停止 ./bin/kylin.sh stop
3.6 web页面
访问端口7070
账号密码:ADMIN / KYLIN
4 Kylin集群安装
4.1 修改环境变量
vim /etc/profile
#>>>注意地址指定为自己的
#kylin
export KYLIN_HOME=/usr/local/src/kylin/apache-kylin-3.0.1-bin-cdh60
export PATH=$PATH:$KYLIN_HOME/bin
#cdh
export CDH_HOME=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373
#hadoop
export HADOOP_HOME=${CDH_HOME}/lib/hadoop
export HADOOP_DIR=${HADOOP_HOME}
export HADOOP_CLASSPATH=${HADOOP_HOME}
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#hbase
export HBASE_HOME=${CDH_HOME}/lib/hbase
export PATH=$PATH:$HBASE_HOME/bin
#hive
export HIVE_HOME=${CDH_HOME}/lib/hive
export PATH=$PATH:$HIVE_HOME/bin
#spark
export SPARK_HOME=${CDH_HOME}/lib/spark
export PATH=$PATH:$SPARK_HOME/bin
#kafka
export KAFKA_HOME=${CDH_HOME}/lib/kafka
export PATH=$PATH:$KAFKA_HOME/bin
#<<<
source /etc/profile
4.2 修改hdfs用户权限
usermod -s /bin/bash hdfs
su hdfs
hdfs dfs -mkdir /kylin
hdfs dfs -chmod a+rwx /kylin
su
4.3 上传安装包解压
mkdir /usr/local/src/kylin
cd /usr/local/src/kylin
tar -zxvf apache-kylin-3.0.1-bin-cdh60.tar.gz
cd /usr/local/src/kylin/apache-kylin-3.0.1-bin-cdh60
4.4 Java兼容hbase
- hbase 所有节点
在CLASSPATH=${CLASSPATH}:$JAVA_HOME/lib/tools.jar后添加
vim /opt/cloudera/parcels/CDH/lib/hbase/bin/hbase
>>---
:/opt/cloudera/parcels/CDH/lib/hbase/lib/*
<<---
- Kylin节点添加jar包
cp /opt/cloudera/cm/common_jars/commons-configuration-1.9.cf57559743f64f0b3a504aba449c9649.jar /usr/local/src/kylin/apache-kylin-3.0.1-bin-cdh60/tomcat/lib
这2步不做会引起 Could not find or load main class org.apache.hadoop.hbase.util.GetJavaProperty
4.5 修改kylin配置文件
Kylin根据自己的运行职责状态,可以划分为以下三大类角色
- Job节点:仅用于任务调度,不用于查询
- Query节点:仅用于查询,不用于构建任务的调度
- All节点:模式代表该服务同时用于任务调度和 SQL 查询
- 2.0以前同一个集群只能有一个节点(Kylin实例)用于job调度(all或者job模式的只能有一个实例)
- 2.0开始可以多个job或者all节点实现HA
vim conf/kylin.properties
>>----
#指定元数据库路径,默认值为 kylin_metadata@hbase,确保kylin集群使用一致
kylin.metadata.url=kylin_metadata@hbase
#指定 Kylin 服务所用的 HDFS 路径,默认值为 /kylin,请确保启动 Kylin 实例的用户有读写该目录的权限
kylin.env.hdfs-working-dir=/kylin
kylin.server.mode=all
kylin.server.cluster-servers=cdh01.cm:7070,cdh02.cm:7070,cdh03.cm:7070
kylin.storage.url=hbase
#构建任务失败后的重试次数,默认值为 0
kylin.job.retry=2
#最大构建并发数,默认值为 10
kylin.job.max-concurrent-jobs=10
#构建引擎间隔多久检查 Hadoop 任务的状态,默认值为 10(s)
kylin.engine.mr.yarn-check-interval-seconds=10
#MapReduce 任务启动前会依据输入预估 Reducer 接收数据的总量,再除以该参数得出 Reducer 的数目,默认值为 500(MB)
kylin.engine.mr.reduce-input-mb=500
#MapReduce 任务中 Reducer 数目的最大值,默认值为 500
kylin.engine.mr.max-reducer-number=500
#每个 Mapper 可以处理的行数,默认值为 1000000,如果将这个值调小,会起更多的 Mapper
kylin.engine.mr.mapper-input-rows=1000000
#启用分布式任务锁
kylin.job.scheduler.default=2
kylin.job.lock=org.apache.kylin.storage.hbase.util.ZookeeperJobLock
<<----
4.6 启动停止
所有Kylin节点
./bin/kylin.sh start
#停止 ./bin/kylin.sh stop
4.7 nginx负载均衡
yum -y install nginx
vim /etc/nginx/nginx.conf
>>---http中添加替换内容
upstream kylin {
least_conn;
server 192.168.37.10:7070 weight=8;
server 192.168.37.11:7070 weight=7;
server 192.168.37.12:7070 weight=7;
}
server {
listen 9090;
server_name localhost;
location / {
proxy_pass http://kylin;
}
}
<<---
#重启 nginx 服务
systemctl restart nginx
4.8 访问web页面
访问任何节点的7070端口都可以进入kylin
访问nginx所在机器9090端口/kylin负载均衡进入kylin
账号密码:ADMIN / KYLIN
4 大规模并行处理@列式存储
自从 10 年前 Hadoop 诞生以来,大数据的存储和批处理问题均得到了妥善解决,而如何高速地分析数据也就成为了下一个挑战。于是各式各样的“SQL on Hadoop”技术应运而生,其中以 Hive 为代表,Impala、Presto、Phoenix、Drill、 SparkSQL 等紧随其后(何以解忧--唯有CV SQL BOY)。它们的主要技术是“大规模并行处理”(Massive Parallel Processing,MPP)和“列式存储”(Columnar Storage)。
大规模并行处理可以调动多台机器一起进行并行计算,用线性增加的资源来换取计算时间的线性下降。
列式存储则将记录按列存放,这样做不仅可以在访问时只读取需要的列,还可以利用存储设备擅长连续读取的特点,大大提高读取的速率。
这两项关键技术使得 Hadoop 上的 SQL 查询速度从小时提高到了分钟。 然而分钟级别的查询响应仍然离交互式分析的现实需求还很远。分析师敲入 查询指令,按下回车,还需要去倒杯咖啡,静静地等待查询结果。得到结果之后才能根据情况调整查询,再做下一轮分析。如此反复,一个具体的场景分析常常需要几小时甚至几天才能完成,效率低下。 这是因为大规模并行处理和列式存储虽然提高了计算和存储的速度,但并没有改变查询问题本身的时间复杂度,也没有改变查询时间与数据量成线性增长的关系这一事实。
假设查询 1 亿条记录耗时 1 分钟,那么查询 10 亿条记录就需 10分钟,100 亿条记录就至少需要 1 小时 40 分钟。 当然,可以用很多的优化技术缩短查询的时间,比如更快的存储、更高效的压缩算法,等等,但总体来说,查询性能与数据量呈线性相关这一点是无法改变的。虽然大规模并行处理允许十倍或百倍地扩张计算集群,以期望保持分钟级别的查询速度,但购买和部署十倍或百倍的计算集群又怎能轻易做到,更何况还有 高昂的硬件运维成本。 另外,对于分析师来说,完备的、经过验证的数据模型比分析性能更加重要, 直接访问纷繁复杂的原始数据并进行相关分析其实并不是很友好的体验,特别是在超大规模的数据集上,分析师将更多的精力花在了等待查询结果上,而不是在更加重要的建立领域模型上。
5 Kylin如何解决海量数据的查询问题
**Apache Kylin 的初衷就是要解决千亿条、万亿条记录的秒级查询问题,其中的关键就是要打破查询时间随着数据量成线性增长的这个规律。根据OLAP分析,可以注意到两个结论: **
-
大数据查询要的一般是统计结果,是多条记录经过聚合函数计算后的统计值。原始的记录则不是必需的,或者访问频率和概率都极低。
-
聚合是按维度进行的,由于业务范围和分析需求是有限的,有意义的维度聚合组合也是相对有限的,一般不会随着数据的膨胀而增长。
**基于以上两点,我们可以得到一个新的思路——“预计算”。应尽量多地预先计算聚合结果,在查询时刻应尽量使用预算的结果得出查询结果,从而避免直 接扫描可能无限增长的原始记录。 **
举例来说,使用如下的 SQL 来查询 11月 11日 那天销量最高的商品:
select item,sum(sell_amount)
from sell_details
where sell_date='2020-11-11'
group by item
order by sum(sell_amount) desc
用传统的方法时需要扫描所有的记录,再找到 11月 11日 的销售记录,然后按商品聚合销售额,最后排序返回。
假如 11月 11日 有 1 亿条交易,那么查询必须读取并累计至少 1 亿条记录,且这个查询速度会随将来销量的增加而逐步下降。如果日交易量提高一倍到 2 亿,那么查询执行的时间可能也会增加一倍。
而使用预 计算的方法则会事先按维度 [sell_date , item] 计 算 sum(sell_amount)并存储下来,在查询时找到 11月 11日 的销售商品就可以直接排序返回了。读取的记录数最大不会超过维度[sell_date,item]的组合数。
显然这个数字将远远小于实际的销售记录,比如 11月 11日 的 1 亿条交易包含了 100万条商品,那么预计算后就只有 100 万条记录了,是原来的百分之一。并且这些 记录已经是按商品聚合的结果,因此又省去了运行时的聚合运算。从未来的发展来看,查询速度只会随日期和商品数目(时间,商品维度)的增长而变化,与销售记录的总数不再有直接联系。假如日交易量提高一倍到 2 亿,但只要商品的总数不变,那么预计算的结果记录总数就不会变,查询的速度也不会变。
预计算就是 Kylin 在“大规模并行处理”和“列式存储”之外,提供给大数据分析的第三个关键技术。
6 Kylin 入门案例
6.1 hive数据准备
--创建数据库kylin_hive
create database kylin_hive;
--创建表部门表dept
create external table if not exists kylin_hive.dept(
deptno int,
dname string,
loc int )
row format delimited fields terminated by '\t';
--添加数据
INSERT INTO TABLE kylin_hive.dept VALUES(10,"ACCOUNTING",1700),(20,"RESEARCH",1800),(30,"SALES",1900),(40,"OPERATIONS",1700)
--查看数据
SELECT * FROM kylin_hive.dept
--创建员工表emp
create external table if not exists kylin_hive.emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
--添加数据
INSERT INTO TABLE kylin_hive.emp VALUES(7369,"SMITHC","LERK",7902,"1980-12-17",800.00,0.00,20),(7499,"ALLENS","ALESMAN",7698,"1981-2-20",1600.00,300.00,30),(7521,"WARDSA","LESMAN",7698,"1981-2-22",1250.00,500.00,30),(7566,"JONESM","ANAGER",7839,"1981-4-2",2975.00,0.00,20),(7654,"MARTIN","SALESMAN",7698,"1981-9-28",1250.00,1400.00,30),(7698,"BLAKEM","ANAGER",7839,"1981-5-1",2850.00,0.00,30),(7782,"CLARKM","ANAGER",7839,"1981-6-9",2450.00,0.00,10),(7788,"SCOTTA","NALYST",7566,"1987-4-19",3000.00,0.00,20),(7839,"KINGPR","ESIDENT",7533,"1981-11-17",5000.00,0.00,10),(7844,"TURNER","SALESMAN",7698,"1981-9-8",1500.00,0.00,30),(7876,"ADAMSC","LERK",7788,"1987-5-23",1100.00,0.00,20),(7900,"JAMESC","LERK",7698,"1981-12-3",950.00,0.00,30),(7902,"FORDAN","ALYST",7566,"1981-12-3",3000.00,0.00,20),(7934,"MILLER","CLERK",7782,"1982-1-23",1300.00,0.00,10)
--查看数据
SELECT * FROM kylin_hive.emp
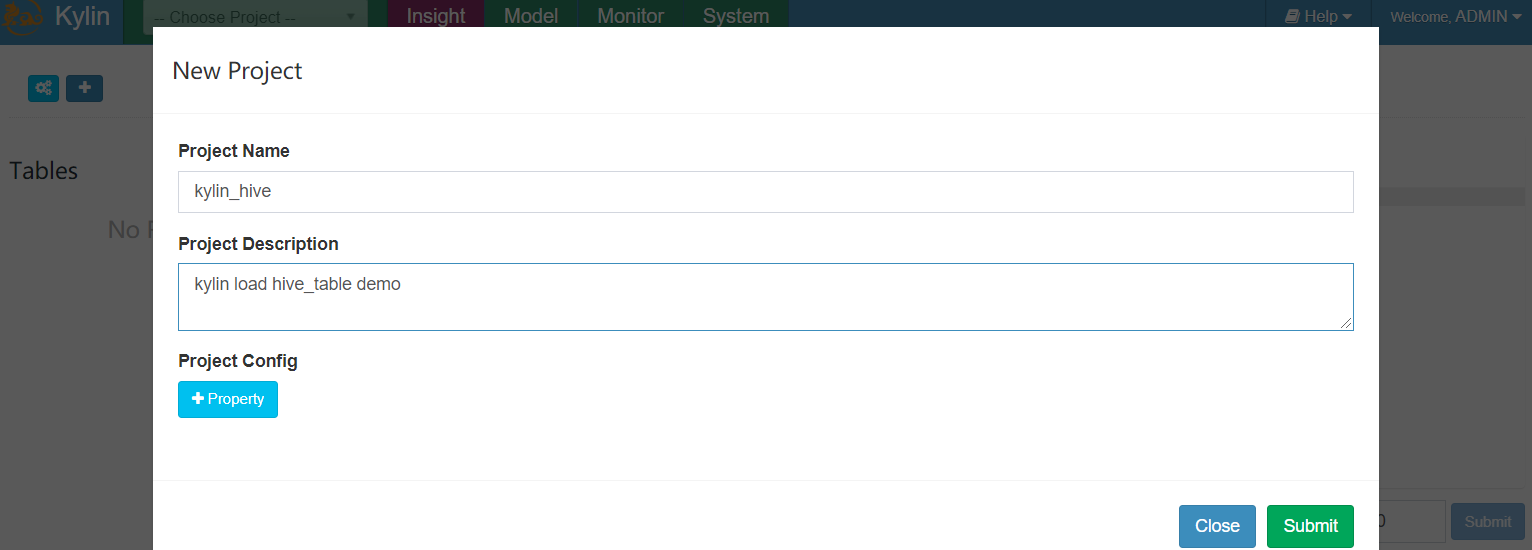
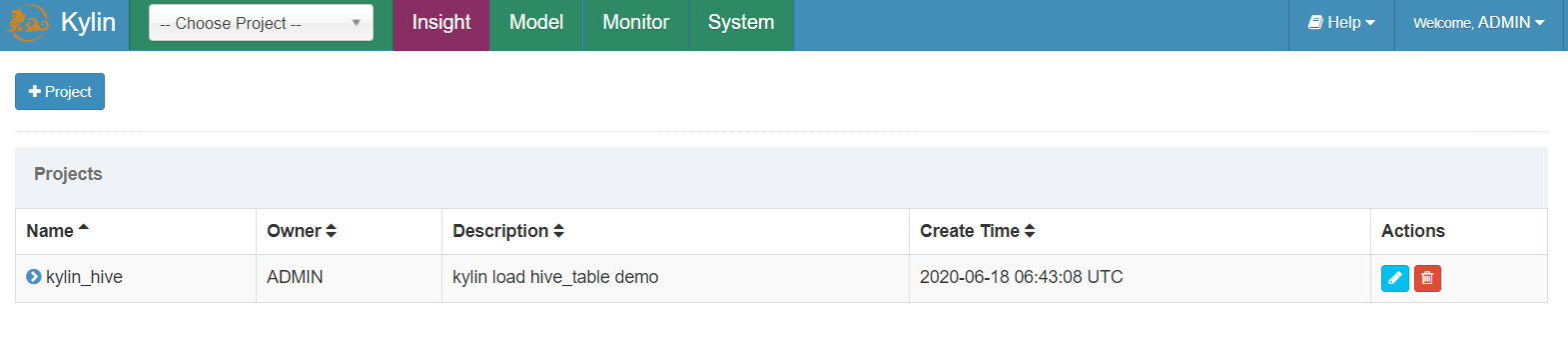
6.2 创建工程

- 输入工程名称以及工程描述
6.3 Kylin加载Hive表
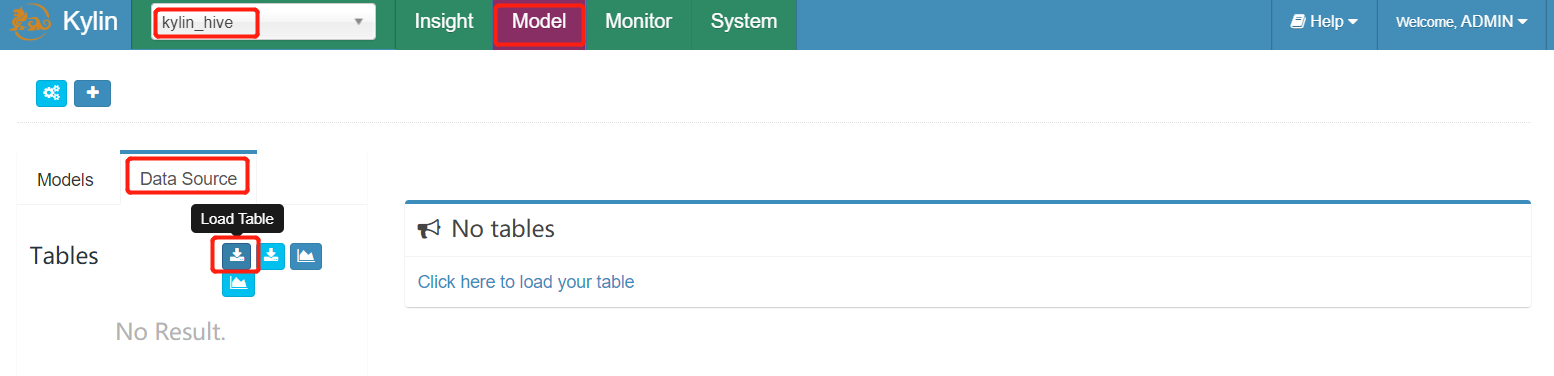
虽然 Kylin 使用 SQL 作为查询接口并利用 Hive 元数据,Kylin 不会让用户查询所有的 hive 表,因为到目前为止它是一个预构建 OLAP(MOLAP) 系统。为了使表在 Kylin 中可用,使用 “Sync” 方法能够方便地从 Hive 中同步表。
- 选择项目添加hive数据源
- 添加数据源表-->hive库名称.表名称(以逗号分隔)
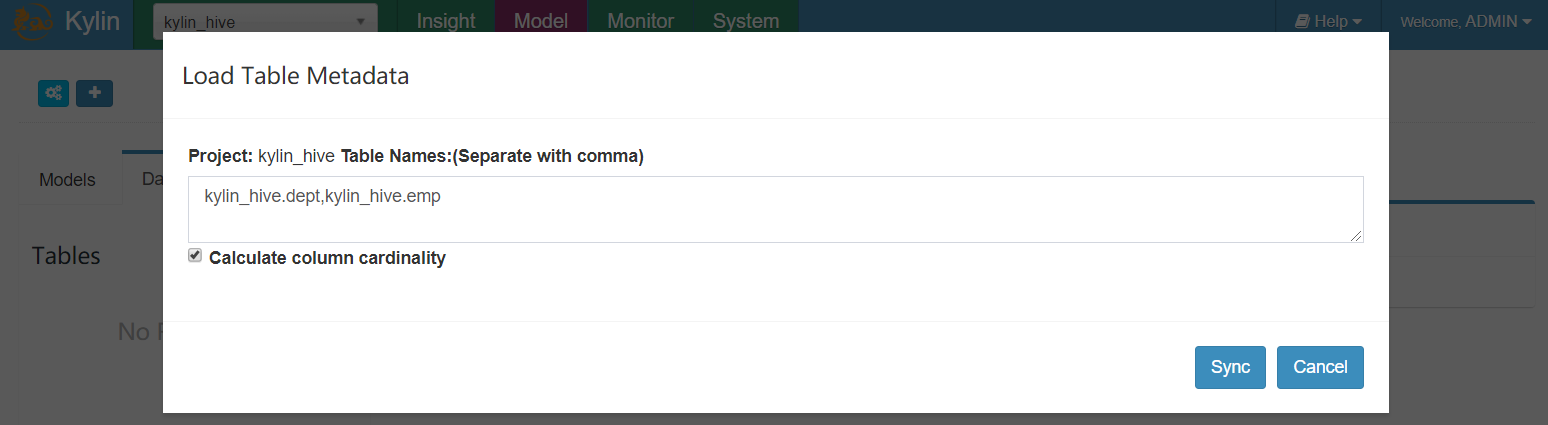
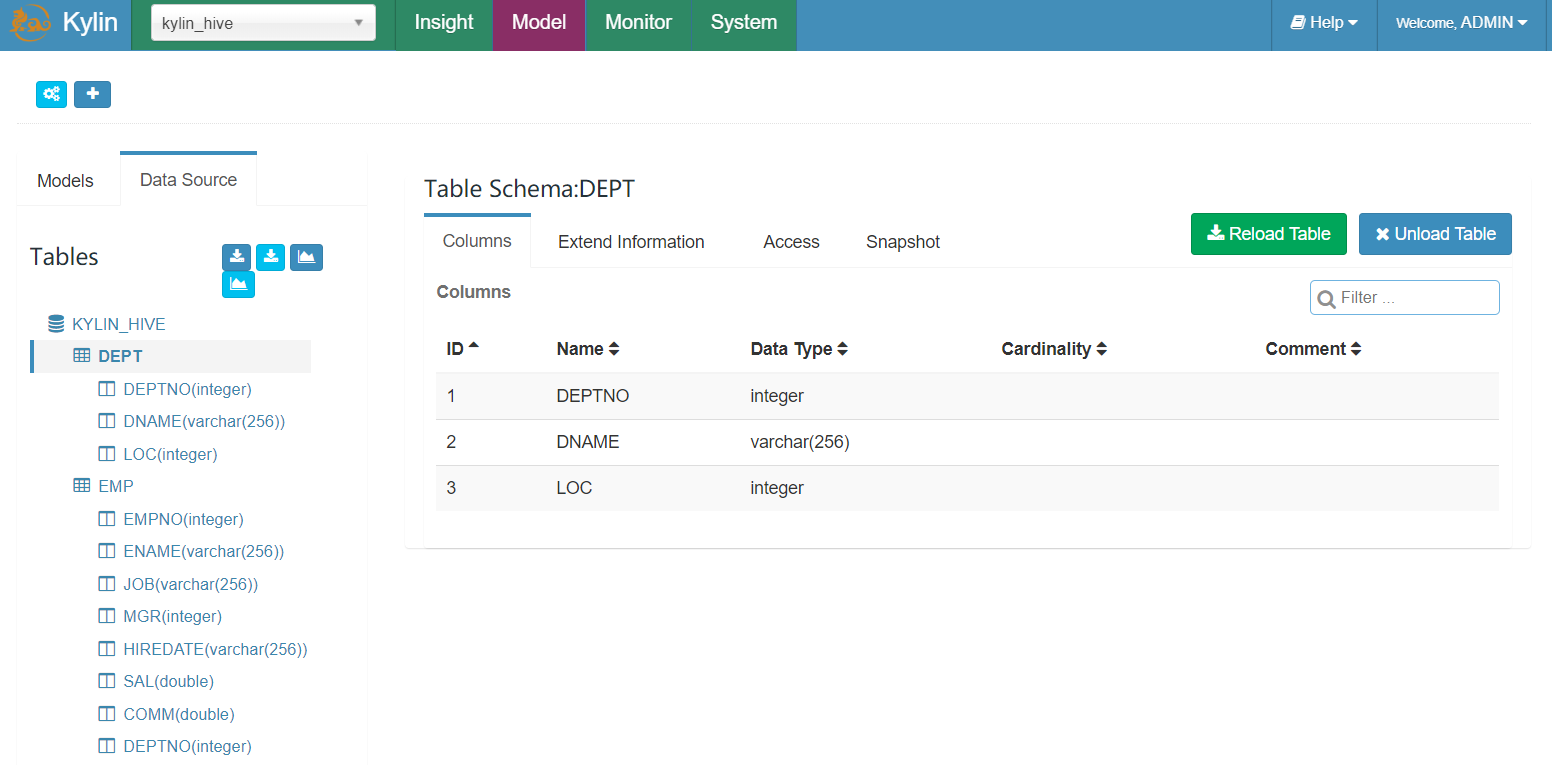
- 这里只添加了表的Schema元信息,如果需要加载数据,还需要点击Reload Table
6.4 Kylin添加Models(模型)
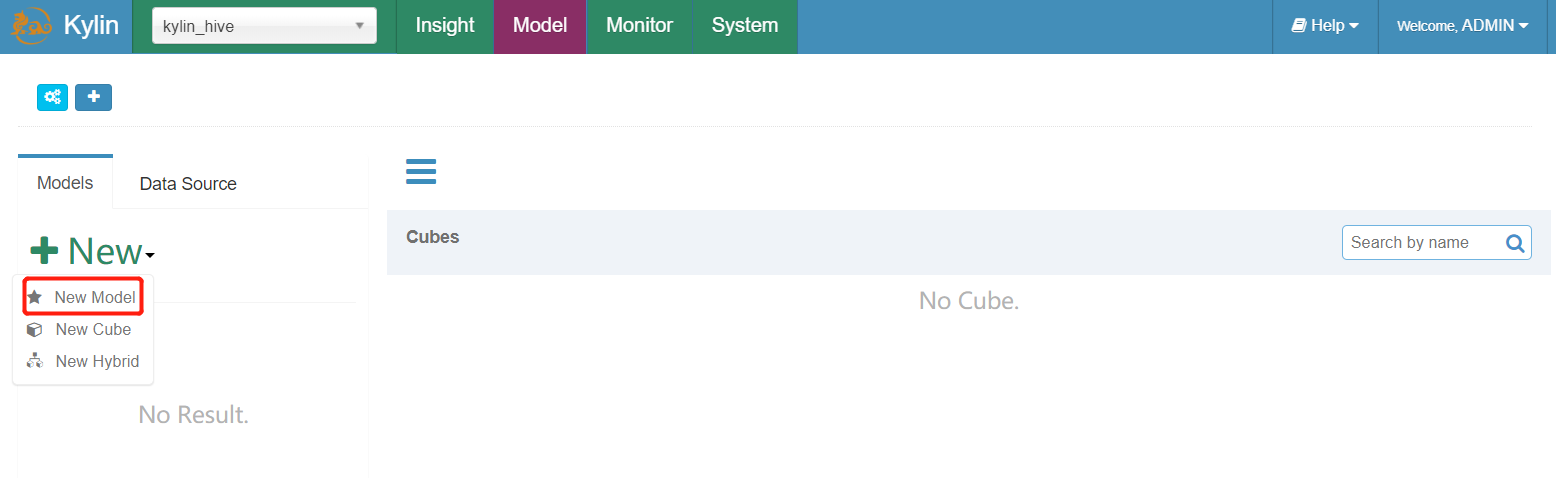
- 填写模型名字
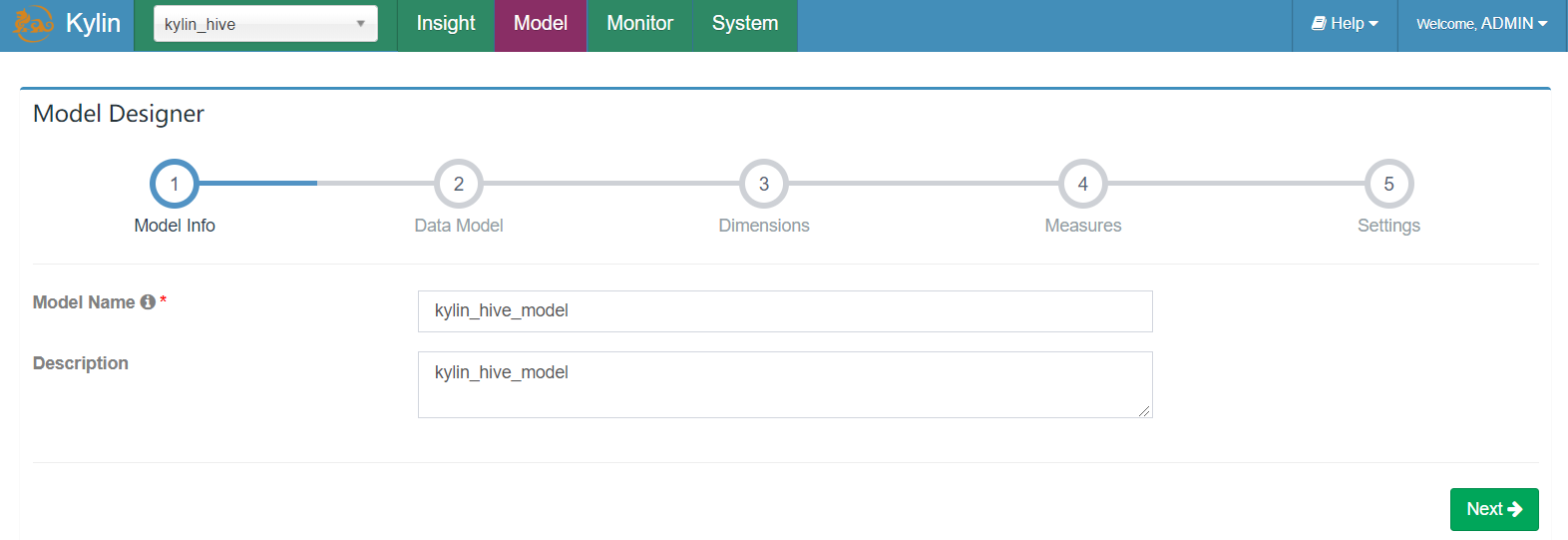
- 选择事实表,这里选择员工EMP表为事实表
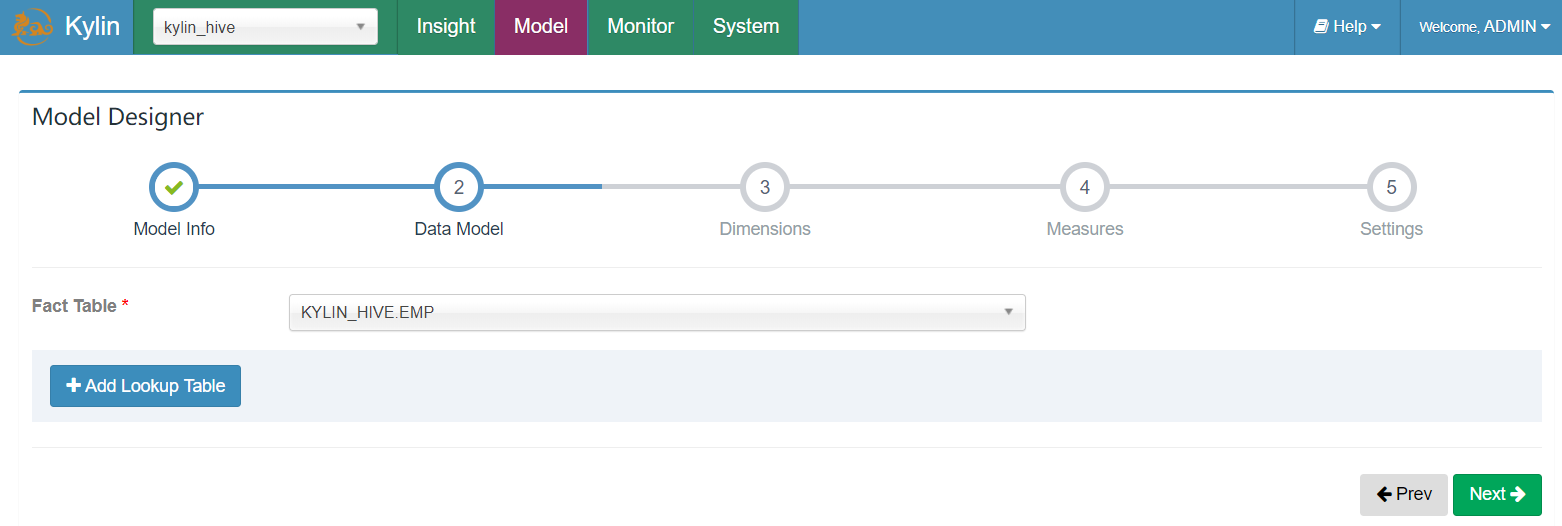
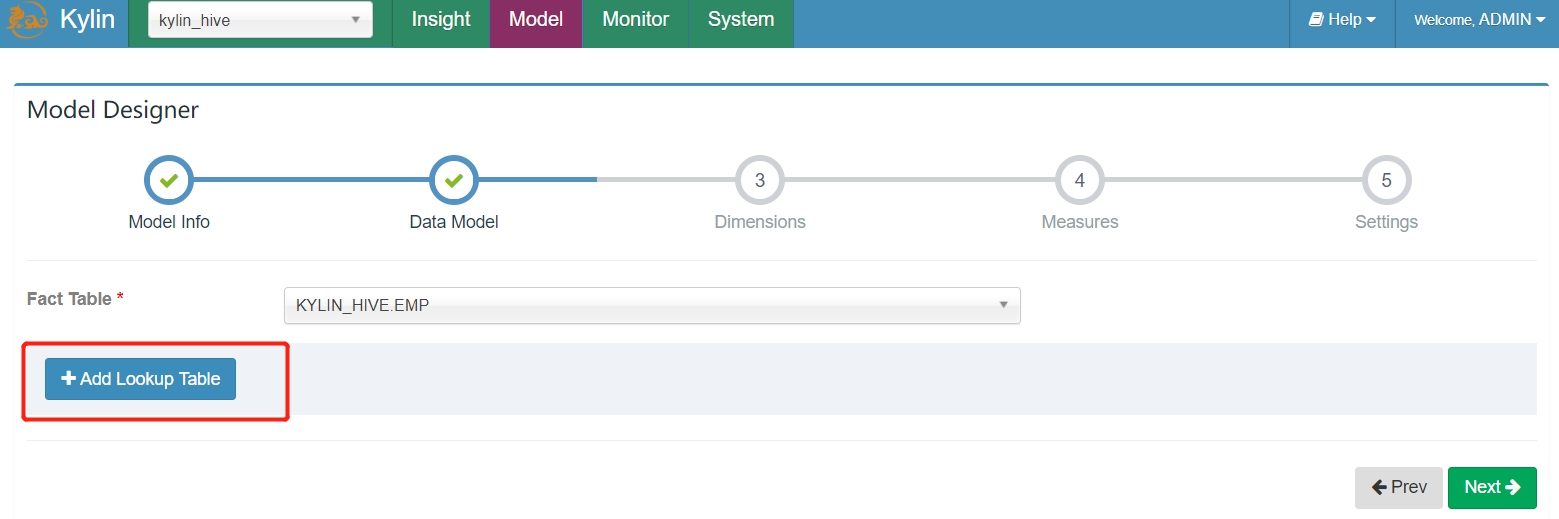
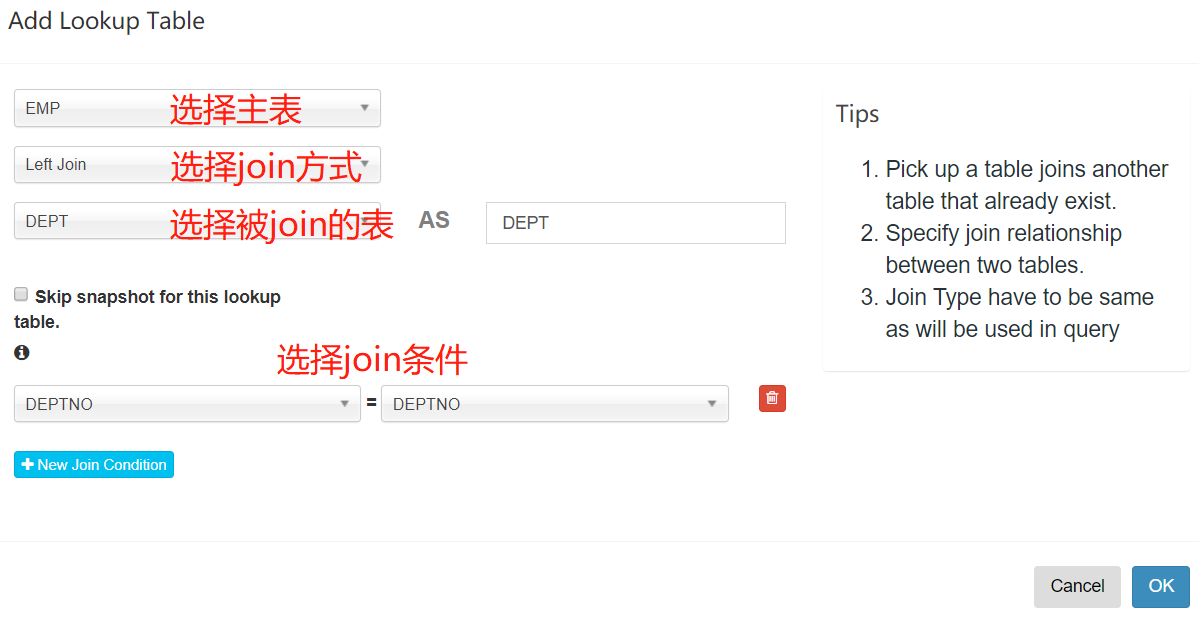
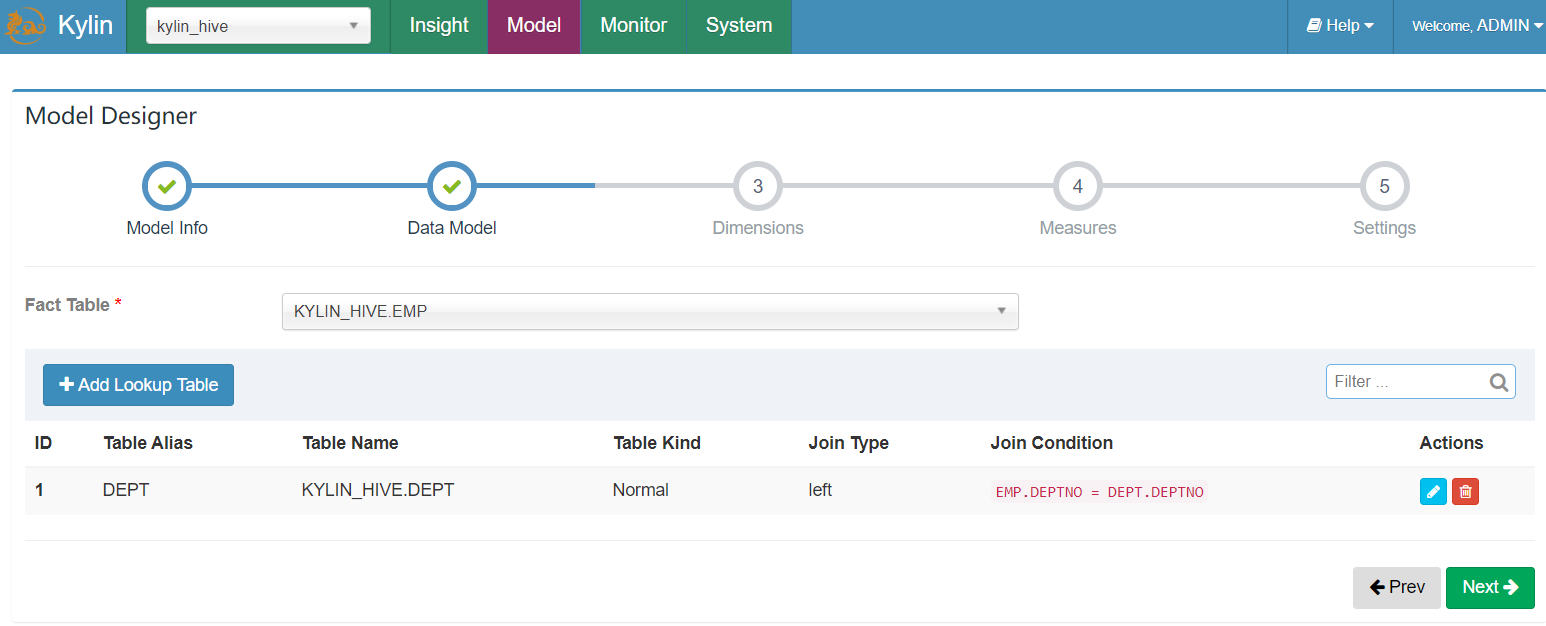
- 添加维度表,这里选择部门DEPT表为维度表,并选择我们的join方式,以及join连接字段
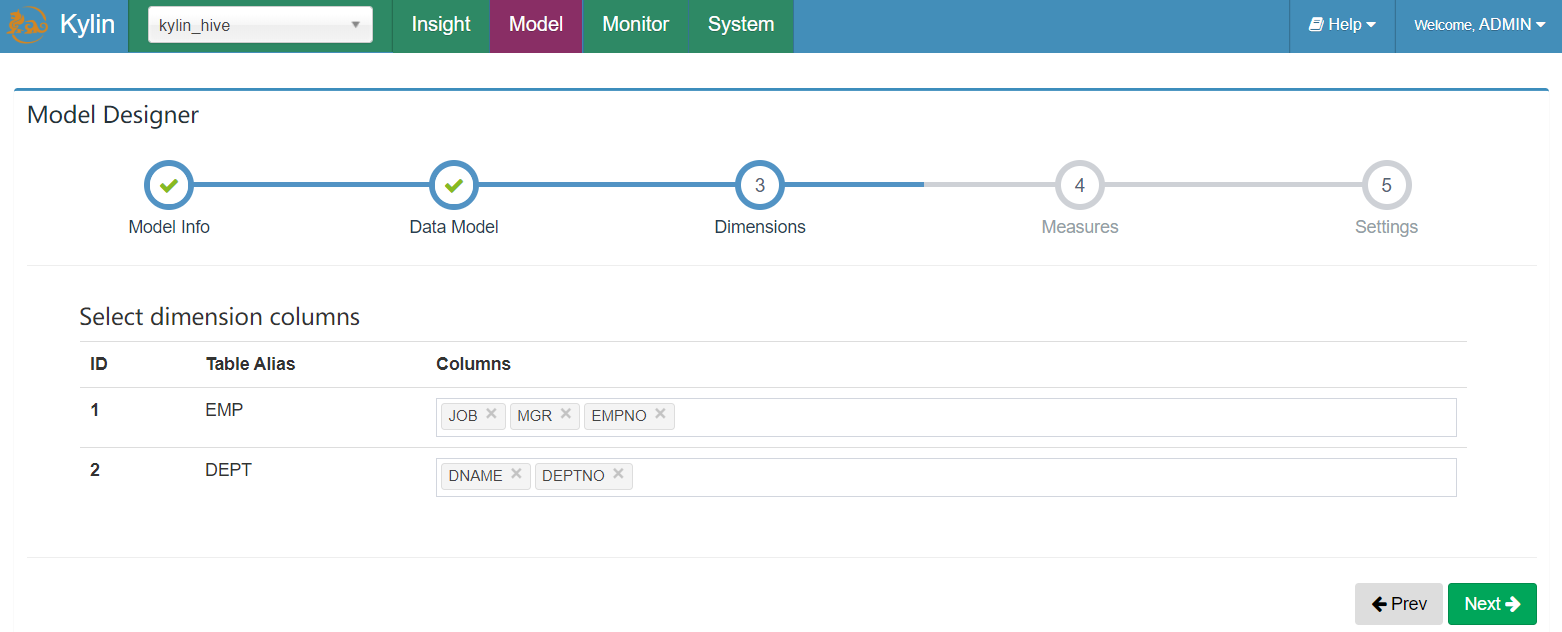
- 选择聚合维度信息
- 选择度量信息
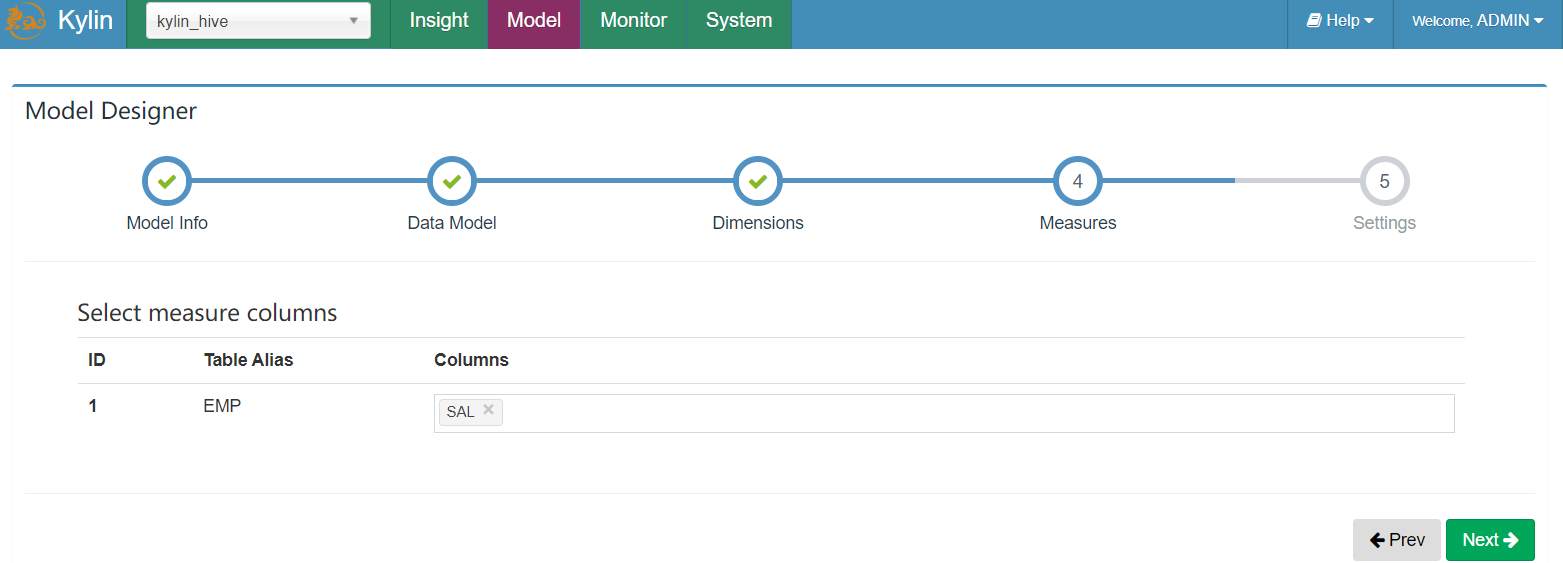
- 添加分区信息及过滤条件之后“Save”
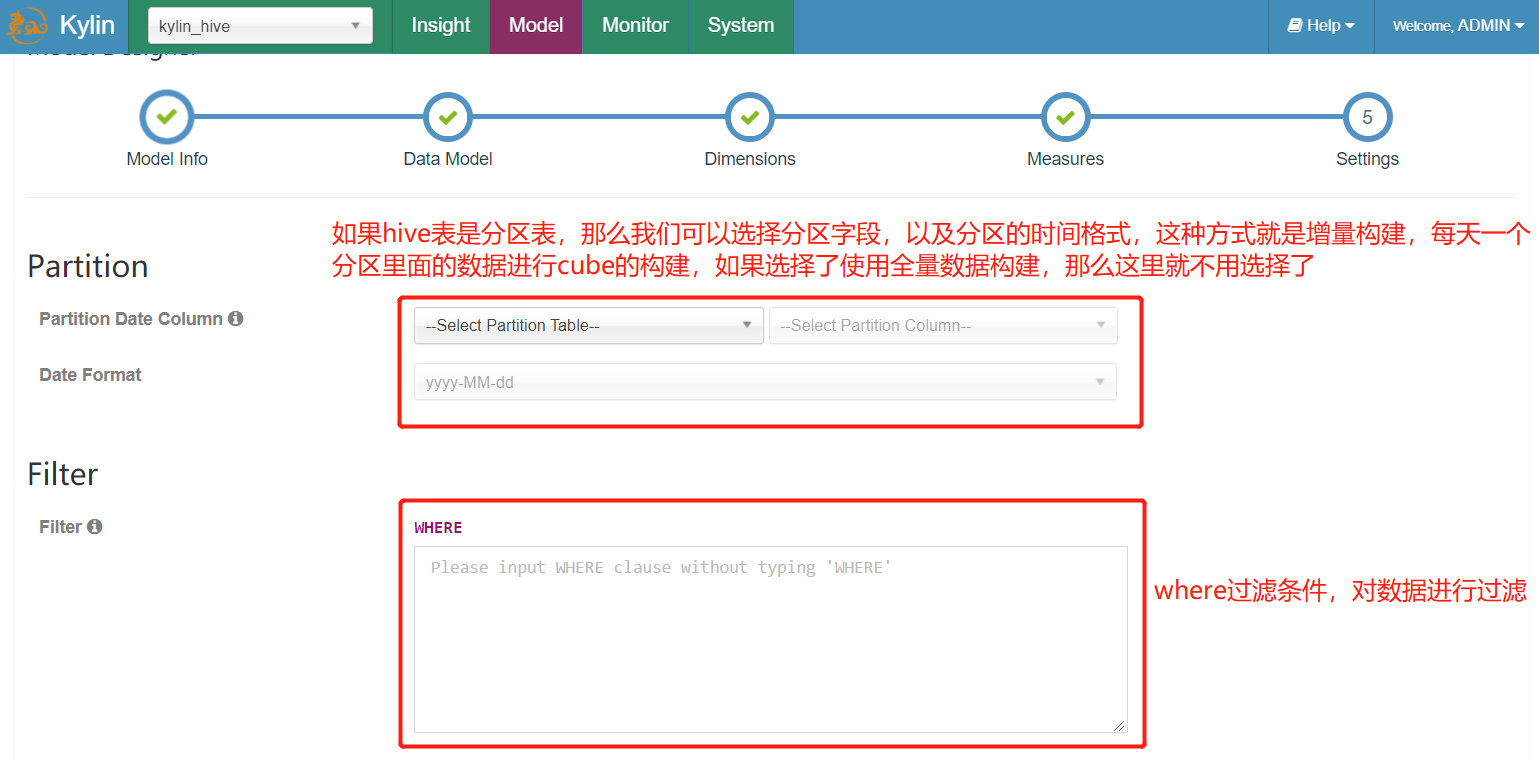
6.5 Kylin构建Cube
Kylin 的 OLAP Cube 是从星型模式的 Hive 表中获取的预计算数据集,这是供用户探索、管理所有 cube 的网页管理页面。由菜单栏进入Model 页面,系统中所有可用的 cube 将被列出。
- 创建一个new cube
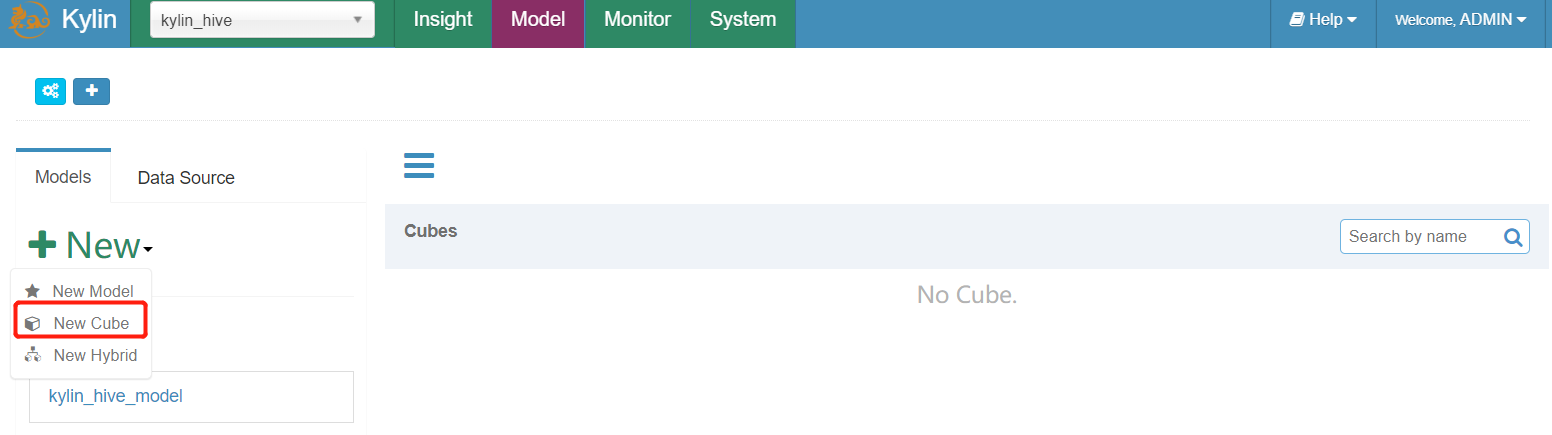
- 选择我们的model以及指定cube name

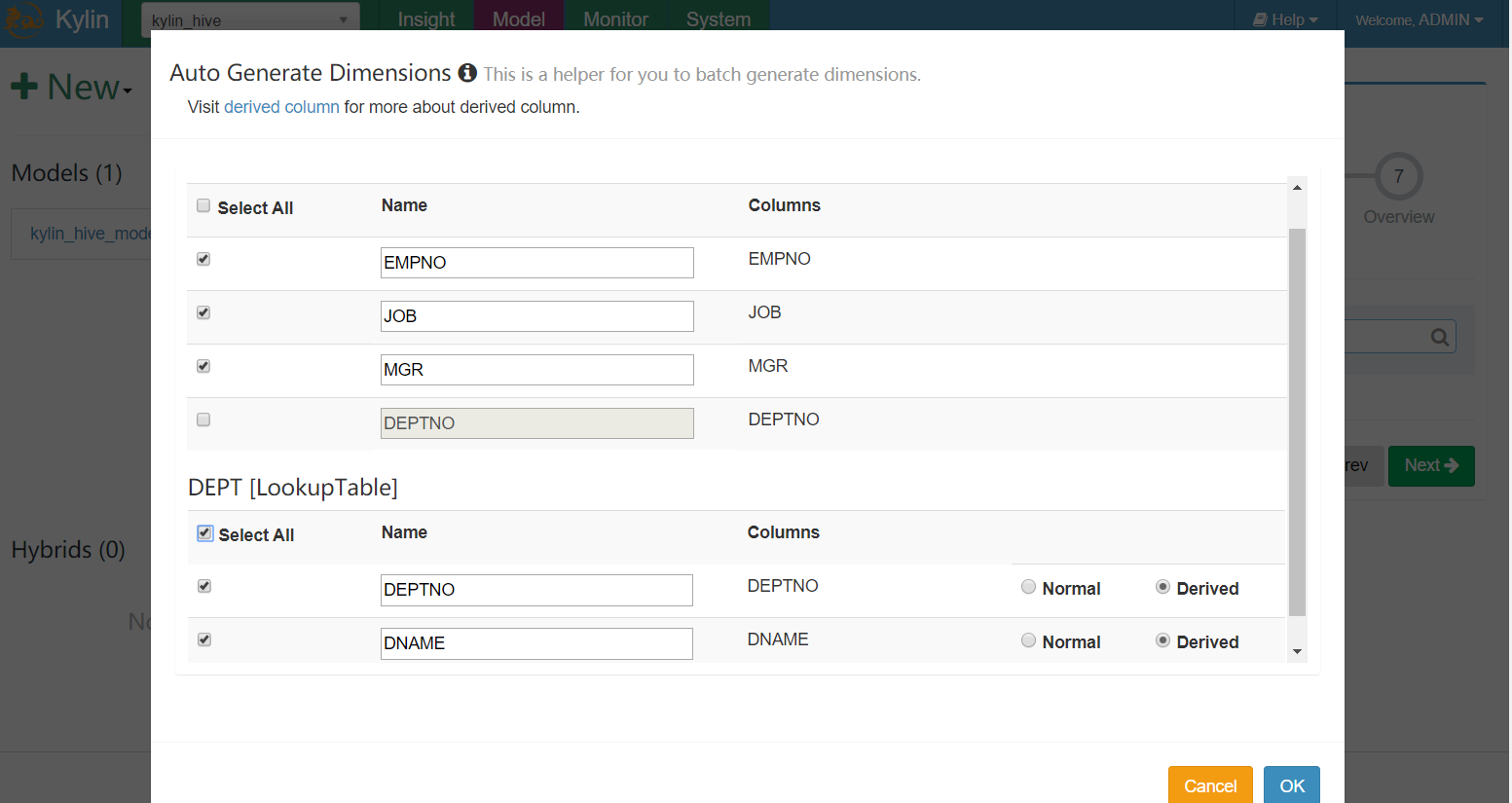
- 添加我们的自定义维度,这里是在创建Models模型时指定的事实表和维度表中取
- LookUpTable可选择normal或derived(一般列、衍生列)
- normal纬度作为普通独立的纬度,而derived 维度不会计算入cube,将由事实表的外键推算出
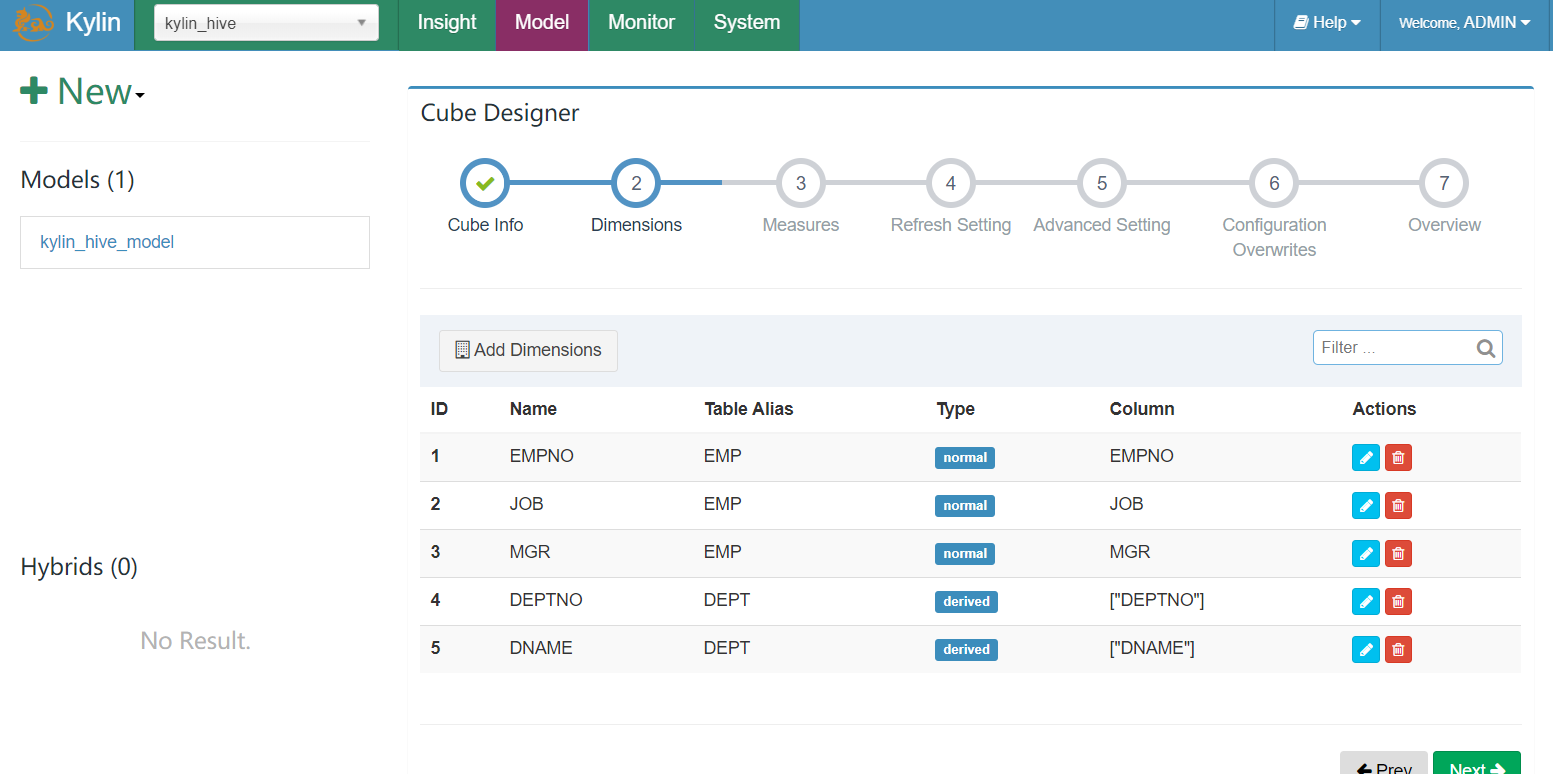
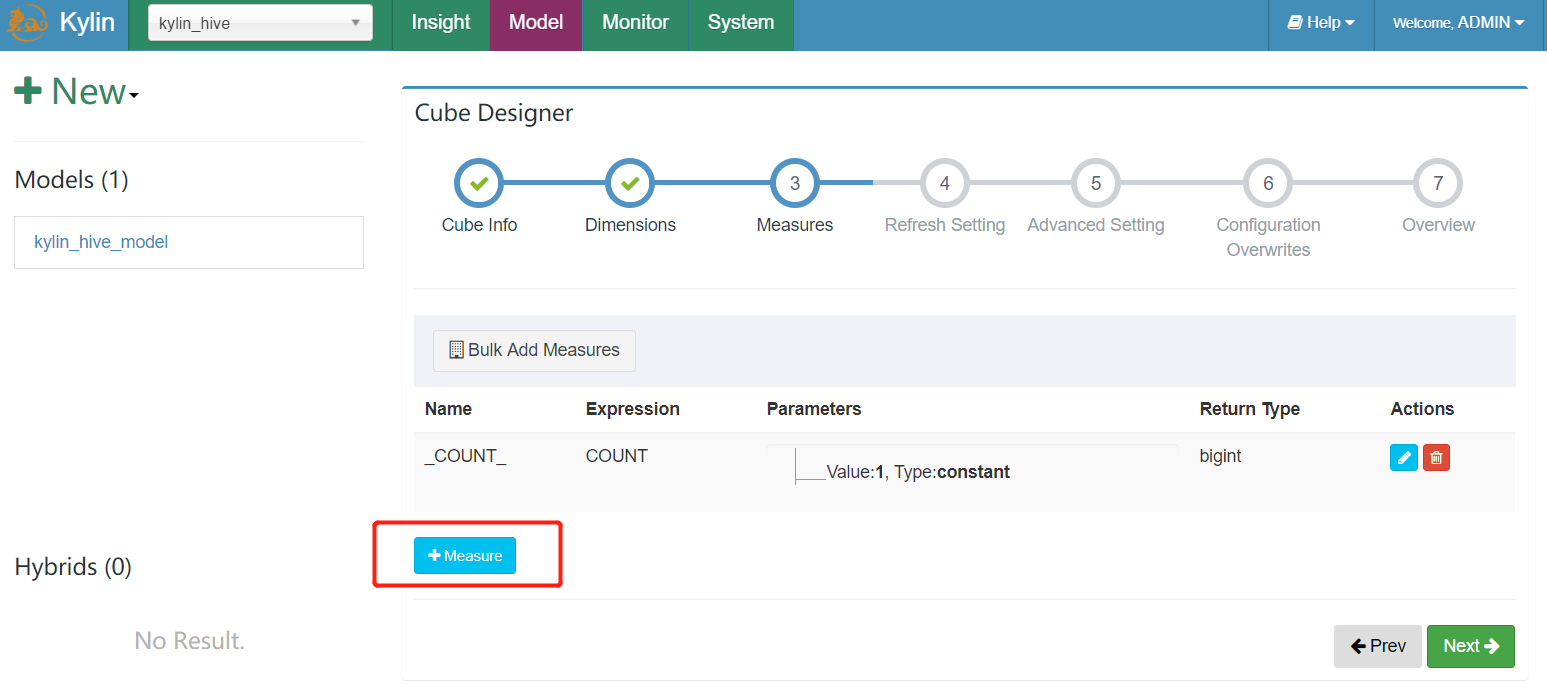
- 添加统计维度,勾选相应列作为度量,kylin提供8种度量:SUM、MAX、MIN、COUNT、COUNT_DISTINCT、TOP_N、EXTENDED_COLUMN、PERCENTILE
- DISTINCT_COUNT有两个实现:
- 近似实现 HyperLogLog,选择可接受的错误率,低错误率需要更多存储;
- 精确实现 bitmap
- TopN 度量在每个维度结合时预计算,需要两个参数:
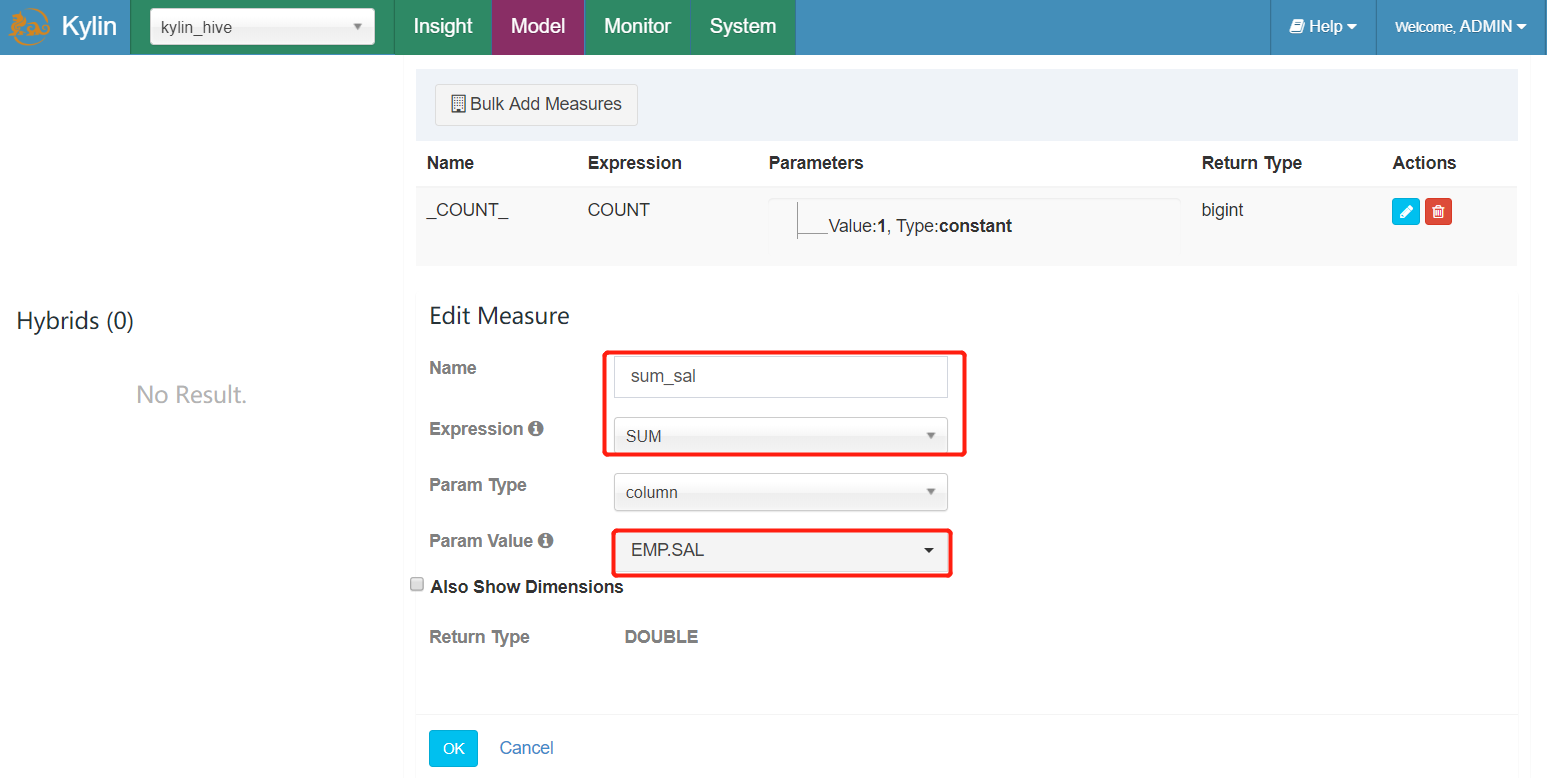
- 一是被用来作为 Top 记录的度量列,Kylin 将计算它的 SUM 值并做倒序排列,如sum(price)
- 二是 literal ID,代表最 Top 的记录,如seller_id
- EXTENDED_COLUMN
- Extended_Column 作为度量比作为维度更节省空间。一列和零一列可以生成新的列
- PERCENTILE
- Percentile 代表了百分比。值越大,错误就越少。100为最合适的值
- DISTINCT_COUNT有两个实现:
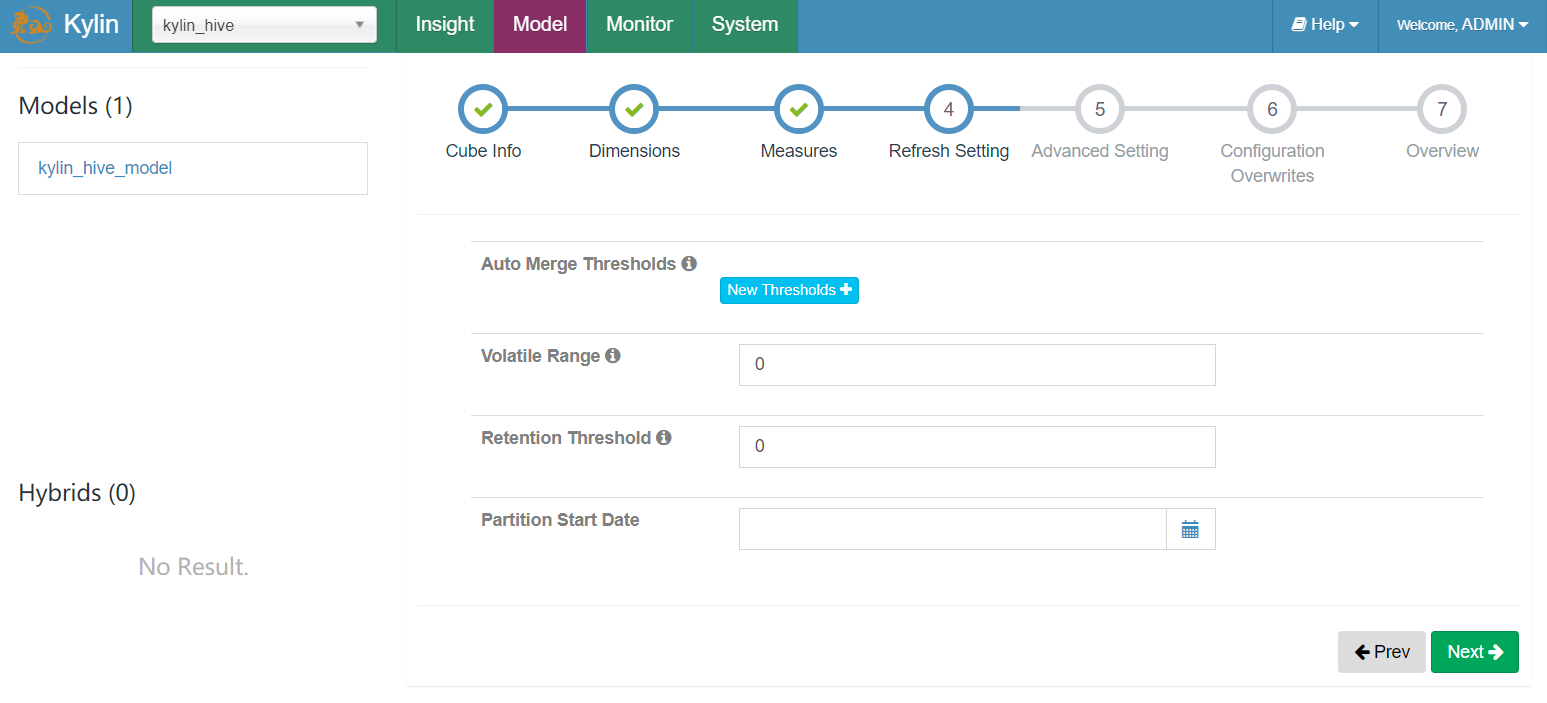
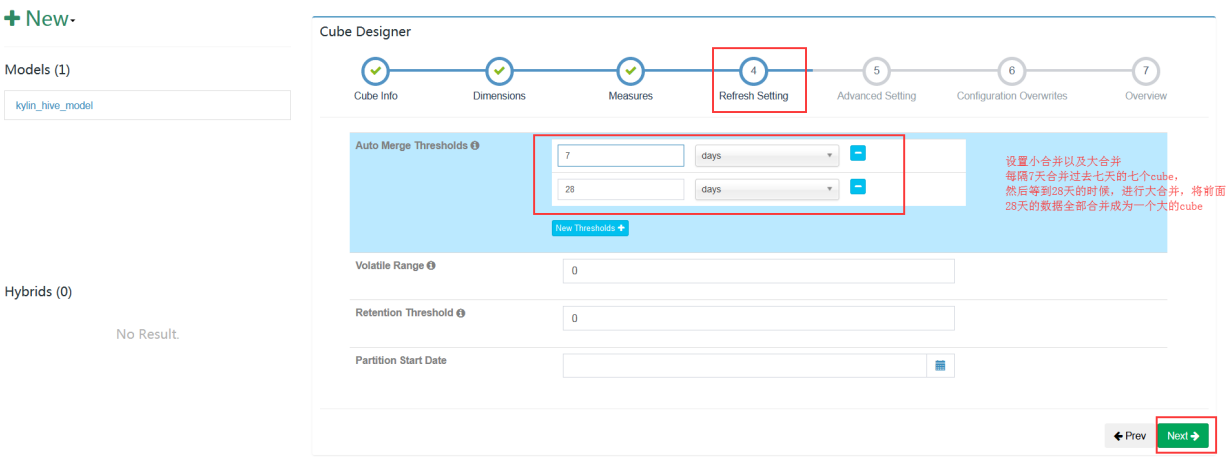
- 设置多个分区cube合并信息
如果是分区统计,需要关于历史cube的合并,
这里是全量统计,不涉及多个分区cube进行合并,所以不用设置历史多个cube进行合并
Auto Merge Thresholds:
- 自动合并小的 segments 到中等甚至更大的 segment。如果不想自动合并,删除默认2个选项
Volatile Range:
- 默认为0,会自动合并所有可能的cube segments,或者用 ‘Auto Merge’ 将不会合并最新的 [Volatile Range] 天的 cube segments
Retention Threshold:
- 默认为0,只会保存 cube 过去几天的 segment,旧的 segment 将会自动从头部删除
Partition Start Date:
- cube 的开始日期
- 高级设置
暂时也不做任何设
置高级设定关系到立方体是否足够优化,可根据实际情况将维度列定义为强制维度、层级维度、联合维度
- Mandatory维度指的是总会存在于group by或where中的维度
- Hierarchy是一组有层级关系的维度,如国家、省份、城市
- Joint是将多个维度组合成一个维度
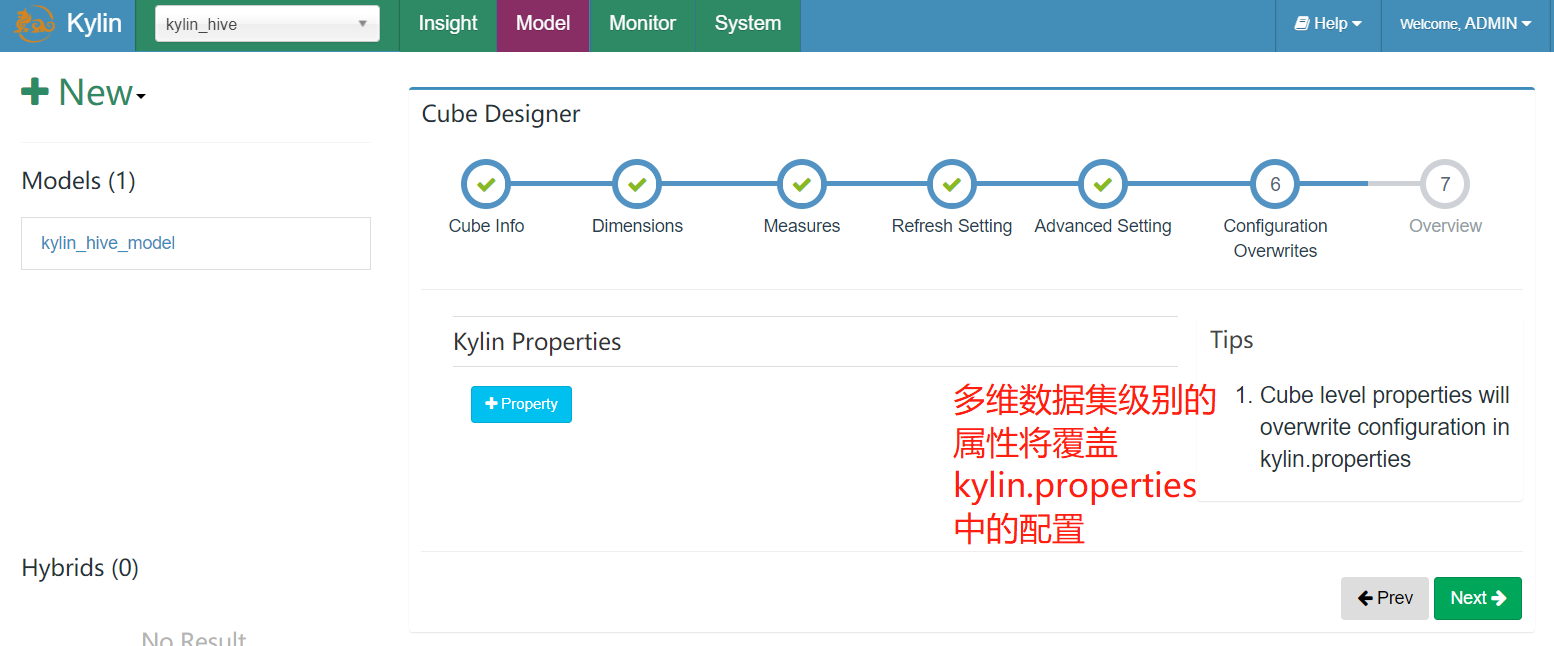
- 额外的其他的配置属性
这里也暂时不做配置
Kylin 允许在 Cube 级别覆盖部分 kylin.properties 中的配置
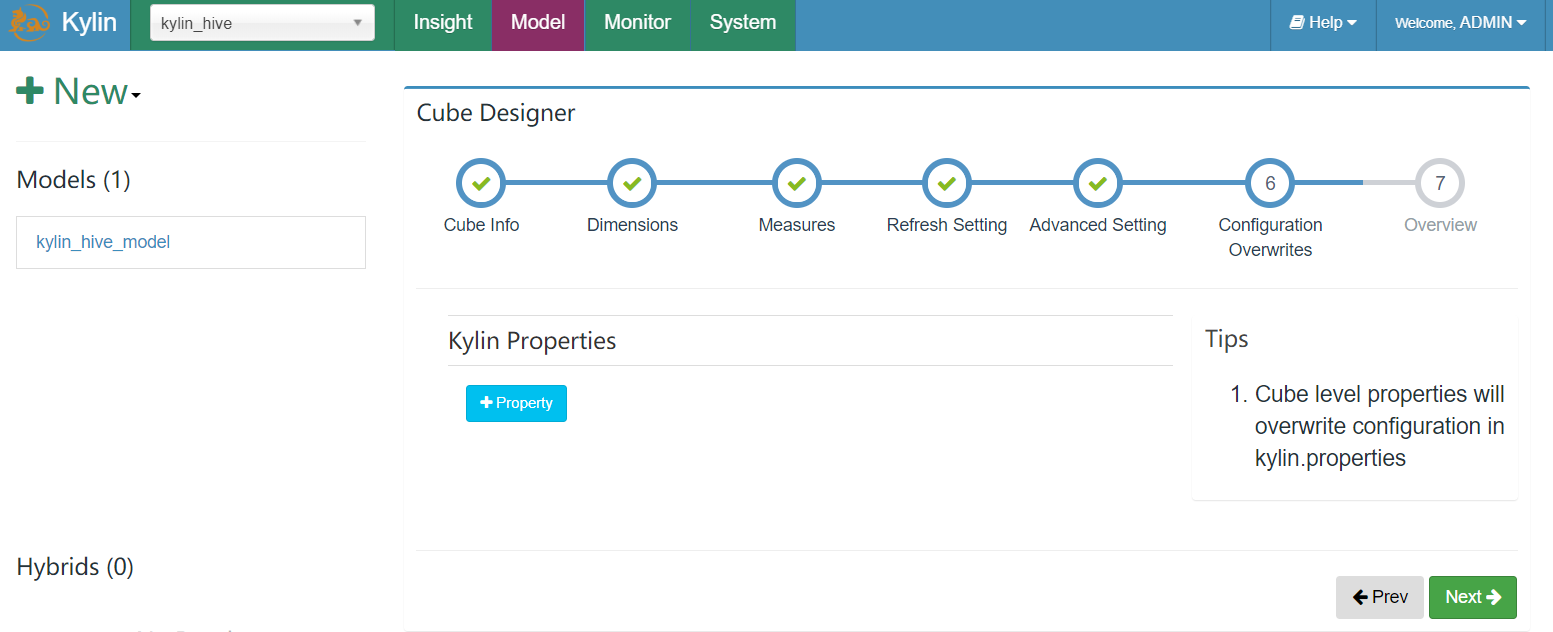
- 完成保存配置
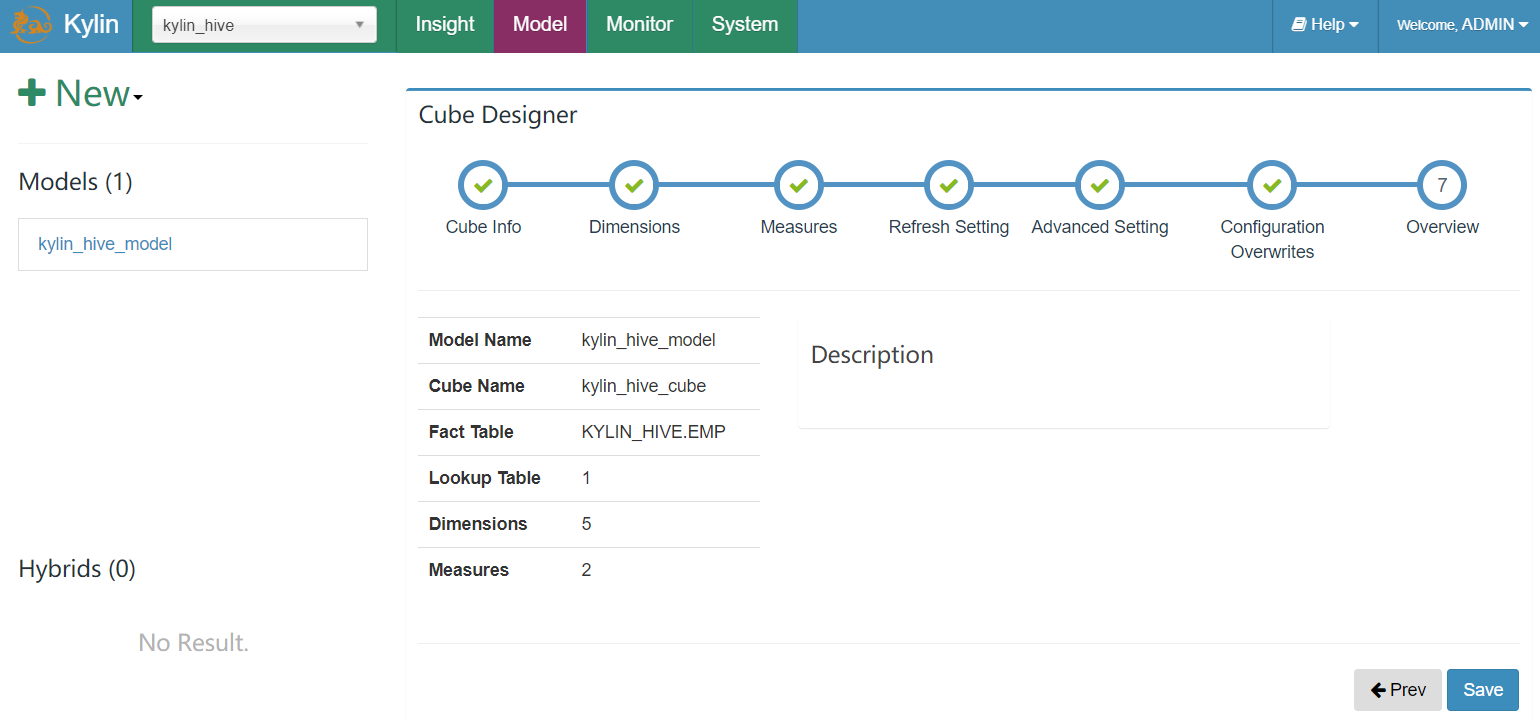
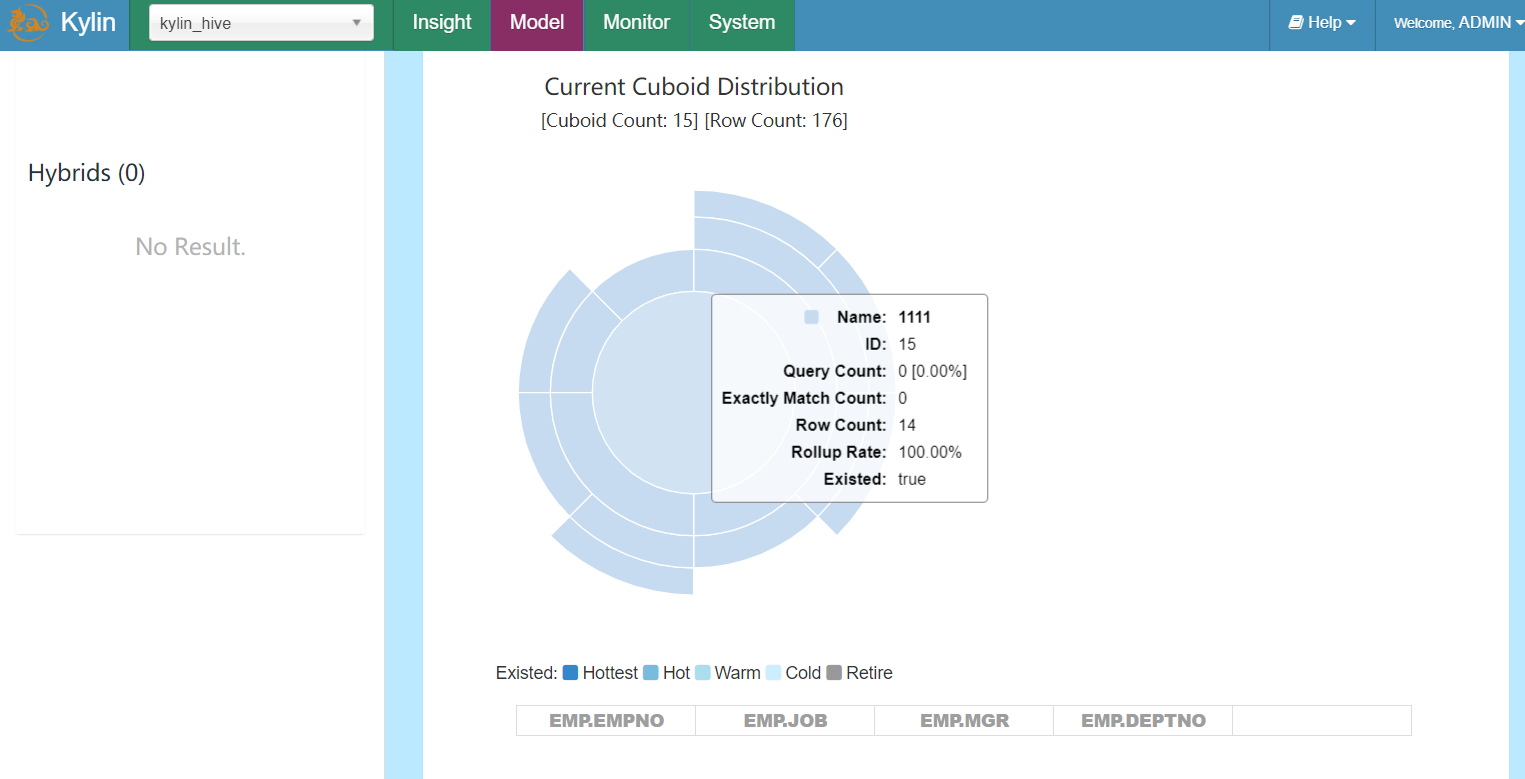
通过Planner计划者,可以看到4个维度,得到Cuboid Conut=15,为2的4次方-1,因为全部没有的指标不会使用,所以结果等于15。
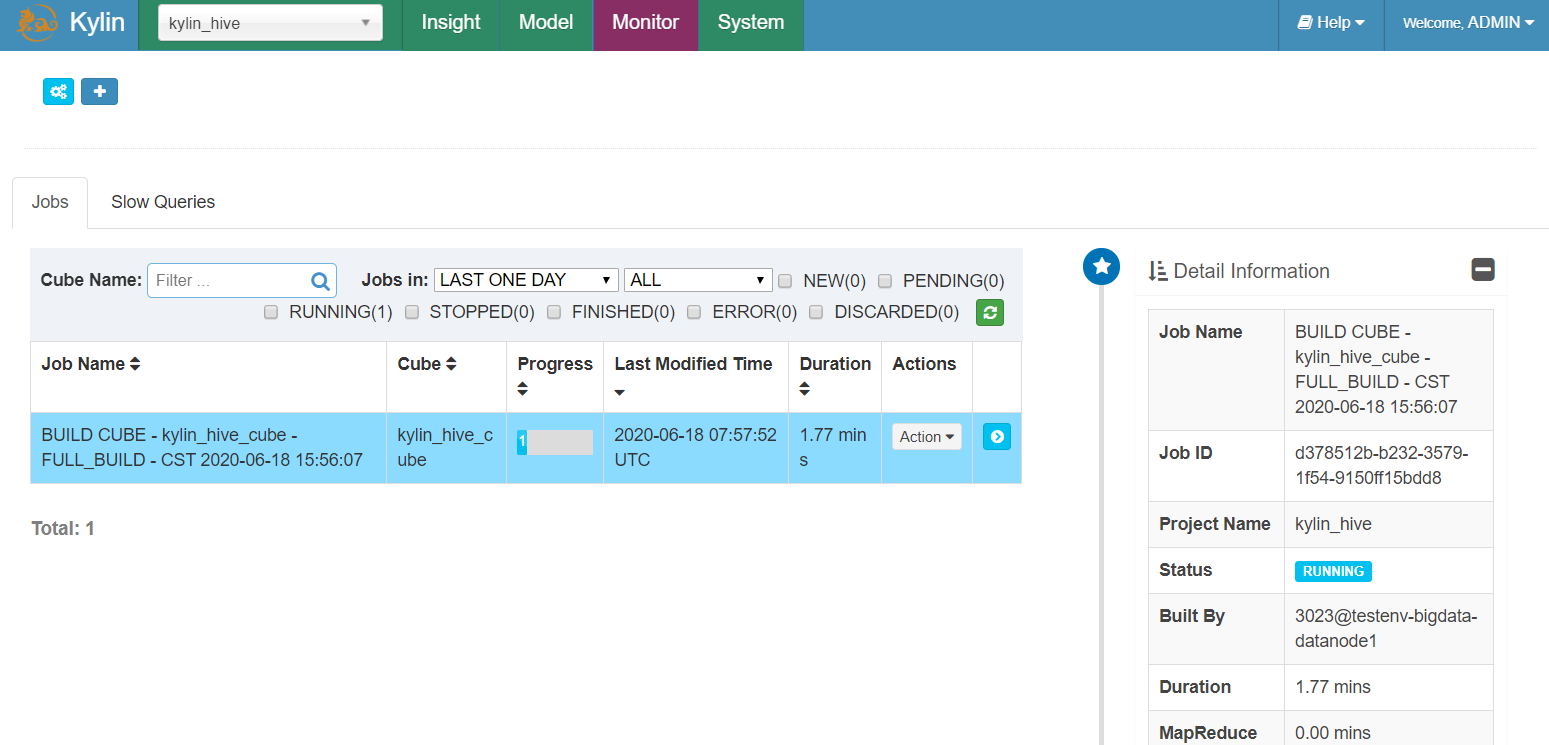
- 构建Cube
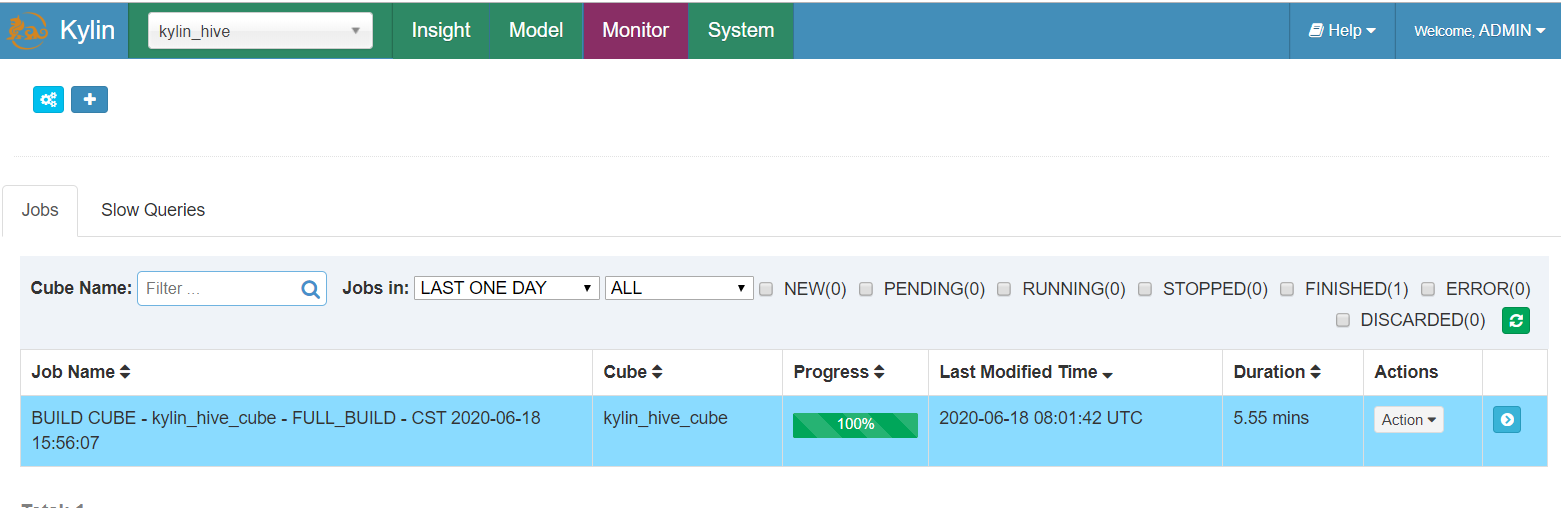
6.6 数据查询
- 根据部门查询,部门工资总和
SELECT DEPT.DNAME,SUM(EMP.SAL)
FROM EMP
LEFT JOIN DEPT
ON DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DEPT.DNAME
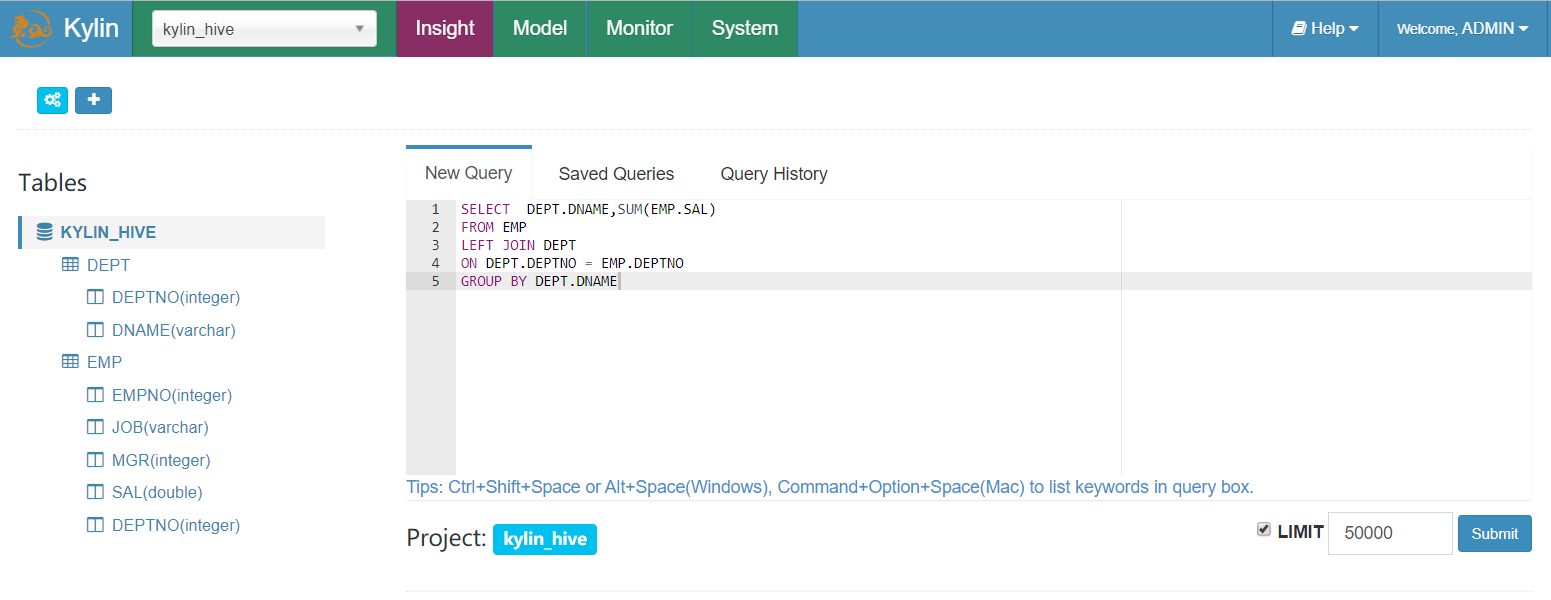
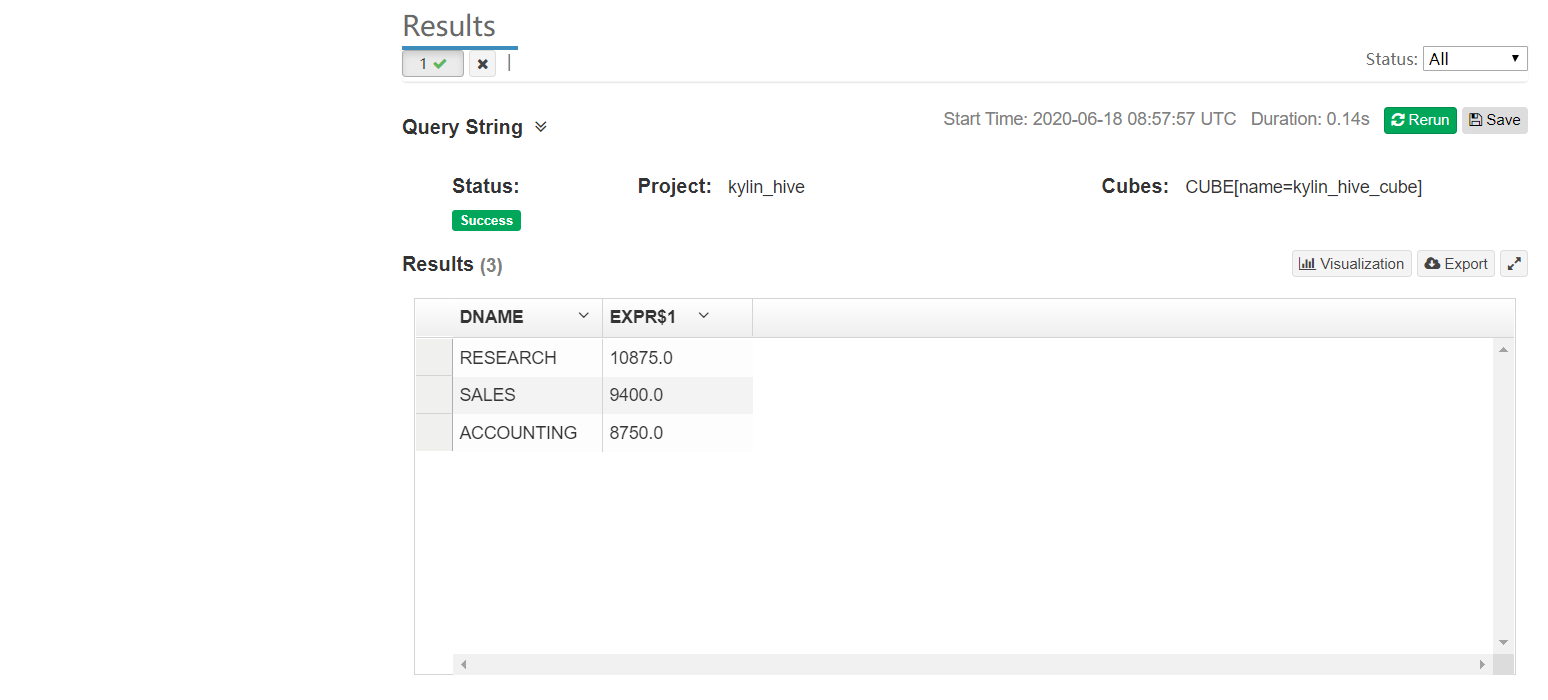
7 入门案例构建流程
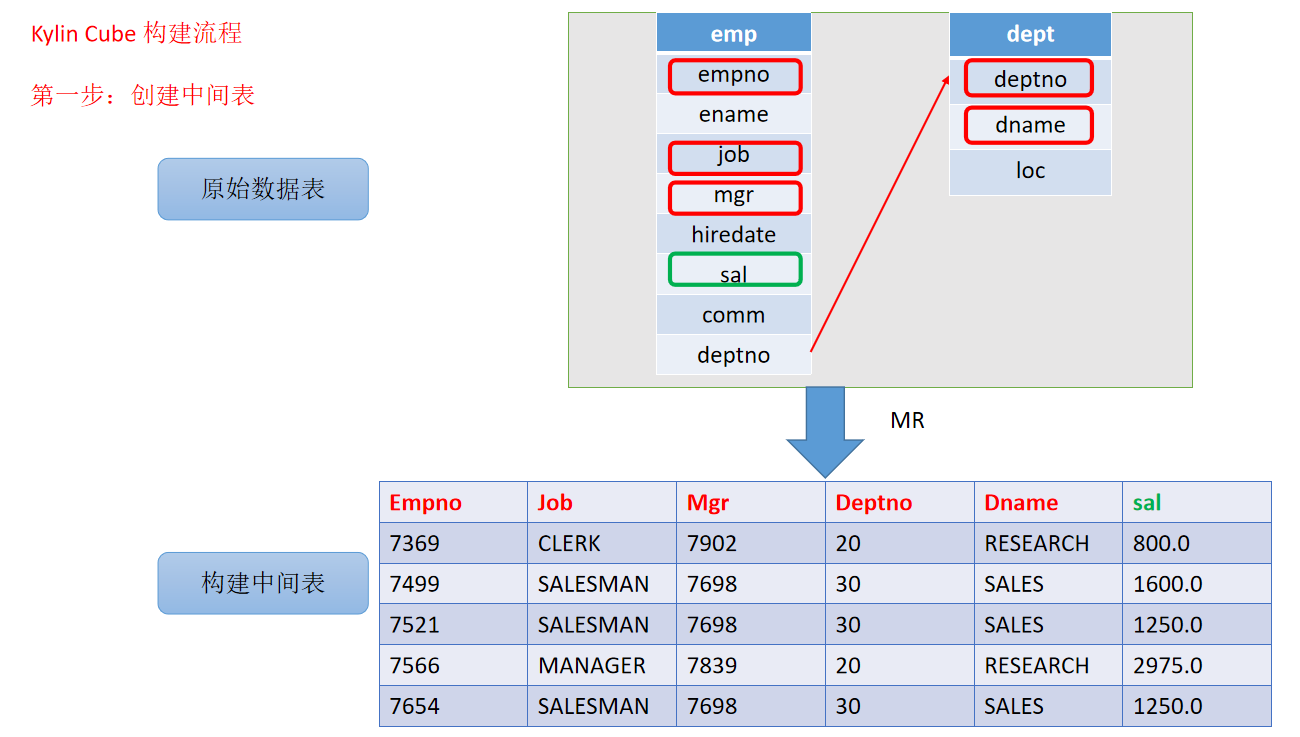
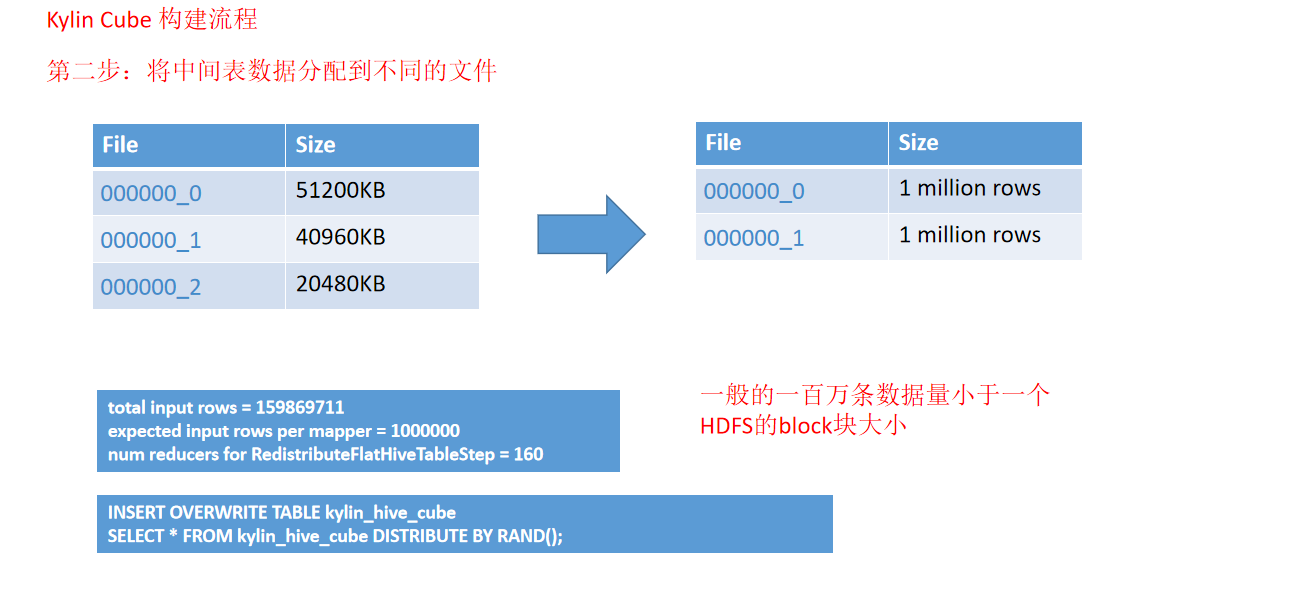

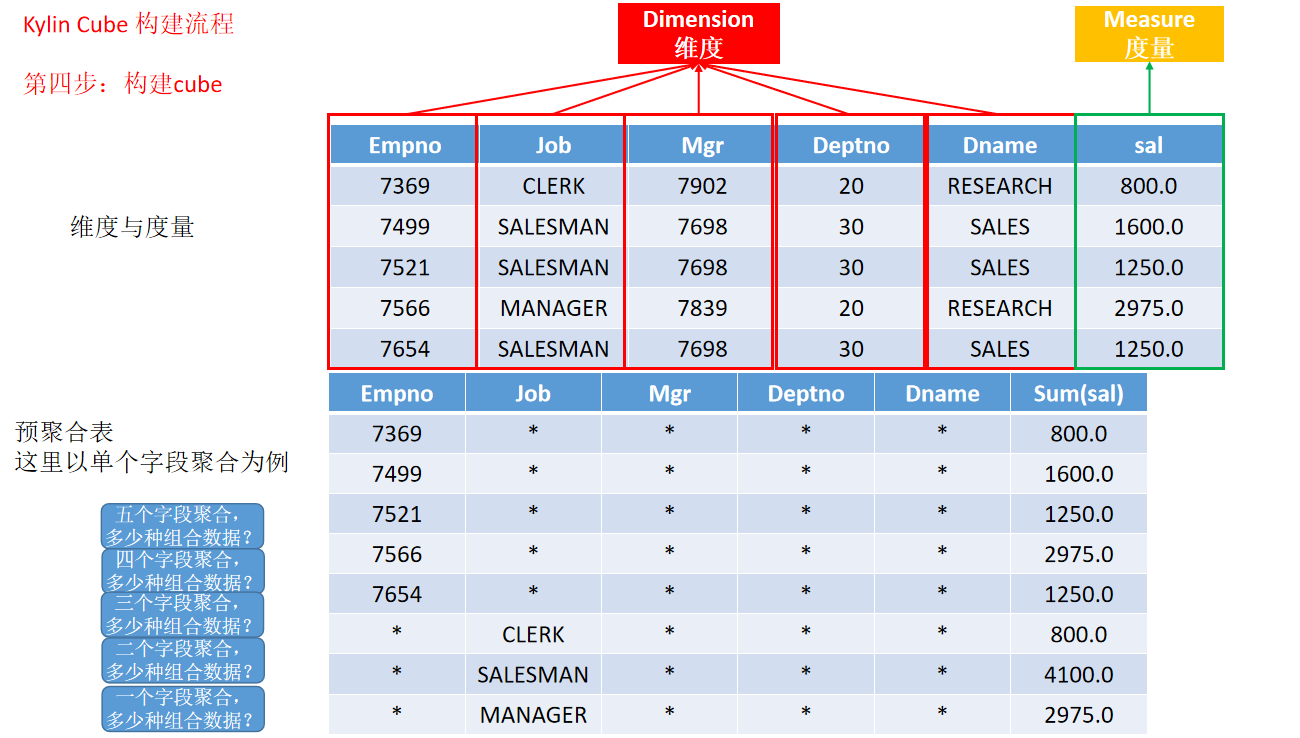
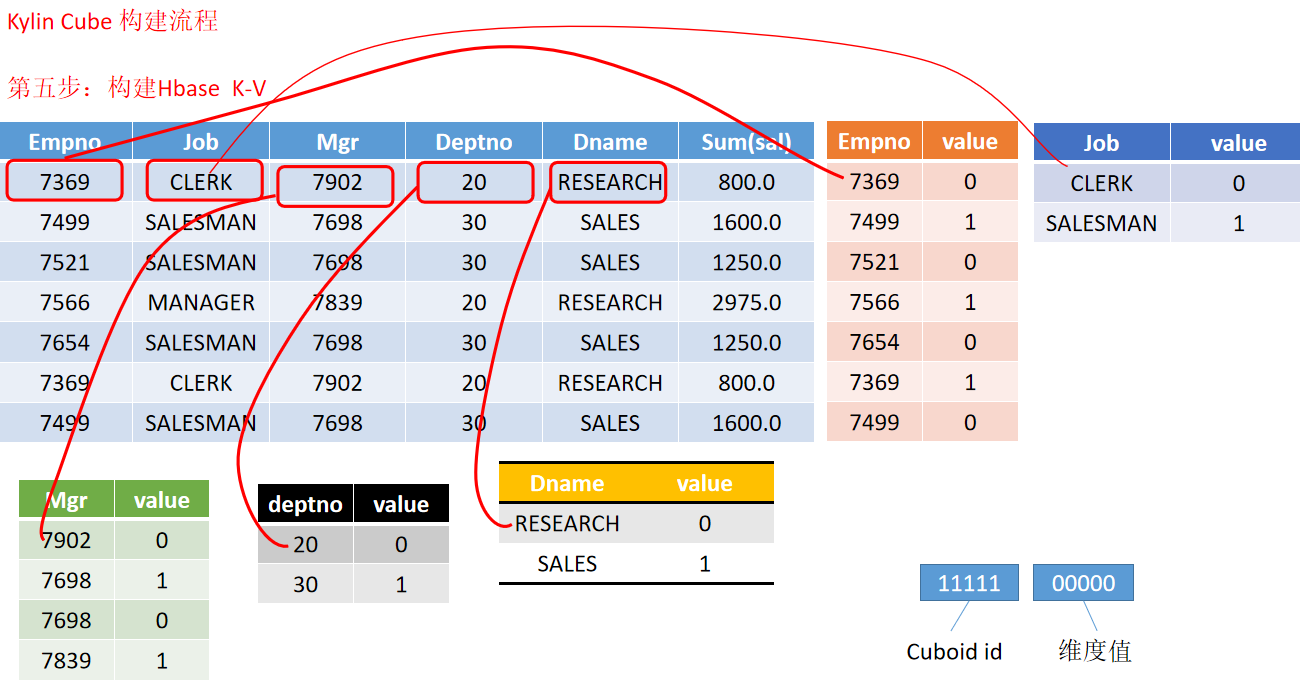
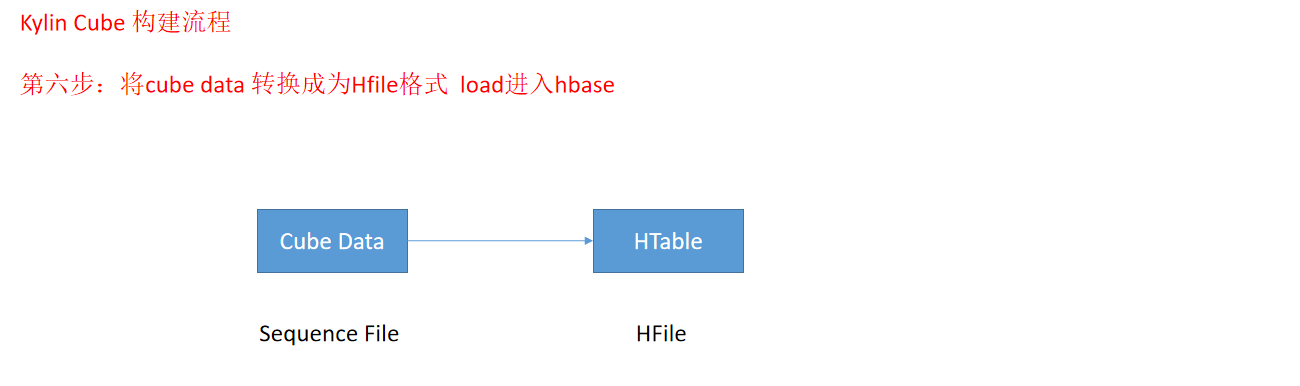
- 动画演示


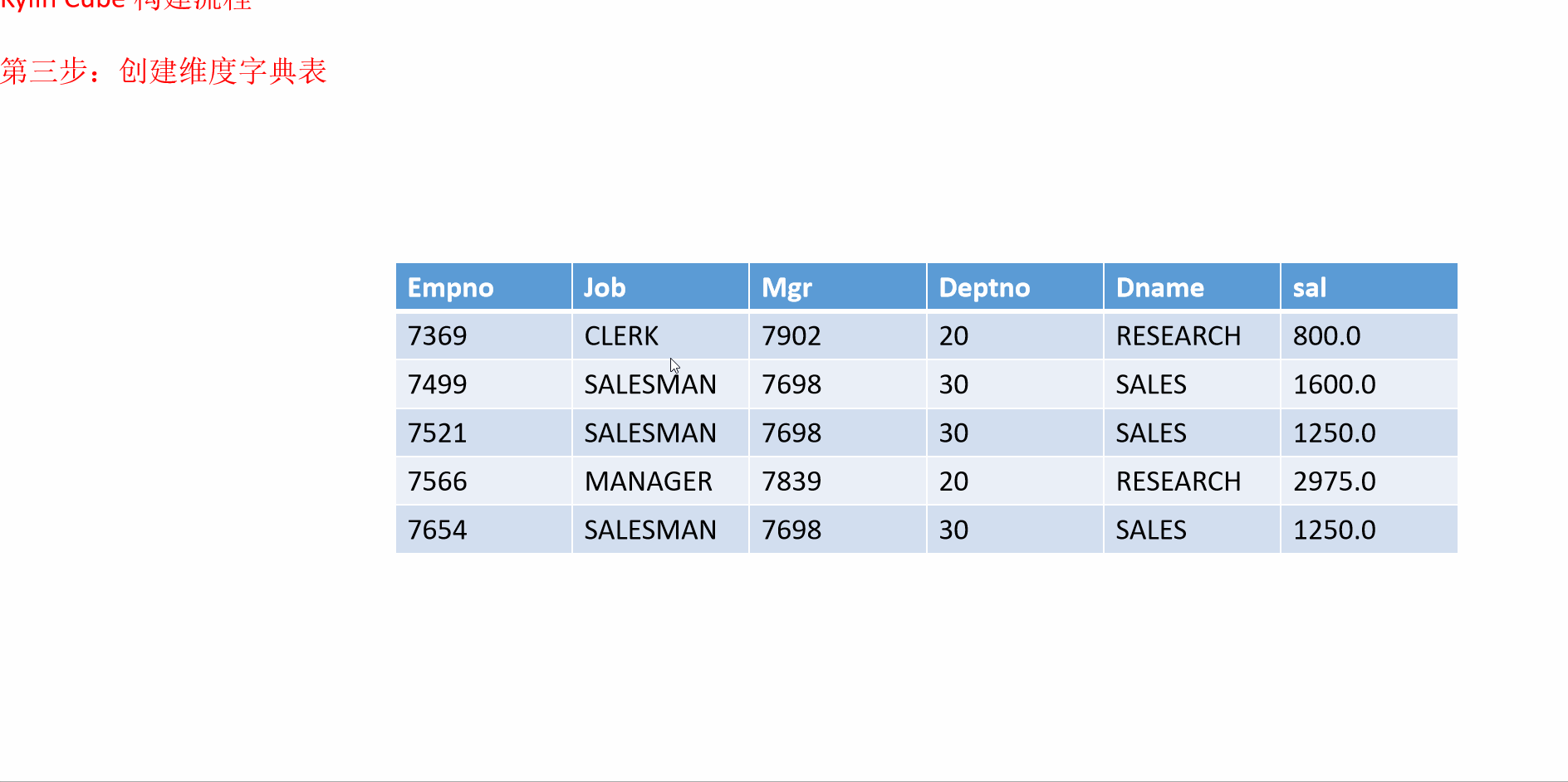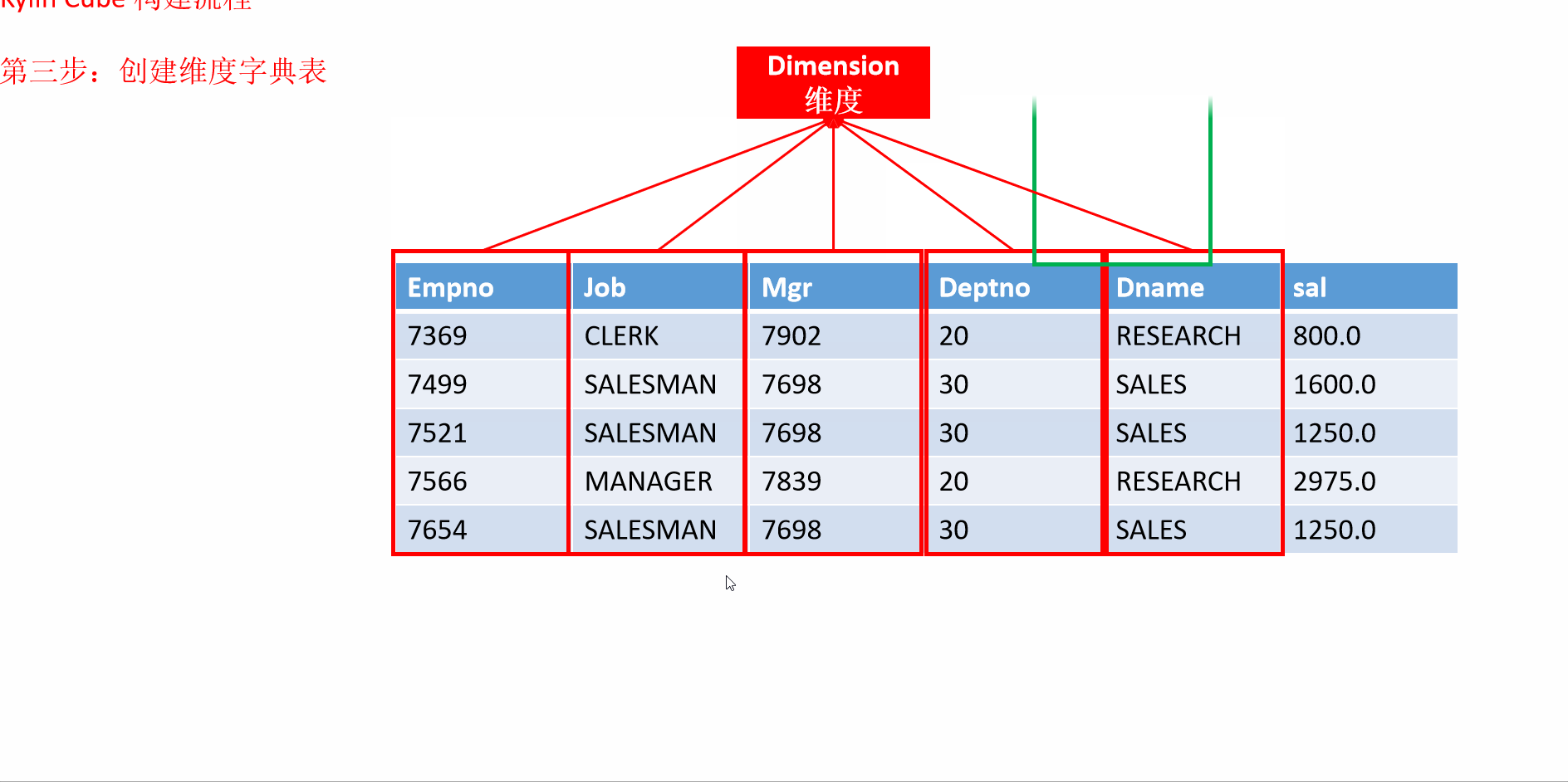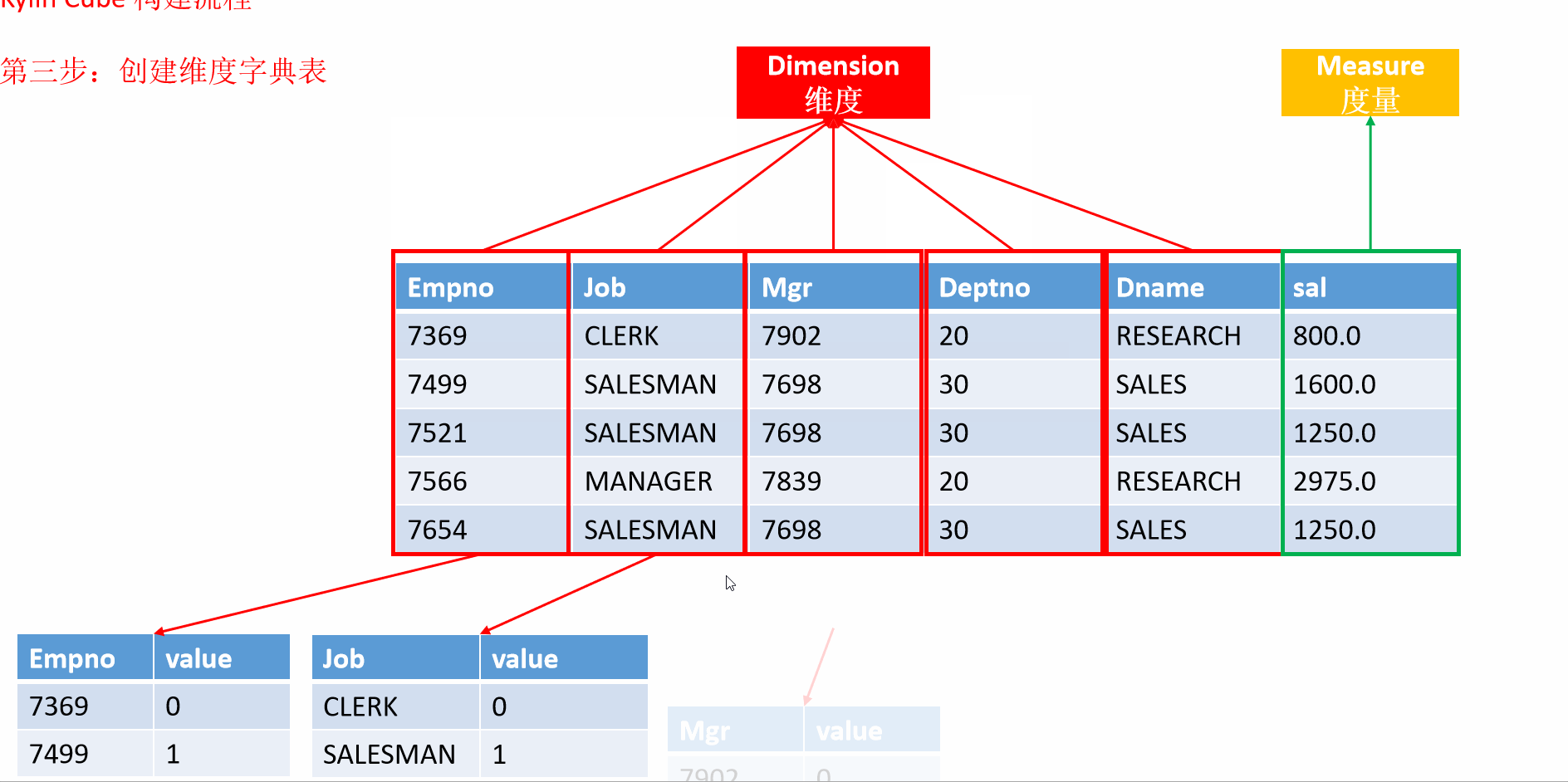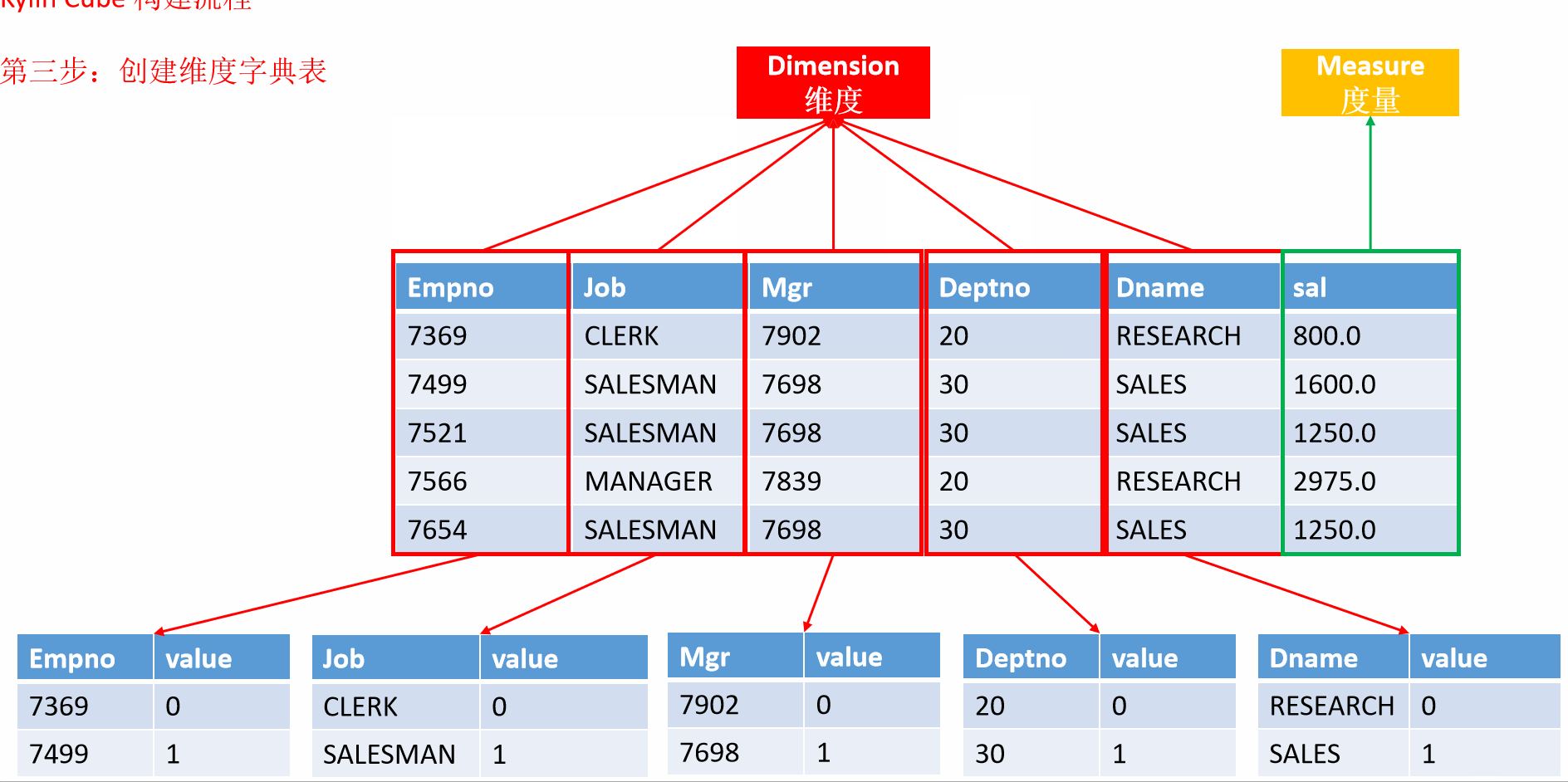
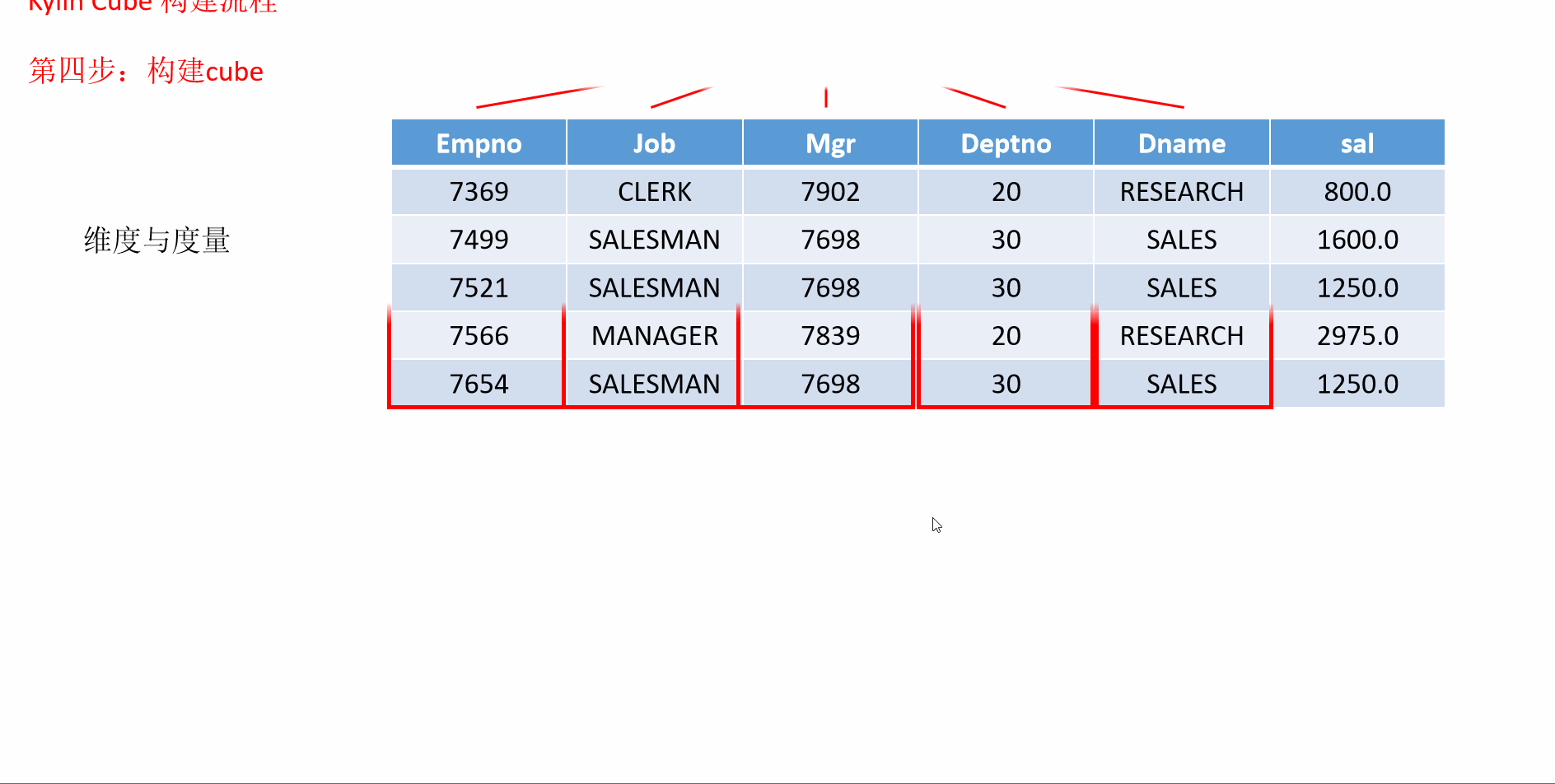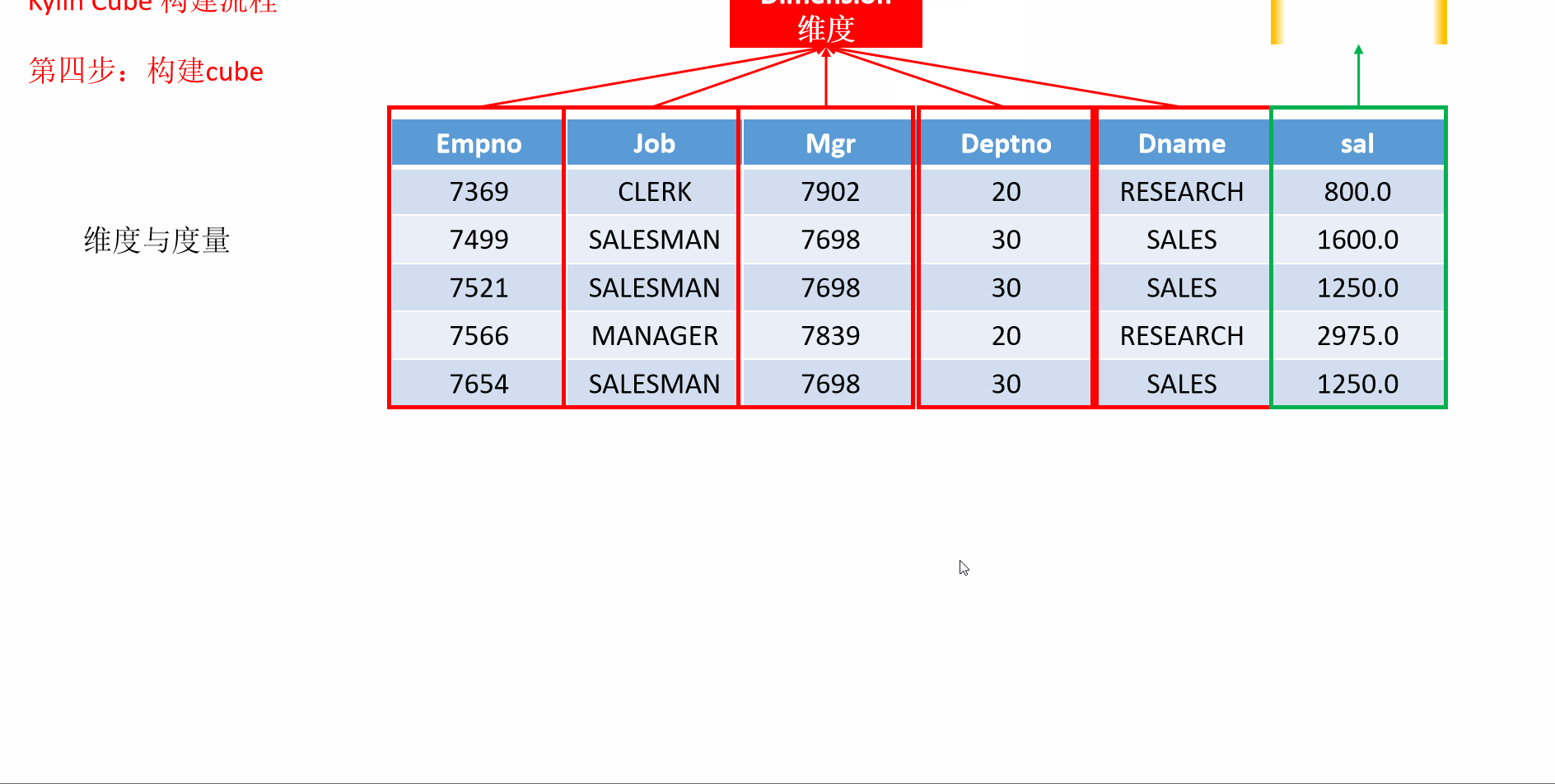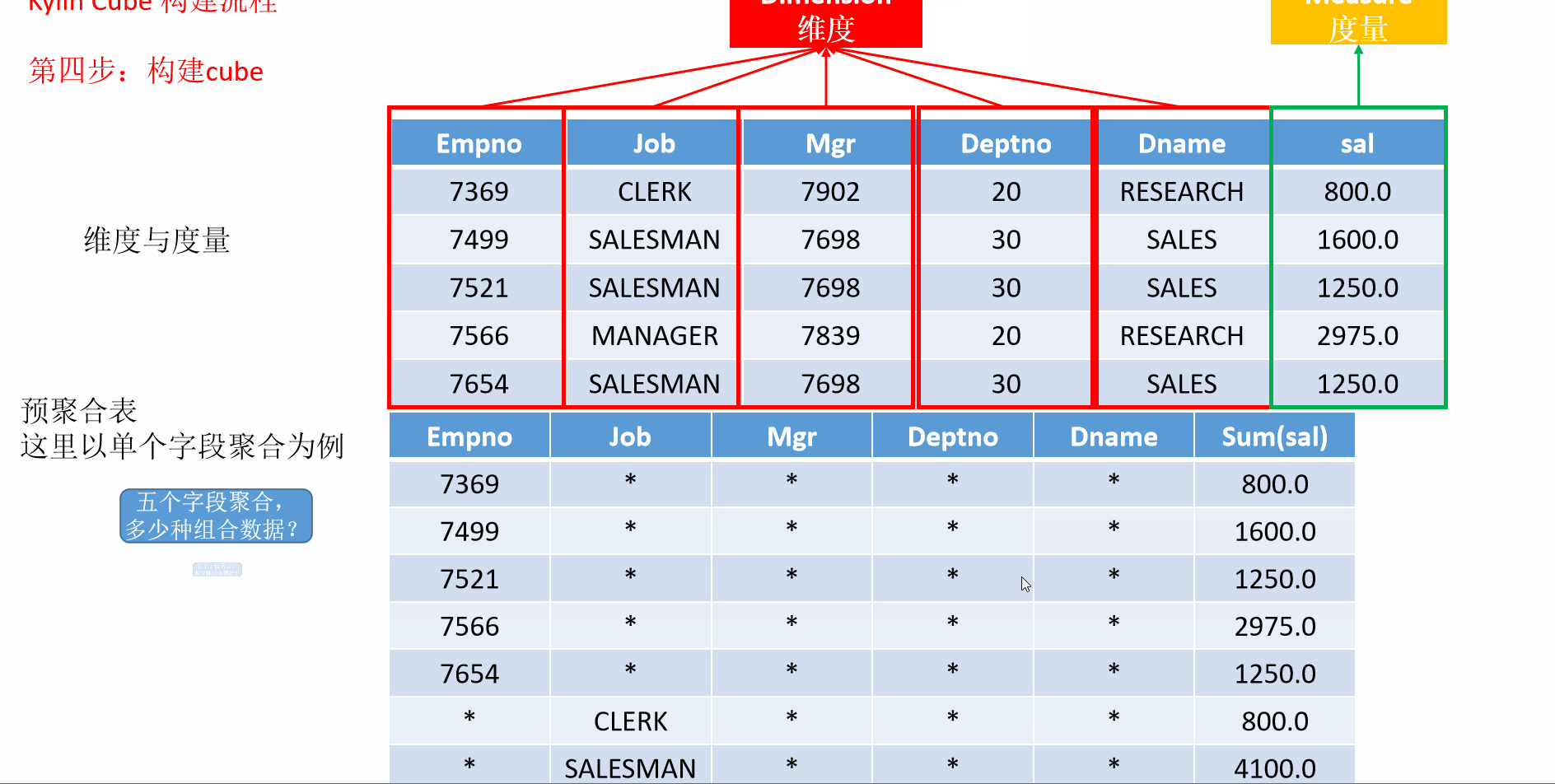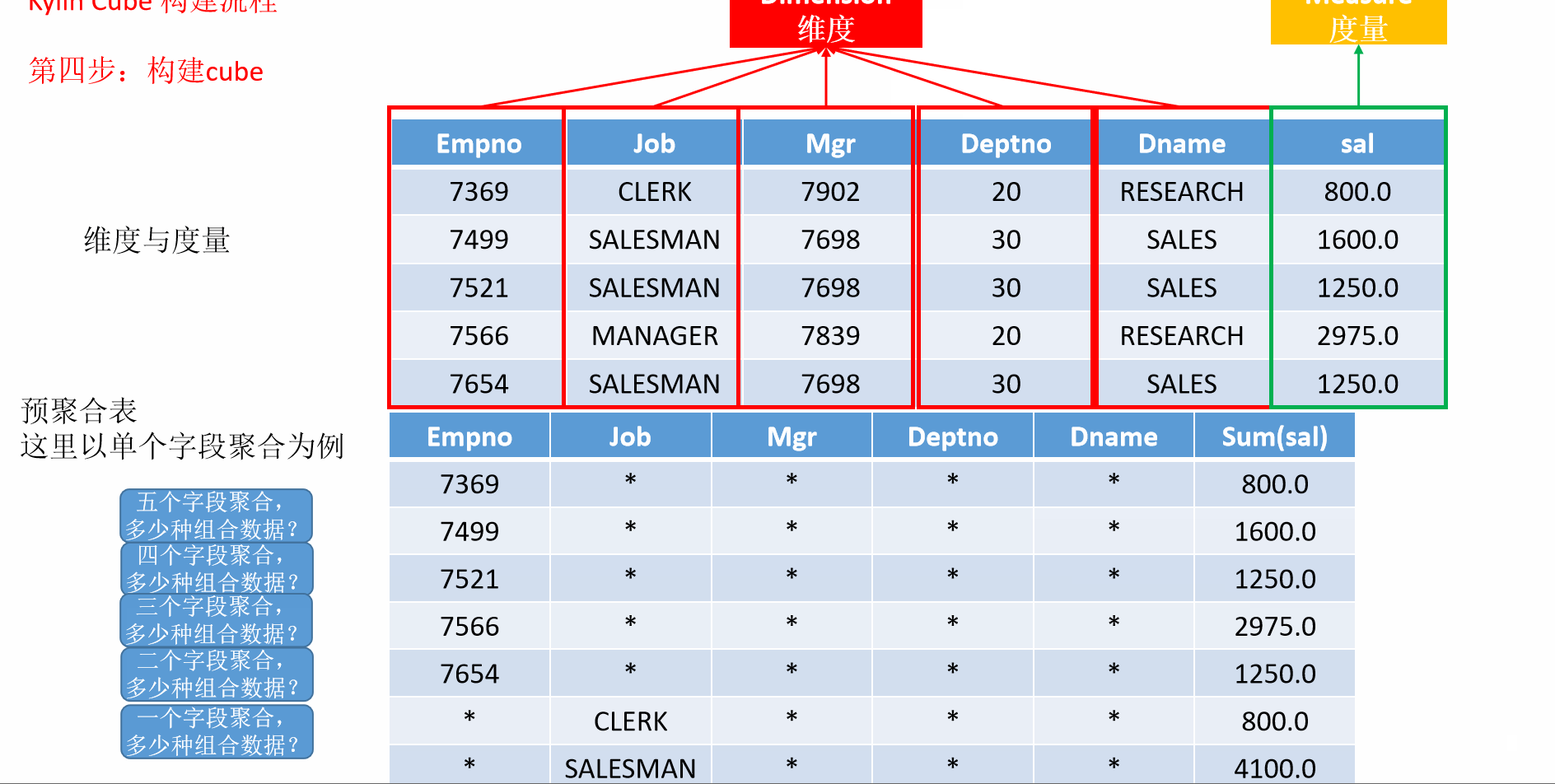
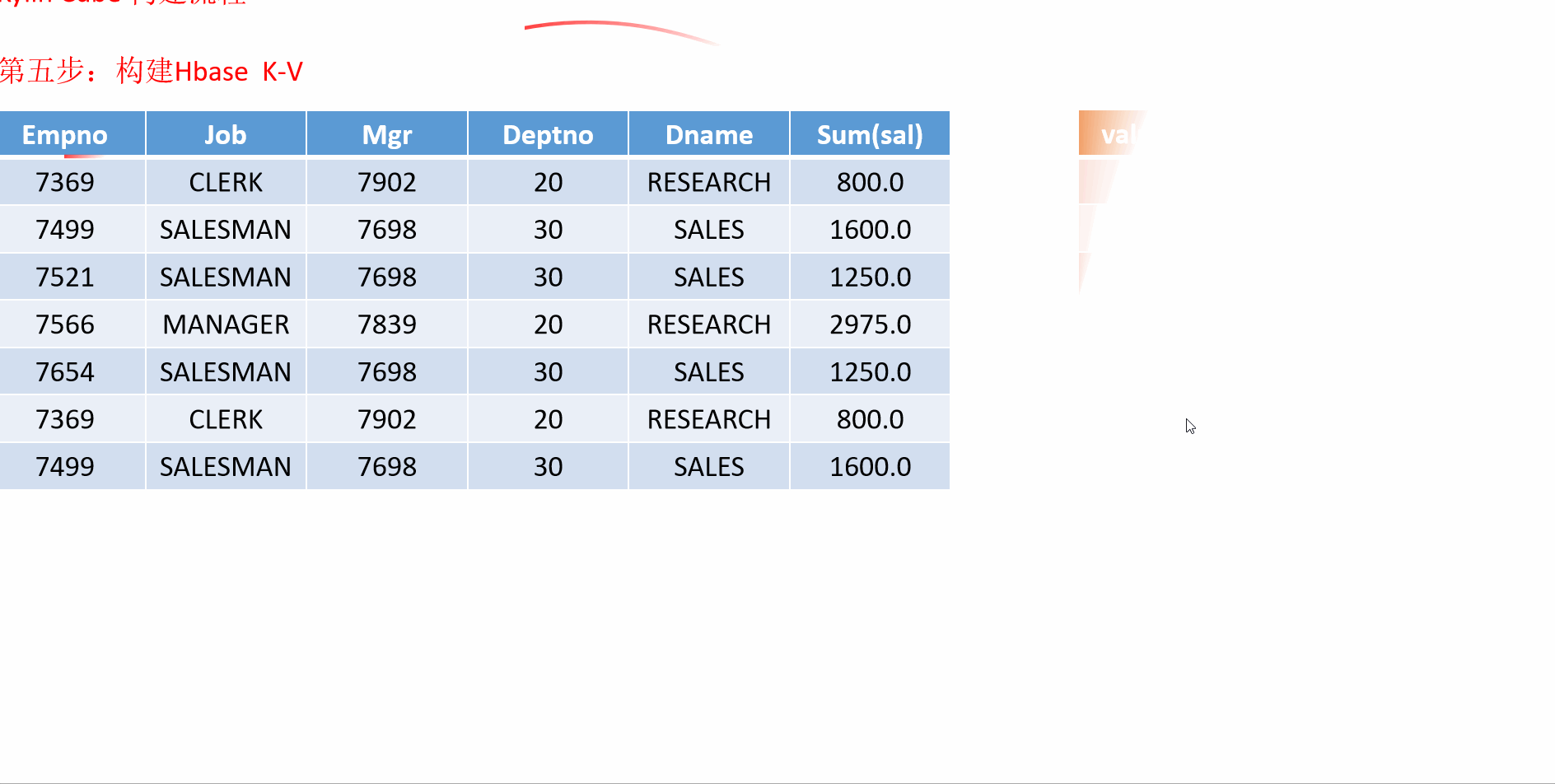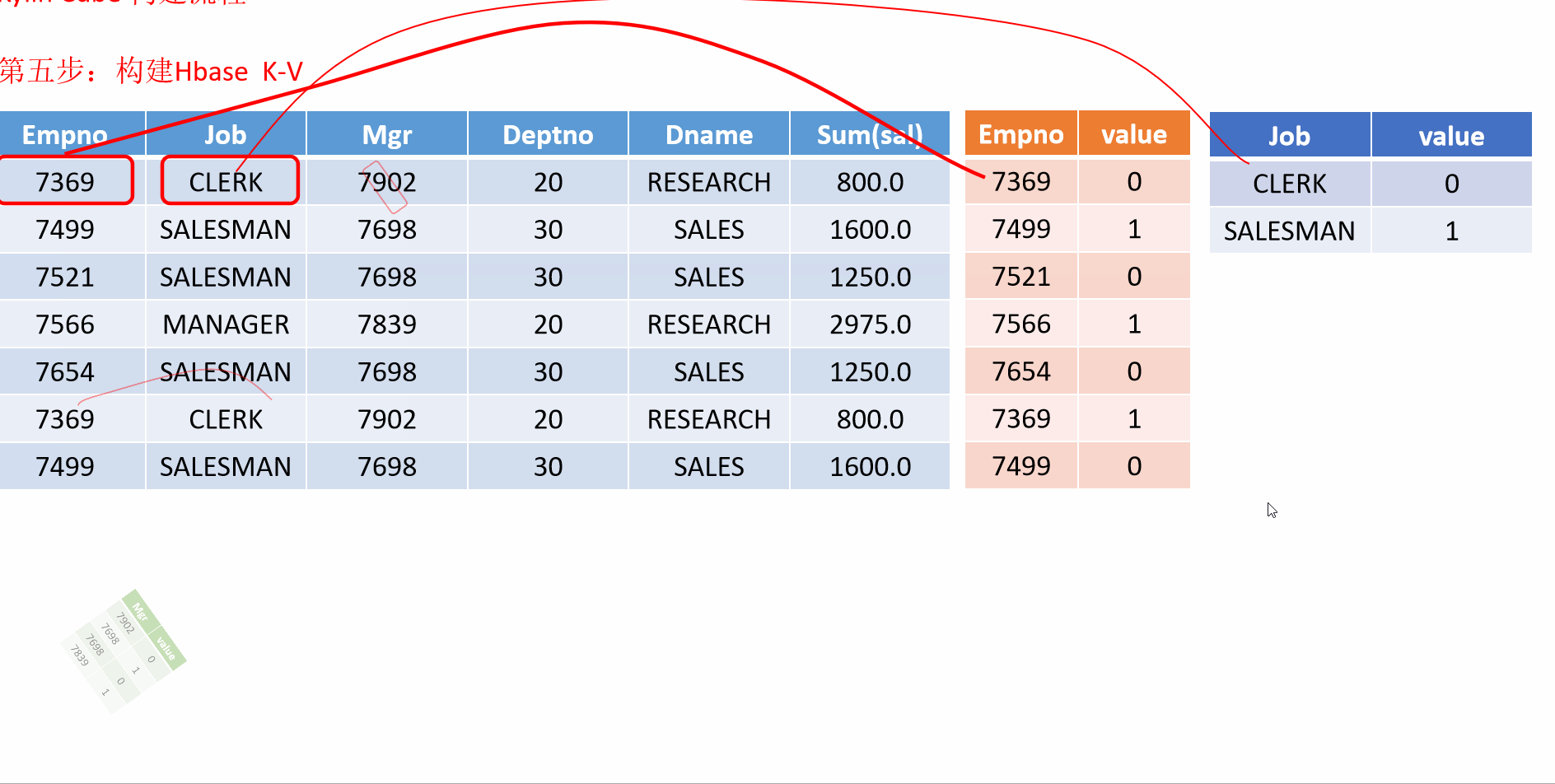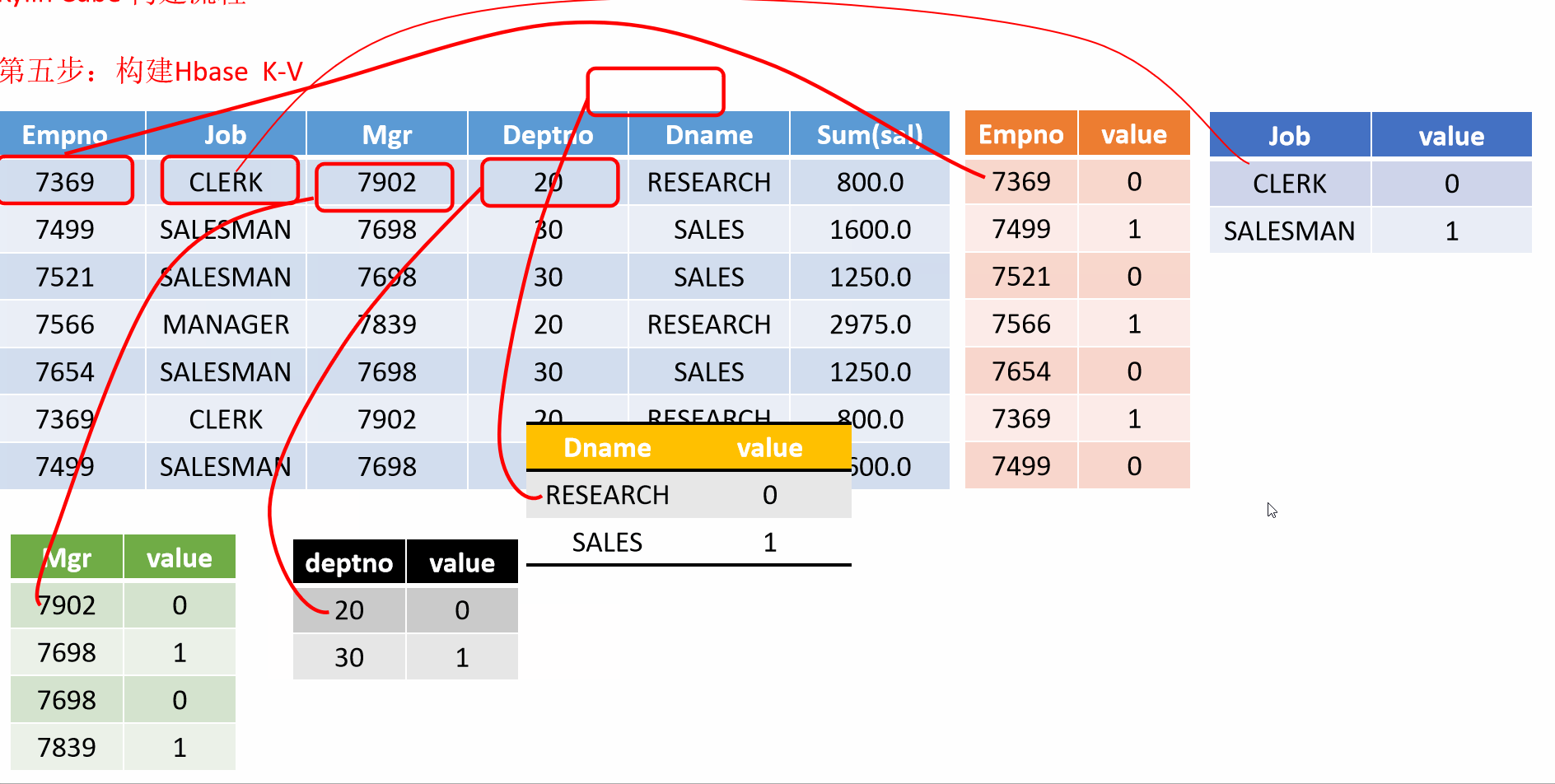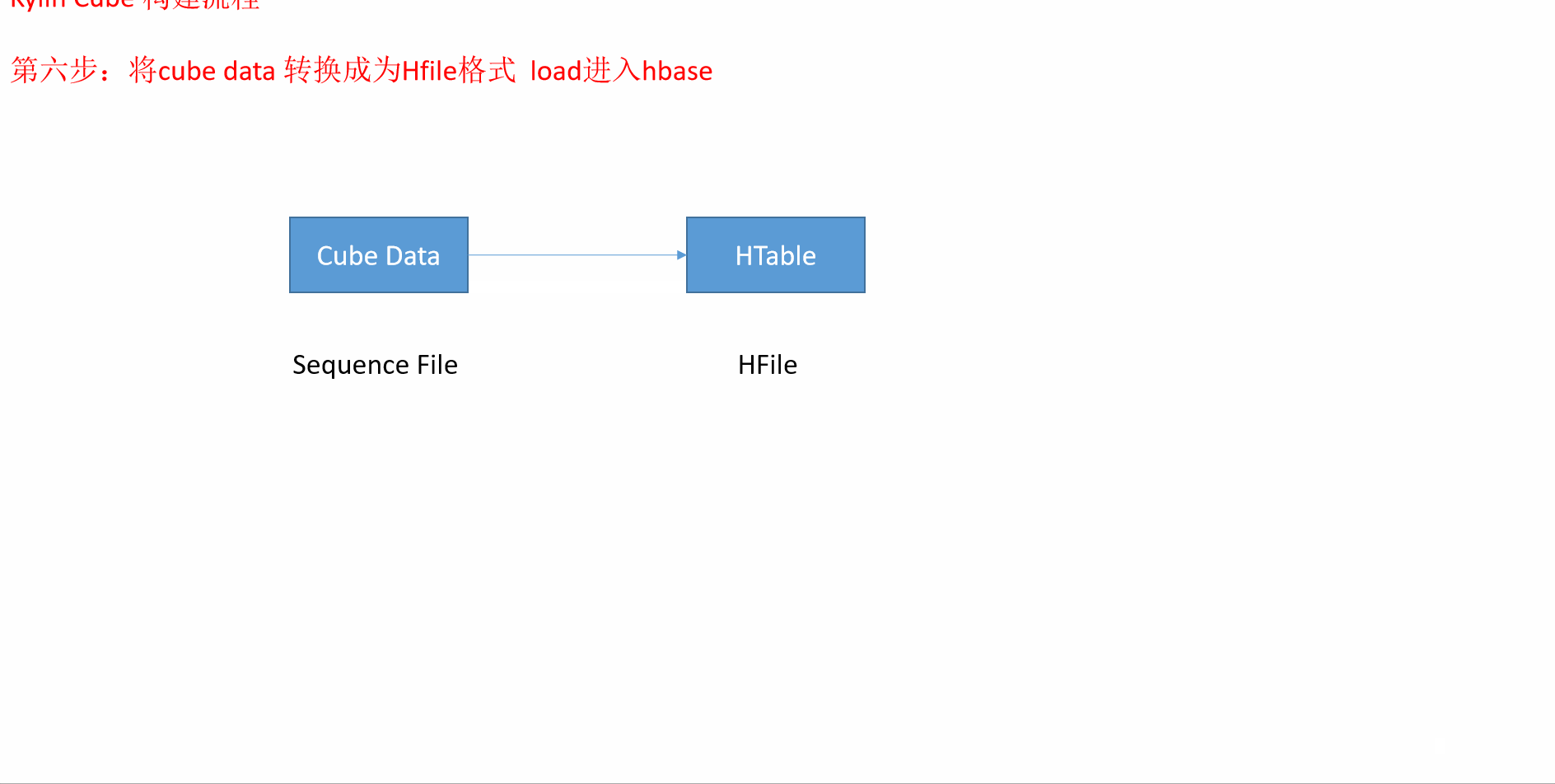
8 Kylin的工作原理
就是对数据模型做 Cube 预计算,并利用计算的结果加速查询,具体工作过程如下:
-
指定数据模型,定义维度和度量。
-
预计算 Cube,计算所有 Cuboid 并保存为物化视图。
-
执行查询时,读取 Cuboid,运算,产生查询结果。
由于 Kylin 的查询过程不会扫描原始记录,而是通过预计算预先完成表的关联、聚合等复杂运算,并利用预计算的结果来执行查询,因此相比非预计算的查询技术,其速度一般要快一到两个数量级,并且这点在超大的数据集上优势更明显。当数据集达到千亿乃至万亿级别时,Kylin 的速度甚至可以超越其他非预计算技术 1000 倍以上。
9 Cube 和 Cuboid
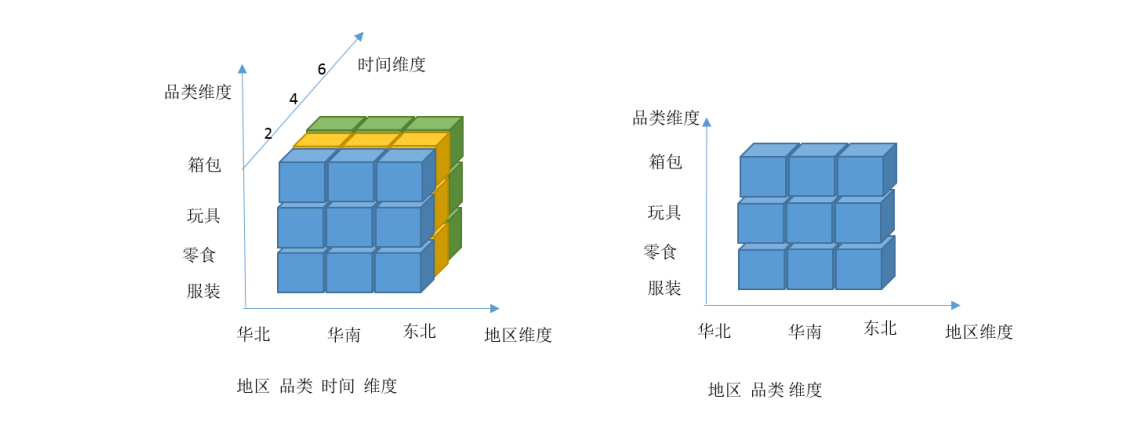
Cube(或 Data Cube),即数据立方体,是一种常用于数据分析与索引的技术;它可以对原始数据建立多维度索引。通过 Cube 对数据进行分析,可以大大加快数据的查询效率。
Cuboid 特指在某一种维度组合下所计算的数据。 给定一个数据模型,我们可以对其上的所有维度进行组合。对于 N 个维度来说,组合的所有可能性共有 2 的 N 次方种。对于每一种维度的组合,将度量做 聚合运算,然后将运算的结果保存为一个物化视图,称为 Cuboid。
所有维度组合的 Cuboid 作为一个整体,被称为 Cube。所以简单来说,一个 Cube 就是许多按维度聚合的物化视图的集合。
下面来列举一个具体的例子:
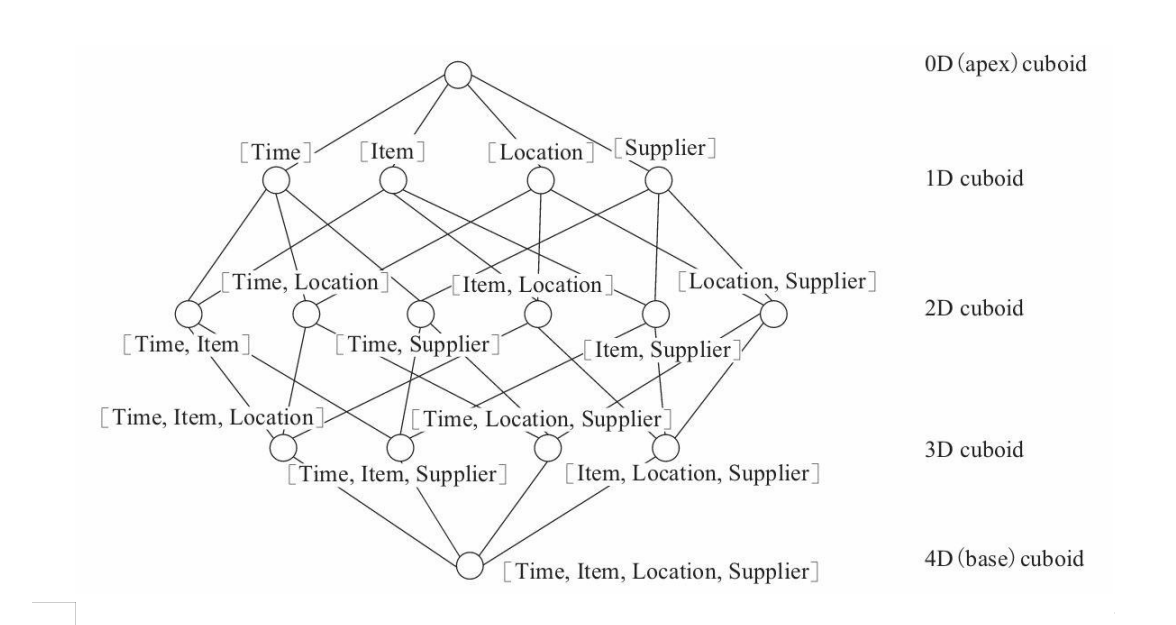
假定有一个电商的销售数据集,其中维度包括 时间(Time)、商品(Item)、地点(Location)和供应商(Supplier),度量为销售额(GMV)。
- 那么所有维度的组合就有 2 的 4 次方 =16 种
- 一维度(1D) 的组合有[Time]、[Item]、[Location]、[Supplier]4 种
- 二维度(2D)的组合 有[Time,Item]、[Time,Location]、[Time、Supplier]、[Item,Location]、 [Item,Supplier]、[Location,Supplier]6 种
- 三维度(3D)的组合也有 4 种
- 零维度(0D)的组合有 1 种
- 四维度(4D)的组合有 1 种
10 cube构建算法
10.1 逐层构建算法
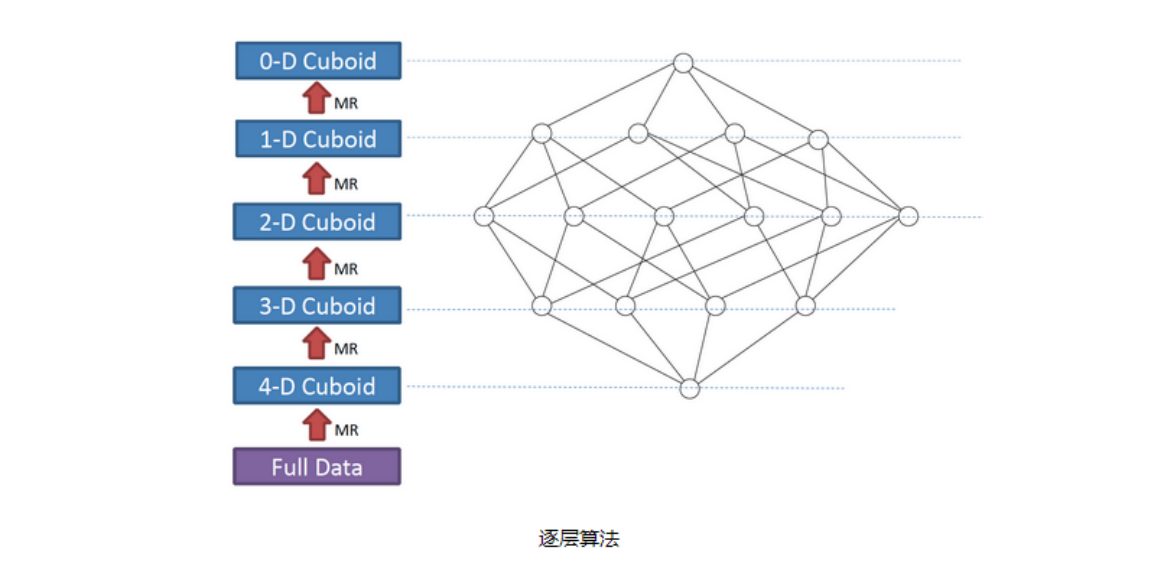
我们知道,一个N维的Cube,是由1个N维子立方体、N个(N-1)维子立方体、N*(N-1)/2个(N-2)维子立方体、......、N个1维子立方体和1个0维子立方体构成,总共有2^N个子立方体组成。
在逐层算法中,按维度数逐层减少来计算,每个层级的计算(除了第一层,它是从原始数据聚合而来),是基于它上一层级的结果来计算的。比如,[Group by A, B]的结果,可以基于[Group by A, B, C]的结果,通过去掉C后聚合得来的;这样可以减少重复计算;当 0维度Cuboid计算出来的时候,整个Cube的计算也就完成了。
每一轮的计算都是一个MapReduce任务,且串行执行;一个N维的Cube,至少需要N次MapReduce Job。
算法优点:
-
此算法充分利用了MapReduce的优点,处理了中间复杂的排序和shuffle工作,故而算法代码清晰简单,易于维护;
-
受益于Hadoop的日趋成熟,此算法非常稳定,即便是集群资源紧张时,也能保证最终能够完成。
算法缺点:
-
当Cube有比较多维度的时候,所需要的MapReduce任务也相应增加;由于Hadoop的任务调度需要耗费额外资源,特别是集群较庞大的时候,反复递交任务造成的额外开销会相当可观;
-
由于Mapper逻辑中并未进行聚合操作,所以每轮MR的shuffle工作量都很大,导致效率低下。
-
对HDFS的读写操作较多:由于每一层计算的输出会用做下一层计算的输入,这些Key-Value需要写到HDFS上;当所有计算都完成后,Kylin还需要额外的一轮任务将这些文件转成HBase的HFile格式,以导入到HBase中去;
总体而言,该算法的效率较低,尤其是当Cube维度数较大的时候。
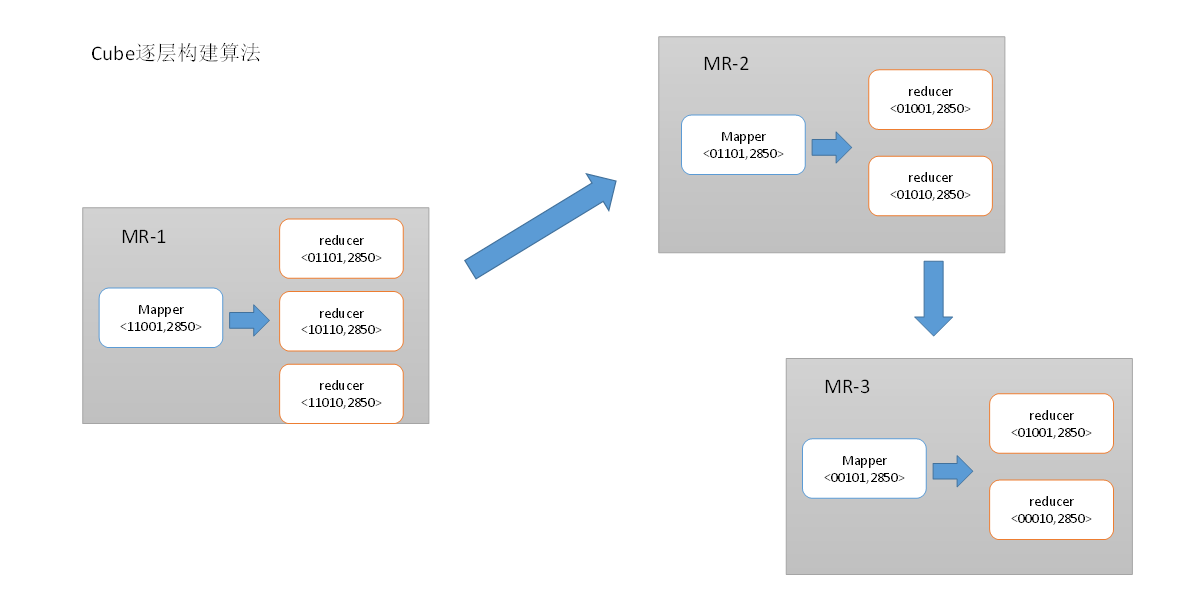
10.2 快速构建算法
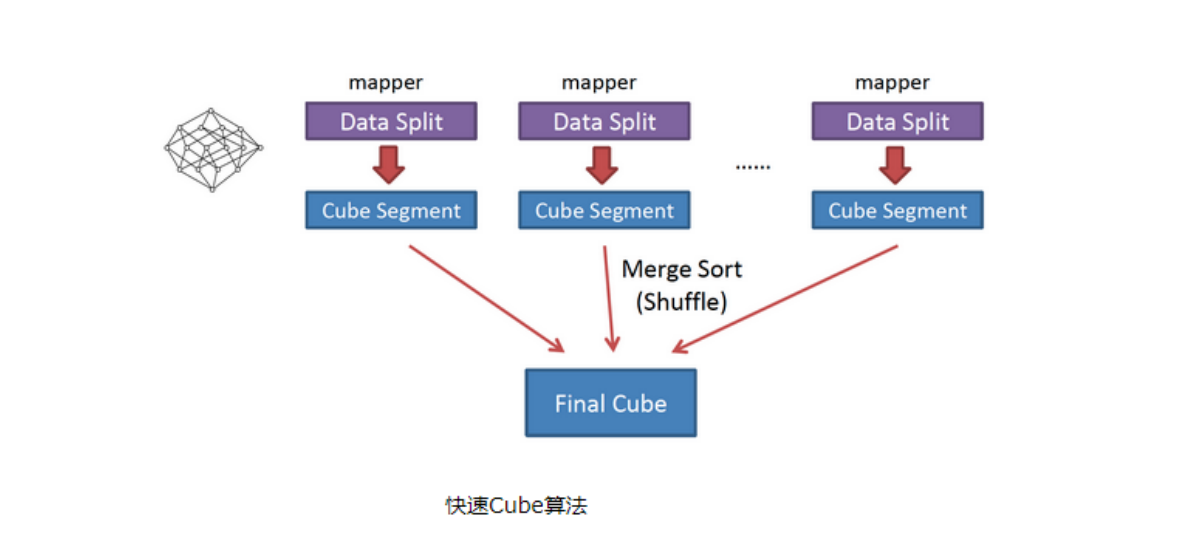
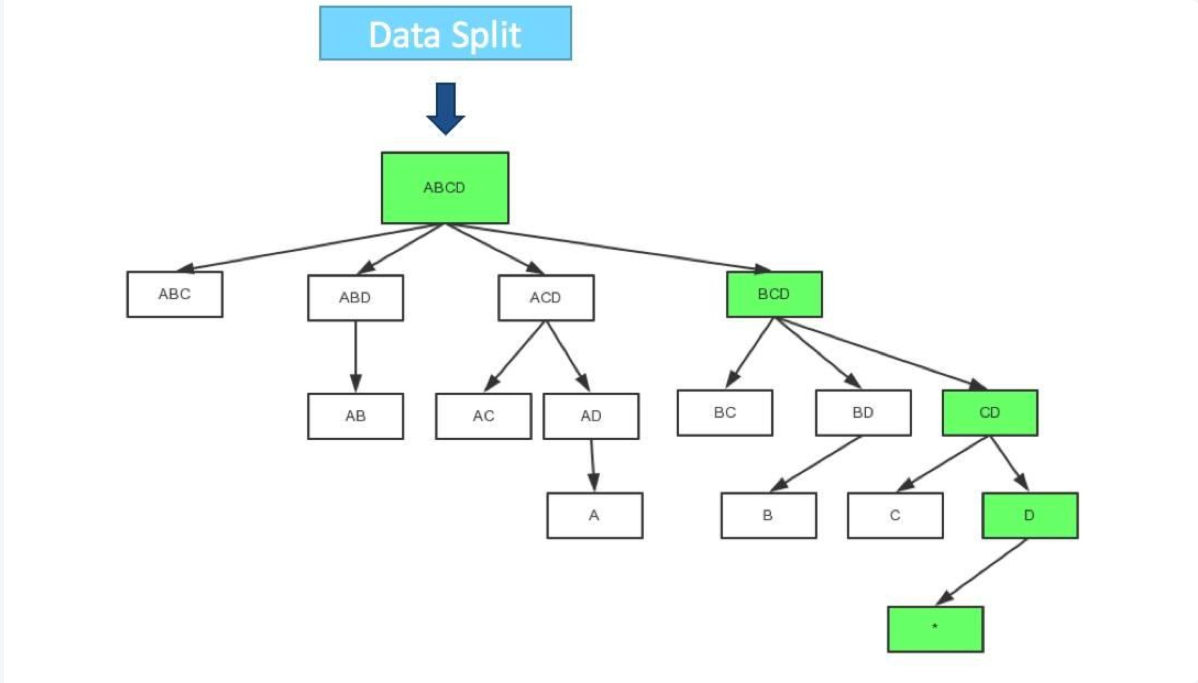
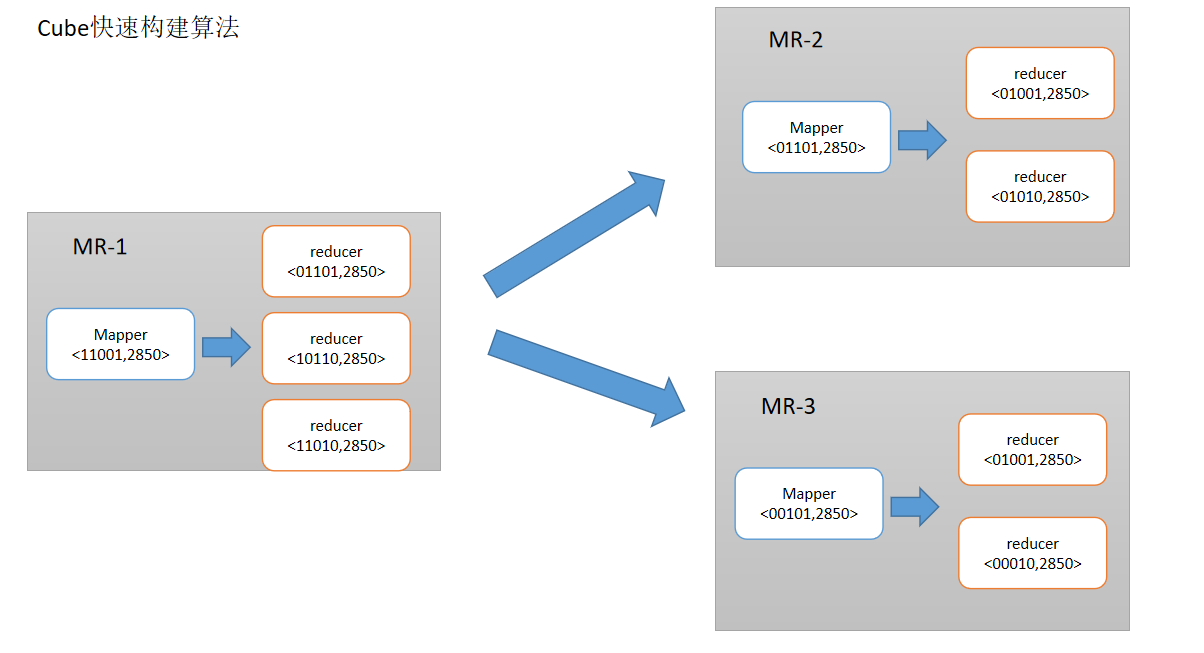
也被称作“逐段”(By Segment) 或“逐块”(By Split) 算法,从1.5.x开始引入该算法,该算法的主要思想是,每个Mapper将其所分配到的数据块,计算成一个完整的小Cube 段(包含所有Cuboid)。每个Mapper将计算完的Cube段输出给Reducer做合并,生成大Cube,也就是最终结果。如图所示解释了此流程。
与旧的逐层构建算法相比,快速算法主要有两点不同:
-
Mapper会利用内存做预聚合,算出所有组合;Mapper输出的每个Key都是不同的,这样会减少输出到Hadoop MapReduce的数据量,Combiner也不再需要;
-
一轮MapReduce便会完成所有层次的计算,减少Hadoop任务的调配。
11 备份及恢复
Kylin将它全部的元数据(包括cube描述和实例、项目、倒排索引描述和实例、任务、表和字典)组织成层级文件系统的形式。然而,Kylin使用hbase来存储元数据,而不是一个普通的文件系统。如果你查看过Kylin的配置文件(kylin.properties),你会发现这样一行:
## The metadata store in hbase
kylin.metadata.url=kylin_metadata@hbase
这表明元数据会被保存在一个叫作“kylin_metadata”的htable里。你可以在hbase shell里scan该htbale来获取它。
11.1 使用二进制包来备份Metadata Store
有时你需要将Kylin的Metadata Store从hbase备份到磁盘文件系统。在这种情况下,假设你在部署Kylin的hadoop命令行(或沙盒)里,你可以到KYLIN_HOME并运行:
./bin/metastore.sh backup
来将你的元数据导出到本地目录,这个目录在KYLIN_HOME/metadata_backps下,它的命名规则使用了当前时间作为参数:KYLIN_HOME/meta_backups/meta_year_month_day_hour_minute_second,如:meta_backups/meta_2020_06_18_19_37_49/
11.2 使用二进制包来恢复Metatdara Store
万一你发现你的元数据被搞得一团糟,想要恢复先前的备份:
- 首先,重置Metatdara Store(这个会清理Kylin在hbase的Metadata Store的所有信息,请确保先备份):
./bin/metastore.sh reset
- 然后上传备份的元数据到Kylin的Metadata Store:
./bin/metastore.sh restore $KYLIN_HOME/meta_backups/meta_xxxx_xx_xx_xx_xx_xx
- 等恢复操作完成,可以在“Web UI”的“System”页面单击“Reload Metadata”按钮对元数据缓存进行刷新,即可看到最新的元数据
做完备份,删除一些文件,然后进行恢复测试,完美恢复,叮叮叮!
12 kylin的垃圾清理
Kylin在构建cube期间会在HDFS上生成中间文件;除此之外,当清理/删除/合并cube时,一些HBase表可能被遗留在HBase却以后再也不会被查询;虽然Kylin已经开始做自动化的垃圾回收,但不一定能覆盖到所有的情况;你可以定期做离线的存储清理:
- 检查哪些资源可以清理,这一步不会删除任何东西:
${KYLIN_HOME}/bin/kylin.sh org.apache.kylin.tool.StorageCleanupJob --delete false
- 你可以抽查一两个资源来检查它们是否已经没有被引用了;然后加上“–delete true”选项进行清理。
${KYLIN_HOME}/bin/kylin.sh org.apache.kylin.tool.StorageCleanupJob --delete true
完成后,中间HDFS上的中间文件和HTable会被移除。
13 Kylin优化
13.1 维度优化
如果不进行任何维度优化,直接将所有的维度放在一个聚集组里,Kylin就会计算所有的维度组合(cuboid)。
比如,有12个维度,Kylin就会计算2的12次方即4096个cuboid,实际上查询可能用到的cuboid不到1000个,甚至更少。 如果对维度不进行优化,会造成集群计算和存储资源的浪费,也会影响cube的build时间和查询性能,所以我们需要进行cube的维度优化。
当你在保存cube时遇到下面的异常信息时,意味1个聚集组的维度组合数已经大于 4096 ,你就必须进行维度优化了。

或者发现cube的膨胀率过大。
但在现实情况中,用户的维度数量一般远远大于4个。假设用户有10 个维度,那么没有经过任何优化的Cube就会存在 2的10次方 = 1024个Cuboid;虽然每个Cuboid的大小存在很大的差异,但是单单想到Cuboid的数量就足以让人想象到这样的Cube对构建引擎、存储引擎来说压力有多么巨大。因此,在构建维度数量较多的Cube时,尤其要注意Cube的剪枝优化(即减少Cuboid的生成)。
13.2 使用衍生维度
-
衍生维度:维表中可以由主键推导出值的列可以作为衍⽣维度。
-
使用场景:以星型模型接入时。例如用户维表可以从userid推导出用户的姓名,年龄,性别。
-
优化效果:维度表的N个维度组合成的cuboid个数会从2的N次方降为2。
衍生维度用于在有效维度内将维度表上的非主键维度排除掉,并使用维度表的主键(其实是事实表上相应的外键)来替代它们。Kylin会在底层记录维度表主键与维度表其他维度之间的映射关系,以便在查询时能够动态地将维度表的主键“翻译”成这些非主键维度,并进行实时聚合。
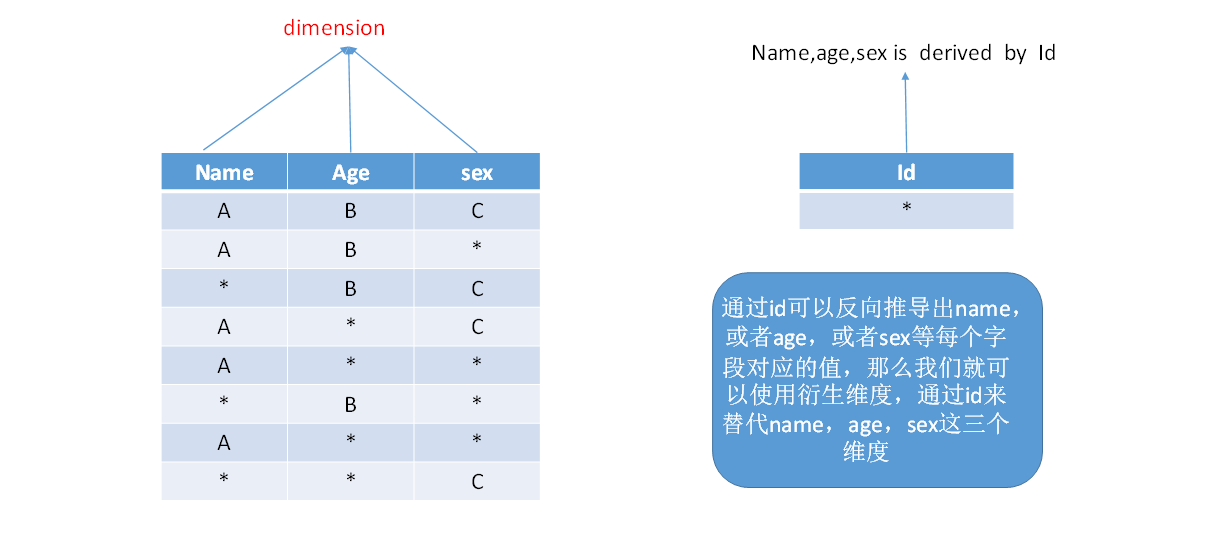
虽然衍生维度具有非常大的吸引力,但这也并不是说所有维度表上的维度都得变成衍生维度,如果从维度表主键到某个维度表维度所需要的聚合工作量非常大,则不建议使用衍生维度。
13.3 使用聚合组(Aggregation group)
聚合组(Aggregation Group)是一种强大的剪枝工具。聚合组假设一个Cube的所有维度均可以根据业务需求划分成若干组(当然也可以是一个组),由于同一个组内的维度更可能同时被同一个查询用到,因此会表现出更加紧密的内在关联。每个分组的维度集合均是Cube所有维度的一个子集,不同的分组各自拥有一套维度集合,它们可能与其他分组有相同的维度,也可能没有相同的维度。每个分组各自独立地根据自身的规则贡献出一批需要被物化的Cuboid,所有分组贡献的Cuboid的并集就成为了当前Cube中所有需要物化的Cuboid的集合。不同的分组有可能会贡献出相同的Cuboid,构建引擎会察觉到这点,并且保证每一个Cuboid无论在多少个分组中出现,它都只会被物化一次。
对于每个分组内部的维度,用户可以使用如下三种可选的方式定义,它们之间的关系,具体如下。
-
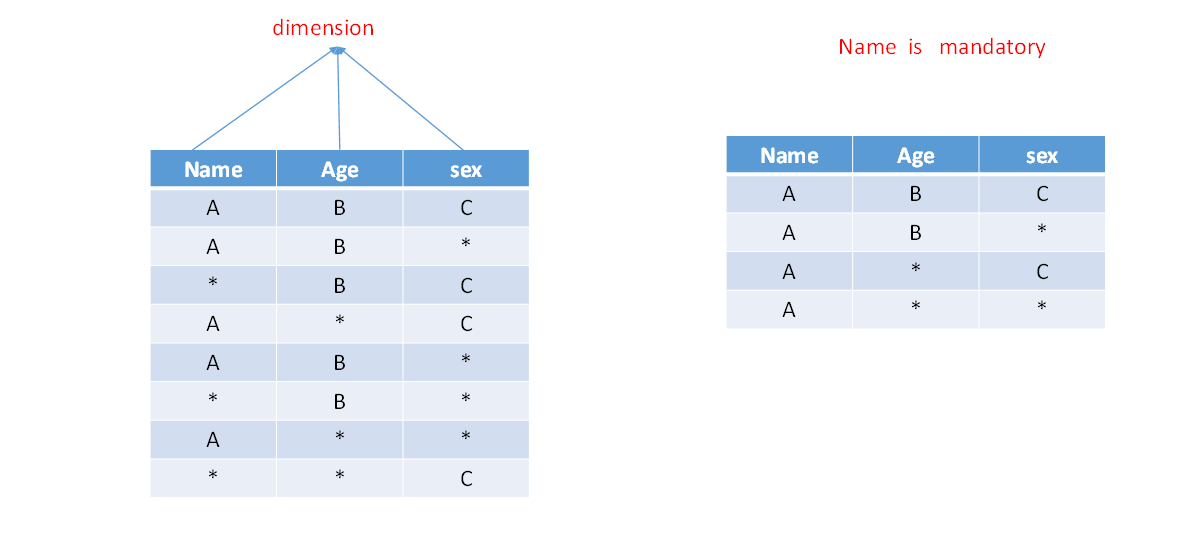
强制维度(Mandatory)
-
强制维度:所有cuboid必须包含的维度,不会计算不包含强制维度的cuboid。
-
适用场景:可以将确定在查询时一定会使用的维度设为强制维度。例如,时间维度。
-
优化效果:将一个维度设为强制维度,则cuboid个数直接减半。
-
如果一个维度被定义为强制维度,那么这个分组产生的所有Cuboid中每一个Cuboid都会包含该维度。每个分组中都可以有0个、1个或多个强制维度。如果根据这个分组的业务逻辑,则相关的查询一定会在过滤条件或分组条件中,因此可以在该分组中把该维度设置为强制维度。
-
层级维度(Hierarchy),
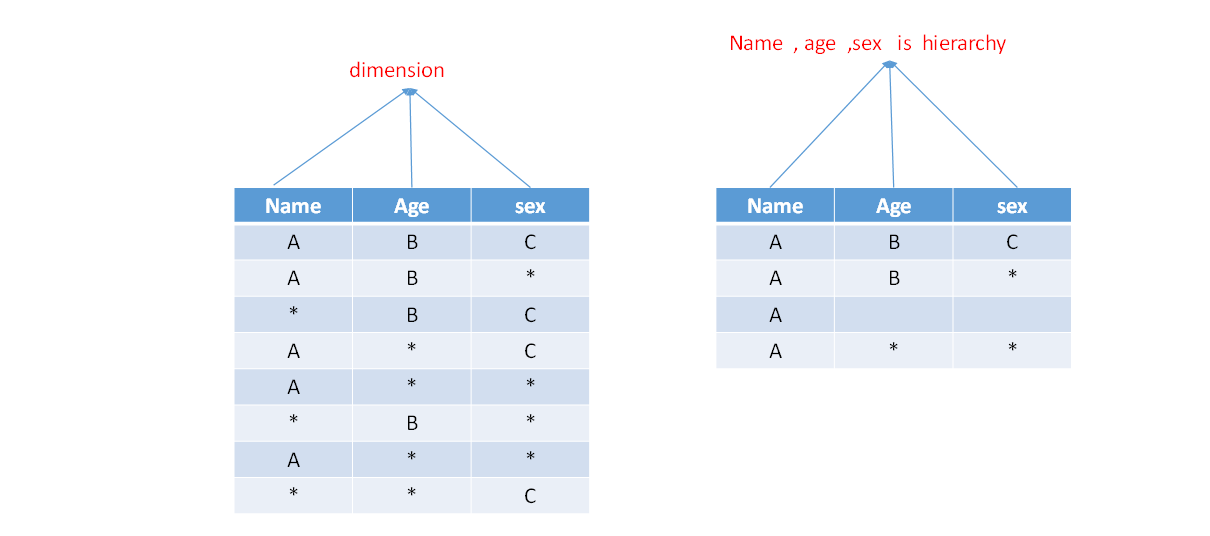
-
层级维度:具有一定层次关系的维度。
-
使用场景:像年,月,日;国家,省份,城市这类具有层次关系的维度。
-
优化效果:将N个维度设置为层次维度,则这N个维度组合成的cuboid个数会从2的N次方减少到N+1。
-
每个层级包含两个或更多个维度。假设一个层级中包含D1,D2…Dn这n个维度,那么在该分组产生的任何Cuboid中, 这n个维度只会以(),(D1),(D1,D2)…(D1,D2…Dn)这n+1种形式中的一种出现。每个分组中可以有0个、1个或多个层级,不同的层级之间不应当有共享的维度。如果根据这个分组的业务逻辑,则多个维度直接存在层级关系,因此可以在该分组中把这些维度设置为层级维度。
-
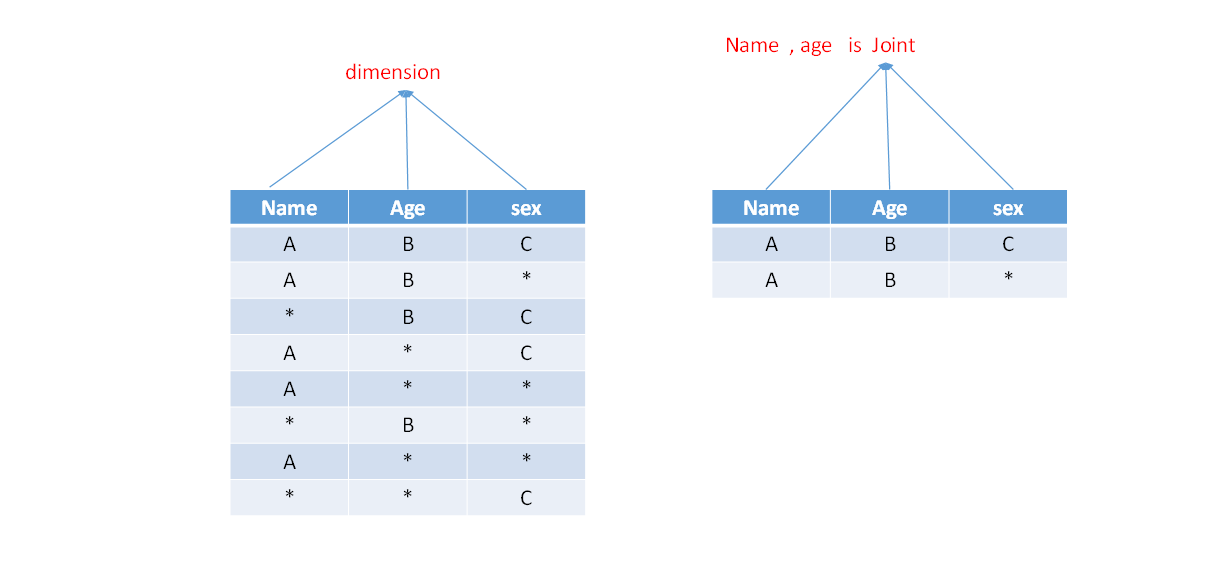
联合维度(Joint),
-
联合维度:将几个维度视为一个维度。
-
适用场景:
- 可以将确定在查询时一定会同时使用的几个维度设为一个联合维度。
- 可以将基数很小的几个维度设为一个联合维度。
- 可以将查询时很少使用的几个维度设为一个联合维度。
-
优化效果:将N个维度设置为联合维度,则这N个维度组合成的cuboid个数会从2的N次方减少到1。
-
每个联合中包含两个或更多个维度,如果某些列形成一个联合,那么在该分组产生的任何Cuboid中,这些联合维度要么一起出现,要么都不出现。每个分组中可以有0个或多个联合,但是不同的联合之间不应当有共享的维度(否则它们可以合并成一个联合)。如果根据这个分组的业务逻辑,多个维度在查询中总是同时出现,则可以在该分组中把这些维度设置为联合维度。
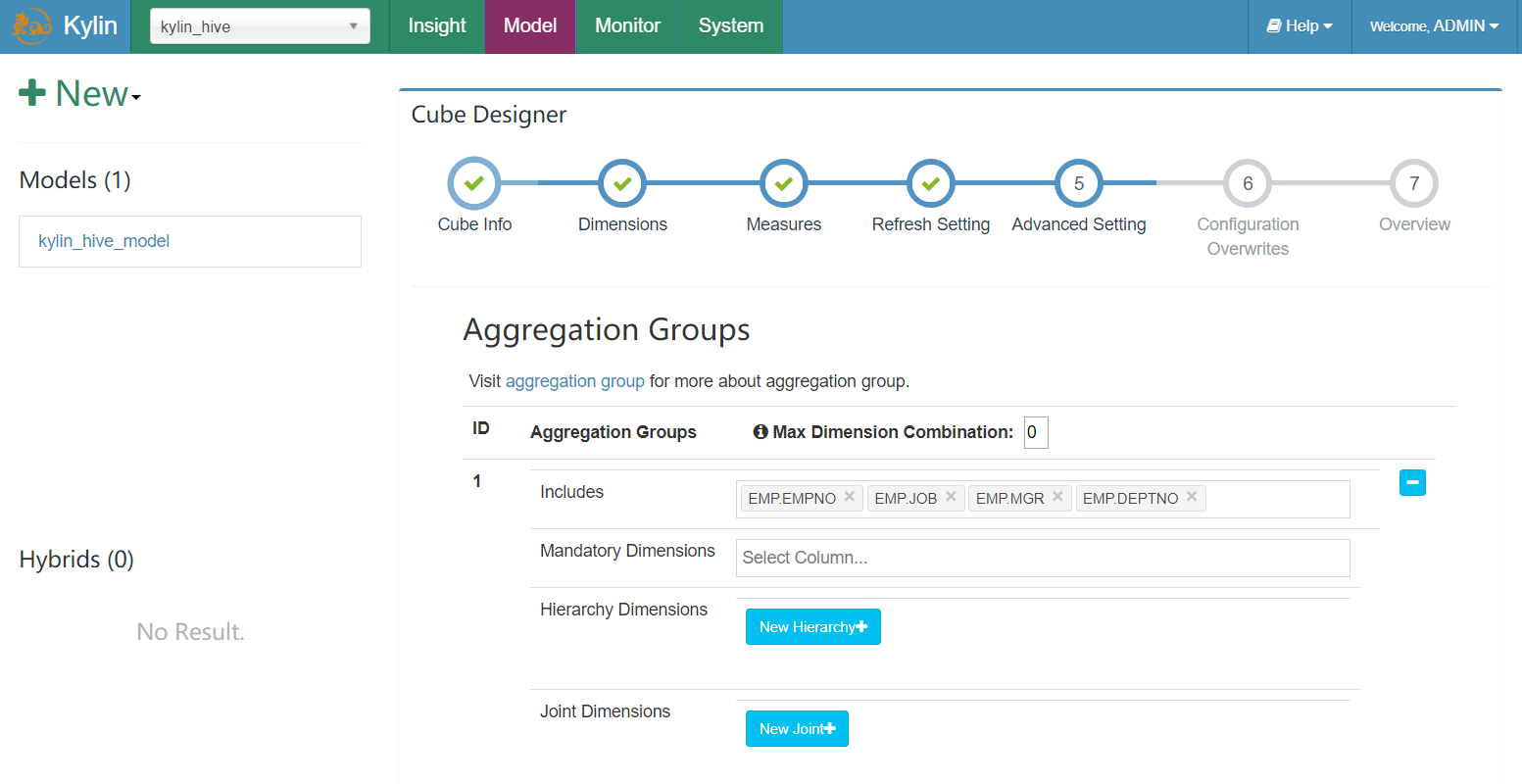
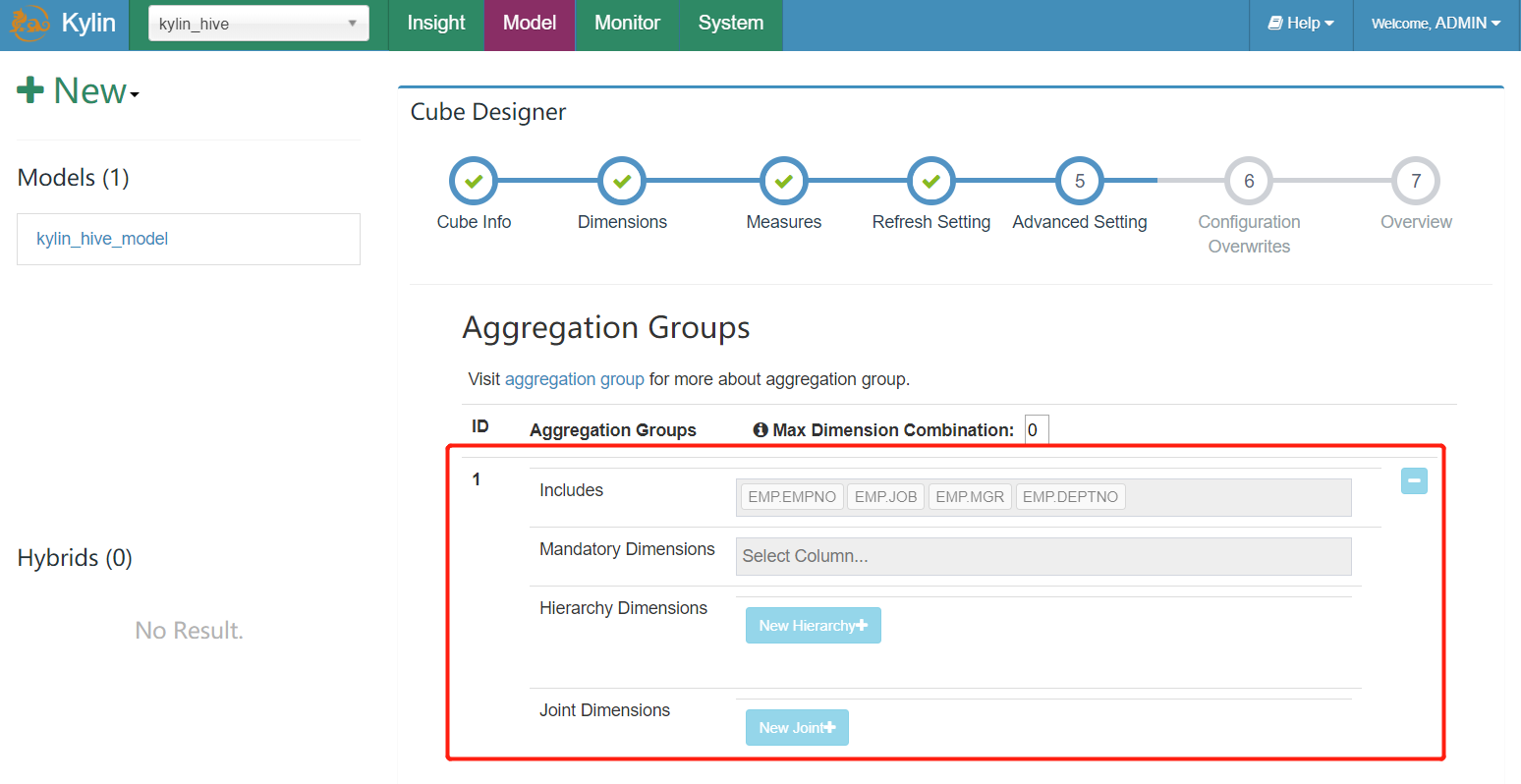
这些操作可以在Cube Designer的Advanced Setting中的Aggregation Groups区域完成,如下图所示。
聚合组的设计非常灵活,甚至可以用来描述一些极端的设计。假设我们的业务需求非常单一,只需要某些特定的Cuboid,那么可以创建多个聚合组,每个聚合组代表一个Cuboid。具体的方法是在聚合组中先包含某个Cuboid所需的所有维度,然后把这些维度都设置为强制维度。这样当前的聚合组就只能产生我们想要的那一个Cuboid了。
再比如,有的时候我们的Cube中有一些基数非常大的维度,如果不做特殊处理,它就会和其他的维度进行各种组合,从而产生一大堆包含它的Cuboid。包含高基数维度的Cuboid在行数和体积上往往非常庞大,这会导致整个Cube的膨胀率变大。如果根据业务需求知道这个高基数的维度只会与若干个维度(而不是所有维度)同时被查询到,那么就可以通过聚合组对这个高基数维度做一定的“隔离”。我们把这个高基数的维度放入一个单独的聚合组,再把所有可能会与这个高基数维度一起被查询到的其他维度也放进来。这样,这个高基数的维度就被“隔离”在一个聚合组中了,所有不会与它一起被查询到的维度都没有和它一起出现在任何一个分组中,因此也就不会有多余的Cuboid产生。这点也大大减少了包含该高基数维度的Cuboid的数量,可以有效地控制Cube的膨胀率。
13.4 并发粒度优化
当Segment中某一个Cuboid的大小超出一定的阈值时,系统会将该Cuboid的数据分片到多个分区中,以实现Cuboid数据读取的并行化,从而优化Cube的查询速度。具体的实现方式如下:构建引擎根据Segment估计的大小,以及参数“kylin.hbase.region.cut”的设置决定Segment在存储引擎中总共需要几个分区来存储,如果存储引擎是HBase,那么分区的数量就对应于HBase中的Region数量。kylin.hbase.region.cut的默认值是5.0,单位是GB,也就是说对于一个大小估计是50GB的Segment,构建引擎会给它分配10个分区。用户还可以通过设置kylin.hbase.region.count.min(默认为1)和kylin.hbase.region.count.max(默认为500)两个配置来决定每个Segment最少或最多被划分成多少个分区。
由于每个Cube的并发粒度控制不尽相同,因此建议在Cube Designer 的Configuration Overwrites(上图所示)中为每个Cube量身定制控制并发粒度的参数。假设将把当前Cube的kylin.hbase.region.count.min设置为2,kylin.hbase.region.count.max设置为100。这样无论Segment的大小如何变化,它的分区数量最小都不会低于2,最大都不会超过100。相应地,这个Segment背后的存储引擎(HBase)为了存储这个Segment,也不会使用小于两个或超过100个的分区。我们还调整了默认的kylin.hbase.region.cut,这样50GB的Segment基本上会被分配到50个分区,相比默认设置,我们的Cuboid可能最多会获得5倍的并发量。
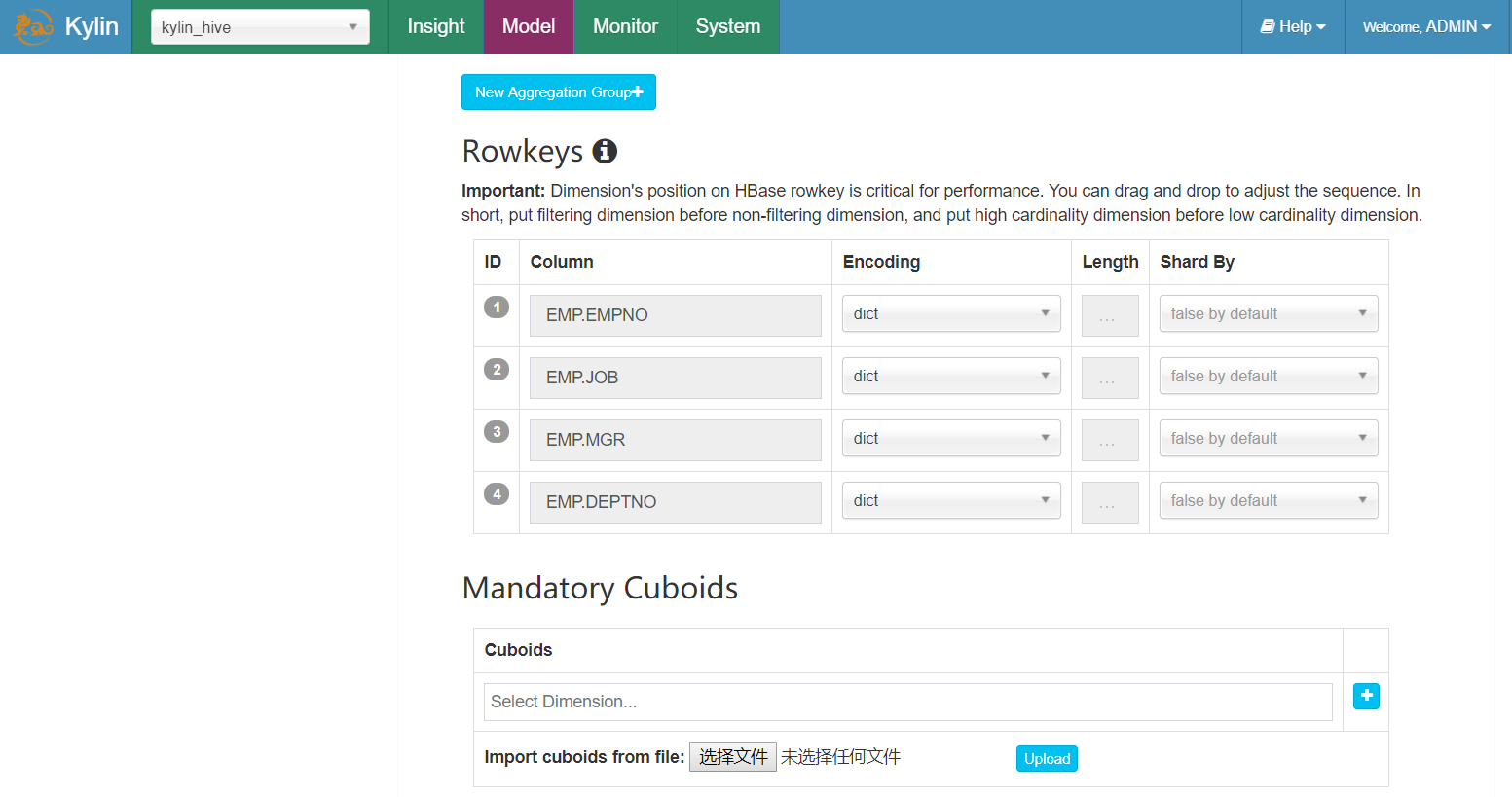
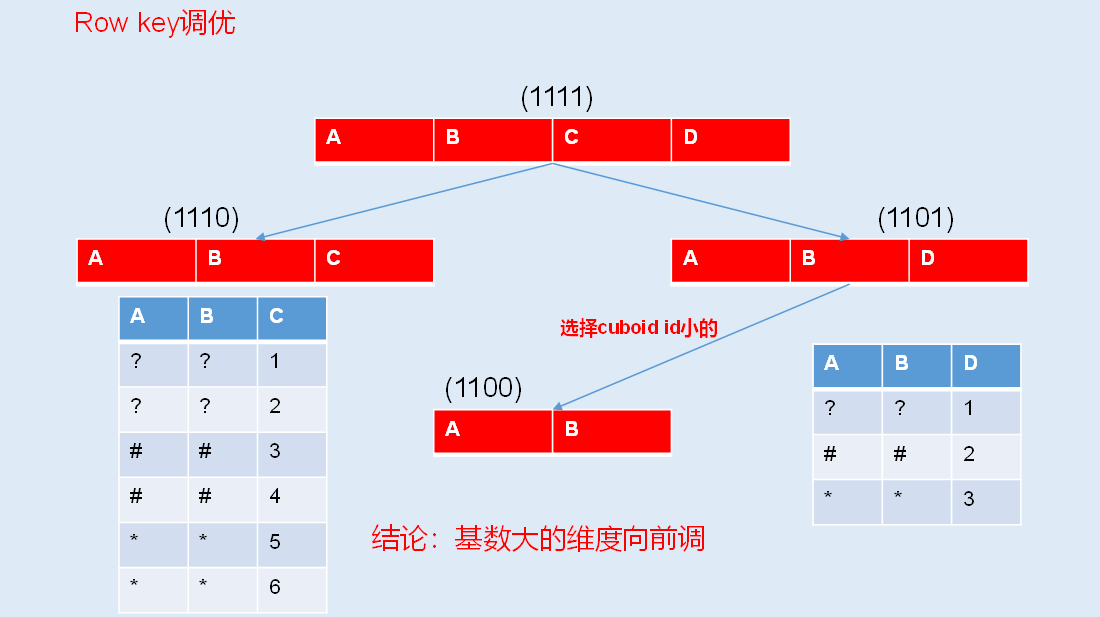
13.5 Row Key优化
Kylin会把所有的维度按照顺序组合成一个完整的Rowkey,并且按照这个Rowkey升序排列Cuboid中所有的行。
设计良好的Rowkey将更有效地完成数据的查询过滤和定位,减少IO次数,提高查询速度,维度在rowkey中的次序,对查询性能有显著的影响。
Row key的设计原则如下:
- 被用作where过滤的维度放在前边。

- 基数大的维度放在基数小的维度前边。
13.6 增量cube构建
构建全量cube,也可以实现增量cube的构建,就是通过分区表的分区时间字段来进行增量构建
- 更改model
- 更改cube

14 Kafka 流构建 Cube(Kylin实时案例)
Kylin v1.6 发布了可扩展的 streaming cubing 功能,它利用 Hadoop 消费 Kafka 数据的方式构建 cube。
参考:http://kylin.apache.org/blog/2016/10/18/new-nrt-streaming/
前期准备:kylin v1.6.0 或以上版本 和 可运行的 Kafka(v0.10.0 或以上版本)的 Hadoop 环境
14.1 Kafka创建Topic
- 创建样例名为 “kylin_streaming_topic” 具有一个副本三个分区的 topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic kylin_streaming_topic

- 将样例数据放入 topic,Kylin 有一个实用类可以做这项工作;
cd $KYLIN_HOME
./bin/kylin.sh org.apache.kylin.source.kafka.util.KafkaSampleProducer --topic kylin_streaming_topic --broker cdh01.cm:9092,cdh02.cm:9092,cdh03.cm:9092

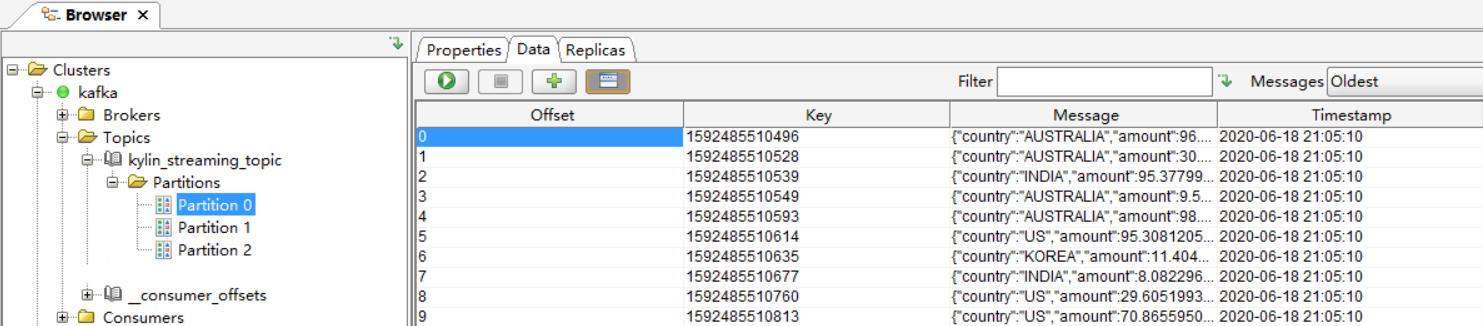
工具每一秒会向 Kafka 发送 100 条记录。直至本案例结束请让其一直运行。
14.2 用streaming定义一张表
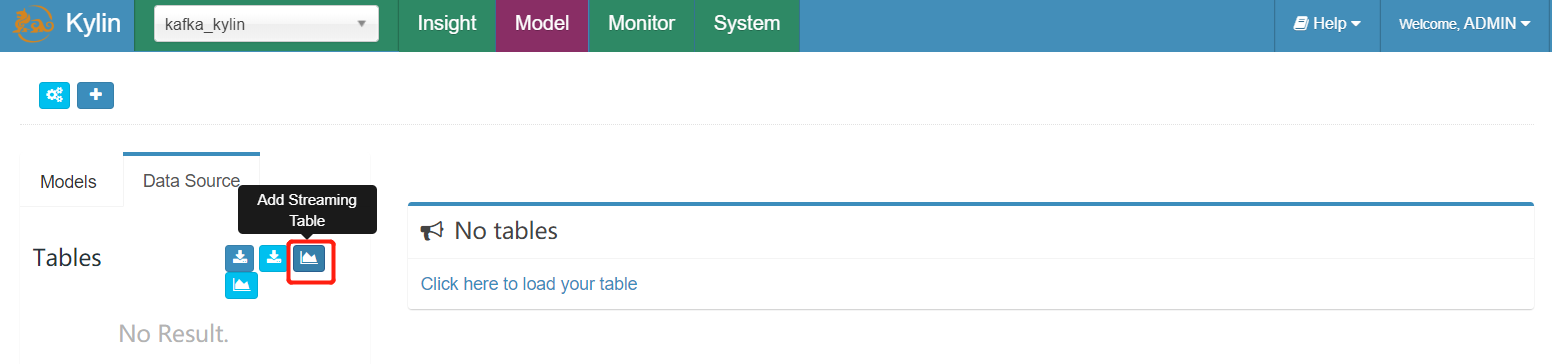
登陆 Kylin Web GUI,选择一个已存在的 project 或创建一个新的 project;点击 “Model” -> “Data Source”,点击 “Add Streaming Table” 图标
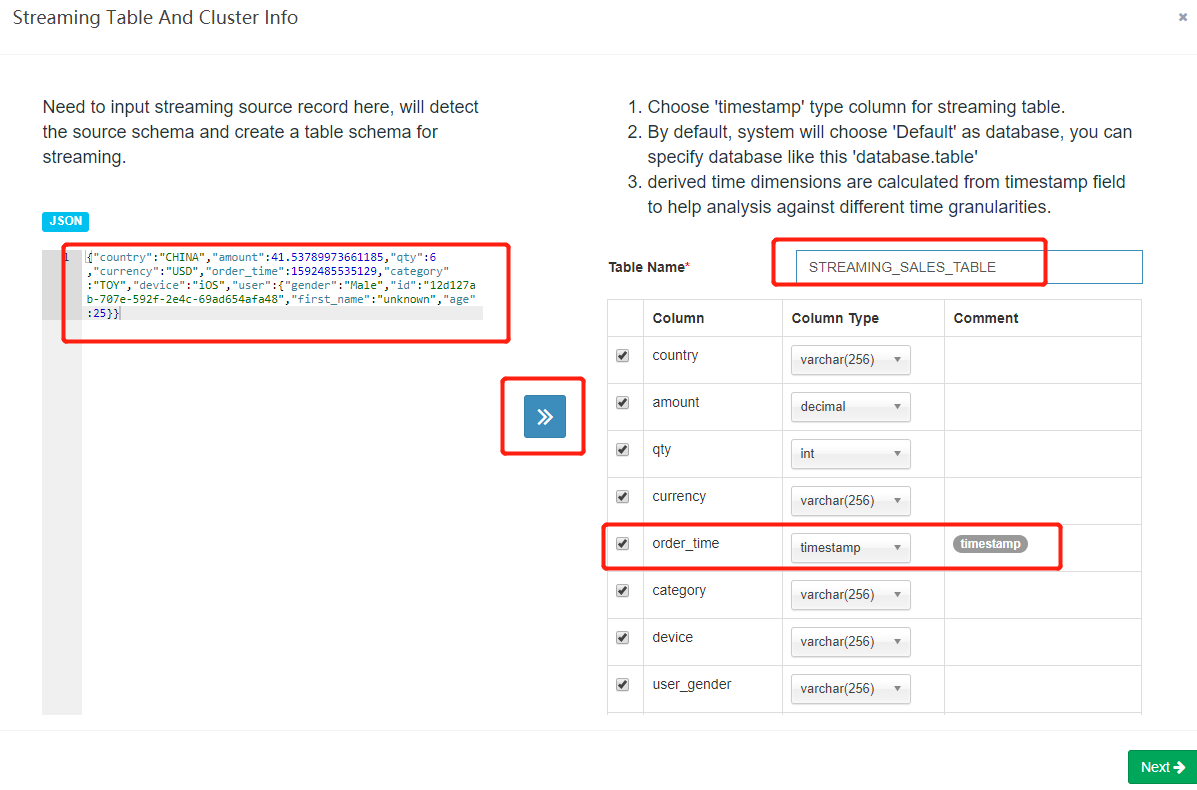
- 在弹出的对话框中,输入您从 kafka-console-consumer 中获得的样例记录,点击 “»” 按钮,Kylin 会解析 JSON 消息并列出所有的消息
{"country":"CHINA","amount":41.53789973661185,"qty":6,"currency":"USD","order_time":1592485535129,"category":"TOY","device":"iOS","user":{"gender":"Male","id":"12d127ab-707e-592f-2e4c-69ad654afa48","first_name":"unknown","age":25}}
-
您需要为这个 streaming 数据源起一个逻辑表名;该名字会在后续用于 SQL 查询;这里是在 “Table Name” 字段输入 “STREAMING_SALES_TABLE” 作为样例。
-
您需要选择一个时间戳字段用来标识消息的时间;Kylin 可以从这列值中获得其他时间值,如 “year_start”,”quarter_start”,这为您构建和查询 cube 提供了更高的灵活性。这里可以查看 “order_time”。您可以取消选择那些 cube 不需要的属性。这里我们保留了所有字段。
-
注意 Kylin 从 1.6 版本开始支持结构化 (或称为 “嵌入”) 消息,会将其转换成一个 flat table structure。默认使用 “_” 作为结构化属性的分隔符。
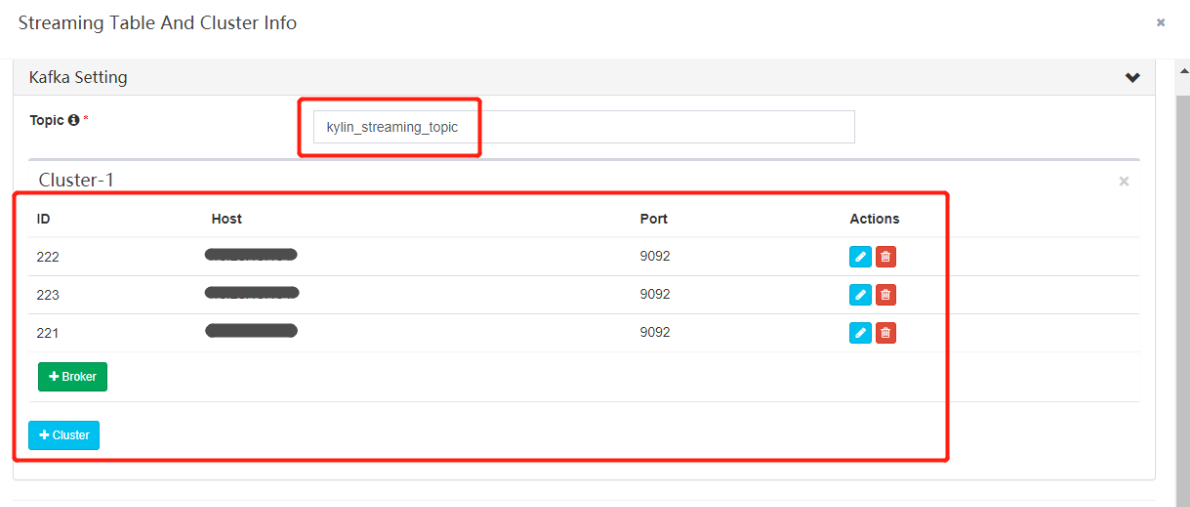
- 点击 “Next”。在这个页面,提供了 Kafka 集群信息;输入 “kylin_streaming_topic” 作为 “Topic” 名;集群有 3 个 broker,其主机名为”cdh01.cm,cdh02.cm,cdh03.cm“,端口为 “9092”,点击 “Save”。
-
在 “Advanced setting” 部分,”timeout” 和 “buffer size” 是和 Kafka 进行连接的配置,保留它们。
-
在 “Parser Setting”,Kylin 默认您的消息为 JSON 格式,每一个记录的时间戳列 (由 “tsColName” 指定) 是 bigint (新纪元时间) 类型值;在这个例子中,您只需设置 “tsColumn” 为 “order_time”;
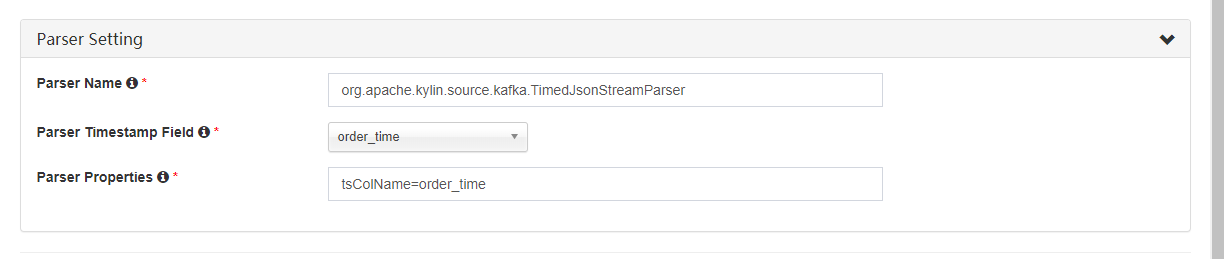
- 在现实情况中如果时间戳值为 string 如 “Jul 20,2016 9:59:17 AM”,您需要用 “tsParser” 指定解析类和时间模式例如:

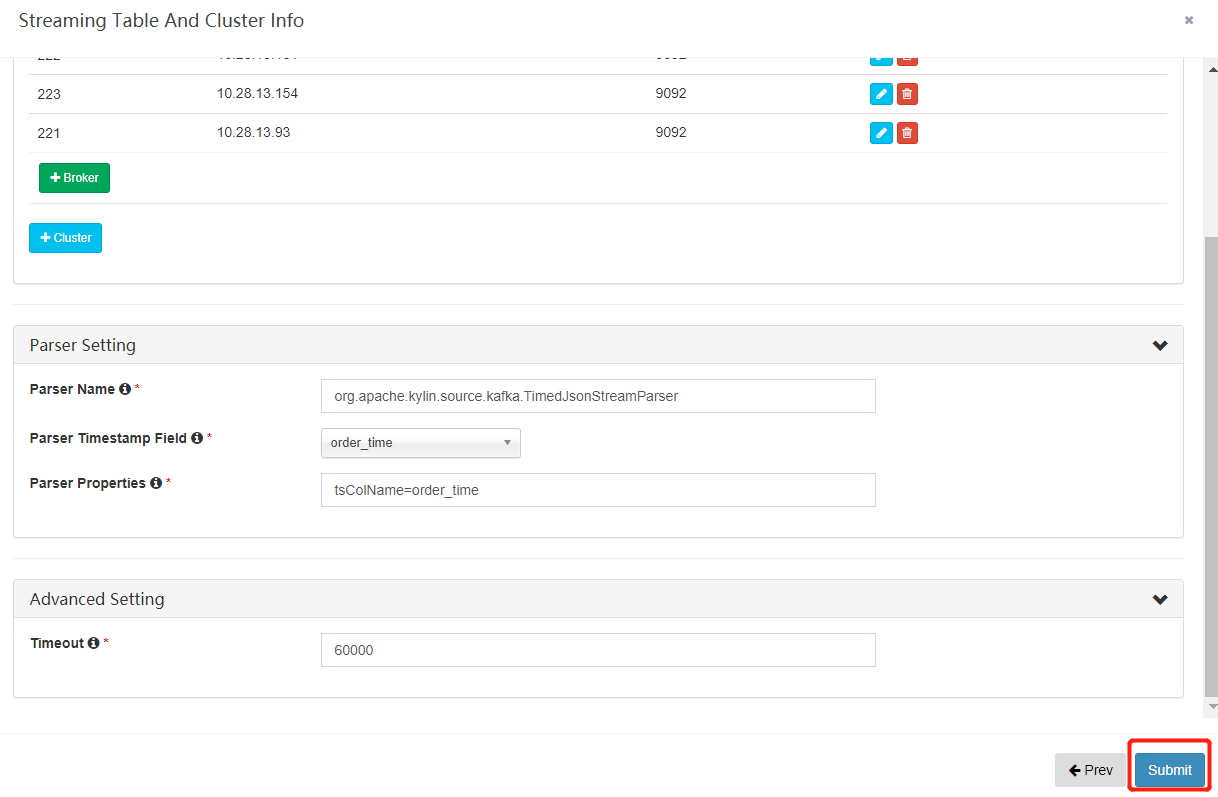
- 点击 “Submit” 保存设置。现在 “Streaming” 表就创建好了。
14.3 定义数据模型
-
有了上一步创建的表,现在我们可以创建数据模型了。步骤和您创建普通数据模型是一样的,但有两个要求:
- Streaming Cube 不支持与 lookup 表进行 join;当定义数据模型时,只选择 fact 表,不选 lookup 表;
- Streaming Cube 必须进行分区;如果您想要在分钟级别增量的构建 Cube,选择 “MINUTE_START” 作为 cube 的分区日期列。如果是在小时级别,选择 “HOUR_START”。
-
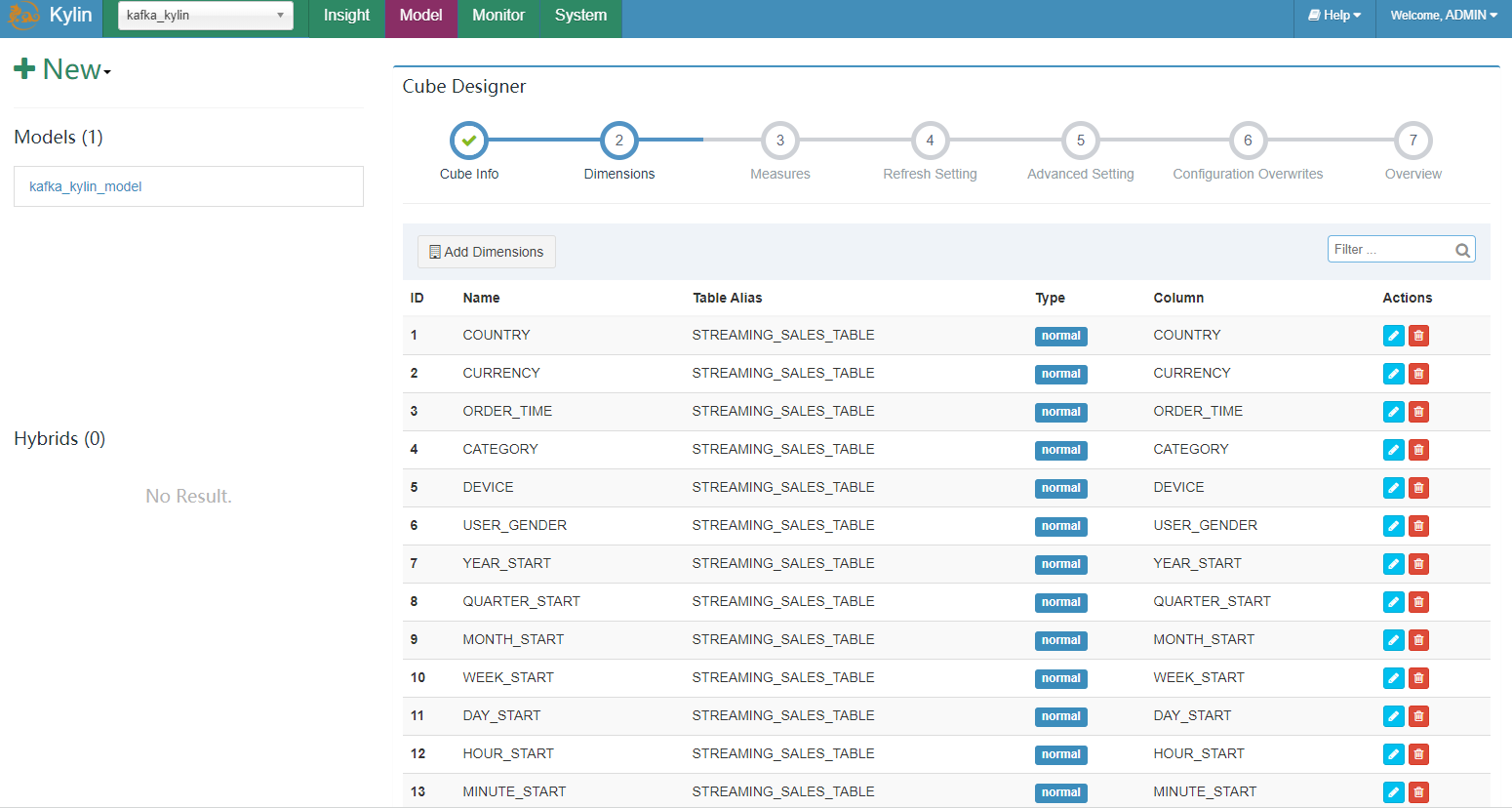
这里我们选择 13 个 dimension 和 2 个 measure 列:

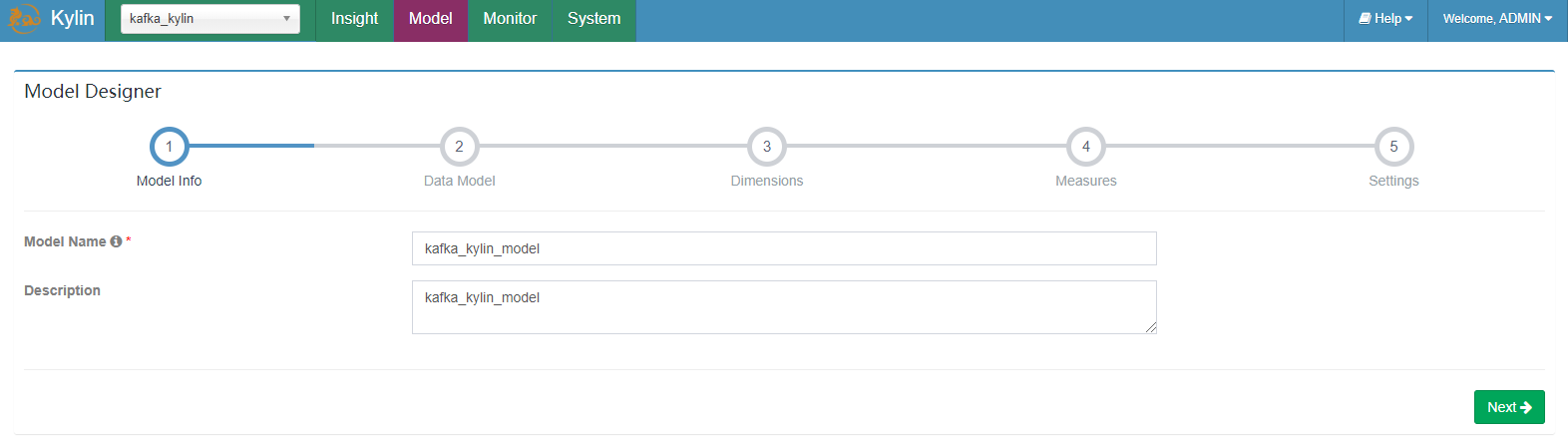
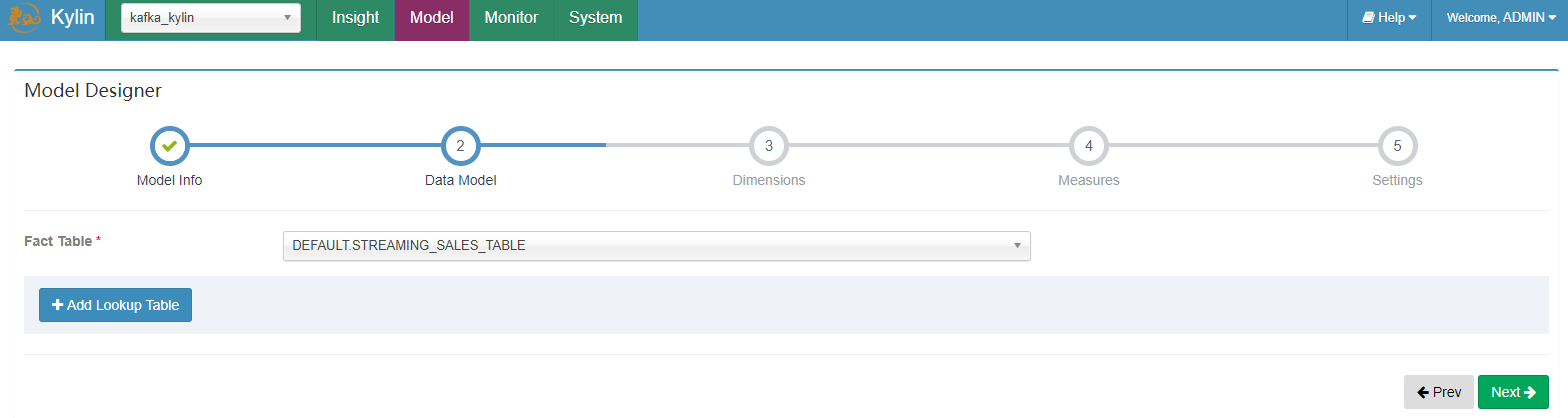

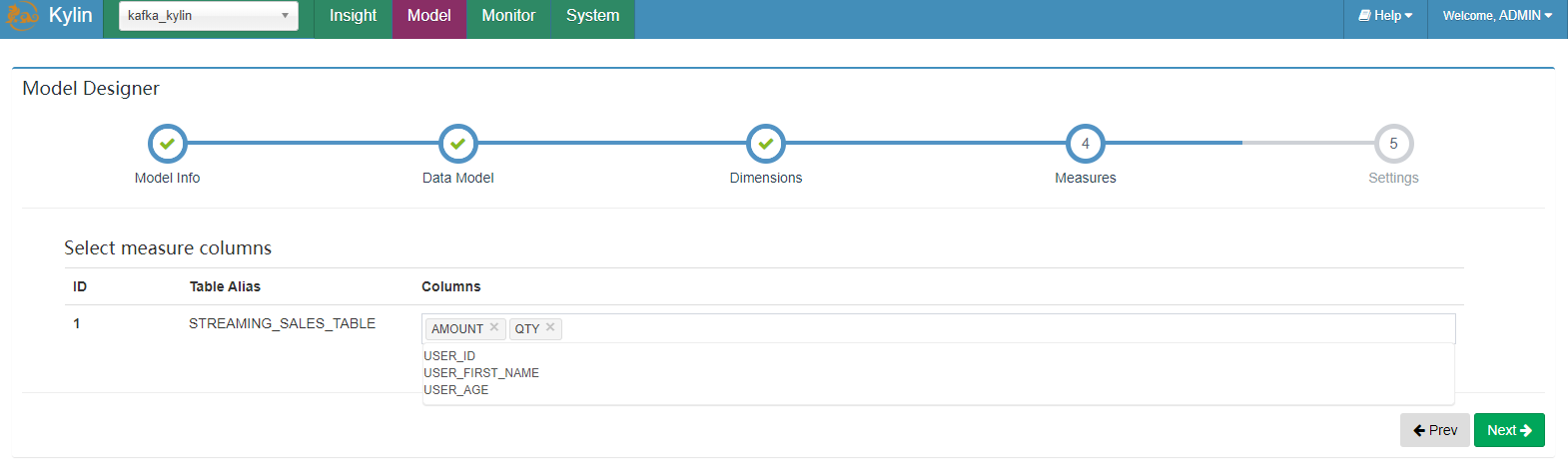
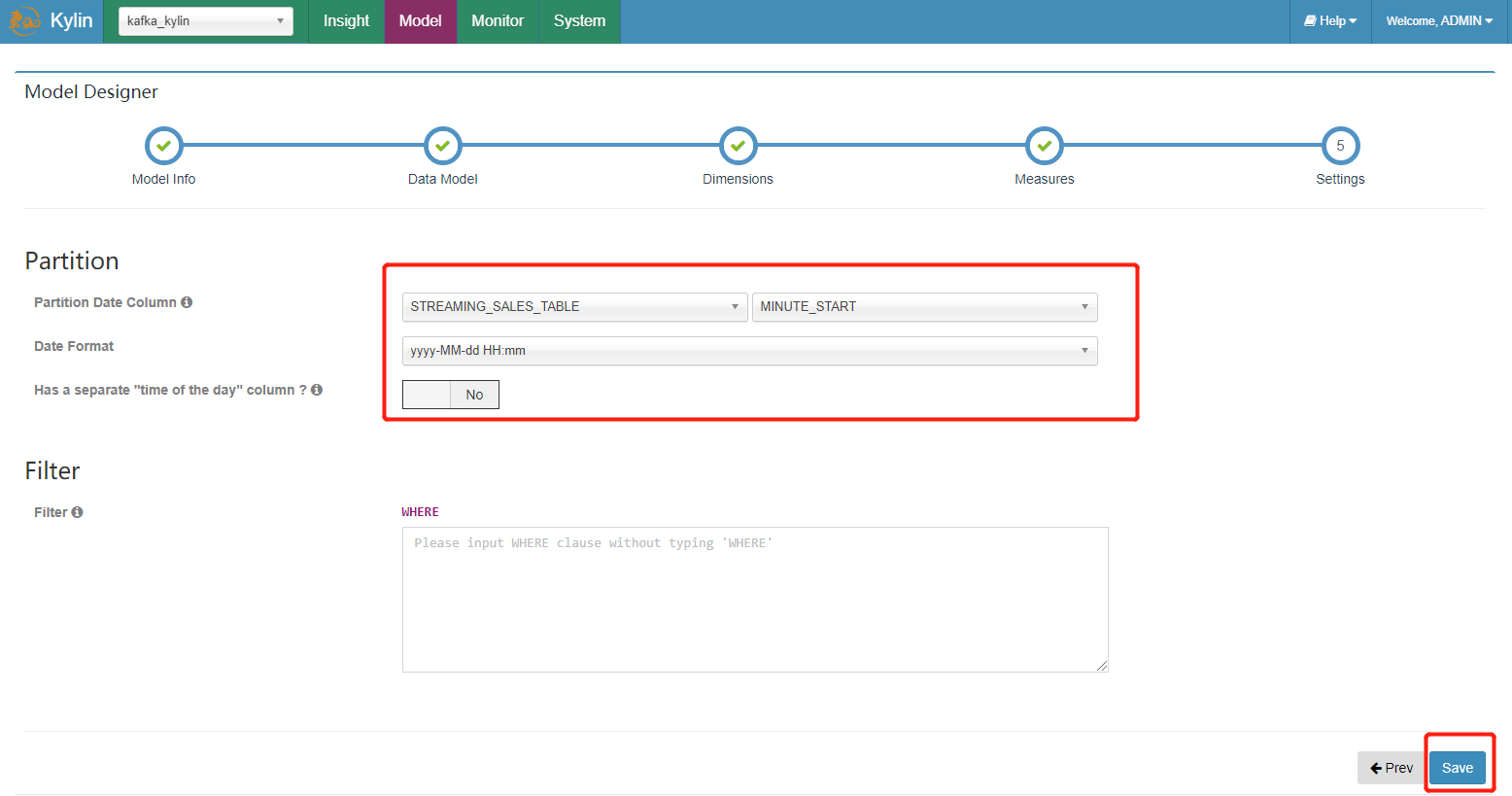
保存数据模型。
14.4 创建 Cube
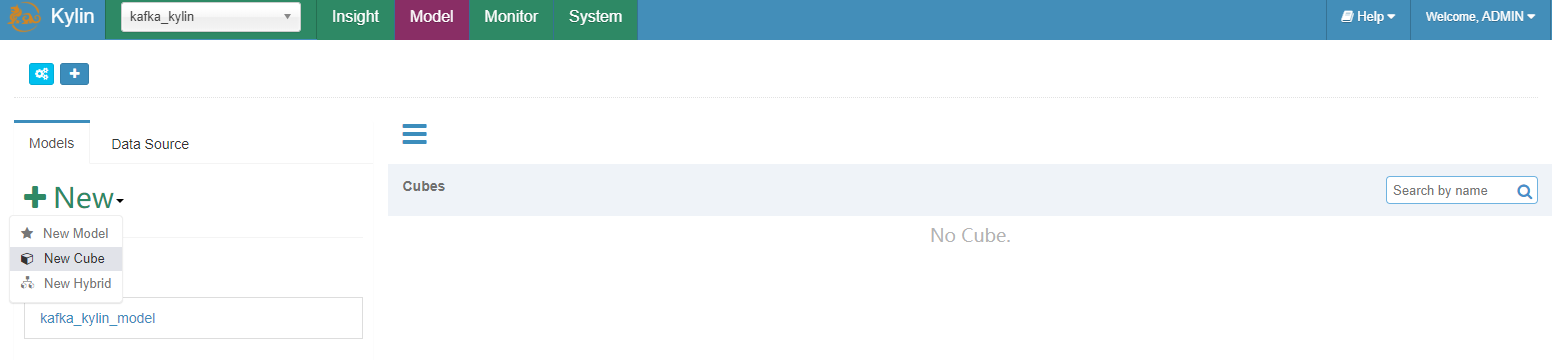
Streaming Cube 和普通的 cube 大致上一样. 有以下几点需要您注意:
- 分区时间列应该是 Cube 的一个 dimension。在 Streaming OLAP 中时间总是一个查询条件,Kylin 利用它来缩小扫描分区的范围。
- 不要使用 “order_time” 作为 dimension 因为它非常的精细;建议使用 “mintue_start”,”hour_start” 或其他,取决于您如何检查数据。
- 定义 “year_start”,”quarter_start”,”month_start”,”day_start”,”hour_start”,”minute_start” 作为层级以减少组合计算。
- 在 “refersh setting” 这一步,创建更多合并的范围,如 0.5 小时,4 小时,1 天,然后是 7 天;这将会帮助您控制 cube segment 的数量。
- 在 “rowkeys” 部分,拖拽 “minute_start” 到最上面的位置,对于 streaming 查询,时间条件会一直显示;将其放到前面将会帮助您缩小扫描范围。
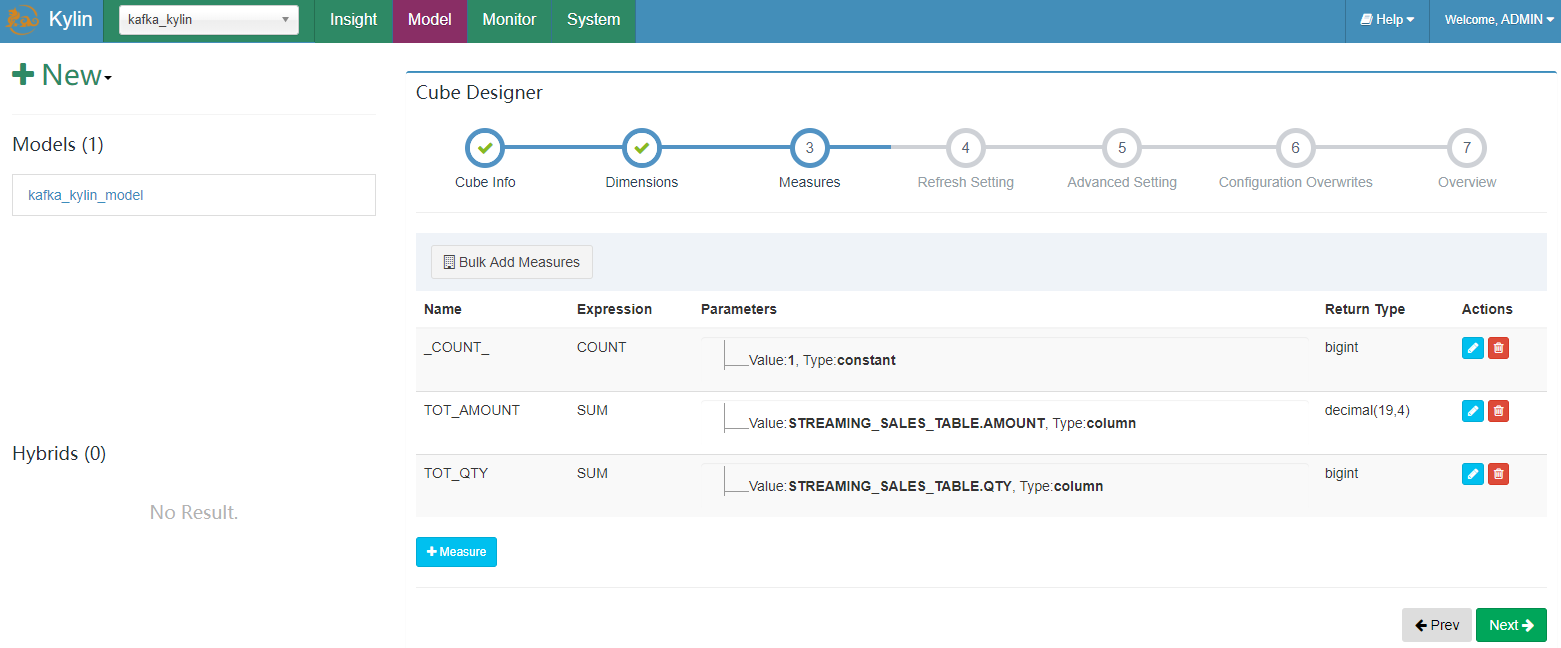
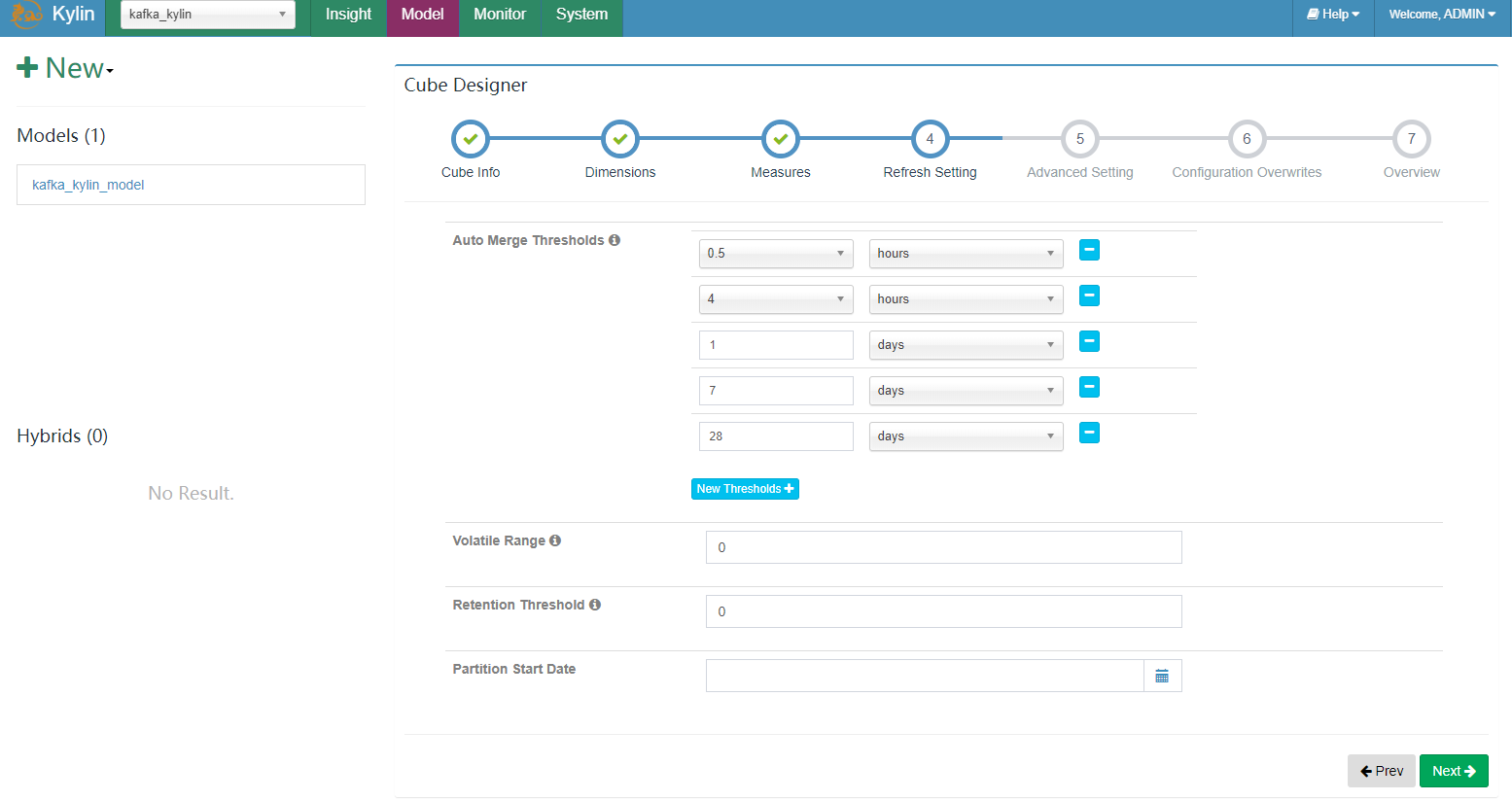
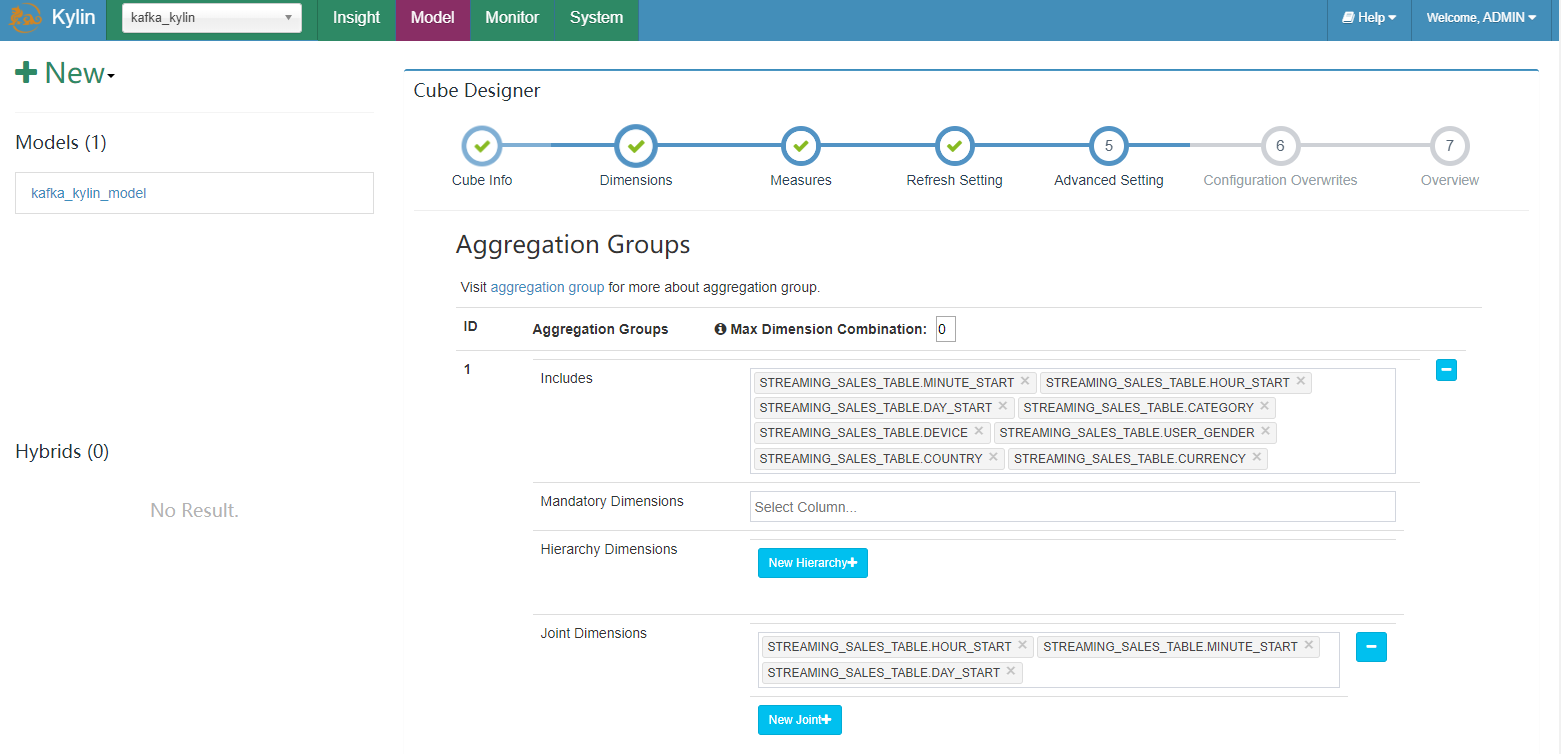
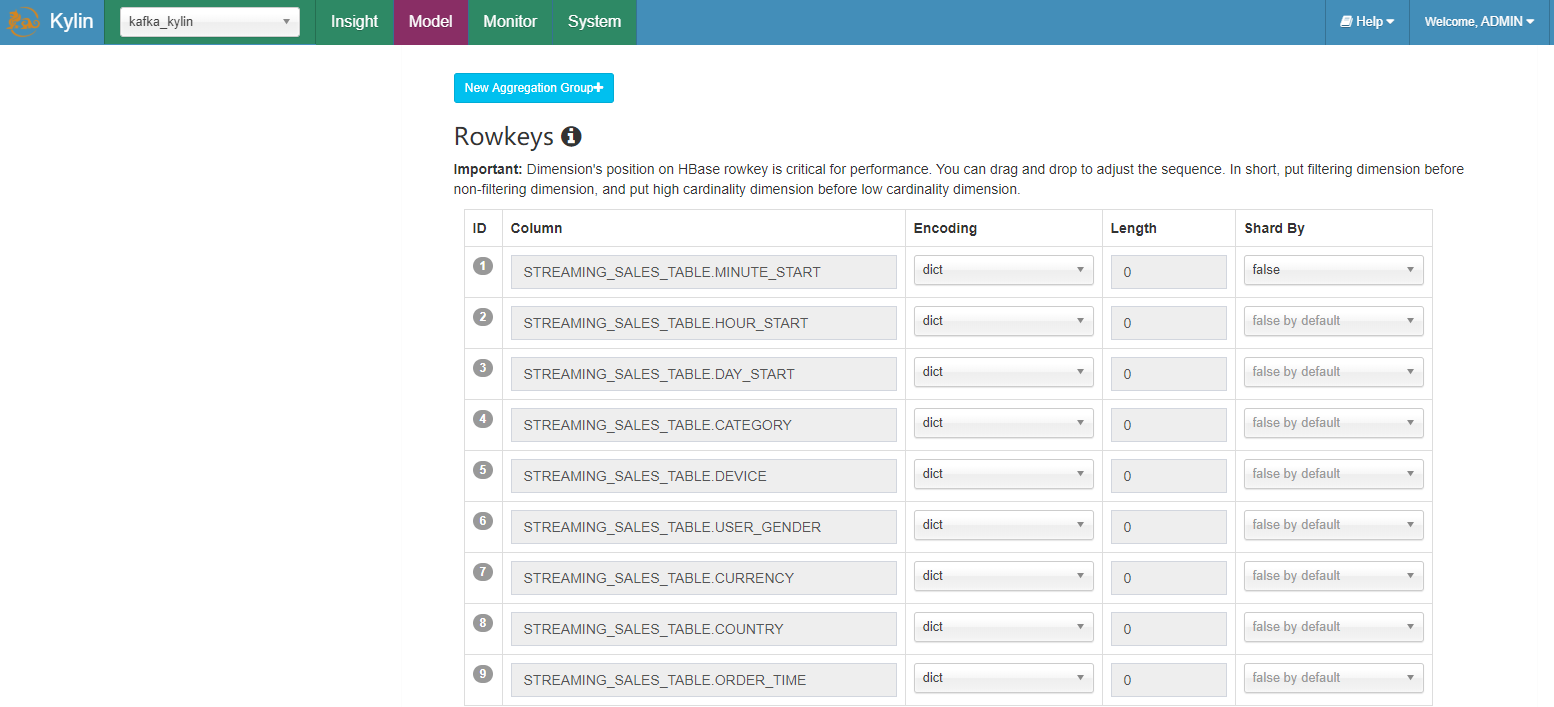
保存 cube。
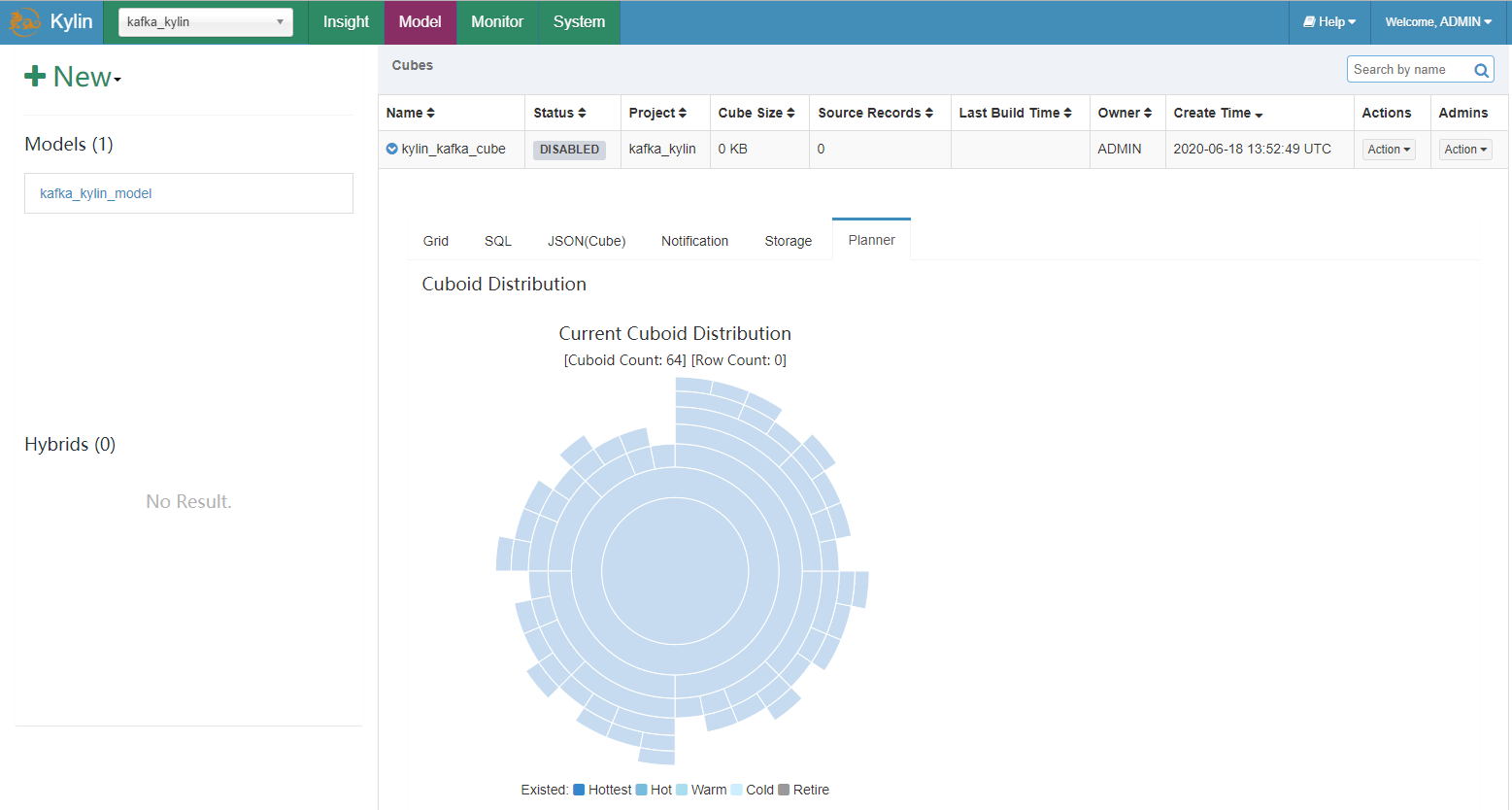
14.5 运行Cube
可以在 web GUI 触发 build,通过点击 “Actions” -> “Build”,或用 ‘curl’ 命令发送一个请求到 Kylin RESTful API:
curl -X PUT --user ADMIN:KYLIN -H "Content-Type: application/json;charset=utf-8" -d '{ "sourceOffsetStart": 0, "sourceOffsetEnd": 9223372036854775807, "buildType": "BUILD"}' http://localhost:7070/kylin/api/cubes/{your_cube_name}/build2
请注意 API 终端和普通 cube 不一样 (这个 URL 以 “build2” 结尾)。
这里的 0 表示从最后一个位置开始,9223372036854775807 (Long 类型的最大值) 表示到 Kafka topic 的结束位置。如果这是第一次 build (没有以前的 segment),Kylin 将会寻找 topics 的开头作为开始位置。
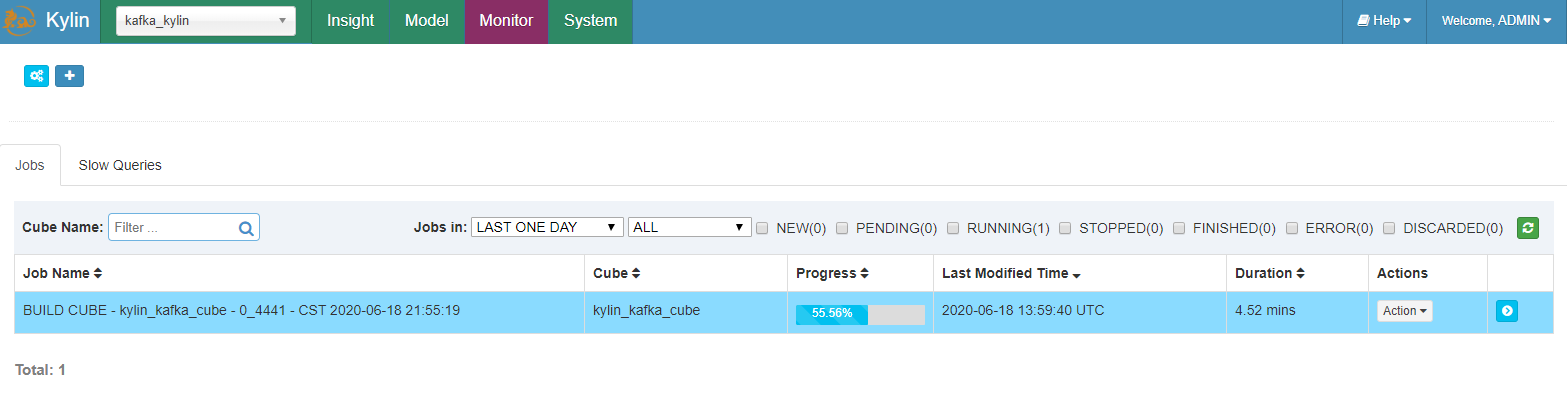
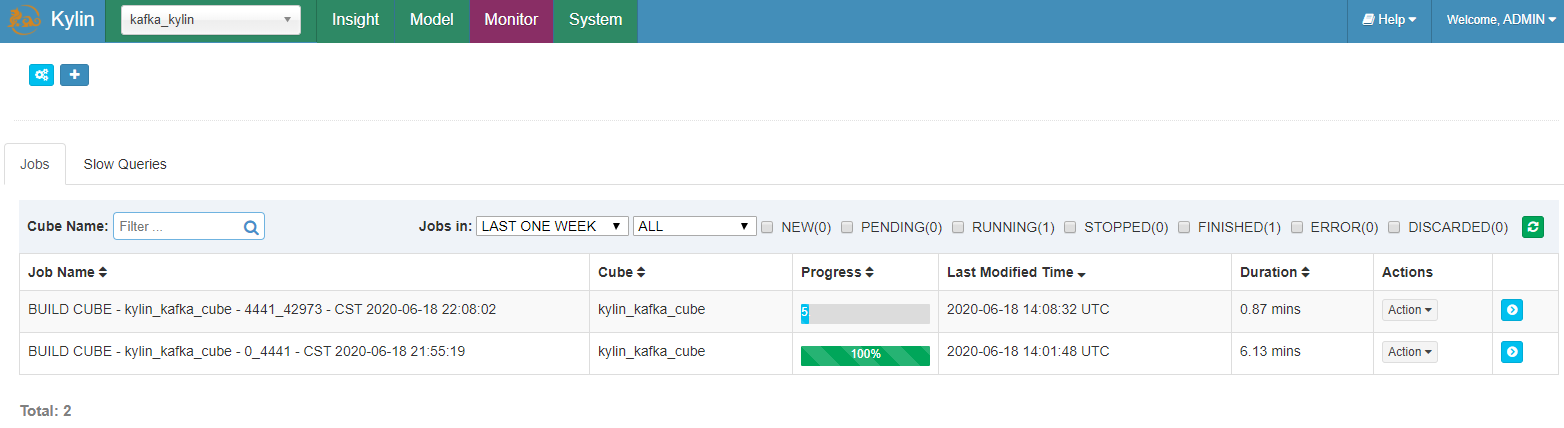
在 “Monitor” 页面,一个新的 job 生成了;等待其直到 100% 完成。
14.6 查看结果
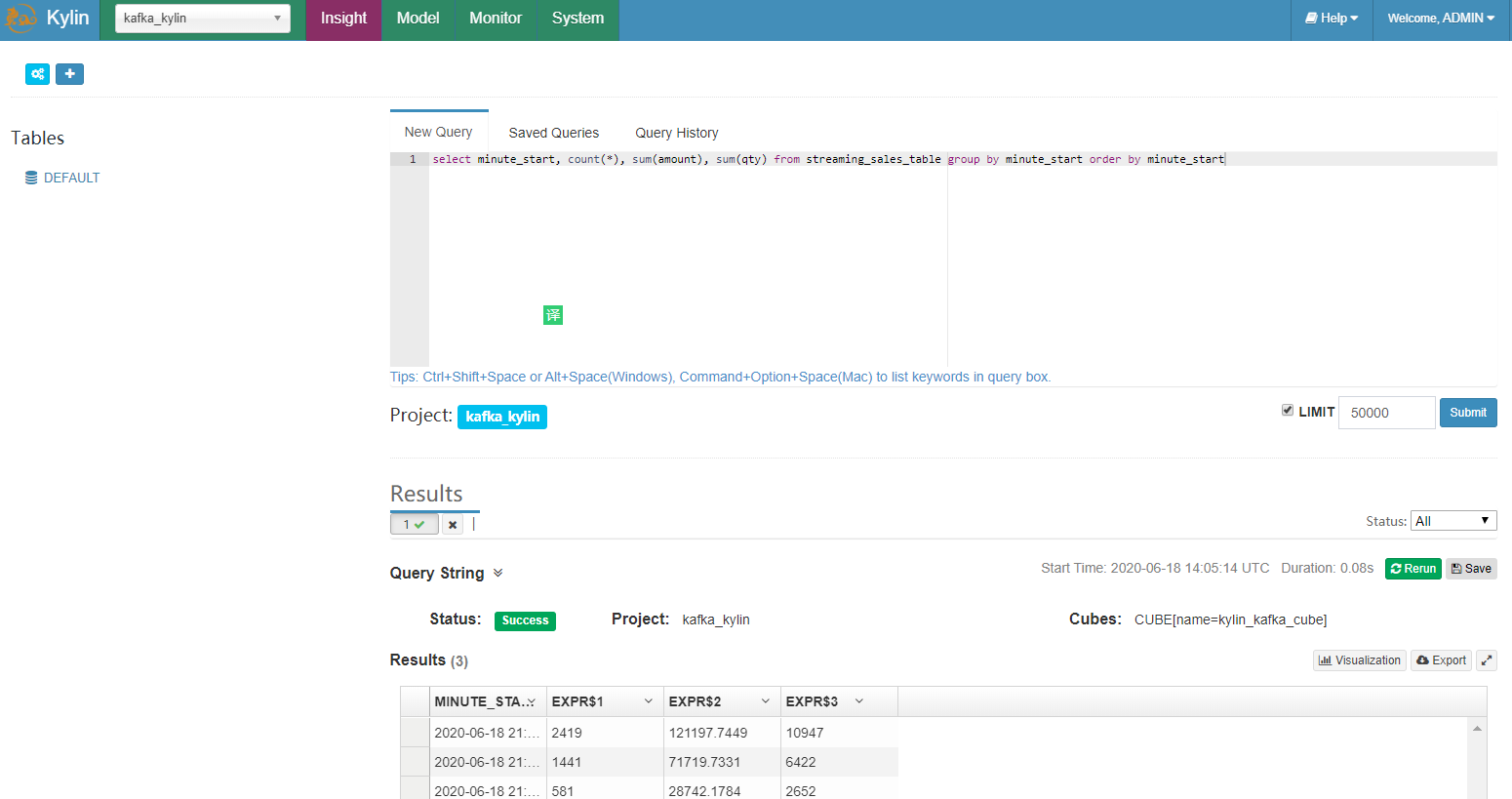
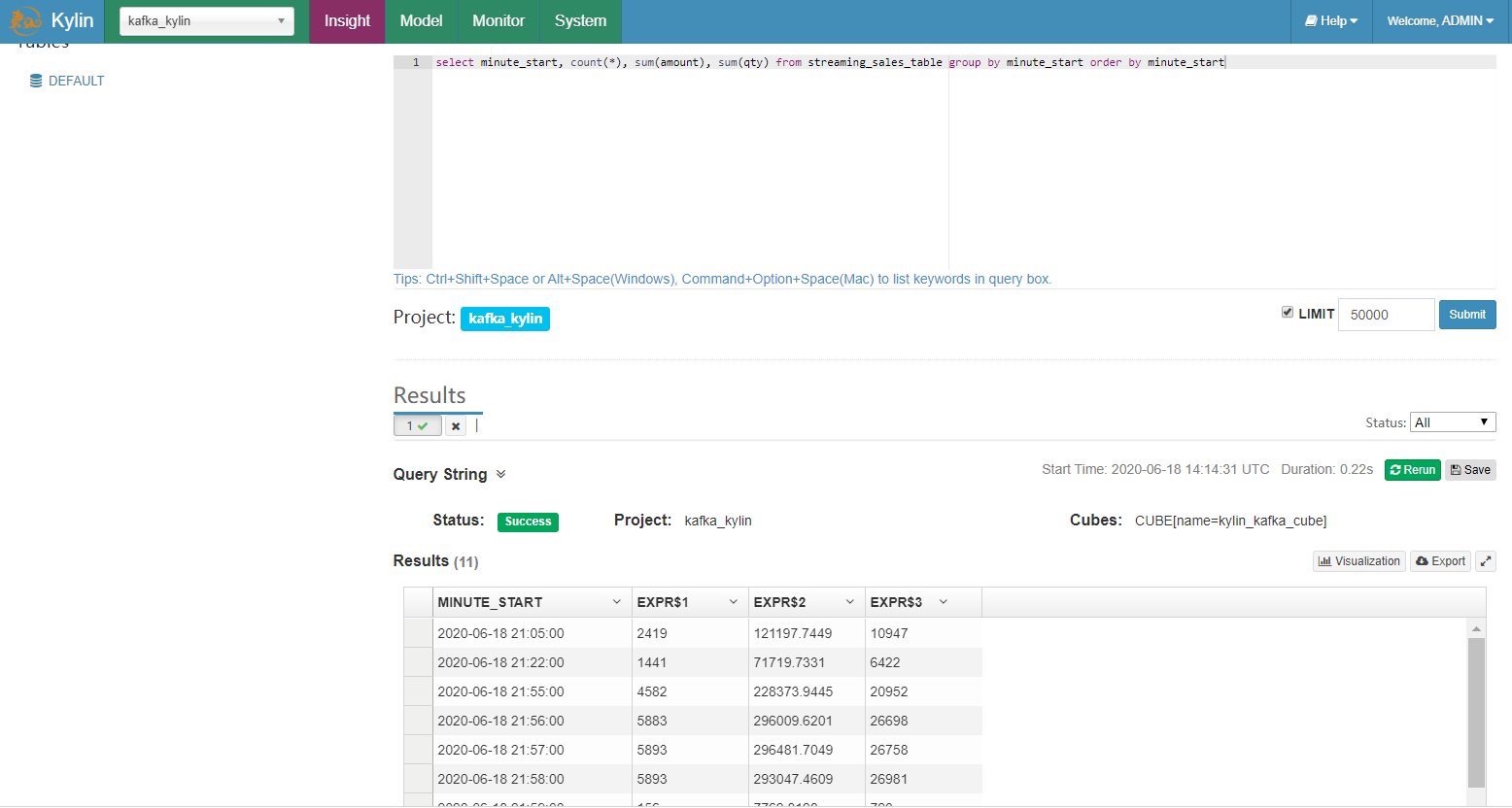
点击 “Insight” 标签,编写 SQL 运行,例如:
select minute_start, count(*), sum(amount), sum(qty) from streaming_sales_table group by minute_start order by minute_start
14.7 自动 build
一旦第一个 build 和查询成功了,您可以按照一定的频率调度增量 build。Kylin 将会记录每一个 build 的 offsets;当收到一个 build 请求,它将会从上一个结束的位置开始,然后从 Kafka 获取最新的 offsets。有了 REST API 您可以使用任何像 Linux cron 调度工具触发它:
crontab -e
*/5 * * * * curl -X PUT --user ADMIN:KYLIN -H "Content-Type: application/json;charset=utf-8" -d '{ "sourceOffsetStart": 0, "sourceOffsetEnd": 9223372036854775807, "buildType": "BUILD"}' http://localhost:7070/kylin/api/cubes/{your_cube_name}/build2
现在您可以观看 cube 从 streaming 中自动 built。当 cube segments 累积到更大的时间范围,Kylin 将会自动的将其合并到一个更大的 segment 中。
15 JDBC查询kylin
- maven依赖
<dependencies>
<dependency>
<groupId>org.apache.kylin</groupId>
<artifactId>kylin-jdbc</artifactId>
<version>3.0.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 限制jdk版本插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
- java类
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class KylinJdbc {
public static void main(String[] args) throws Exception {
//Kylin_JDBC 驱动
String KYLIN_DRIVER = "org.apache.kylin.jdbc.Driver";
//Kylin_URL
String KYLIN_URL = "jdbc:kylin://localhost:9090/kylin_hive";
//Kylin的用户名
String KYLIN_USER = "ADMIN";
//Kylin的密码
String KYLIN_PASSWD = "KYLIN";
//添加驱动信息
Class.forName(KYLIN_DRIVER);
//获取连接
Connection connection = DriverManager.getConnection(KYLIN_URL, KYLIN_USER, KYLIN_PASSWD);
//预编译SQL
PreparedStatement ps = connection.prepareStatement("SELECT sum(sal) FROM emp group by deptno");
//执行查询
ResultSet resultSet = ps.executeQuery();
//遍历打印
while (resultSet.next()) {
System.out.println(resultSet.getInt(1));
}
}
}


您的资助是我最大的动力!
金额随意,欢迎来赏!

