大数据篇:Spark
大数据篇:Spark

- Spark是什么
Spark是一个快速(基于内存),通用,可扩展的计算引擎,采用Scala语言编写。2009年诞生于UC Berkeley(加州大学伯克利分校,CAL的AMP实验室),2010年开源,2013年6月进入Apach孵化器,2014年成为Apach顶级项目,目前有1000+个活跃者。就是说用Spark就对了。
Spark支持Scala,Java,R,Python语言,并提供了几十种(目前80+种)高性能的算法,这些如果让我们自己来做,几乎不可能。
Spark得到众多公司支持,如:阿里、腾讯、京东、携程、百度、优酷、土豆、IBM、Cloudera、Hortonworks等。
- 如果没有Spark
解决MapReduce慢的问题而诞生,官网解释比同样的MapReduce任务快100倍!
1 内置模块
机器学习(MLlib),图计算(GraphicX),实时处理(SparkStreaming),SQL解析(SparkSql)

1.1 集群资源管理
Spark设计为可以高效的在一个计算节点到数千个计算节点之间伸缩计算,为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群资源管理器上运行,目前支持的3种如下:(上图中下三个)
- Hadoop YARN(国内几乎都用)
- Apach Mesos(国外使用较多)
- Standalone(Spark自带的资源调度器,需要在集群中的每台节点上配置Spark)
1.2 Spark Core
实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。其中还包含了对弹性分布式数据集(RDD:Resilient Distributed DataSet)的API定义
1.3 Spark SQL
是Spark用来操作结构化数据的程序包,通过Spark SQL 我们可以使用SQL或者HQL来查询数据。且支持多种数据源:Hive、Parquet、Json等
1.4 Spark Streaming
是Spark提供的对实时数据进行流式计算的组件
1.5 Spark MLlib
提供常见的机器学习功能和程序库,包括分类、回归、聚类、协同过滤等。还提供了模型评估、数据导入等额外的支持功能。
2 运行模式
2.1 核心概念介绍
-
Master
- Spark特有的资源调度系统Leader,掌控整个集群资源信息,类似于Yarn框架中的ResourceManager
- 监听Worker,看Worker是否正常工作
- Master对Worker、Application等的管理(接收Worker的注册并管理所有的Worker,接收Client提交的Application,调度等待Application并向Worker提交)
-
Worker
- Spark特有的资源调度Slave,有多个,每个Slave掌管着所有节点的资源信息,类似Yarn框架中的NodeManager
- 通过RegisterWorker注册到Master
- 定时发送心跳给Master
- 根据Master发送的Application配置进程环境,并启动ExecutorBackend(执行Task所需的进程)
-
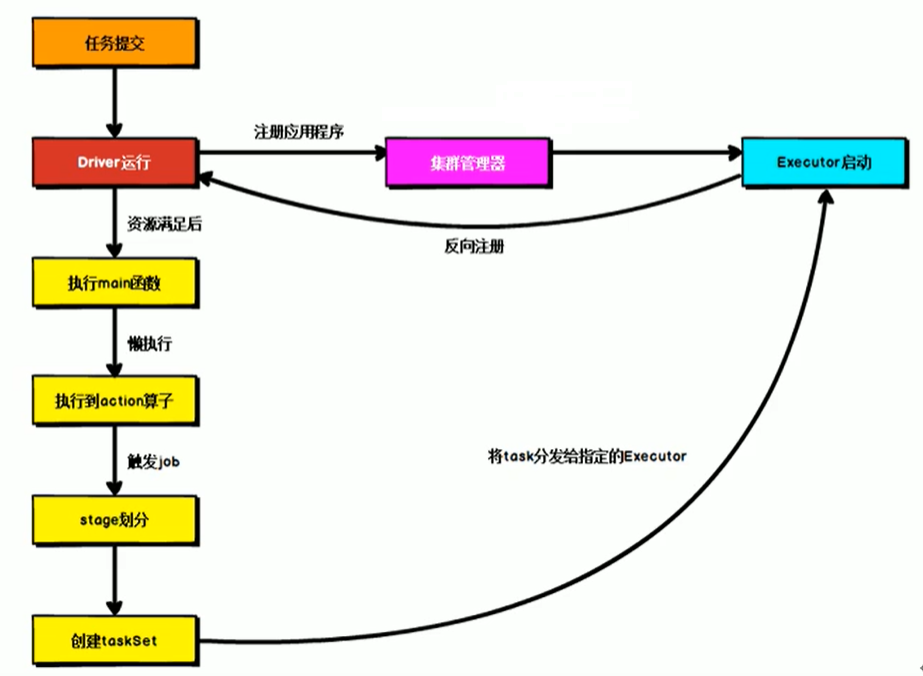
Driver
- Spark的驱动器,是执行开发程序中的main方法的线程
- 负责开发人员编写SparkContext、RDD,以及进行RDD操作的代码执行,如果使用Spark Shell,那么启动时后台自启动了一个Spark驱动器,预加载一个叫做sc的SparkContext对象,如果驱动器终止,那么Spark应用也就结束了。
- 4大主要职责:
- 将用户程序转化为作业(Job)
- 在Executor之间调度任务(Task)
- 跟踪Executor的执行情况
- 通过UI展示查询运行情况
-
Excutor
- Spark Executor是一个工作节点,负责在Spark作业中运行任务,任务间相互独立。Spark应用启动时,Executor节点被同时启动,并且始终伴随着整个Spark应用的生命周期而存在,如果有Executor节点发生了故障或崩溃,Spark应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行
- 两个核心功能:
- 负责运行组成Spark应用的任务,并将结果返回给驱动器(Driver)
- 它通过自身块管理器(BlockManager)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
-
RDDs
- Resilient Distributed DataSet:弹性分布式数据集
- 一旦拥有SparkContext对象,就可以用它来创建RDD
-
通用流程图
2.2 WordCount案例
- Spark Shell方式
#创建word.txt文件
vim word.txt
#--->
hadoop hello spark
spark word
hello hadoop spark
#---<
#上传HDFS集群
hadoop dfs -put word.txt /
#链接客户端
spark-shell
sc.textFile("/word.txt").flatMap(line => line.split(' ')).map((_,1)).reduceByKey(_ + _).collect

每个Spark应用程序都包含一个驱动程序,驱动程序负责把并行操作发布到集群上,驱动程序包含Spark应用中的主函数,定义了分布式数据集以应用在集群中,在前面的wordcount案例中,spark-shell就是我们的驱动程序,所以我们键入我们任何想要的操作,然后由它负责发布,驱动程序通过SparkContext对象来访问Spark,SparkContext对象相当于一个到Spark集群的链接
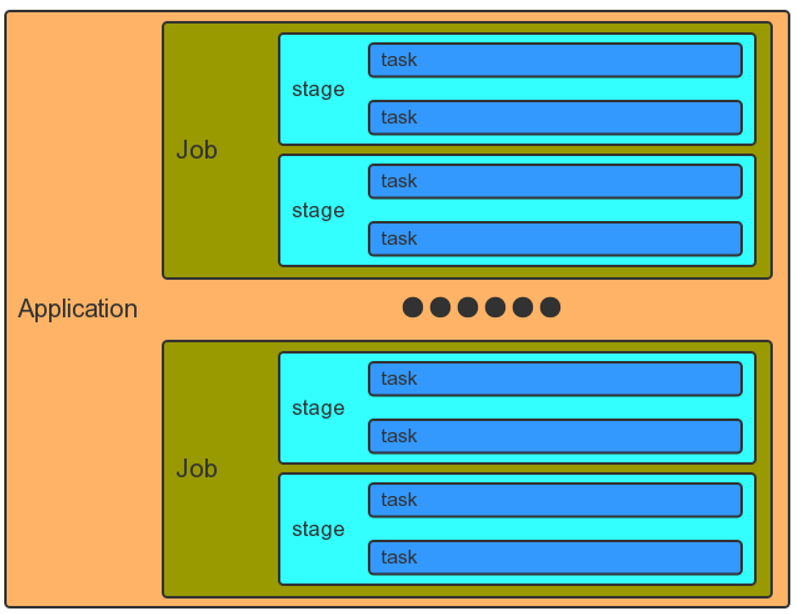
2.3 Job划分和调度
- Application应用
- 一个SparkContext就是一个Application
- Job作业:
- 一个行动算子(Action)就是一个Job
- Stage阶段:
- 一次宽依赖(一次shuffle)就是一个Stage,划分是从后往前划分
- Task任务:
- 一个核心就是一个Task,体现任务的并行度,常常根据核心数的1.5倍进行设置
- 使用WordCount案例分析
一个行动算子collect(),一个job

一次宽依赖shuffle算子reduceByKey(),切分成2个Stage阶段
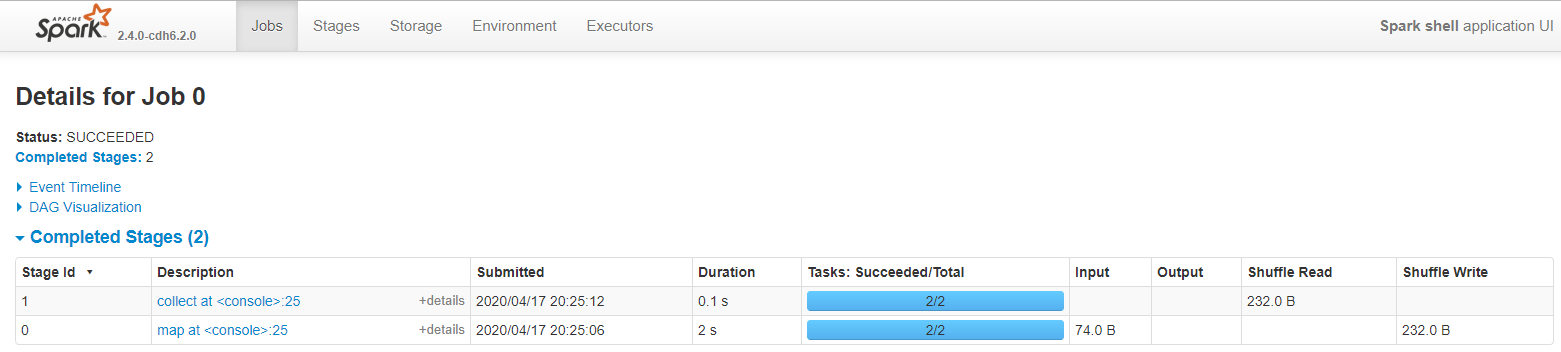
Stage阶段,默认文件被切分成2份,所以有2个task
Stage阶段0
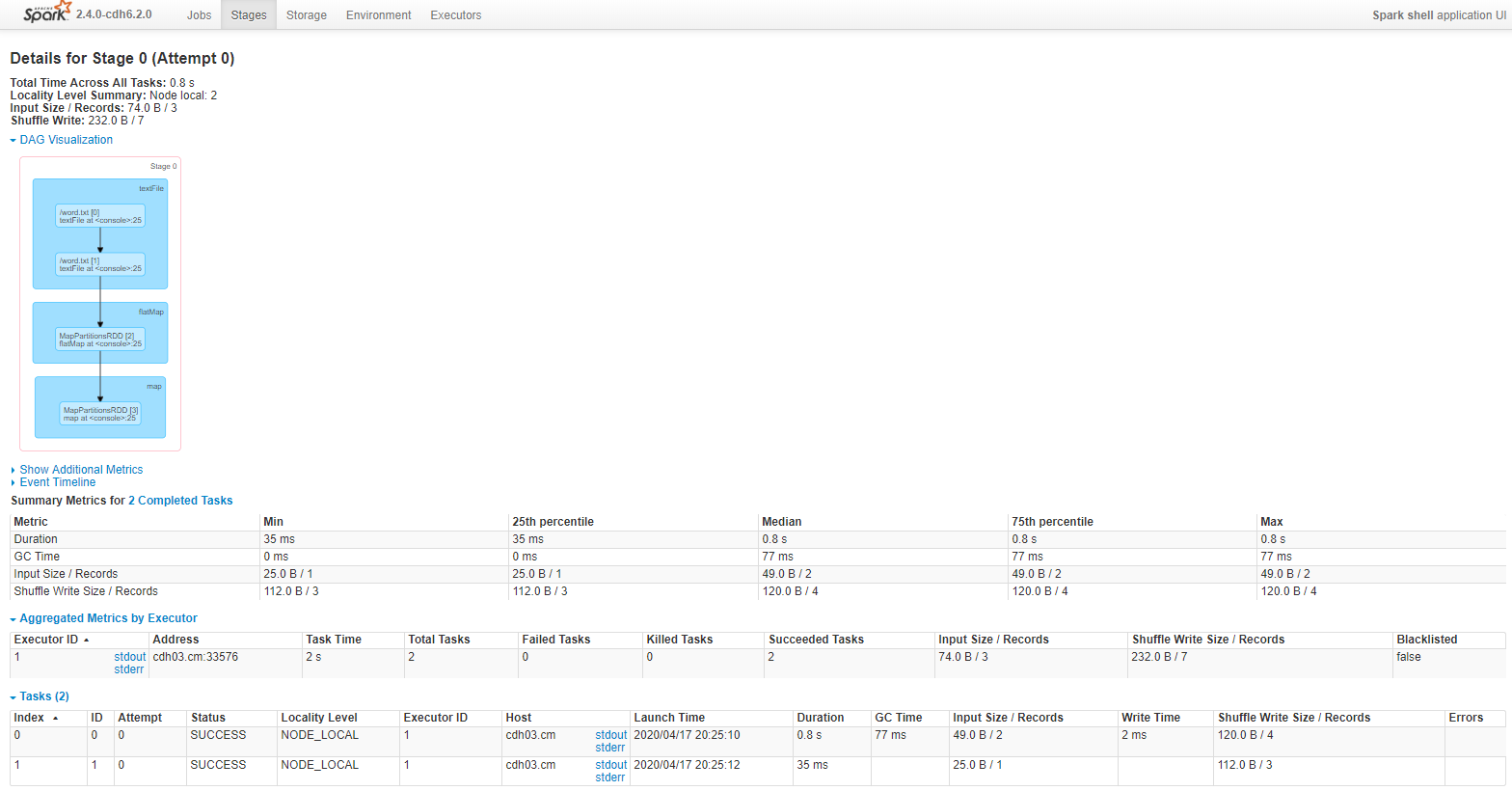
Stage阶段1
2.4 Shuffle洗牌
2.4.1 ShuffleMapStage And ResultStage
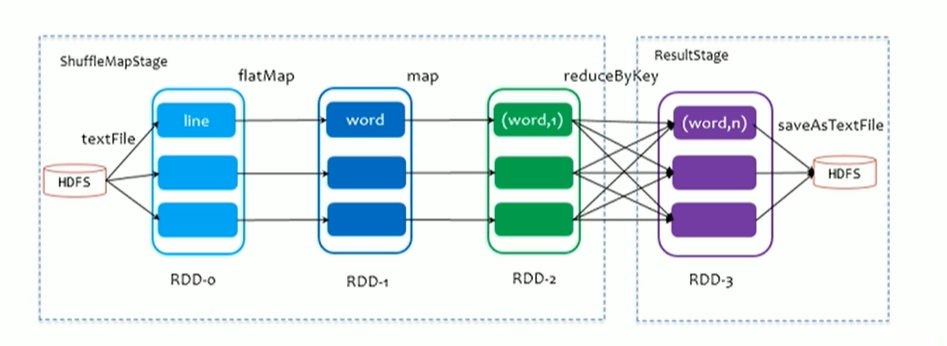
-
在划分stage时,最后一个stage称为FinalStage,本质上是一个ResultStage对象,前面所有的stage被称为ShuffleMapStage
-
ShuffleMapStage 的结束伴随着shuffle文件写磁盘
-
ResultStage对应代码中的action算子,即将一个函数应用在RDD的各个Partition(分区)的数据集上,意味着一个Job运行结束
2.4.2 HashShuffle
- 未优化HashShuffle流程图:目前已经没有了
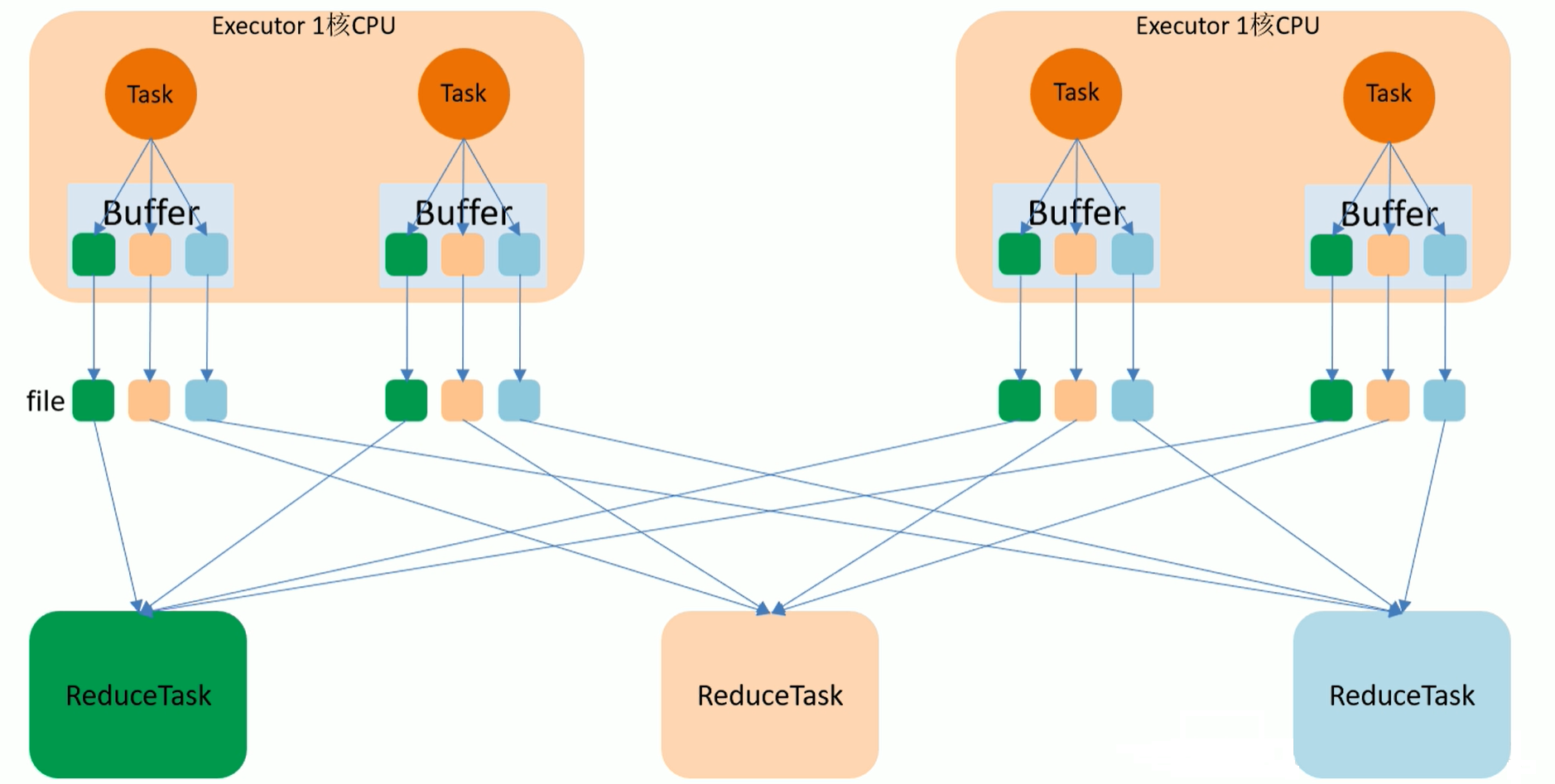
如上图,最终结果会有12个小文件
- 优化后HashShuffle流程图
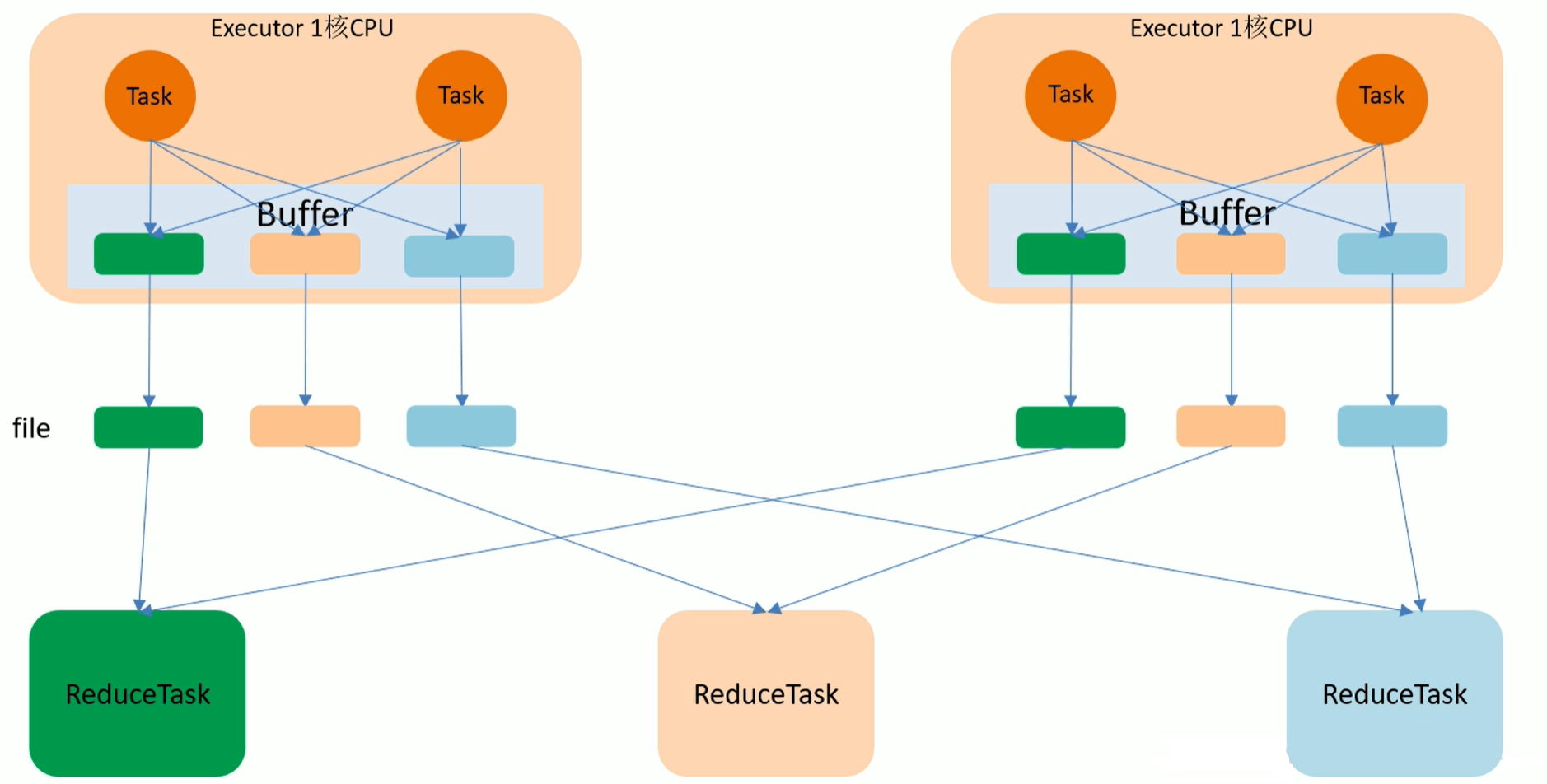
如上图,最终结果会有6个小文件,比未优化前少了一半
2.4.3 SortShuffle
该模式下,数据会先写入一个数据结果,reduceByKey写入Map,一边通过Map局部聚合,一边写入内存,
Join算子写入ArrayList直接写入内存中,然后需要判断是否达到阀值,如果达到就会将内存数据写入磁盘,释放内存资源
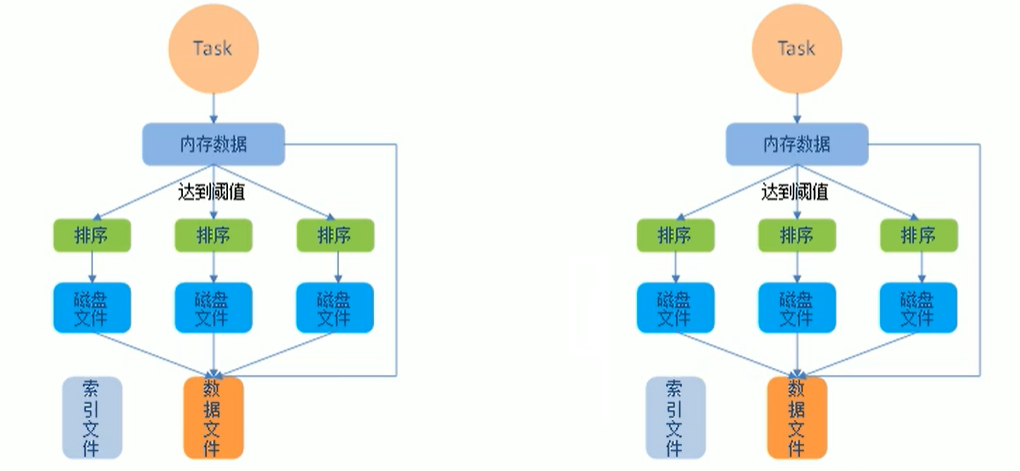
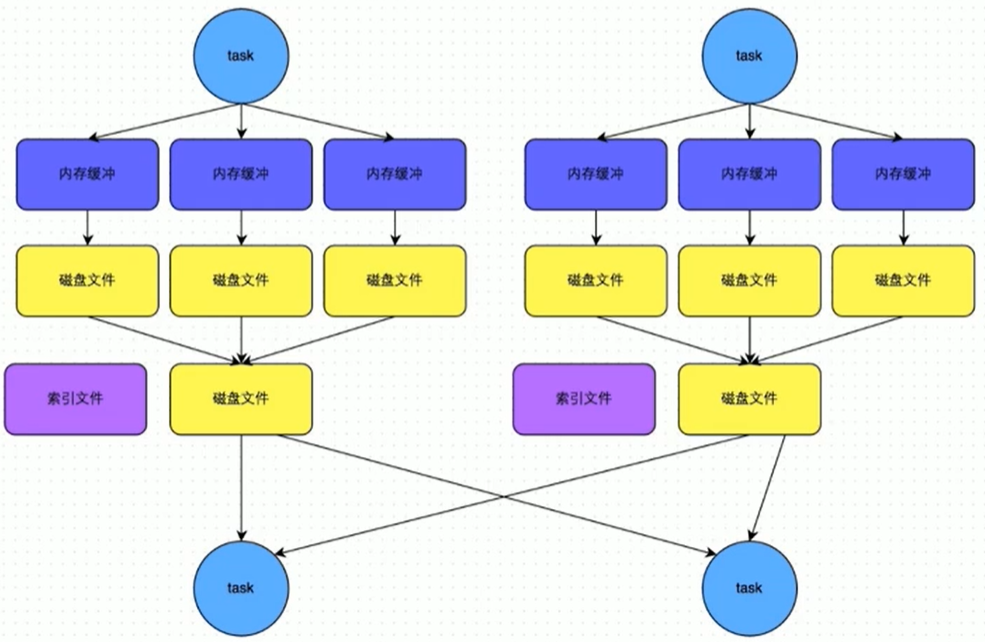
2.4.4 Bypass SortShuffle
- Bypass SortShuffle运行机制触发条件
- shuffle map task 数量小于 spark.shuffle.sort.bypassMargeThreshold参数的值,默认为200
- 不是聚合类的shuffle算子
2.5 Submit语法
spark-submit \
--class <main-calss> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... #其他 options
<application-jar> \
[application-arguments]
- --class:应用启动类全类名(如:org.apache.spark.examples.SparkPi)
- --master:指定master地址,默认本机Local(本地一般使用Local[*],集群一般使用yarn)
- --deploy-mode:是否发布到驱动worker节点(参数:cluster),或者作为一个本地客户端(参数:client),默认本地client
- --conf:任意Spark配置属性,格式key=value,如包含空格,可以加引号"key=value"
- application-jar:打包好的应用程序jar,包含依赖,这个URL在集群中全局课件,如HDFS上的jar->hdfs://path;如linux上的jar->file://path 且所有节点路径都需要包含这个jar
- application-arguments:给main()方法传参数
- --executor-memory 1G:指定每个executor可用内存为1G
- --total-executor-cores 6:指定所有executor使用的cpu核数为6个
- --executor-cores 2:表示每个executor使用的cpu的核数2个
2.6 Local模式
Local模式就是在一台计算机上运行Spark,通常用于开发中。(单机)
- Submit提交方式
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[*] \
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark/examples/jars/spark-examples_2.11-2.4.0-cdh6.2.0.jar 100

2.7 Standalone模式
构建一个由 Master + Slave 构成的Spark集群,Spark运行在集群中,只依赖Spark,不依赖别的组件(如:Yarn)。(独立的Spark集群)
#链接客户端
spark-shell --master spark://cdh01.cm:7337
参考wordCount案例
- Standalone-Client流程图
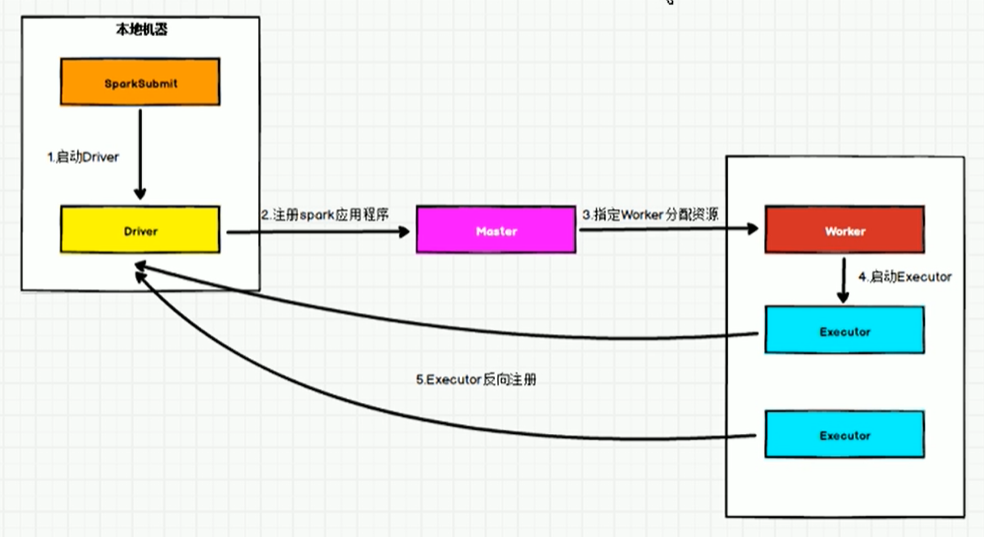
- Standalone-Cluster流程图

2.8 Yarn模式
Spark客户端可以直接连接Yarn,不需要构建Spark集群。
有yarn-client和yarn-cluster两种模式,主要区别在:Driver程序的运行节点不同。
yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看见APP输出
yarn-cluster:Driver程序运行在由ResourceManager启动的ApplicationMaster上,适用于生产环境
- Yarn-Client流程图

- Yarn-Cluster流程图
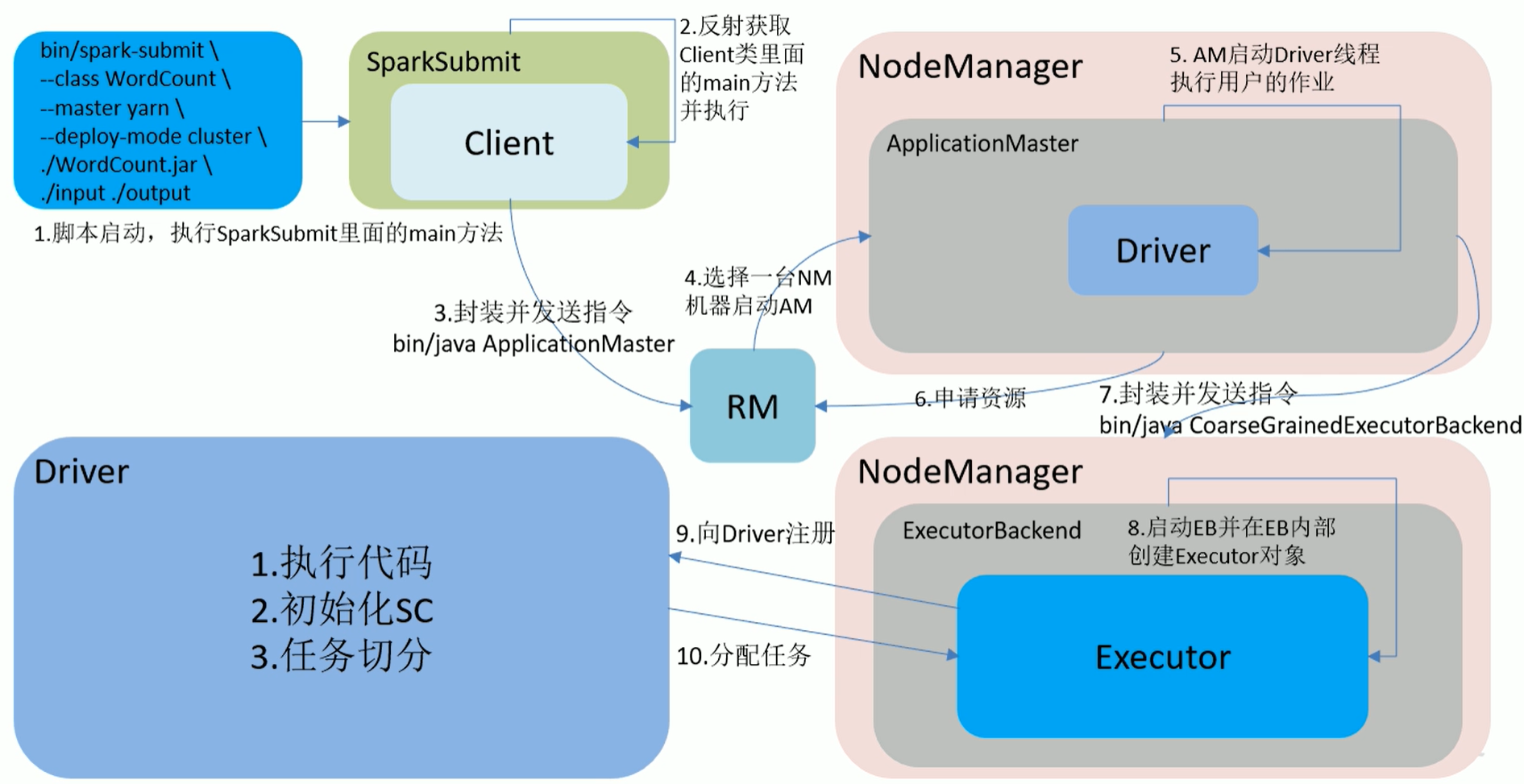
- 客户端模式:Driver是在Client端,日志结果可以直接在后台看见
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark/examples/jars/spark-examples_2.11-2.4.0-cdh6.2.0.jar 100
- 集群模式:Driver是在NodeManager端,日志结果需要通过监控日志查看
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark/examples/jars/spark-examples_2.11-2.4.0-cdh6.2.0.jar 100
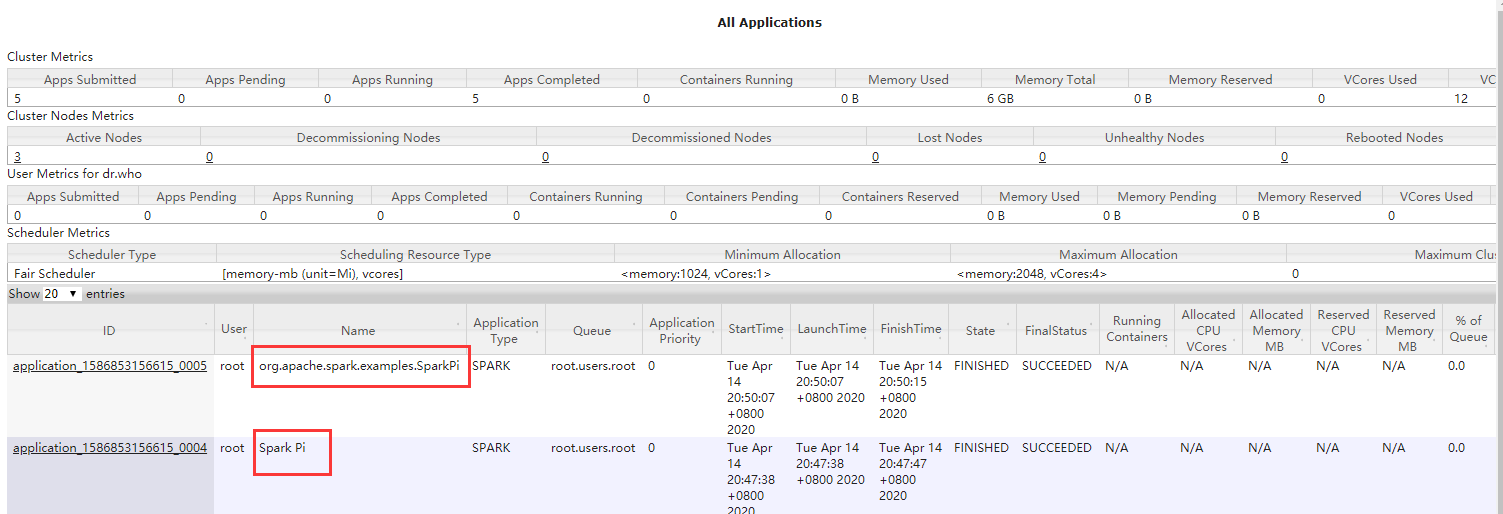
3 使用IDEA开发Spark
- pom.xml
<dependencies>
<!-- scala -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>2.11.12</version>
</dependency>
<!-- Spark Core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<!-- Spark SQL -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<!-- Spark On Hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<!-- Hbase On Spark-->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-spark</artifactId>
<version>2.1.0-cdh6.2.0</version>
</dependency>
<!-- Spark Streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<!-- Spark Streaming Kafka-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<!-- Kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-tools</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-examples</artifactId>
<version>2.1.0</version>
</dependency>
<!--mysql依赖的jar包-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<build>
<plugins>
<!-- 在maven项目中既有java又有scala代码时配置 maven-scala-plugin 插件打包时可以将两类代码一起打包 -->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<!-- MAVEN 编译使用的JDK版本 -->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.3</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<phase>package</phase><!--绑定到package生命周期阶段-->
<goals>
<goal>single</goal><!--只运行一次-->
</goals>
</execution>
</executions>
<configuration>
<!--<finalName></finalName><!–主类入口–>-->
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.10</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
-
WorkCount案例
- 在resources文件夹下,新建word.csv文件
hello,spark hello,scala,hadoop hello,hdfs hello,spark,hadoop hello- WorkCount.scala
import org.apache.spark.{SparkConf, SparkContext} object WorkCount { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("WorkCount").setMaster("local[*]") val sc = new SparkContext(conf) val tuples: Array[(String, Int)] = sc.textFile(ClassLoader.getSystemResource("word.csv").getPath) .flatMap(_.split(",")) .map((_, 1)) .reduceByKey(_ + _) .collect() tuples.foreach(println) } }结果:
(scala,1)
(hello,5)
(spark,2)
(hadoop,2)
(hdfs,1)
4 Spark Core
4.1 什么是RDD
Resilient Distributed DataSet:弹性分布式数据集,是Spark中最基本数据抽象,可以理解为数据集合。
在代码中是一个抽象类,它代表一个弹性的、不可变的、可分区,里面的元素可并行计算的集合。
4.2 RDD的五个主要特性
- 分区性
- 多个分区,分区可以看成是数据集的基本组成单位
- 对于RDD来说,每个分区都会被一个计算任务处理,并决定了并行计算的粒度。
- 用户可以在创建RDD时,指定RDD的分区数,如果没有指定,那么采用默认值(程序所分配到的CPU Coure的数目)
- 每个分配的储存是由BlockManager实现的,每个分区都会被逻辑映射成BlockManager的一个Block,而这个Block会被一个Task负责计算。
- 计算每个分区的函数
- Spark中RDD的计算是以分区为单位的,每个RDD都会实现compute函数以达到这个目的
- 依赖性
- RDD的每次转换都会生成一个新的RDD,所以RDD之间会形成类似于流水线一样的前后依赖关系,在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
- 对储存键值对的RDD,还有一个可选的分区器
- 只有对key-value的RDD,才会有Partitioner,非key-value的RDD的Rartitioner的值是None
- Partitioner不但决定了RDD的分区数量,也决定了parent RDD Shuffle输出时的分区数量
- 默认是HashPartitioner,还有RangePartition,自定义分区
- 储存每个分区优先位置的列表(本地计算性)
- 比如对于一个HDFS文件来说,这个列表保存的就是每个Partition所在文件快的位置,按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的储存位置。
4.3 Transformation和Action算子
在Spark中,Transformation算子(也称转换算子),在没有Action算子(也称行动算子)去触发的时候,是不会执行的,可以理解为懒算子,而Action算子可以理解为触发算子,常用Action算子如下:
- redece:通过函数聚集RDD的所有元素,先聚合分区内的数据,在聚合分区间的数据(预聚合)
- collect:以数组的形式返回RDD中的所有元素,所有数据都会被拉到Driver端,内存开销很大,所以慎用
- count:返回RDD中元素个数
- take:返回RDD中前N个元素组成的数组
- first:返回RDD中的第一个元素,类似于tack(1)
- takeOrdered:返回排序后的前N个元素,默认升序,数据也会拉到Driver端
- aggregate:分区内聚合后,在分区间聚合
- fold:aggregate简化操作,如果分区内和分区间算法一样,则可以使用
- saveAsTextFile:将数据集的元素以textFile的形式保存到HDFS文件系统或者其他文件系统,对每个元素,Spark都会调用toString方法转换为文本
- saveAsSequenceFile:将数据集的元素以Hadoop SquenceFile的形式保存到指定目录下,可以是HDFS或者其他文件系统
- saveAsObjectFile:将RDD中的元素序列化成对象,储存到文件中
- countByKey:针对k-v类型RDD,返回一个Map(Key,count),可以用来查看数据是否倾斜
- foreach:针对RDD中的每一个元素都执行一次函数,每个函数实在Executor上执行的
常用Transformation算子如下:
- map:输入变换函数应用于RDD中所有元素,转换其类型
- mapPartitions:输入变换函数应用于每个分区中所有元素
- mapPartitionsWithIndex:输入变换函数应用于每个分区中所有元素,带有分区号
- filter:过滤算子
- flatMap:扁平化算子
- sample:抽样算子
- union:并集算子
- intersection:交集算子
- distinct:去重算子
- groupByKey:根据Key分组算子
- reduceByKey:根据Key聚合算子
- aggregateByKey:根据Key聚合算子
- sortByKey:根据Key排序算子
- join:链接算子
- coalesce:压缩分区算子
- repartition:重分区算子
4.4 RDD的创建
4.4.1 从集合中创建
object Demo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WorkCount").setMaster("local[*]")
val sc = new SparkContext(conf)
/**
* 通过parallelize方法传入序列得到RDD
* 传入分区数为1,结果为1 2 3 4 5 6 7 8 9 10
* 传入分区数大于1,结果顺序不定,因为数据被打散在2个分区里
* */
val rdd: RDD[Int] = sc.parallelize(1.to(10), 1)
rdd.foreach(x => print(x + "\t"))
}
}
4.4.2 从外部储存创建RDD
- 读取textFile
WordCount案例介绍了此种用法
- 读取Json文件
在idea中,resources目录下创建word.json文件
{"name": "zhangsa"}
{"name": "lisi", "age": 30}
{"name": "wangwu"}
["aa","bb"]
object Demo0 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("json").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.textFile(this.getClass().getClassLoader.getResource("word.json").getPath)
val rdd2: RDD[Option[Any]] = rdd1.map(JSON.parseFull(_))
rdd2.foreach(println)
/**
* Some(Map(name -> zhangsa))
* Some(Map(name -> wangwu))
* Some(List(aa, bb))
* Some(Map(name -> lisi, age -> 30.0))
* */
}
}
- 读取Object对象文件
object Demo1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("object").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1,2,3,4,5))
// rdd1.saveAsObjectFile("hdfs://cdh01.cm/test")
val rdd2: RDD[Nothing] = sc.objectFile("hdfs://cdh01.cm/test")
rdd2.foreach(println)
/**
* 2
* 5
* 1
* 4
* 3
* */
}
}
4.4.3 从其他RDD转换得到新的RDD
- 根据RDD的数据类型的不同,整体分为2种RDD:Value类型,Key-Value类型(二维元组)
map()返回一个新的RDD,该RDD是由原RDD的每个元素经过函数转换后的值组成,主要作用就是转换结构。(不存在shuffle)
- 案例一:
object Demo2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("map").setMaster("local[*]")
val sc = new SparkContext(conf)
/**
* map算子,一共有多少元素就会执行多少次,和分区数无关
**/
val rdd: RDD[Int] = sc.parallelize(1.to(10), 1)
val mapRdd: RDD[Int] = rdd.map(x => {
println("执行") //一共被执行10次
x * 2
})
val result: Array[Int] = mapRdd.collect()
result.foreach(x => print(x + "\t")) //2 4 6 8 10 12 14 16 18 20
}
}
- 案例二:
object demo3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("mapPartitions").setMaster("local[*]")
val sc = new SparkContext(conf)
/**
* mapPartitions算子,一个分区内处理,几个分区就执行几次,优于map函数
**/
val rdd: RDD[Int] = sc.parallelize(1.to(10), 2)
val mapRdd: RDD[Int] = rdd.mapPartitions(it => {
println("执行") //分区2次,共打印2次
it.map(x => x * 2)
})
val result: Array[Int] = mapRdd.collect()
result.foreach(x => print(x + "\t")) //2 4 6 8 10 12 14 16 18 20
}
}
- 案例三:
object Demo4 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("mapPartitionsWithIndex").setMaster("local[*]")
val sc = new SparkContext(conf)
/**
* mapPartitionsWithIndex算子,一个分区内处理,几个分区就执行几次,返回带有分区号的结果集
**/
val rdd: RDD[Int] = sc.parallelize(1.to(10), 2)
val value: RDD[(Int, Int)] = rdd.mapPartitionsWithIndex((index, it) => it.map((index, _)))
val result: Array[(Int, Int)] = value.collect()
result.foreach(x => print(x + "\t")) //(0,1) (0,2) (0,3) (0,4) (0,5) (1,6) (1,7) (1,8) (1,9) (1,10)
}
}
4.5 flatMap
扁平化(不存在shuffle)
object Demo5 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("flatMap").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[(String, Int)] = sc.parallelize(Array(("A", 1), ("B", 2), ("C", 3)))
val map_result: RDD[String] = rdd.map(ele => ele._1 + ele._2)
val flatMap_result: RDD[Char] = rdd.flatMap(ele => ele._1 + ele._2)
/**
* C3
* A1
* B2
**/
map_result.foreach(println)
/**
* B
* A
* C
* 1
* 2
* 3
**/
flatMap_result.foreach(println)
}
}
4.6 glom
将每一个分区的元素合并成一个数组,形成新的RDD类型:RDD[Array[T]] (不存在shuffle)
object Demo6 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("glom").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(1.to(10), 3)
val result: RDD[Array[Int]] = rdd.glom()
/**
* 1,2,3
* 7,8,9,10
* 4,5,6
* */
result.foreach(x=>{
println(x.toList.mkString(","))
})
}
}
4.7 groupBy
根据条件函数分组(存在shuffle)
object Demo7 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("groupBy").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(1.to(10))
val result1: RDD[(Int, Iterable[Int])] = rdd.groupBy(x => x % 2)
val result2: RDD[(Boolean, Iterable[Int])] = rdd.groupBy(x => x % 2 == 0)
/**
* (0,CompactBuffer(2, 4, 6, 8, 10))
* (1,CompactBuffer(1, 3, 5, 7, 9))
**/
result1.foreach(println)
/**
* (true,CompactBuffer(2, 4, 6, 8, 10))
* (false,CompactBuffer(1, 3, 5, 7, 9))
**/
result2.foreach(println)
}
}
4.8 filter
过滤(不存在shuffle)
object Demo8 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("filter").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(1.to(10))
val result: RDD[Int] = rdd.filter(x => x % 2 == 0)
result.foreach(x => print(x + "\t")) //6 10 8 4 2
}
}
4.9 sample
sample(withReplacement,fraction,seed)抽样,常用在解决定位大key问题
- 以指定的随机种子随机抽样出比例为fraction的数据(抽取到的数量是size*fraction),注意:得到的结果并不能保证准确的比例,也就是说fraction只决定了这个数被选中的比率,并不是从数据中抽出多少百分比的数据,决定的不是个数,而是比率。
- withReplacement表示抽出的数据是否放回,true为有放回抽样,flase为无放回抽样,放回表示数据有可能会被重复抽取到,false则不可能重复抽取到,如果为false则fraction必须在[0,1]内,是true则大于0即可。
- seed用于指定随机数生成器种子,一般默认的,或者传入当前的时间戳,(如果传入定值,每次取出结果一样)
object Demo9 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("sample").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(1.to(10))
/**
* 不放回抽样
* 从结果中可以看出,抽出结果没有重复
* */
val result1: RDD[Int] = rdd.sample(false,0.5)
result1.foreach(println)
/**
* 放回抽样
* 从结果中可以看出,抽出结果有重复
* */
val result2: RDD[Int] = rdd.sample(true,2)
result2.foreach(println)
}
}
4.10 distinct
distinct([numTasks])去重,参数表示任务数量,默认值和分区数保持一致(不存在shuffle)
object Demo10 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("distinct").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(Array(1,2,3,4,2,3,4,3,4,5))
val result: RDD[Int] = rdd.distinct(2)
result.foreach(println)
}
}
4.11 coalesce
coalesce(numPatitions)缩减,缩减分区到指定数量,用于大数据集过滤后,提高小数据集的执行效率,只能减不能加。(不存在shuffle)
object Demo11 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("coalesce").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(1.to(10),5)
println(rdd.partitions.length) //5
val result: RDD[Int] = rdd.coalesce(2)
println(result.partitions.length) //2
}
}
4.12 repartition
repartition(numPatitions)更改分区,更改分区到指定数量,可加可减,但是减少还是使用coalesce,将这个理解为增加。(存在shuffle)
object Demo12 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("repartition").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(1.to(10),2)
println(rdd.partitions.length) //2
val result: RDD[Int] = rdd.repartition(5)
println(result.partitions.length) //5
}
}
4.13 sortBy
排序(存在shuffle)
object Demo13 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("sortBy").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(Array(4, 2, 3, 1, 5), 1)
val result1: RDD[Int] = rdd.sortBy(x => x, false)
result1.foreach(x => print(x + "\t")) //5 4 3 2 1
val result2: RDD[Int] = rdd.sortBy(x => x, true)
result2.foreach(x => print(x + "\t")) //1 2 3 4 5
}
}
4.14 RDD与RDD互交
- 并集:union
- 差集:subtract
- 交集:intersection
- 笛卡尔积:cartesian
- 拉链:zip
object Demo14 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD AND RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(1.to(5))
val rdd2: RDD[Int] = sc.parallelize(3.to(8))
//并集
rdd1.union(rdd2).collect().foreach(x => print(x + "\t")) //1 2 3 4 5 3 4 5 6 7 8
//差集
rdd1.subtract(rdd2).collect().foreach(x => print(x + "\t")) //1 2
//交集
rdd1.intersection(rdd2).collect().foreach(x => print(x + "\t")) //3 4 5\
//笛卡尔积
/*(1,3) (1,4) (1,5) (1,6) (1,7) (1,8)
(2,3) (2,4) (2,5) (2,6) (2,7) (2,8)
(3,3) (3,4) (3,5) (3,6) (3,7) (3,8)
(4,3) (4,4) (4,5) (4,6) (4,7) (4,8)
(5,3) (5,4) (5,5) (5,6) (5,7) (5,8)*/
rdd1.cartesian(rdd2).collect().foreach(x => print(x + "\t"))
//拉链:必须保证RDD分区元素数量相同
val rdd3: RDD[Int] = sc.parallelize(1.to(5))
val rdd4: RDD[Int] = sc.parallelize(2.to(6))
rdd3.zip(rdd4).collect().foreach(x => print(x + "\t")) //(1,2) (2,3) (3,4) (4,5) (5,6)
}
}
4.15 k-v类型 partitionBy
大多数Spark算子都可以用在任意类型的RDD上,但是有一些比较特殊的操作只能用在key-value类型的RDD上
使用HashPartitioner分区器
object Demo15 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("partitionBy").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
println(rdd2.partitions.length) //1
println(rdd2.partitioner) //None
val rdd3: RDD[(String, Int)] = rdd2.partitionBy(new HashPartitioner(2))
println(rdd3.partitions.length) //2
println(rdd3.partitioner) //Some(org.apache.spark.HashPartitioner@2)
val result: RDD[(Int, (String, Int))] = rdd3.mapPartitionsWithIndex((index, it) => {
it.map(x => (index, (x._1, x._2)))
})
result.foreach(println)
/**
* (1,(spark,1))
* (0,(hello,1))
* (0,(hadooop,1))
* (0,(hello,1))
**/
}
}
自定义分区器
object Demo16 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("partitionBy").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
println(rdd2.partitions.length) //1
println(rdd2.partitioner) //None
val rdd3: RDD[(String, Int)] = rdd2.partitionBy(new MyPatitioner(2))
println(rdd3.partitions.length) //2
println(rdd3.partitioner) //Some(com.test.sparkcore.MyPatitioner@769a58e5)
val result: RDD[(Int, (String, Int))] = rdd3.mapPartitionsWithIndex((index, it) => {
it.map(x => (index, (x._1, x._2)))
})
result.foreach(println)
/**
* (0,(hadooop,1))
* (1,(hello,1))
* (0,(spark,1))
* (1,(hello,1))
**/
}
}
class MyPatitioner(num: Int) extends Partitioner {
override def numPartitions: Int = num
override def getPartition(key: Any): Int = {
System.identityHashCode(key) % num.abs
}
}
4.16 k-v类型 reduceByKey
reduceByKey(V , V)=>V 根据key进行聚合,在shuffle之前会有combine(预聚合)操作
object Demo17 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("reduceByKey").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
val result: RDD[(String, Int)] = rdd2.reduceByKey(_ + _)
result.foreach(x => print(x + "\t")) //(spark,1) (hadooop,1) (hello,2)
}
}
4.17 k-v类型 groupByKey
根据key进行分组,直接shuffle
object Demo18 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("groupByKey").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
val result: RDD[(String, Iterable[Int])] = rdd2.groupByKey()
result.foreach(x => print(x + "\t")) //(spark,CompactBuffer(1)) (hadooop,CompactBuffer(1)) (hello,CompactBuffer(1, 1))
result.map(x=>(x._1,x._2.size)).foreach(x => print(x + "\t")) //(spark,1) (hadooop,1) (hello,2)
}
}
4.18 k-v类型 aggrateByKey
aggrateByKey(zero : U)(( U , V )=>U , (U , U)=>U)
基于Key分组然后去聚合的操作,耗费资源太多,这时可以使用reduceByKey或aggrateByKey算子去提高性能
aggrateByKey分区内聚合,后在进行shuffle聚合。
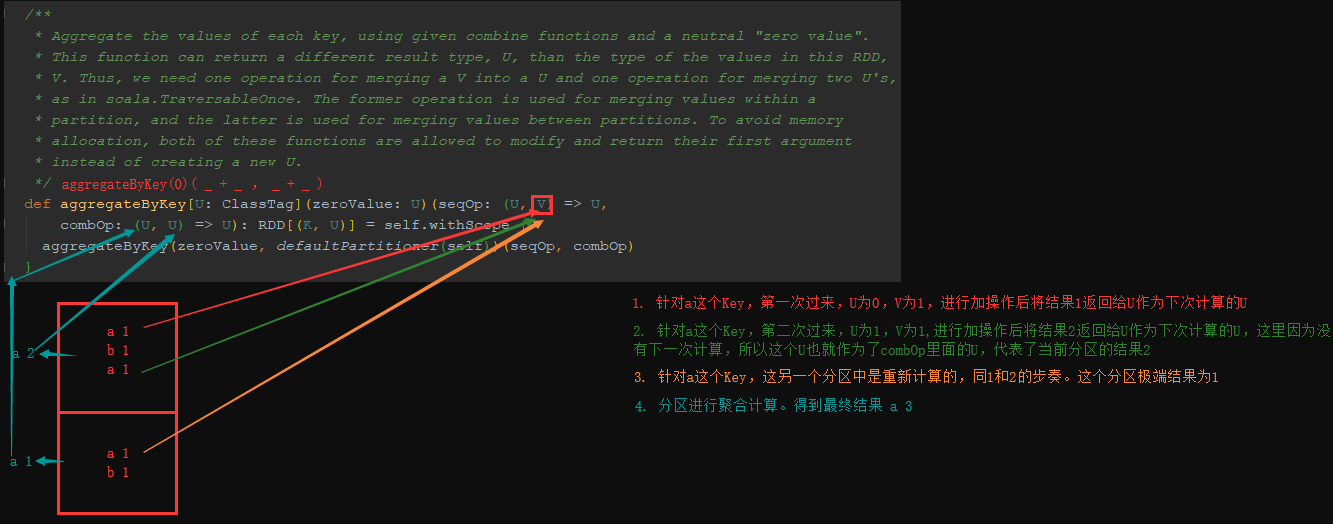
object Demo19 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("aggregateByKey").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
val result: RDD[(String, Int)] = rdd2.aggregateByKey(0)(_ + _, _ + _)
result.foreach(x => print(x + "\t")) //(spark,1) (hadooop,1) (hello,2)
}
}
4.19 k-v类型 foldByKey
foldByKey(zero : V)((V , V)=>V) 折叠计算,没有aggrateByKey灵活,如果分区内和分区外聚合计算不一样,则不行
object Demo20 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("foldByKey").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
val result: RDD[(String, Int)] = rdd2.foldByKey(0)(_+_)
result.foreach(x => print(x + "\t")) //(spark,1) (hadooop,1) (hello,2)
}
}
4.20 k-v类型 combineByKey
combineByKey(V=>U,(U , V)=>U , (U , U)=>U) 根据Key组合计算
object Demo21 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("combineByKey").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
val result: RDD[(String, Int)] = rdd2.combineByKey(v => v, (c: Int, v: Int) => c + v, (c1: Int, c2: Int) => c1 + c2)
result.foreach(x => print(x + "\t")) //(spark,1) (hadooop,1) (hello,2)
}
}
4.21 k-v类型 sortByKey
根据Key排序
object Demo22 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("sortByKey").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("ahello", "bhadooop", "chello", "dspark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
rdd2.sortByKey(false).foreach(x => print(x + "\t")) //(dspark,1) (chello,1) (bhadooop,1) (ahello,1)
}
}
4.22 k-v类型 mapValues
只对value操作的map转换操作
object Demo23 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("mapValues").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
rdd2.mapValues(x => x + 1).foreach(x => print(x + "\t")) //(hello,2) (hadooop,2) (hello,2) (spark,2)
}
}
4.23 k-v类型 join
object Demo24 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("join").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = sc.parallelize(Array(("a",10),("b",10),("a",20),("d",10)))
val rdd2: RDD[(String, Int)] = sc.parallelize(Array(("a",30),("b",20),("c",10)))
//内连接 (a,(10,30)) (b,(10,20)) (a,(20,30))
rdd1.join(rdd2).foreach(x => print(x + "\t"))
//左链接(b,(10,Some(20))) (d,(10,None)) (a,(10,Some(30))) (a,(20,Some(30)))
rdd1.leftOuterJoin(rdd2).foreach(x => print(x + "\t"))
//右链接(c,(None,10)) (a,(Some(10),30)) (b,(Some(10),20)) (a,(Some(20),30))
rdd1.rightOuterJoin(rdd2).foreach(x => print(x + "\t"))
//全链接(b,(Some(10),Some(20))) (c,(None,Some(10))) (d,(Some(10),None)) (a,(Some(10),Some(30))) (a,(Some(20),Some(30)))
rdd1.fullOuterJoin(rdd2).foreach(x => print(x + "\t"))
}
}
4.24 k-v类型 cogroup
根据Key聚合RDD
object Demo25 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("cogroup").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = sc.parallelize(Array(("a",10),("b",10),("a",20),("d",10)))
val rdd2: RDD[(String, Int)] = sc.parallelize(Array(("a",30),("b",20),("c",10)))
/**
* (c,(CompactBuffer(),CompactBuffer(10)))
* (b,(CompactBuffer(10),CompactBuffer(20)))
* (a,(CompactBuffer(10, 20),CompactBuffer(30)))
* (d,(CompactBuffer(10),CompactBuffer()))
*/
rdd1.cogroup(rdd2).foreach(println)
}
}
4.25 keyo序列化
在分布式应用中,经常会进行IO操作,传递对象,而网络传输过程中就必须要序列化。
Java序列化可以序列化任何类,比较灵活,但是相当慢,并且序列化后对象的提交也比较大。
Spark出于性能考虑,在2.0以后,开始支持kryo序列化机制,速度是Serializable的10倍以上,当RDD在Shuffle数据的时候,简单数据类型,简单数据类型数组,字符串类型已经使用kryo来序列化。
object Demo26 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("keyo")
.setMaster("local[*]")
//替换默认序列化机制
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
//注册需要使用的kryo序列化自定义类
.registerKryoClasses(Array(classOf[MySearcher]))
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hadoop yarn", "hadoop hdfs", "c"))
val rdd2: RDD[String] = MySearcher("hadoop").getMathcRddByQuery(rdd1)
rdd2.foreach(println)
}
}
case class MySearcher(val query: String) {
def getMathcRddByQuery(rdd: RDD[String]): RDD[String] = {
rdd.filter(x => x.contains(query))
}
}
4.26 依赖
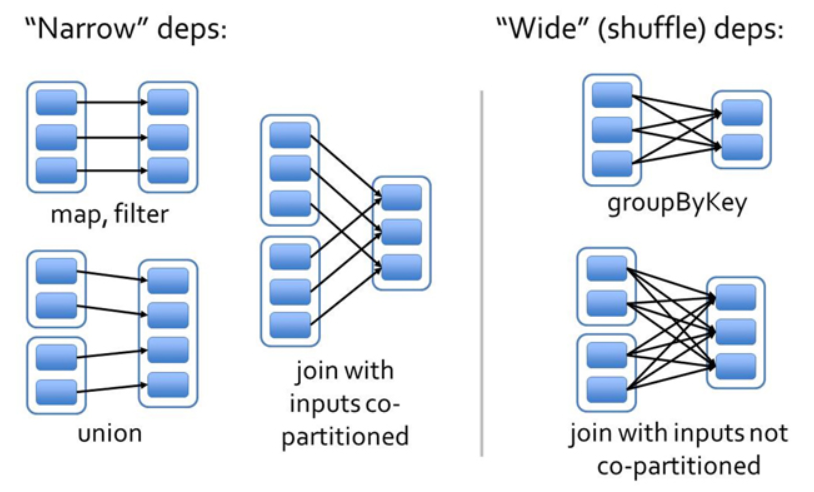
-
窄依赖:(不会shuffle)
- 如果RDD2由RDD1计算得到,则RDD2就是子RDD,RDD1就是父RDD
- 如果依赖关系在设计的时候就可以确定,而不需要考虑父RDD分区中的记录,并且父RDD中的每个分区最多只有一个子分区,这就叫窄依赖
- 父RDD的每个分区中的数据最多被一个子RDD的分区使用
-
宽依赖:(会shuffle)
- 宽依赖往往对应着shuffle操作,需要在运行过程中将同一个父RDD的分区传入到不同的子RDD分区中。
- 对于宽依赖,重算的父RDD分区对应多个子RDD分区,这样实际上父RDD 中只有一部分的数据是被用于恢复这个丢失的子RDD分区的,另一部分对应子RDD的其它未丢失分区,这就造成了多余的计算;
- 宽依赖中子RDD分区通常来自多个父RDD分区,极端情况下,所有的父RDD分区都要进行重新计算。
4.27 持久化
object Demo27 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("cache").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("a", "b", "c"))
val rdd2: RDD[String] = rdd1.flatMap(x => {
println("执行flatMap操作")
x.split("")
})
val rdd3: RDD[(String, Int)] = rdd2.map((_, 1))
/** 持久化到内存 */
//rdd3.cache() //持久化到内存
/**
* 持久化到磁盘
* DISK_ONLY:持久化到磁盘
* DISK_ONLY_2:持久化到磁盘并且存一个副本(2个文件)
* MEMORY_ONLY:持久化到内存
* MEMORY_ONLY_2:持久化到内存并且存一个副本(2个文件)
* MEMORY_ONLY_SER:持久化到内存,并且序列化
* MEMORY_ONLY_SER_2:持久化到内存,并且序列化,还要存一个副本(2个文件)
* MEMORY_AND_DISK:持久化到内存和磁盘
* MEMORY_AND_DISK_2:持久化到内存和磁盘并且存一个副本(2个文件)
* MEMORY_AND_DISK_SER:持久化到内存和磁盘,并且序列化
* MEMORY_AND_DISK_SER_2:持久化到内存和磁盘,并且序列化,还要存一个副本(2个文件)
* OFF_HEAP:持久化在堆外内存中,Spark自己管理的内存
* */
rdd3.persist(StorageLevel.DISK_ONLY) //持久化到磁盘
rdd3.collect.foreach(x => print(x + "\t"))
println("------------")
//输出语句不会执行
rdd3.collect.foreach(x => print(x + "\t"))
}
}
4.28 checkpoint
持久化只是将数据保存在BlockManager中,而RDD的Lineage是不变的,但是checkpoint执行完后,RDD已经没有之前所谓的依赖了,而只是一个强行为其设定的checkpointRDD,RDD的Lineage改变了。
持久化的数据丢失可能性更大,磁盘、内存都有可能会存在数据丢失情况。但是checkpoint的数据通常是储存在如HDFS等容错、高可用的文件系统,数据丢失可能性较小。
默认情况下,如果某个RDD没有持久化,但是设置了checkpoint Job想要将RDD的数据写入文件系统,需要全部重新计算一次,再将计算出来的RDD数据checkpoint到文件系统,所以,建议对checkpoint的RDD使用十九画,这样RDD只需要计算一次就可以了。
object Demo28 {
def main(args: Array[String]): Unit = {
//设置当前用户
System.setProperty("HADOOP_USER_NAME", "Heaton")
val conf = new SparkConf().setAppName("checkpoint").setMaster("local[*]")
val sc = new SparkContext(conf)
//设置checkpoint目录
sc.setCheckpointDir("hdfs://cdh01.cm:8020/test")
val rdd1: RDD[String] = sc.parallelize(Array("abc"))
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
/**
* 标记RDD2的checkpoint
* RDD2会被保存到文件中,并且会切断到父RDD的引用,该持久化操作,必须在job运行之前调用
* 如果不进行持久化操作,那么在保存到文件的时候需要重新计算
**/
rdd2.cache()
rdd2.collect.foreach(x => print(x + "\t"))
rdd2.collect.foreach(x => print(x + "\t"))
}
}
4.29 累加器
4.29.1 累加器问题抛出
object Demo29 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Accumulator").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 2, 3, 4, 5), 2)
var a = 1
rdd1.foreach(x => {
a += 1
println("rdd: "+a)
})
println("-----")
println("main: "+a)
/**
* rdd: 2
* rdd: 2
* rdd: 3
* rdd: 3
* rdd: 4
* -----
* main: 1
* */
}
}
从上面可以看出,2个问题:
- 变量是在RDD分区中进行累加,并且2个RDD分区中的变量不同
- 最后并没有main方法中的变量值改变
考虑到main方法中的a变量是在Driver端,而RDD分区又是在Excutor端进行计算,所以只是拿了一个Driver端的镜像,而且不同步回Driver端
在实际开发中,我们需要进行这种累加,这时就用到了累加器
4.29.2 累加器案例
Spark提供了一些常用累加器,主要针对值类型
object Demo30 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Accumulator").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 2, 3, 4, 5), 2)
val acc: util.LongAccumulator = sc.longAccumulator("acc")
rdd1.foreach(x => {
acc.add(1)
println("rdd: "+acc.value)
})
println("-----")
println("main: "+acc.count)
/**
* rdd: 1
* rdd: 1
* rdd: 2
* rdd: 2
* rdd: 3
* -----
* main: 5
* */
}
}
如上代码,我们发现累加器是分区内先累加,再分区间累加
4.29.3 自定义累加器
- 案例一:自定义Int累加器
object Demo31 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Accumulator").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 2, 3, 4, 5), 2)
val acc = new MyAccumulator
//注册累加器
sc.register(acc)
rdd1.foreach(x => {
acc.add(1)
println("rdd: " + acc.value)
})
println("-----")
println("main: " + acc.value)
/**
* rdd: 1
* rdd: 1
* rdd: 2
* rdd: 3
* rdd: 2
* -----
* main: 5
**/
}
}
class MyAccumulator extends AccumulatorV2[Int, Int] {
var sum: Int = 0
//判断累加的值是不是空
override def isZero: Boolean = sum == 0
//如何把累加器copy到Executor
override def copy(): AccumulatorV2[Int, Int] = {
val accumulator = new MyAccumulator
accumulator.sum = sum
accumulator
}
//重置值
override def reset(): Unit = {
sum = 0
}
//分区内的累加
override def add(v: Int): Unit = {
sum += v
}
//分区间的累加,累加器最终的值
override def merge(other: AccumulatorV2[Int, Int]): Unit = {
other match {
case o: MyAccumulator => this.sum += o.sum
case _ =>
}
}
override def value: Int = this.sum
}
- 案例二:自定义map平均值累加器
object Demo32 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("partitionBy").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 2, 3, 4, 5), 2)
val acc = new MyAccumulator
//注册累加器
sc.register(acc)
rdd1.foreach(x => {
acc.add(x)
})
println("main: " + acc.value)
/**main: Map(sum -> 15.0, count -> 17.0, avg -> 0.8823529411764706) */
}
}
class MyAccumulator extends AccumulatorV2[Int, Map[String, Double]] {
var map: Map[String, Double] = Map[String, Double]()
//判断累加的值是不是空
override def isZero: Boolean = map.isEmpty
//如何把累加器copy到Executor
override def copy(): AccumulatorV2[Int, Map[String, Double]] = {
val accumulator = new MyAccumulator
accumulator.map ++= map
accumulator
}
//重置值
override def reset(): Unit = {
map = Map[String, Double]()
}
//分区内的累加
override def add(v: Int): Unit = {
map += "sum" -> (map.getOrElse("sum", 0d) + v)
map += "count" -> (map.getOrElse("sum", 0d) + 1)
}
//分区间的累加,累加器最终的值
override def merge(other: AccumulatorV2[Int, Map[String, Double]]): Unit = {
other match {
case o: MyAccumulator =>
this.map += "sum" -> (map.getOrElse("sum", 0d) + o.map.getOrElse("sum", 0d))
this.map += "count" -> (map.getOrElse("count", 0d) + o.map.getOrElse("count", 0d))
case _ =>
}
}
override def value: Map[String, Double] = {
map += "avg" -> map.getOrElse("sum", 0d) / map.getOrElse("count", 1d)
map
}
}
4.30 广播变量
广播变量在每个节点上保存一个只读的变量的缓存,而不用给每个task来传送一个copy
object Demo33 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("partitionBy").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.parallelize(Array("a", "b"))
val broadArr: Broadcast[Array[Int]] = sc.broadcast(Array(1, 2))
rdd.foreach(x => {
val value: Array[Int] = broadArr.value
println(value.toList)
})
/**
* List(1, 2)
* List(1, 2)
* */
}
}
5 Spark SQL
Spark SQL是Spark用于结构化数据处理的Spark模块。如:Mysql,Hbase,Hive
Spark SQL将SQL转换成RDD,然后提交到集群执行,执行效率非常快,而且使只会写SQL的同学可以直接开发
Spark SQL提供了2个编程抽象,等同于Spark Core中的RDD,分别是:DataFrame,DataSet
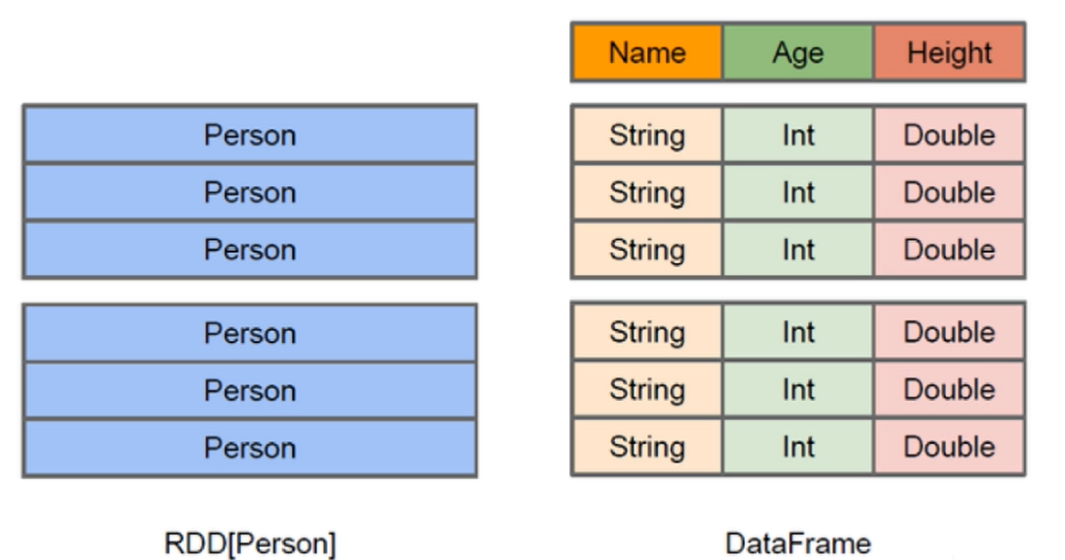
5.1 DataFrame
与RDD类似,DataFrame是一个分布式的数据容器
DataFrame更像是传统数据库的二维表格,除了数据以外,还记录了数据的结构信息(Schema)
与Hive类似,DataFrame也支持嵌套数据类型(Struct、Array、Map)
- 底层架构
- Predicate Pushdown 机制
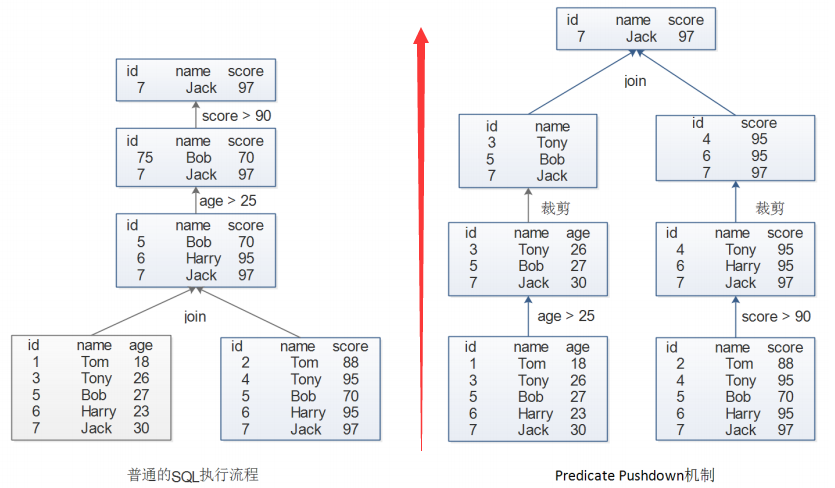
5.2 DataSet
DataSet是DataFrame的一个扩展,是SparkSQL1.6后新增的数据抽象,API友好
scala样例类支持非常好,用样例类在DataSet中定义数据结构信息,样例类中每个属性的没成直接映射到DataSet中的字段名称。
DataFrame是DataSet的特例,DataFrame=DataSet[Row],可以通过as方法将DataFrame转换成DataSet,Row是一个类型,可以是Person、Animal,所有的表结构信息都用Row来表示
DataFrame只知道字段,不知道字段类型,而DataSet不仅知道字段,还知道类型。
DataSet具有强类型的数据集合,需要提供对应的类型信息。
5.3 SparkSession
从Spark2.0开始,SparkSession是Spark新的查询起始点,其内部封装了SparkContext,所以计算实际上是由SparkContext完成
5.4 DataFrame编程
5.4.1 解析Json数据
- 读取Json文件
在idea中,resources目录下创建student.json文件
{"id":1,"name": "zhangsa", "age": 10}
{"id":2,"name": "lisi", "age": 20}
{"id":3,"name": "wangwu", "age": 30}
{"id":4,"name": "zhaoliu", "age": 12}
{"id":5,"name": "hahaqi", "age": 24}
{"id":6,"name": "xixiba", "age": 33}
object SparkSQLDemo1 {
def main(args: Array[String]): Unit = {
//创建sparksession
val spark = SparkSession.builder().appName("demo1").master("local[*]") getOrCreate()
val frame: DataFrame = spark.read.json(this.getClass.getClassLoader.getResource("student.json").getPath)
frame.show(100)
/**
* +---+---+-------+
* |age| id| name|
* +---+---+-------+
* | 10| 1|zhangsa|
* | 20| 2| lisi|
* | 30| 3| wangwu|
* | 12| 4|zhaoliu|
* | 24| 5| hahaqi|
* | 33| 6| xixiba|
* +---+---+-------+
*/
println(frame.schema)
/**
* StructType(StructField(age,LongType,true), StructField(id,LongType,true), StructField(name,StringType,true))
*/
}
}
5.4.2 TempView
- 在使用sql查询之前需要注册临时视图
- createTempView():注册视图,当前Session有效
- createOrReplaceTempView():注册视图,当前Session有效,如果已经存在,那么替换
- createGlobalTempView():注册全局视图,在所有Session中生效
- createOrReplaceGlobalTempView():注册全局视图,在所有Session中生效,如果已经存在,那么替换
使用全局视图,需要在表名前添加global_tmp,如student表,写法为:global_tmp.student
object SparkSQLDemo2 {
def main(args: Array[String]): Unit = {
//创建sparksession
val spark = SparkSession.builder().appName("demo2").master("local[*]") getOrCreate()
val frame: DataFrame = spark.read.json(this.getClass.getClassLoader.getResource("student.json").getPath)
frame.createOrReplaceTempView("student")
val result: DataFrame = spark.sql("select * from student where age >= 20")
result.show()
/**
* +---+---+------+
* |age| id| name|
* +---+---+------+
* | 20| 2| lisi|
* | 30| 3|wangwu|
* | 24| 5|hahaqi|
* | 33| 6|xixiba|
* +---+---+------+
*/
}
}
5.5 DataSet编程
- DataSet简单使用
object SparkSQLDemo3 {
def main(args: Array[String]): Unit = {
//创建sparksession
val spark = SparkSession.builder().appName("demo3").master("local[*]") getOrCreate()
import spark.implicits._
val sRDD: Dataset[Student] = Seq(Student(1,"zhangsan",15),Student(2,"lisi",16)).toDS
sRDD.foreach(s=>{
println(s.name+":"+s.age)
})
/**
* zhangsan:15
* lisi:16
* */
}
}
case class Student(id: Long, name: String, age: Long)
5.6 DataSet和DataFrame和RDD互相转换
涉及到RDD,DataFrame,DataSet之间操作时,需要隐式转换导入: import spark.implicits._ 这里的spark不是报名,而是代表了SparkSession的那个对象名,所以必须先创建SparkSession对象在导入
RDD转DF:toDF
RDD转DS:toDS
DF转RDD:rdd
DS转RDD:rdd
DS转DF:toDF
DF转DS:as
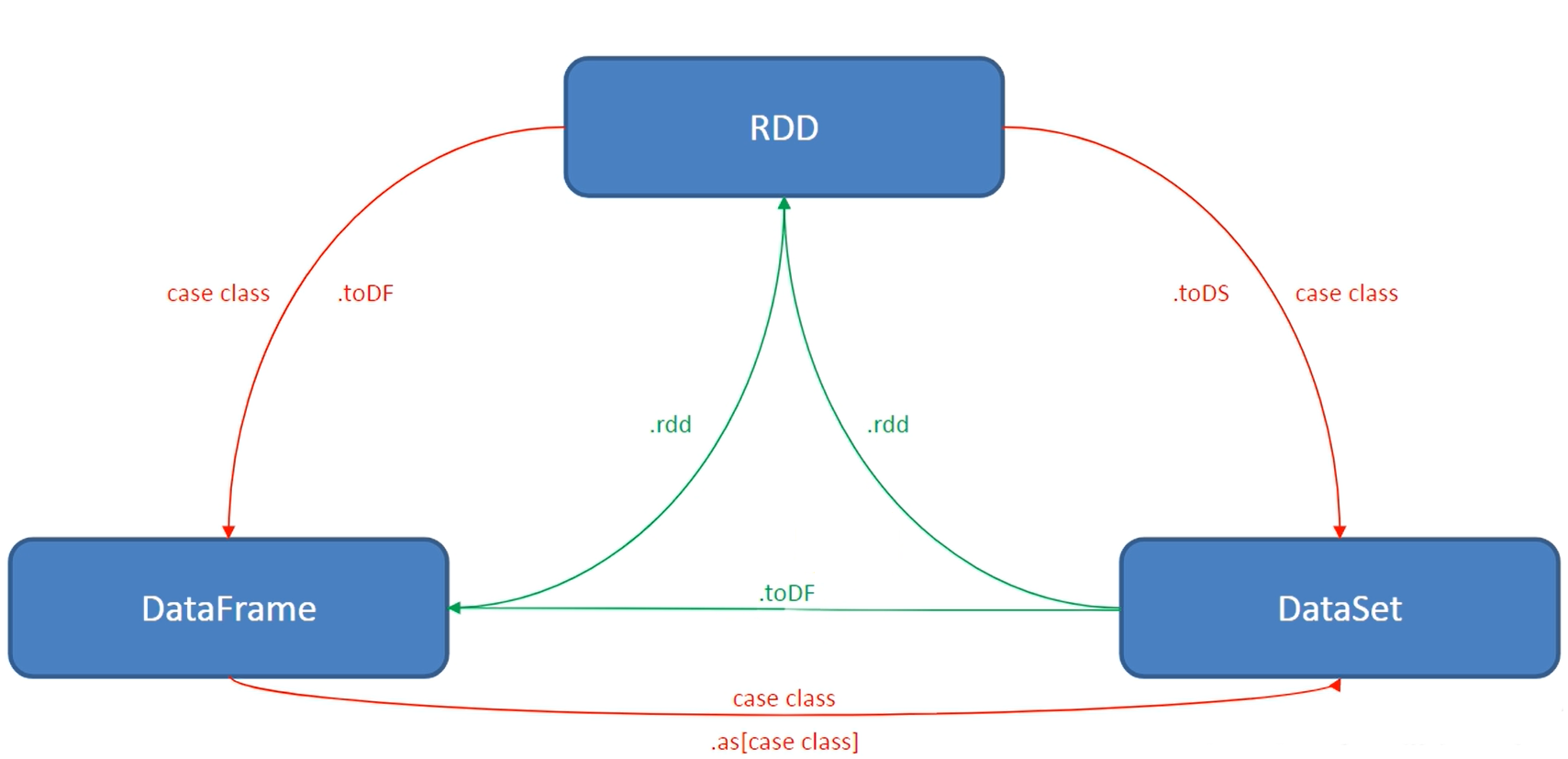
- 创建student.csv文件
1,zhangsa,10
2,lisi,20
3,wangwu,30
object SparkSQLDemo4 {
def main(args: Array[String]): Unit = {
//创建sparksession
val spark = SparkSession.builder().appName("demo4").master("local[*]") getOrCreate()
import spark.implicits._
val rdd: RDD[String] = spark.sparkContext.textFile(this.getClass.getClassLoader.getResource("student.csv").getPath)
val studentRDD: RDD[Student] = rdd.map(x => {
val arr: Array[String] = x.split(",")
Student(arr(0).toLong, arr(1), arr(2).toLong)
})
/** 1. RDD转DF
* +---+-------+---+
* | id| name|age|
* +---+-------+---+
* | 1|zhangsa| 10|
* | 2| lisi| 20|
* | 3| wangwu| 30|
* +---+-------+---+
* */
val df1: DataFrame = studentRDD.toDF()
df1.show()
/** 2. RDD转DS
* +---+-------+---+
* | id| name|age|
* +---+-------+---+
* | 1|zhangsa| 10|
* | 2| lisi| 20|
* | 3| wangwu| 30|
* +---+-------+---+
* */
val ds1: Dataset[Student] = studentRDD.toDS()
ds1.show()
/** 3. DF转RDD
* List([1,zhangsa,10], [2,lisi,20], [3,wangwu,30])
* */
val rdd1: RDD[Row] = df1.rdd
println(rdd1.collect.toList)
/** 4. DS转RDD
* List(Student(1,zhangsa,10), Student(2,lisi,20), Student(3,wangwu,30))
* */
val rdd2: RDD[Student] = ds1.rdd
println(rdd2.collect.toList)
/** 5. DS转DF
* +---+-------+---+
* | id| name|age|
* +---+-------+---+
* | 1|zhangsa| 10|
* | 2| lisi| 20|
* | 3| wangwu| 30|
* +---+-------+---+
* */
val df2: DataFrame = ds1.toDF()
df2.show()
/** 6. DF转DS
* +---+-------+---+
* | id| name|age|
* +---+-------+---+
* | 1|zhangsa| 10|
* | 2| lisi| 20|
* | 3| wangwu| 30|
* +---+-------+---+
* */
val ds2: Dataset[Student] = df2.as[Student]
ds2.show()
}
}
case class Student(id: Long, name: String, age: Long)
5.7 UDF函数:一对一
object SparkSQLDemo5 {
def main(args: Array[String]): Unit = {
//创建sparksession
val spark = SparkSession.builder().appName("demo5").master("local[*]") getOrCreate()
//注册函数
val toUpper: UserDefinedFunction = spark.udf.register("toUpper", (s: String) => s.toUpperCase)
val frame: DataFrame = spark.read.json(this.getClass.getClassLoader.getResource("student.json").getPath)
frame.createOrReplaceTempView("student")
val result: DataFrame = spark.sql("select id,toUpper(name),age from student where age >= 20")
result.show()
/**
* +---+-----------------+---+
* | id|UDF:toUpper(name)|age|
* +---+-----------------+---+
* | 2| LISI| 20|
* | 3| WANGWU| 30|
* | 5| HAHAQI| 24|
* | 6| XIXIBA| 33|
* +---+-----------------+---+
**/
}
}
5.8 UDAF函数:多对一
object SparkSQLDemo6 {
def main(args: Array[String]): Unit = {
//创建sparksession
val spark = SparkSession.builder().appName("demo6").master("local[*]") getOrCreate()
//注册函数
spark.udf.register("MyAvg", new MyAvg)
val frame: DataFrame = spark.read.json(this.getClass.getClassLoader.getResource("student.json").getPath)
frame.createOrReplaceTempView("student")
frame.printSchema()
val result: DataFrame = spark.sql("select sum(age),count(1),MyAvg(age) from student")
result.show()
/**
* +--------+--------+----------+
* |sum(age)|count(1)|myavg(age)|
* +--------+--------+----------+
* | 129| 6| 21.5|
* +--------+--------+----------+
* */
}
}
class MyAvg extends UserDefinedAggregateFunction {
//输入数据类型
override def inputSchema: StructType = StructType(StructField("input", LongType) :: Nil)
//缓冲区中值的类型
override def bufferSchema: StructType = StructType(StructField("sum", DoubleType) :: StructField("count", LongType) :: Nil)
//最终输出数据类型
override def dataType: DataType = DoubleType
//输入和输出之间的确定性,一般都是true
override def deterministic: Boolean = true
//缓冲区中值的初始化
override def initialize(buffer: MutableAggregationBuffer): Unit = {
//sum
buffer(0) = 0.0d
//count
buffer(1) = 0L
}
//分区内聚合
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
//如果值不为空
if (!input.isNullAt(0)) {
buffer(0) = buffer.getDouble(0) + input.getLong(0)
buffer(1) = buffer.getLong(1) + 1
}
}
//分区间聚合
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
//如果值不为空
if (!buffer2.isNullAt(0)) {
buffer1(0) = buffer1.getDouble(0) + buffer2.getDouble(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
}
//最终输出的值
override def evaluate(buffer: Row): Any = {
new DecimalFormat(".00").format(buffer.getDouble(0) / buffer.getLong(1)).toDouble
}
}
5.9 UDTF函数:一对多
需要使用Hive的UDTF
import java.util.ArrayList
import org.apache.hadoop.hive.ql.exec.{UDFArgumentException, UDFArgumentLengthException}
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory
import org.apache.hadoop.hive.serde2.objectinspector.{ObjectInspector, ObjectInspectorFactory, StructObjectInspector}
import org.apache.spark.sql.{DataFrame, SparkSession}
object SparkSQLDemo7 {
def main(args: Array[String]): Unit = {
//创建sparksession
val spark = SparkSession.builder()
.appName("demo7")
.master("local[*]")
.enableHiveSupport() //启用hive
.getOrCreate()
import spark.implicits._
//注册utdf算子,这里无法使用sparkSession.udf.register(),注意包全路径
spark.sql("CREATE TEMPORARY FUNCTION MySplit as 'com.xx.xx.MySplit'")
val frame: DataFrame = spark.sparkContext.parallelize(Array("a,b,c,d")).toDF("word")
frame.createOrReplaceTempView("test")
val result: DataFrame = spark.sql("select MySplit(word,',') from test")
result.show()
/**
* +----+
* |col1|
* +----+
* | a|
* | b|
* | c|
* | d|
* +----+
*/
}
}
class MySplit extends GenericUDTF {
override def initialize(args: Array[ObjectInspector]): StructObjectInspector = {
if (args.length != 2) {
throw new UDFArgumentLengthException("UserDefinedUDTF takes only two argument")
}
if (args(0).getCategory() != ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentException("UserDefinedUDTF takes string as a parameter")
}
//列名,会被用户传递的覆盖
val fieldNames: ArrayList[String] = new ArrayList[String]()
fieldNames.add("col1")
//返回列以什么格式输出,这里是string,添加几个就是几个列,和上面的名字个数对应个数。
var fieldOIs: ArrayList[ObjectInspector] = new ArrayList[ObjectInspector]()
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector)
ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs)
}
override def process(objects: Array[AnyRef]): Unit = {
//获取数据
val data: String = objects(0).toString
//获取分隔符
val splitKey: String = objects(1).toString()
//切分数据
val words: Array[String] = data.split(splitKey)
//遍历写出
words.foreach(x => {
//将数据放入集合
var tmp: Array[String] = new Array[String](1)
tmp(0) = x
//写出数据到缓冲区
forward(tmp)
})
}
override def close(): Unit = {
//没有流操作
}
}
5.10 读取Json数据拓展
- 读取嵌套json数据
{"name":"zhangsan","score":100,"infos":{"age":30,"gender":"man"}},
{"name":"lisi","score":66,"infos":{"age":28,"gender":"feman"}},
{"name":"wangwu","score":77,"infos":{"age":15,"gender":"feman"}}
object SparkSQLDemo8 {
def main(args: Array[String]): Unit = {
//创建sparksession
val spark = SparkSession.builder()
.appName("demo8")
.master("local[*]")
.getOrCreate()
//读取嵌套的json文件
val frame: DataFrame = spark.read.json(this.getClass.getClassLoader.getResource("student.json").getPath)
frame.createOrReplaceTempView("infosView")
spark.sql("select name,infos.age,score,infos.gender from infosView").show(100)
/**
* +--------+---+-----+------+
* | name|age|score|gender|
* +--------+---+-----+------+
* |zhangsan| 30| 100| man|
* | lisi| 28| 66| feman|
* | wangwu| 15| 77| feman|
* +--------+---+-----+------+
**/
}
}
- 读取嵌套jsonArray数据
{"name":"zhangsan","age":18,"scores":[{"yuwen":98,"shuxue":90,"yingyu":100,"xueqi":1},{"yuwen":77,"shuxue":33,"yingyu":55,"xueqi":2}]},
{"name":"lisi","age":19,"scores":[{"yuwen":58,"shuxue":50,"yingyu":78,"xueqi":1},{"yuwen":66,"shuxue":88,"yingyu":66,"xueqi":2}]},
{"name":"wangwu","age":17,"scores":[{"yuwen":18,"shuxue":90,"yingyu":45,"xueqi":1},{"yuwen":88,"shuxue":77,"yingyu":44,"xueqi":2}]},
{"name":"zhaoliu","age":20,"scores":[{"yuwen":68,"shuxue":23,"yingyu":63,"xueqi":1},{"yuwen":44,"shuxue":55,"yingyu":77,"xueqi":2}]},
{"name":"tianqi","age":22,"scores":[{"yuwen":88,"shuxue":91,"yingyu":41,"xueqi":1},{"yuwen":55,"shuxue":66,"yingyu":88,"xueqi":2}]}
object SparkSQLDemo8 {
def main(args: Array[String]): Unit = {
//创建sparksession
val spark = SparkSession.builder()
.appName("demo8")
.master("local[*]")
.getOrCreate()
//读取嵌套的json文件
val frame: DataFrame = spark.read.json(this.getClass.getClassLoader.getResource("student.json").getPath)
frame.createOrReplaceTempView("infosView")
spark.sql("select name,age,explode(scores) from infosView")
//不折叠显示
frame.show(false)
/**
* +---+--------+-----------------------------------+
* |age|name |scores |
* +---+--------+-----------------------------------+
* |18 |zhangsan|[[90, 1, 100, 98], [33, 2, 55, 77]]|
* |19 |lisi |[[50, 1, 78, 58], [88, 2, 66, 66]] |
* |17 |wangwu |[[90, 1, 45, 18], [77, 2, 44, 88]] |
* |20 |zhaoliu |[[23, 1, 63, 68], [55, 2, 77, 44]] |
* |22 |tianqi |[[91, 1, 41, 88], [66, 2, 88, 55]] |
* +---+--------+-----------------------------------+
*/
}
}
5.11 读取Mysql数据
- 使用Mysql
create database spark;
use spark;
create table person(id varchar(12),name varchar(12),age int(10));
insert into person values('1','zhangsan',18),('2','lisi',19),('3','wangwu',20);
object SparkSQLDemo9 {
def main(args: Array[String]): Unit = {
//创建sparksession
val spark = SparkSession.builder()
.appName("demo9")
.master("local[*]")
.getOrCreate()
val frame: DataFrame = spark.read.format("jdbc")
.option("url", "jdbc:mysql://localhost:3306/spark")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "root")
.option("dbtable", "person")
.load()
frame.show()
/**
* +---+--------+---+
* | id| name|age|
* +---+--------+---+
* | 1|zhangsan| 18|
* | 2| lisi| 19|
* | 3| wangwu| 20|
* +---+--------+---+
*/
}
}
5.12 读取Hive数据
- 使用Hive
//创建数据库
CREATE DATABASE dwd
//创建表
CREATE EXTERNAL TABLE `dwd.student`(
`ID` bigint COMMENT '',
`CreatedBy` string COMMENT '创建人',
`CreatedTime` string COMMENT '创建时间',
`UpdatedBy` string COMMENT '更新人',
`UpdatedTime` string COMMENT '更新时间',
`Version` int COMMENT '版本号',
`name` string COMMENT '姓名'
) COMMENT '学生表'
PARTITIONED BY (
`dt` String COMMENT 'partition'
)
row format delimited fields terminated by '\t'
stored as parquet
location '/warehouse/dwd/test/student/'
tblproperties ("parquet.compression"="snappy")
//添加数据
INSERT INTO TABLE dwd.student partition(dt='2020-04-05') VALUES(1,"heaton","2020-04-05","","","1","zhangsan")
INSERT INTO TABLE dwd.student partition(dt='2020-04-06') VALUES(2,"heaton","2020-04-06","","","1","lisi")
- 将服务端配置hive-site.xml,放入resources路径
object SparkSQLDemo10 {
def main(args: Array[String]): Unit = {
//创建sparksession
val spark = SparkSession.builder()
.appName("demo10")
.master("local[*]")
.enableHiveSupport() //启用hive
.getOrCreate()
spark.sql("select * from dwd.student").show()
/**
* +---+---------+-----------+---------+-----------+-------+--------+----------+
* | id|createdby|createdtime|updatedby|updatedtime|version| name| dt|
* +---+---------+-----------+---------+-----------+-------+--------+----------+
* | 1| heaton| 2020-04-05| | | 1|zhangsan|2020-04-05|
* | 2| heaton| 2020-04-06| | | 1| lisi|2020-04-06|
* +---+---------+-----------+---------+-----------+-------+--------+----------+
*/
}
}
5.13 读取Hbase数据
object SparkSQLDemo11 {
def main(args: Array[String]): Unit = {
//创建sparksession
val spark = SparkSession.builder()
.appName("demo11")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.master("local[*]")
.getOrCreate()
import spark.implicits._
val hconf: Configuration = HBaseConfiguration.create
hconf.set(HConstants.ZOOKEEPER_QUORUM, "cdh01.cm,cdh02.cm,cdh03.cm")
hconf.set(HConstants.ZOOKEEPER_CLIENT_PORT, "2181")
//一定要创建这个hbaseContext, 因为后面写入时会用到它,不然空指针
val hBaseContext = new HBaseContext(spark.sparkContext, hconf)
//构建DataSet
val ds1: Dataset[HBaseRecord] = spark.sparkContext.parallelize(1.to(256)).map(i => new HBaseRecord(i, "Hbase")).toDS()
//定义映射的catalog
val catalog: String = "{" +
" \"table\":{\"namespace\":\"default\", \"name\":\"test1\"}," +
" \"rowkey\":\"key\"," +
" \"columns\":{" +
" \"f0\":{\"cf\":\"rowkey\", \"col\":\"key\", \"type\":\"string\"}," +
" \"f1\":{\"cf\":\"cf1\", \"col\":\"f1\", \"type\":\"boolean\"}," +
" \"f2\":{\"cf\":\"cf2\", \"col\":\"f2\", \"type\":\"double\"}," +
" \"f3\":{\"cf\":\"cf3\", \"col\":\"f3\", \"type\":\"float\"}," +
" \"f4\":{\"cf\":\"cf4\", \"col\":\"f4\", \"type\":\"int\"}," +
" \"f5\":{\"cf\":\"cf5\", \"col\":\"f4\", \"type\":\"bigint\"}," +
" \"f6\":{\"cf\":\"cf6\", \"col\":\"f6\", \"type\":\"smallint\"}," +
" \"f7\":{\"cf\":\"cf7\", \"col\":\"f7\", \"type\":\"string\"}," +
" \"f8\":{\"cf\":\"cf8\", \"col\":\"f8\", \"type\":\"tinyint\"}" +
" }" +
" }"
//数据写入Hbase
ds1.write
.format("org.apache.hadoop.hbase.spark")
.option(HBaseTableCatalog.tableCatalog, catalog)
.option(HBaseTableCatalog.newTable, 5)
.mode(SaveMode.Overwrite) //写入5个分区
.save()
//读取Hbase数据
val ds2: DataFrame = spark.read
.format("org.apache.hadoop.hbase.spark")
.option(HBaseTableCatalog.tableCatalog, catalog)
.load()
ds2.show(10)
/**
* +------------+-----+---+---+------------+-----+-----+---+---+
* | f7| f1| f4| f6| f0| f3| f2| f5| f8|
* +------------+-----+---+---+------------+-----+-----+---+---+
* |String:Hbase| true|100|100|row100:Hbase|100.0|100.0|100|100|
* |String:Hbase|false|101|101|row101:Hbase|101.0|101.0|101|101|
* |String:Hbase| true|102|102|row102:Hbase|102.0|102.0|102|102|
* |String:Hbase|false|103|103|row103:Hbase|103.0|103.0|103|103|
* |String:Hbase| true|104|104|row104:Hbase|104.0|104.0|104|104|
* |String:Hbase|false|105|105|row105:Hbase|105.0|105.0|105|105|
* |String:Hbase| true|106|106|row106:Hbase|106.0|106.0|106|106|
* |String:Hbase|false|107|107|row107:Hbase|107.0|107.0|107|107|
* |String:Hbase| true|108|108|row108:Hbase|108.0|108.0|108|108|
* |String:Hbase|false|109|109|row109:Hbase|109.0|109.0|109|109|
* +------------+-----+---+---+------------+-----+-----+---+---+
*/
}
}
case class HBaseRecord(f0: String, f1: Boolean, f2: Double, f3: Float, f4: Int, f5: Long, f6: Short, f7: String, f8: Byte) {
def this(i: Int, s: String) {
this(s"row$i:$s", i % 2 == 0, i.toDouble, i.toFloat, i, i.toLong, i.toShort, s"String:$s", i.toByte)
}
}

6 Spark Streaming
Spark Streaming是Spark核心API扩展,用于构建弹性、高吞吐、容错的在线数据流的流式处理程序
数据来源有多种:Kafla、Flume、TCP等
Spark Streaming中提供的高级抽象:Discretized stream,DStream表示一个连续的数据流,可以由来自数据源的输入数据流来创建,也可以通过在其他DStream上转换得到,一个DStream是由一个RDD序列来表示的,对DStream的操作都会转换成对其里面的RDD的操作
- 执行流程
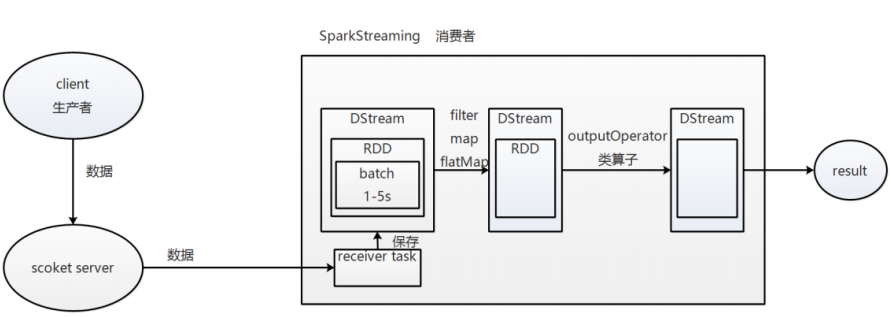
Receiver task 是 7*24h 一直在执行,一直接收数据,将接收到的数据保存到 batch 中,假设 batch interval 为 5s,
那么把接收到的数据每隔 5s 切割到一个 batch,因为 batch 是没有分布式计算的特性的,而 RDD 有,
所以把 batch 封装到 RDD 中,又把 RDD 封装到DStream 中进行计算,在第 5s 的时候,计算前 5s 的数据,
假设计算 5s 的数据只需要 3s,那么第 5-8s 一边计算任务,一边接收数据,第 9-11s 只是接收数据,然后在第 10s 的时
候,循环上面的操作。如果 job 执行时间大于 batch interval,那么未执行的数据会越攒越多,最终导致 Spark集群崩溃。注意:Receiver (接收器)在新版本中已经去除了。
6.1 端口监听案例
object SparkStreamingDemo1 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("demo1").setMaster("local[*]")
//创建一个10秒封装一次数据的StreamingContext
val ssc: StreamingContext = new StreamingContext(conf, Seconds(10))
//监控cdh01.cm上11111端口
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("cdh01.cm", 11111)
val words: DStream[(String, Int)] = lines.flatMap(_.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
//行动算子打印
words.print()
//启动StreamingContext并等待终止
ssc.start()
ssc.awaitTermination()
}
}
- 监听服务器,间隔10秒发送数据测试如下
nc -lk 11111



6.2 对接Kafka
生产中这种是最常用的方式
object SparkStreamingDemo2 {
def main(args: Array[String]): Unit = {
val brokers = "cdh01.cm:9092,cdh02.cm:9092,cdh03.cm:9092"
val topic = "bigdata"
val cgroup = "test"
val params: Map[String, Object] = Map(
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
ConsumerConfig.GROUP_ID_CONFIG -> cgroup,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val conf: SparkConf = new SparkConf().setAppName("demo2").set("spark.serializer", "org.apache.spark.serializer.KryoSerializer").setMaster("local[*]")
//创建一个10秒封装一次数据的StreamingContext
val ssc: StreamingContext = new StreamingContext(conf, Seconds(10))
//Streaming对接kafka
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](List(topic), params)
)
kafkaDStream.print
//启动StreamingContext并等待终止
ssc.start()
ssc.awaitTermination()
}
}
- 使用Kafka
kafka-console-producer --broker-list cdh01.cm:9092,cdh02.cm:9092,cdh03.cm:9092 --topic bigdata

ConsumerRecord(topic = bigdata, partition = 0, offset = 13, CreateTime = 1587194334601, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = a)
ConsumerRecord(topic = bigdata, partition = 0, offset = 14, CreateTime = 1587194335215, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = b)
ConsumerRecord(topic = bigdata, partition = 0, offset = 15, CreateTime = 1587194335975, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = c)
ConsumerRecord(topic = bigdata, partition = 0, offset = 16, CreateTime = 1587194336887, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = d)
ConsumerRecord(topic = bigdata, partition = 0, offset = 17, CreateTime = 1587194337912, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = e)
6.3 Checkpoint
Spark的一种持久化方式,并不推荐
这种方式很容易做到,但是有以下的缺点:
多次输出,结果必须满足幂等性
事务性不可选
如果代码变更不能从Checkpoint恢复,不过你可以同时运行新任务和旧任务,因为输出结果具有等幂性
object SparkStreamingDemo3 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("demo3").set("spark.serializer", "org.apache.spark.serializer.KryoSerializer").setMaster("local[*]")
val ssc: StreamingContext = StreamingContext.getActiveOrCreate("./ck", createSSC)
//启动StreamingContext并等待终止
ssc.start()
ssc.awaitTermination()
}
def createSSC() : StreamingContext = {
val brokers = "cdh01.cm:9092,cdh02.cm:9092,cdh03.cm:9092"
val topic = "bigdata"
val cgroup = "test"
val params: Map[String, Object] = Map(
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
ConsumerConfig.GROUP_ID_CONFIG -> cgroup,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val conf: SparkConf = new SparkConf().setAppName("demo2").set("spark.serializer", "org.apache.spark.serializer.KryoSerializer").setMaster("local[*]")
//创建一个10秒封装一次数据的StreamingContext
val ssc: StreamingContext = new StreamingContext(conf, Seconds(10))
//设置检查点
ssc.checkpoint("./ck")
//Streaming对接kafka
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](List(topic), params)
)
kafkaDStream.print
ssc
}
}
- 使用Kafka
kafka-console-producer --broker-list cdh01.cm:9092,cdh02.cm:9092,cdh03.cm:9092 --topic bigdata

ConsumerRecord(topic = bigdata, partition = 0, offset = 18, CreateTime = 1587195534875, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 1)
ConsumerRecord(topic = bigdata, partition = 0, offset = 19, CreateTime = 1587195535127, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 2)
ConsumerRecord(topic = bigdata, partition = 0, offset = 20, CreateTime = 1587195535439, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 3)
ConsumerRecord(topic = bigdata, partition = 0, offset = 21, CreateTime = 1587195535903, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 4)
- 将程序关闭,在Kafka中继续写入数据,在启动程序

ConsumerRecord(topic = bigdata, partition = 0, offset = 22, CreateTime = 1587195646015, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 5)
ConsumerRecord(topic = bigdata, partition = 0, offset = 23, CreateTime = 1587195646639, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 6)
ConsumerRecord(topic = bigdata, partition = 0, offset = 24, CreateTime = 1587195647207, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 7)
ConsumerRecord(topic = bigdata, partition = 0, offset = 25, CreateTime = 1587195647647, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 8)
6.4 转换算子
| Transformation | 含义 |
|---|---|
| map(func) | 通过函数func传递源DStream的每个元素,返回一个新的DStream。 |
| flatMap(func) | 类似于map,但是每个输入项可以映射到0或多个输出项。 |
| filter(func) | 通过只选择func返回true的源DStream的记录来返回一个新的DStream。 |
| repartition(numPartitions) | 重分区,通过创建或多或少的分区来更改此DStream中的并行度级别。 |
| union(otherStream) | 返回一个新的DStream,它包含源DStream和其他DStream中的元素的联合。 |
| count() | 通过计算源DStream的每个RDD中的元素数量,返回一个新的单元素RDD DStream。 |
| reduce(func) | 使用func函数(函数接受两个参数并返回一个参数)聚合源DStream的每个RDD中的元素,从而返回单元素RDDs的新DStream。这个函数应该是结合律和交换律的,这样才能并行计算。 |
| countByValue() | 当对K类型的元素的DStream调用时,返回一个新的(K, Long)对的DStream,其中每个键的值是它在源DStream的每个RDD中的频率。 |
| reduceByKey(func, [numTasks]) | 当对(K, V)对的DStream调用时,返回一个新的(K, V)对的DStream,其中每个键的值使用给定的reduce函数进行聚合。注意:默认情况下,这将使用Spark的默认并行任务数量(本地模式为2,在集群模式下,该数量由config属性Spark .default.parallelism决定)来进行分组。我们可以传递一个可选的numTasks参数来设置不同数量的任务。 |
| join(otherStream, [numTasks]) | 当调用两个(K, V)和(K, W)对的DStream时,返回一个新的(K, (V, W))对的DStream,其中包含每个Key的所有元素对。 |
| cogroup(otherStream, [numTasks]) | 当调用(K, V)和(K, W)对的DStream时,返回一个新的(K, Seq[V], Seq[W])元组DStream。 |
| transform(func) | 通过将RDD-to-RDD函数应用于源DStream的每个RDD,返回一个新的DStream。它可以用于应用DStream API中没有公开的任何RDD操作。例如将数据流中的每个批处理与另一个数据集连接的功能并不直接在DStream API中公开。但是你可以很容易地使用transform来实现这一点。这带来了非常强大的可能性。例如,可以通过将输入数据流与预先计算的垃圾信息(也可能是使用Spark生成的)结合起来进行实时数据清理 |
| updateStateByKey(func) | 返回一个新的“state”DStream,其中每个Key的状态通过将给定的函数应用于Key的前一个状态和Key的新值来更新。这可以用于维护每个Key的任意状态数据。要使用它,您需要执行两个步骤:(1).定义状态——状态可以是任意数据类型;(2).定义状态更新函数——用函数指定如何使用输入流中的前一个状态和新值更新状态。 |
object SparkStreamingDemo4 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("demo4").setMaster("local[*]")
//创建一个10秒封装一次数据的StreamingContext
val ssc: StreamingContext = new StreamingContext(conf, Seconds(10))
//监控cdh01.cm上11111端口
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("cdh01.cm", 11111)
//转换成RDD操作
val words: DStream[(String, Int)] = lines.transform(rdd => {
rdd.flatMap(_.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
})
//行动算子打印
words.print()
//启动StreamingContext并等待终止
ssc.start()
ssc.awaitTermination()
}
}
- 监听服务器,间隔10秒发送数据测试如下
nc -lk 11111
6.5 行动算子
| Output Operation | 含义 |
|---|---|
| print() | 在运行流应用程序的驱动程序节点上打印DStream中每批数据的前10个元素。这对于开发和调试非常有用。这在Python API中称为pprint()。 |
| saveAsTextFiles(prefix, [suffix]) | 将此DStream的内容保存为文本文件。每个批处理间隔的文件名是根据前缀和后缀生成的:“prefix- time_in_ms [.suffix]”。 |
| saveAsObjectFiles(prefix, [suffix]) | 将此DStream的内容保存为序列化Java对象的sequencefile。每个批处理间隔的文件名是根据前缀和后缀生成的:“prefix- time_in_ms [.suffix]”。这在Python API中是不可用的。 |
| saveAsHadoopFiles(prefix, [suffix]) | 将这个DStream的内容保存为Hadoop文件。每个批处理间隔的文件名是根据前缀和后缀生成的:“prefix- time_in_ms [.suffix]”。这在Python API中是不可用的。 |
| foreachRDD(func) | 对流生成的每个RDD应用函数func的最通用输出操作符。这个函数应该将每个RDD中的数据推送到外部系统,例如将RDD保存到文件中,或者通过网络将其写入数据库。请注意,函数func是在运行流应用程序的驱动程序进程中执行的,其中通常会有RDD操作,这将强制流RDDs的计算。在func中创建远程连接时可以使用foreachPartition 替换foreach操作以降低系统的总体吞吐量 |
6.6 有状态转换
使用updateStateByKey配合检查点,可以做到从头开始保存数据。
object SparkStreamingDemo5 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("demo5").setMaster("local[*]")
//创建一个10秒封装一次数据的StreamingContext
val ssc: StreamingContext = new StreamingContext(conf, Seconds(10))
//使用updateStateByKey必须设置检查点
ssc.checkpoint("./ck")
//监控cdh01.cm上11111端口
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("cdh01.cm", 11111)
def f(seq: Seq[Int], opt: Option[Int]): Some[Int] = {
Some(seq.sum + opt.getOrElse(0)
)
}
//使用updateStateByKey,根据Key保存前面接收序列里的数据为一个序列
val words: DStream[(String, Int)] = lines.flatMap(_.split(" ")).map((_, 1)).updateStateByKey(f)
//行动算子打印
words.print()
//启动StreamingContext并等待终止
ssc.start()
ssc.awaitTermination()
}
}
- 监听服务器,间隔10秒发送数据测试如下
nc -lk 11111

(aa,1)
(dd,1)
(bb,1)
(cc,1)
- 间隔10秒后
(aa,3)
(dd,1)
(bb,1)
(cc,3)
6.7 窗口函数
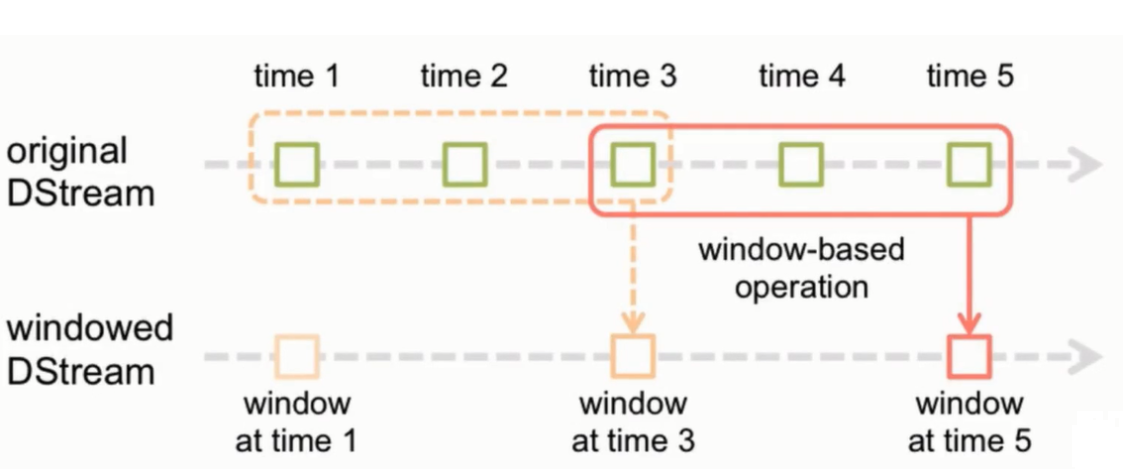
窗口计算,允许你在滑动的数据窗口上应用转换。
每当窗口滑过源DStream时,属于该窗口的源RDDs就被组合起来并对其进行操作,从而生成窗口化DStream的RDDs。
上图中操作应用于最后3个时间单位的数据,并以2个时间单位进行移动。这表明任何窗口操作都需要指定两个参数:
窗口长度(windowLength)——窗口的持续时间
滑动间隔(slideInterval)——执行窗口操作的间隔
这两个参数必须是批处理间隔的倍数
| Transformation | 含义 |
|---|---|
| window(windowLength, slideInterval) | 返回一个新的DStream,它是基于源DStream的窗口批次计算的。 |
| countByWindow(windowLength, slideInterval) | 返回流中元素的滑动窗口计数。 |
| reduceByWindow(func, windowLength, slideInterval) | 返回一个新的单元素流,该流是使用func在滑动间隔上聚合流中的元素创建的。这个函数应该是结合律和交换律的,这样才能并行地正确计算。 |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | 当对(K, V)对的DStream调用时,返回一个新的(K, V)对的DStream,其中每个Key的值使用给定的reduce函数func在滑动窗口中分批聚合。注意:默认情况下,这将使用Spark的默认并行任务数量(本地模式为2,在集群模式下,该数量由config属性Spark .default.parallelism决定)来进行分组。您可以传递一个可选的numTasks参数来设置不同数量的任务。 |
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | 上面reduceByKeyAndWindow()的一个更有效的版本,其中每个窗口的reduce值是使用前一个窗口的reduce值增量计算的。这是通过减少进入滑动窗口的新数据和“反向减少”离开窗口的旧数据来实现的。例如,在窗口滑动时“添加”和“减去”键的计数。但是,它只适用于“可逆约简函数”,即具有相应“逆约简”函数的约简函数(取invFunc参数)。与reduceByKeyAndWindow类似,reduce任务的数量可以通过一个可选参数进行配置。注意,必须启用checkpoint才能使用此操作。 |
| countByValueAndWindow(windowLength, slideInterval, [numTasks]) | 当对(K, V)对的DStream调用时,返回一个新的(K, Long)对的DStream,其中每个Key的值是它在滑动窗口中的频率。与reduceByKeyAndWindow类似,reduce任务的数量可以通过一个可选参数进行配置。 |
object SparkStreamingDemo6 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("demo6").setMaster("local[*]")
//创建一个10秒封装一次数据的StreamingContext
val ssc: StreamingContext = new StreamingContext(conf, Seconds(5))
//监控cdh01.cm上11111端口
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("cdh01.cm", 11111)
// Duration.of(10,TimeUnit.SECONDS)
//使用窗口,比封装数据时间多一倍,意思是相当于包含两个窗口,滑动间隔为一个窗口
val words: DStream[(String, Int)] = lines.window(Seconds(10), Seconds(5)).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
//行动算子打印
words.print()
//启动StreamingContext并等待终止
ssc.start()
ssc.awaitTermination()
}
}
- 监听服务器,间隔10秒发送数据测试如下
nc -lk 11111

每间隔5秒输如一行,结果集如下
(aa,1)
(bb,1)
(cc,1)
(aa,2)
(bb,2)
(cc,1)
(aa,2)
(bb,1)
(cc,1)
- 图解
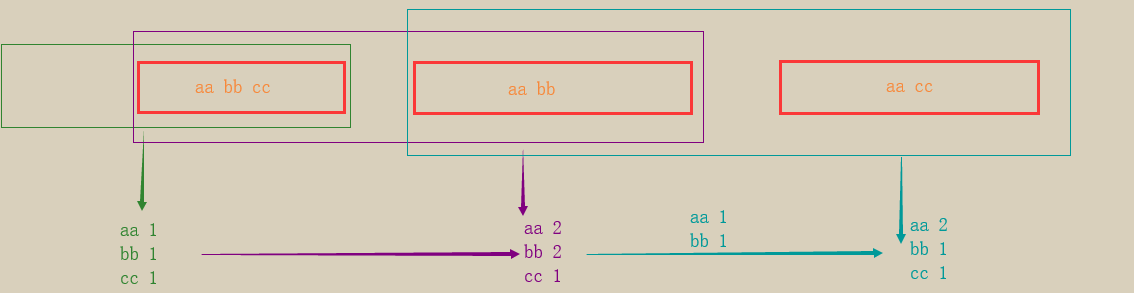
7 Spark内存管理
7.1 堆内和堆外内存
作为一个JVM进程,Executor的内存管理建立在JVM的内存管理之上,Spark对JVM的堆内(On-head)空间进行了更为详细的分配,以充分利用内存。同时,Spark引入了堆外(Off-head)内存,使之可以直接在工作节点的系统内存中开辟空间,进一步优化了内存的使用。堆内内存受到JVM统一管理,堆外内存式直接向操作系统进行内存的申请和释放。

- 堆内内存
堆内内存的大小,由Spark应用程序启动时的 executor-memory 或 spark.executor.memory参数配置,Executor内运行的并发任务共享JVM堆内内存,这些任务在缓存RDD数据和广播(Broadcast)数据时占用的内存被规划为储存(Storage)内存,而这些任务在执行Shuffle时占用的内存被规划委执行(Executor)内存,剩余的部分不做特殊规划,那些Spark内部的对象实例,或者用户定义的Spark应用程序中的对象实例,均占用剩余的空间,不同的管理模式下,这三部分占用的空间大小各部相同
Spark对堆内内存的管理是一种逻辑上的“规划式”管理,因为对象实际占用内存的申请和释放都是由JVM完成,Spark只能在申请后和释放前记录这些内存
申请内存流程如下:
- Spark记录该对象释放的内存,删除该对象的引用
- 等待JVM的垃圾回收机制释放该对象占用的堆内内存
JVM的对象可以序列化的方式储存,序列化的过程是将对象转换成为二进制字节流,本质上可以理解为将非连续空间的链式储存转化为连续空间或块式储存,在访问时则需要进行序列化的逆过程--反序列化,将字节流转化成对象,序列化的方式可以节省存储空间,但增加了内存的读取时候的计算开销
对于 Spark 中序列化的对象,由于是字节流的形式,其占用的内存大小可直接计算,而对于非序列化的对象,其占用的内存是通过周期性地采样近似估算而得,即并不是每次新增的数据项都会计算一次占用的内存大小,这种方法降低了时间开销但是有可能误差较大,导致某一时刻的实际内存有可能远远超出预期[2]。此外,在被 Spark 标记为释放的对象实例,很有可能在实际上并没有被 JVM 回收,导致实际可用的内存小于 Spark 记录的可用内存。所以 Spark 并不能准确记录实际可用的堆内内存,从而也就无法完全避免内存溢出(OOM, Out of Memory)的异常。
虽然不能精准控制堆内内存的申请和释放,但 Spark 通过对存储内存和执行内存各自独立的规划管理,可以决定是否要在存储内存里缓存新的 RDD,以及是否为新的任务分配执行内存,在一定程度上可以提升内存的利用率,减少异常的出现。
- 堆外内存
为了进一步优化内存的使用以及提高 Shuffle 时排序的效率,Spark 引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,存储经过序列化的二进制数据。利用 JDK Unsafe API(从 Spark 2.0 开始,在管理堆外的存储内存时不再基于 Tachyon,而是与堆外的执行内存一样,基于 JDK Unsafe API 实现[3]),Spark 可以直接操作系统堆外内存,减少了不必要的内存开销,以及频繁的 GC 扫描和回收,提升了处理性能。堆外内存可以被精确地申请和释放,而且序列化的数据占用的空间可以被精确计算,所以相比堆内内存来说降低了管理的难度,也降低了误差。
在默认情况下堆外内存并不启用,可通过配置 spark.memory.offHeap.enabled 参数启用,并由 spark.memory.offHeap.size 参数设定堆外空间的大小。除了没有 other 空间,堆外内存与堆内内存的划分方式相同,所有运行中的并发任务共享存储内存和执行内存。
7.2 内存空间管理
7.2.1 静态内存管理
在 Spark 最初采用的静态内存管理机制下,存储内存、执行内存和其他内存的大小在 Spark 应用程序运行期间均为固定的,但用户可以应用程序启动前进行配置
- 静态内存管理图-堆内

可用的堆内内存的大小需要按照下面的方式计算
- 可用的存储内存 = systemMaxMemory * spark.storage.memoryFraction * spark.storage.safetyFraction
- 可用的执行内存 = systemMaxMemory * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction
其中 systemMaxMemory 取决于当前 JVM 堆内内存的大小,最后可用的执行内存或者存储内存要在此基础上与各自的 memoryFraction 参数和 safetyFraction 参数相乘得出。上述计算公式中的两个 safetyFraction 参数,其意义在于在逻辑上预留出 1-safetyFraction 这么一块保险区域,降低因实际内存超出当前预设范围而导致 OOM 的风险(上文提到,对于非序列化对象的内存采样估算会产生误差)。值得注意的是,这个预留的保险区域仅仅是一种逻辑上的规划,在具体使用时 Spark 并没有区别对待,和“其它内存”一样交给了 JVM 去管理。
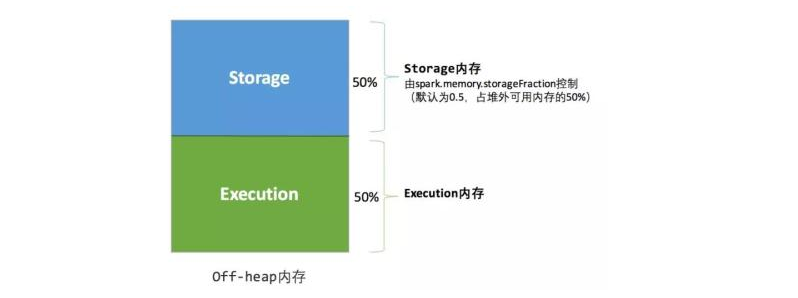
堆外的空间分配较为简单,只有存储内存和执行内存,如图所示。可用的执行内存和存储内存占用的空间大小直接由参数 spark.memory.storageFraction 决定,由于堆外内存占用的空间可以被精确计算,所以无需再设定保险区域。
- 静态内存管理图- 堆外
静态内存管理机制实现起来较为简单,但如果用户不熟悉 Spark 的存储机制,或没有根据具体的数据规模和计算任务或做相应的配置,很容易造成"一半海水,一半火焰"的局面,即存储内存和执行内存中的一方剩余大量的空间,而另一方却早早被占满,不得不淘汰或移出旧的内容以存储新的内容。由于新的内存管理机制的出现,这种方式目前已经很少有开发者使用,出于兼容旧版本的应用程序的目的,Spark 仍然保留了它的实现。
7.2.2 统一内存管理
- 动态占用机制图
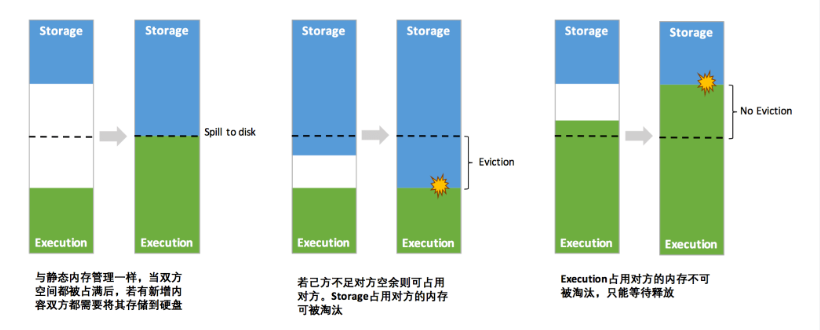
凭借统一内存管理机制,Spark 在一定程度上提高了堆内和堆外内存资源的利用率,降低了开发者维护 Spark 内存的难度,但并不意味着开发者可以高枕无忧。譬如,所以如果存储内存的空间太大或者说缓存的数据过多,反而会导致频繁的全量垃圾回收,降低任务执行时的性能,因为缓存的 RDD 数据通常都是长期驻留内存的 。所以要想充分发挥 Spark 的性能,需要开发者进一步了解存储内存和执行内存各自的管理方式和实现原理。
7.2.3 存储内存管理
- RDD 的持久化机制
弹性分布式数据集(RDD)作为 Spark 最根本的数据抽象,是只读的分区记录(Partition)的集合,只能基于在稳定物理存储中的数据集上创建,或者在其他已有的 RDD 上执行转换(Transformation)操作产生一个新的 RDD。转换后的 RDD 与原始的 RDD 之间产生的依赖关系,构成了血统(Lineage)。凭借血统,Spark 保证了每一个 RDD 都可以被重新恢复。但 RDD 的所有转换都是惰性的,即只有当一个返回结果给 Driver 的行动(Action)发生时,Spark 才会创建任务读取 RDD,然后真正触发转换的执行。
Task 在启动之初读取一个分区时,会先判断这个分区是否已经被持久化,如果没有则需要检查 Checkpoint 或按照血统重新计算。所以如果一个 RDD 上要执行多次行动,可以在第一次行动中使用 persist 或 cache 方法,在内存或磁盘中持久化或缓存这个 RDD,从而在后面的行动时提升计算速度。事实上,cache 方法是使用默认的 MEMORY_ONLY 的存储级别将 RDD 持久化到内存,故缓存是一种特殊的持久化。 堆内和堆外存储内存的设计,便可以对缓存 RDD 时使用的内存做统一的规划和管 理 (存储内存的其他应用场景,如缓存 broadcast 数据,暂时不在本文的讨论范围之内)。
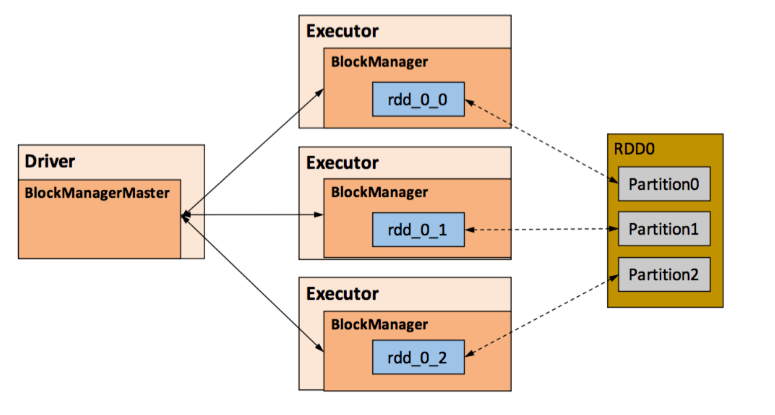
RDD 的持久化由 Spark 的 Storage 模块 [7] 负责,实现了 RDD 与物理存储的解耦合。Storage 模块负责管理 Spark 在计算过程中产生的数据,将那些在内存或磁盘、在本地或远程存取数据的功能封装了起来。在具体实现时 Driver 端和 Executor 端的 Storage 模块构成了主从式的架构,即 Driver 端的 BlockManager 为 Master,Executor 端的 BlockManager 为 Slave。Storage 模块在逻辑上以 Block 为基本存储单位,RDD 的每个 Partition 经过处理后唯一对应一个 Block(BlockId 的格式为 rdd_RDD-ID_PARTITION-ID )。Master 负责整个 Spark 应用程序的 Block 的元数据信息的管理和维护,而 Slave 需要将 Block 的更新等状态上报到 Master,同时接收 Master 的命令,例如新增或删除一个 RDD。
- Storage 模块示意图
在对 RDD 持久化时,Spark 规定的存储级别如下
- DISK_ONLY:持久化到磁盘
- DISK_ONLY_2:持久化到磁盘并且存一个副本(2个文件)
- MEMORY_ONLY:持久化到内存
- MEMORY_ONLY_2:持久化到内存并且存一个副本(2个文件)
- MEMORY_ONLY_SER:持久化到内存,并且序列化
- MEMORY_ONLY_SER_2:持久化到内存,并且序列化,还要存一个副本(2个文件)
- MEMORY_AND_DISK:持久化到内存和磁盘
- MEMORY_AND_DISK_2:持久化到内存和磁盘并且存一个副本(2个文件)
- MEMORY_AND_DISK_SER:持久化到内存和磁盘,并且序列化
- MEMORY_AND_DISK_SER_2:持久化到内存和磁盘,并且序列化,还要存一个副本(2个文件)
- OFF_HEAP:持久化在堆外内存中,Spark自己管理的内存
通过对数据结构的分析,可以看出存储级别从三个维度定义了 RDD 的 Partition(同时也就是 Block)的存储方式:
- 存储位置:磁盘/堆内内存/堆外内存。如 MEMORY_AND_DISK 是同时在磁盘和堆内内存上存储,实现了冗余备份。OFF_HEAP 则是只在堆外内存存储,目前选择堆外内存时不能同时存储到其他位置。
- 存储形式:Block 缓存到存储内存后,是否为非序列化的形式。如 MEMORY_ONLY 是非序列化方式存储,OFF_HEAP 是序列化方式存储。
- 副本数量:大于 1 时需要远程冗余备份到其他节点。如 DISK_ONLY_2 需要远程备份 1 个副本。
- RDD 缓存的过程
RDD 在缓存到存储内存之前,Partition 中的数据一般以迭代器(Iterator)的数据结构来访问,这是 Scala 语言中一种遍历数据集合的方法。通过 Iterator 可以获取分区中每一条序列化或者非序列化的数据项(Record),这些 Record 的对象实例在逻辑上占用了 JVM 堆内内存的 other 部分的空间,同一 Partition 的不同 Record 的空间并不连续。
RDD 在缓存到存储内存之后,Partition 被转换成 Block,Record 在堆内或堆外存储内存中占用一块连续的空间。将Partition由不连续的存储空间转换为连续存储空间的过程,Spark称之为"展开"(Unroll)。Block 有序列化和非序列化两种存储格式,具体以哪种方式取决于该 RDD 的存储级别。非序列化的 Block 以一种 DeserializedMemoryEntry 的数据结构定义,用一个数组存储所有的对象实例,序列化的 Block 则以 SerializedMemoryEntry的数据结构定义,用字节缓冲区(ByteBuffer)来存储二进制数据。每个 Executor 的 Storage 模块用一个链式 Map 结构(LinkedHashMap)来管理堆内和堆外存储内存中所有的 Block 对象的实例[6],对这个 LinkedHashMap 新增和删除间接记录了内存的申请和释放。
因为不能保证存储空间可以一次容纳 Iterator 中的所有数据,当前的计算任务在 Unroll 时要向 MemoryManager 申请足够的 Unroll 空间来临时占位,空间不足则 Unroll 失败,空间足够时可以继续进行。对于序列化的 Partition,其所需的 Unroll 空间可以直接累加计算,一次申请。而非序列化的 Partition 则要在遍历 Record 的过程中依次申请,即每读取一条 Record,采样估算其所需的 Unroll 空间并进行申请,空间不足时可以中断,释放已占用的 Unroll 空间。如果最终 Unroll 成功,当前 Partition 所占用的 Unroll 空间被转换为正常的缓存 RDD 的存储空间。
- Spark Unroll 示意图
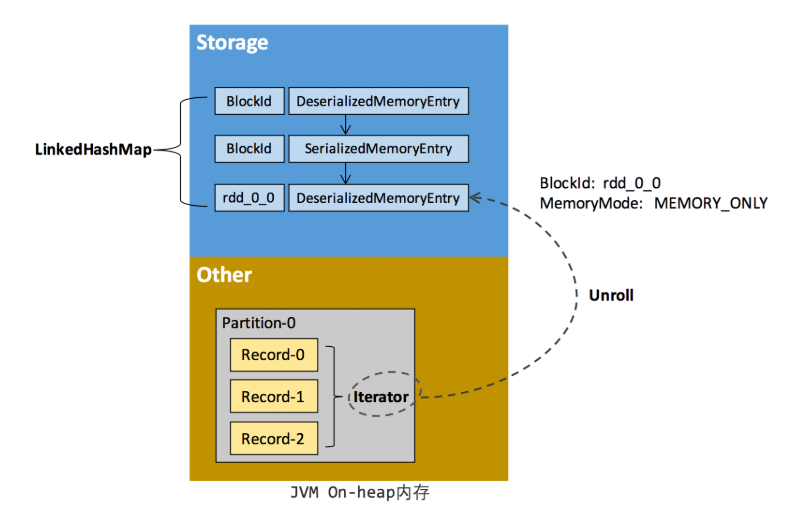
在静态内存管理时,Spark 在存储内存中专门划分了一块 Unroll 空间,其大小是固定的,统一内存管理时则没有对 Unroll 空间进行特别区分,当存储空间不足时会根据动态占用机制进行处理。
- 淘汰和落盘
由于同一个 Executor 的所有的计算任务共享有限的存储内存空间,当有新的 Block 需要缓存但是剩余空间不足且无法动态占用时,就要对 LinkedHashMap 中的旧 Block 进行淘汰(Eviction),而被淘汰的 Block 如果其存储级别中同时包含存储到磁盘的要求,则要对其进行落盘(Drop),否则直接删除该 Block。
存储内存的淘汰规则为:
- 被淘汰的旧 Block 要与新 Block 的 MemoryMode 相同,即同属于堆外或堆内内存
- 新旧 Block 不能属于同一个 RDD,避免循环淘汰
- 旧 Block 所属 RDD 不能处于被读状态,避免引发一致性问题
- 遍历 LinkedHashMap 中 Block,按照最近最少使用(LRU)的顺序淘汰,直到满足新 Block 所需的空间。其中 LRU 是 LinkedHashMap 的特性。
落盘的流程则比较简单,如果其存储级别符合_useDisk 为 true 的条件,再根据其_deserialized 判断是否是非序列化的形式,若是则对其进行序列化,最后将数据存储到磁盘,在 Storage 模块中更新其信息。
7.2.4 执行内存管理
- 多任务间内存分配
Executor 内运行的任务同样共享执行内存,Spark 用一个 HashMap 结构保存了任务到内存耗费的映射。每个任务可占用的执行内存大小的范围为 1/2N ~ 1/N,其中 N 为当前 Executor 内正在运行的任务的个数。每个任务在启动之时,要向 MemoryManager 请求申请最少为 1/2N 的执行内存,如果不能被满足要求则该任务被阻塞,直到有其他任务释放了足够的执行内存,该任务才可以被唤醒
- Shuffle 的内存占用
执行内存主要用来存储任务在执行 Shuffle 时占用的内存,Shuffle 是按照一定规则对 RDD 数据重新分区的过程,我们来看 Shuffle 的 Write 和 Read 两阶段对执行内存的使用:
Shuffle Write
1、若在 map 端选择普通的排序方式,会采用 ExternalSorter 进行外排,在内存中存储数据时主要占用堆内执行空间。
2、若在 map 端选择 Tungsten 的排序方式,则采用 ShuffleExternalSorter 直接对以序列化形式存储的数据排序,在内存中存储数据时可以占用堆外或堆内执行空间,取决于用户是否开启了堆外内存以及堆外执行内存是否足够。
Shuffle Read
1、在对 reduce 端的数据进行聚合时,要将数据交给 Aggregator 处理,在内存中存储数据时占用堆内执行空间。
2、如果需要进行最终结果排序,则要将再次将数据交给 ExternalSorter 处理,占用堆内执行空间。
在 ExternalSorter 和 Aggregator 中,Spark 会使用一种叫 AppendOnlyMap 的哈希表在堆内执行内存中存储数据,但在 Shuffle 过程中所有数据并不能都保存到该哈希表中,当这个哈希表占用的内存会进行周期性地采样估算,当其大到一定程度,无法再从 MemoryManager 申请到新的执行内存时,Spark 就会将其全部内容存储到磁盘文件中,这个过程被称为溢存(Spill),溢存到磁盘的文件最后会被归并(Merge)。
Shuffle Write 阶段中用到的 Tungsten 是 Databricks 公司提出的对 Spark 优化内存和 CPU 使用的计划,解决了一些 JVM 在性能上的限制和弊端。Spark 会根据 Shuffle 的情况来自动选择是否采用 Tungsten 排序。Tungsten 采用的页式内存管理机制建立在 MemoryManager 之上,即 Tungsten 对执行内存的使用进行了一步的抽象,这样在 Shuffle 过程中无需关心数据具体存储在堆内还是堆外。每个内存页用一个 MemoryBlock 来定义,并用 Object obj 和 long offset 这两个变量统一标识一个内存页在系统内存中的地址。堆内的 MemoryBlock 是以 long 型数组的形式分配的内存,其 obj 的值为是这个数组的对象引用,offset 是 long 型数组的在 JVM 中的初始偏移地址,两者配合使用可以定位这个数组在堆内的绝对地址;堆外的 MemoryBlock 是直接申请到的内存块,其 obj 为 null,offset 是这个内存块在系统内存中的 64 位绝对地址。Spark 用 MemoryBlock 巧妙地将堆内和堆外内存页统一抽象封装,并用页表(pageTable)管理每个 Task 申请到的内存页。
Tungsten 页式管理下的所有内存用 64 位的逻辑地址表示,由页号和页内偏移量组成:
- 页号:占 13 位,唯一标识一个内存页,Spark 在申请内存页之前要先申请空闲页号。
- 页内偏移量:占 51 位,是在使用内存页存储数据时,数据在页内的偏移地址。
有了统一的寻址方式,Spark 可以用 64 位逻辑地址的指针定位到堆内或堆外的内存,整个 Shuffle Write 排序的过程只需要对指针进行排序,并且无需反序列化,整个过程非常高效,对于内存访问效率和 CPU 使用效率带来了明显的提升。
Spark 的存储内存和执行内存有着截然不同的管理方式:对于存储内存来说,Spark 用一个 LinkedHashMap 来集中管理所有的 Block,Block 由需要缓存的 RDD 的 Partition 转化而成;而对于执行内存,Spark 用 AppendOnlyMap 来存储 Shuffle 过程中的数据,在 Tungsten 排序中甚至抽象成为页式内存管理,开辟了全新的 JVM 内存管理机制。
8 常规性能调优
8.1 最优资源配置
Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围内,增加资源的分配与性能的提升是成正比的,实现了最优的资源配置后,在此基础上再考虑进行后面论述的性能调优策略。
- 资源的分配在使用脚本提交Spark任务时进行指定,标准的Spark任务提交脚本如下:
spark-submit \
--class com.xxx.spark.TestSpark \
--num-executors 80 \
--driver-memory 6g \
--executor-memory 6g \
--executor-cores 3 \
/usr/opt/modules/spark/jar/spark.jar
| 名称 | 说明 |
|---|---|
| --num-executors | 配置Executor的数量 |
| --driver-memory | 配置Driver内存(影响不大) |
| --executor-memory | 配置每个Executor的内存大小 |
| --executor-cores | 配置每个Executor的CPU core数量 |
-
调节原则:尽量将任务分配的资源调节到可以使用的资源的最大限度。
-
对于具体资源的分配,我们分别讨论Spark的两种Cluster运行模式:
- 第一种是Spark Standalone模式,你在提交任务前,一定知道或者可以从运维部门获取到你可以使用的资源情况,在编写submit脚本的时候,就根据可用的资源情况进行资源的分配,比如说集群有15台机器,每台机器为8G内存,2个CPU core,那么就指定15个Executor,每个Executor分配8G内存,2个CPU core。
- 第二种是Spark Yarn模式,由于Yarn使用资源队列进行资源的分配和调度,在表写submit脚本的时候,就根据Spark作业要提交到的资源队列,进行资源的分配,比如资源队列有400G内存,100个CPU core,那么指定50个Executor,每个Executor分配8G内存,2个CPU core。
-
各项资源进行了调节后,得到的性能提升如下表
| 名称 | 解析 |
|---|---|
| 增加Executor个数 | 在资源允许的情况下,增加Executor的个数可以提高执行task的并行度。 比如有4个Executor,每个Executor有2个CPU core,那么可以并行执行8个task, 如果将Executor的个数增加到8个(资源允许的情况下),那么可以并行执行16个task,此时的并行能力提升了一倍。 |
| 增加每个Executor的CPU core个数 | 在资源允许的情况下,增加每个Executor的Cpu core个数,可以提高执行task的并行度。 比如有4个Executor,每个Executor有2个CPU core,那么可以并行执行8个task, 如果将每个Executor的CPU core个数增加到4个(资源允许的情况下), 那么可以并行执行16个task,此时的并行能力提升了一倍 |
| 增加每个Executor的内存量 | 在资源允许的情况下,增加每个Executor的内存量以后,对性能的提升有三点: 可以缓存更多的数据(即对RDD进行cache),写入磁盘的数据相应减少, 甚至可以不写入磁盘,减少了可能的磁盘IO; 可以为shuffle操作提供更多内存,即有更多空间来存放reduce端拉取的数据, 写入磁盘的数据相应减少,甚至可以不写入磁盘,减少了可能的磁盘IO; 可以为task的执行提供更多内存,在task的执行过程中可能创建很多对象, 内存较小时会引发频繁的GC,增加内存后,可以避免频繁的GC,提升整体性能。 |
- 生产环境Spark submit脚本配置
spark-submit \
--class com.xxx.spark.WordCount \
--num-executors 80 \
--driver-memory 6g \
--executor-memory 6g \
--executor-cores 3 \
--master yarn-cluster \
--queue root.default \
--conf spark.yarn.executor.memoryOverhead=2048 \
--conf spark.core.connection.ack.wait.timeout=300 \
/usr/local/spark/spark.jar
参数配置参考值:
--num-executors:50~100
--driver-memory:1G~5G
--executor-memory:6G~10G
--executor-cores:3
--master:实际生产环境一定使用yarn-cluster
8.2 RDD优化
8.2.1 RDD复用
- 在对RDD进行算子时,要避免相同的算子和计算逻辑之下对RDD进行重复的计算
- 对上图中的RDD计算架构进行修改,得到如图所示的优化结果
8.2.2 RDD持久化
在Spark中,当多次对同一个RDD执行算子操作时,每一次都会对这个RDD以之前的父RDD重新计算一次,这种情况是必须要避免的,对同一个RDD的重复计算是对资源的极大浪费,因此,必须对多次使用的RDD进行持久化,通过持久化将公共RDD的数据缓存到内存/磁盘中,之后对于公共RDD的计算都会从内存/磁盘中直接获取RDD数据。
- 对于RDD的持久化,有两点需要说明:
- RDD的持久化是可以进行序列化的,当内存无法将RDD的数据完整的进行存放的时候,可以考虑使用序列化的方式减小数据体积,将数据完整存储在内存中。
- 如果对于数据的可靠性要求很高,并且内存充足,可以使用副本机制,对RDD数据进行持久化。当持久化启用了复本机制时,对于持久化的每个数据单元都存储一个副本,放在其他节点上面,由此实现数据的容错,一旦一个副本数据丢失,不需要重新计算,还可以使用另外一个副本。
8.2.3 RDD尽可能早的filter操作
- 获取到初始RDD后,应该考虑尽早地过滤掉不需要的数据,进而减少对内存的占用,从而提升Spark作业的运行效率。
8.3 并行度调节
Spark作业中的并行度指各个stage的task的数量。
如果并行度设置不合理而导致并行度过低,会导致资源的极大浪费,例如,20个Executor,每个Executor分配3个CPU core,而Spark作业有40个task,这样每个Executor分配到的task个数是2个,这就使得每个Executor有一个CPU core空闲,导致资源的浪费。
理想的并行度设置,应该是让并行度与资源相匹配,简单来说就是在资源允许的前提下,并行度要设置的尽可能大,达到可以充分利用集群资源。合理的设置并行度,可以提升整个Spark作业的性能和运行速度。
Spark官方推荐,task数量应该设置为Spark作业总CPU core数量的2~3倍。之所以没有推荐task数量与CPU core总数相等,是因为task的执行时间不同,有的task执行速度快而有的task执行速度慢,如果task数量与CPU core总数相等,那么执行快的task执行完成后,会出现CPU core空闲的情况。如果task数量设置为CPU core总数的2~3倍,那么一个task执行完毕后,CPU core会立刻执行下一个task,降低了资源的浪费,同时提升了Spark作业运行的效率。
- Spark作业并行度的设置如下:
val conf = new SparkConf().set("spark.default.parallelism", "500")
8.4 广播大变量
默认情况下,task中的算子中如果使用了外部的变量,每个task都会获取一份变量的复本,这就造成了内存的极大消耗。一方面,如果后续对RDD进行持久化,可能就无法将RDD数据存入内存,只能写入磁盘,磁盘IO将会严重消耗性能;另一方面,task在创建对象的时候,也许会发现堆内存无法存放新创建的对象,这就会导致频繁的GC,GC会导致工作线程停止,进而导致Spark暂停工作一段时间,严重影响Spark性能。
假设当前任务配置了20个Executor,指定500个task,有一个20M的变量被所有task共用,此时会在500个task中产生500个副本,耗费集群10G的内存,如果使用了广播变量, 那么每个Executor保存一个副本,一共消耗400M内存,内存消耗减少了5倍。
广播变量在每个Executor保存一个副本,此Executor的所有task共用此广播变量,这让变量产生的副本数量大大减少。
在初始阶段,广播变量只在Driver中有一份副本。task在运行的时候,想要使用广播变量中的数据,此时首先会在自己本地的Executor对应的BlockManager中尝试获取变量,如果本地没有,BlockManager就会从Driver或者其他节点的BlockManager上远程拉取变量的复本,并由本地的BlockManager进行管理;之后此Executor的所有task都会直接从本地的BlockManager中获取变量。
8.5 Kryo序列化
默认情况下,Spark使用Java的序列化机制。Java的序列化机制使用方便,不需要额外的配置,在算子中使用的变量实现Serializable接口即可,但是,Java序列化机制的效率不高,序列化速度慢并且序列化后的数据所占用的空间依然较大。
Kryo序列化机制比Java序列化机制性能提高10倍左右,Spark之所以没有默认使用Kryo作为序列化类库,是因为它不支持所有对象的序列化,同时Kryo需要用户在使用前注册需要序列化的类型,不够方便,但从Spark 2.0.0版本开始,简单类型、简单类型数组、字符串类型的Shuffling RDDs 已经默认使用Kryo序列化方式了。
- 自定义类的Kryo序列化注册方式的实例代码如下
public class MyKryoRegistrator implements KryoRegistrator
{
@Override
public void registerClasses(Kryo kryo)
{
kryo.register(StartupReportLogs.class);
}
}
- Kryo序列化机制配置代码如下
//创建SparkConf对象
val conf = new SparkConf().setMaster(…).setAppName(…)
//使用Kryo序列化库,如果要使用Java序列化库,需要把该行屏蔽掉
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
//在Kryo序列化库中注册自定义的类集合,如果要使用Java序列化库,需要把该行屏蔽掉
conf.set("spark.kryo.registrator", "com.xxx.MyKryoRegistrator");
8.6 调节本地化等待时长
Spark作业运行过程中,Driver会对每一个stage的task进行分配。根据Spark的task分配算法,Spark希望task能够运行在它要计算的数据算在的节点(数据本地化思想),这样就可以避免数据的网络传输。通常来说,task可能不会被分配到它处理的数据所在的节点,因为这些节点可用的资源可能已经用尽,此时,Spark会等待一段时间,默认3s,如果等待指定时间后仍然无法在指定节点运行,那么会自动降级,尝试将task分配到比较差的本地化级别所对应的节点上,比如将task分配到离它要计算的数据比较近的一个节点,然后进行计算,如果当前级别仍然不行,那么继续降级。
当task要处理的数据不在task所在节点上时,会发生数据的传输。task会通过所在节点的BlockManager获取数据,BlockManager发现数据不在本地时,户通过网络传输组件从数据所在节点的BlockManager处获取数据。
网络传输数据的情况是我们不愿意看到的,大量的网络传输会严重影响性能,因此,我们希望通过调节本地化等待时长,如果在等待时长这段时间内,目标节点处理完成了一部分task,那么当前的task将有机会得到执行,这样就能够改善Spark作业的整体性能。
- Spark本地化等级
| 名称 | 解析 |
|---|---|
| PROCESS_LOCAL | 进程本地化,task和数据在同一个Executor中,性能最好。 |
| NODE_LOCAL | 节点本地化,task和数据在同一个节点中,但是task和数据不在同一个Executor中,数据需要在进程间进行传输。 |
| RACK_LOCAL | 机架本地化,task和数据在同一个机架的两个节点上,数据需要通过网络在节点之间进行传输。 |
| NO_PREF | 对于task来说,从哪里获取都一样,没有好坏之分。 |
| ANY | task和数据可以在集群的任何地方,而且不在一个机架中,性能最差。 |
在Spark项目开发阶段,可以使用client模式对程序进行测试,此时,可以在本地看到比较全的日志信息,日志信息中有明确的task数据本地化的级别,如果大部分都是PROCESS_LOCAL,那么就无需进行调节,但是如果发现很多的级别都是NODE_LOCAL、ANY,那么需要对本地化的等待时长进行调节,通过延长本地化等待时长,看看task的本地化级别有没有提升,并观察Spark作业的运行时间有没有缩短。
注意,过犹不及,不要将本地化等待时长延长地过长,导致因为大量的等待时长,使得Spark作业的运行时间反而增加了。
- 本地化等待市场设置如下:
val conf = new SparkConf().set("spark.locality.wait", "6")
9 算子调优
9.1 mapPartitions
普通的map算子对RDD中的每一个元素进行操作,而mapPartitions算子对RDD中每一个分区进行操作。如果是普通的map算子,假设一个partition有1万条数据,那么map算子中的function要执行1万次,也就是对每个元素进行操作。
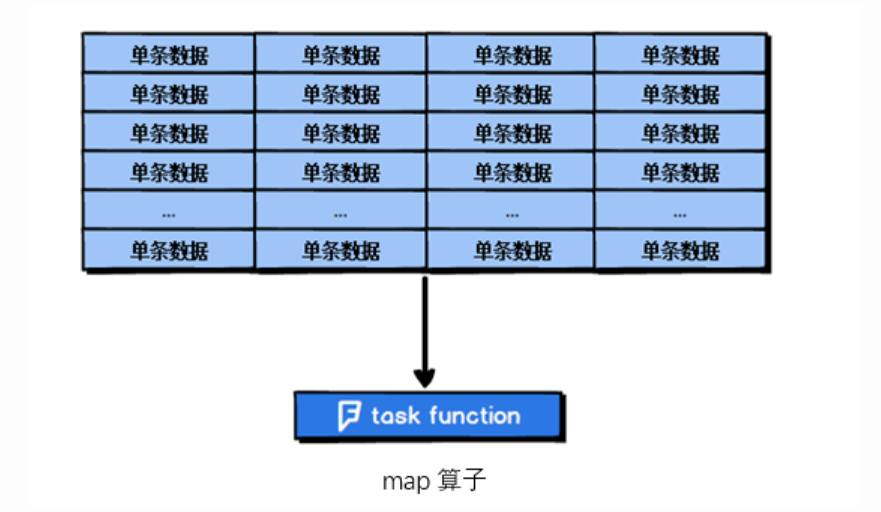
如果是mapPartition算子,由于一个task处理一个RDD的partition,那么一个task只会执行一次function,function一次接收所有的partition数据,效率比较高。
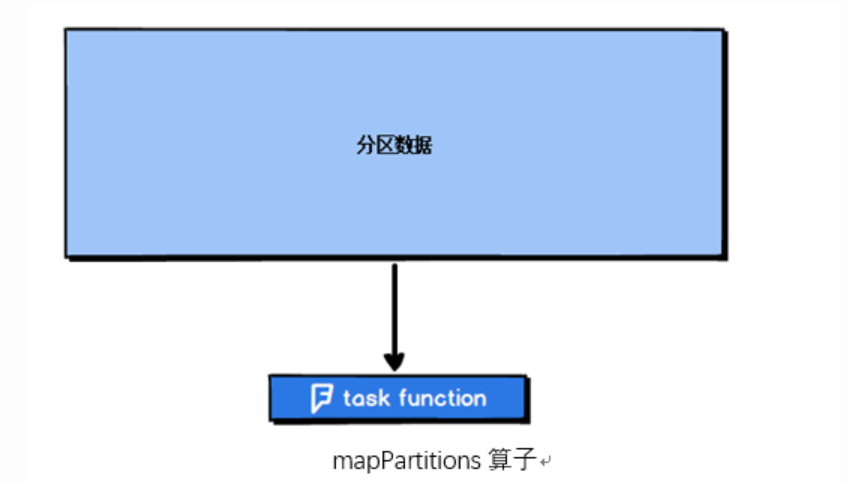
比如,当要把RDD中的所有数据通过JDBC写入数据,如果使用map算子,那么需要对RDD中的每一个元素都创建一个数据库连接,这样对资源的消耗很大,如果使用mapPartitions算子,那么针对一个分区的数据,只需要建立一个数据库连接。
mapPartitions算子也存在一些缺点:对于普通的map操作,一次处理一条数据,如果在处理了2000条数据后内存不足,那么可以将已经处理完的2000条数据从内存中垃圾回收掉;但是如果使用mapPartitions算子,但数据量非常大时,function一次处理一个分区的数据,如果一旦内存不足,此时无法回收内存,就可能会OOM,即内存溢出。
因此,mapPartitions算子适用于数据量不是特别大的时候,此时使用mapPartitions算子对性能的提升效果还是不错的。(当数据量很大的时候,一旦使用mapPartitions算子,就会直接OOM)
在项目中,应该首先估算一下RDD的数据量、每个partition的数据量,以及分配给每个Executor的内存资源,如果资源允许,可以考虑使用mapPartitions算子代替map。
9.2 foreachPartition优化数据库操作
在生产环境中,通常使用foreachPartition算子来完成数据库的写入,通过foreachPartition算子的特性,可以优化写数据库的性能。
如果使用foreach算子完成数据库的操作,由于foreach算子是遍历RDD的每条数据,因此,每条数据都会建立一个数据库连接,这是对资源的极大浪费,因此,对于写数据库操作,我们应当使用foreachPartition算子。
与mapPartitions算子非常相似,foreachPartition是将RDD的每个分区作为遍历对象,一次处理一个分区的数据,也就是说,如果涉及数据库的相关操作,一个分区的数据只需要创建一次数据库连接

- 使用了foreachPartition算子后,可以获得以下的性能提升:
- 对于我们写的function函数,一次处理一整个分区的数据;
- 对于一个分区内的数据,创建唯一的数据库连接;
- 只需要向数据库发送一次SQL语句和多组参数;
在生产环境中,全部都会使用foreachPartition算子完成数据库操作。foreachPartition算子存在一个问题,与mapPartitions算子类似,如果一个分区的数据量特别大,可能会造成OOM,即内存溢出。
9.3 filter与coalesce的配合使用
在Spark任务中我们经常会使用filter算子完成RDD中数据的过滤,在任务初始阶段,从各个分区中加载到的数据量是相近的,但是一旦进过filter过滤后,每个分区的数据量有可能会存在较大差异

-
如上图我们可以发现两个问题:
- 每个partition的数据量变小了,如果还按照之前与partition相等的task个数去处理当前数据,有点浪费task的计算资源;
- 每个partition的数据量不一样,会导致后面的每个task处理每个partition数据的时候,每个task要处理的数据量不同,这很有可能导致数据倾斜问题。
-
如图,第二个分区的数据过滤后只剩100条,而第三个分区的数据过滤后剩下800条,在相同的处理逻辑下,第二个分区对应的task处理的数据量与第三个分区对应的task处理的数据量差距达到了8倍,这也会导致运行速度可能存在数倍的差距,这也就是数据倾斜问题。
-
针对上述的两个问题,我们分别进行分析:
- 针对第一个问题,既然分区的数据量变小了,我们希望可以对分区数据进行重新分配,比如将原来4个分区的数据转化到2个分区中,这样只需要用后面的两个task进行处理即可,避免了资源的浪费。
- 针对第二个问题,解决方法和第一个问题的解决方法非常相似,对分区数据重新分配,让每个partition中的数据量差不多,这就避免了数据倾斜问题。
-
那么具体应该如何实现上面的解决思路?我们需要coalesce算子。
repartition与coalesce都可以用来进行重分区,其中repartition只是coalesce接口中shuffle为true的简易实现,coalesce默认情况下不进行shuffle,但是可以通过参数进行设置。
- 假设我们希望将原本的分区个数A通过重新分区变为B,那么有以下几种情况:
- A > B(多数分区合并为少数分区)
① A与B相差值不大
此时使用coalesce即可,无需shuffle过程。
② A与B相差值很大
此时可以使用coalesce并且不启用shuffle过程,但是会导致合并过程性能低下,所以推荐设置coalesce的第二个参数为true,即启动shuffle过程。
- A < B(少数分区分解为多数分区)
此时使用repartition即可,如果使用coalesce需要将shuffle设置为true,否则coalesce无效。
我们可以在filter操作之后,使用coalesce算子针对每个partition的数据量各不相同的情况,压缩partition的数量,而且让每个partition的数据量尽量均匀紧凑,以便于后面的task进行计算操作,在某种程度上能够在一定程度上提升性能。
注意:local模式是进程内模拟集群运行,已经对并行度和分区数量有了一定的内部优化,因此不用去设置并行度和分区数量。
9.4 repartition解决SparkSQL低并行度问题
在常规性能调优中我们讲解了并行度的调节策略,但是,并行度的设置对于Spark SQL是不生效的,用户设置的并行度只对于Spark SQL以外的所有Spark的stage生效。
Spark SQL的并行度不允许用户自己指定,Spark SQL自己会默认根据hive表对应的HDFS文件的split个数自动设置Spark SQL所在的那个stage的并行度,用户自己通spark.default.parallelism参数指定的并行度,只会在没Spark SQL的stage中生效。
由于Spark SQL所在stage的并行度无法手动设置,如果数据量较大,并且此stage中后续的transformation操作有着复杂的业务逻辑,而Spark SQL自动设置的task数量很少,这就意味着每个task要处理为数不少的数据量,然后还要执行非常复杂的处理逻辑,这就可能表现为第一个有Spark SQL的stage速度很慢,而后续的没有Spark SQL的stage运行速度非常快。
为了解决Spark SQL无法设置并行度和task数量的问题,我们可以使用repartition算子
Spark SQL这一步的并行度和task数量肯定是没有办法去改变了,但是,对于Spark SQL查询出来的RDD,立即使用repartition算子,去重新进行分区,这样可以重新分区为多个partition,从repartition之后的RDD操作,由于不再设计Spark SQL,因此stage的并行度就会等于你手动设置的值,这样就避免了Spark SQL所在的stage只能用少量的task去处理大量数据并执行复杂的算法逻辑。使用repartition算子的前后对比如下图

9.5 reduceByKey本地聚合
reduceByKey相较于普通的shuffle操作一个显著的特点就是会进行map端的本地聚合,map端会先对本地的数据进行combine操作,然后将数据写入给下个stage的每个task创建的文件中,也就是在map端,对每一个key对应的value,执行reduceByKey算子函数。reduceByKey算子的执行过程如下图
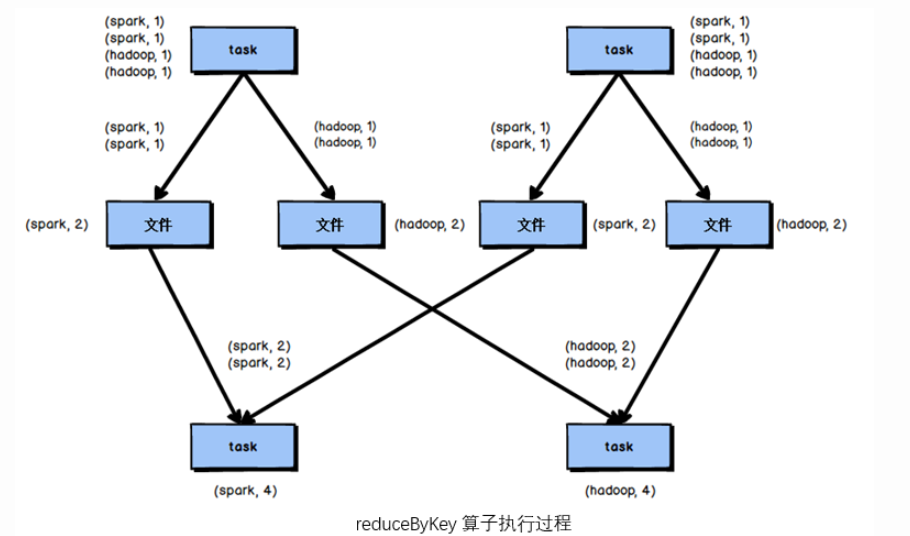
-
使用reduceByKey对性能的提升如下:
- 本地聚合后,在map端的数据量变少,减少了磁盘IO,也减少了对磁盘空间的占用;
- 本地聚合后,下一个stage拉取的数据量变少,减少了网络传输的数据量;
- 本地聚合后,在reduce端进行数据缓存的内存占用减少;
- 本地聚合后,在reduce端进行聚合的数据量减少。
-
基于reduceByKey的本地聚合特征,我们应该考虑使用reduceByKey代替其他的shuffle算子,例如groupByKey。reduceByKey与groupByKey的运行原理如下图
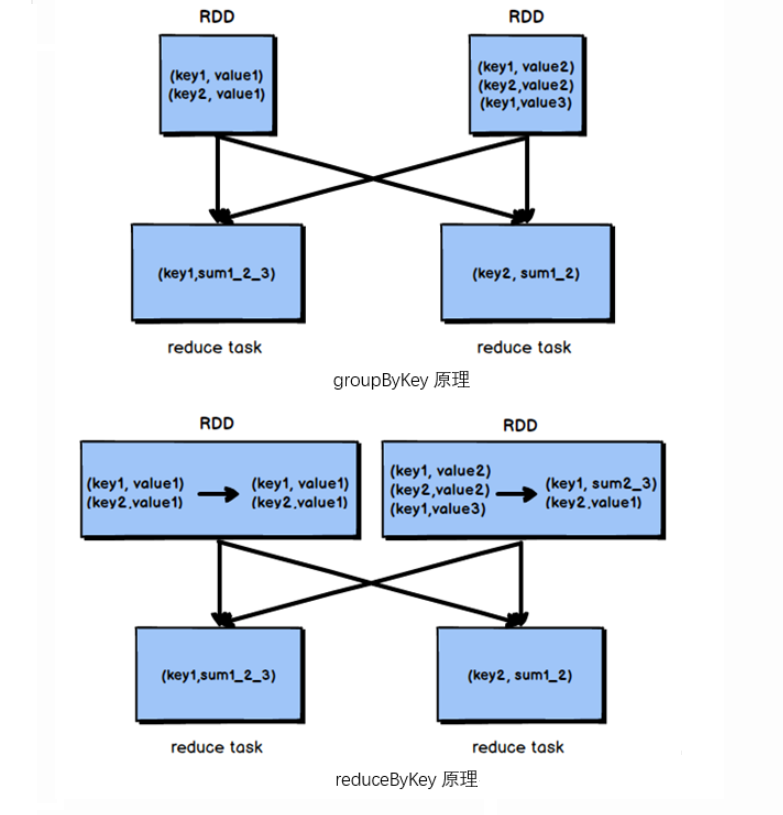
groupByKey不会进行map端的聚合,而是将所有map端的数据shuffle到reduce端,然后在reduce端进行数据的聚合操作。由于reduceByKey有map端聚合的特性,使得网络传输的数据量减小,因此效率要明显高于groupByKey。
10 Shuffle调优
10.1 调节map端缓冲区大小
在Spark任务运行过程中,如果shuffle的map端处理的数据量比较大,但是map端缓冲的大小是固定的,可能会出现map端缓冲数据频繁spill溢写到磁盘文件中的情况,使得性能非常低下,通过调节map端缓冲的大小,可以避免频繁的磁盘IO操作,进而提升Spark任务的整体性能。
map端缓冲的默认配置是32KB,如果每个task处理640KB的数据,那么会发生640/32 = 20次溢写,如果每个task处理64000KB的数据,机会发生64000/32=2000此溢写,这对于性能的影响是非常严重的。
- map端缓冲的配置方法
val conf = new SparkConf().set("spark.shuffle.file.buffer", "64")
10.2 调节reduce端拉取数据缓冲区大小
Spark Shuffle过程中,shuffle reduce task的buffer缓冲区大小决定了reduce task每次能够缓冲的数据量,也就是每次能够拉取的数据量,如果内存资源较为充足,适当增加拉取数据缓冲区的大小,可以减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。
- reduce端数据拉取缓冲区的大小可以通过spark.reducer.maxSizeInFlight参数进行设置,默认为48MB,该参数的设置方法
val conf = new SparkConf().set("spark.reducer.maxSizeInFlight", "96")
10.3 调节reduce端拉取数据重试次数
Spark Shuffle过程中,reduce task拉取属于自己的数据时,如果因为网络异常等原因导致失败会自动进行重试。对于那些包含了特别耗时的shuffle操作的作业,建议增加重试最大次数(比如60次),以避免由于JVM的full gc或者网络不稳定等因素导致的数据拉取失败。在实践中发现,对于针对超大数据量(数十亿~上百亿)的shuffle过程,调节该参数可以大幅度提升稳定性。
- reduce端拉取数据重试次数可以通过spark.shuffle.io.maxRetries参数进行设置,该参数就代表了可以重试的最大次数。如果在指定次数之内拉取还是没有成功,就可能会导致作业执行失败,默认为3,该参数的设置方法
val conf = new SparkConf().set("spark.shuffle.io.maxRetries", "6")
10.4 调节reduce端拉取数据等待时间
Spark Shuffle过程中,reduce task拉取属于自己的数据时,如果因为网络异常等原因导致失败会自动进行重试,在一次失败后,会等待一定的时间间隔再进行重试,可以通过加大间隔时长(比如60s),以增加shuffle操作的稳定性。
- reduce端拉取数据等待间隔可以通过spark.shuffle.io.retryWait参数进行设置,默认值为5s,该参数的设置方法
val conf = new SparkConf().set("spark.shuffle.io.retryWait", "60s")
10.5 调节SortShuffle排序操作阀值
对于SortShuffleManager,如果shuffle reduce task的数量小于某一阈值则shuffle write过程中不会进行排序操作,而是直接按照未经优化的HashShuffleManager的方式去写数据,但是最后会将每个task产生的所有临时磁盘文件都合并成一个文件,并会创建单独的索引文件。
当你使用SortShuffleManager时,如果的确不需要排序操作,那么建议将这个参数调大一些,大于shuffle read task的数量,那么此时map-side就不会进行排序了,减少了排序的性能开销,但是这种方式下,依然会产生大量的磁盘文件,因此shuffle write性能有待提高。
SortShuffleManager排序操作阈值的设置可以通过spark.shuffle.sort. bypassMergeThreshold这一参数进行设置,默认值为200
- 该参数的设置方法如下:
val conf = new SparkConf().set("spark.shuffle.sort.bypassMergeThreshold", "400")
11 JVM调优
11.1 降低cache操作的内存占比
11.1.1 静态内存管理机制
根据Spark静态内存管理机制,堆内存被划分为了两块,Storage和Execution。Storage主要用于缓存RDD数据和broadcast数据,Execution主要用于缓存在shuffle过程中产生的中间数据,Storage占系统内存的60%,Execution占系统内存的20%,并且两者完全独立。
在一般情况下,Storage的内存都提供给了cache操作,但是如果在某些情况下cache操作内存不是很紧张,而task的算子中创建的对象很多,Execution内存又相对较小,这回导致频繁的minor gc,甚至于频繁的full gc,进而导致Spark频繁的停止工作,性能影响会很大。
在Spark UI中可以查看每个stage的运行情况,包括每个task的运行时间、gc时间等等,如果发现gc太频繁,时间太长,就可以考虑调节Storage的内存占比,让task执行算子函数式,有更多的内存可以使用。
Storage内存区域可以通过spark.storage.memoryFraction参数进行指定,默认为0.6,即60%,可以逐级向下递减,如代码清单所示:
- 内存占比设置
val conf = new SparkConf().set("spark.storage.memoryFraction", "0.4")
- 统一内存管理机制
根据Spark统一内存管理机制,堆内存被划分为了两块,Storage和Execution。Storage主要用于缓存数据,Execution主要用于缓存在shuffle过程中产生的中间数据,两者所组成的内存部分称为统一内存,Storage和Execution各占统一内存的50%,由于动态占用机制的实现,shuffle过程需要的内存过大时,会自动占用Storage的内存区域,因此无需手动进行调节。
11.1.2 调节Executor堆外内存
Executor的堆外内存主要用于程序的共享库、Perm Space、 线程Stack和一些Memory mapping等, 或者类C方式allocate object。
有时,如果你的Spark作业处理的数据量非常大,达到几亿的数据量,此时运行Spark作业会时不时地报错,例如shuffle output file cannot find,executor lost,task lost,out of memory等,这可能是Executor的堆外内存不太够用,导致Executor在运行的过程中内存溢出。
stage的task在运行的时候,可能要从一些Executor中去拉取shuffle map output文件,但是Executor可能已经由于内存溢出挂掉了,其关联的BlockManager也没有了,这就可能会报出shuffle output file cannot find,executor lost,task lost,out of memory等错误,此时,就可以考虑调节一下Executor的堆外内存,也就可以避免报错,与此同时,堆外内存调节的比较大的时候,对于性能来讲,也会带来一定的提升。
默认情况下,Executor堆外内存上限大概为300多MB,在实际的生产环境下,对海量数据进行处理的时候,这里都会出现问题,导致Spark作业反复崩溃,无法运行,此时就会去调节这个参数,到至少1G,甚至于2G、4G。
- Executor堆外内存的配置需要在spark-submit脚本里配置
--conf spark.yarn.executor.memoryOverhead=2048
11.1.3 调节链接等待时长
在Spark作业运行过程中,Executor优先从自己本地关联的BlockManager中获取某份数据,如果本地BlockManager没有的话,会通过TransferService远程连接其他节点上Executor的BlockManager来获取数据。
如果task在运行过程中创建大量对象或者创建的对象较大,会占用大量的内存,这回导致频繁的垃圾回收,但是垃圾回收会导致工作现场全部停止,也就是说,垃圾回收一旦执行,Spark的Executor进程就会停止工作,无法提供相应,此时,由于没有响应,无法建立网络连接,会导致网络连接超时。
在生产环境下,有时会遇到file not found、file lost这类错误,在这种情况下,很有可能是Executor的BlockManager在拉取数据的时候,无法建立连接,然后超过默认的连接等待时长60s后,宣告数据拉取失败,如果反复尝试都拉取不到数据,可能会导致Spark作业的崩溃。这种情况也可能会导致DAGScheduler反复提交几次stage,TaskScheduler返回提交几次task,大大延长了我们的Spark作业的运行时间。
调节连接等待时长后,通常可以避免部分的XX文件拉取失败、XX文件lost等报错。
- 此时,可以考虑调节连接的超时时长,连接等待时长需要在spark-submit脚本中进行设置,设置方式如下
--conf spark.core.connection.ack.wait.timeout=300
12 故障排除
12.1 控制reduce端缓冲大小以及避免OOM
在Shuffle过程,reduce端task并不是等到map端task将其数据全部写入磁盘后再去拉取,而是map端写一点数据,reduce端task就会拉取一小部分数据,然后立即进行后面的聚合、算子函数的使用等操作。
reduce端task能够拉取多少数据,由reduce拉取数据的缓冲区buffer来决定,因为拉取过来的数据都是先放在buffer中,然后再进行后续的处理,buffer的默认大小为48MB。
reduce端task会一边拉取一边计算,不一定每次都会拉满48MB的数据,可能大多数时候拉取一部分数据就处理掉了。
虽然说增大reduce端缓冲区大小可以减少拉取次数,提升Shuffle性能,但是有时map端的数据量非常大,写出的速度非常快,此时reduce端的所有task在拉取的时候,有可能全部达到自己缓冲的最大极限值,即48MB,此时,再加上reduce端执行的聚合函数的代码,可能会创建大量的对象,这可难会导致内存溢出,即OOM。
如果一旦出现reduce端内存溢出的问题,我们可以考虑减小reduce端拉取数据缓冲区的大小,例如减少为12MB。
在实际生产环境中是出现过这种问题的,这是典型的以性能换执行的原理。reduce端拉取数据的缓冲区减小,不容易导致OOM,但是相应的,reudce端的拉取次数增加,造成更多的网络传输开销,造成性能的下降。
注意,要保证任务能够运行,再考虑性能的优化。
12.2 JVM GC导致的shuffle文件拉取失败
在Spark作业中,有时会出现shuffle file not found的错误,这是非常常见的一个报错,有时出现这种错误以后,选择重新执行一遍,就不再报出这种错误。
出现上述问题可能的原因是Shuffle操作中,后面stage的task想要去上一个stage的task所在的Executor拉取数据,结果对方正在执行GC,执行GC会导致Executor内所有的工作现场全部停止,比如BlockManager、基于netty的网络通信等,这就会导致后面的task拉取数据拉取了半天都没有拉取到,就会报出shuffle file not found的错误,而第二次再次执行就不会再出现这种错误。
可以通过调整reduce端拉取数据重试次数和reduce端拉取数据时间间隔这两个参数来对Shuffle性能进行调整,增大参数值,使得reduce端拉取数据的重试次数增加,并且每次失败后等待的时间间隔加长。
- JVM GC导致的shuffle文件拉取失败
val conf = new SparkConf()
.set("spark.shuffle.io.maxRetries", "60")
.set("spark.shuffle.io.retryWait", "60s")
12.3 解决各种序列化导致的报错
当Spark作业在运行过程中报错,而且报错信息中含有Serializable等类似词汇,那么可能是序列化问题导致的报错。
- 序列化问题要注意以下三点:
- 作为RDD的元素类型的自定义类,必须是可以序列化的;
- 算子函数里可以使用的外部的自定义变量,必须是可以序列化的;
- 不可以在RDD的元素类型、算子函数里使用第三方的不支持序列化的类型,例如Connection。
12.4 解决算子函数返回NULL导致的问题
在一些算子函数里,需要我们有一个返回值,但是在一些情况下我们不希望有返回值,此时我们如果直接返回NULL,会报错,例如Scala.Math(NULL)异常。
- 如果你遇到某些情况,不希望有返回值,那么可以通过下述方式解决:
- 返回特殊值,不返回NULL,例如“-1”;
- 在通过算子获取到了一个RDD之后,可以对这个RDD执行filter操作,进行数据过滤,将数值为-1的数据给过滤掉;
- 在使用完filter算子后,继续调用coalesce算子进行优化。
12.5 解决YARN-CLIENT模式导致的网卡流量激增问题
- YARN-client模式的运行原理图
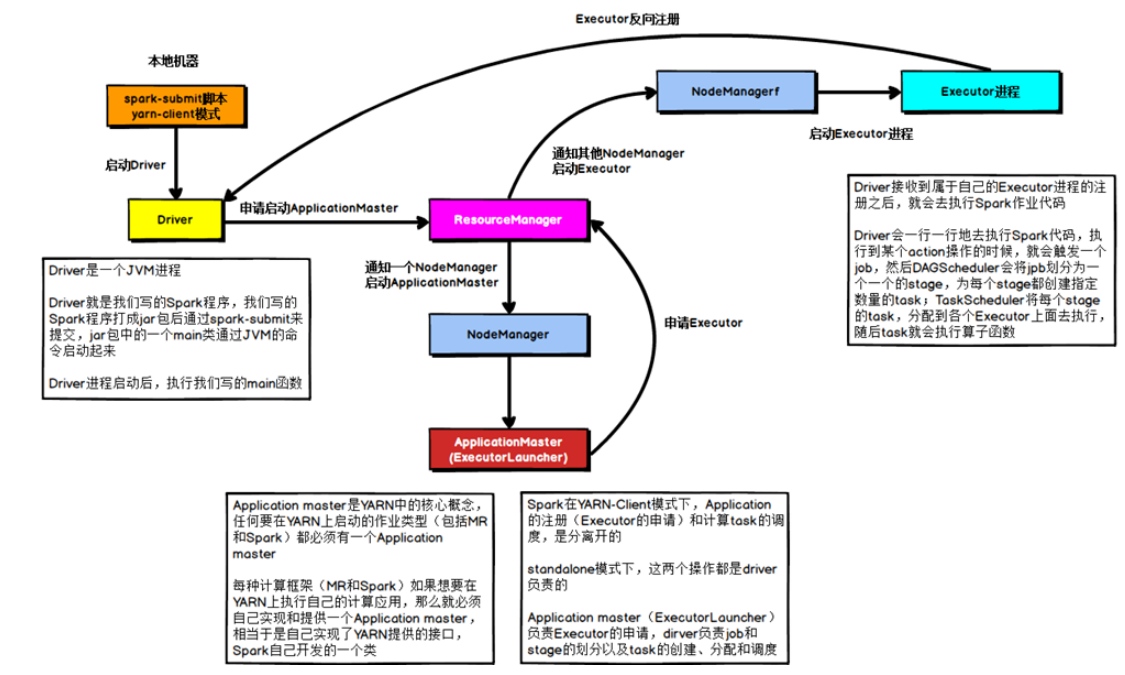
在YARN-client模式下,Driver启动在本地机器上,而Driver负责所有的任务调度,需要与YARN集群上的多个Executor进行频繁的通信。
假设有100个Executor, 1000个task,那么每个Executor分配到10个task,之后,Driver要频繁地跟Executor上运行的1000个task进行通信,通信数据非常多,并且通信品类特别高。这就导致有可能在Spark任务运行过程中,由于频繁大量的网络通讯,本地机器的网卡流量会激增。
注意,YARN-client模式只会在测试环境中使用,而之所以使用YARN-client模式,是由于可以看到详细全面的log信息,通过查看log,可以锁定程序中存在的问题,避免在生产环境下发生故障。
在生产环境下,使用的一定是YARN-cluster模式。在YARN-cluster模式下,就不会造成本地机器网卡流量激增问题,如果YARN-cluster模式下存在网络通信的问题,需要运维团队进行解决。
12.6 解决YARN-CLUSTER模式的JVM栈内存溢出无法执行问题
- YARN-cluster模式的运行原理图
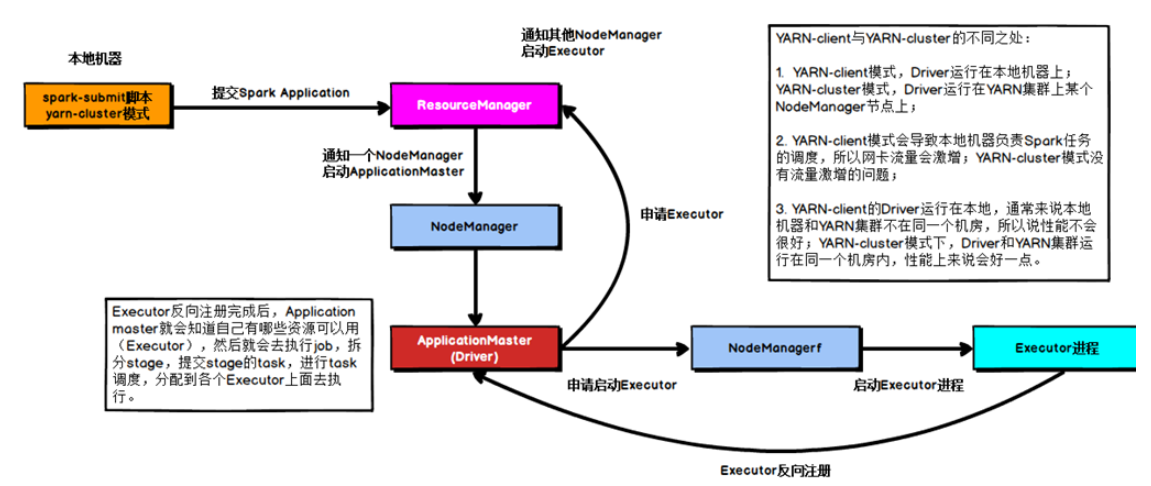
当Spark作业中包含SparkSQL的内容时,可能会碰到YARN-client模式下可以运行,但是YARN-cluster模式下无法提交运行(报出OOM错误)的情况。
YARN-client模式下,Driver是运行在本地机器上的,Spark使用的JVM的PermGen的配置,是本地机器上的spark-class文件,JVM永久代的大小是128MB,这个是没有问题的,但是在YARN-cluster模式下,Driver运行在YARN集群的某个节点上,使用的是没有经过配置的默认设置,PermGen永久代大小为82MB。
SparkSQL的内部要进行很复杂的SQL的语义解析、语法树转换等等,非常复杂,如果sql语句本身就非常复杂,那么很有可能会导致性能的损耗和内存的占用,特别是对PermGen的占用会比较大。
所以,此时如果PermGen的占用好过了82MB,但是又小于128MB,就会出现YARN-client模式下可以运行,YARN-cluster模式下无法运行的情况。
- 解决上述问题的方法时增加PermGen的容量,需要在spark-submit脚本中对相关参数进行设置,设置方法下
--conf spark.driver.extraJavaOptions="-XX:PermSize=128M -XX:MaxPermSize=256M"
通过上述方法就设置了Driver永久代的大小,默认为128MB,最大256MB,这样就可以避免上面所说的问题。
12.7 解决SparkSQL导致的JVM栈内存溢出
当SparkSQL的sql语句有成百上千的or关键字时,就可能会出现Driver端的JVM栈内存溢出。
JVM栈内存溢出基本上就是由于调用的方法层级过多,产生了大量的,非常深的,超出了JVM栈深度限制的递归。(我们猜测SparkSQL有大量or语句的时候,在解析SQL时,例如转换为语法树或者进行执行计划的生成的时候,对于or的处理是递归,or非常多时,会发生大量的递归)
此时,建议将一条sql语句拆分为多条sql语句来执行,每条sql语句尽量保证100个以内的子句。根据实际的生产环境试验,一条sql语句的or关键字控制在100个以内,通常不会导致JVM栈内存溢出。
12.8 持久化与checkpoint的使用
Spark持久化在大部分情况下是没有问题的,但是有时数据可能会丢失,如果数据一旦丢失,就需要对丢失的数据重新进行计算,计算完后再缓存和使用,为了避免数据的丢失,可以选择对这个RDD进行checkpoint,也就是将数据持久化一份到容错的文件系统上(比如HDFS)。
一个RDD缓存并checkpoint后,如果一旦发现缓存丢失,就会优先查看checkpoint数据存不存在,如果有,就会使用checkpoint数据,而不用重新计算。也即是说,checkpoint可以视为cache的保障机制,如果cache失败,就使用checkpoint的数据。
使用checkpoint的优点在于提高了Spark作业的可靠性,一旦缓存出现问题,不需要重新计算数据,缺点在于,checkpoint时需要将数据写入HDFS等文件系统,对性能的消耗较大。
13 数据倾斜
参考:https://www.cnblogs.com/xiaodf/p/6055803.html#21
有的时候,我们可能会遇到大数据计算中一个最棘手的问题——数据倾斜,此时Spark作业的性能会比期望差很多。数据倾斜调优,就是使用各种技术方案解决不同类型的数据倾斜问题,以保证Spark作业的性能。
13.1 数据倾斜发生时的现象
- 绝大多数task执行得都非常快,但个别task执行极慢。比如,总共有1000个task,997个task都在1分钟之内执行完了,但是剩余两三个task却要一两个小时。这种情况很常见。
- 原本能够正常执行的Spark作业,某天突然报出OOM(内存溢出)异常,观察异常栈,是我们写的业务代码造成的。这种情况比较少见。
13.2 数据倾斜发生的原理
数据倾斜的原理很简单:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作。此时如果某个key对应的数据量特别大的话,就会发生数据倾斜。比如大部分key对应10条数据,但是个别key却对应了100万条数据,那么大部分task可能就只会分配到10条数据,然后1秒钟就运行完了;但是个别task可能分配到了100万数据,要运行一两个小时。因此,整个Spark作业的运行进度是由运行时间最长的那个task决定的。
因此出现数据倾斜的时候,Spark作业看起来会运行得非常缓慢,甚至可能因为某个task处理的数据量过大导致内存溢出。
下图就是一个很清晰的例子:hello这个key,在三个节点上对应了总共7条数据,这些数据都会被拉取到同一个task中进行处理;而world和you这两个key分别才对应1条数据,所以另外两个task只要分别处理1条数据即可。此时第一个task的运行时间可能是另外两个task的7倍,而整个stage的运行速度也由运行最慢的那个task所决定。
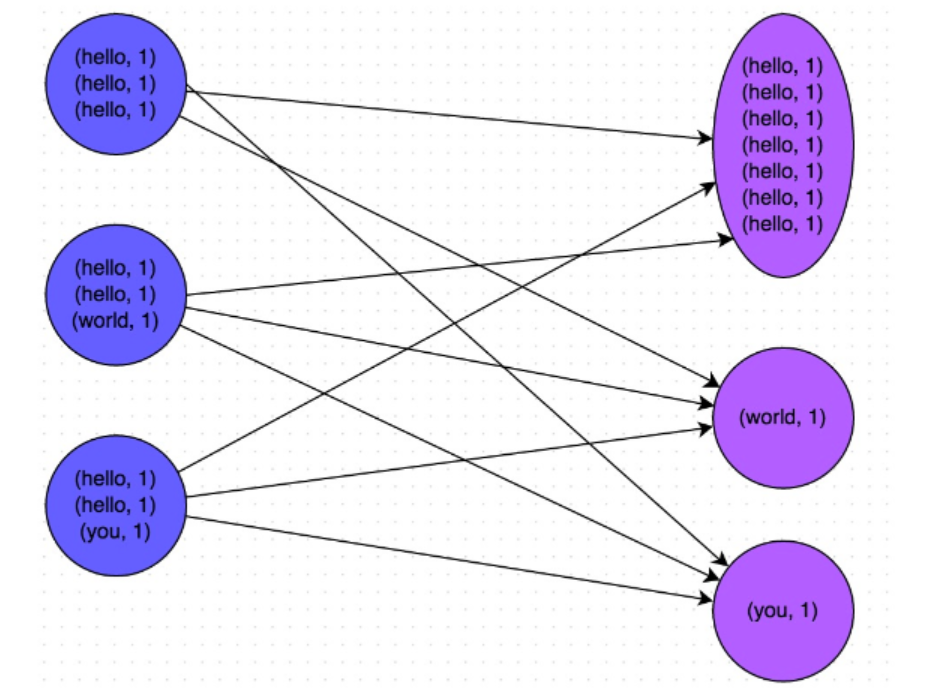
13.3 如何定位导致数据倾斜的代码
数据倾斜只会发生在shuffle过程中。这里给大家罗列一些常用的并且可能会触发shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。出现数据倾斜时,可能就是你的代码中使用了这些算子中的某一个所导致的。
13.4 数据倾斜的解决方案
13.4.1 解决方案一:使用Hive ETL预处理数据
方案适用场景:导致数据倾斜的是Hive表。如果该Hive表中的数据本身很不均匀(比如某个key对应了100万数据,其他key才对应了10条数据),而且业务场景需要频繁使用Spark对Hive表执行某个分析操作,那么比较适合使用这种技术方案。
方案实现思路:此时可以评估一下,是否可以通过Hive来进行数据预处理(即通过Hive ETL预先对数据按照key进行聚合,或者是预先和其他表进行join),然后在Spark作业中针对的数据源就不是原来的Hive表了,而是预处理后的Hive表。此时由于数据已经预先进行过聚合或join操作了,那么在Spark作业中也就不需要使用原先的shuffle类算子执行这类操作了。
方案实现原理:这种方案从根源上解决了数据倾斜,因为彻底避免了在Spark中执行shuffle类算子,那么肯定就不会有数据倾斜的问题了。但是这里也要提醒一下大家,这种方式属于治标不治本。因为毕竟数据本身就存在分布不均匀的问题,所以Hive ETL中进行group by或者join等shuffle操作时,还是会出现数据倾斜,导致Hive ETL的速度很慢。我们只是把数据倾斜的发生提前到了Hive ETL中,避免Spark程序发生数据倾斜而已。
方案优点:实现起来简单便捷,效果还非常好,完全规避掉了数据倾斜,Spark作业的性能会大幅度提升。
方案缺点:治标不治本,Hive ETL中还是会发生数据倾斜。
方案实践经验:在一些Java系统与Spark结合使用的项目中,会出现Java代码频繁调用Spark作业的场景,而且对Spark作业的执行性能要求很高,就比较适合使用这种方案。将数据倾斜提前到上游的Hive ETL,每天仅执行一次,只有那一次是比较慢的,而之后每次Java调用Spark作业时,执行速度都会很快,能够提供更好的用户体验。
项目实践经验:在美团·点评的交互式用户行为分析系统中使用了这种方案,该系统主要是允许用户通过Java Web系统提交数据分析统计任务,后端通过Java提交Spark作业进行数据分析统计。要求Spark作业速度必须要快,尽量在10分钟以内,否则速度太慢,用户体验会很差。所以我们将有些Spark作业的shuffle操作提前到了Hive ETL中,从而让Spark直接使用预处理的Hive中间表,尽可能地减少Spark的shuffle操作,大幅度提升了性能,将部分作业的性能提升了6倍以上。
13.4.2 解决方案二:过滤少数导致倾斜的key
方案适用场景:如果发现导致倾斜的key就少数几个,而且对计算本身的影响并不大的话,那么很适合使用这种方案。比如99%的key就对应10条数据,但是只有一个key对应了100万数据,从而导致了数据倾斜。
方案实现思路:如果我们判断那少数几个数据量特别多的key,对作业的执行和计算结果不是特别重要的话,那么干脆就直接过滤掉那少数几个key。比如,在Spark SQL中可以使用where子句过滤掉这些key或者在Spark Core中对RDD执行filter算子过滤掉这些key。如果需要每次作业执行时,动态判定哪些key的数据量最多然后再进行过滤,那么可以使用sample算子对RDD进行采样,然后计算出每个key的数量,取数据量最多的key过滤掉即可。
方案实现原理:将导致数据倾斜的key给过滤掉之后,这些key就不会参与计算了,自然不可能产生数据倾斜。
方案优点:实现简单,而且效果也很好,可以完全规避掉数据倾斜。
方案缺点:适用场景不多,大多数情况下,导致倾斜的key还是很多的,并不是只有少数几个。
方案实践经验:在项目中我们也采用过这种方案解决数据倾斜。有一次发现某一天Spark作业在运行的时候突然OOM了,追查之后发现,是Hive表中的某一个key在那天数据异常,导致数据量暴增。因此就采取每次执行前先进行采样,计算出样本中数据量最大的几个key之后,直接在程序中将那些key给过滤掉。
13.4.3 解决方案三:提高shuffle操作的并行度
方案适用场景:如果我们必须要对数据倾斜迎难而上,那么建议优先使用这种方案,因为这是处理数据倾斜最简单的一种方案。
方案实现思路:在对RDD执行shuffle算子时,给shuffle算子传入一个参数,比如reduceByKey(1000),该参数就设置了这个shuffle算子执行时shuffle read task的数量。对于Spark SQL中的shuffle类语句,比如group by、join等,需要设置一个参数,即spark.sql.shuffle.partitions,该参数代表了shuffle read task的并行度,该值默认是200,对于很多场景来说都有点过小。
方案实现原理:增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据。举例来说,如果原本有5个key,每个key对应10条数据,这5个key都是分配给一个task的,那么这个task就要处理50条数据。而增加了shuffle read task以后,每个task就分配到一个key,即每个task就处理10条数据,那么自然每个task的执行时间都会变短了。具体原理如下图所示。
方案优点:实现起来比较简单,可以有效缓解和减轻数据倾斜的影响。
方案缺点:只是缓解了数据倾斜而已,没有彻底根除问题,根据实践经验来看,其效果有限。
方案实践经验:该方案通常无法彻底解决数据倾斜,因为如果出现一些极端情况,比如某个key对应的数据量有100万,那么无论你的task数量增加到多少,这个对应着100万数据的key肯定还是会分配到一个task中去处理,因此注定还是会发生数据倾斜的。所以这种方案只能说是在发现数据倾斜时尝试使用的第一种手段,尝试去用嘴简单的方法缓解数据倾斜而已,或者是和其他方案结合起来使用。

13.4.4 解决方案四:两阶段聚合(局部聚合+全局聚合)
方案适用场景:对RDD执行reduceByKey等聚合类shuffle算子或者在Spark SQL中使用group by语句进行分组聚合时,比较适用这种方案。
方案实现思路:这个方案的核心实现思路就是进行两阶段聚合。第一次是局部聚合,先给每个key都打上一个随机数,比如10以内的随机数,此时原先一样的key就变成不一样的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就会变成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接着对打上随机数后的数据,执行reduceByKey等聚合操作,进行局部聚合,那么局部聚合结果,就会变成了(1_hello, 2) (2_hello, 2)。然后将各个key的前缀给去掉,就会变成(hello,2)(hello,2),再次进行全局聚合操作,就可以得到最终结果了,比如(hello, 4)。
方案实现原理:将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。具体原理见下图。
方案优点:对于聚合类的shuffle操作导致的数据倾斜,效果是非常不错的。通常都可以解决掉数据倾斜,或者至少是大幅度缓解数据倾斜,将Spark作业的性能提升数倍以上。
方案缺点:仅仅适用于聚合类的shuffle操作,适用范围相对较窄。如果是join类的shuffle操作,还得用其他的解决方案。
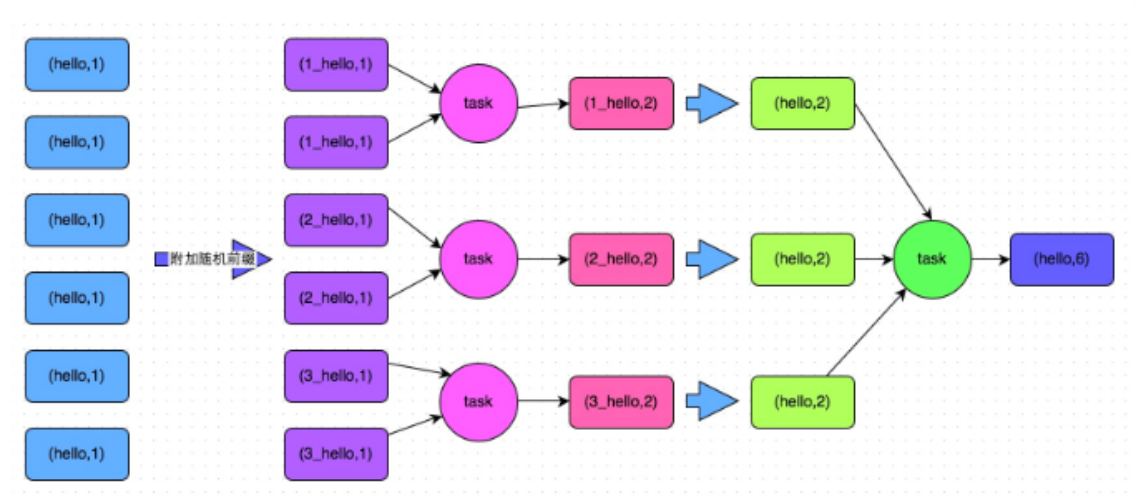
// 第一步,给RDD中的每个key都打上一个随机前缀。
JavaPairRDD<String, Long> randomPrefixRdd = rdd.mapToPair(
new PairFunction<Tuple2<Long,Long>, String, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Long> call(Tuple2<Long, Long> tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(10);
return new Tuple2<String, Long>(prefix + "_" + tuple._1, tuple._2);
}
});
// 第二步,对打上随机前缀的key进行局部聚合。
JavaPairRDD<String, Long> localAggrRdd = randomPrefixRdd.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
// 第三步,去除RDD中每个key的随机前缀。
JavaPairRDD<Long, Long> removedRandomPrefixRdd = localAggrRdd.mapToPair(
new PairFunction<Tuple2<String,Long>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<String, Long> tuple)
throws Exception {
long originalKey = Long.valueOf(tuple._1.split("_")[1]);
return new Tuple2<Long, Long>(originalKey, tuple._2);
}
});
// 第四步,对去除了随机前缀的RDD进行全局聚合。
JavaPairRDD<Long, Long> globalAggrRdd = removedRandomPrefixRdd.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
13.4.5 解决方案五:将reduce join转为map join
方案适用场景:在对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(比如几百M或者一两G),比较适用此方案。
方案实现思路:不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作,进而完全规避掉shuffle类的操作,彻底避免数据倾斜的发生和出现。将较小RDD中的数据直接通过collect算子拉取到Driver端的内存中来,然后对其创建一个Broadcast变量;接着对另外一个RDD执行map类算子,在算子函数内,从Broadcast变量中获取较小RDD的全量数据,与当前RDD的每一条数据按照连接key进行比对,如果连接key相同的话,那么就将两个RDD的数据用你需要的方式连接起来。
方案实现原理:普通的join是会走shuffle过程的,而一旦shuffle,就相当于会将相同key的数据拉取到一个shuffle read task中再进行join,此时就是reduce join。但是如果一个RDD是比较小的,则可以采用广播小RDD全量数据+map算子来实现与join同样的效果,也就是map join,此时就不会发生shuffle操作,也就不会发生数据倾斜。具体原理如下图所示。
方案优点:对join操作导致的数据倾斜,效果非常好,因为根本就不会发生shuffle,也就根本不会发生数据倾斜。
方案缺点:适用场景较少,因为这个方案只适用于一个大表和一个小表的情况。毕竟我们需要将小表进行广播,此时会比较消耗内存资源,driver和每个Executor内存中都会驻留一份小RDD的全量数据。如果我们广播出去的RDD数据比较大,比如10G以上,那么就可能发生内存溢出了。因此并不适合两个都是大表的情况。
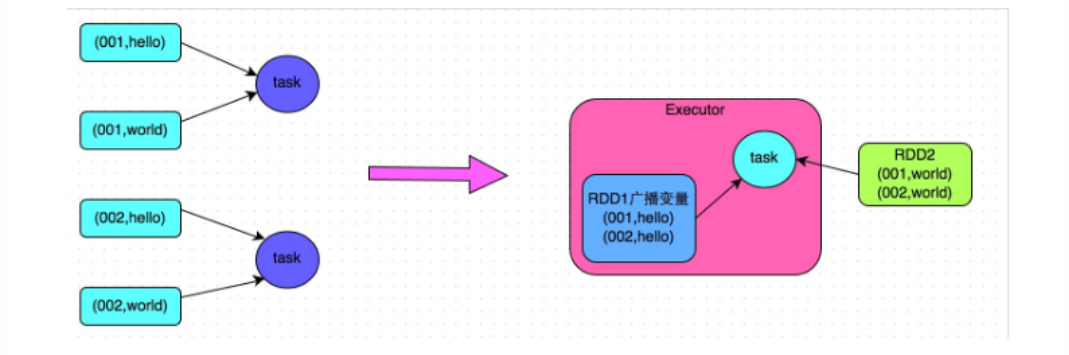
// 首先将数据量比较小的RDD的数据,collect到Driver中来。
List<Tuple2<Long, Row>> rdd1Data = rdd1.collect()
// 然后使用Spark的广播功能,将小RDD的数据转换成广播变量,这样每个Executor就只有一份RDD的数据。
// 可以尽可能节省内存空间,并且减少网络传输性能开销。
final Broadcast<List<Tuple2<Long, Row>>> rdd1DataBroadcast = sc.broadcast(rdd1Data);
// 对另外一个RDD执行map类操作,而不再是join类操作。
JavaPairRDD<String, Tuple2<String, Row>> joinedRdd = rdd2.mapToPair(
new PairFunction<Tuple2<Long,String>, String, Tuple2<String, Row>>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Tuple2<String, Row>> call(Tuple2<Long, String> tuple)
throws Exception {
// 在算子函数中,通过广播变量,获取到本地Executor中的rdd1数据。
List<Tuple2<Long, Row>> rdd1Data = rdd1DataBroadcast.value();
// 可以将rdd1的数据转换为一个Map,便于后面进行join操作。
Map<Long, Row> rdd1DataMap = new HashMap<Long, Row>();
for(Tuple2<Long, Row> data : rdd1Data) {
rdd1DataMap.put(data._1, data._2);
}
// 获取当前RDD数据的key以及value。
String key = tuple._1;
String value = tuple._2;
// 从rdd1数据Map中,根据key获取到可以join到的数据。
Row rdd1Value = rdd1DataMap.get(key);
return new Tuple2<String, String>(key, new Tuple2<String, Row>(value, rdd1Value));
}
});
// 这里得提示一下。
// 上面的做法,仅仅适用于rdd1中的key没有重复,全部是唯一的场景。
// 如果rdd1中有多个相同的key,那么就得用flatMap类的操作,在进行join的时候不能用map,而是得遍历rdd1所有数据进行join。
// rdd2中每条数据都可能会返回多条join后的数据。
13.4.6 解决方案六:采样倾斜key并分拆join操作
方案适用场景:两个RDD/Hive表进行join的时候,如果数据量都比较大,无法采用“解决方案五”,那么此时可以看一下两个RDD/Hive表中的key分布情况。如果出现数据倾斜,是因为其中某一个RDD/Hive表中的少数几个key的数据量过大,而另一个RDD/Hive表中的所有key都分布比较均匀,那么采用这个解决方案是比较合适的。
方案实现思路:
对包含少数几个数据量过大的key的那个RDD,通过sample算子采样出一份样本来,然后统计一下每个key的数量,计算出来数据量最大的是哪几个key。
然后将这几个key对应的数据从原来的RDD中拆分出来,形成一个单独的RDD,并给每个key都打上n以内的随机数作为前缀,而不会导致倾斜的大部分key形成另外一个RDD。
接着将需要join的另一个RDD,也过滤出来那几个倾斜key对应的数据并形成一个单独的RDD,将每条数据膨胀成n条数据,这n条数据都按顺序附加一个0~n的前缀,不会导致倾斜的大部分key也形成另外一个RDD。
再将附加了随机前缀的独立RDD与另一个膨胀n倍的独立RDD进行join,此时就可以将原先相同的key打散成n份,分散到多个task中去进行join了。
而另外两个普通的RDD就照常join即可。
最后将两次join的结果使用union算子合并起来即可,就是最终的join结果。
方案实现原理:对于join导致的数据倾斜,如果只是某几个key导致了倾斜,可以将少数几个key分拆成独立RDD,并附加随机前缀打散成n份去进行join,此时这几个key对应的数据就不会集中在少数几个task上,而是分散到多个task进行join了。具体原理见下图。
方案优点:对于join导致的数据倾斜,如果只是某几个key导致了倾斜,采用该方式可以用最有效的方式打散key进行join。而且只需要针对少数倾斜key对应的数据进行扩容n倍,不需要对全量数据进行扩容。避免了占用过多内存。
方案缺点:如果导致倾斜的key特别多的话,比如成千上万个key都导致数据倾斜,那么这种方式也不适合。
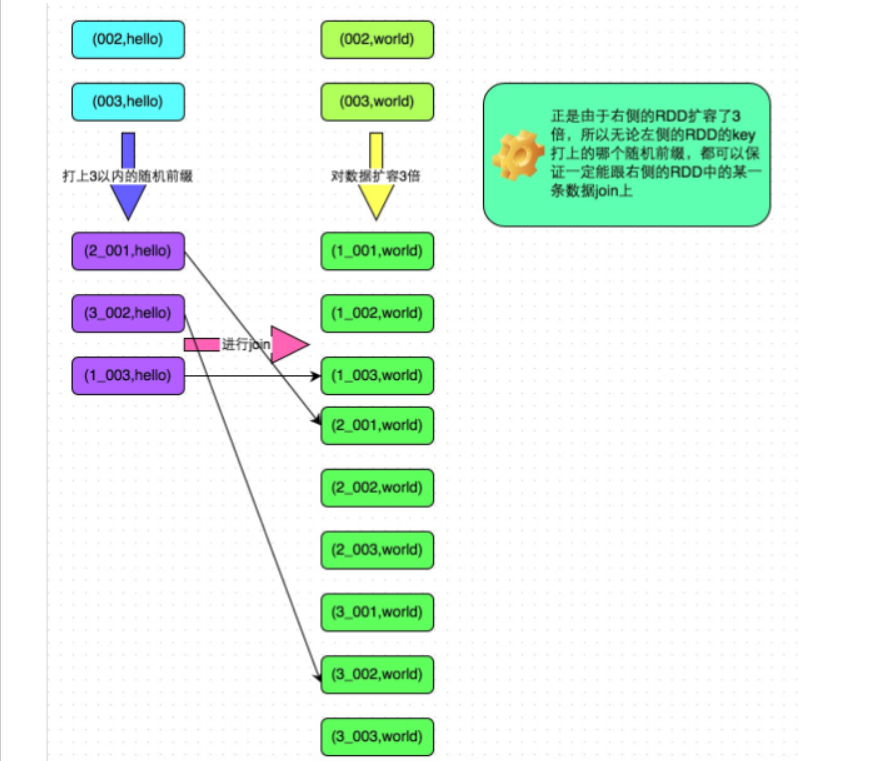
// 首先从包含了少数几个导致数据倾斜key的rdd1中,采样10%的样本数据。
JavaPairRDD<Long, String> sampledRDD = rdd1.sample(false, 0.1);
// 对样本数据RDD统计出每个key的出现次数,并按出现次数降序排序。
// 对降序排序后的数据,取出top 1或者top 100的数据,也就是key最多的前n个数据。
// 具体取出多少个数据量最多的key,由大家自己决定,我们这里就取1个作为示范。
JavaPairRDD<Long, Long> mappedSampledRDD = sampledRDD.mapToPair(
new PairFunction<Tuple2<Long,String>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<Long, String> tuple)
throws Exception {
return new Tuple2<Long, Long>(tuple._1, 1L);
}
});
JavaPairRDD<Long, Long> countedSampledRDD = mappedSampledRDD.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
JavaPairRDD<Long, Long> reversedSampledRDD = countedSampledRDD.mapToPair(
new PairFunction<Tuple2<Long,Long>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<Long, Long> tuple)
throws Exception {
return new Tuple2<Long, Long>(tuple._2, tuple._1);
}
});
final Long skewedUserid = reversedSampledRDD.sortByKey(false).take(1).get(0)._2;
// 从rdd1中分拆出导致数据倾斜的key,形成独立的RDD。
JavaPairRDD<Long, String> skewedRDD = rdd1.filter(
new Function<Tuple2<Long,String>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, String> tuple) throws Exception {
return tuple._1.equals(skewedUserid);
}
});
// 从rdd1中分拆出不导致数据倾斜的普通key,形成独立的RDD。
JavaPairRDD<Long, String> commonRDD = rdd1.filter(
new Function<Tuple2<Long,String>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, String> tuple) throws Exception {
return !tuple._1.equals(skewedUserid);
}
});
// rdd2,就是那个所有key的分布相对较为均匀的rdd。
// 这里将rdd2中,前面获取到的key对应的数据,过滤出来,分拆成单独的rdd,并对rdd中的数据使用flatMap算子都扩容100倍。
// 对扩容的每条数据,都打上0~100的前缀。
JavaPairRDD<String, Row> skewedRdd2 = rdd2.filter(
new Function<Tuple2<Long,Row>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, Row> tuple) throws Exception {
return tuple._1.equals(skewedUserid);
}
}).flatMapToPair(new PairFlatMapFunction<Tuple2<Long,Row>, String, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<Tuple2<String, Row>> call(
Tuple2<Long, Row> tuple) throws Exception {
Random random = new Random();
List<Tuple2<String, Row>> list = new ArrayList<Tuple2<String, Row>>();
for(int i = 0; i < 100; i++) {
list.add(new Tuple2<String, Row>(i + "_" + tuple._1, tuple._2));
}
return list;
}
});
// 将rdd1中分拆出来的导致倾斜的key的独立rdd,每条数据都打上100以内的随机前缀。
// 然后将这个rdd1中分拆出来的独立rdd,与上面rdd2中分拆出来的独立rdd,进行join。
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD1 = skewedRDD.mapToPair(
new PairFunction<Tuple2<Long,String>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(Tuple2<Long, String> tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(100);
return new Tuple2<String, String>(prefix + "_" + tuple._1, tuple._2);
}
})
.join(skewedUserid2infoRDD)
.mapToPair(new PairFunction<Tuple2<String,Tuple2<String,Row>>, Long, Tuple2<String, Row>>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Tuple2<String, Row>> call(
Tuple2<String, Tuple2<String, Row>> tuple)
throws Exception {
long key = Long.valueOf(tuple._1.split("_")[1]);
return new Tuple2<Long, Tuple2<String, Row>>(key, tuple._2);
}
});
// 将rdd1中分拆出来的包含普通key的独立rdd,直接与rdd2进行join。
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD2 = commonRDD.join(rdd2);
// 将倾斜key join后的结果与普通key join后的结果,uinon起来。
// 就是最终的join结果。
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD = joinedRDD1.union(joinedRDD2);
13.4.7 解决方案七:使用随机前缀和扩容RDD进行join
方案适用场景:如果在进行join操作时,RDD中有大量的key导致数据倾斜,那么进行分拆key也没什么意义,此时就只能使用最后一种方案来解决问题了。
方案实现思路:
该方案的实现思路基本和“解决方案六”类似,首先查看RDD/Hive表中的数据分布情况,找到那个造成数据倾斜的RDD/Hive表,比如有多个key都对应了超过1万条数据。
然后将该RDD的每条数据都打上一个n以内的随机前缀。
同时对另外一个正常的RDD进行扩容,将每条数据都扩容成n条数据,扩容出来的每条数据都依次打上一个0~n的前缀。
最后将两个处理后的RDD进行join即可。
方案实现原理:将原先一样的key通过附加随机前缀变成不一样的key,然后就可以将这些处理后的“不同key”分散到多个task中去处理,而不是让一个task处理大量的相同key。该方案与“解决方案六”的不同之处就在于,上一种方案是尽量只对少数倾斜key对应的数据进行特殊处理,由于处理过程需要扩容RDD,因此上一种方案扩容RDD后对内存的占用并不大;而这一种方案是针对有大量倾斜key的情况,没法将部分key拆分出来进行单独处理,因此只能对整个RDD进行数据扩容,对内存资源要求很高。
方案优点:对join类型的数据倾斜基本都可以处理,而且效果也相对比较显著,性能提升效果非常不错。
方案缺点:该方案更多的是缓解数据倾斜,而不是彻底避免数据倾斜。而且需要对整个RDD进行扩容,对内存资源要求很高。
方案实践经验:曾经开发一个数据需求的时候,发现一个join导致了数据倾斜。优化之前,作业的执行时间大约是60分钟左右;使用该方案优化之后,执行时间缩短到10分钟左右,性能提升了6倍。
// 首先将其中一个key分布相对较为均匀的RDD膨胀100倍。
JavaPairRDD<String, Row> expandedRDD = rdd1.flatMapToPair(
new PairFlatMapFunction<Tuple2<Long,Row>, String, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<Tuple2<String, Row>> call(Tuple2<Long, Row> tuple)
throws Exception {
List<Tuple2<String, Row>> list = new ArrayList<Tuple2<String, Row>>();
for(int i = 0; i < 100; i++) {
list.add(new Tuple2<String, Row>(0 + "_" + tuple._1, tuple._2));
}
return list;
}
});
// 其次,将另一个有数据倾斜key的RDD,每条数据都打上100以内的随机前缀。
JavaPairRDD<String, String> mappedRDD = rdd2.mapToPair(
new PairFunction<Tuple2<Long,String>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(Tuple2<Long, String> tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(100);
return new Tuple2<String, String>(prefix + "_" + tuple._1, tuple._2);
}
});
// 将两个处理后的RDD进行join即可。
JavaPairRDD<String, Tuple2<String, Row>> joinedRDD = mappedRDD.join(expandedRDD);
13.4.8 解决方案八:多种方案组合使用
在实践中发现,很多情况下,如果只是处理较为简单的数据倾斜场景,那么使用上述方案中的某一种基本就可以解决。但是如果要处理一个较为复杂的数据倾斜场景,那么可能需要将多种方案组合起来使用。比如说,我们针对出现了多个数据倾斜环节的Spark作业,可以先运用解决方案一和二,预处理一部分数据,并过滤一部分数据来缓解;其次可以对某些shuffle操作提升并行度,优化其性能;最后还可以针对不同的聚合或join操作,选择一种方案来优化其性能。大家需要对这些方案的思路和原理都透彻理解之后,在实践中根据各种不同的情况,灵活运用多种方案,来解决自己的数据倾斜问题。

您的资助是我最大的动力!
金额随意,欢迎来赏!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号