大数据篇:ElasticSearch
大数据篇:ElasticSearch

- ElasticSearch是什么
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。ElasticSearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
当然,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确地形容:
- 一个分布式的实时文档存储,每个字段可以被索引与搜索;
- 一个分布式实时分析搜索引擎;
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据;
- 主要用于全文搜索,结构化搜索,分析。
- 全文检索:将非结构化数据中的一部分信息提取出来,重新组织,使其变得具有一定的结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。
- 结构化检索:传统SQL就是结构化检索。
由于Elasticsearch的功能强大和使用简单,维基百科、卫报、Stack Overflow、GitHub等都纷纷采用它来做搜索。现在,Elasticsearch已成为全文搜索领域的主流软件之一。
0 ElasticSearch 和 Mysql的对比
| Mysql | ElasticSearch |
|---|---|
| database(数据库) | index(索引库) |
| table(表) | type(类型) |
| row(一行记录) | document(文档) |
| column(列) | field(字段) |
| schema(约束) | mapping(映射) |
-
Index
-
索引包含一堆有相似结构的文档数据,比如商品索引,订单索引。可以理解为数据库,
一个index包含很多document。
-
Type
-
每个索引都可以有一个或者多个type,type是index中的一个逻辑数据分类,一个type下的document,都具有相同的field,可以理解为数据库中的表,比如一个商品index下有生鲜商品type,日用品type,这两个type就具有不同的字段。
-
Document
-
文档是es中的最小数据单元,一个document就是一条数据,可以理解为表里的一行数据。
-
Field
-
列是es中的最小单位,可以理解为表里的数据字段。
-
Mapping
-
数据如何存放到索引对象上,需要有一个映射配置,包括:数据类型、是否存储、是否分词等。
-
索引区域和数据区域
-
逻辑上在type中存在索引区域和数据区域。
数据在存入es时,先找到对应的index(数据库),再找到对应的type(表),将数据进行切词,词语对应document的id号放入索引区域,数据放入数据区域。
搜索时通过倒排索引,在索引区域找到对应词语的documentID,去数据区域拿取数据进行返回。
1 ElasticSearch 安装
-
百度网盘下载地址:https://pan.baidu.com/s/1yCH-DX9z2U3smW0_73Yozg 提取码:qh4m
-
推荐使用7.4.2版本,下文使用7.3.1版本讲解安装
-
注意事项:
- 需要jdk环境11以上(使用12)
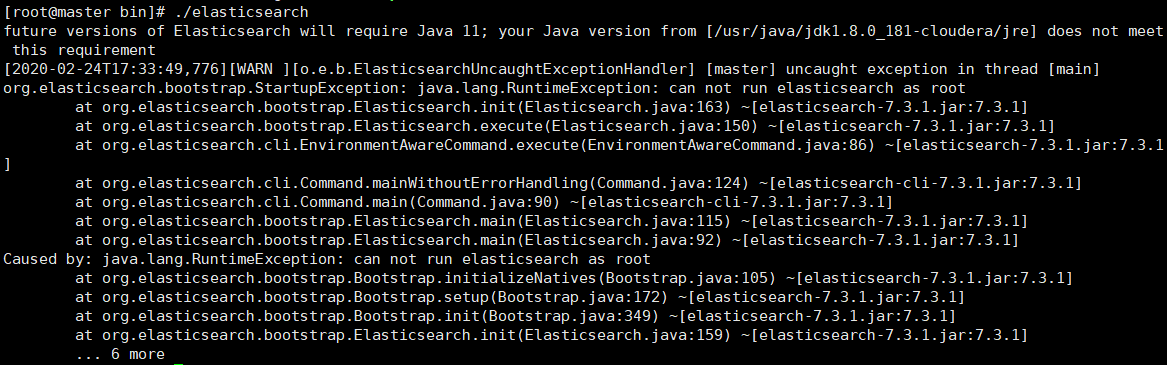
- 只允许普通用户操作,不允许root用户否则会抛出如下异常:
- org.elasticsearch.bootstrap.StartupException: java.lang.RuntimeException: can not run elasticsearch as root
-
安装准备
-
创建新用户el
-
#添加用户 useradd es #修改密码 passwd es -
修改环境
-
vim /etc/security/limits.conf
-
#添加如下内容 * soft nofile 65536 * hard nofile 131072 * soft nproc 4096 * hard nproc 4096 #没报内存问题暂时不需要 #* hard memlock unlimited #* soft memlock unlimited -
vim /etc/security/limits.d/20-nproc.conf
-
#修改如下内容 * soft nproc 4096 -
vim /etc/sysctl.conf
-
#在末尾添加 vm.max_map_count=655360 -
sysctl -p(输入该命令使配置生效)
-
vim /etc/systemd/system.conf
-
DefaultLimitNOFILE=65536 DefaultLimitNPROC=32000 DefaultLimitMEMLOCK=infinity -
reboot重启系统
-
1.1 linux安装java
- https://www.oracle.com/java/technologies/javase-downloads.html
- 百度网盘地址:https://pan.baidu.com/s/14Ew1cQwf0q72B_JsQ64wcw 提取码:ruqy
#1 修改配置文件,加入如下配置
vim /etc/profile
#jdk
export JAVA_HOME=/usr/local/src/jdk12/jdk-12.0.2
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#2 更新配置文件
source /etc/profile
#3 检查java版本
java -version
1.2 ES单机版安装
- 上传tar包到服务器

-
解压
-
tar -zxvf elasticsearch-7.3.1-linux-x86_64.tar.gz -
修改解压后文件夹权限
-
chown -R es:es elasticsearch-7.3.1

-
进入conf文件夹,修改elasticsearch.yml文件
-
vim elasticsearch.yml #如下是修改及添加内容 cluster.name: es-cluster #设置集群的名称 node.name: master #修改当前节点的hostname名称 path.data: /usr/local/src/elasticsearch/elasticsearch-7.3.1/data #修改数据路径 path.logs: /usr/local/src/elasticsearch/elasticsearch-7.3.1/logs #修改日志路径 bootstrap.memory_lock: false #设置ES节点允许内存交换 network.host: 192.168.74.10 #设置当前主机IP discovery.seed_hosts: ["master"] #如下两个配置为es服务器允许别的插件服务访问 http.cors.enabled: true http.cors.allow-origin: "*" -
进入bin目录,切换之前建立的普通用户
-
su es ./elasticsearch

- 使用restful调用
curl -XGET http://192.168.192.11:9200
- 使用浏览器调用

1.3 ES集群版安装
- 上传tar包到集群服务器
-
解压
-
tar -zxvf elasticsearch-7.3.1-linux-x86_64.tar.gz -
修改解压后文件夹权限
-
chown -R es:es elasticsearch-7.3.1 -
进入conf文件夹,修改elasticsearch.yml文件(vim 输入:set paste在粘贴)
-
主节点
-
#设置集群的名称 cluster.name: es-cluster #当前节点的hostname名称 node.name: master #设置是否能成为主节点,false是永远不可能成为主节点,true:表示有可能成为主节点,并不一定。跟指定的参 数cluster.initial_master_nodes 有关系。当所有node都可为主节点时,如果主节点宕机,其他节点会再次选举一个新的主节点. node.master: true #当前节点是否用于存储数据 node.data: true #修改索引存放路径 path.data: /usr/local/src/elasticsearch/elasticsearch-7.3.1/data #修改日志存放路径 path.logs: /usr/local/src/elasticsearch/elasticsearch-7.3.1/logs #是否锁住ES节点内存交换 bootstrap.memory_lock: true #监听IP,用于访问ES network.host: 192.168.192.10 #ES对外提供的http监听端口 http.port: 9200 # TCP的默认监听端口,默认 9300 transport.tcp.port: 9300 # 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4) discovery.zen.minimum_master_nodes: 2 #es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["master:9300","slave1:9300","slave2:9300"] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5 # es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["master","slave1","slave2"] #主节点配置 # 是否支持跨域,是:true,在使用head插件时需要此配置,“*” 表示支持所有域名 http.cors.enabled: true http.cors.allow-origin: "*" action.destructive_requires_name: true action.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history* xpack.security.enabled: false xpack.monitoring.enabled: true xpack.graph.enabled: false xpack.watcher.enabled: false xpack.ml.enabled: false -
从节点1
-
#设置集群的名称 cluster.name: es-cluster #修改当前节点的hostname名称 node.name: slave1 #设置是否能成为主节点,false是永远不可能成为主节点,true:表示有可能成为主节点,并不一定。跟指定的参 数cluster.initial_master_nodes 有关系。当所有node都可为主节点时,如果主节点宕机,其他节点会再次选举一个新的主节点. node.master: true #当前节点是否用于存储数据 node.data: true #修改索引存放路径 path.data: /usr/local/src/elasticsearch/elasticsearch-7.3.1/data #修改日志存放路径 path.logs: /usr/local/src/elasticsearch/elasticsearch-7.3.1/logs #是否锁住ES节点内存交换 bootstrap.memory_lock: true #监听IP,用于访问ES network.host: 192.168.192.11 #ES对外提供的http监听端口 http.port: 9200 # TCP的默认监听端口,默认 9300 transport.tcp.port: 9300 # 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4) discovery.zen.minimum_master_nodes: 2 #es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["master:9300","slave1:9300","slave2:9300"] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5 # es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["master","slave1","slave2"] #主节点配置 # 是否支持跨域,是:true,在使用head插件时需要此配置,“*” 表示支持所有域名 http.cors.enabled: true http.cors.allow-origin: "*" action.destructive_requires_name: true action.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history* xpack.security.enabled: false xpack.monitoring.enabled: true xpack.graph.enabled: false xpack.watcher.enabled: false xpack.ml.enabled: false -
从节点2
-
#设置集群的名称 cluster.name: es-cluster #修改当前节点的hostname名称 node.name: slave2 #设置是否能成为主节点,false是永远不可能成为主节点,true:表示有可能成为主节点,并不一定。跟指定的参 数cluster.initial_master_nodes 有关系。当所有node都可为主节点时,如果主节点宕机,其他节点会再次选举一个新的主节点. node.master: true #当前节点是否用于存储数据 node.data: true #修改索引存放路径 path.data: /usr/local/src/elasticsearch/elasticsearch-7.3.1/data #修改日志存放路径 path.logs: /usr/local/src/elasticsearch/elasticsearch-7.3.1/logs #是否锁住ES节点内存交换 bootstrap.memory_lock: true #监听IP,用于访问ES network.host: 192.168.192.12 #ES对外提供的http监听端口 http.port: 9200 # TCP的默认监听端口,默认 9300 transport.tcp.port: 9300 # 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4) discovery.zen.minimum_master_nodes: 2 #es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["master:9300","slave1:9300","slave2:9300"] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5 # es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["master","slave1","slave2"] #主节点配置 # 是否支持跨域,是:true,在使用head插件时需要此配置,“*” 表示支持所有域名 http.cors.enabled: true http.cors.allow-origin: "*" action.destructive_requires_name: true action.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history* xpack.security.enabled: false xpack.monitoring.enabled: true xpack.graph.enabled: false xpack.watcher.enabled: false xpack.ml.enabled: false
-
-
集群所有节点进入bin目录,切换之前建立的普通用户
-
su es ./elasticsearch -
成功如下



-
使用restful调用
-
curl -XGET http://192.168.192.10:9200
- 使用浏览器调用
1.4 ElasticSearch Chrome插件
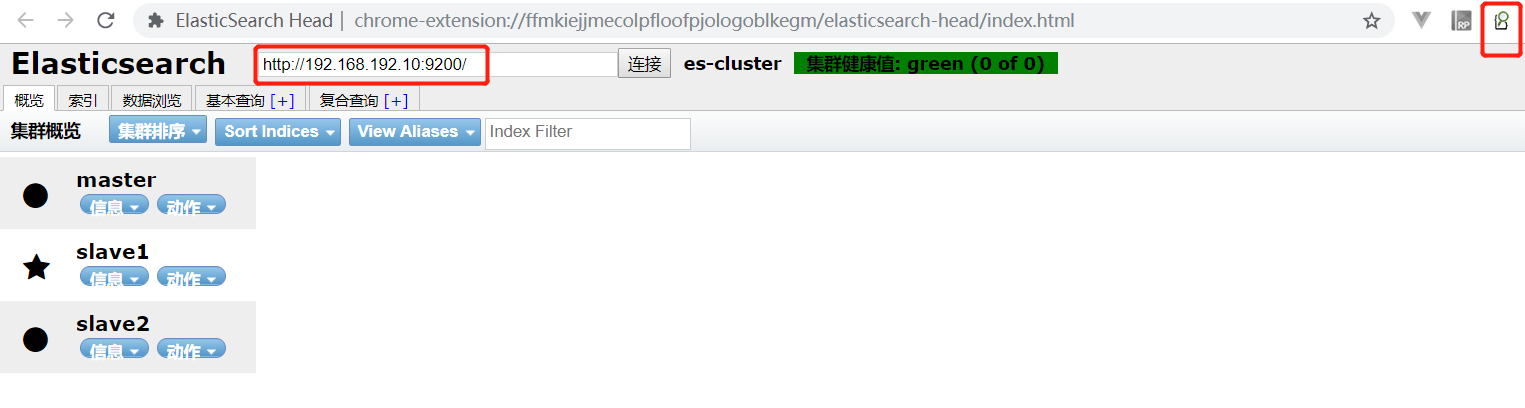
BIgDesk插件用于监控es集群
kibana用于读取es中索引库的type信息,并使用可视化图表的方式展示出来。
cerebro漂亮的es查询工具
1.5 kibana 安装
-
百度网盘下载地址:https://pan.baidu.com/s/1YmFdSOysZ9QxlO15avZraA 提取码:9oio
-
下载解压

-
tar -zxvf kibana-7.3.1-linux-x86_64.tar.gz #修改配置文件,添加如下内容 vim kibana-7.3.1-linux-x86_64/config/kibana.yml server.host: "192.168.192.10" elasticsearch.hosts: ["http://192.168.192.10:9200","http://192.168.192.11:9200","http://192.168.192.12:9200"] -
启动(kibana不建议以root用户启动,如果用root启动,需要加--allow-root)
-
./bin/kibana --allow-root -
访问5601端口
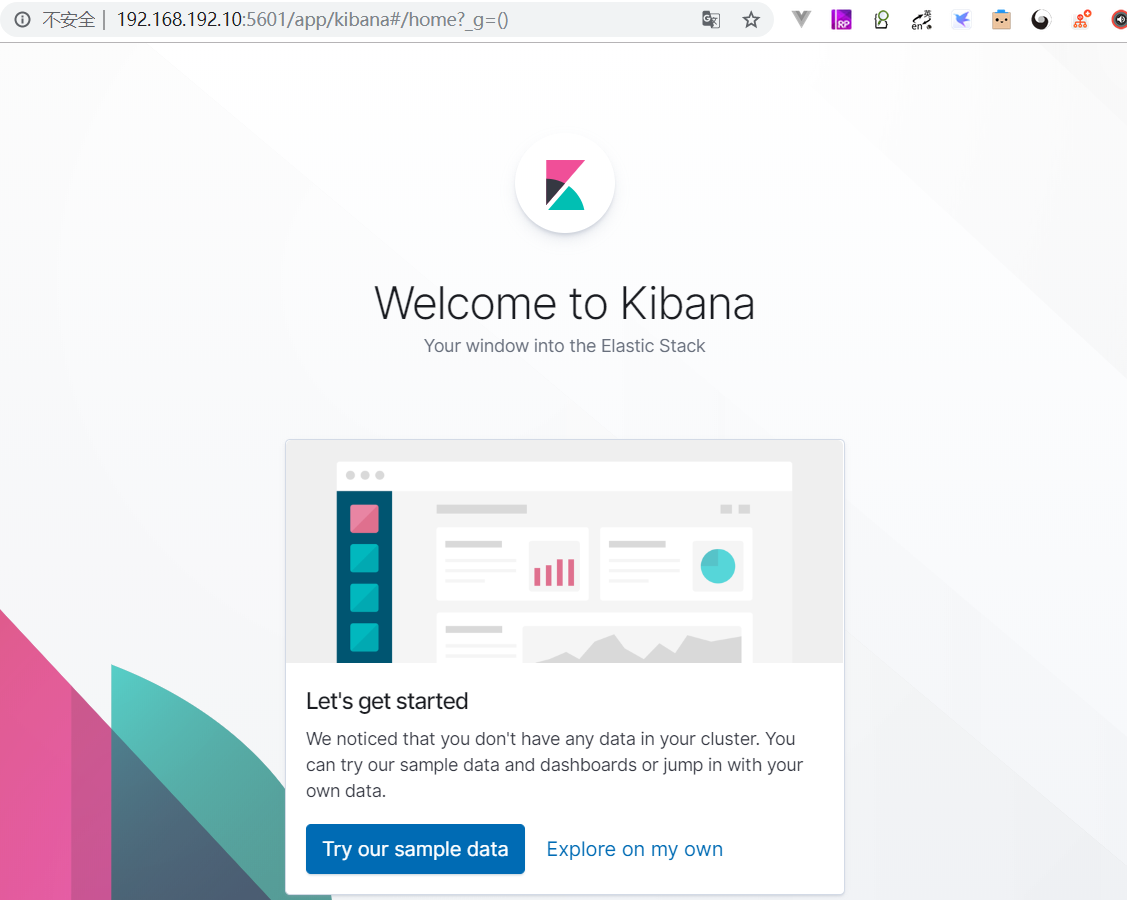
- 可以选择试试数据样本 或者 直接开始探索
- 这里选择Try our sample data,将数据导入ES中,方便后面学习使用。


- 可以选择添加仪表盘的各种视图,玩玩吧。
1.6 Open Distro For Elasticsearch
Open Distro for Elasticsearch使您可以使用熟悉的SQL查询语法从Elasticsearch中提取见解。使用聚合,分组依据和where子句来调查数据。以JSON文档或CSV表的形式读取数据,因此您可以灵活地使用最适合自己的格式,也就是抛弃DSL,多好啊!
1.6.1 Open Distro For Elasticsearch 搭建
-
https://github.com/opendistro-for-elasticsearch/sql/releases
-
注意查看对应es版本,由于这里采用es7.4.2,所以sql插件选择1.4.0.0
-
太慢可以点这里下载解压:https://files.cnblogs.com/files/ttzzyy/sql-1.4.0.0.tar.gz
tar -zxvf sql-1.4.0.0.tar.gz
cd sql-1.4.0.0
#1 修改build.gradle
vim build.gradle
#将(有两个地方)
repositories {
mavenCentral()
}
#修改为
repositories {
maven { url 'https://maven.aliyun.com/repository/central' }
maven { url 'https://maven.aliyun.com/repository/apache-snapshots' }
maven { url 'https://maven.aliyun.com/repository/gradle-plugin' }
maven { url 'https://maven.aliyun.com/repository/google' }
maven { url 'https://maven.aliyun.com/repository/jcenter' }
maven { url 'https://maven.aliyun.com/repository/publics' }
maven { url 'http://repo1.maven.org/maven2' }
maven { url 'http://repo2.maven.org/maven2' }
mavenCentral()
}
#2 修改gradle.properties
vim gradle.properties
org.gradle.daemon=true // 开启线程守护,第一次编译时开线程,之后就不会再开了
org.gradle.parallel=true // 开启并行编译,相当于多条线程再走
org.gradle.configureondemand=true 启用新的孵化模式
#3 构建
./gradlew build
-
编译过后,sql-1.4.0.0/build/distributions/opendistro_sql-1.4.0.0.zip会有一个这个包
-
需要VPN,如果编译不了可以在这里下载
-
所有节点安装插件
/usr/local/src/elasticsearch/elasticsearch-7.4.2/bin/elasticsearch-plugin install file:///usr/local/src/sql-1.4.0.0/build/distributions/opendistro_sql-1.4.0.0.zip

- 重启ES集群
1.6.2 elasticsearch-sql 使用
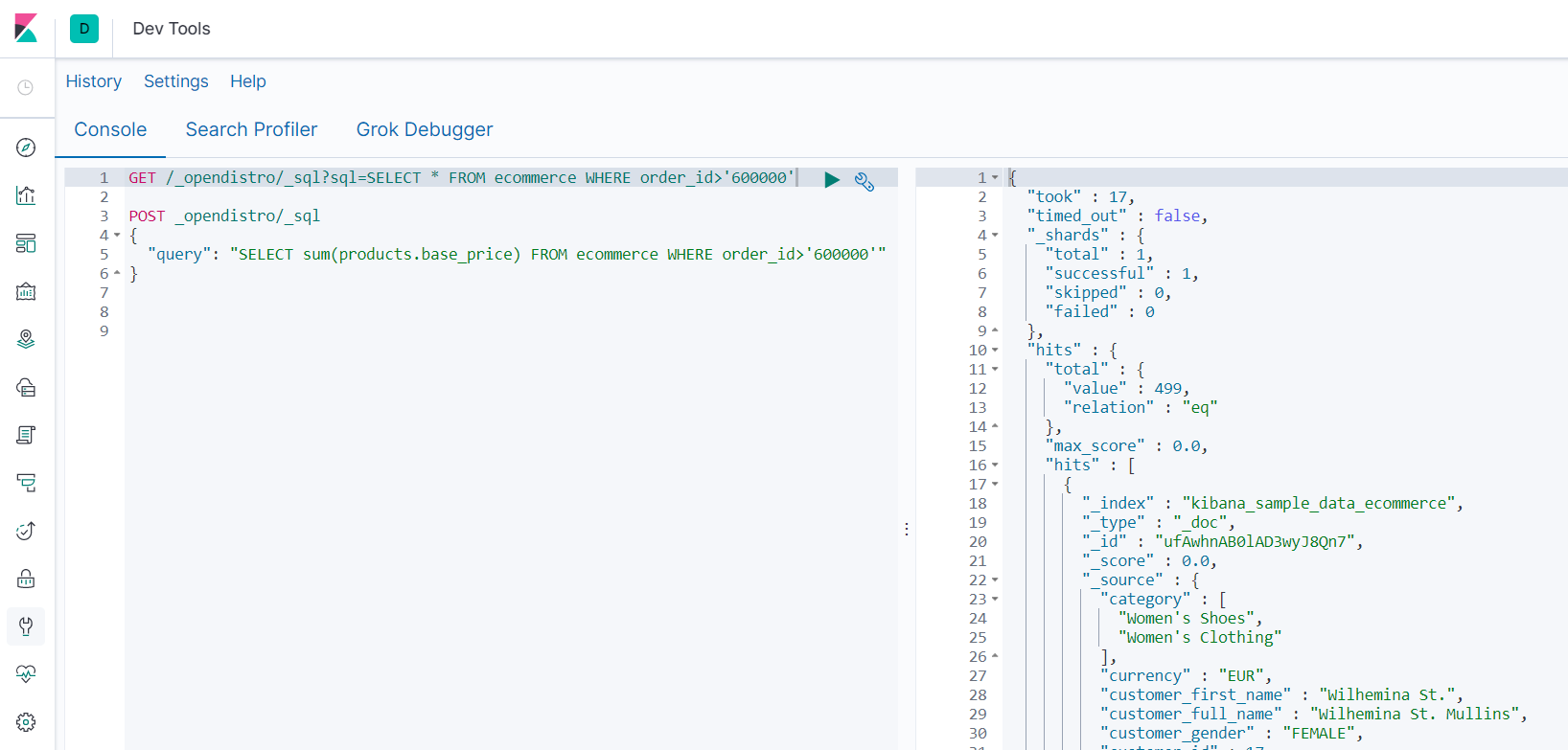
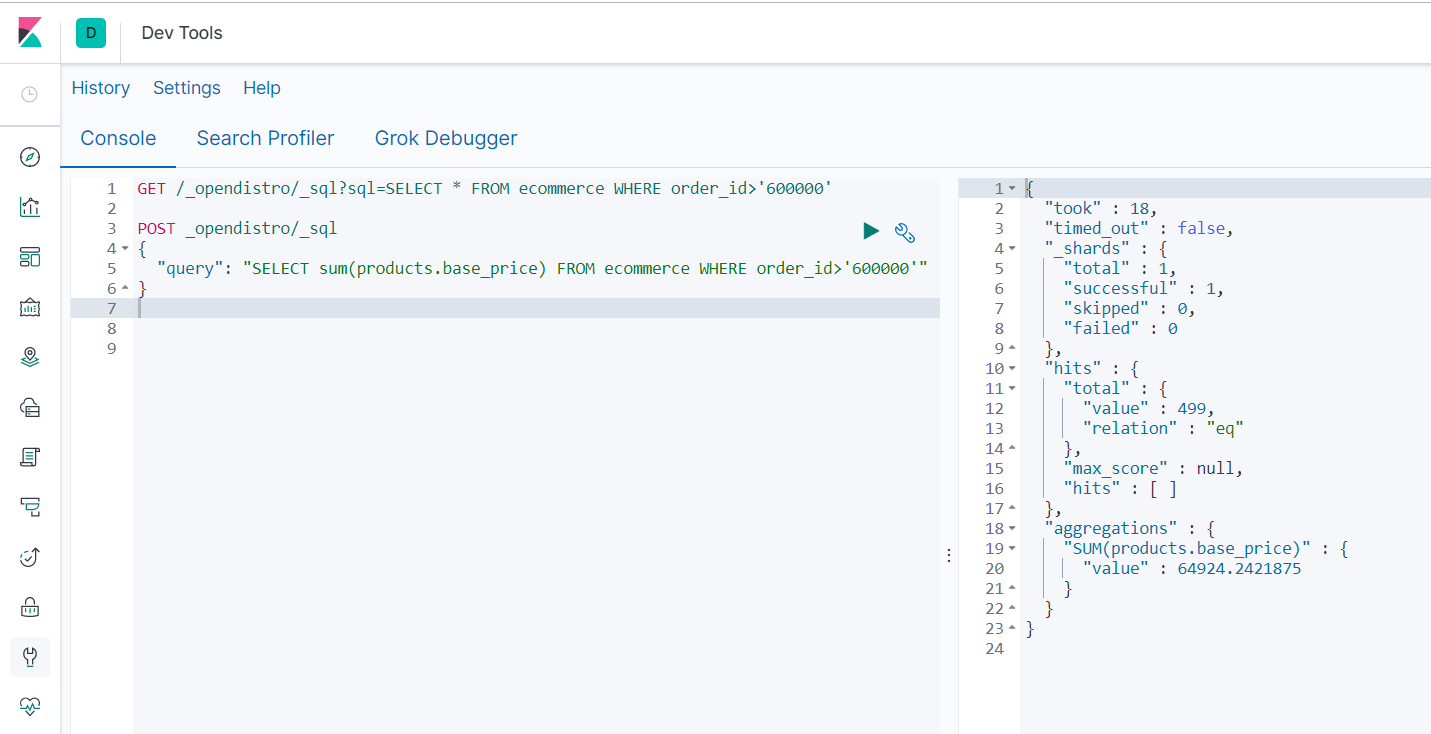
GET /_opendistro/_sql?sql=SELECT * FROM ecommerce WHERE order_id>'600000'
POST _opendistro/_sql
{
"query": "SELECT sum(products.base_price) FROM ecommerce WHERE order_id>'600000'"
}
2 ElasticSearch 数据类型
2.1文本类型
2.1.1 text 文本数据类型
用于索引全文值的字段。使用文本数据类型的字段,它们会被分词,在索引之前将字符串转换为单个术语的列表(倒排索引),分词过程允许ES搜索每个全文字段中的单个单词。文本字段不用于排序,很少用于聚合(重要的术语聚合是一个例外)。什么情况适合使用text datatype,只要不具备唯一性的字符串一般都可以使用text,例如:电子邮件正文,商品介绍,个人简介
①analyzer:指明该字段用于索引时和搜索时的分析字符串的分词器(使用search_analyzer可覆盖它)。 默认为索引分析器或标准分词器
②fielddata:指明该字段是否可以使用内存中的fielddata进行排序,聚合或脚本编写?默认值为false,可取值true或false。(排序,分组需要指定为true)
③fields:text类型字段会被分词搜索,不能用于排序,而当字段既要能被搜索,又要能够排序,就要设置fields为keyword进行聚合排序。
④index:设置该字段是否可以用于搜索。默认为true,表示可以用于搜索。
⑤search_analyzer:设置在搜索时,用于分析该字段的分析器,默认是【analyzer】参数的值。
⑥search_quote_analyzer:设置在遇到短语搜索时,用于分析该字段的分析器,默认是【search_analyzer】参数的值。
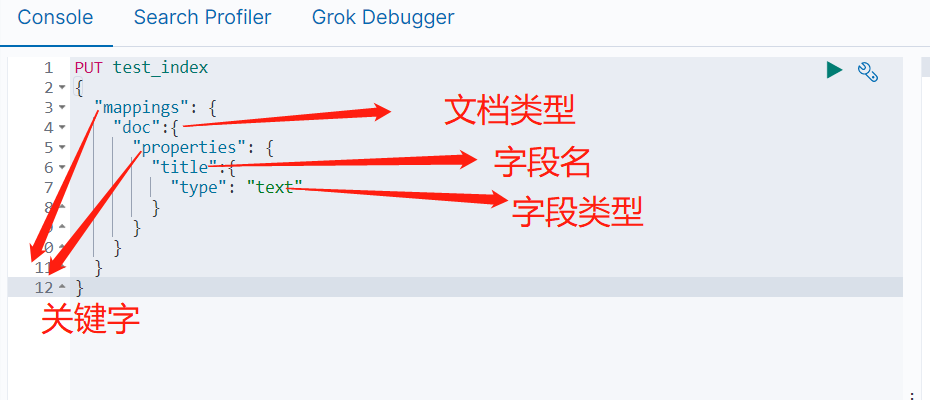
PUT test_index
{
"mappings": {
"doc":{
"properties": {
"title":{
"type": "text"
}
}
}
}
}
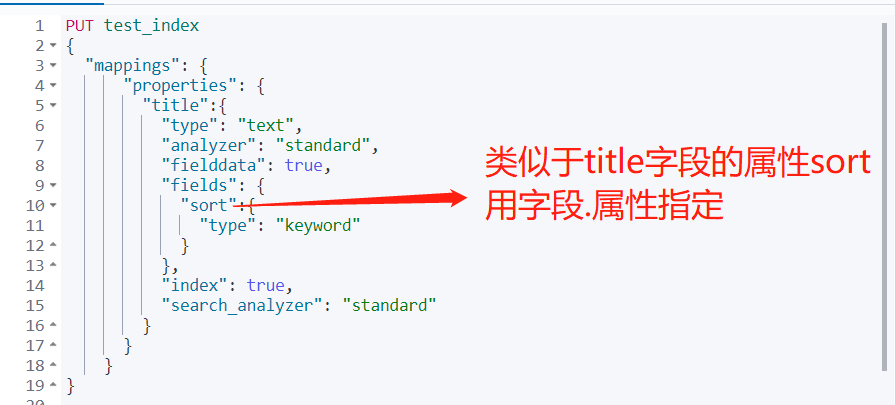
PUT test_index
{
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "standard",
"fielddata": true,
"fields": {
"sort":{
"type": "keyword"
}
},
"index": true,
"search_analyzer": "standard"
}
}
}
}
#插入两条数据,测试一下
PUT test_index/_doc/1
{
"title": "York"
}
PUT test_index/_doc/2
{
"title": "NEW York"
}
#查询测试
GET test_index/_search
{
"query": {
"match": {
"title": "york"
}
},
"sort": {
"title.sort": "asc"
}
}
2.1.2 keyword 关键字数据类型
keyword datatype,关键字数据类型,用于索引结构化内容的字段。使用keyword类型的字段,其不会被分析,给什么值就原封不动地按照这个值索引,所以关键字字段只能按其确切值进行搜索,通常用于过滤、排序和聚合。什么情况下使用keyword datatype,具有唯一性的字符串,例如:电子邮件地址、MAC地址、身份证号、状态代码...
①eager_global_ordinals:指明该字段是否加载全局序数?默认为false,不加载。 对于经常用于术语聚合的字段,启用此功能是个好主意。
②fields:指明能以不同的方式索引该字段相同的字符串值,例如用于搜索的一个字段和用于排序和聚合的多字段
③ignore_above:不要索引长于此值的任何字符串。默认为2147483647,以便接受所有值
④index:指明该字段是否可以被搜索,默认为true,表示可以被搜索
⑤index_options:指定该字段应将哪些信息存储在索引中,以便用于评分。默认为docs,但也可以设置为freqs,这样可以在计算分数时考虑术语频率
⑥norms:在进行查询评分时,是否需要考虑字段长度,默认为false,不考虑
PUT test_index
{
"mappings": {
"properties": {
"title":{
"type": "keyword",
"eager_global_ordinals": true,
"fields": {
"sort":{
"type":"text"
}
},
"ignore_above": 1024,
"index": true,
"index_options": "freqs",
"norms": true
}
}
}
}
2.2 数字类型
数字类型,这类数据类型都是以确切值索引的,可以使用"term"查询精确匹配。
-
ES支持的数字类型有
-
long 带符号的64位整数,最小值-263,最大值263-1 integer 带符号的32位整数,最小值-231,最大值231-1 short 带符号的16位整数,最小值-32768,最大值32767 byte 带符号的8位整数,最小值-128,最小值127 double 双精度64位IEEE 754 浮点数 float 单精度32位IEEE 754 浮点数 half_float 半精度16位IEEE 754 浮点数 scaled_float 带有缩放因子的缩放类型浮点数
①coerce:是否尝试将字符串转换为整数并截断整数的分数,默认为true,是
②ignore_malformed:如果为true,则忽略格式错误的数字;如果为false则格式错误的数字会抛出异常并拒绝整个文档,默认false
③index:指明该字段是否被搜索。默认为true,表示可以被搜索
④null_value:指明一个与该字段相同类型的值去替换掉该字段中的null。默认为null,表示该字段被视为缺失
- 注意点
- double、float、half_float这3种浮点型数据类型,认为-0.0和0.0是不同的值。这意味着在-0.0上进行查询(match or term)匹配不到0.0,反之亦然;范围查询也是如此:如果上限为-0.0则0.0将不匹配,如果下限为0.0则-0.0将不匹配。
- 就整数类型(byte,short,integer和long)而言,要选择满足实际需求的最小类型,这有助于索引和搜索。但请注意:ES存储数据是根据存储的实际值进行优化的,因此选择一种类型而不是另一种类型,将不会影响存储要求。
- scaled_float类型需要格外注意:必须指定缩放因子scaling_factor。ES索引时,原始值会乘以该缩放因子并四舍五入得到新值,ES内部储存的是这个新值,但返回结果仍是原始值。例如:scale_factor为10的scaled_float字段将在内部存储2.34为23,查询时,ES都会将查询参数*10再四舍五入得到的值与23匹配,若能匹配到返回结果为2.34
PUT test_index
{
"mappings": {
"properties": {
"number1":{
"type": "long"
},
"number2":{
"type": "integer"
},
"number3":{
"type": "short"
},
"number4":{
"type": "byte"
},
"number5":{
"type": "double"
},
"number6":{
"type": "float"
},
"number7":{
"type": "half_float"
},
"number8":{
"type": "scaled_float",
"scaling_factor": 100
}
}
}
}
#添加两条数据
#21.2121*100四舍五入得到2121储存结果
#21.2155*100四舍五入得到2122储存结果
PUT test_index/_doc/1
{
"number8": 21.2121
}
PUT test_index/_doc/2
{
"number8": 21.2155
}
#查询测试
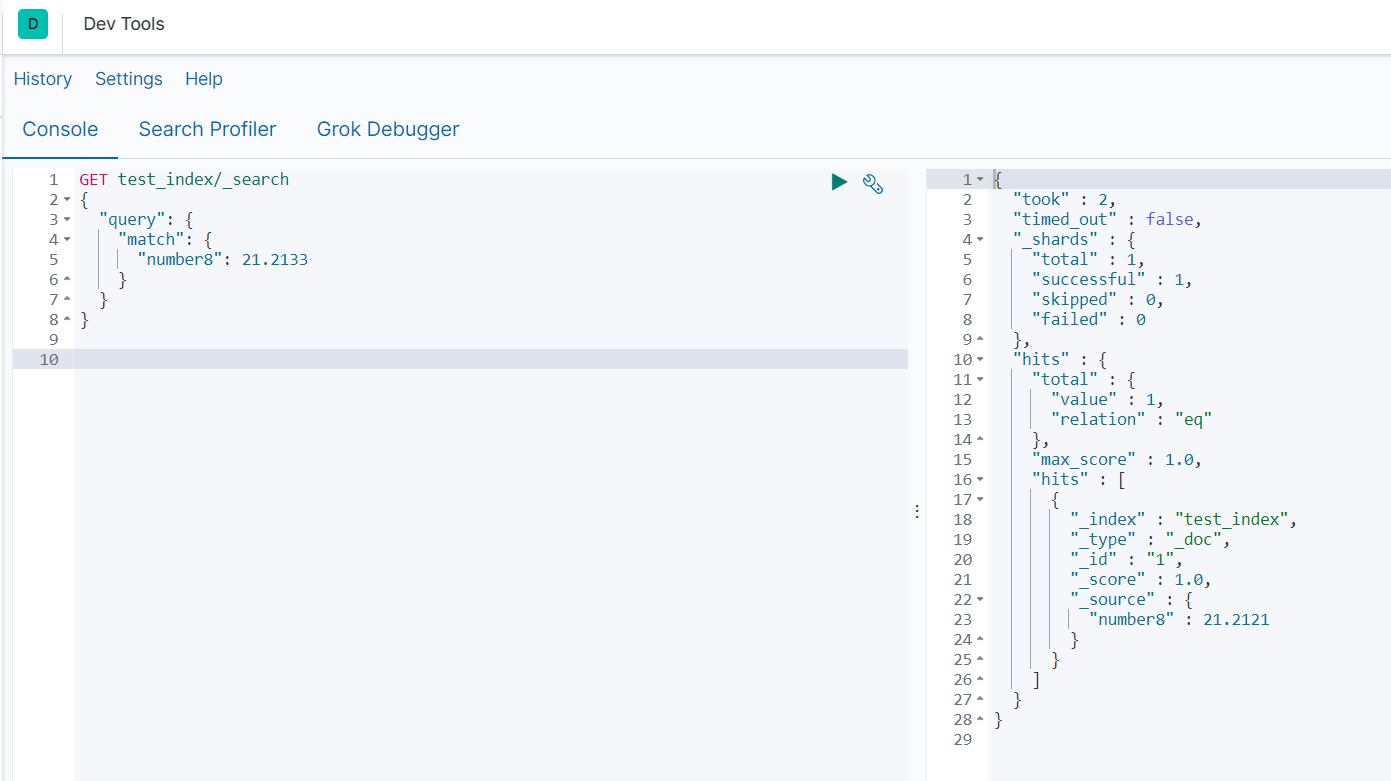
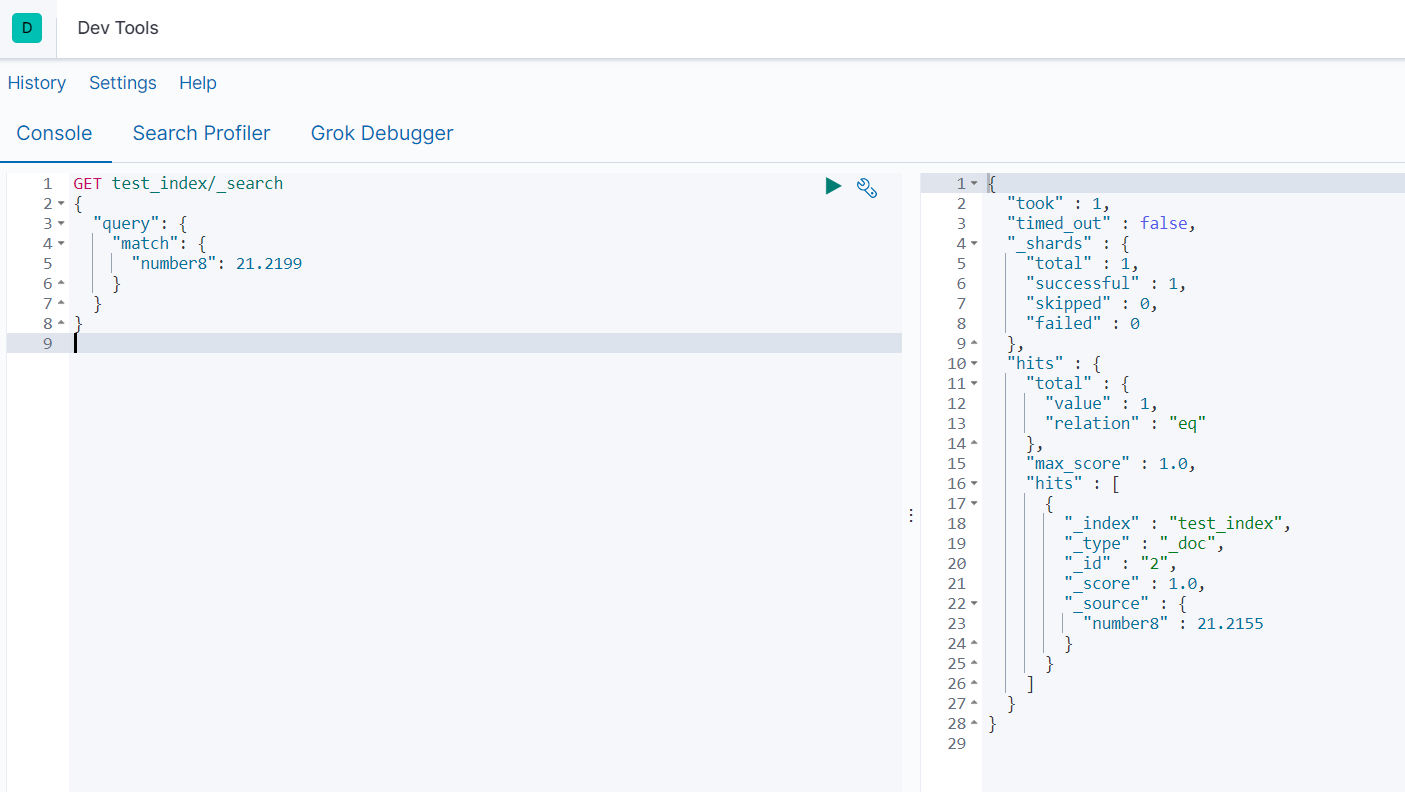
#21.2133*100四舍五入得到2121匹配上面插入的_id=1的数据
#21.2199*100四舍五入得到2122匹配上面插入的_id=2的数据
GET test_index/_search
{
"query": {
"match": {
"number8": 21.2133
}
}
}
GET test_index/_search
{
"query": {
"match": {
"number8": 21.2199
}
}
}
2.3 日期类型
日期数据类型。
-
由于JSON中没有表示日期的数据类型,所以ES中的日期可以表示为:
- 日期格式化后的字符串,如:"2018-01-01"或"2018/01/01 11:11:11"
- long类型值表示自纪元以来的毫秒数
- integer类型值表示自纪元以来的秒数
-
如果指定了时区,ES将日期转换为UTC,然后再存储为自纪元以来的毫秒数(long类型)。
-
当字段被设置为date类型时,可以自定义日期格式,但如果未指定格式,则使用默认格式:"strict_date_optional_time||epoch_millis"
-
若未指定自定义日期格式,在保存日期的时候容易出错。若未指定日期格式,ES采用默认日期格式:严格日期格式或者时间戳,例如:
- 2020-01-01 ---- yes
- 2020/01/01 ---- no
- 2020-01-1 ---- no
- 1577808000000 ---- yes
-
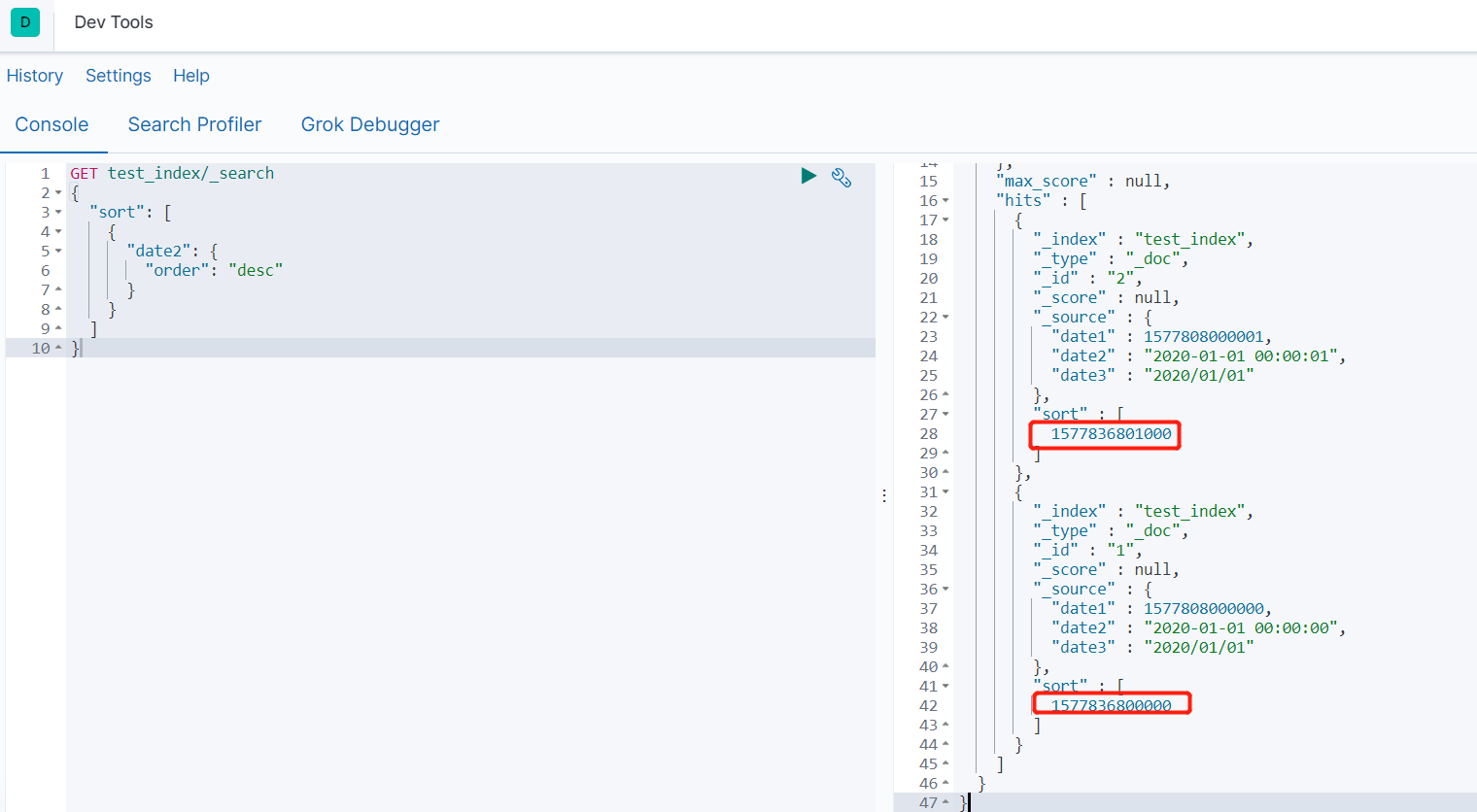
在使用date类型字段进行排序时,返回的排序值都是以毫秒为单位
①format:自定义的日期格式,默认:strict_date_optional_time || epoch_millis
②ignore_malformed:若为true,则忽略格式错误的数字;若为false,则格式错误的数字会抛出异常并拒绝整个文档。默认false
③index:指明该字段是否可以被搜索,true为可以,默认true
④null_value:接受其中一个配置格式的日期值作为替换任何显式空值的字段。默认为null,表示该字段被视为缺失
PUT test_index
{
"mappings": {
"properties": {
"date1":{
"type": "date"
},
"date2":{
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"date3":{
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy/MM/dd||epoch_millis"
}
}
}
}
#添加2条数据
PUT test_index/_doc/1
{
"date1": 1577808000000,
"date2": "2020-01-01 00:00:00",
"date3": "2020/01/01"
}
PUT test_index/_doc/2
{
"date1": 1577808000001,
"date2": "2020-01-01 00:00:01",
"date3": "2020/01/01"
}
#查询测试
GET test_index/_search
{
"sort": [
{
"date2": {
"order": "desc"
}
}
]
}
2.4 范围类型
范围数据类型。具有大小关系的一个值区间,所以会用到gt、gte、lt、lte..等逻辑表示符。
- ES支持下面6种范围数据类型
- integer_range,带符号的32位整数区间,最小值-231,最大值231-1
- long_range,带符号的64位整数区间,最小值-263,最小值263-1
- float_range,单精度32位IEEE 754浮点数区间
- double_range,双精度64位IEEE 754浮点数区间
- date_range,日期值范围,表示为系统纪元以来经过的无符号64位整数毫秒
- ip_range,支持IPv4或IPv6(或混合)地址ip值范围
PUT test_index
{
"mappings": {
"properties": {
"data1":{
"type": "integer_range"
},
"data2":{
"type": "float_range"
},
"data3":{
"type": "date_range",
"format": "yyyy-MM-dd HH:mm:ss"
},
"data4":{
"type": "ip_range"
}
}
}
}
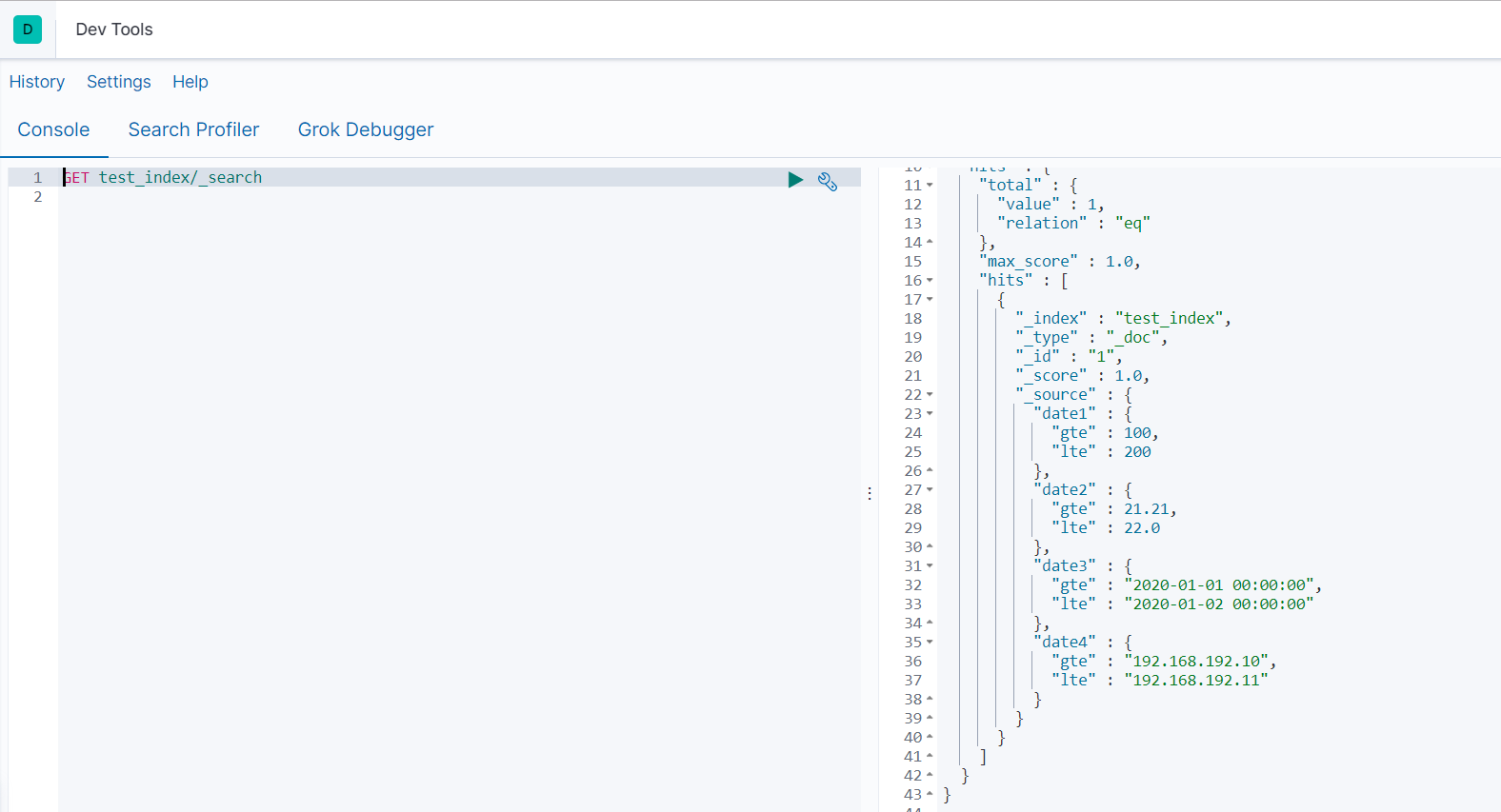
#添加数据
PUT test_index/_doc/1
{
"date1": {
"gte": 100,
"lte": 200
},
"date2": {
"gte": 21.21,
"lte": 22.00
},
"date3": {
"gte": "2020-01-01 00:00:00",
"lte": "2020-01-02 00:00:00"
},
"date4": {
"gte": "192.168.192.10",
"lte": "192.168.192.11"
}
}
#查询测试
GET test_index/_search
2.5 数组类型
数组类型。默认情况下,任何字段都可以包含零个或多个值,当包含多个值时,它就表示array datatype了。但是,数组中的所有值必须具有相同的数据类型(要么同为字符串,要么同为整型,不能数组中一些值为字符串,另一些值为整型)
-
当数组里面放的是对象(object datatype),即对象数组时,要改为使用nested datatype。
-
在动态添加字段时,ES从数组中的第一个值确定字段类型,所有后续值必须具有相同的数据类型,或者必须至少可以将后续值强制转换为相同的数据类型。
-
使用array datatype,不需要预先配置,它们是开箱即用的。(不像整型,它需要手动定义type: "integer")
-
使用_mapping查看索引的映射类型时,array datatype不会被写出来,还是以数组的元素的基本类型来表示。
PUT test_index
{
"mappings": {
"properties": {
"data1":{
"type": "long"
},
"data2":{
"type": "text"
}
}
}
}
#添加数据
PUT test_index/_doc/1
{
"date1": [1,2,3],
"date2": ["a","b","c"]
}
#查询测试
GET test_index/_search
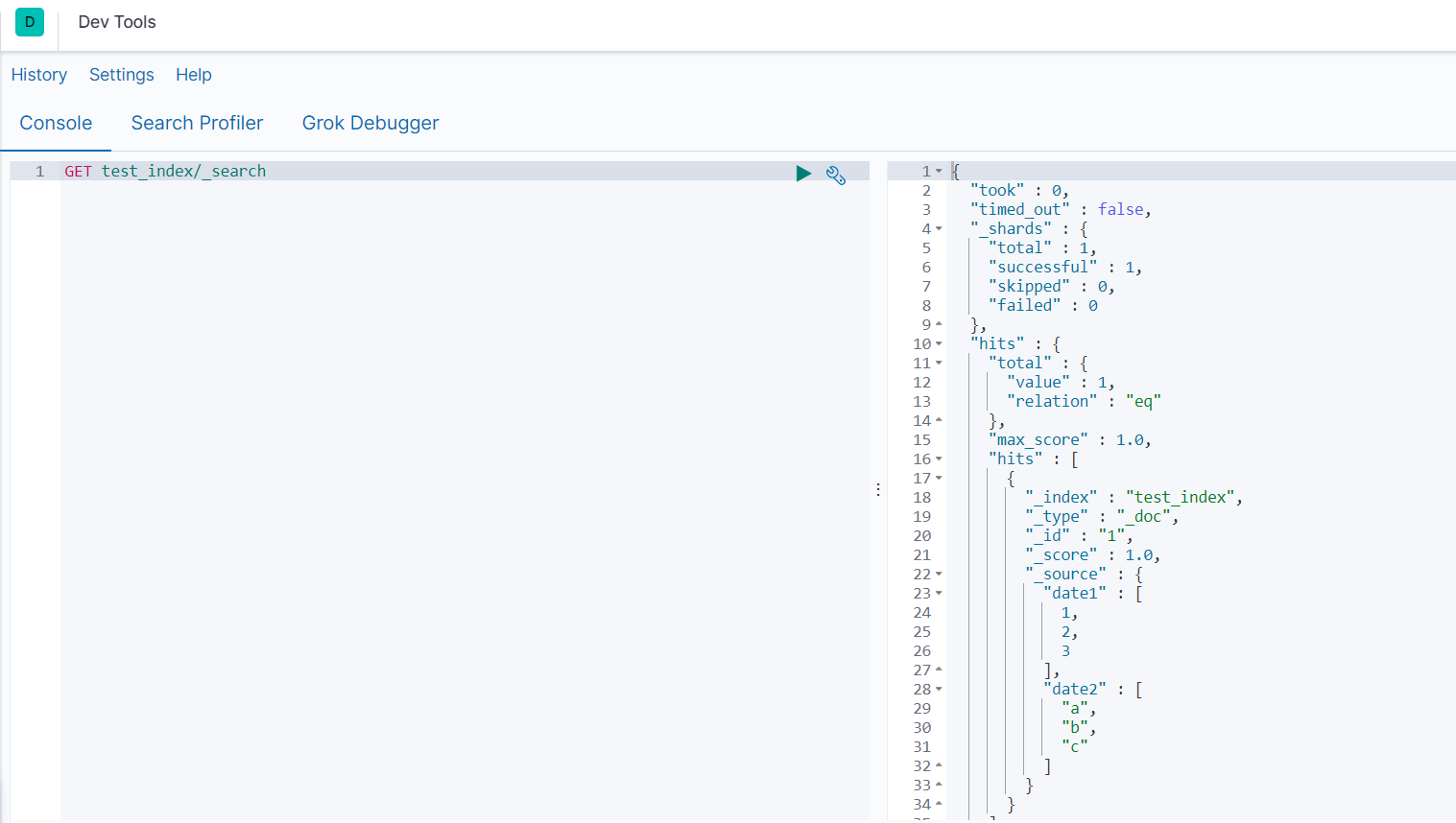
2.6 对象类型
即对象类型。一个文档的一个属性可以是一个内部对象,而且,这个内部对象,可以再包含一个内部对象..(可以有多层嵌套)
- 整个外部文档是一个JSON对象
- 在ES内部,这种文档会被索引成一种简单平坦的键值对列表(平铺)
PUT test_index
{
"mappings": {
"properties": {
"persion":{
"type": "object"
}
}
}
}
PUT test_index/_doc/1
{
"persion": [
{
"first": "li",
"last": "si"
},
{
"first": "李",
"last": "四"
}
]
}
PUT test_index/_doc/2
{
"persion": [
{
"first": "li",
"last": "四"
},
{
"first": "李",
"last": "si"
}
]
}
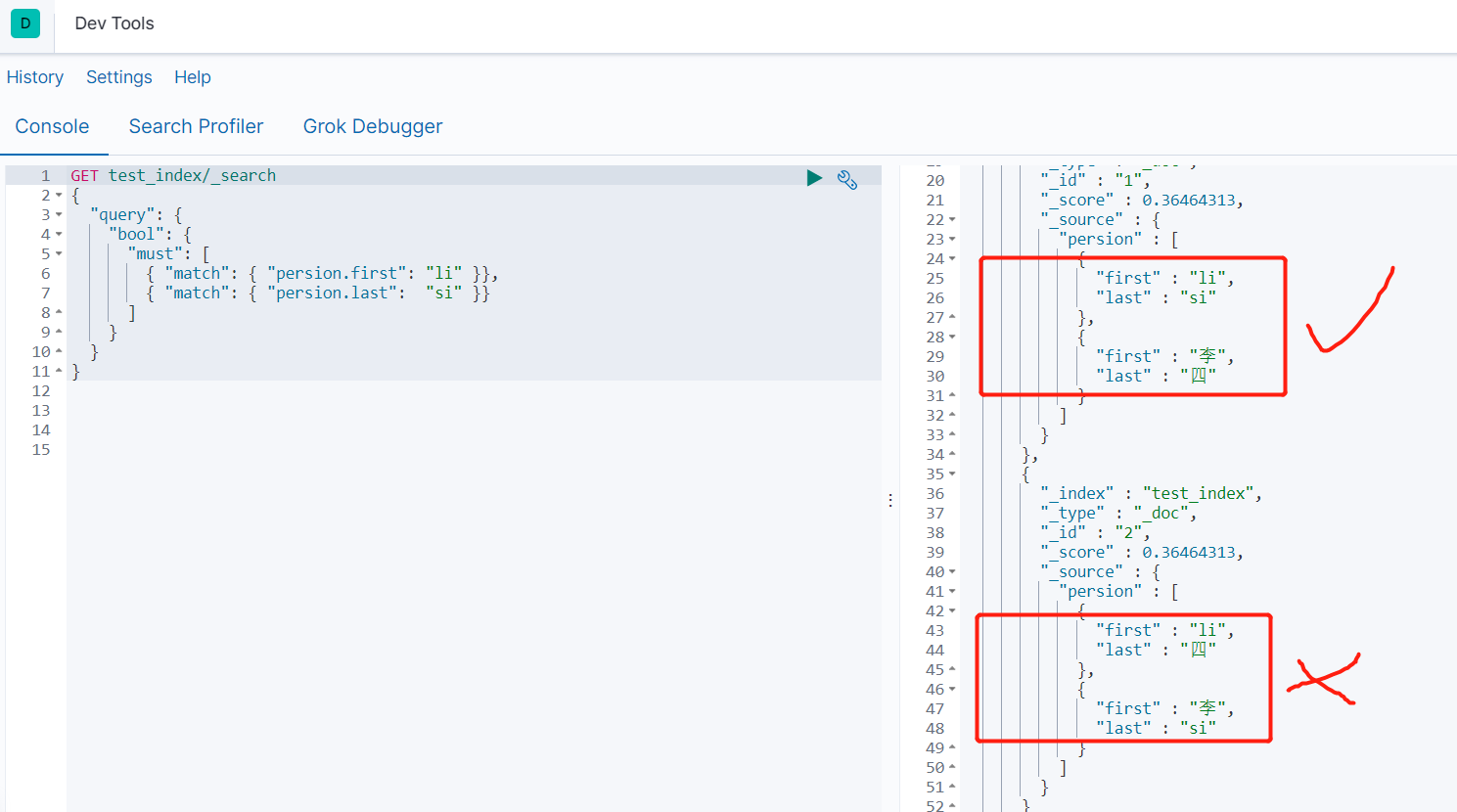
#查询测试1
GET test_index/_search
- 无法做到对象中数组独立索引和查询
#查询测试
GET test_index/_search
{
"query": {
"bool": {
"must": [
{ "match": { "persion.first": "li" }},
{ "match": { "persion.last": "si" }}
]
}
}
}
-
出现问题,不正确的匹配。使用nested嵌套对象类型解决
-
原因:对象类型里的数组类型会将字段平铺为多值字段,因此 li si 之间的关联关系会消失,会将上面的文档转换成如下格式:
-
{
persion.first:["li 李"]
persion.last:["四 si"]
}
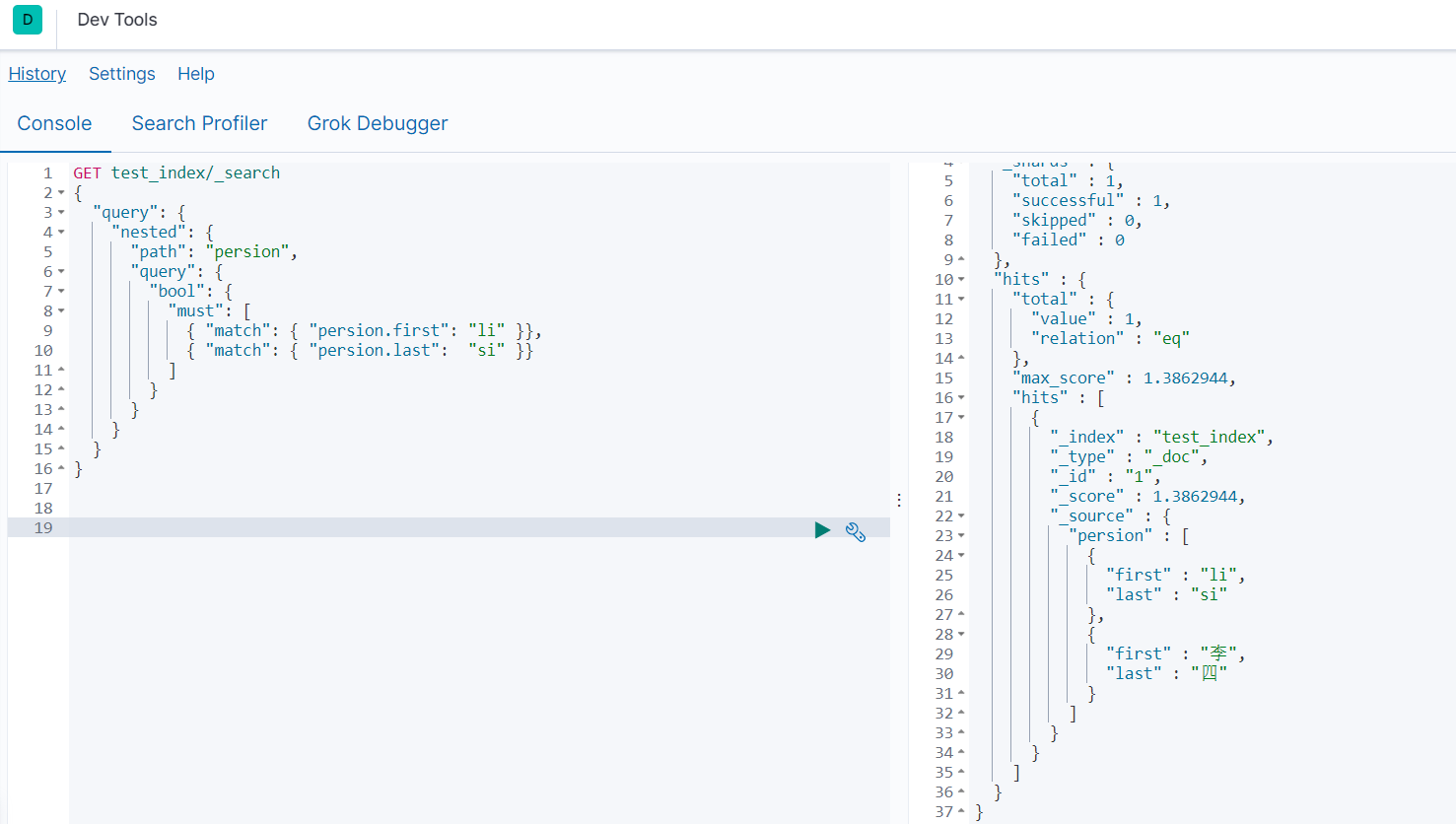
2.7 嵌套对象类型
嵌套数据类型,是object datatype的专用版本,在文档属性是一个对象数组时使用,它允许对象数组彼此独立地编制索引和查询
PUT test_index
{
"mappings": {
"properties": {
"persion":{
"type": "nested"
}
}
}
}
#添加数据
PUT test_index/_doc/1
{
"persion": [
{
"first": "li",
"last": "si"
},
{
"first": "李",
"last": "四"
}
]
}
PUT test_index/_doc/2
{
"persion": [
{
"first": "li",
"last": "四"
},
{
"first": "李",
"last": "si"
}
]
}
#查询测试
GET test_index/_search
{
"query": {
"nested": {
"path": "persion",
"query": {
"bool": {
"must": [
{ "match": { "persion.first": "li" }},
{ "match": { "persion.last": "si" }}
]
}
}
}
}
}
2.8 地理类型
地址位置数据类型,可以用来表示经纬度。
PUT test_index
{
"mappings": {
"properties": {
"add":{
"type": "geo_point"
}
}
}
}
- 地理点表示为一个对象,lat属性表示维度,lon属性表示经度
PUT test_index/_doc/1
{
"add":{
"lat": 22.22,
"lon": -22.22
}
}
- 地理点表示为一个字符串,格式为:"lat,lon"
PUT test_index/_doc/2
{
"add": "22.22,-22.22"
}
- 地理点表示为一个geohash字符串
PUT test_index/_doc/3
{
"add": "eebnqm5bukpn"
}
- 地理点表示为一个数组,格式为[lon,lat],注意经纬度顺序字符串标识相反
PUT test_index/_doc/4
{
"add": [-22.22,22.22]
}
3 ElasticSearch 基础操作
- 注意:
- 索引库名称必须要全部小写,不能以下划线开头,也不能包括逗号。
- 如果没有明确指定索引数据的ID,那么es会自动生成一个随机的ID,需要使用POST参数
- PUT和POST进行更新时,是全局更新(可以理解为删除旧的,然后建立一个ID相同的新document)
- POST和PUT都可以进行添加和更新操作,但是PUT是幂等方法,POST不是,所以PUT用于更新,POST用于新增比较合适。(幂等:无论多少次操作,最终结果一致)
3.1 创建索引库
#创建索引库(只能使用put)
curl -XPUT 'http://192.168.192.10:9200/twitter?pretty'

- 插件创建索引
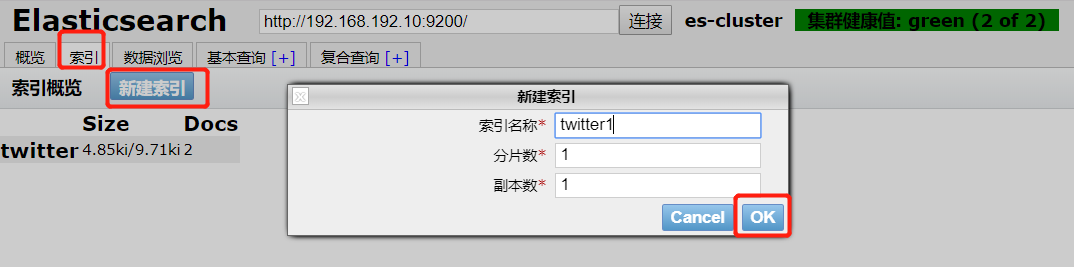
3.2 添加索引内容
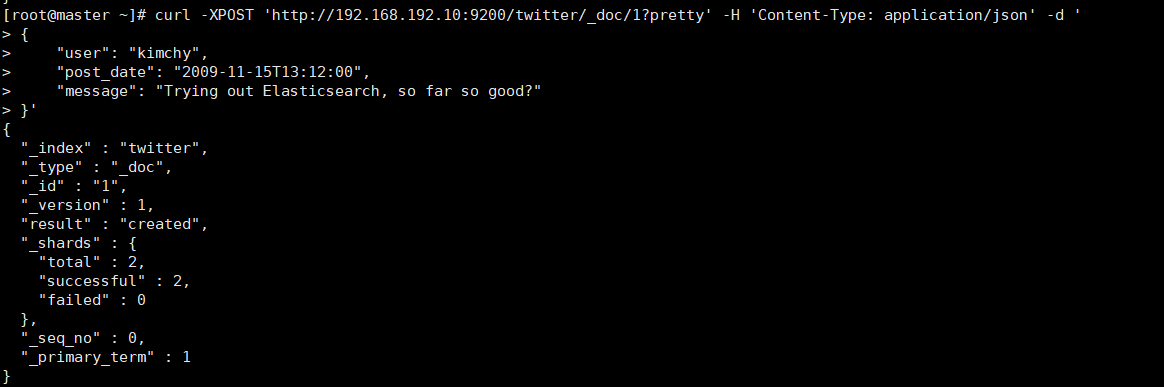
curl -XPOST 'http://192.168.192.10:9200/twitter/_doc/1?pretty' -H 'Content-Type: application/json' -d '
{
"user": "kimchy",
"post_date": "2009-11-15T13:12:00",
"message": "Trying out Elasticsearch, so far so good?"
}'
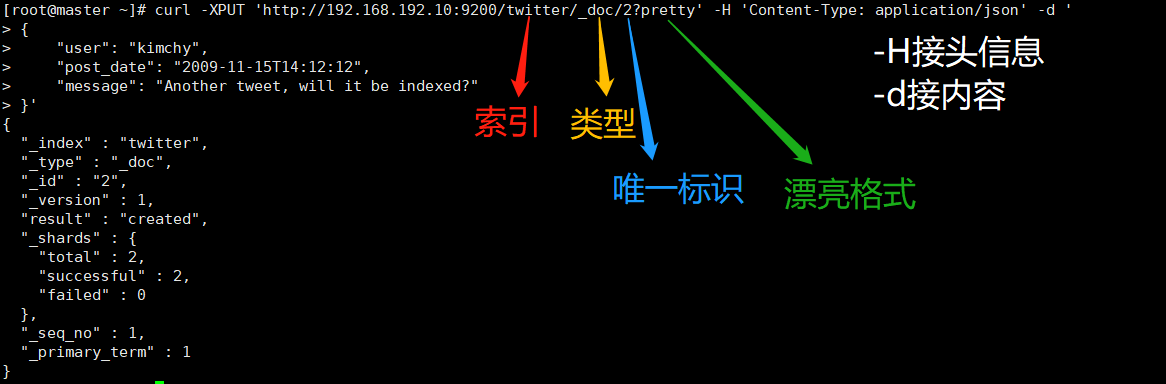
curl -XPUT 'http://192.168.192.10:9200/twitter/_doc/2?pretty' -H 'Content-Type: application/json' -d '
{
"user": "kimchy",
"post_date": "2009-11-15T14:12:12",
"message": "Another tweet, will it be indexed?"
}'
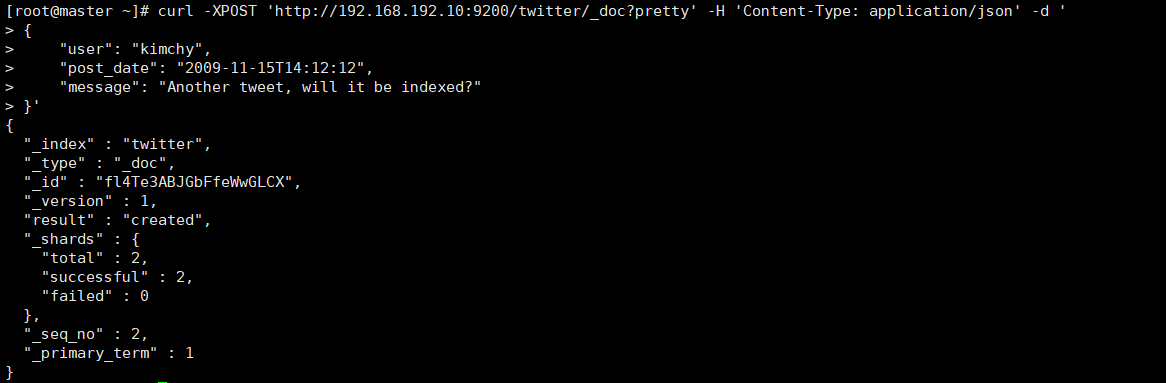
#不指定唯一ID标识,会自动生成,但是必须使用POST添加
curl -XPOST 'http://192.168.192.10:9200/twitter/_doc?pretty' -H 'Content-Type: application/json' -d '
{
"user": "kimchy",
"post_date": "2009-11-15T14:12:12",
"message": "Another tweet, will it be indexed?"
}'
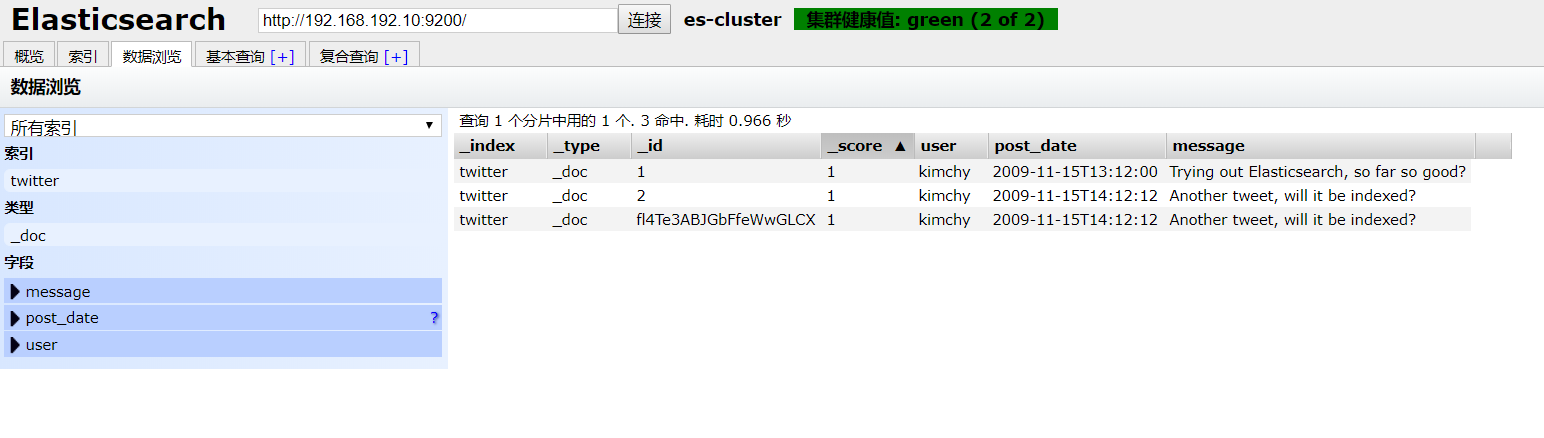
- 插件添加索引内容
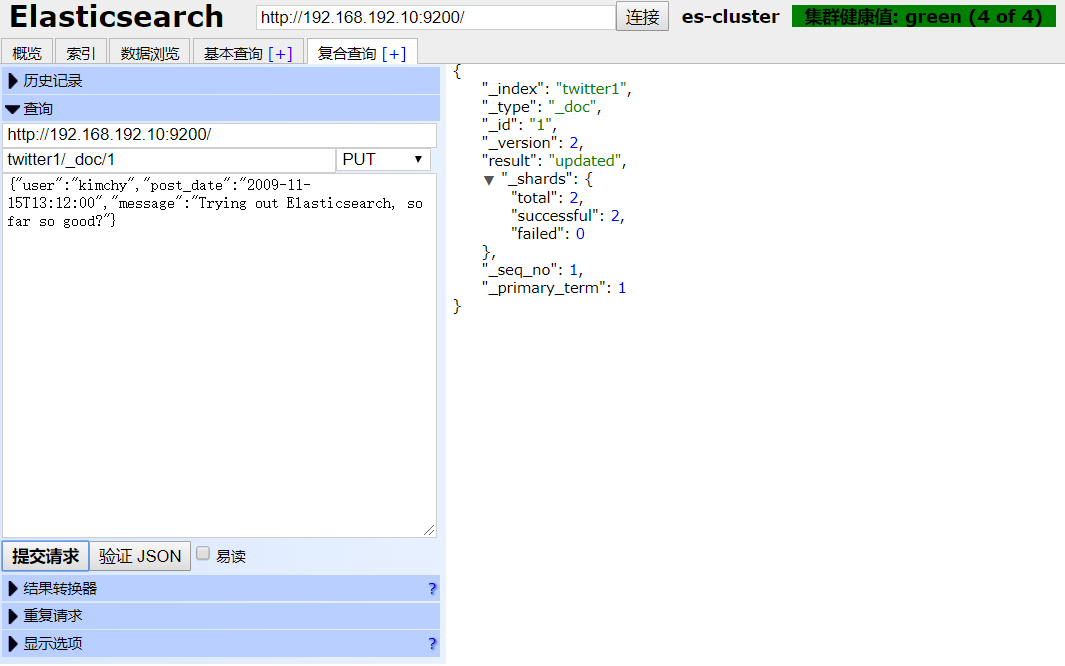
3.3 更新索引
3.3.1 全局更新
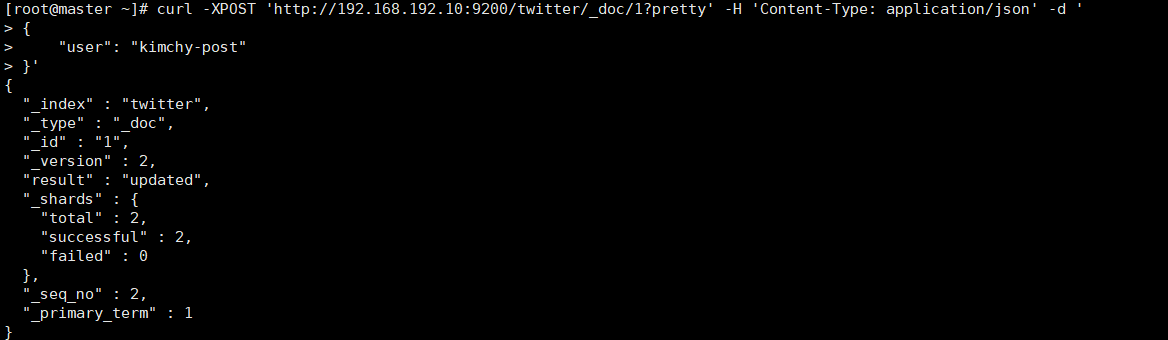
- post更新
curl -XPOST 'http://192.168.192.10:9200/twitter/_doc/1?pretty' -H 'Content-Type: application/json' -d '
{
"user": "kimchy-post"
}'
- put更新
curl -XPUT 'http://192.168.192.10:9200/twitter/_doc/2?pretty' -H 'Content-Type: application/json' -d '
{
"user": "kimchy-put"
}'
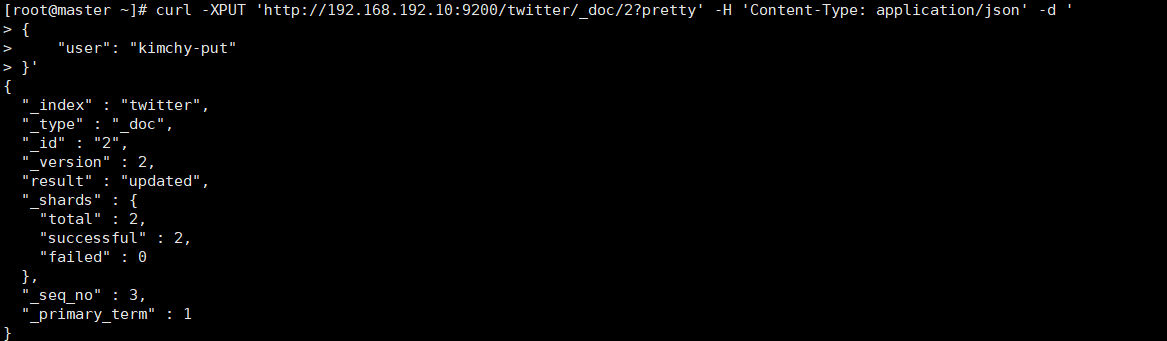
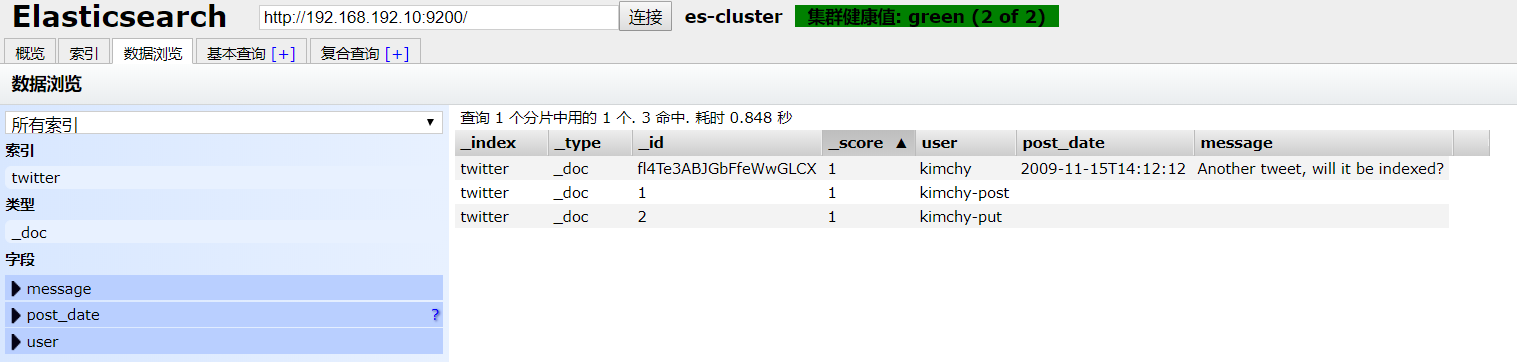
从上面的结果我们看出,不想被更新的字段也被删除了
3.3.2 局部更新
- 需要使用_update动作命令
#必须使用POST
curl -XPOST 'http://192.168.192.10:9200/twitter/_doc/fl4Te3ABJGbFfeWwGLCX/_update?pretty' -H 'Content-Type: application/json' -d '
{
"doc":{
"user": "kimchy-update"
}
}'
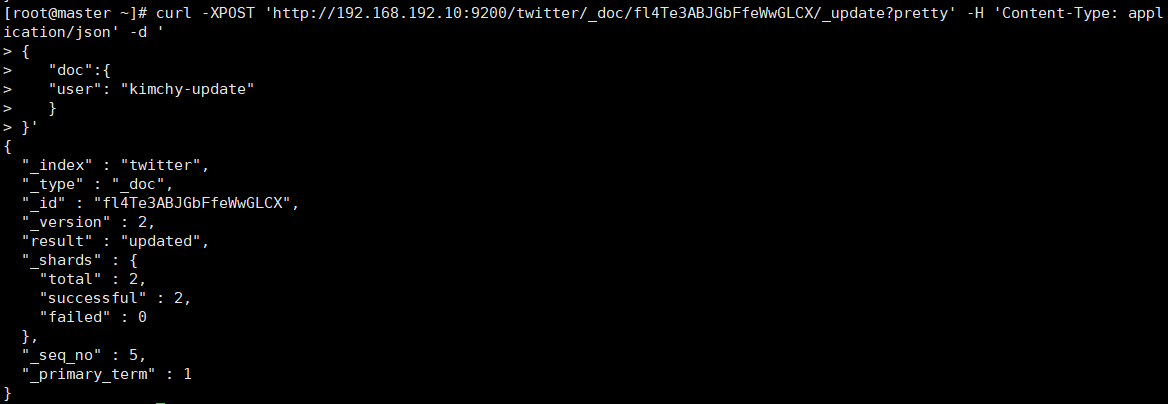
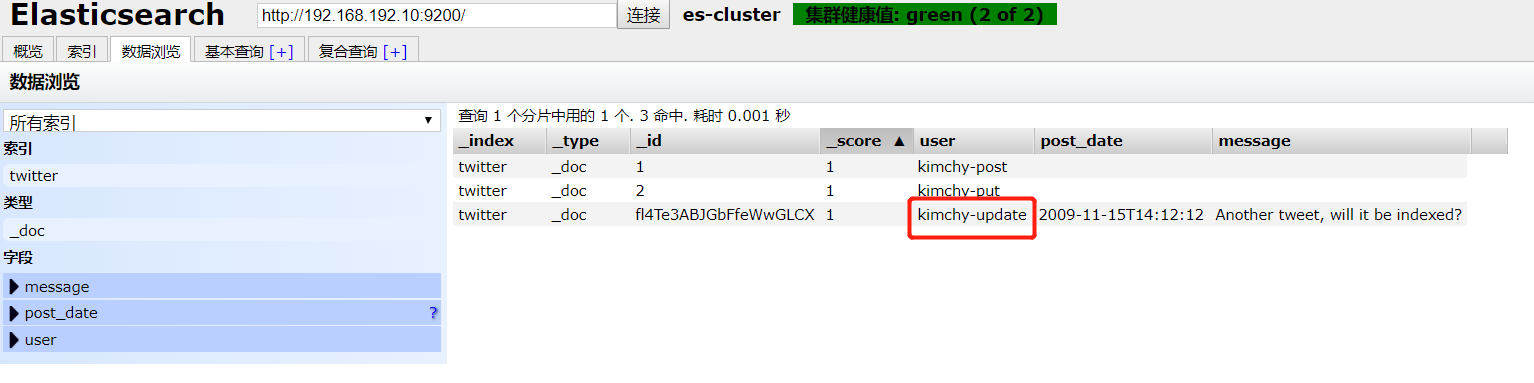
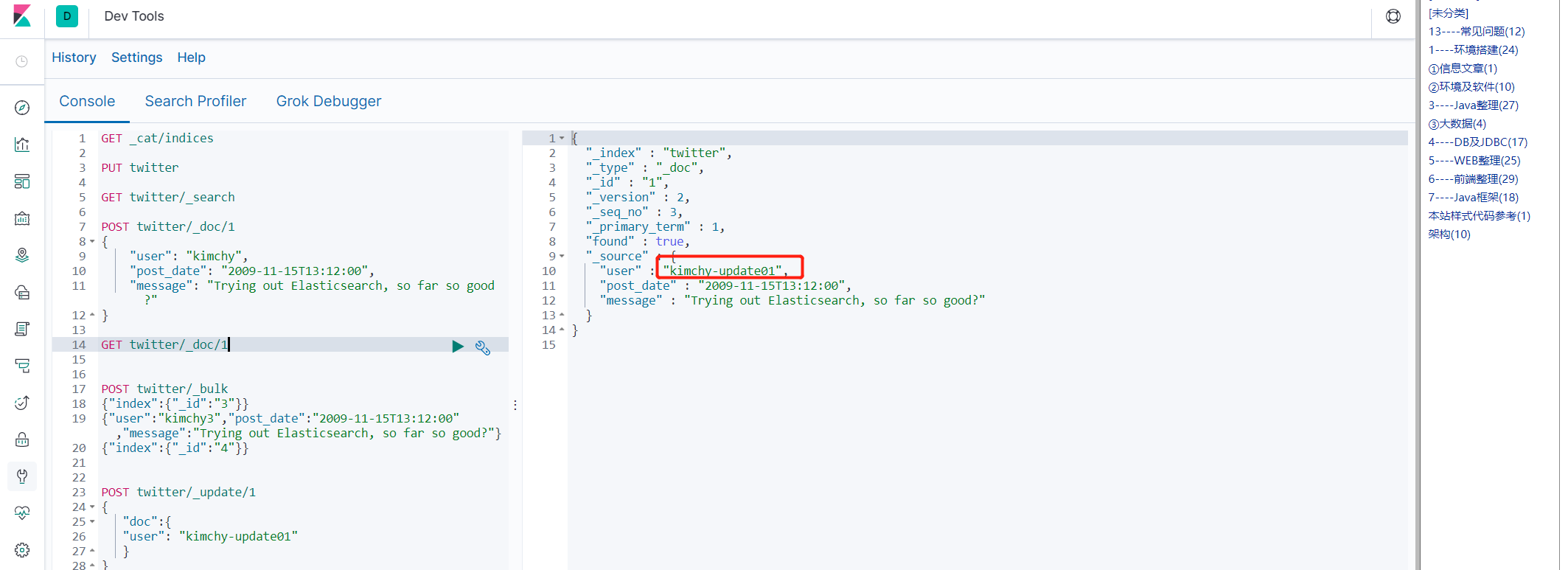
从上面看出做到了局部更新
3.4 查询索引
- 根据ID查看
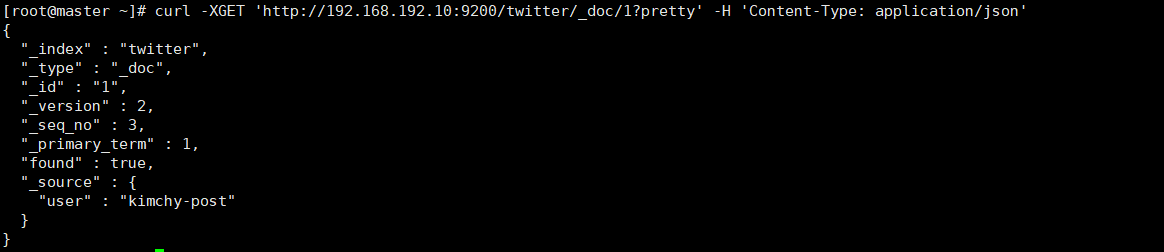
curl -XGET 'http://192.168.192.10:9200/twitter/_doc/1?pretty' -H 'Content-Type: application/json'
- 查询指定字段(_source)
curl -XGET 'http://192.168.192.10:9200/twitter/_doc/fl4Te3ABJGbFfeWwGLCX?_source=user,message&pretty' -H 'Content-Type: application/json'
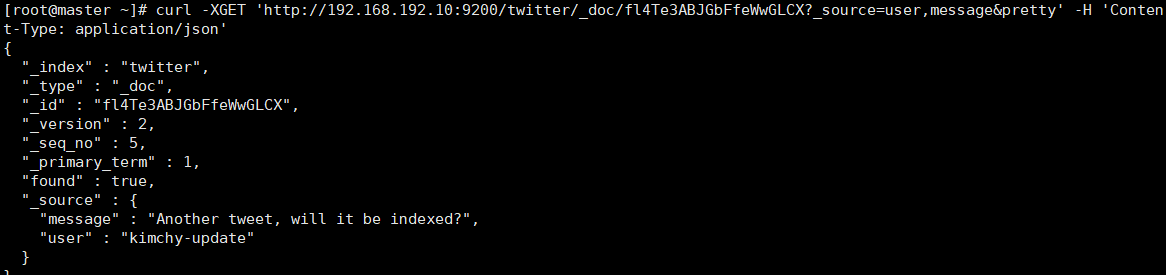
- 只获取source数据
curl -XGET 'http://192.168.192.10:9200/twitter/_doc/fl4Te3ABJGbFfeWwGLCX/_source?pretty' -H 'Content-Type: application/json'

- 查询所有(_search)
curl -XGET 'http://192.168.192.10:9200/twitter/_doc/_search?pretty' -H 'Content-Type: application/json'
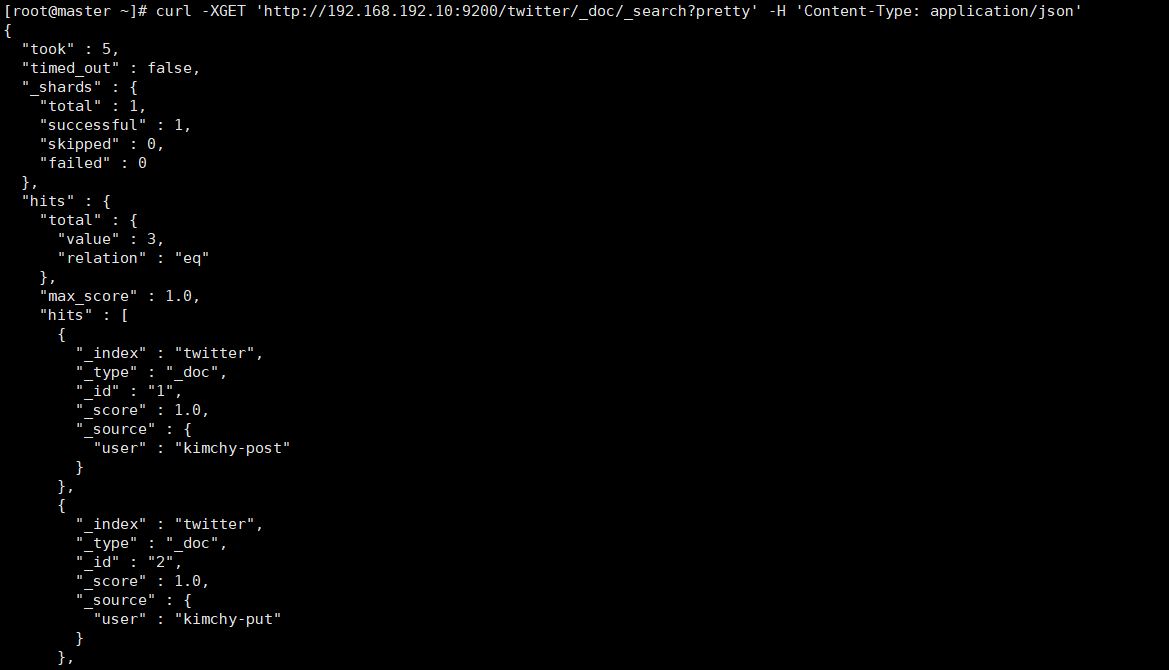
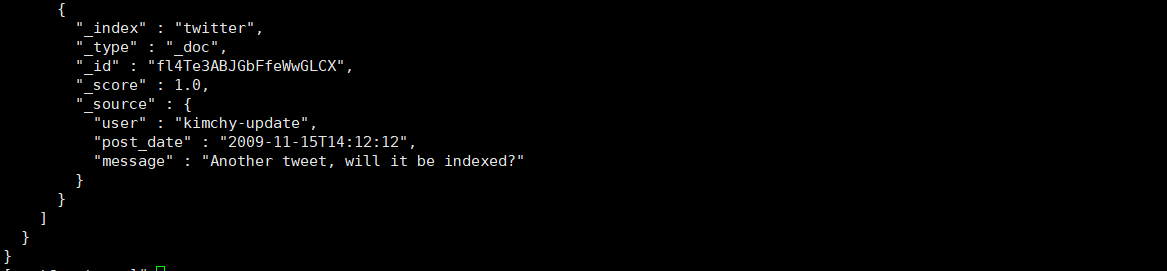
还有很多高级用法,请参考3.7的拓展
3.5 删除索引
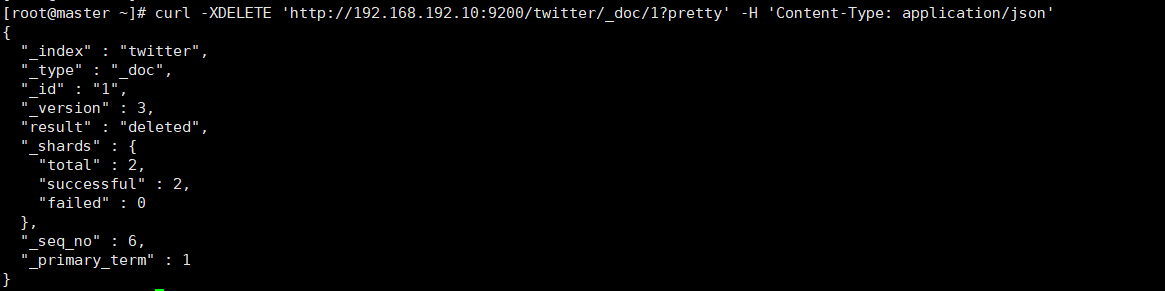
curl -XDELETE 'http://192.168.192.10:9200/twitter/_doc/1?pretty' -H 'Content-Type: application/json'
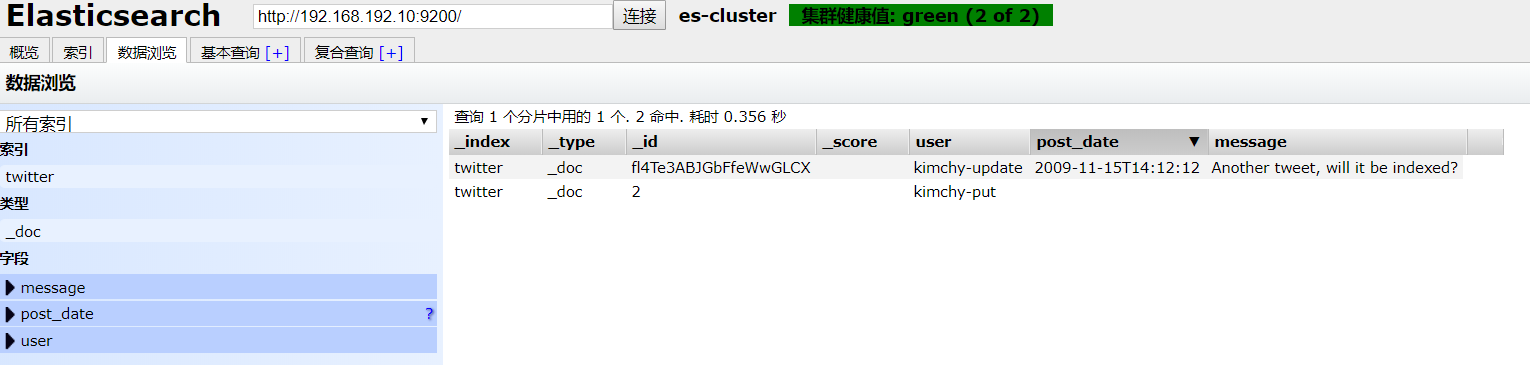
3.6 批处理bulk
bulk 好处就是可以 在一个文件里面执行 create update delete 等操作
如下面要进行什么操作,遵守什么格式就可以了。
3.6.1 新增案例
-
创建批处理文件test.json
-
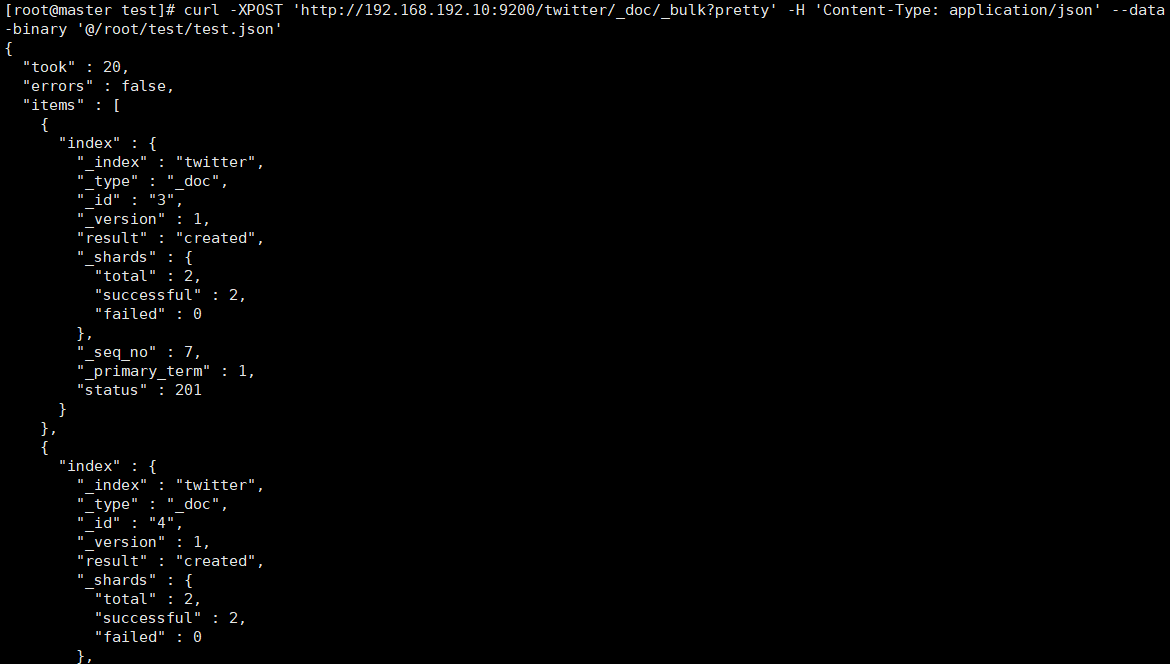
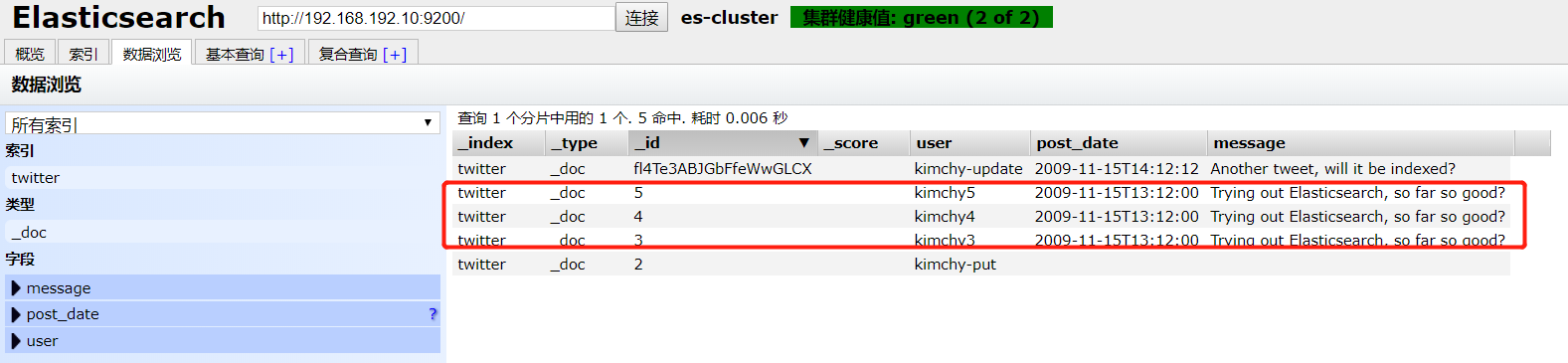
{"index":{"_id":"3"}} {"user":"kimchy3","post_date":"2009-11-15T13:12:00","message":"Trying out Elasticsearch, so far so good?"} {"index":{"_id":"4"}} {"user":"kimchy4","post_date":"2009-11-15T13:12:00","message":"Trying out Elasticsearch, so far so good?"} {"index":{"_id":"5"}} {"user":"kimchy5","post_date":"2009-11-15T13:12:00","message":"Trying out Elasticsearch, so far so good?"} -
执行命令
-
curl -XPOST 'http://192.168.192.10:9200/twitter/_doc/_bulk?pretty' -H 'Content-Type: application/json' --data-binary '@/root/test/test.json'

3.6.2 删除操作
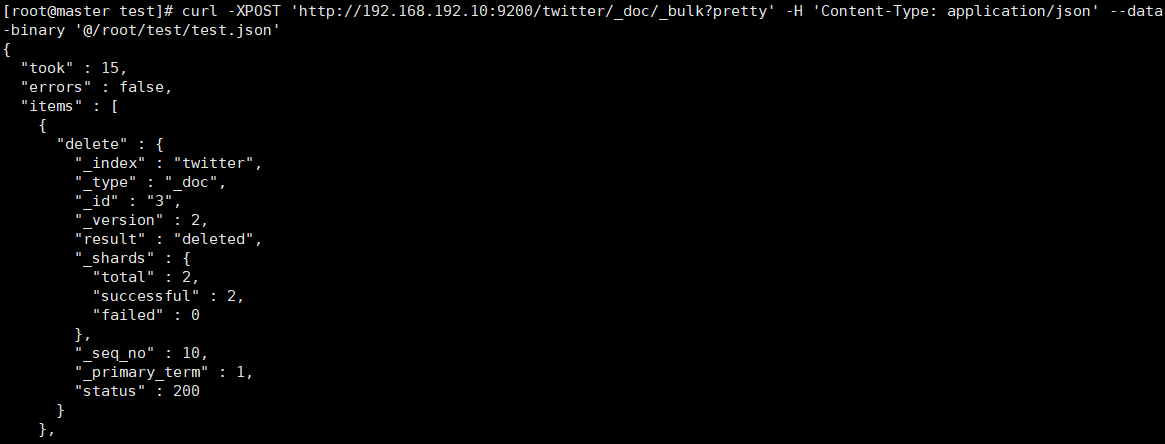
-
创建批处理文件test.json
-
{ "delete":{"_id" : 2}} { "delete":{"_id" : 3}} -
执行命令
-
curl -XPOST 'http://192.168.192.10:9200/twitter/_doc/_bulk?pretty' -H 'Content-Type: application/json' --data-binary '@/root/test/test.json'

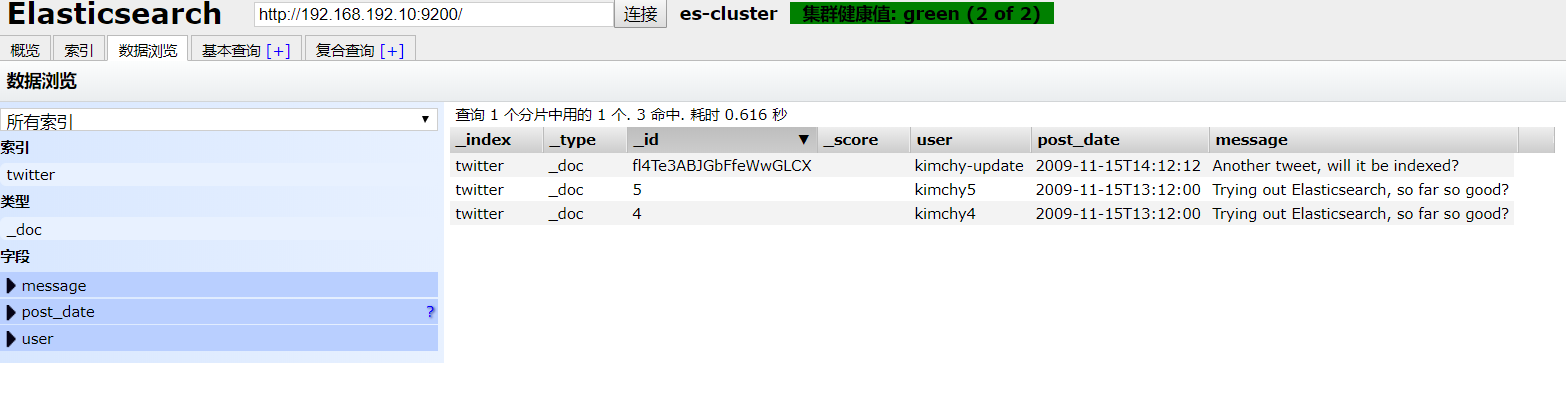
3.6.3 更新操作
-
创建批处理文件test.json
-
{"index":{"_id":"4"}} {"user":"test4"} {"index":{"_id":"5"}} {"user":"test5"} -
执行命令
-
curl -XPOST 'http://192.168.192.10:9200/twitter/_doc/_bulk/_update?pretty' -H 'Content-Type: application/json' --data-binary '@/root/test/test.json'


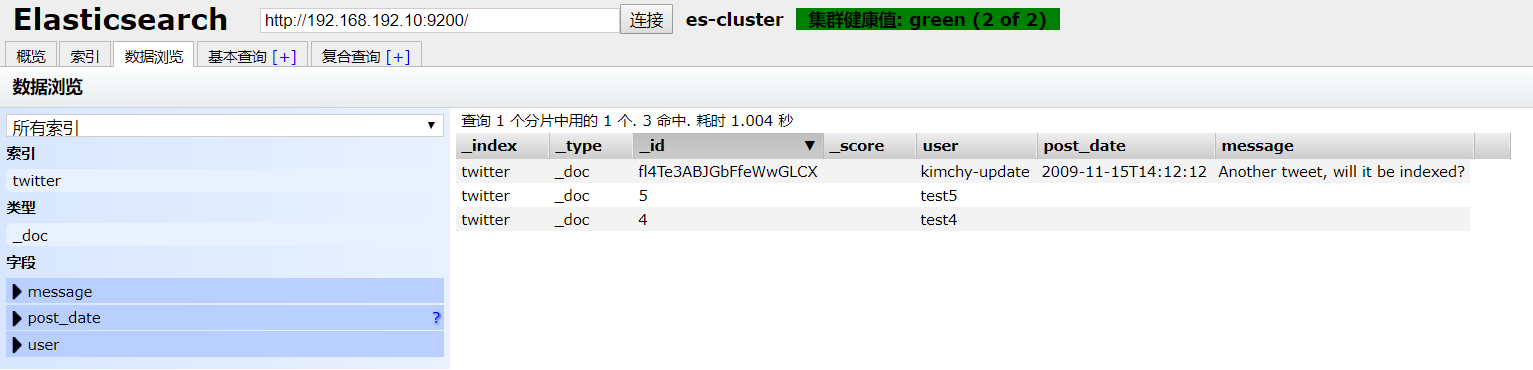
3.7 kibana插件使用拓展
3.7.1 CRUD基础操作
- 查看所有索引 GET _cat/indices
- 添加索引 PUT twitter
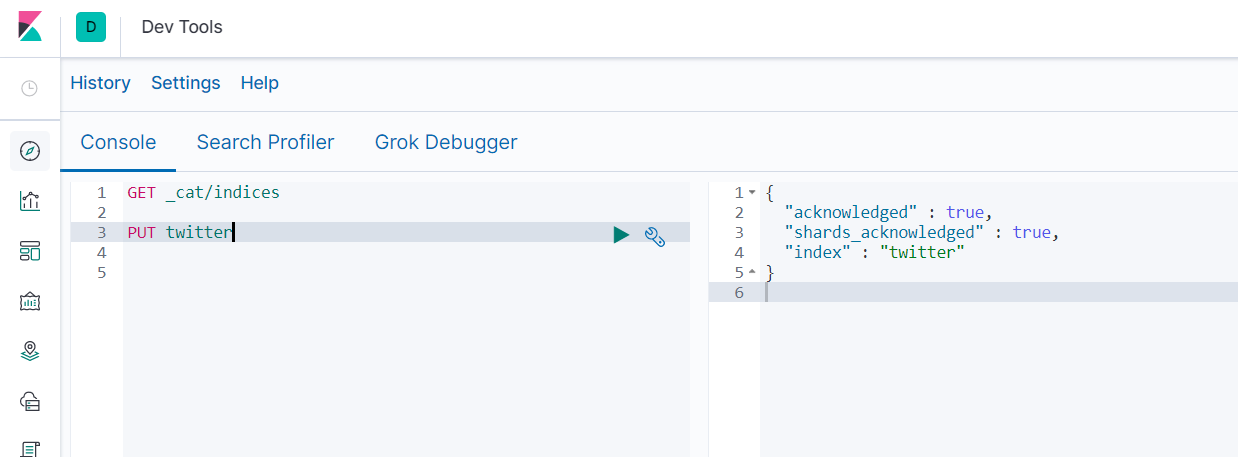

- 查询twitter内容 GET twitter/_search
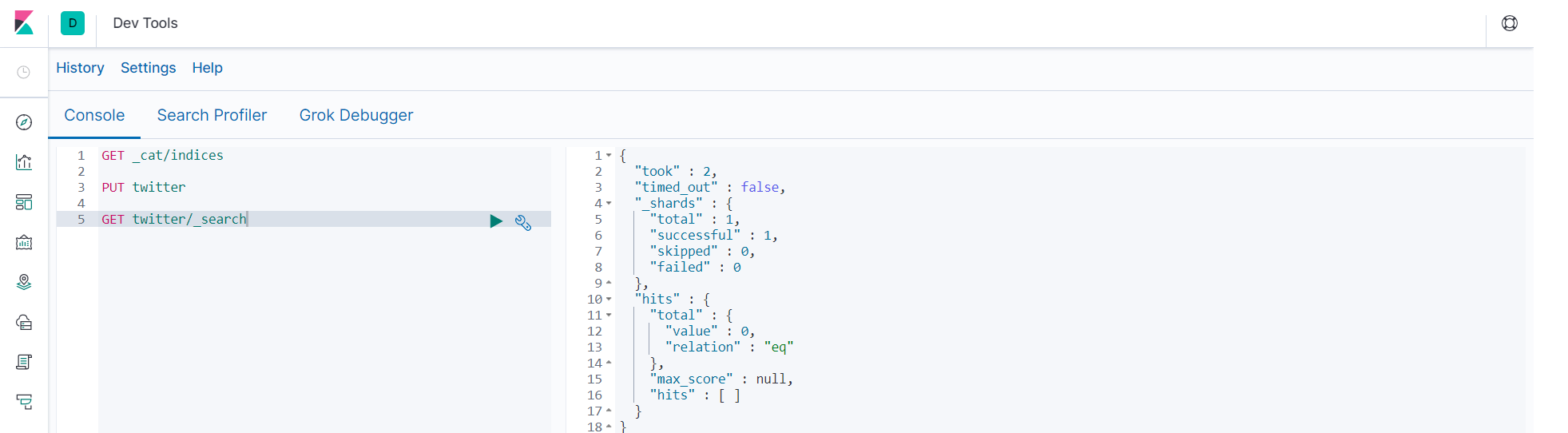
-
新增索引内容
-
POST twitter/_doc/1 { "user": "kimchy", "post_date": "2009-11-15T13:12:00", "message": "Trying out Elasticsearch, so far so good?" }
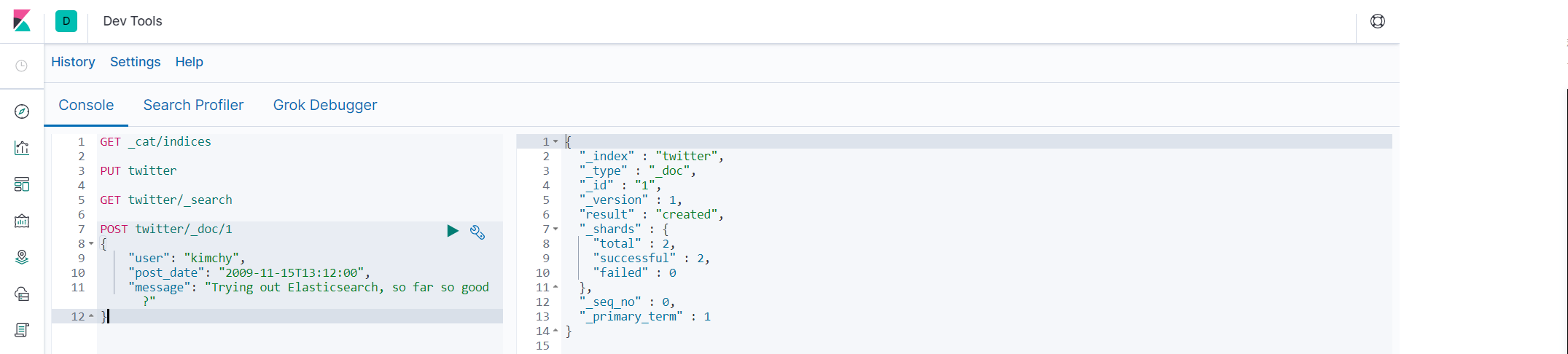
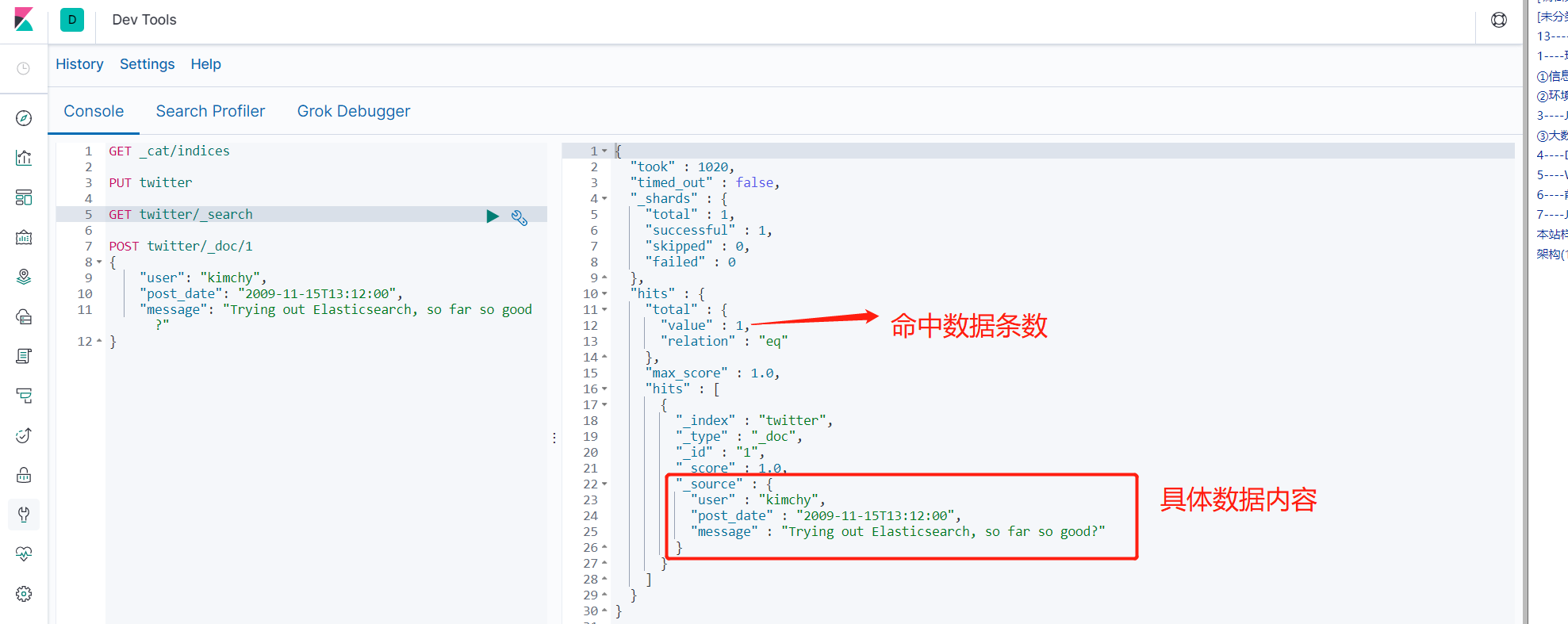
- 查看具体某条记录 GET twitter/_doc/1

-
批量操作
-
POST twitter/_bulk {"index":{"_id":"3"}} {"user":"kimchy3","post_date":"2009-11-15T13:12:00","message":"Trying out Elasticsearch, so far so good?"} {"index":{"_id":"4"}} {"user":"kimchy4","post_date":"2009-11-15T13:12:00","message":"Trying out Elasticsearch, so far so good?"}
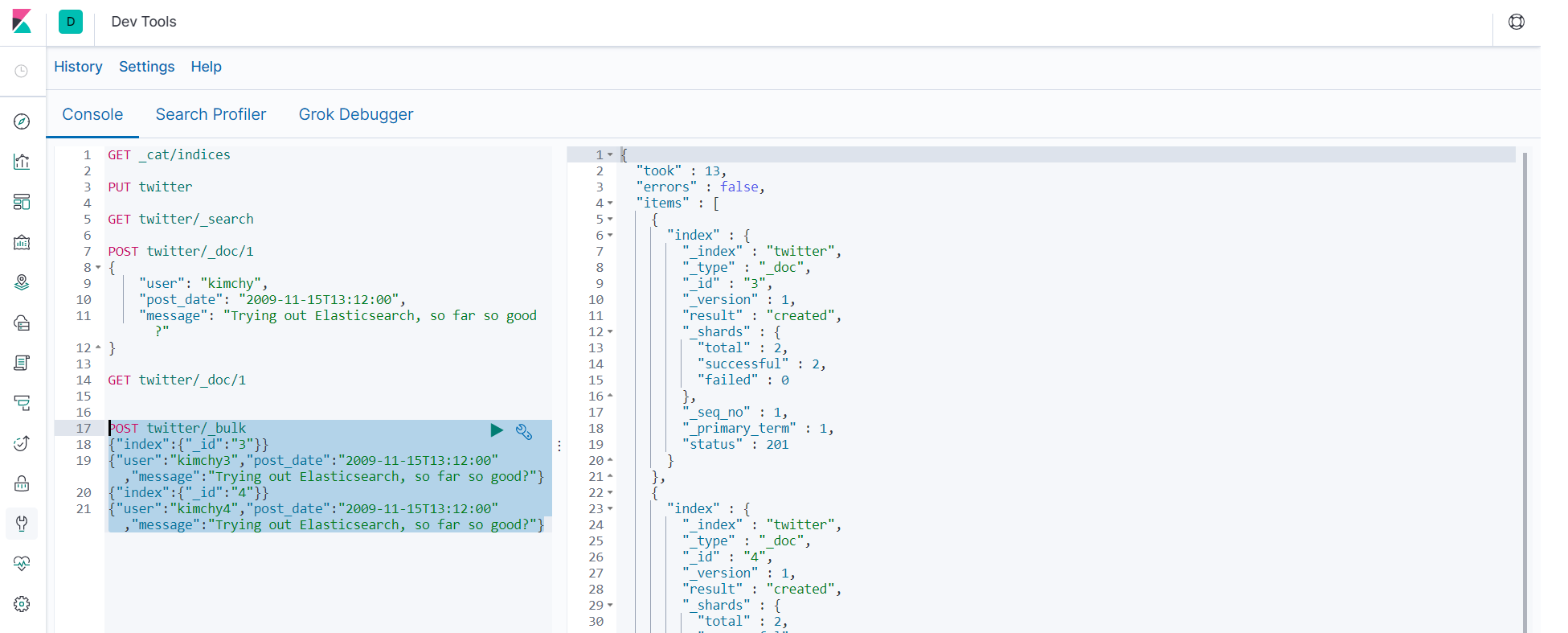

-
更新操作
-
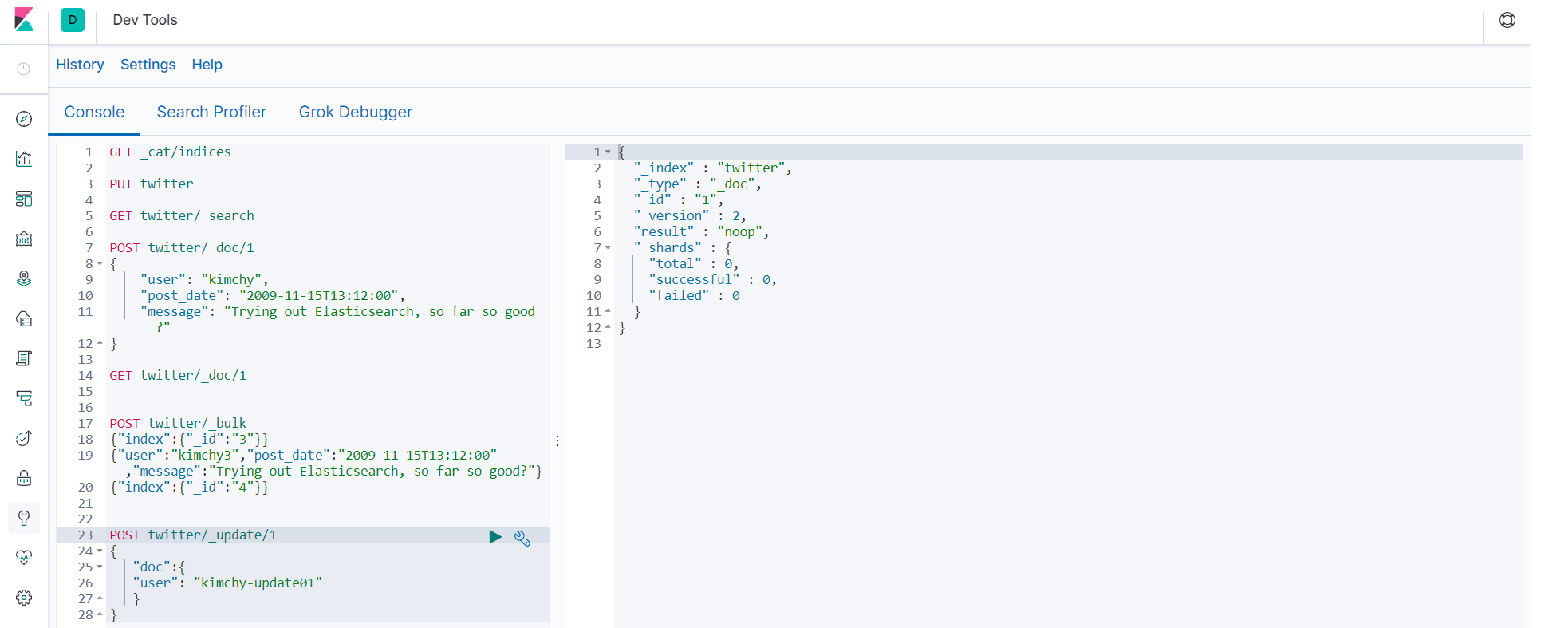
POST twitter/_update/1 { "doc":{ "user": "kimchy-update01" } }
3.7.2 URI查询操作拓展
3.7.2.1 泛查询
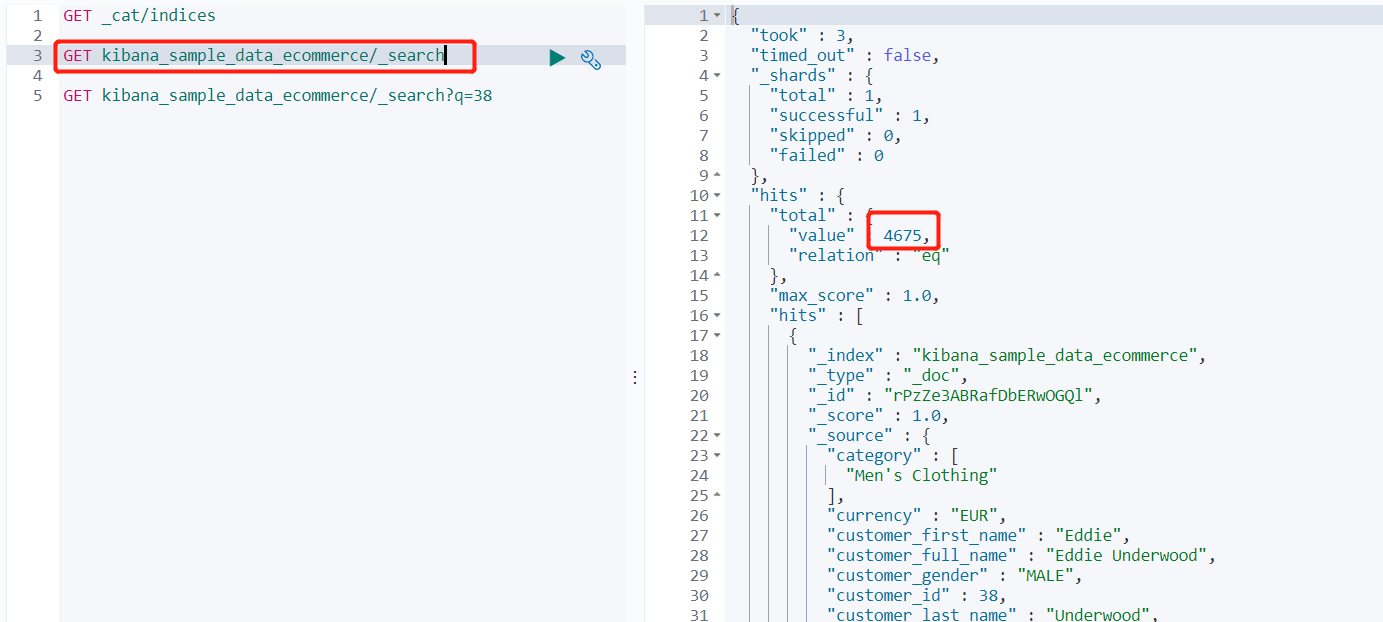
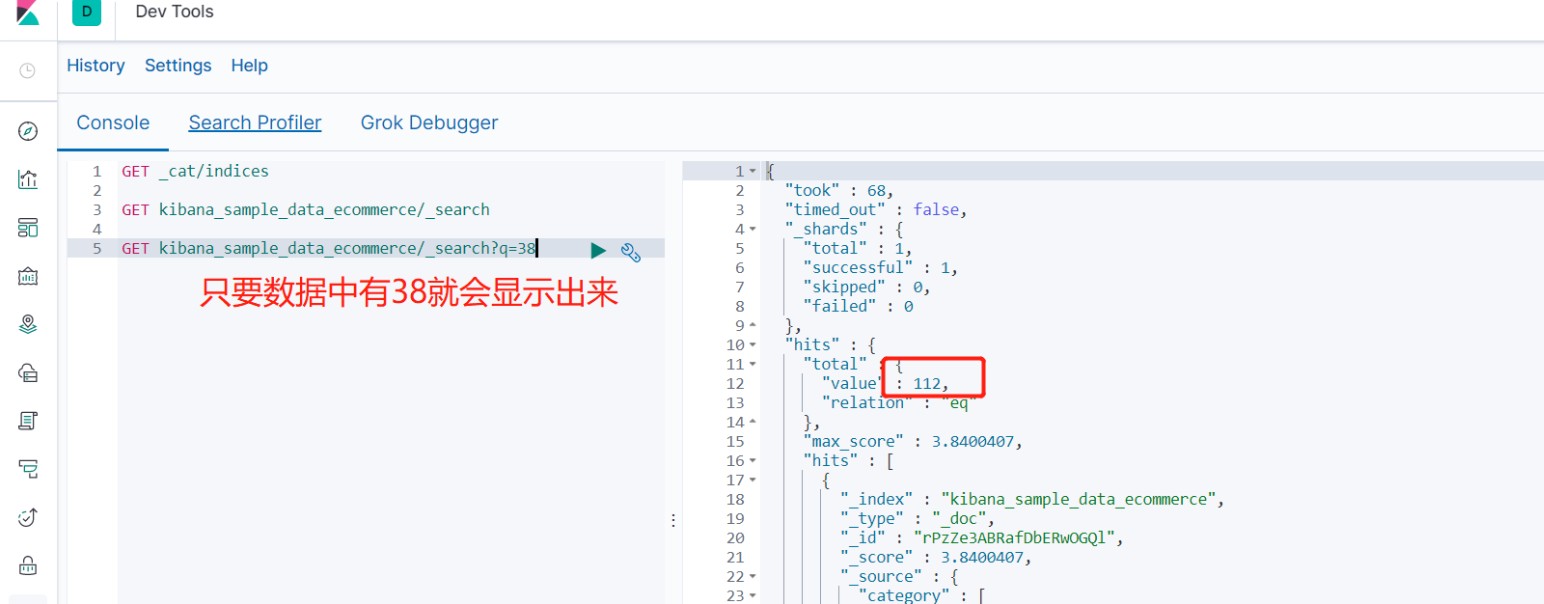
- GET kibana_sample_data_ecommerce/_search?q=38
3.7.2.2 字段匹配查询
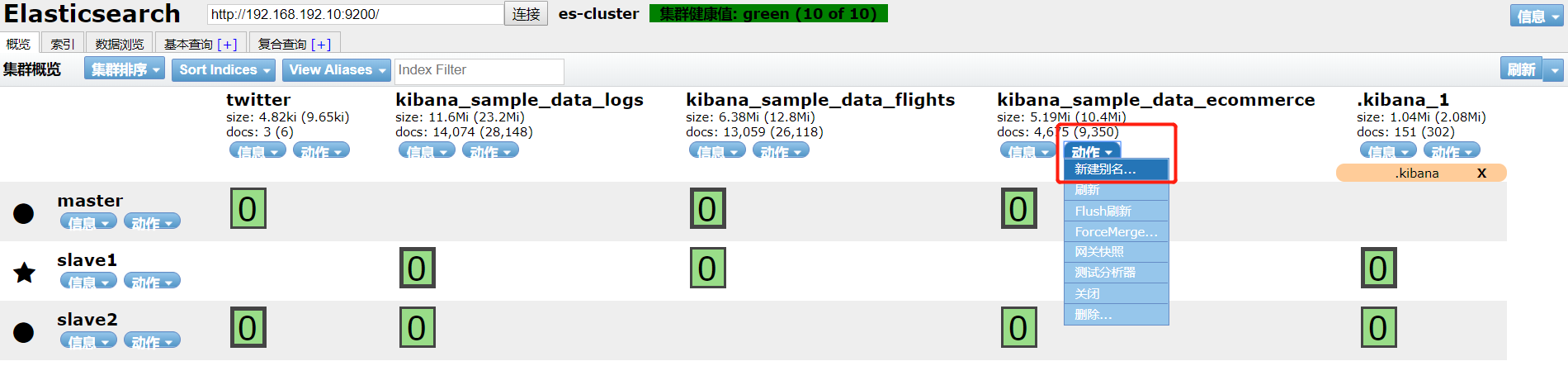
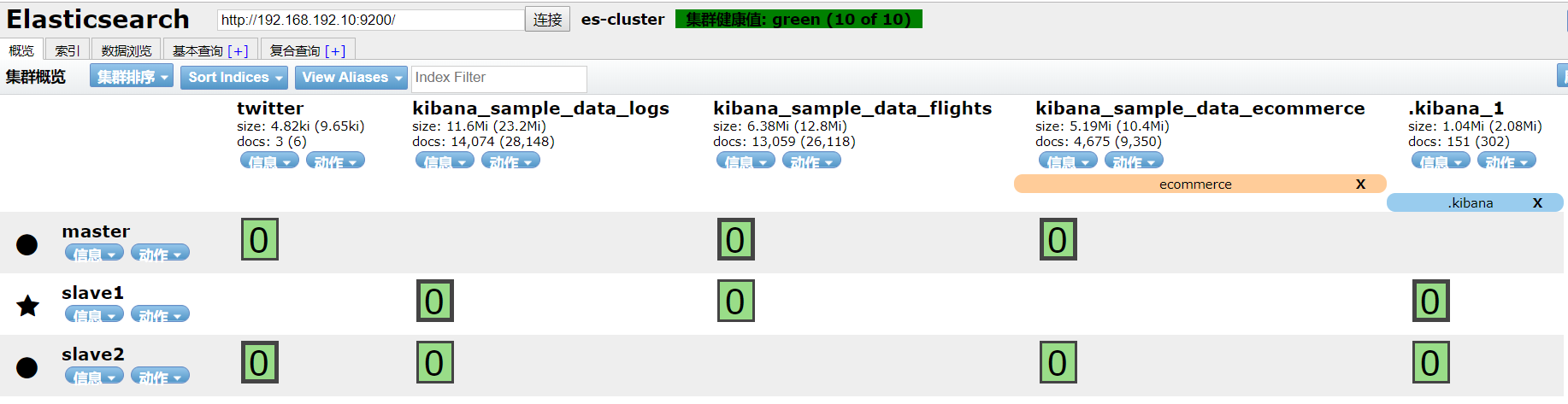
- 索引名字太长,新建别名
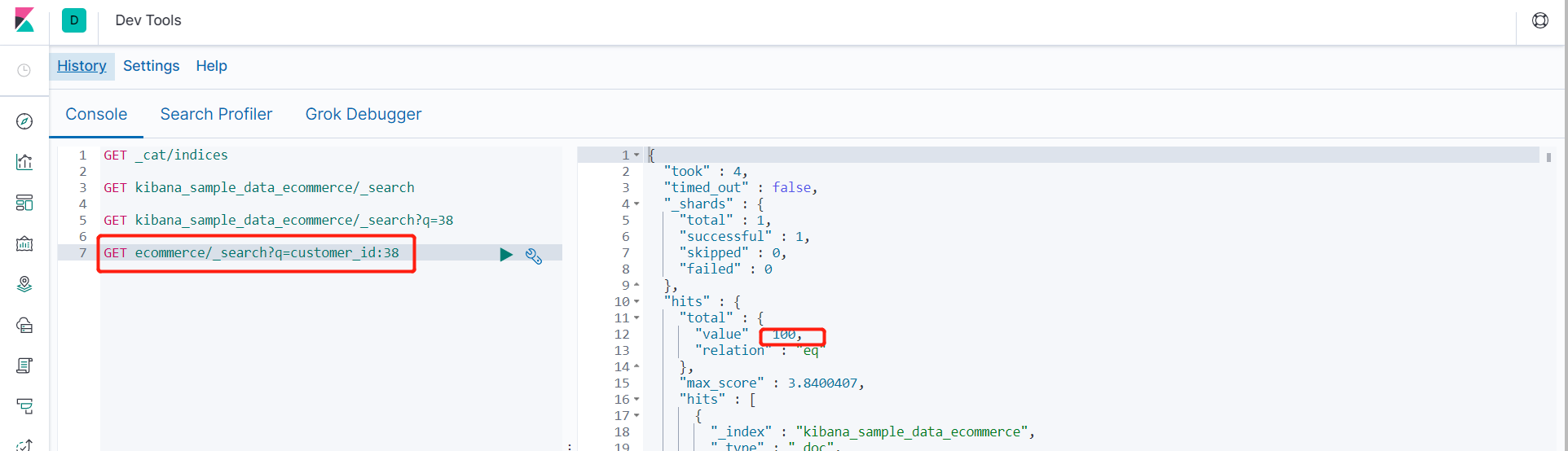
- 普通字段匹配查询 GET ecommerce/_search?q=customer_id:38
- 数组字段匹配查询 GET ecommerce/_search?q=category:Men's
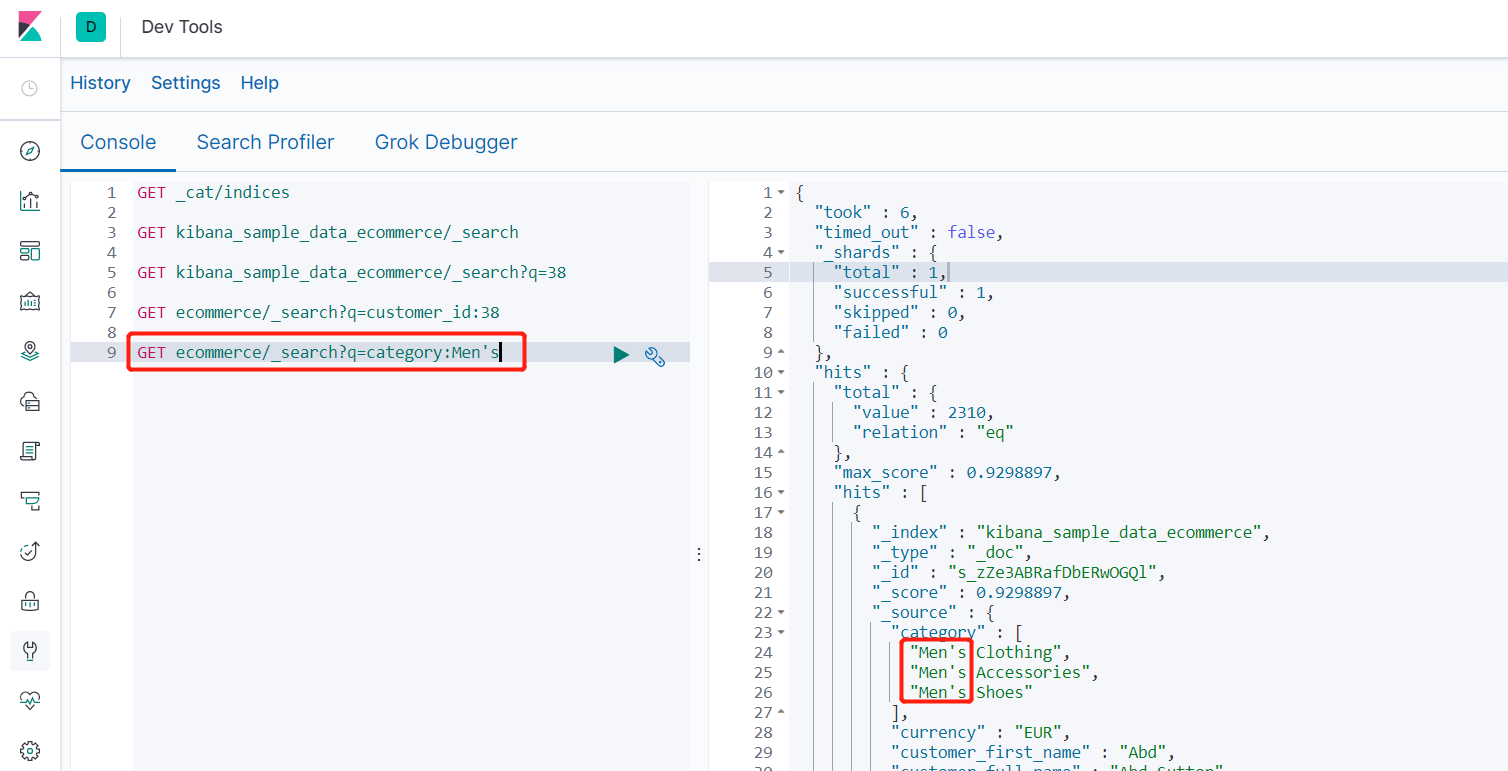
- 数组对象字段匹配查询 GET ecommerce/_search?q=category:Men's

3.7.2.3 字段多条件匹配
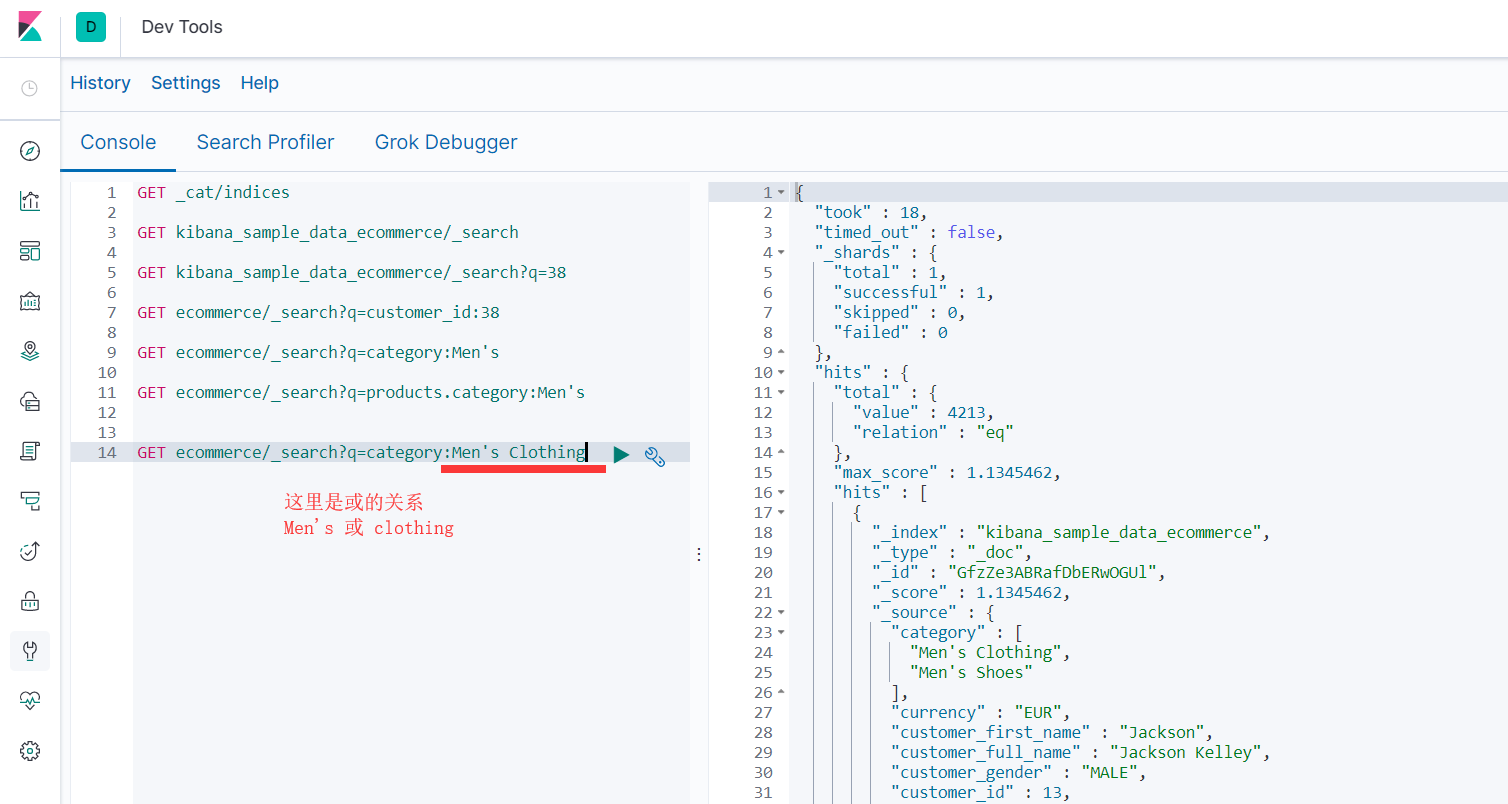
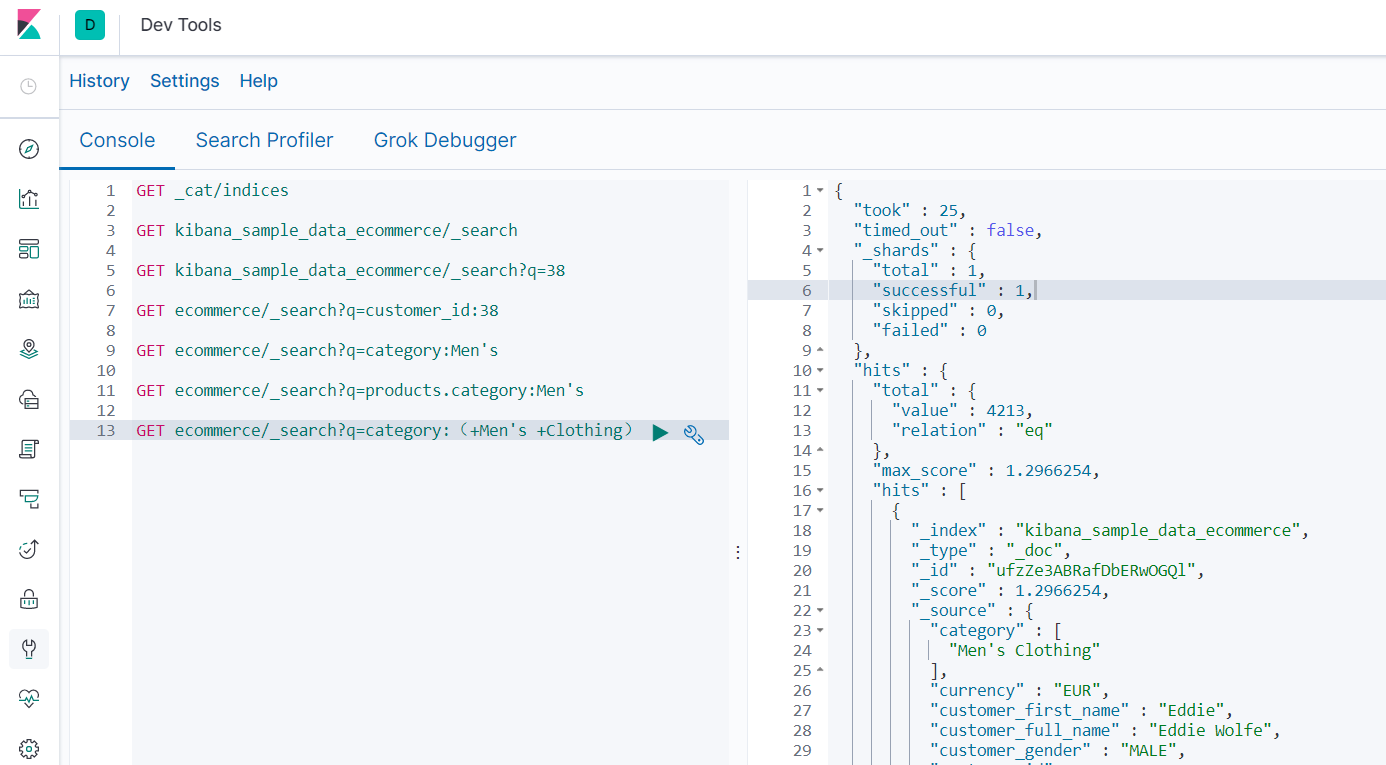
- 查询分类中有 '男士' 或 '服装' 的结果(||)
- GET ecommerce/_search?q=category:Men's Clothing
- GET ecommerce/_search?q=category:(+Men's +Clothing)
- 推荐写法:GET ecommerce/_search?q=category:(Men's Clothing)
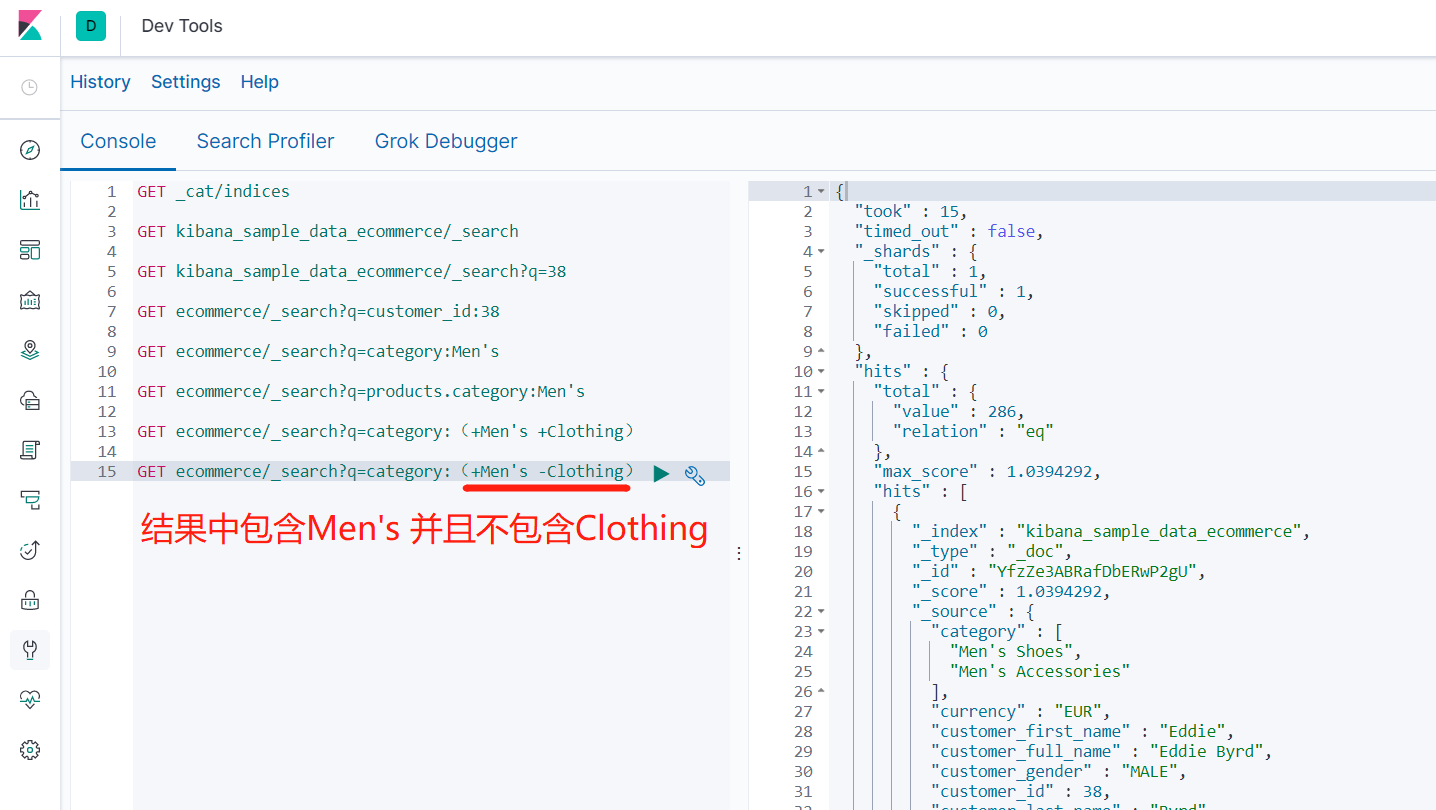
- 查询分类中有 '男士' 且没有 '服装' 的结果
- GET ecommerce/_search?q=category:(+Men's -Clothing)
- 查询分类中有 '男士' 且有 '服装' 的结果(&&)
- GET ecommerce/_search?q=category:(Men's AND Clothing)
- AND必须大写
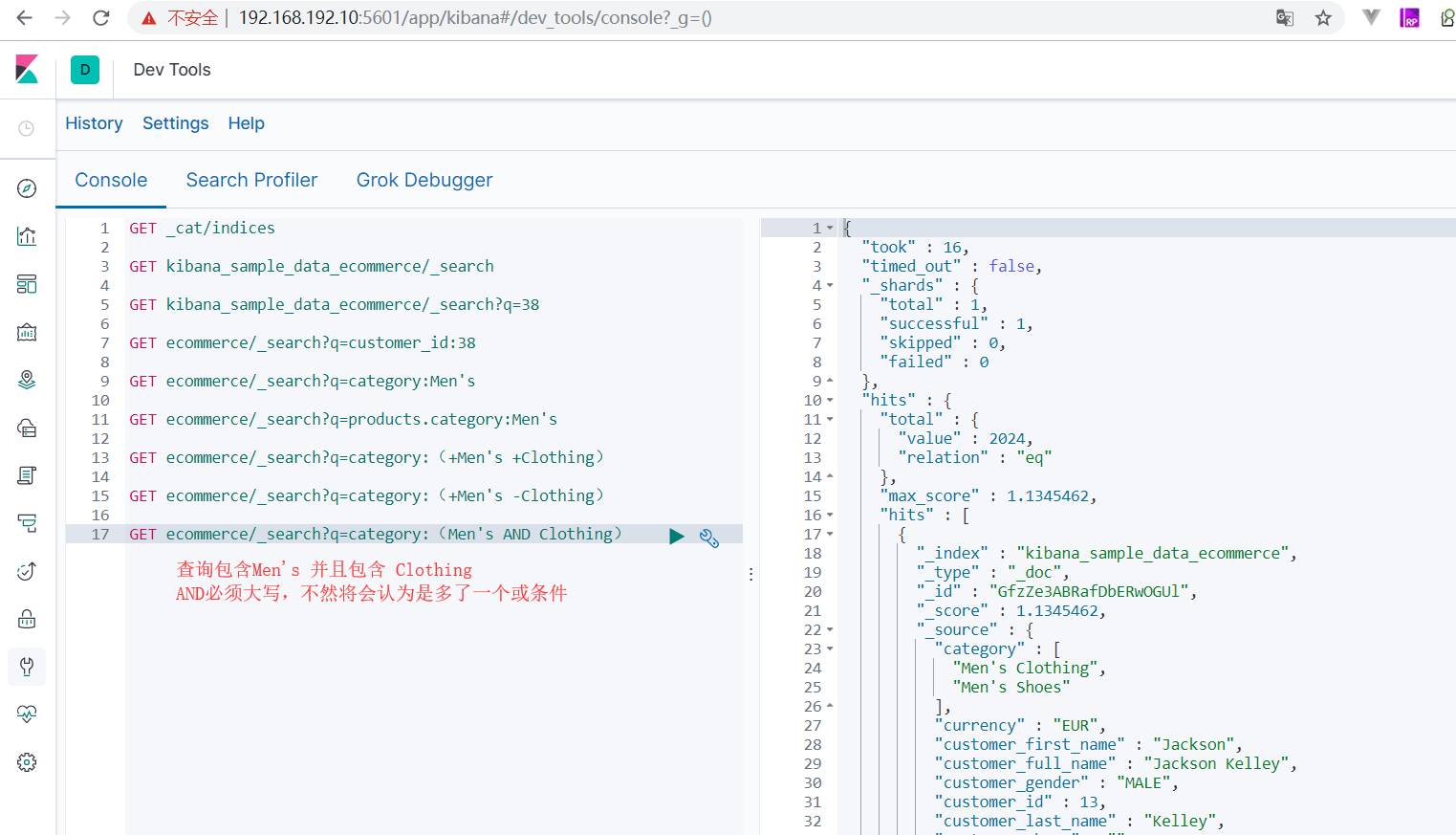
- 查询商品价格在20.00到30.00之间的结果(范围查询)
- GET ecommerce/_search?q=products.base_price:(>=20.00 AND <=30.00)
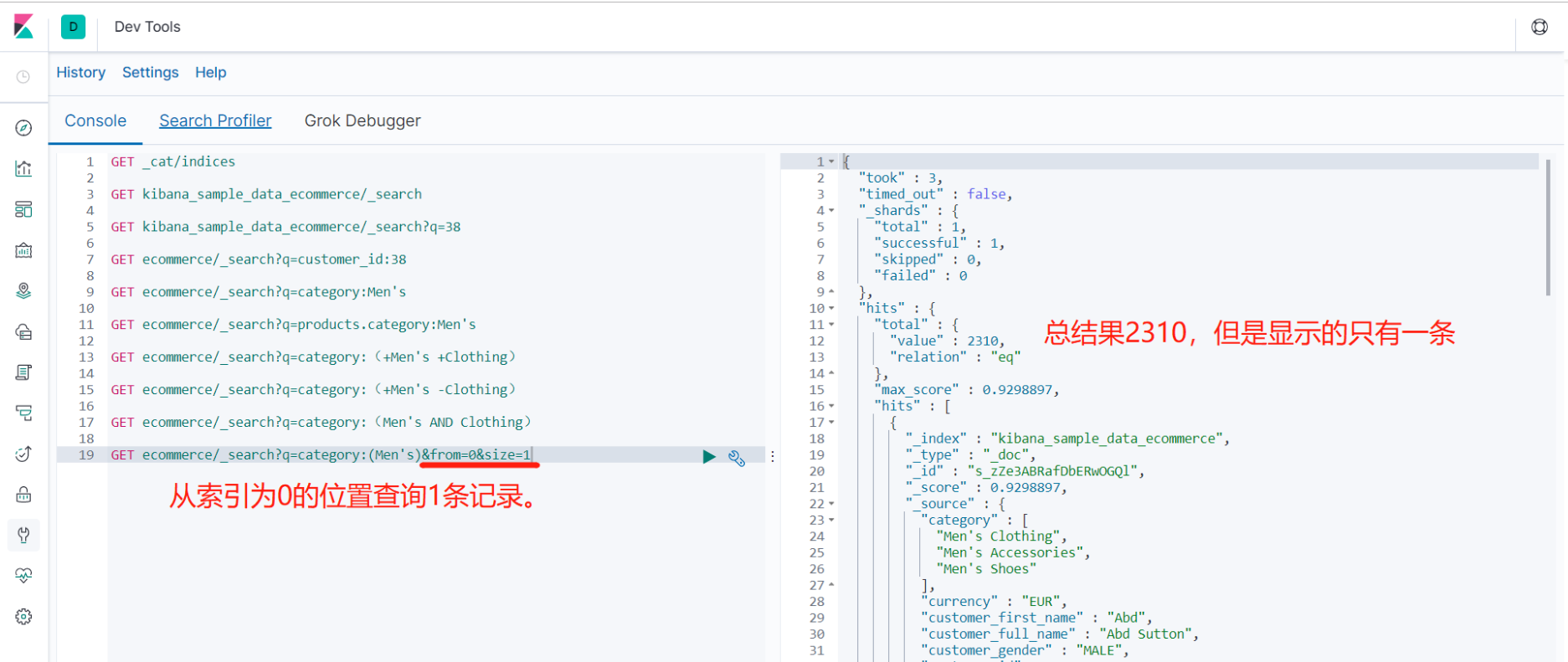
3.7.2.4 分页查询
- 从索引为0处查询分类中有 '男士' 的结果,只显示一条(分页)
- GET ecommerce/_search?q=category:(Men's)&from=0&size=1
3.7.3 DSL查询
ES支持一种JSON格式的查询,叫做DSL,domain specific language。
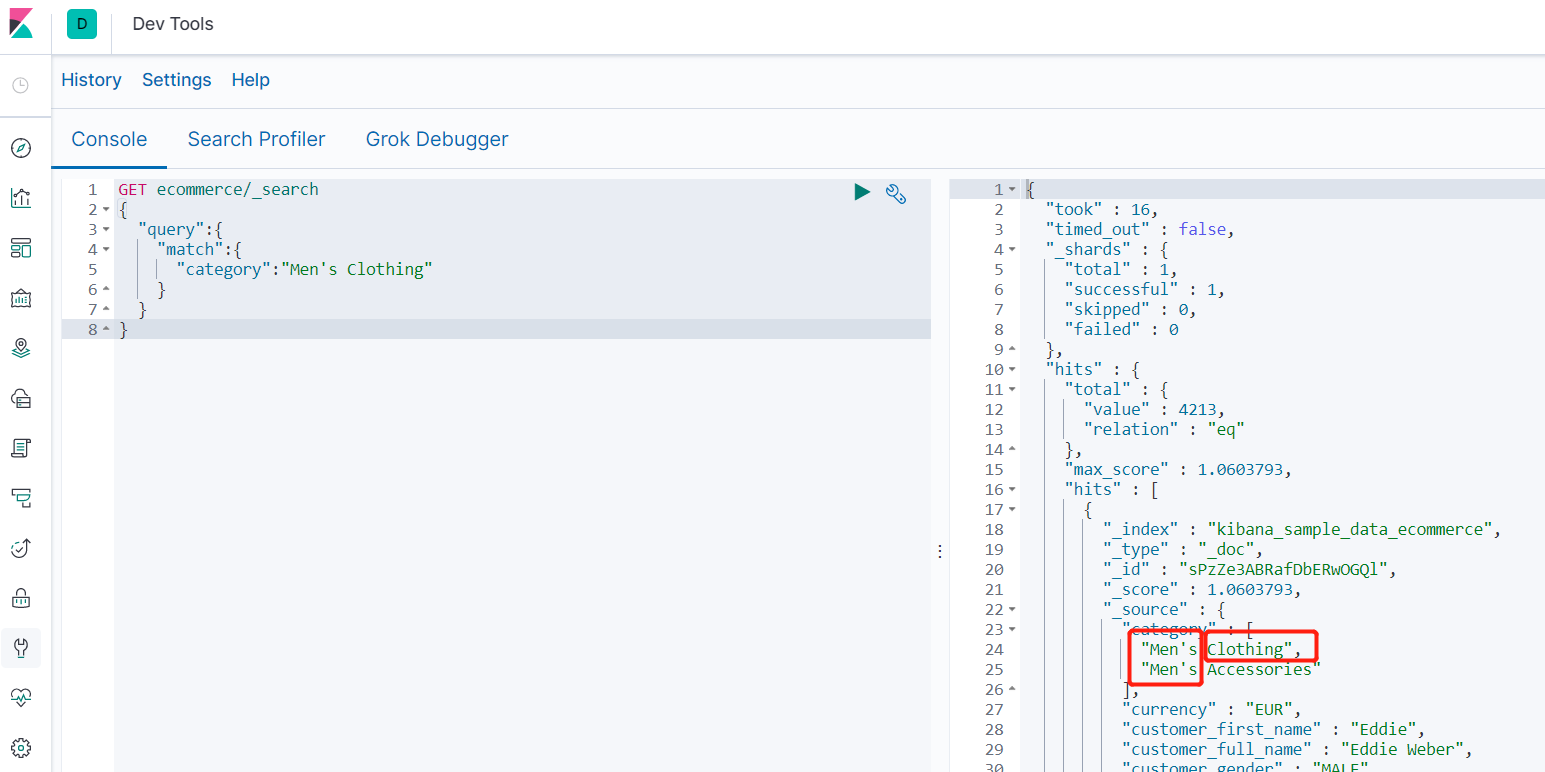
3.7.3.1 match匹配查询
-
查询分类包含 "男性" 或 “服装” 的结果
-
GET ecommerce/_search { "query":{ "match":{ "category":"Men's Clothing" } } }
-
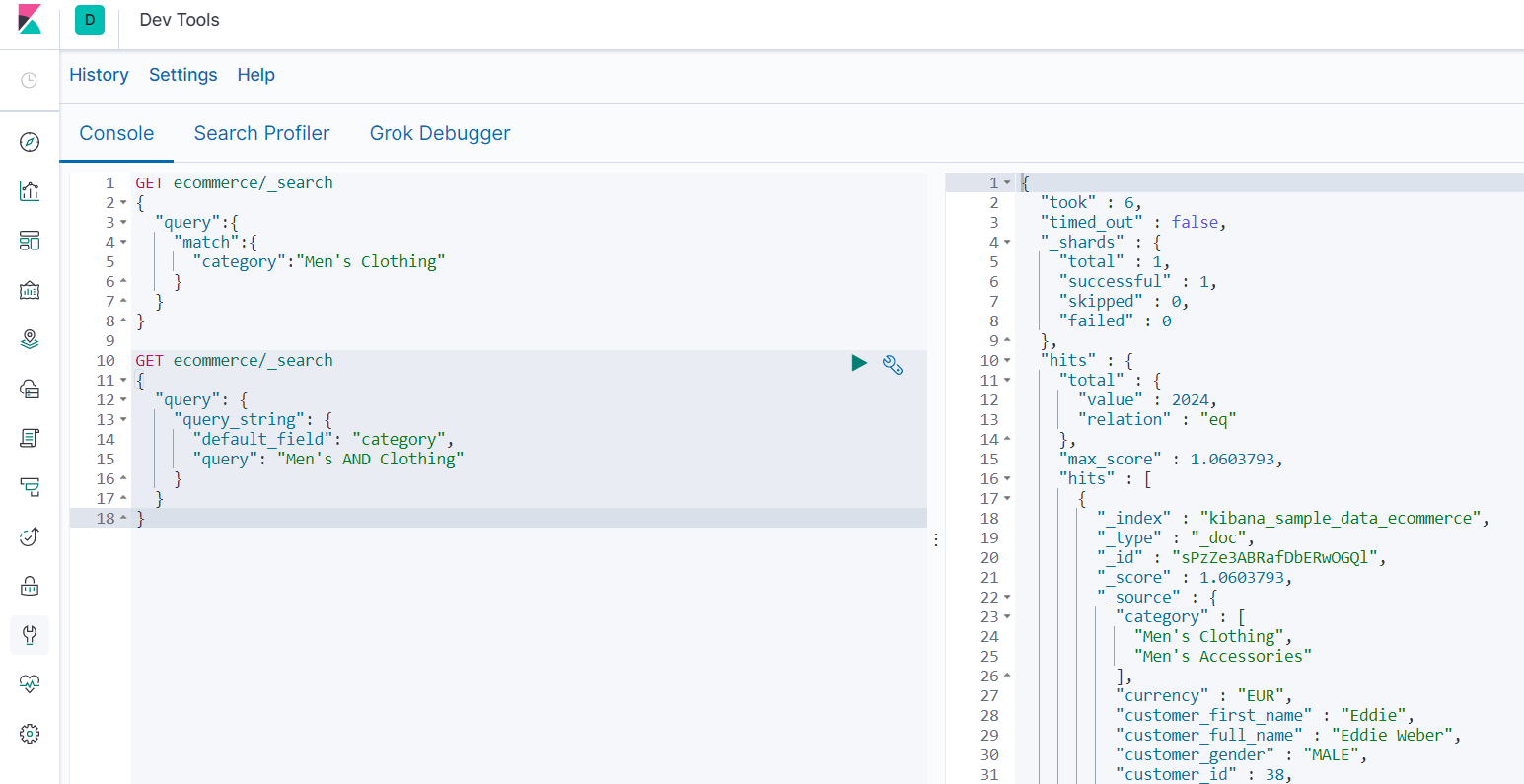
3.7.3.2 query_string匹配查询
-
查询分类包含 "男性服装” 的结果
-
#写法一 GET ecommerce/_search { "query": { "query_string": { "default_field": "category", "query": "Men's AND Clothing" } } } #写法二(条件OR AND) GET ecommerce/_search { "query": { "query_string": { "default_field": "category", "query": "Men's Clothing", "default_operator": "AND" } } }
-
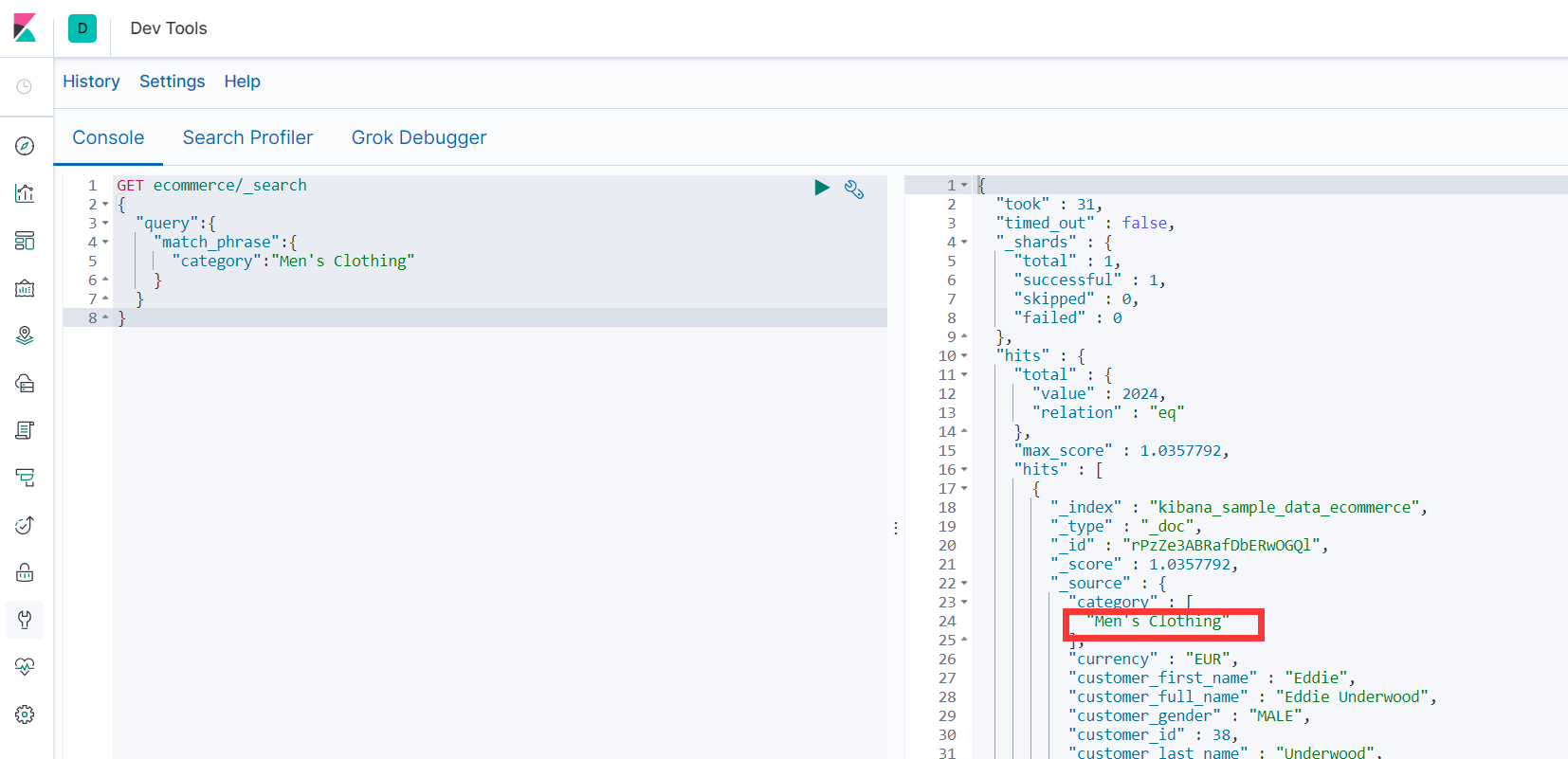
3.7.3.3 match_phrase 强匹配查询
-
查询包含 “男性服装” 的整体结果
-
GET ecommerce/_search { "query":{ "match_phrase":{ "category":"Men's Clothing" } } }
-
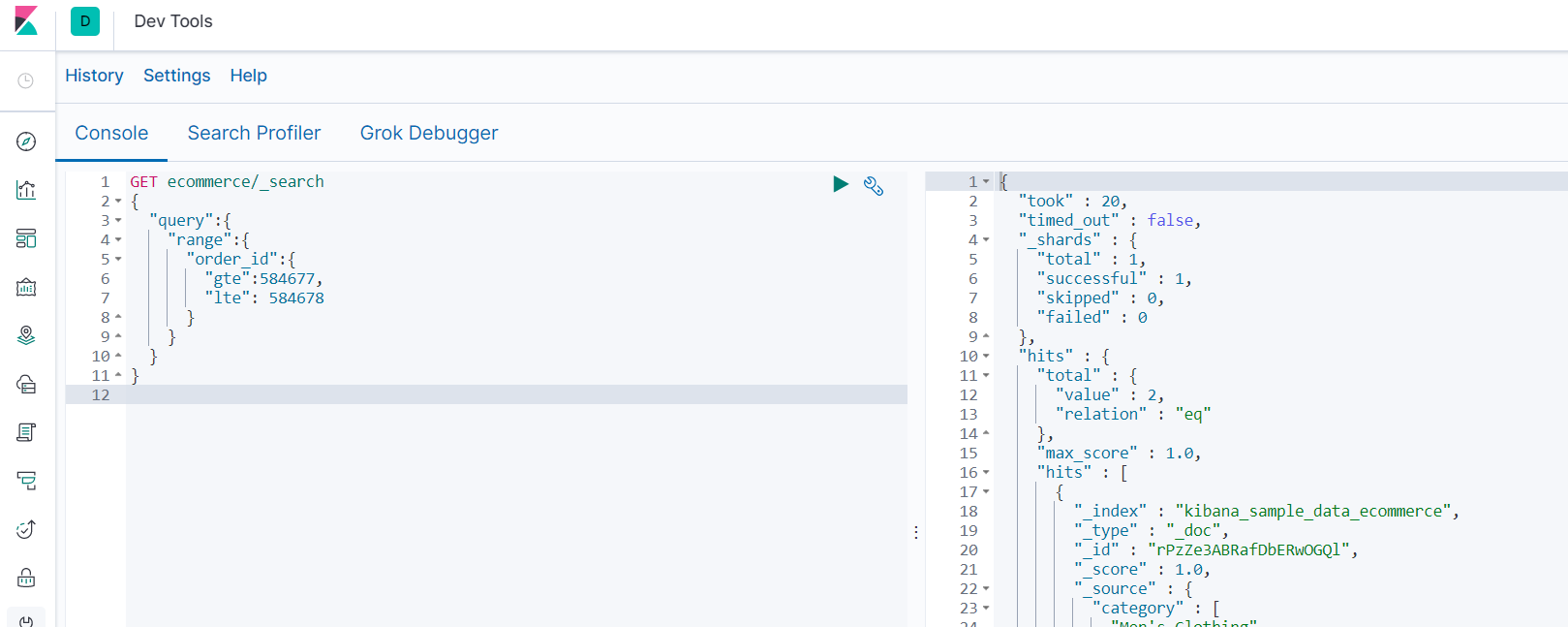
3.7.3.4 range范围查询
-
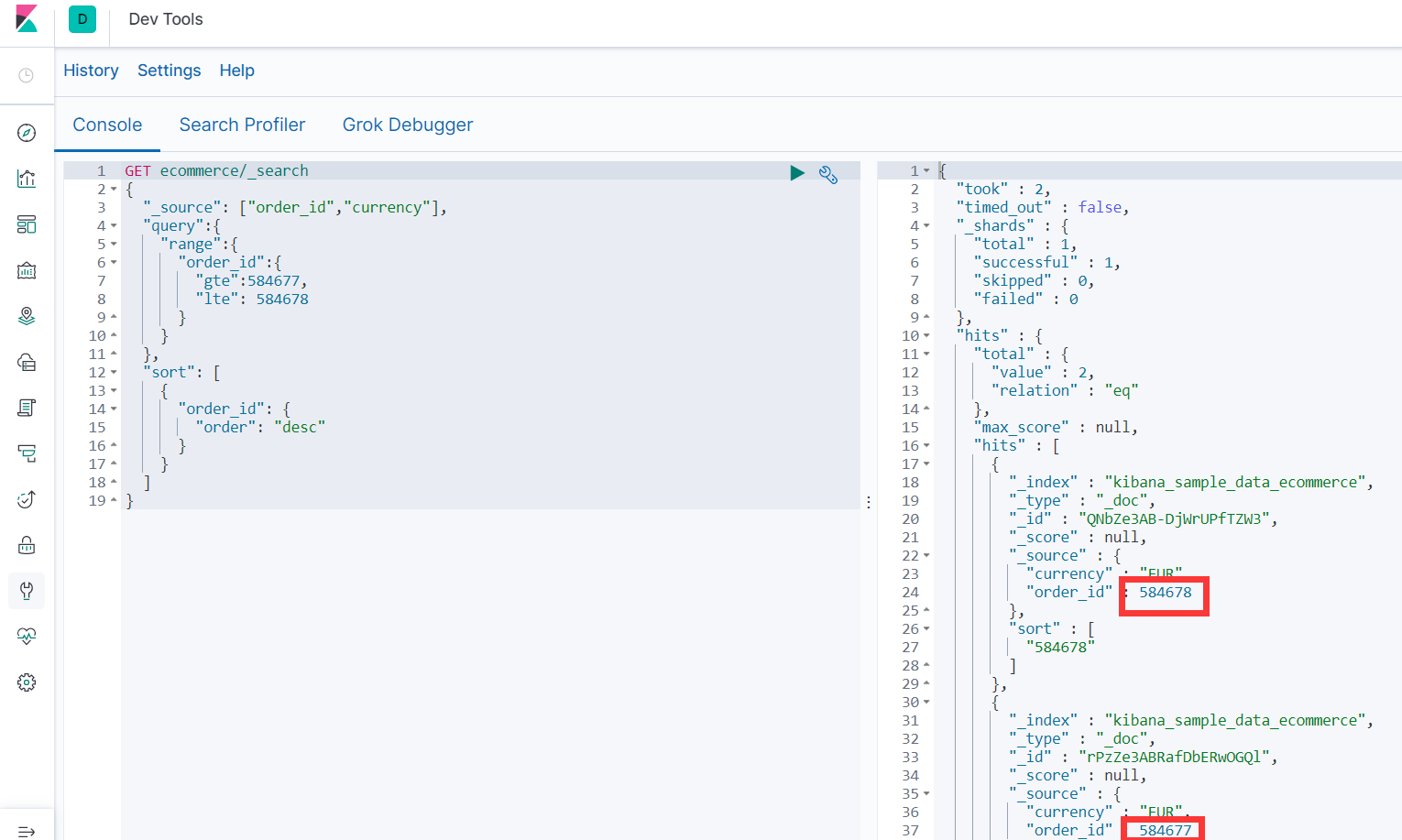
查询包含 “订单>=584677 <=584678” 的整体结果("gt" "lt" "gte" "lte")
-
GET ecommerce/_search { "query":{ "range":{ "order_id":{ "gte":584677, "lte": 584678 } } } }
-
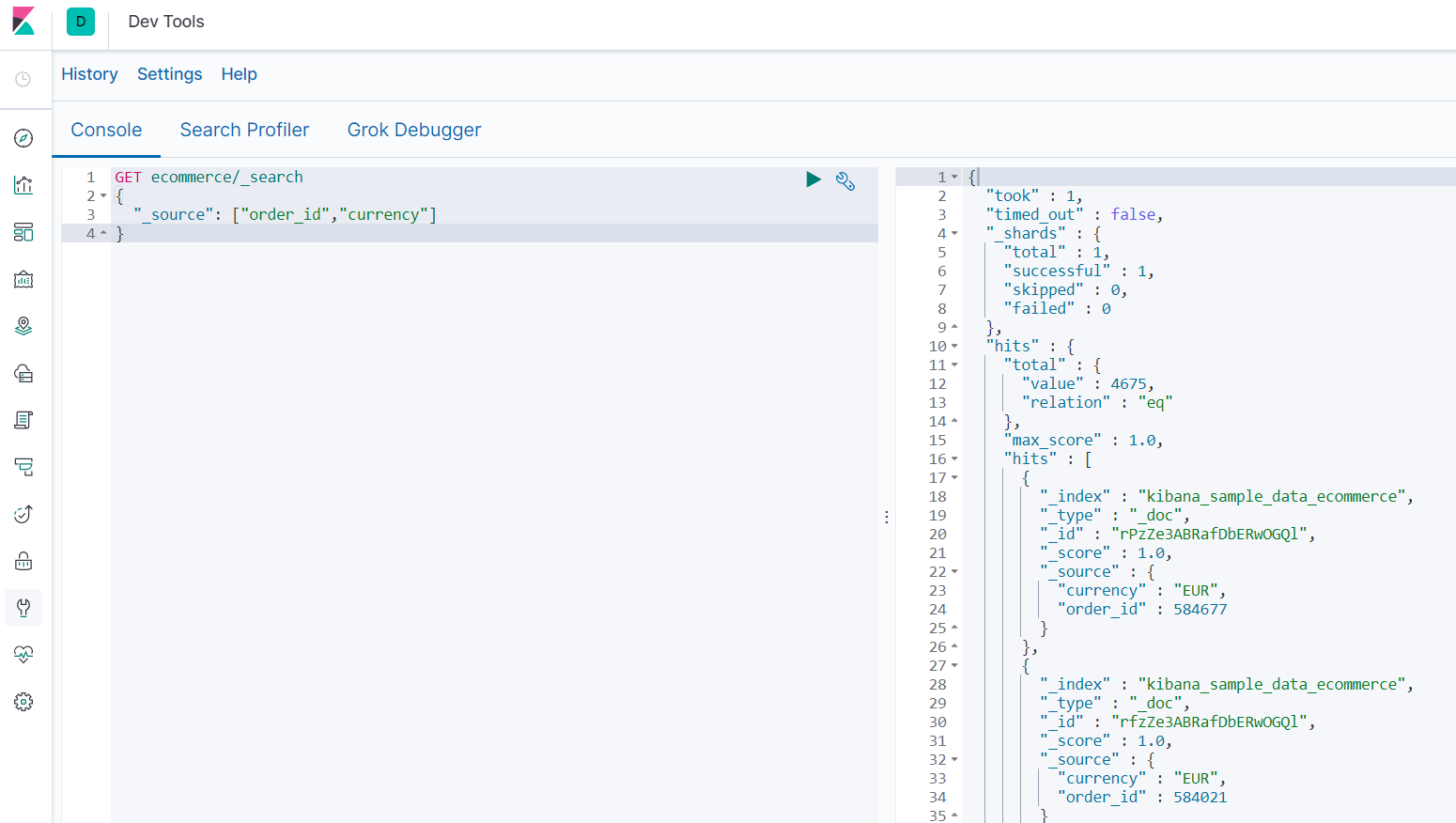
3.7.3.5 _source查询结果过滤
-
查询 “订单ID 和 货币” 的结果
-
GET ecommerce/_search { "_source": ["order_id","currency"] }
-
3.7.3.6 sort排序
-
查询包含 “订单>=584677 <=584678” 的包含 “订单ID 和 货币” 结果,并倒序排列
-
GET ecommerce/_search { "_source": ["order_id","currency"], "query":{ "range":{ "order_id":{ "gte":584677, "lte": 584678 } } }, "sort": [ { "order_id": { "order": "desc" } } ] }
-
3.7.3.7 multi_match多列匹配查询
type类型:
best_fields(默认):在某一字段中匹配的越多,排名越靠前
most_fields:在多字段中匹配的越多,排名越靠前
cross_fields:查询越分散,排名越靠前
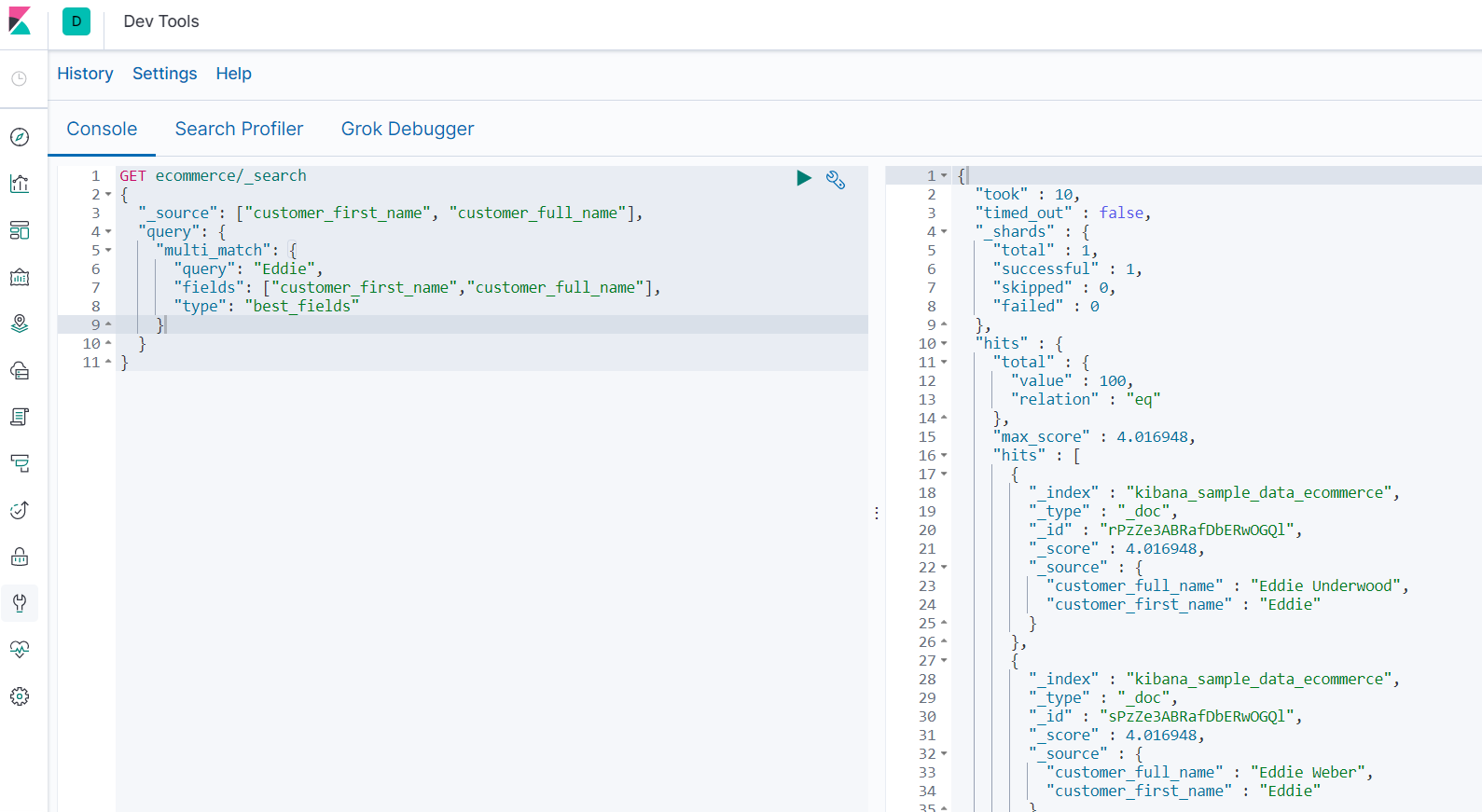
-
查询customer_first_name,customer_full_name中包含 “Eddie” 的结果
-
GET ecommerce/_search { "_source": ["customer_first_name", "customer_full_name"], "query": { "multi_match": { "query": "Eddie", "fields": ["customer_first_name","customer_full_name"], "type": "best_fields" } } }
-
3.7.3.8 bool多字段条件查询
必须 must
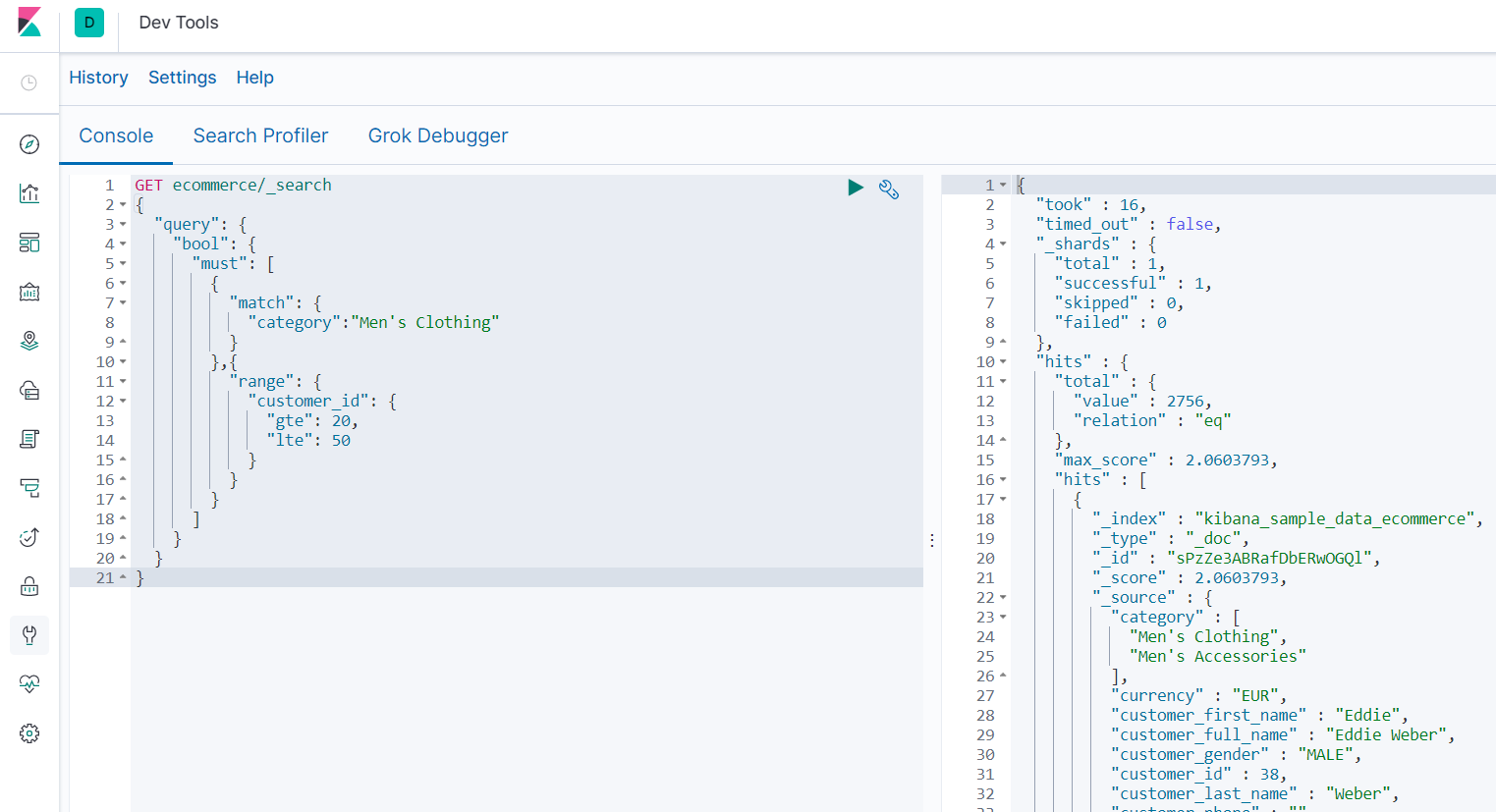
-
查询分类中包含“Men's” 或 "Clothing",并且20<=customer_id<=50的结果
-
GET ecommerce/_search { "query": { "bool": { "must": [ { "match": { "category":"Men's Clothing" } },{ "range": { "customer_id": { "gte": 20, "lte": 50 } } } ] } } }
-
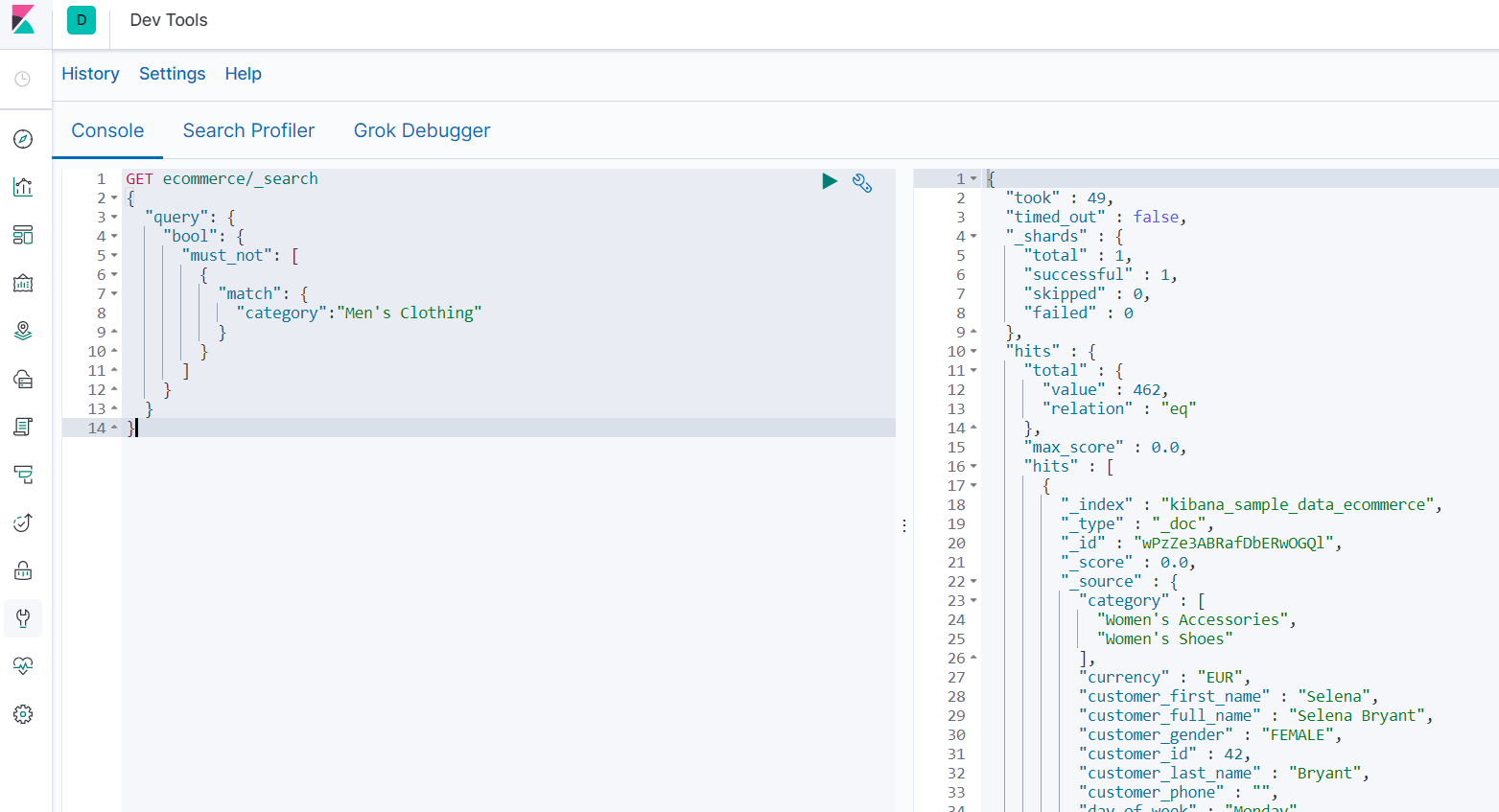
必须不 must_not
-
查询分类中不包含“Men's” 或 "Clothing",并且 40<=customer_id<=50 的结果
-
GET ecommerce/_search { "query": { "bool": { "must_not": [ { "match": { "category":"Men's Clothing" } } ], "must": [ { "range": { "customer_id": { "gte": 40, "lte": 50 } } } ] } } }
-
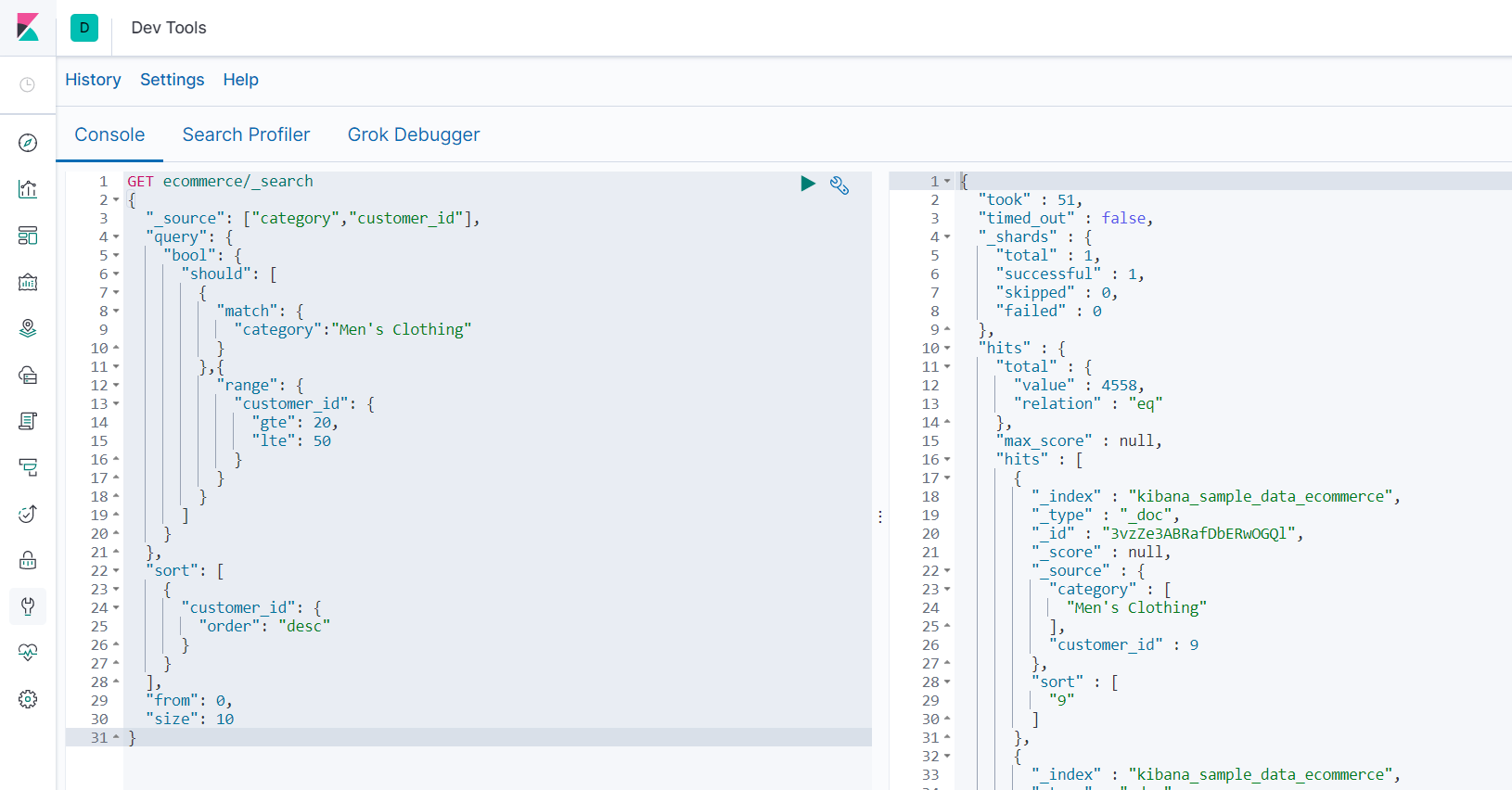
或者 should
-
查询分类中包含“Men's” 或 "Clothing",或者 20<=customer_id<=50的结果,按照customer_id倒序排列,从第0个索引位置展示10条,只显示category,customer_id字段
-
GET ecommerce/_search { "_source": ["category","customer_id"], "query": { "bool": { "should": [ { "match": { "category":"Men's Clothing" } },{ "range": { "customer_id": { "gte": 20, "lte": 50 } } } ] } }, "sort": [ { "customer_id": { "order": "desc" } } ], "from": 0, "size": 10 }
-
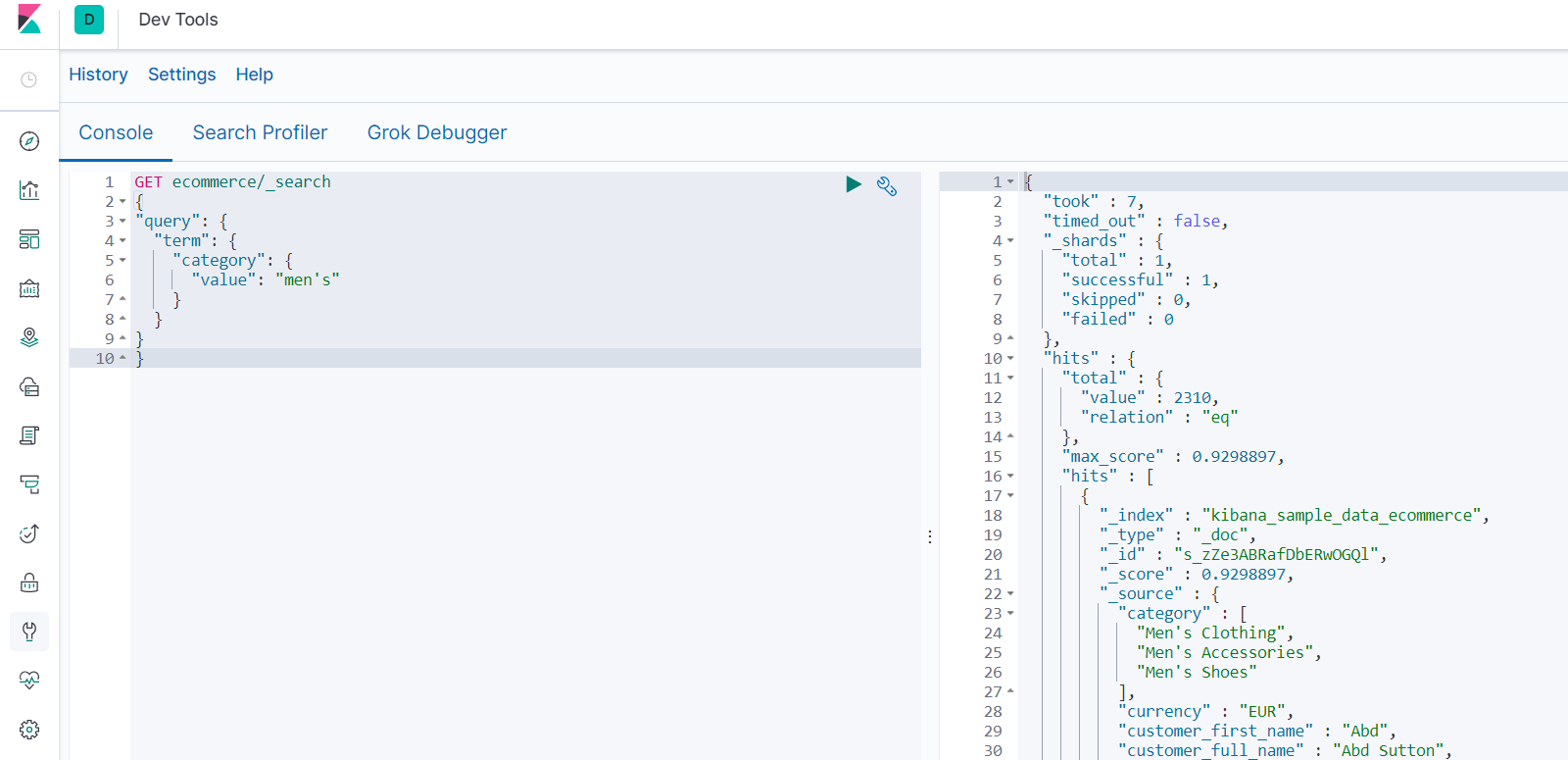
精确查找 term
-
查询分类中包含“men's”的结果
-
注意不能大写,因为精确查找其实找的是索引库,在我们的document存放的时候会将大写转为小写。
-
GET ecommerce/_search { "query": { "term": { "category": { "value": "men's" } } } }
-
缓存查找 filter
-
查询分类中包含“men's”的结果
-
注意不能大写,因为精确查找其实找的是索引库,在我们的document存放的时候会将大写转为小写。
-
GET ecommerce/_search { "query": { "term": { "category": { "value": "men's" } } } }
-
5 ElasticSearch基本概念
- cluster
代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
- shards
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
- replicas
代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
- recovery
代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
- river
代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法。它是以插件方式存在的一个es服务,通过读取river中的数据并把它索引到es中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的。
- gateway
代表es索引快照的存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到本地硬盘。gateway对索引快照进行存储,当这个es集群关闭再重新启动时就会从gateway中读取索引备份数据。es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
- discovery.zen
代表es的自动发现节点机制,es是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
- Transport
代表es内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
6 分词器
6.1 分词介绍
- 新建索引库(中英文测试)
PUT /participles_en
- 添加查询所引
PUT /participles_en/_doc/1
{
"msg":"Eating a banana day keeps!"
}
POST /participles_en/_search
{
"query": {
"match": {
"msg": "eat"
}
}
}
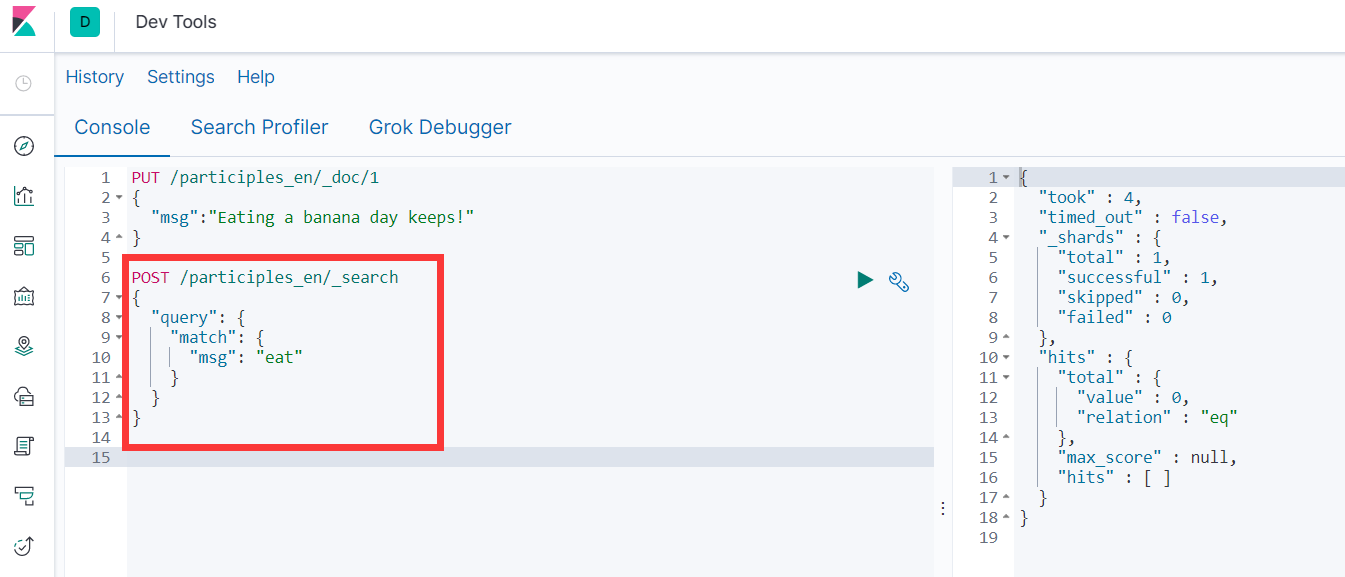
如上图,es返回结果为0,并没有被分成我们想要的词语。
搜索引擎的核心是倒排索引,而倒排索引的基础就是分词。所谓分词可以简单理解为将一个完整的句子切割为一个个单词的过程。
读时分词发生在用户查询时,ES 会即时地对用户输入的关键词进行分词,分词结果只存在内存中,当查询结束时,分词结果也会随即消失。
写时分词发生在文档写入时,ES 会对文档进行分词后,将结果存入倒排索引,该部分最终会以文件的形式存储于磁盘上,不会因查询结束或者 ES 重启而丢失。
使用_analyze可以查询分词结果
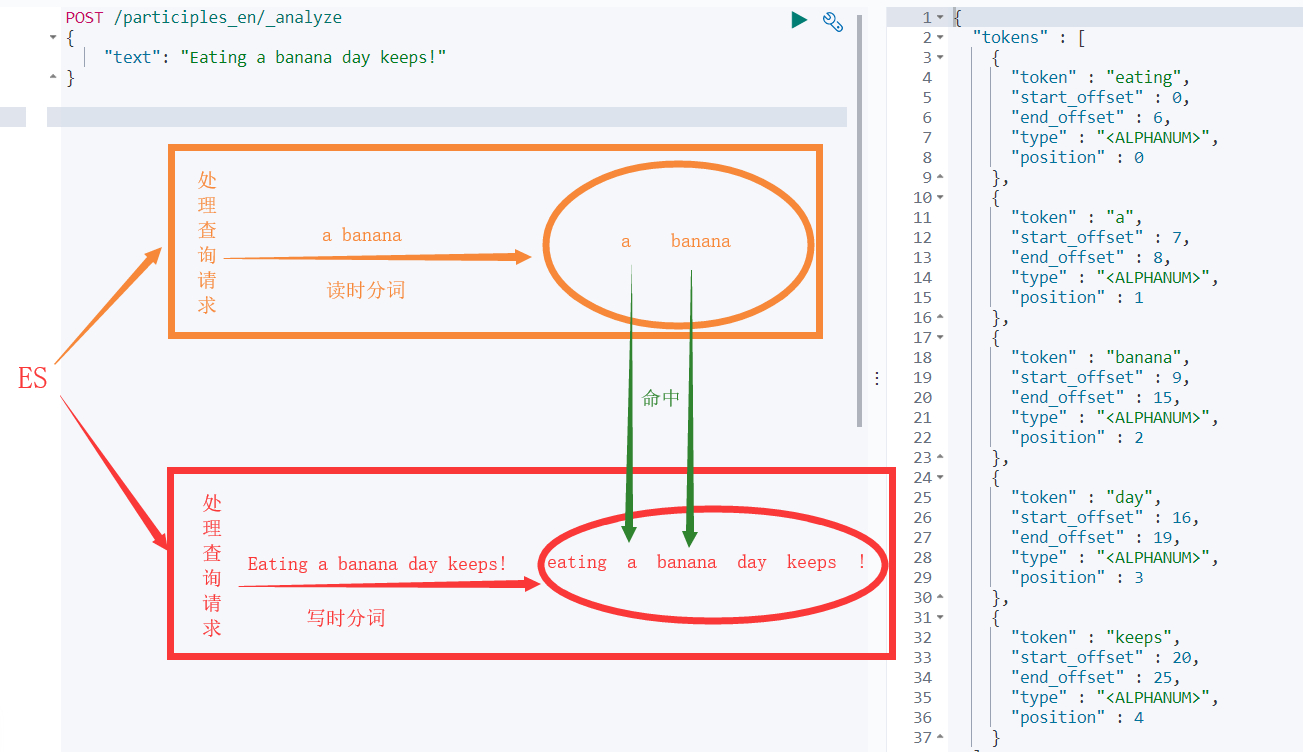
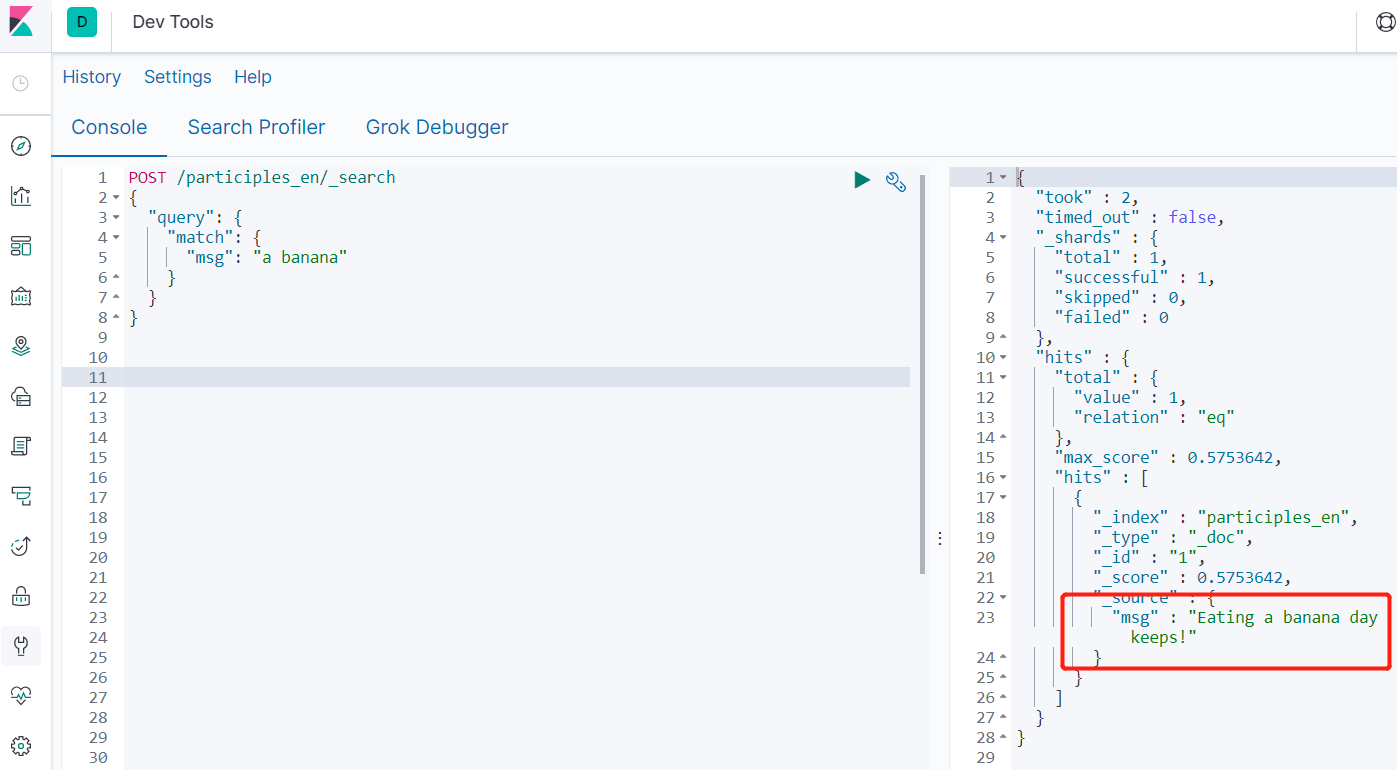
ES 中处理分词的部分被称作分词器,英文是Analyzer,它决定了分词的规则。ES 自带了很多默认的分词器,比如
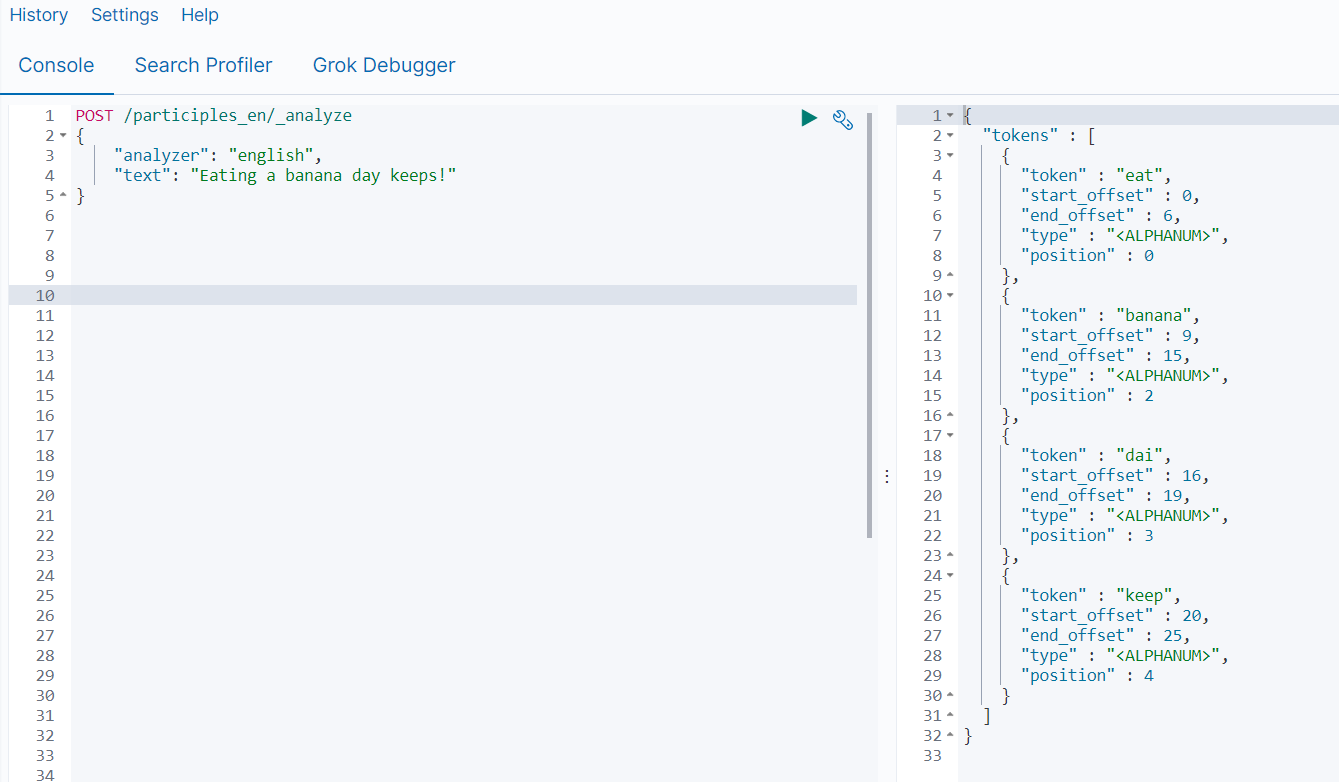
分词器名称 处理过程 Standard Analyzer(默认) 默认的分词器,按词切分,小写处理 Simple Analyzer 按照非字母切分(符号被过滤),小写处理 Stop Analyzer 小写处理,停用词过滤(the, a, this) Whitespace Analyzer 按照空格切分,不转小写 Keyword Analyzer 不分词,直接将输入当做输出 Pattern Analyzer 正则表达式,默认是\W+(非字符串分隔) English Analyzer 英文单词切分 当我们在读时或者写时分词时可以指定要使用的分词器,如下图使用English Analyzer对
“Eating a banana day keeps!”进行分词
- 更多案例
#A. Standard Analyzer
GET _analyze { "analyzer": "standard", "text": "2 Running quick brown-foxes leap over lazy dog in the summer evening" }
#B. Simple Analyzer
GET _analyze { "analyzer": "simple", "text": "2 Running quick brown-foxes leap over lazy dog in the summer evening" }
#C. Stop Analyzer
GET _analyze { "analyzer": "stop", "text": "2 Running quick brown-foxes leap over lazy dog in the summer evening" }
#D. Whitespace Analyzer
GET _analyze { "analyzer": "whitespace", "text": "2 Running quick brown-foxes leap over lazy dog in the summer evening" }
#E. Keyword Analyzer
GET _analyze { "analyzer": "keyword", "text": "2 Running quick brown-foxes leap over lazy dog in the summer evening" }
#F. Pattern Analyzer
GET _analyze { "analyzer": "pattern", "text": "2 Running quick brown-foxes leap over lazy dog in the summer evening" }
6.2 写时分词器指定
写时分词器需要在 mappings 中指定,而且一经指定就不能再修改,若要修改必须新建索引。
- 构建索引指定分词器
PUT participles_en_english
{
"mappings": {
"properties": {
"msg_en":{
"type": "text",
"analyzer": "english"
},
"msg":{
"type": "text"
}
}
}
}
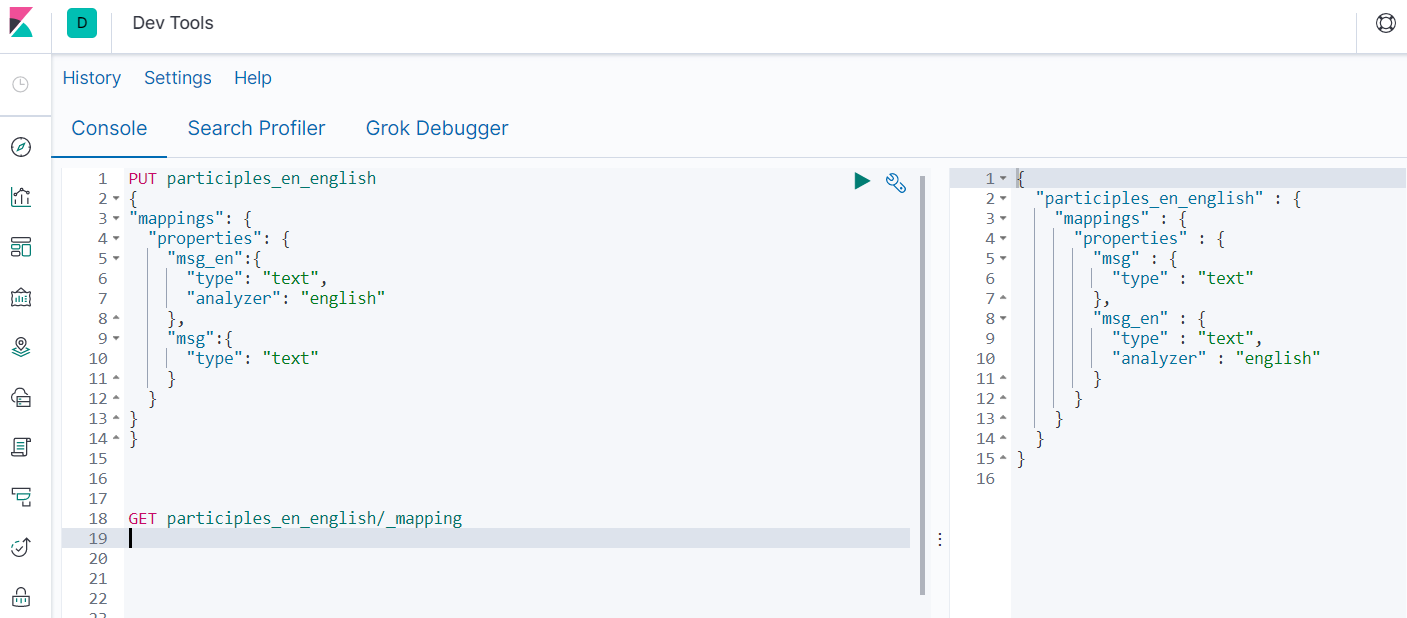
- 查询索引分词设置
GET participles_en_english/_mapping
- 插入数据
PUT /participles_en_english/_doc/1
{
"msg":"Eating a banana day keeps!",
"msg_en":"Eating a banana day keeps!"
}
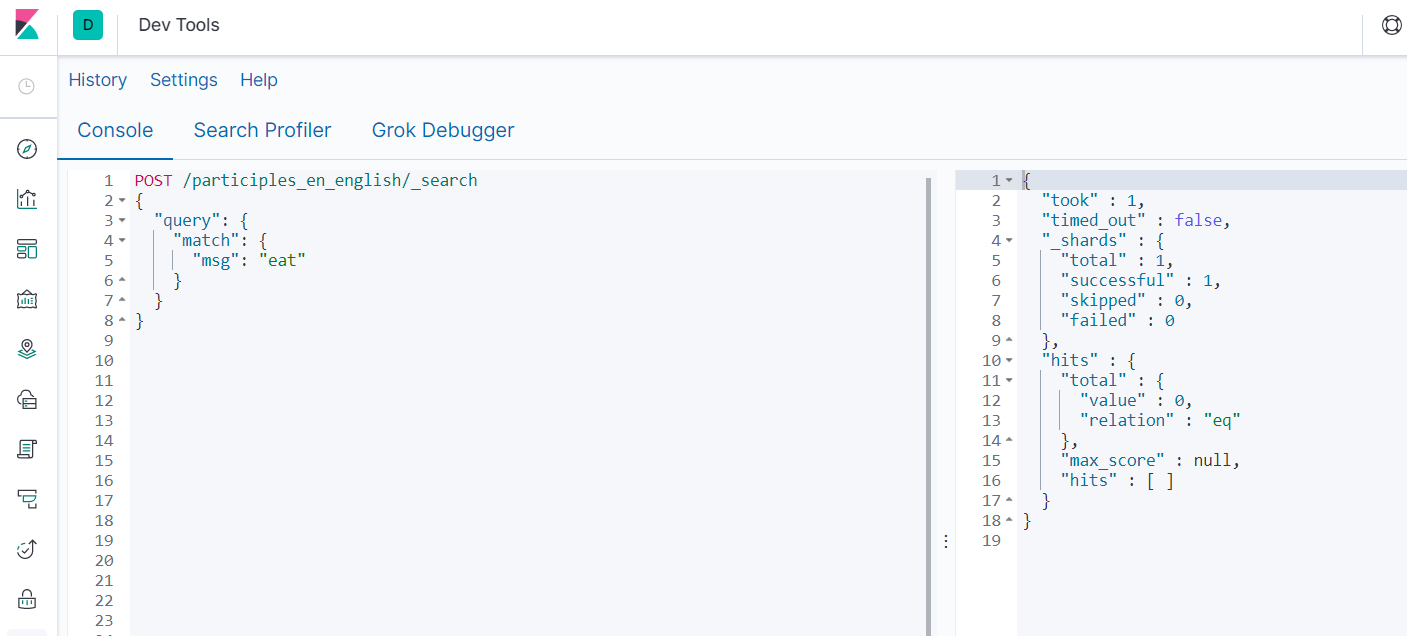
- 查询是否真的被分词
POST /participles_en_english/_search
{
"query": {
"match": {
"msg": "eat"
}
}
}
POST /participles_en_english/_search
{
"query": {
"match": {
"msg_en": "eat"
}
}
}

6.3 读时分词器指定
由于读时分词器默认与写时分词器默认保持一致,你搜索msg字段,那么读时分词器为Standard,搜索msg_en时分词器则为english。
- 查询需要插入字段分词结果
GET /participles_en_english/_analyze
{
"field": "msg_en",
"text": "Eating a banana day keeps!"
}
GET /participles_en_english/_analyze
{
"field": "msg",
"text": "Eating a banana day keeps!"
}
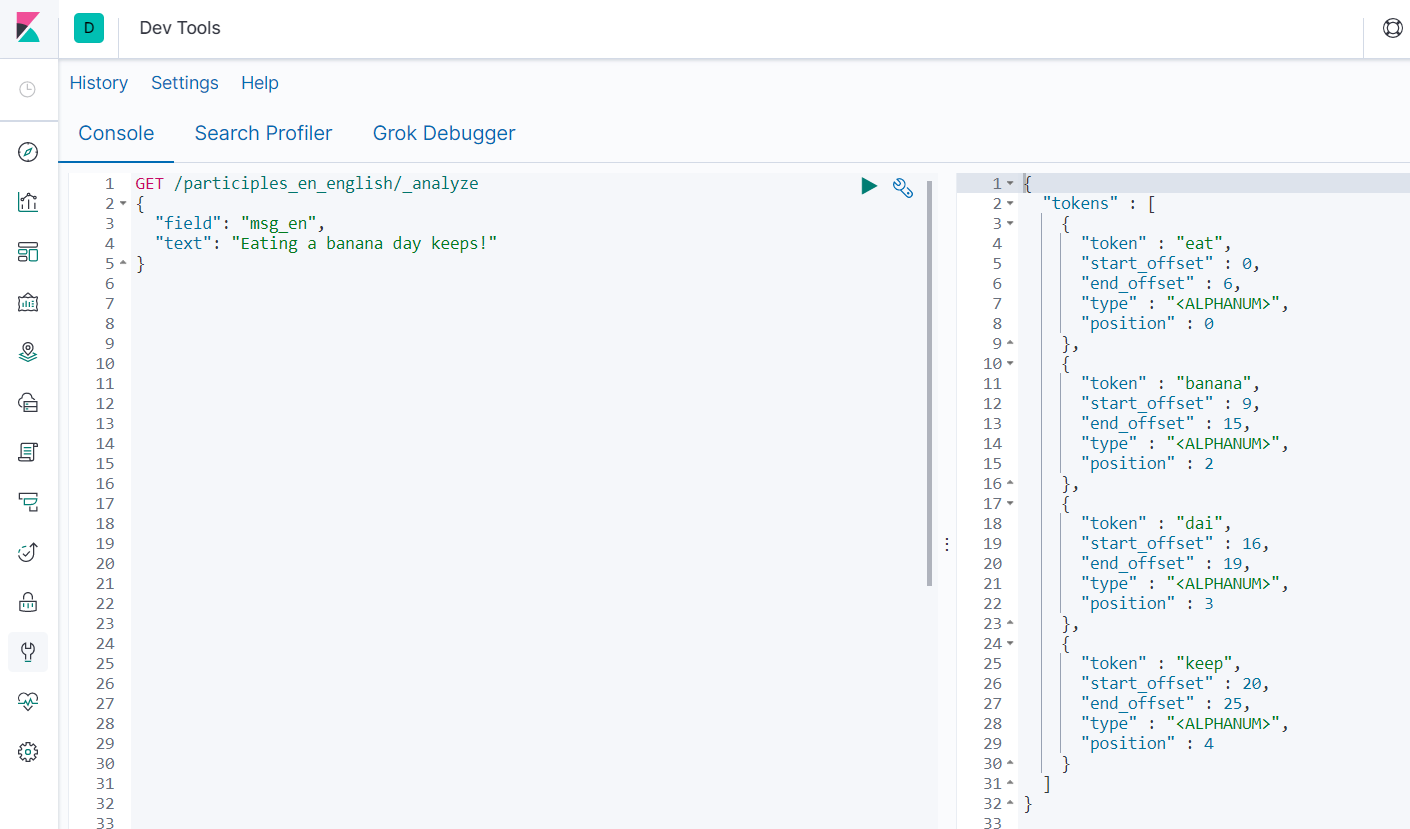
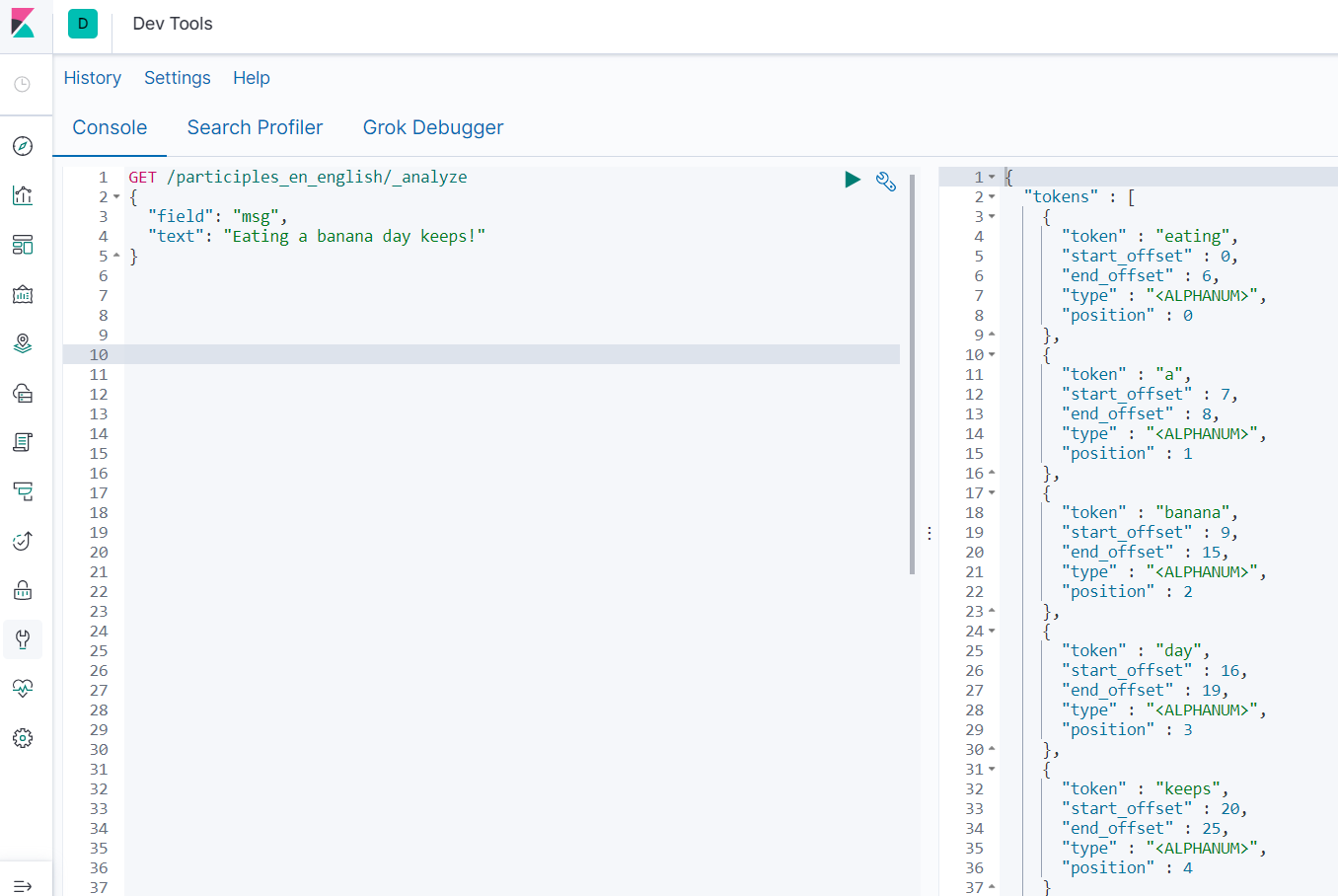
6.4 自定义分词器
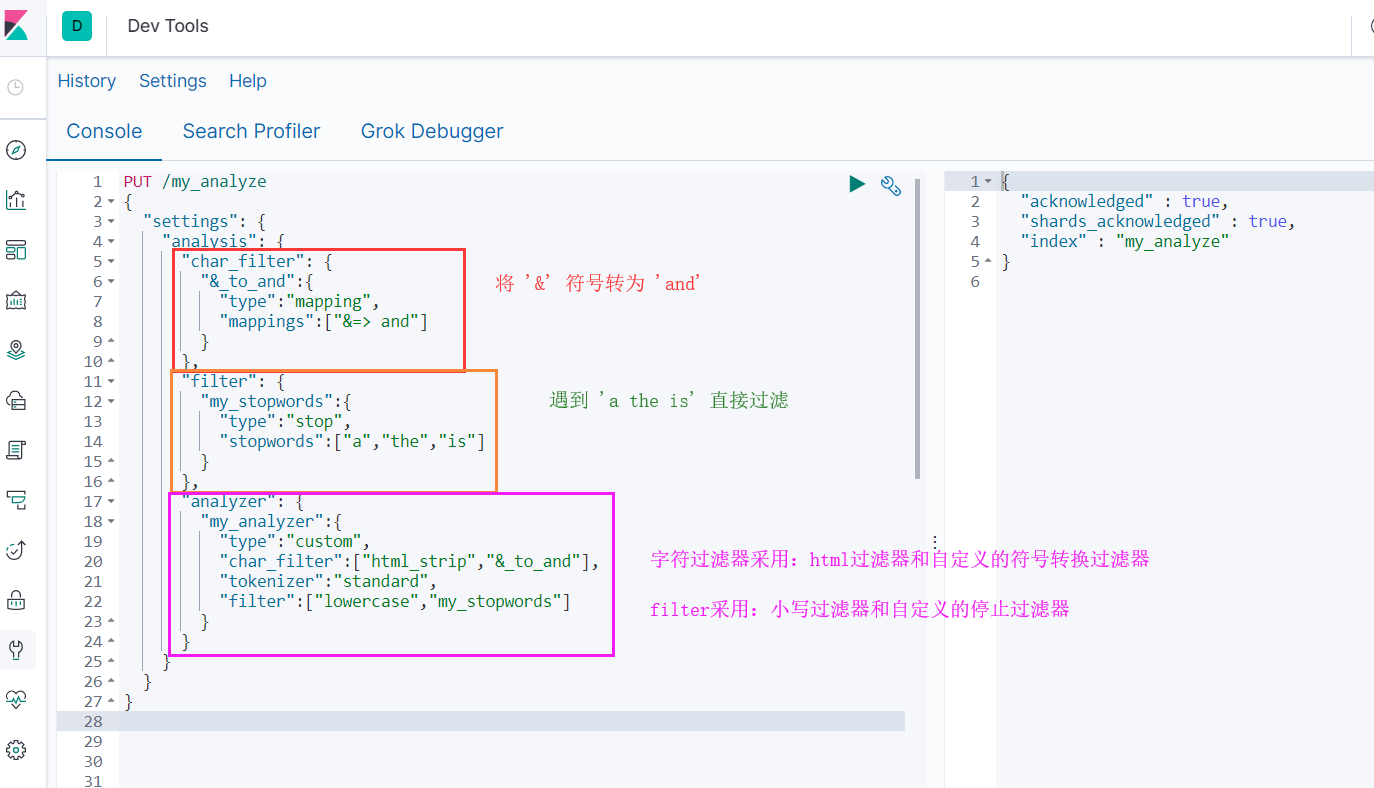
- 添加索引my_analyze,设置自定义分词器
PUT /my_analyze
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and":{
"type":"mapping",
"mappings":["&=> and"]
}
},
"filter": {
"my_stopwords":{
"type":"stop",
"stopwords":["a","the","is"]
}
},
"analyzer": {
"my_analyzer":{
"type":"custom",
"char_filter":["html_strip","&_to_and"],
"tokenizer":"standard",
"filter":["lowercase","my_stopwords"]
}
}
}
}
}
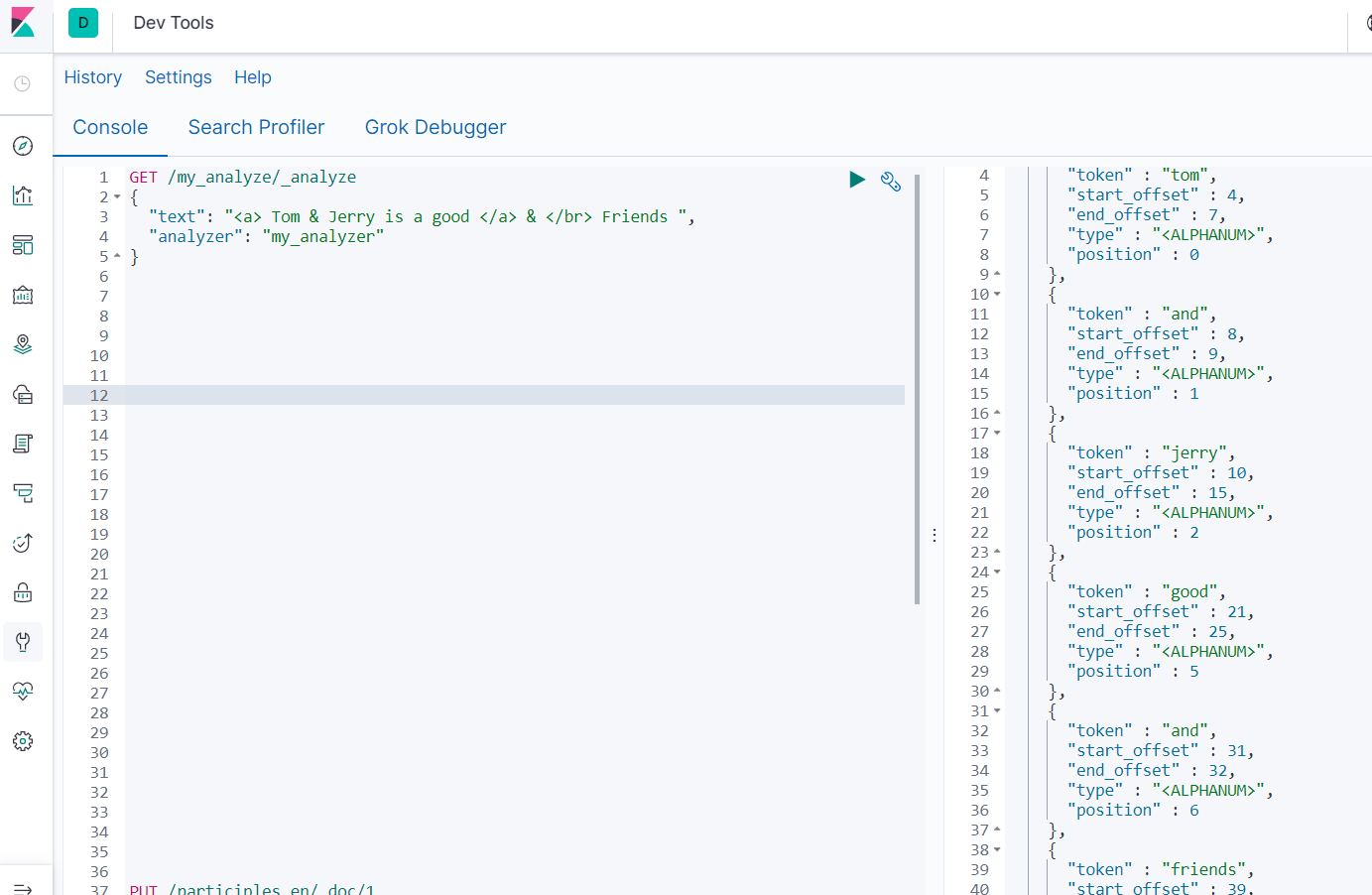
- 查看分词效果
GET /my_analyze/_analyze
{
"text": "<a> Tom & Jerry is a good </a> & </br> Friends ",
"analyzer": "my_analyzer"
}
6.5 IK分词器
IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开始,IK发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。在2012版本中,IK实现了简单的分词歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化
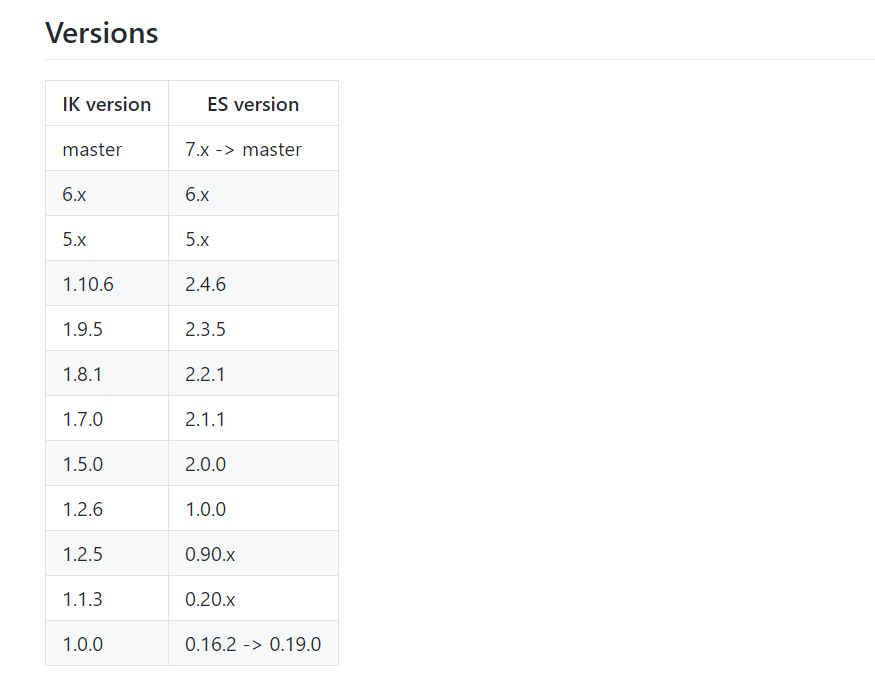
由于es是7.4.2,故选择ik7.4.2
6.5.1安装

- 使用es插件安装(需要file:///协议头)
/usr/local/src/elasticsearch/elasticsearch-7.4.2/bin/elasticsearch-plugin install file:///usr/local/src/ik/elasticsearch-analysis-ik-7.4.2.zip

- 重启es即可
6.5.2 使用
- 未使用IK分词器
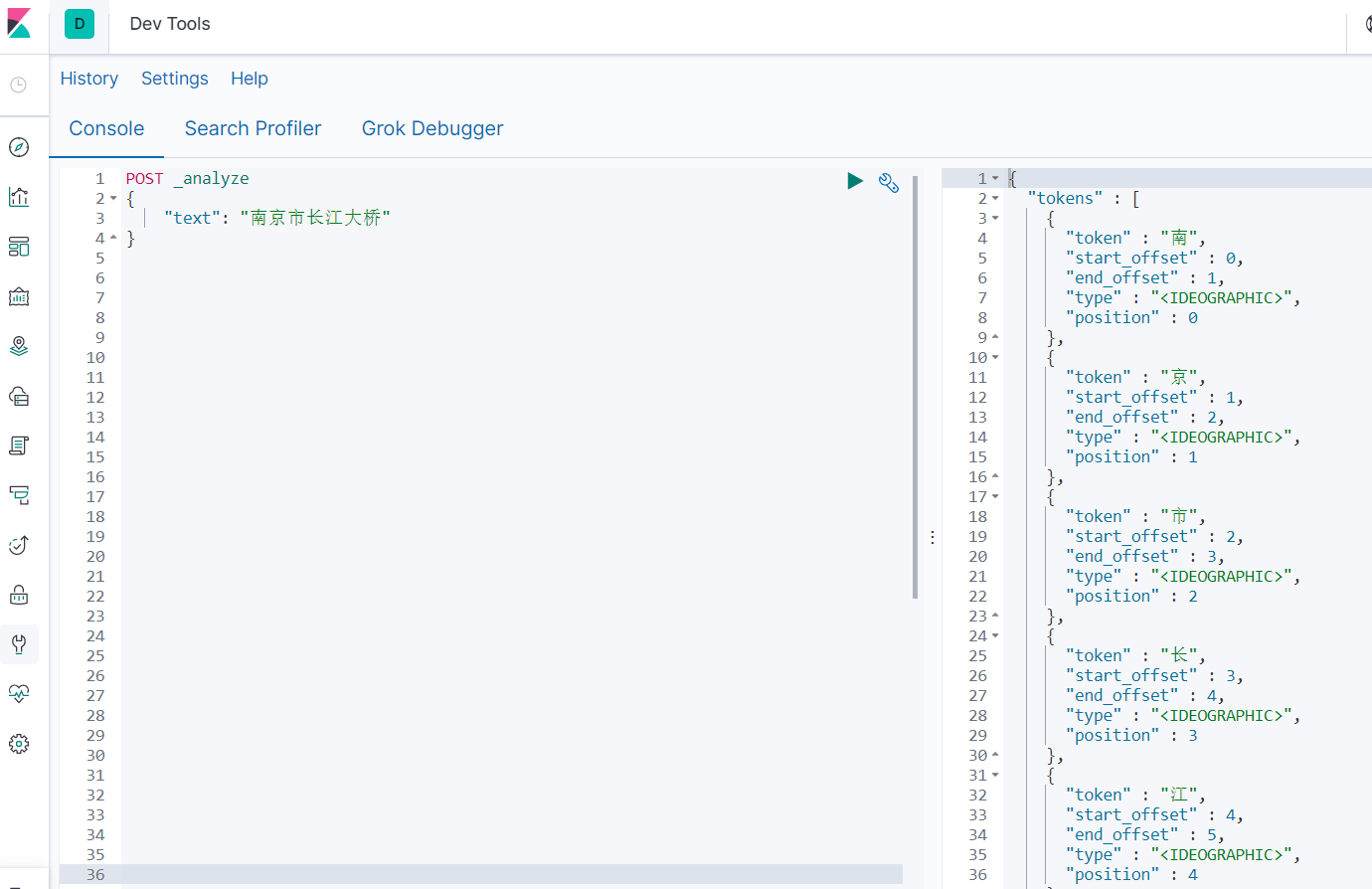
- 使用ik_smart
POST _analyze
{
"analyzer": "ik_smart",
"text": "南京市长江大桥"
}
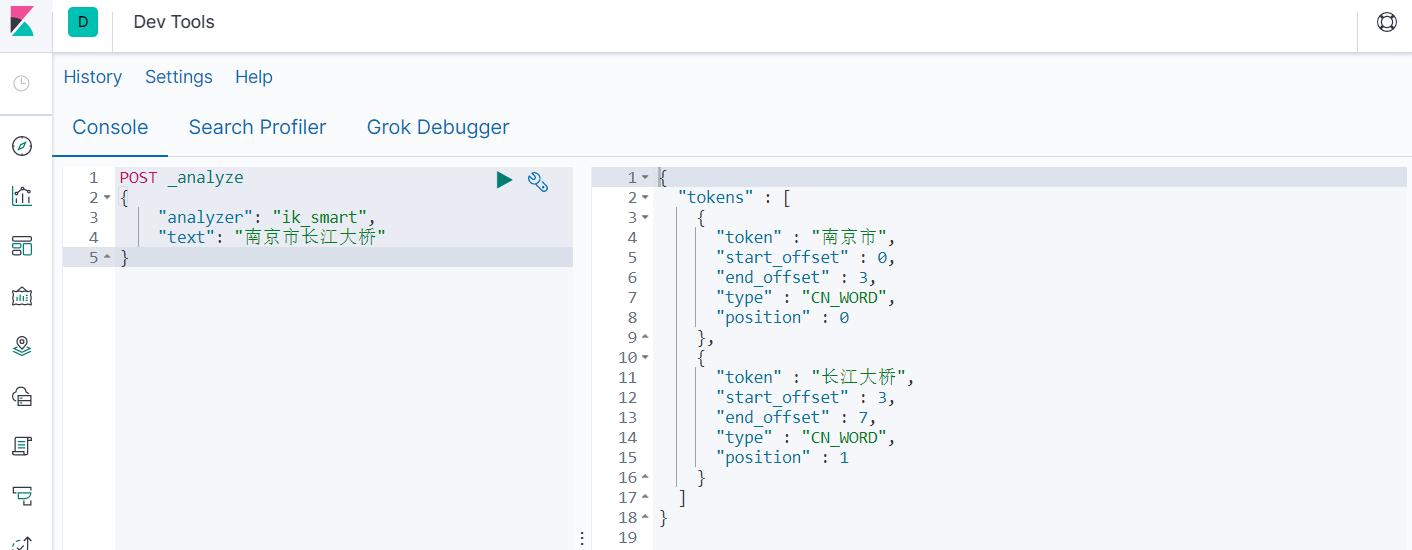
- 使用ik_max_word
POST _analyze
{
"analyzer": "ik_max_word",
"text": "南京市长江大桥"
}
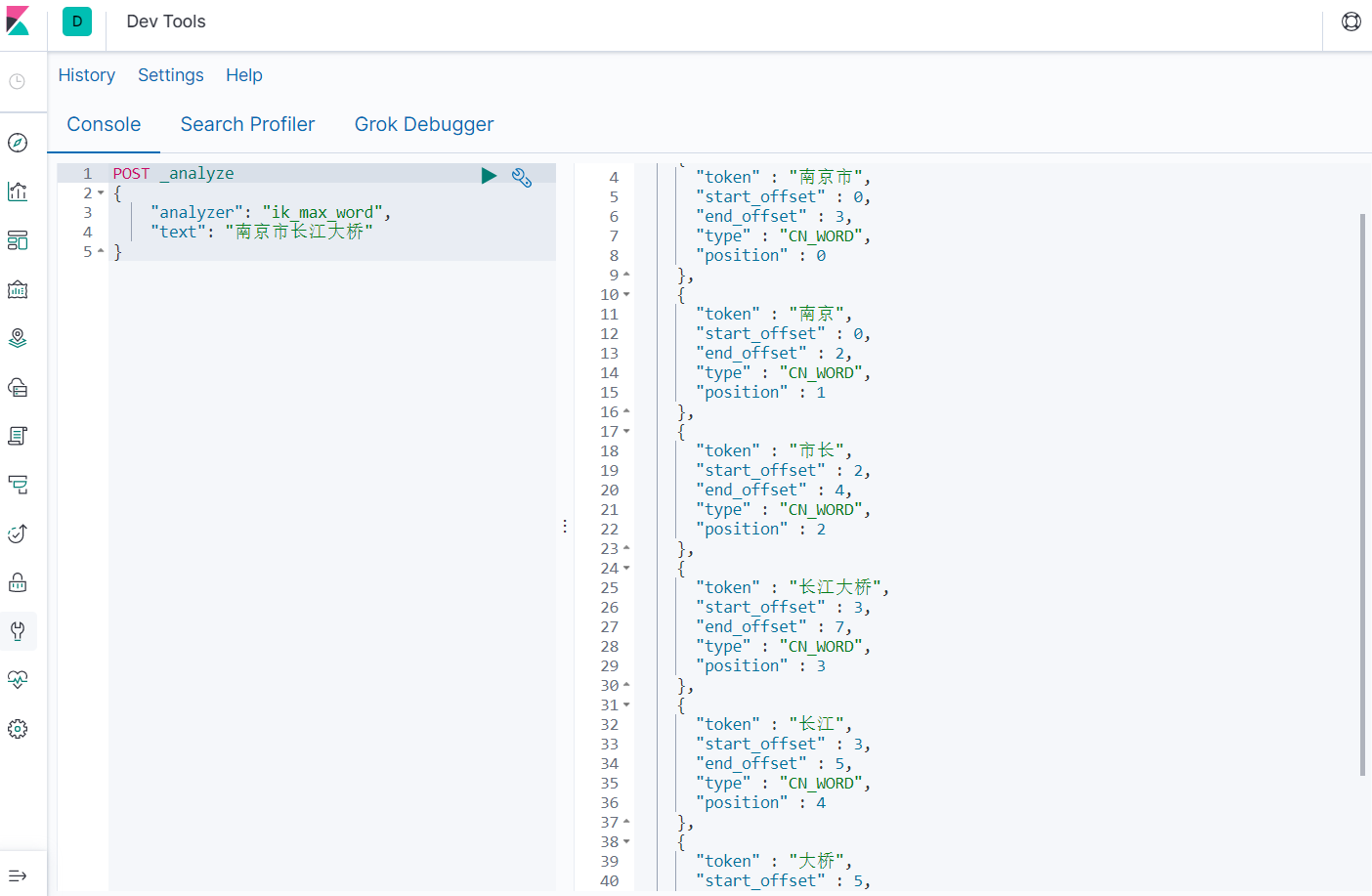
比较两个分词器对同一句中文的分词结果,ik_max_word比ik_smart得到的中文词更多,但这样也带来一个问题,使用ik_max_word会占用更多的存储空间
6.5.3 ik自定义词典
k提供了自定义词典的功能,也就是用户可以自己定义一些词汇,这样ik就会把它们当作词典中的内容来处理。其实就是上面中文能分成那么多词是有一套别人写好的词典。
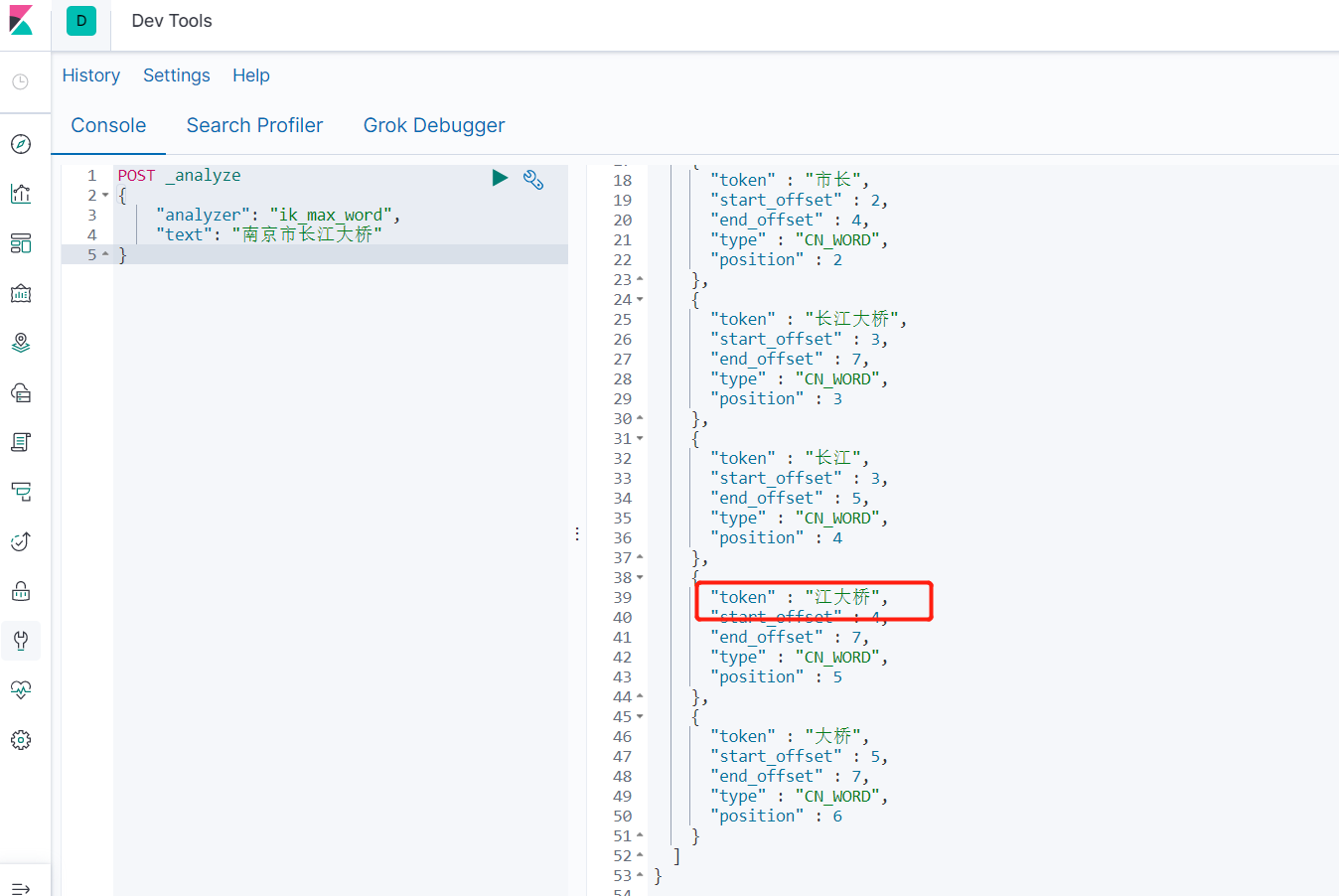
如上面例子中,“江大桥‘是个人,而且火了,我们现在先把江大桥也索引出来。
- 在elasticsearch-7.4.2/config/analysis-ik目录下新建 my.dic文件,写入”江大桥“

- 在elasticsearch-7.4.2/config/analysis-ik目录下修改 IKAnalyzer.cfg.xml文件
vim IKAnalyzer.cfg.xml
#修改如下内容,指定拓展文件
<entry key="ext_dict">my.dic</entry>
- 重启es生效,发现针对ik_max_word生效
6.5.4 ik分词测试
- 创建索引
PUT participles_ik
{
"mappings": {
"properties": {
"msg_ch":{
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"msg":{
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
}
}
}
}
- 插入数据
PUT /participles_ik/_doc/1
{
"msg":"南京市长江大桥",
"msg_ch":"南京市长江大桥"
}
- 获取数据
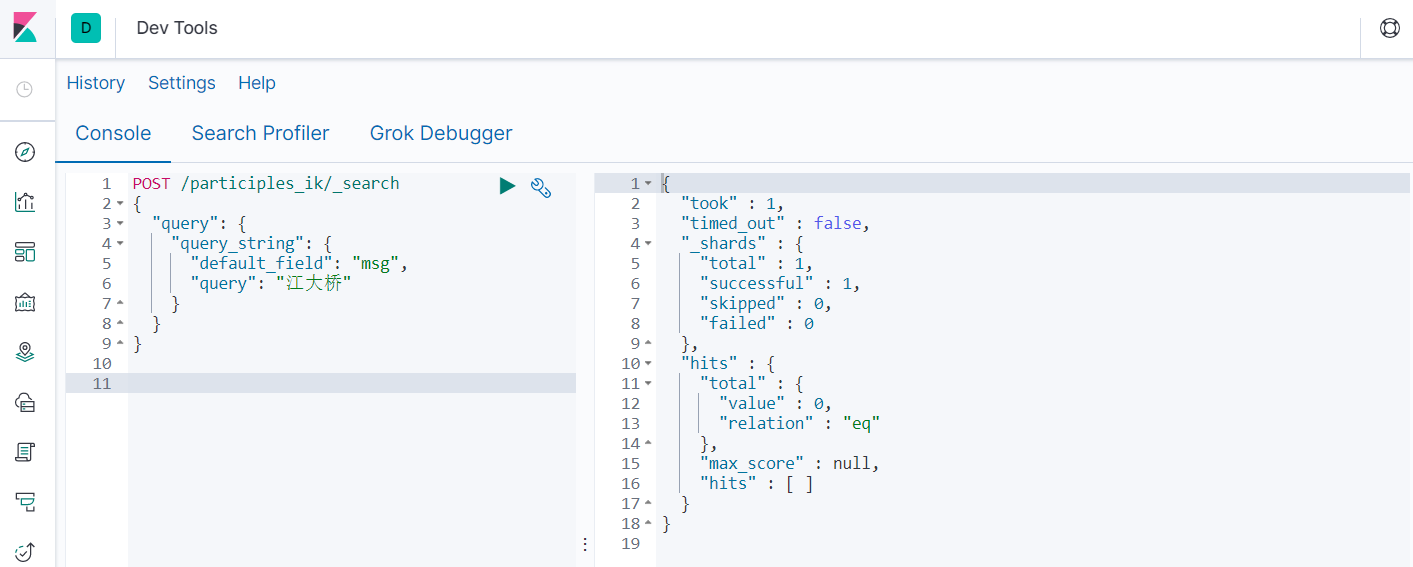
POST /participles_ik/_search
{
"query": {
"query_string": {
"default_field": "msg",
"query": "江大桥"
}
}
}
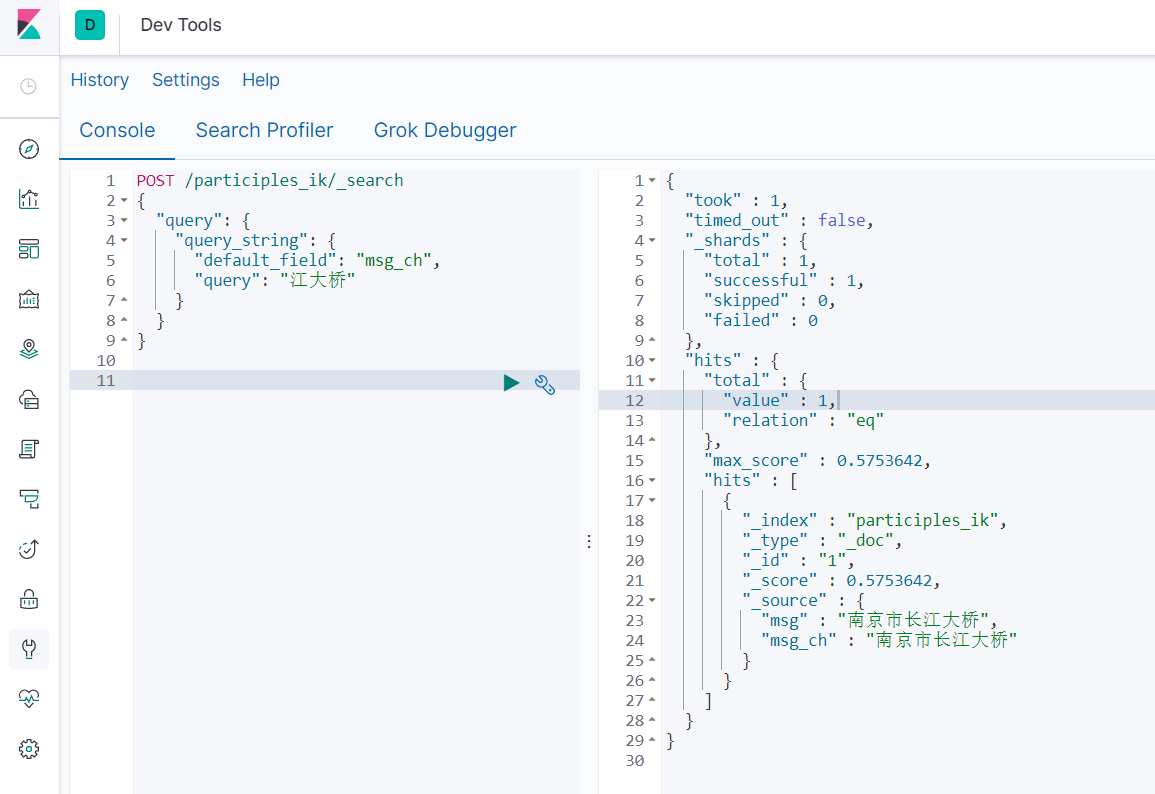
POST /participles_ik/_search
{
"query": {
"query_string": {
"default_field": "msg_ch",
"query": "江大桥"
}
}
}
7 索引设计
- 索引设计重要性
- 好的索引设计在整个集群规划中占据举足轻重的作用,索引的设计直接影响集群设计的好坏和复杂度。
- 好的索引设计应该是充分结合业务场景的时间维度和空间维度,结合业务场景充分考量增、删、改、查等全维度设计的。
- 好的索引设计是完全基于“设计先行,编码在后”的原则,前期会花很长时间,为的是后期工作更加顺畅,避免不必要的返工。
7.1 PB 级别的大索引如何设计?
7.1.1 存储大小限制维度
- 单个分片(Shard)实际是 Lucene 的索引,单分片能存储的最大文档数是:2,147,483,519 (= Integer.MAX_VALUE - 128),可以使用'GET _cat/shards'命令查询全部索引的分隔分片的文档大小。
7.1.2 性能维度
-
索引很大的话,数据写入和查询性能都会变差。
-
而高效检索体现在:基于日期的检索可以直接检索对应日期的索引,无形中缩减了很大的数据规模。
-
比如一开始我们的订单索引设计为order,要检索某一天的数据会是在一个月甚至更大体量的索引中进行。
-
如果索引设计为“业务_yyyy-MM-dd”形式,现在直接检索"order_2020-02-28"的索引,效率提升好几倍。
7.1.3 风险维度
- 一旦一个大索引出现故障,相关的数据都会受到影响。而分成滚动索引的话,相当于做了物理隔离。
7.1.4 方案
- 方案一:rollover + curator + crontab(增量索引的管理模板)
- 方案二(推荐):Index Lifecycle Management(6.6版本的新特性:索引生命周期管理)
- 目的:统一管理索引,相关索引字段完全一致。
7.1.4.1 方案一:Rollver 增量管理索引
-
场景:每天数据量很少,但是又需要保存很久的数据,或者每天数据量极大,每天一个索引已经不能容纳了,这个时候我们就需要考虑一个机制,将索引rollover。
-
按照日期、文档数、文档存储大小三个维度进行更新索引
#1 新建订单索引
PUT order
#2 对ordr建立别名
POST _aliases
{
"actions": [
{
"add": {
"index": "order",
"alias": "test_order",
"is_write_index" : true
}
}
]
}
#3 手动Rollover
# 结合alias,我们可以实现客户端写alias,在需要时将alias指向一个新的索引,就可以自由地控制数据的写入了
# 创建一个新索引order1
PUT order1
#4 再将alias指向新的索引并移除旧的alias
POST _aliases
{
"actions": [
{
"remove": {
"index": "order",
"alias": "test_order"
}
},
{
"add": {
"index": "order1",
"alias": "test_order",
"is_write_index" : true
}
}
]
}
# 4.1 自动Rollover
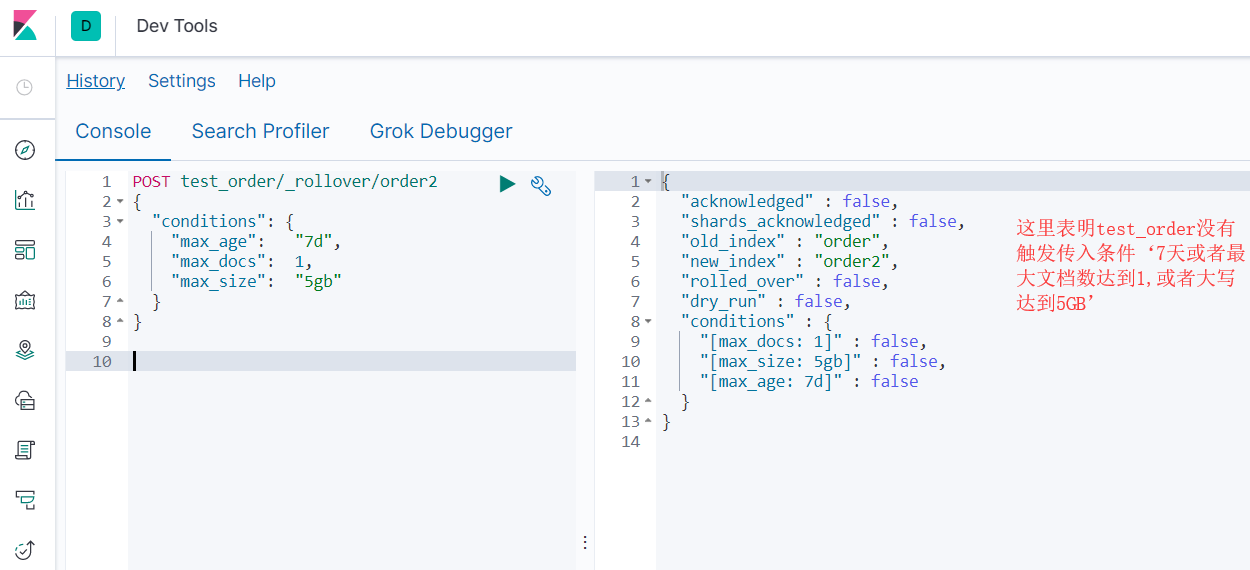
#我们手动Rollover了一个索引,在运行过程中,我们需要不断的获取ES中索引的情况,然后判断是否进行Rollover。这里,我们可以用ES自带的Rollover接口替代,
#已经存在一个order索引, 和一个test_order别名指向order,测试是否可以_rollover
POST test_order/_rollover/order2
{
"conditions": {
"max_age": "7d",
"max_docs": 1,
"max_size": "5gb"
}
}
#4.2 写入一个document
PUT test_order/_doc/1
{
"msg":"value1"
}
#4.3 执行4.1的操作
POST test_order/_rollover/order2
{
"conditions": {
"max_age": "7d",
"max_docs": 1,
"max_size": "5gb"
}
}

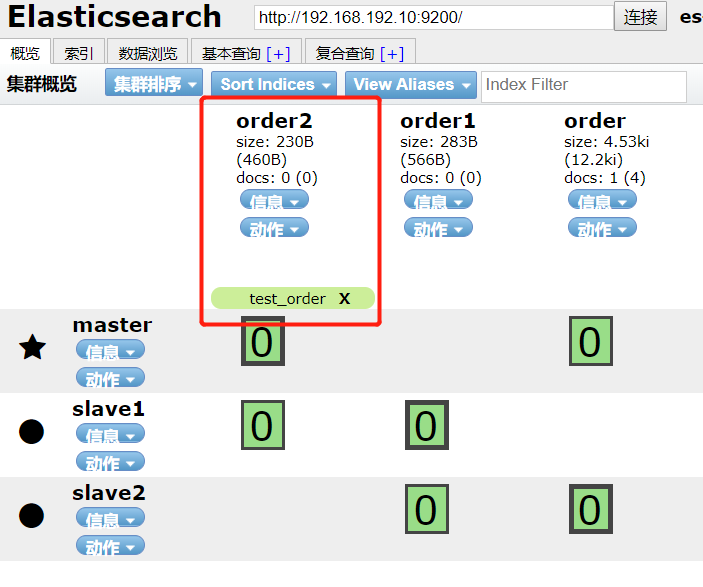
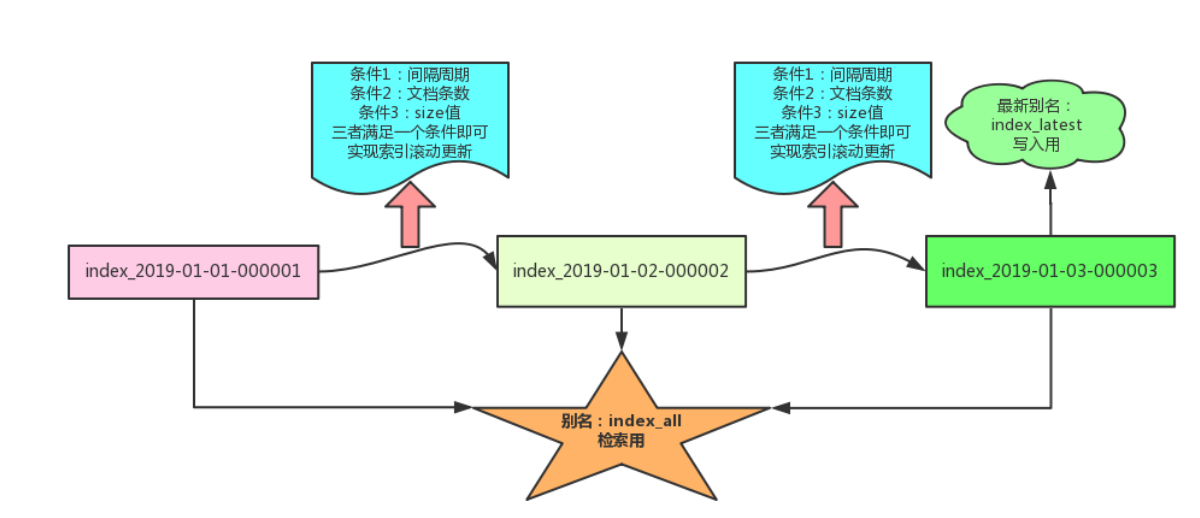
索引更新的时机是:当原始索引满足设置条件的三个中的一个的时候,就会更新为新的索引。为保证业务的全索引检索,一般采用别名机制。
在索引模板设计阶段,模板定义一个全局别名:用途是全局检索,如图所示的别名:indexall。每次更新到新的索引后,新索引指向一个用于实时新数据写入的别名,如图所示的别名:indexlatest。同时将旧索引的别名 index_latest 移除。
7.1.4.2 方案一:使用 curator 高效清理历史数据
- 目的:按照日期定期删除、归档历史数据。
- 解决问题:
- 一个大索引的数据删除方式只能使用 delete_by_query,由于 ES 中使用更新版本机制。删除索引后,由于没有物理删除,磁盘存储信息会不减反增。有同学就反馈 500GB+ 的索引 delete_by_query 导致负载增高的情况
- 如果没有基于时间创建索引,单一索引借助delete_by_query结合时间戳,会越删磁盘空间越紧张,以至于对自己都产生了怀疑?
- 是否还在通过复杂的脚本管理索引?
- 1个增量rollover动态更新脚本,
- 1个定期delete脚本,
- 1个定期force_merge脚本,
- 1个定期shrink脚本,
- 1个定期快照脚本。
- 索引多了或者集群规模大了,脚本的维护是一笔不菲的开销。
- 而按照日期划分索引后,不需要的历史数据可以做如下的处理。
- 删除——对应 delete 索引操作。
- 压缩——对应 shrink 操作。
- 段合并——对应 force_merge 操作。
- 而这一切,可以借助:curator 工具通过简单的配置文件结合定义任务 crontab 一键实现。
curator最早被称为clearESindices.py。 它的唯一功能是删除索引,
而后重命名:logstash_index_cleaner.py。它在logstash存储库下作用:过期日志清理。
此后不久,原作者加入Elastic,它成为了Elasticsearch Curator,
Git地址:https://github.com/elastic/curator
7.1.4.3 方案二:使用 ILM索引生命周期管理
index lifecycle management
只需要在kibana内简单配置,就可以管理以前我们不得不设置cronjob去删除index的工作.
ES索引生命周期管理分为4个阶段:hot、warm、cold、delete,其中hot主要负责对索引进行rollover操作,warm、cold、delete分别对rollover后的数据进一步处理(前提是配置了hot)。
phases desc hot 主要处理时序数据的实时写入 warm 可以用来查询,但是不再写入 cold 索引不再有更新操作,并且查询也会很少 delete 数据将被删除
- 案例
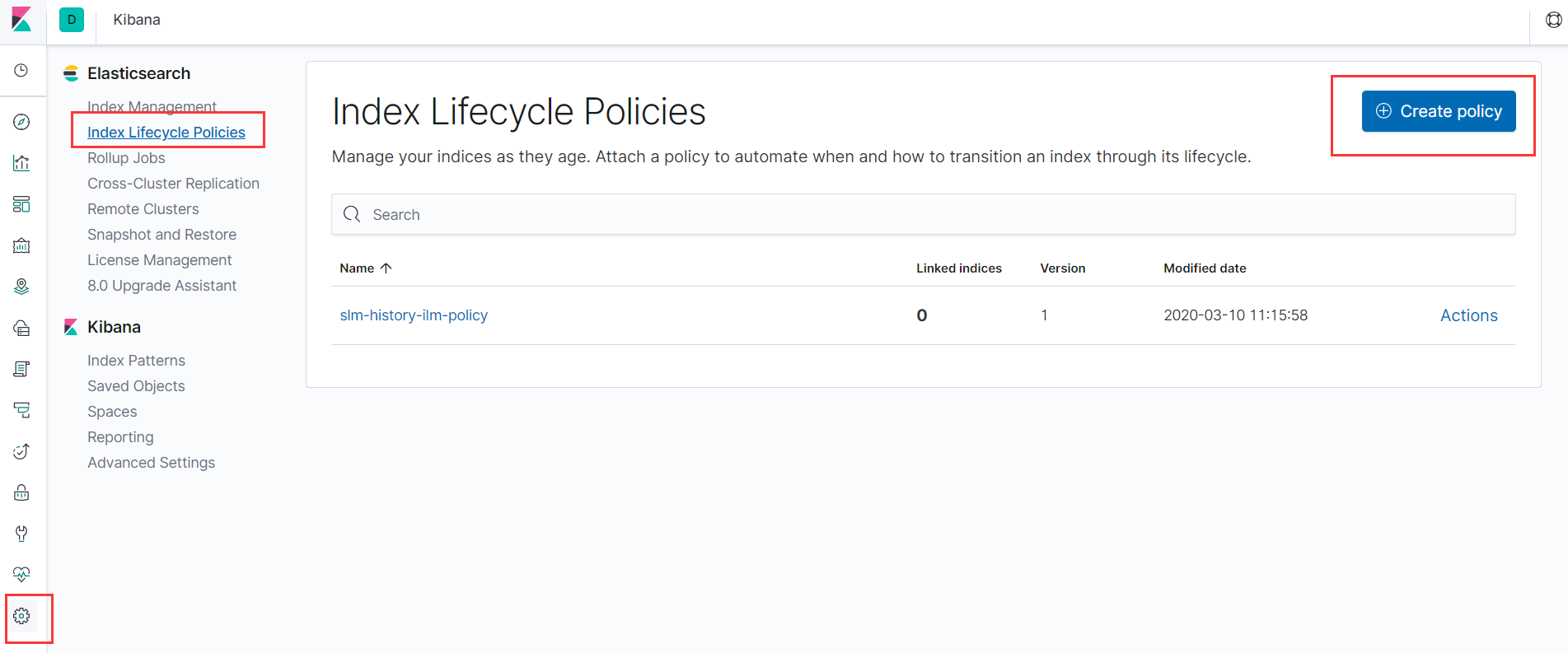
- 建立简单的ILM策略
- 使用命令创建policy,其意思如下:
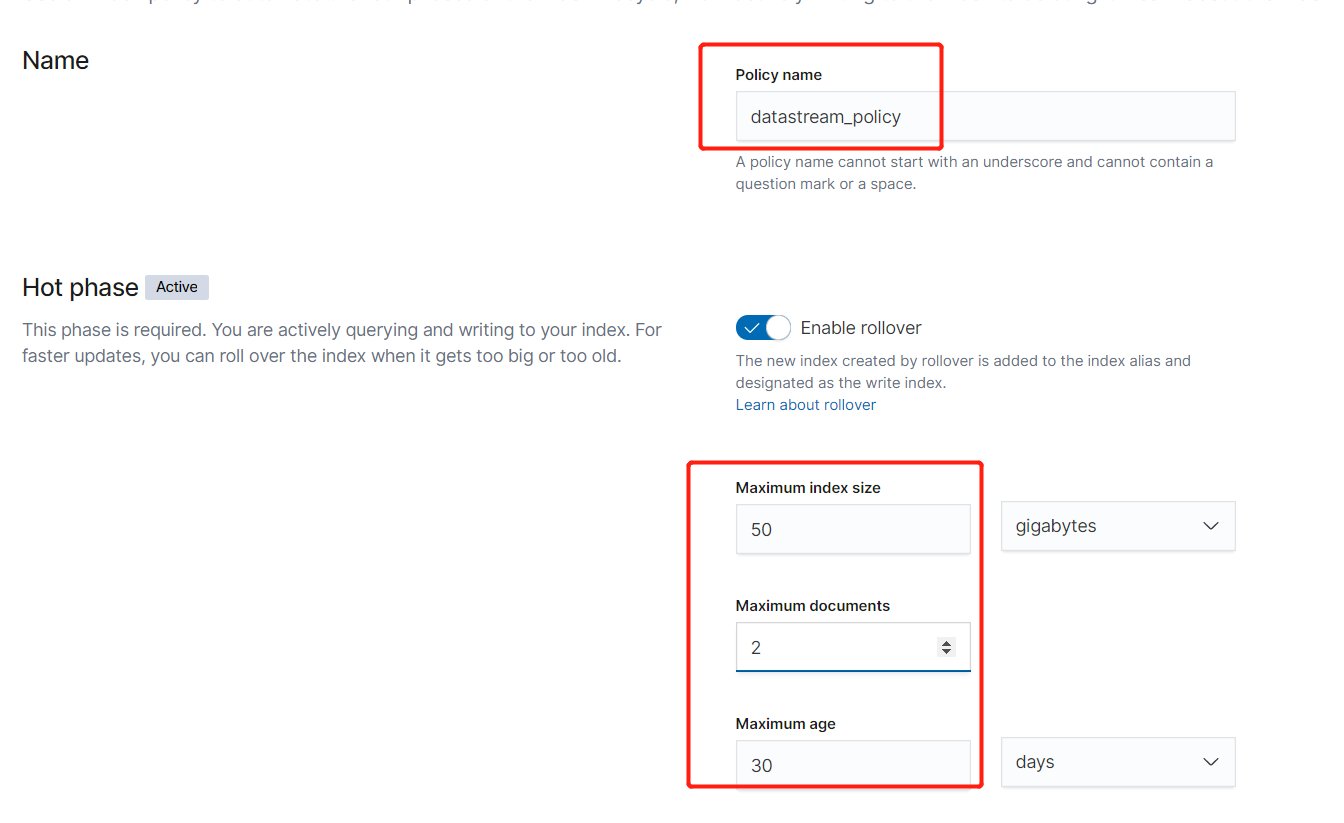
- 如果一个index的大小超过50GB,那么自动rollover
- 如果一个index日期已在30天前创建索引后,那么自动rollover
- 如果一个index的文档数超过2,那么也会自动rollover
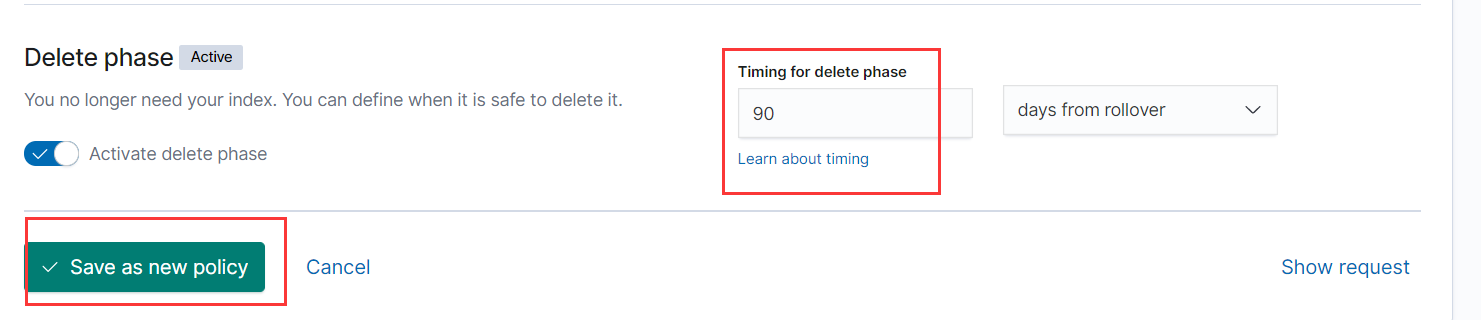
- 当一个index创建的时间超过90天,那么也自动删除
PUT _ilm/policy/datastream_policy
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_age": "30d",
"max_size": "50gb",
"max_docs": 2
},
"set_priority": {
"priority": 100
}
}
},
"delete": {
"min_age": "90d",
"actions": {
"delete": {}
}
}
}
}
}
- 或者使用kibana创建
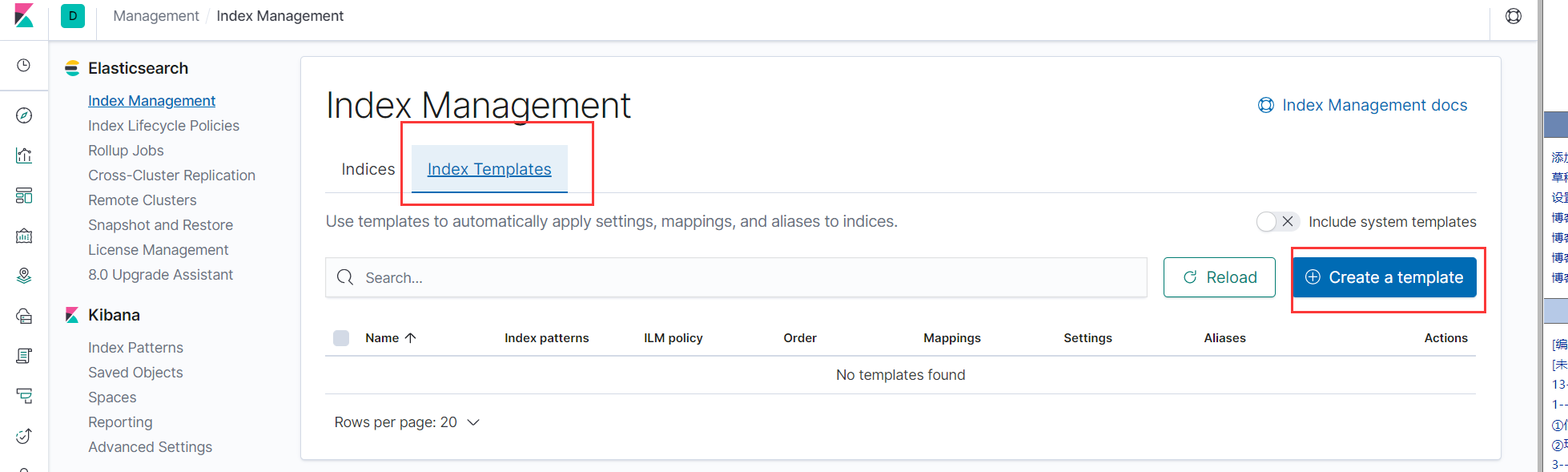
- 定义 Index 模板,使用策略
- 意思如下:
- index_patterns所有以logs开头的index都需要遵循这个规律。
- rollover_alias别名为“logs”。
PUT _template/datastream_template
{
"index_patterns": ["logs-*"],
"order" : 0,
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.lifecycle.name": "datastream_policy",
"index.lifecycle.rollover_alias": "logs"
}
}
- 或者使用kibana创建
- 定义 Index 别名
- 意思如下:
- 在这里定义了一个别名叫做logs,它指向logs-00001索引。
- is_write_index为true。如果有rollover发生时,这个alias会自动指向最新rollover的index
PUT logs-000001
{
"aliases": {
"logs": {
"is_write_index": true
}
}
}
- 添加数据前后查看索引策略
GET logs-*/_ilm/explain
- 生产数据,查看效果
PUT logs/_doc/1
{
"msg":"value1"
}
PUT logs/_doc/2
{
"msg":"value2"
}
PUT logs/_doc/3
{
"msg":"value3"
}

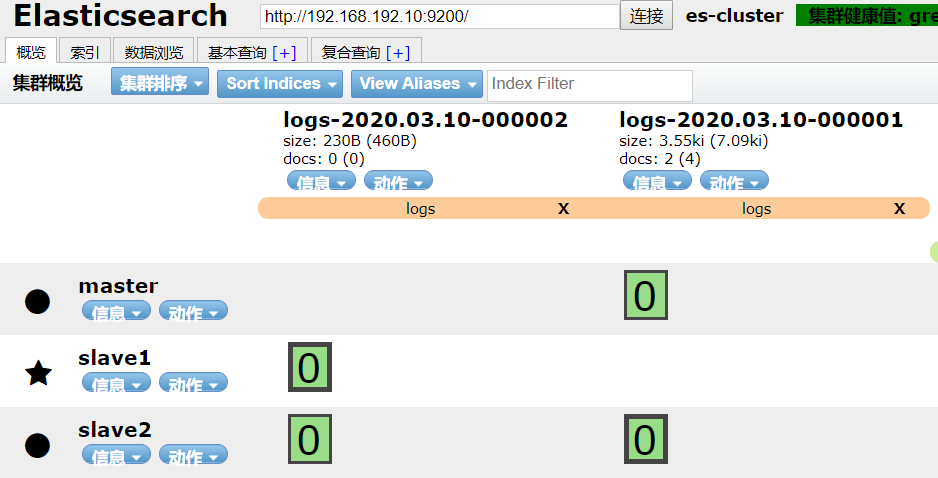
- 补充索引创建日期滚动方式
#PUT /<logs-{now/d}-000001> with URI encoding: 效果 logs-2020.03.10-000001
# 特殊字符都应进行 URI 编码
PUT /%3Clogs-%7Bnow%2Fd%7D-000001%3E
{
"aliases": {
"logs": {
"is_write_index": true
}
}
}

- 如上面操作后效果
- 转码表
| < | %3C |
|---|---|
| > | %3E |
| / | %2F |
| { | %7B |
| } | %7D |
| | | %7C |
| + | %2B |
| : | %3A |
| ,(逗号) | %2C |
- 例子(以2020年3月10日为例)
| 需要形式 | 格式 | 转码表 |
|---|---|---|
| logs-2020.03.10 | <logstash-{now/d}> | %3Clogs-%7Bnow%2Fd%7D%3E |
| logs-2020.03.01 | <logstash-{now/M}> | %3Clogs-%7Bnow%2FM%7D%3E |
| logs-2020.03 | <logstash-{now/M{YYYY.MM}}> | %3Clogs-%7Bnow%2FM%7BYYYY.MM%7D%7D%3E |
| logs-2020.02 | <logstash-{now/M-1M{YYYY.MM}}> | %3Clogs-%7Bnow%2FM-1M%7BYYYY.MM%7D%7D%3E |
7.2 分片数和副本数如何设计?
7.2.1 分片/副本认知
- 分片:分片本身都是一个功能齐全且独立的“索引”,可以托管在集群中的任何节点上。
- 数据切分分片的主要目的:
- (1)水平分割/缩放内容量 。
- (2)跨分片(可能在多个节点上)分布和并行化操作,提高性能/吞吐量。
- 注意:分片一旦创建,不可以修改大小。
- 数据切分分片的主要目的:
- 副本:它在分片/节点出现故障时提供高可用性。
- 副本的好处:因为可以在所有副本上并行执行搜索——因此扩展了搜索量/吞吐量。
- 注意:副本分片与主分片存储在集群中不同的节点。副本的大小可以通过:number_of_replicas动态修改。
- 分片副本例子
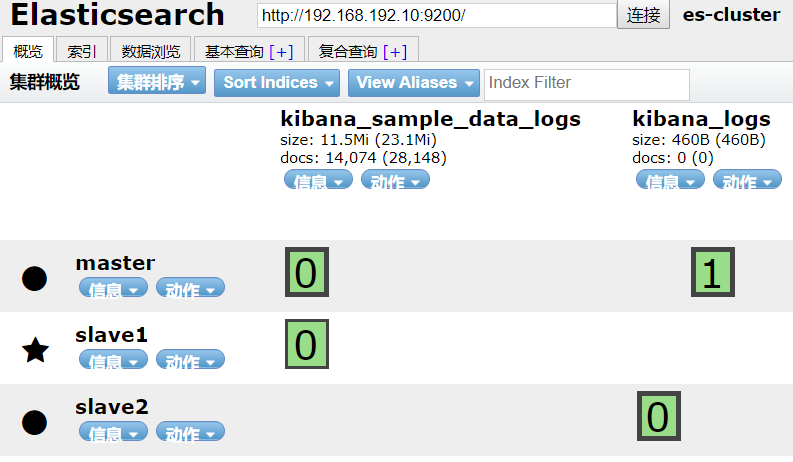
#使用模板控制kibana_开头的索引为2个分片0个副本
PUT _template/shards_and_replicas_template
{
"index_patterns": ["kibana_*"],
"order" : 0,
"settings": {
"number_of_shards": 2,
"number_of_replicas": 0
}
}
#创建kibana_logs索引
PUT kibana_logs
插入一组数据
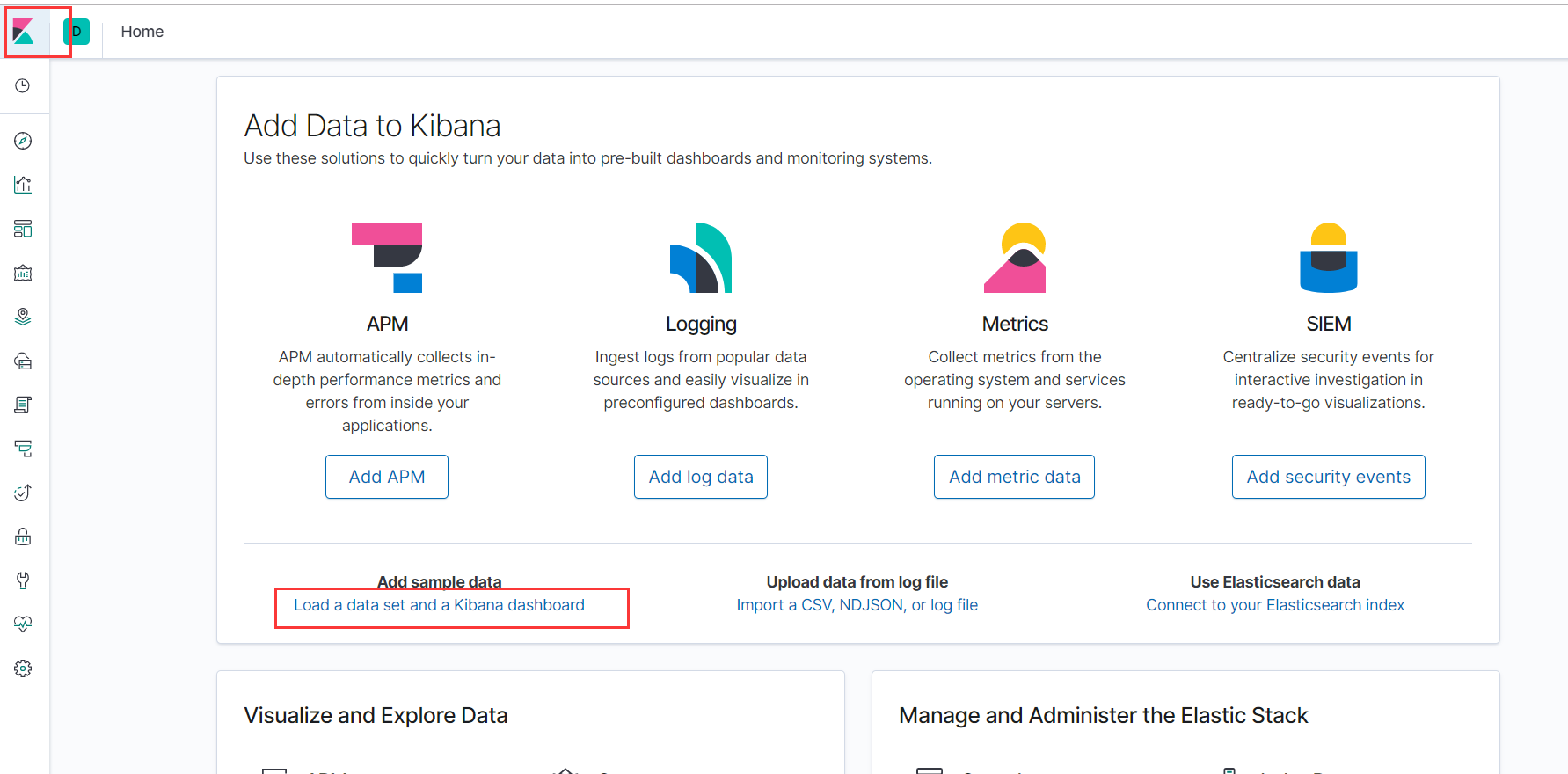
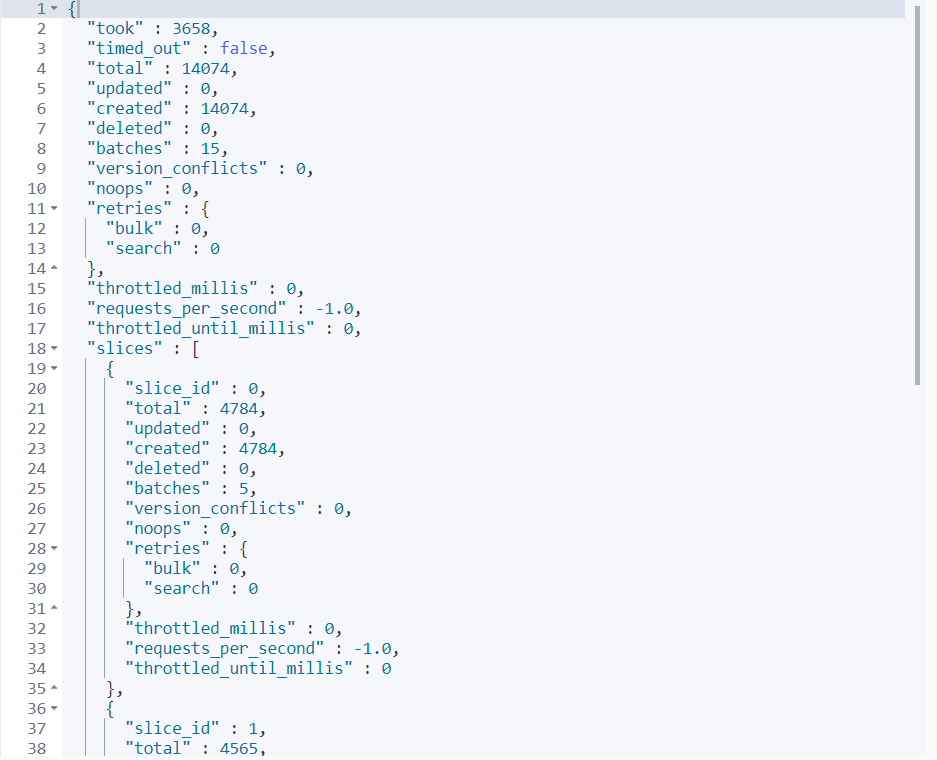
#数据导入_reindex(3个并行且执行刷新),下图中可以看出是分了3组数据一起插入
POST /_reindex?slices=3&refresh
{
"source": {
"index": "kibana_sample_data_logs"
},
"dest": {
"index": "kibana_logs"
}
}
#查询2个分片的数据
GET kibana_logs/_search?preference=_shards:0
GET kibana_logs/_search?preference=_shards:1
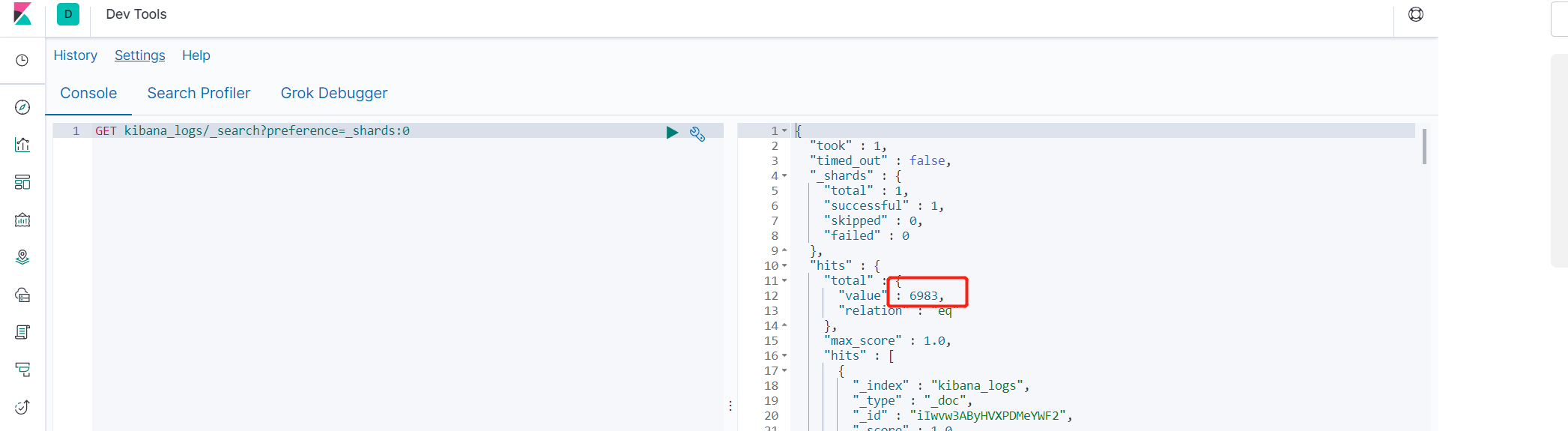
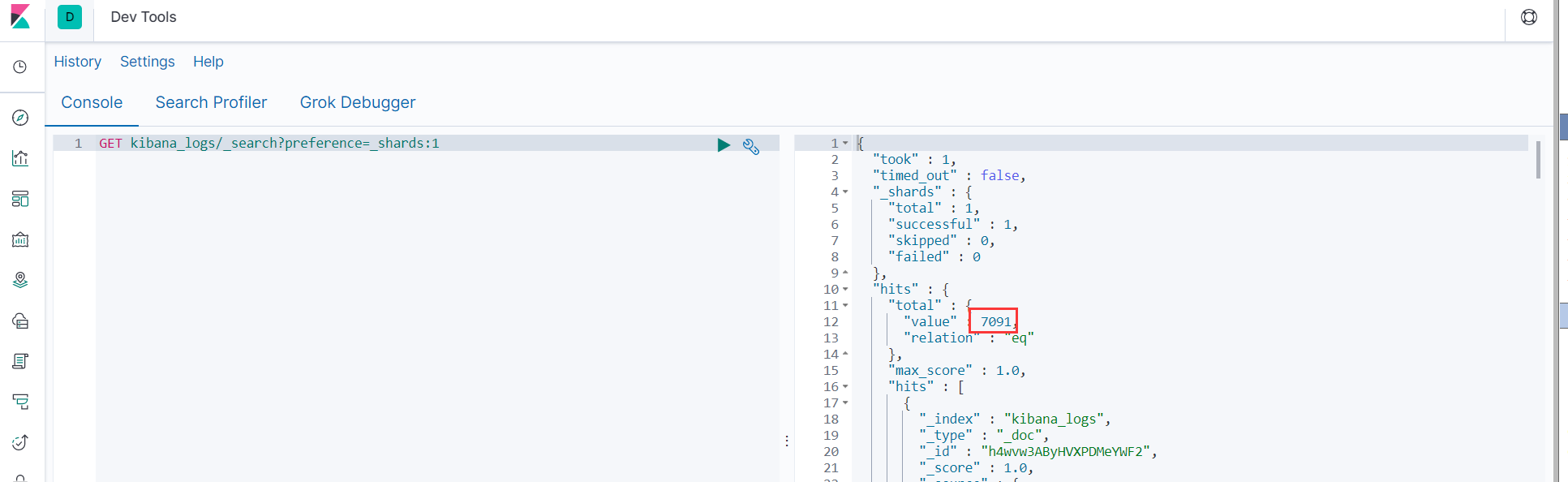
- 分片数据移动例子
从上图中可以看出索引kibana_logs的分片0在slave2上,分片1在master上,现在要将分片1的数据全部移动到slave1上。
POST _cluster/reroute
{
"commands": [
{
"move": {
"index": "kibana_logs",
"shard": 1,
"from_node": "master",
"to_node": "slave1"
}
}
]
}
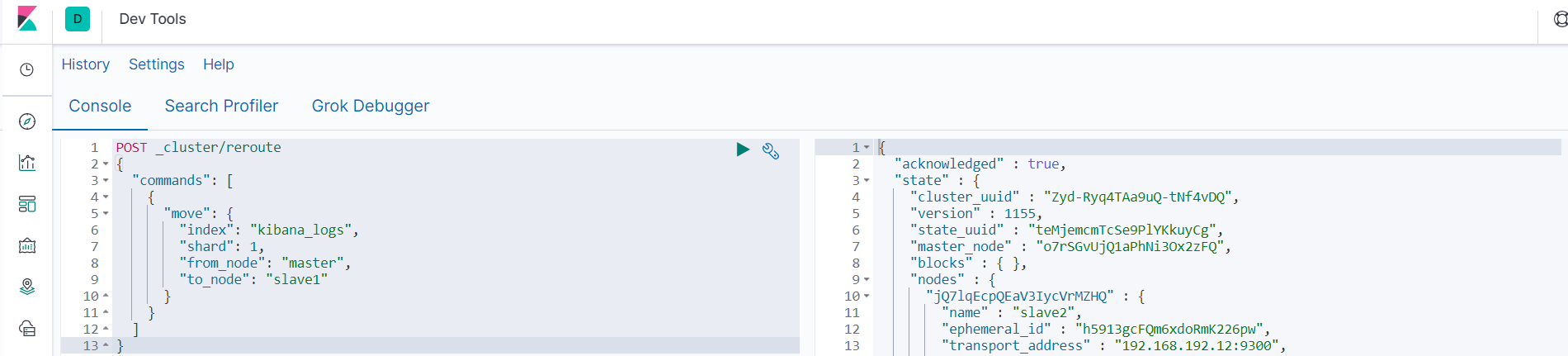
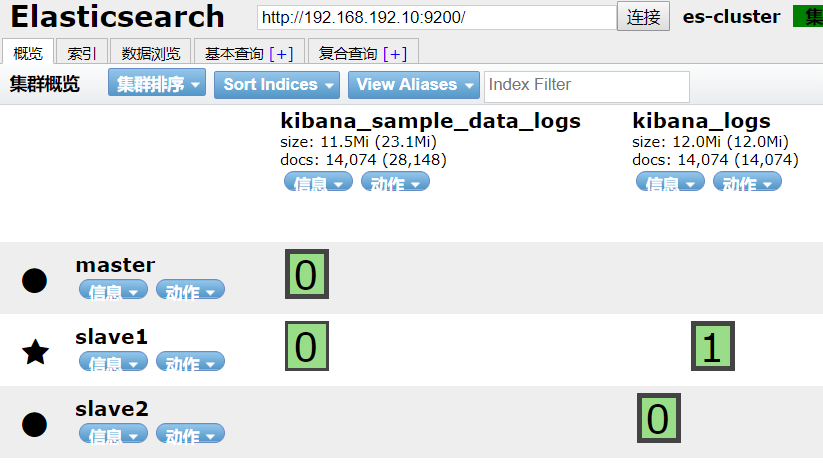
7.2.2 分片和副本设计
- 索引设置多少分片?
Shard 大小官方推荐值为 20-40GB, 具体原理呢?Elasticsearch 员工 Medcl 曾经讨论如下:
Lucene 底层没有这个大小的限制,20-40GB 的这个区间范围本身就比较大,经验值有时候就是拍脑袋,不一定都好使。
Elasticsearch 对数据的隔离和迁移是以分片为单位进行的,分片太大,会加大迁移成本。
一个分片就是一个 Lucene 的库,一个 Lucene 目录里面包含很多 Segment,每个 Segment 有文档数的上限,Segment 内部的文档 ID 目前使用的是 Java 的整型,也就是 2 的 31 次方,所以能够表示的总的文档数为Integer.MAXVALUE - 128 = 2^31 - 128 = 2147483647 - 1 = 2,147,483,519,也就是21.4亿条。
同样,如果你不 forcemerge 成一个 Segment,单个 shard 的文档数能超过这个数。
单个 Lucene 越大,索引会越大,查询的操作成本自然要越高,IO 压力越大,自然会影响查询体验。
具体一个分片多少数据合适,还是需要结合实际的业务数据和实际的查询来进行测试以进行评估
-
综合实战+网上各种经验分享,梳理如下:
-
第一步:预估一下数据量的规模。一共要存储多久的数据,每天新增多少数据?两者的乘积就是总数据量。
-
第二步:预估分多少个索引存储。索引的划分可以根据业务需要。
-
第三步:考虑和衡量可扩展性,预估需要搭建几台机器的集群。存储主要看磁盘空间,假设每台机器2TB,可用:2TB*0.85(磁盘实际利用率)0.85(ES 警戒水位线)。
-
第四步:单分片的大小建议最大设置为 30GB。此处如果是增量索引,可以结合大索引的设计部分的实现一起规划。
-
-
前三步能得出一个索引的大小。分片数考虑维度:
- 1)分片数 = 索引大小/分片大小经验值 30GB 。
- 2)分片数建议和节点数一致。
-
设计的时候1)、2)两者权衡考虑+rollover 动态更新索引结合。
-
每个 shard 大小是按照经验值 30G 到 50G,因为在这个范围内查询和写入性能较好。
- 索引设置多少副本?
- 对于集群数据节点 >=2 的场景:建议副本至少设置为 1。
- 对于集群数据节点 >=3 的场景:建议副本至少设置为 2。
- 多副本带来的就是多落地磁盘,也就会慢。
- 单节点的机器设置了副本也不会生效的。
- 对于数据安全性要求非常高的业务场景,建议做好:增强备份(结合 ES 官方备份方案)。
8 JAVA API
项目地址:https://github.com/70416450/Bigdata-Util
修改配置文件中的信息即可使用,看效果吧。

您的资助是我最大的动力!
金额随意,欢迎来赏!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号