redis
1 单机安装
1)安装redis编译的c环境,yum install gcc tcl

2)将redis-2.8.3.tar.gz上传到Linux系统中
3)解压tar -zxvf redis-2.8.3.tar.gz
4)进入redis-2.8.3目录,编译安装make && make PREFIX=/usr/local/src/redis install
5)配置后端启动:拷贝redis-2.8.3中的redis.conf到安装目录redis中
cp /usr/local/src/redis-2.8.3/redis.conf /usr/local/src/redis/bin/
然后修改这个文件vim /usr/local/src/redis/bin/redis.conf
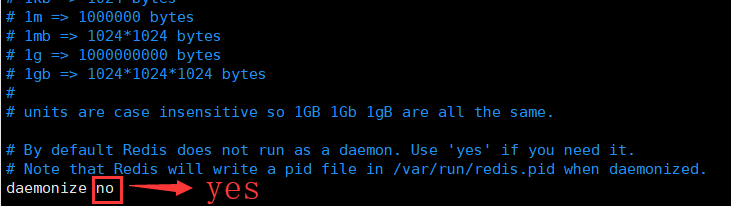
daemonize no 将no改成yes
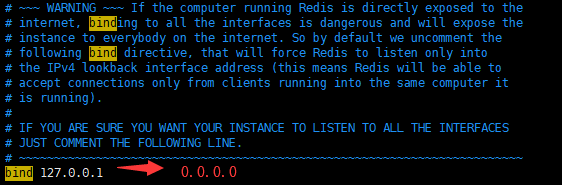
bind端口改成0.0.0.0 方便其他机器访问
配置日志文件输出(需要建立文件)

指定redis本地数据文件存放目录(默认是在哪里启动redis服务就会在哪里生成)

6)配置环境变量vim ~/.bashrc
#redis
REDIS_HOME=/usr/local/src/redis
PATH=$PATH:$REDIS_HOME/bin
更新环境变量source ~/.bashrc
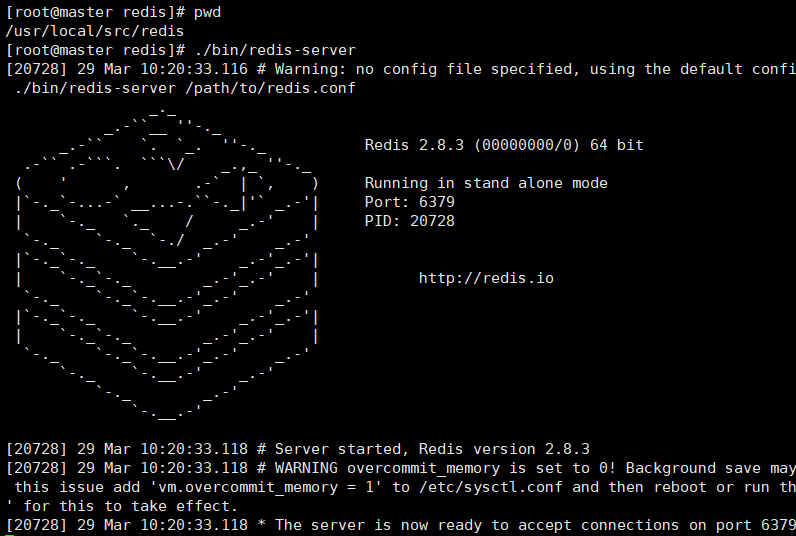
7-1)启动方式一:./bin/redis-server
7-2)启动方式二:./redis-server redis.conf

8)其他命令
#互交命令
redis-cli
#进入互交后退出命令
exit
#停止redis服务命令
redis-cli shutdown

2 集群安装(3.0以后版本)
1)解压tar -zxvf redis-3.0.4.tar.gz
2)安装ruby脚本yum -y install ruby rubygems

3)安装槽位脚本gem install --local redis-3.3.0.gem
4)编译安装redis(进入解压后目录)make && make PREFIX=/usr/local/src/redis/ install
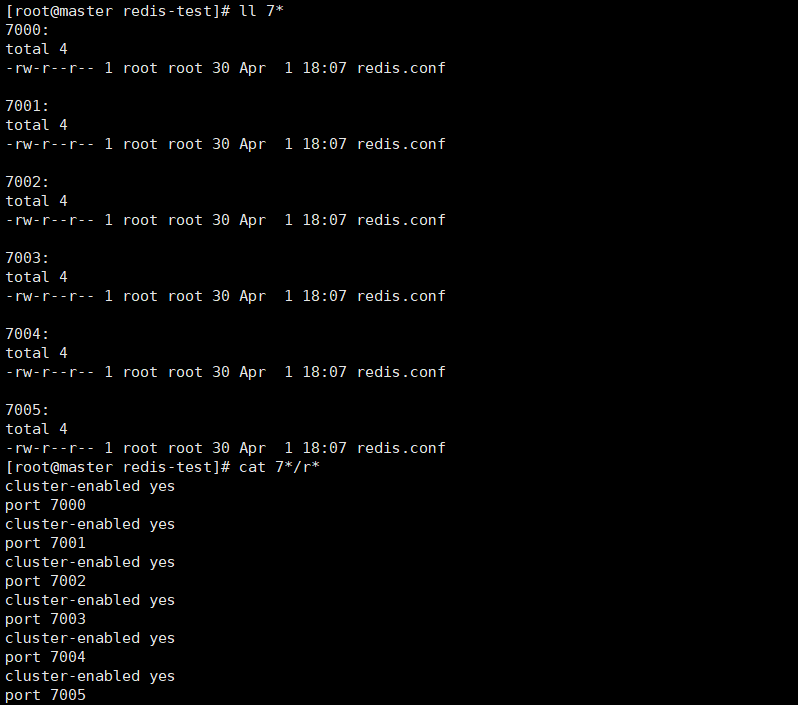
5)分别进入每个文件。启动redis
6)进入源码包redis-3.0.4/src目录找到

7)执行脚本./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
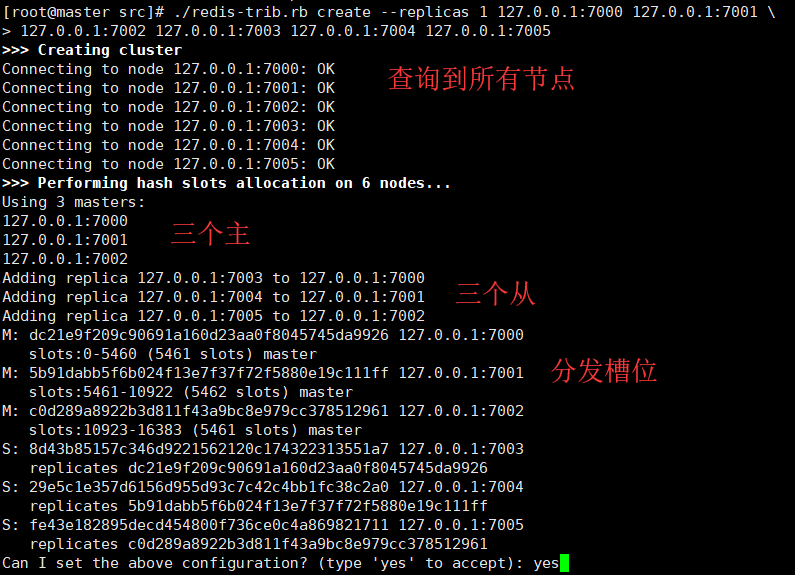
8)使用客户端互交测试





9)主备切换
切断7000

3 命令行操作
3.1 Redis数据结构
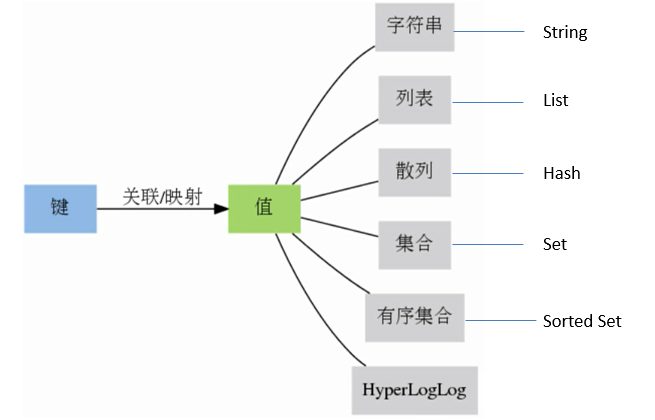
- Redis key 值是二进制安全的,这意味着可以用任何二进制序列作为key值,从形如”foo”的简单字符串到一个JPEG文件的内容都可以。空字符串也是有效key值
- Key取值原则
- 键值不需要太长,最好不超过1024字节,消耗内存。
- 键值不宜过短,可读性较差
- 最好有统一的命名规则
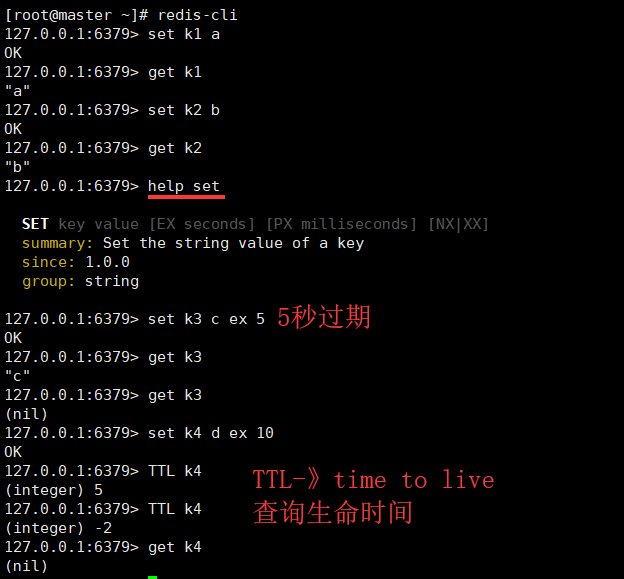
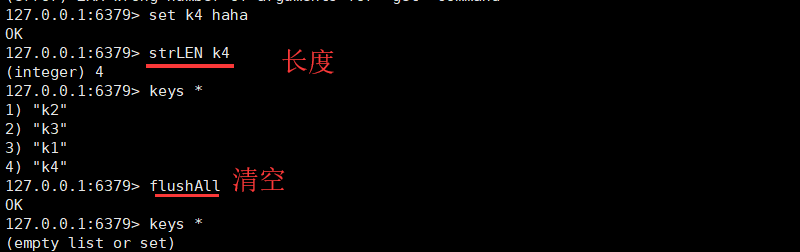
3.2 String字符串
- 字符串是一种最基本的Redis值类型。Redis字符串是二进制安全的,这意味着一个Redis字符串能包含任意类型的数据
- 例如: 一张JPEG格式的图片或者一个序列化的Ruby对象
- 一个字符串类型的值最多能存储512M字节的内容
- key的表征一直是字符串,变的是value
- key : string
- value: string

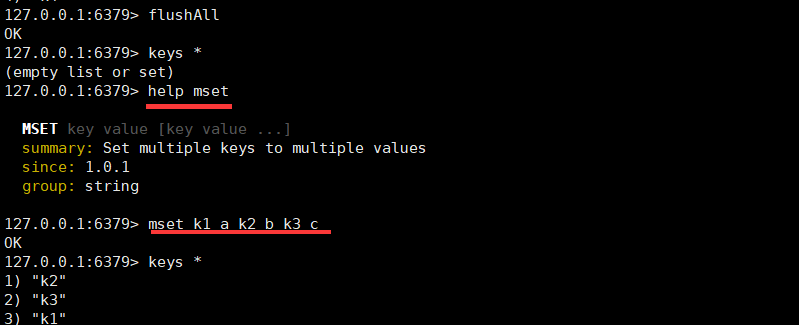







3.3 list列表
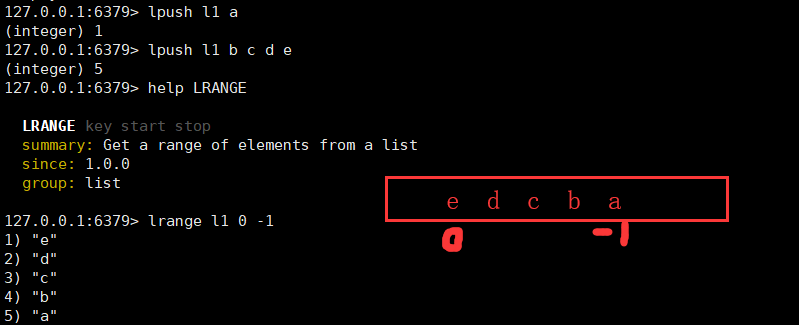
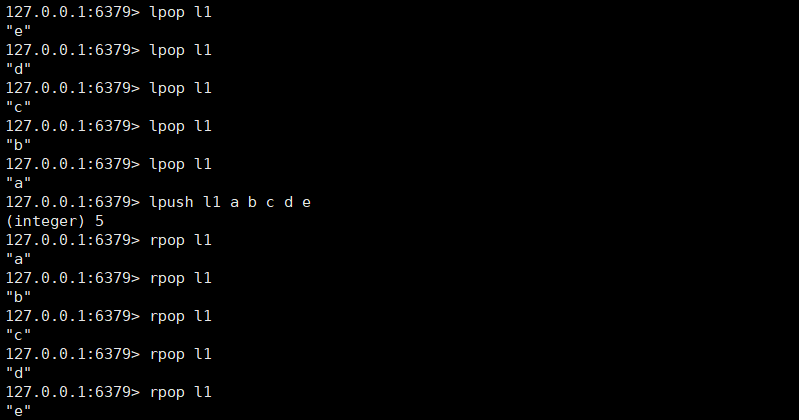


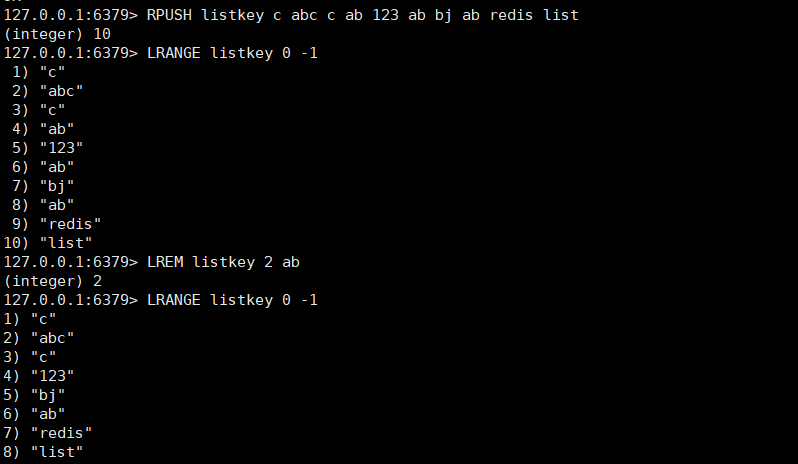
从列表头部开始删除值等于value的元素count次,LIST 可以重复出现
LREM key count value
count > 0 : 从表头开始向表尾搜索,移除与 value 相等的元素,数量为 count
count < 0 : 从表尾开始向表头搜索,移除与 value 相等的元素,数量为 count 的绝对值
count = 0 : 移除表中所有与 value 相等的值
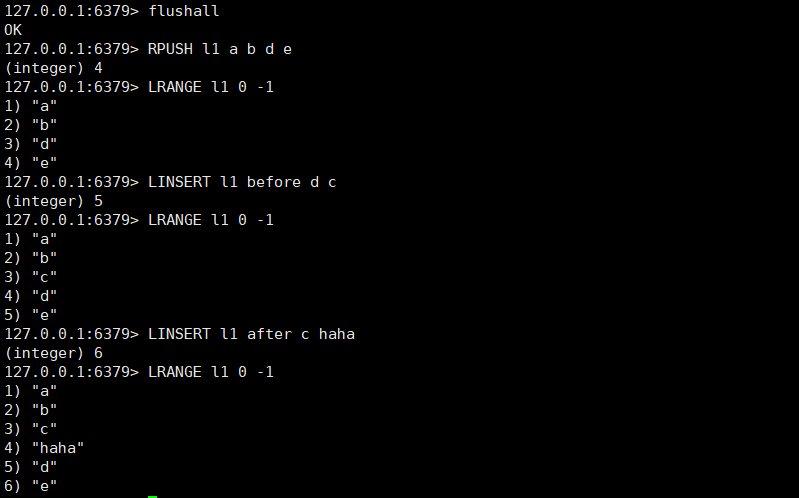
去除指定范围 外 元素
LTRIM key start stop

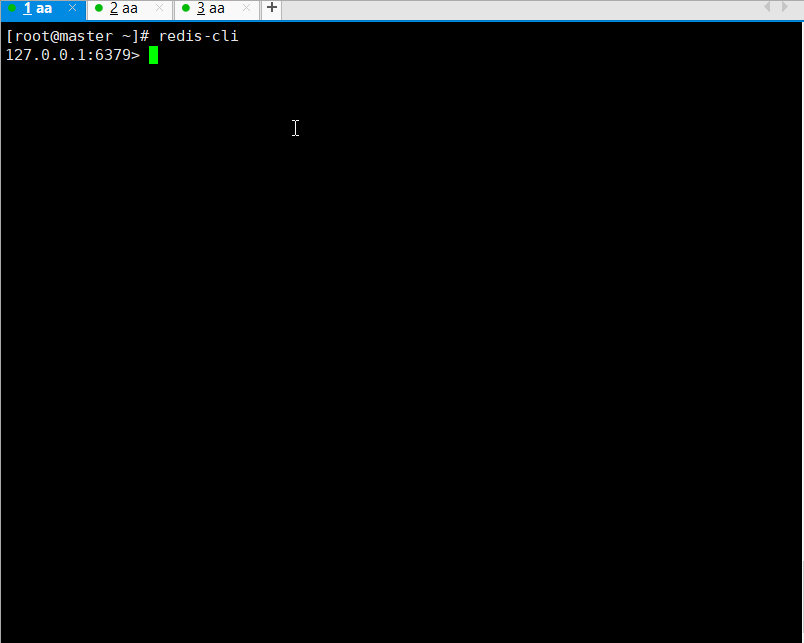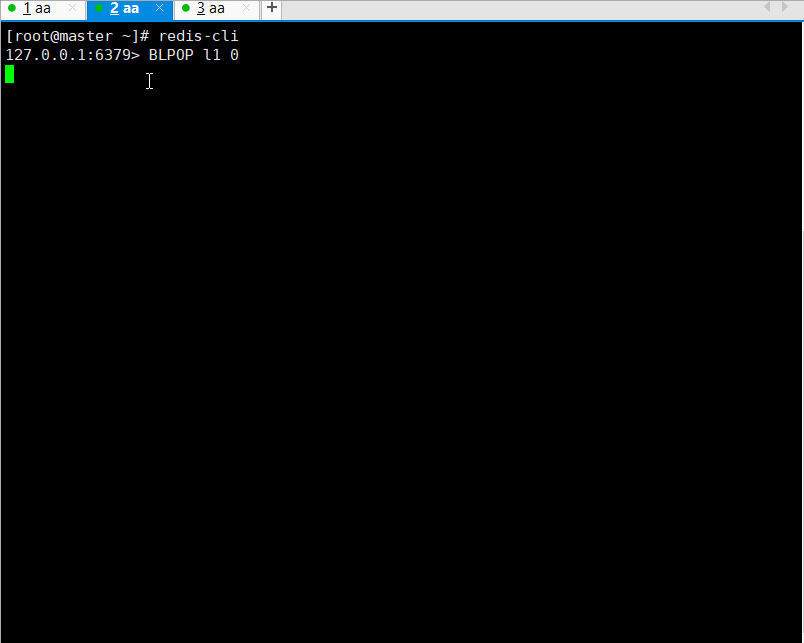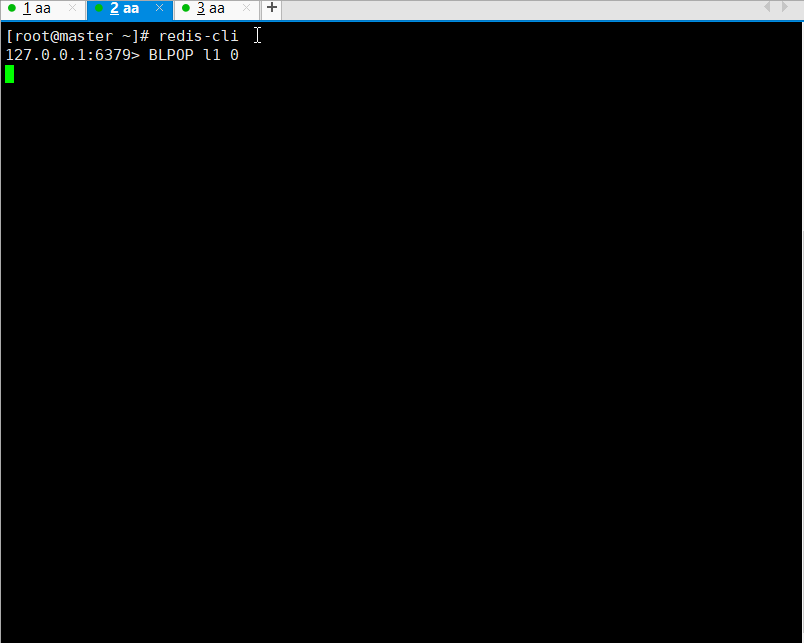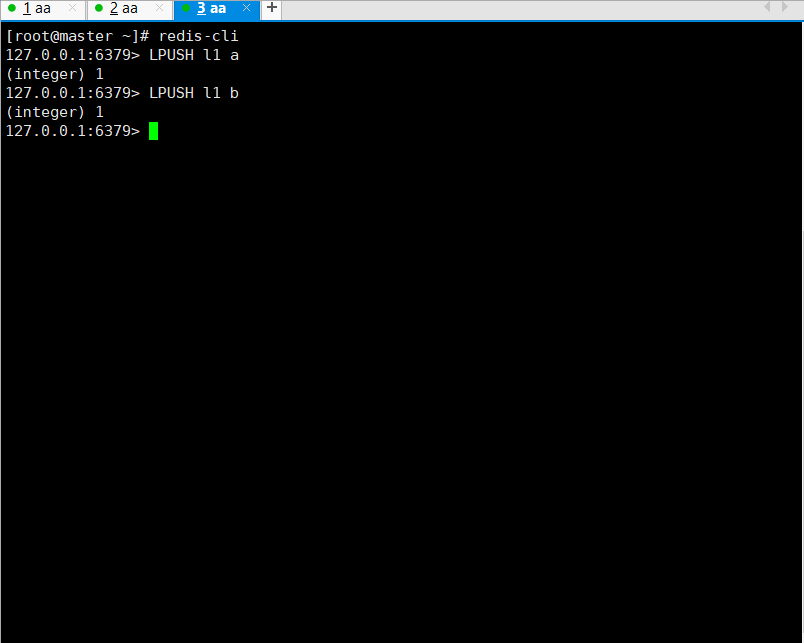
阻塞
如果弹出的列表不存在或者为空,就会阻塞
超时时间设置为0,就是永久阻塞,直到有数据可以弹出
如果多个客户端阻塞在同一个列表上,使用First In First Service原则,先到先服务
左右或者头尾阻塞弹出元素
BLPOP key [key ...] timeout
BRPOP key [key ...] timeout
从一个列表尾部阻塞弹出元素压入到另一个列表的头部
BRPOPLPUSH source destination timeout
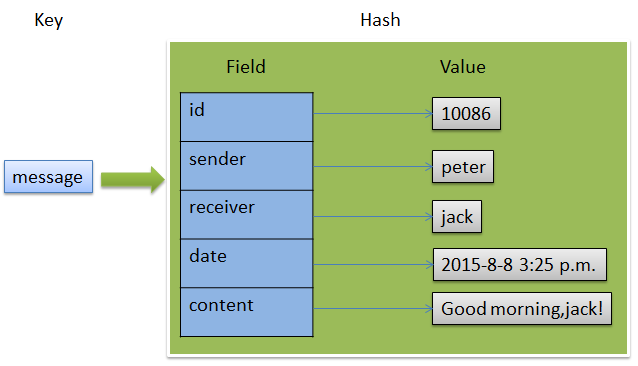
3.4 Hash 散列
由field和关联的value组成的map键值对
field和value是字符串类型
一个hash中最多包含2^32-1键值对
- 设置单个字段
- HSET key field value
- HSETNX key field value(key的filed不存在的情况下执行,key不存在直接创建)
- 设置多个字段
- HMSET key field value [field value ...]
- 返回字段个数
- HLEN key
- 判断字段是否存在
- HEXISTS key field
- key或者field不存在,返回0
- 返回字段值
- HGET key field
- 返回多个字段值
- HMGET key field [field ...]
- 返回所有的键值对
- HGETALL key
- 返回所有字段名
- HKEYS key
- 返回所有值
- HVALS key
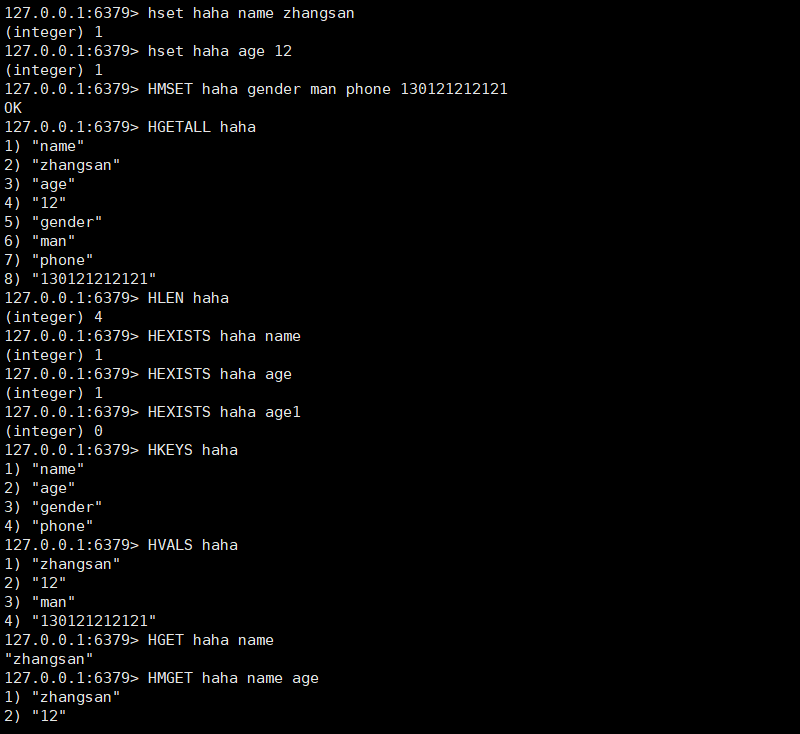
- HVALS key
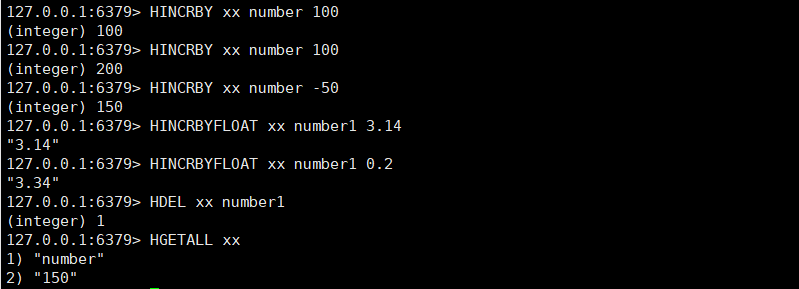
- 在字段对应的值上进行整数的增量计算
- HINCRBY key field increment
- 在字段对应的值上进行浮点数的增量计算
- HINCRBYFLOAT key field increment
- 删除指定的字段
- HDEL key field [field ...]
- HDEL key field [field ...]
3.5 Set集合
无序的、去重的
元素是字符串类型
最多包含2^32-1元素
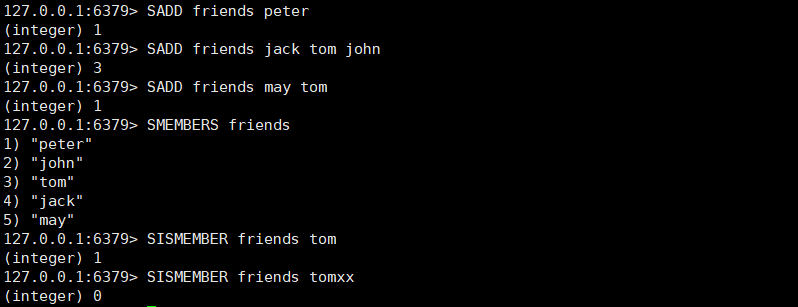
- 增加一个或多个元素
- SADD key member [member ...]
- 如果元素已经存在,则自动忽略
- 返回集合包含的所有元素
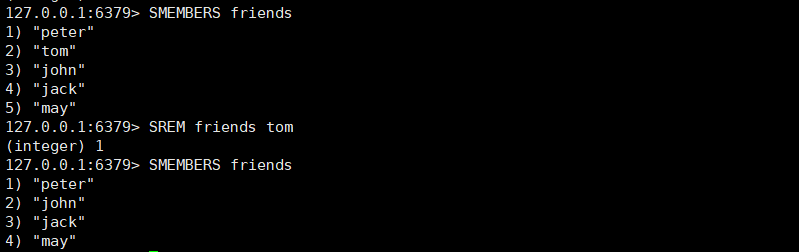
- SMEMBERS key
- 如果集合元素过多,例如百万个,需要遍历,可能会造成服务器阻塞,生产环境应避免使用
- 检查给定元素是否存在于集合中
- SISMEMBER key member
- SISMEMBER key member
- 移除一个或者多个元素
- SREM key member [member ...]
- 元素不存在,自动忽略
- 随机返回集合中指定个数的
- SRANDMEMBER key [count]
- 如果 count 为正数,且小于集合基数,那么命令返回一个包含 count 个元素的数组,数组中的元素各不相同。如果 count 大于等于集合基数,那么返回整个集合 最多返回整个集合 count>=0
- 如果 count 为负数,那么命令返回一个数组,数组中的元素可能会重复出现多次,而数组的长度为 count 的绝对值 count < 0 长度为count绝对值,元素可能重复
- 如果 count 为 0,返回空
- 如果 count 不指定,随机返回一个元素

- 返回集合中元素的个数
- SCARD key
- 键的结果会保存信息,集合长度就记录在里面,所以不需要遍历
- 随机从集合中移除并返回这个被移除的元素
- SPOP key
- 把元素从源集合移动到目标集合
- SMOVE source destination member

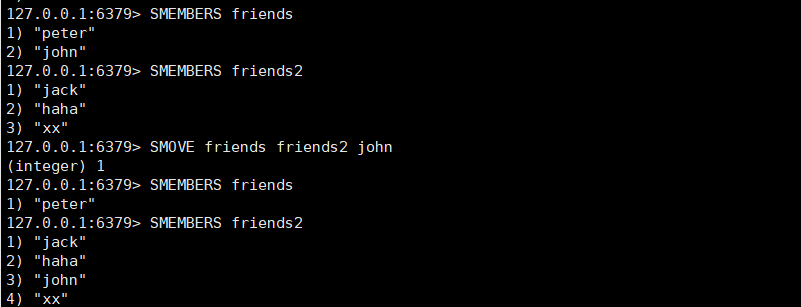
- SMOVE source destination member
- 差集
- SDIFF key [key ...],从第一个key的集合中去除其他集合和自己的交集部分
- SDIFFSTORE destination key [key ...],将差集结果存储在目标key中
- 交集
- SINTER key [key ...],取所有集合交集部分
- SINTERSTORE destination key [key ...],将交集结果存储在目标key中
- 并集
- SUNION key [key ...],取所有集合并集
- SUNIONSTORE destination key [key ...],将并集结果存储在目标key中

3.6 SortedSet有序集合
类似Set集合
有序的、去重的
元素是字符串类型
每一个元素都关联着一个浮点数分值(Score),并按照分值从小到大的顺序排列集合中的元素。分值可以相同
最多包含2^32-1元素

- 增加一个或多个元素
- ZADD key score member [score member ...]
- 如果元素已经存在,则使用新的score
- 移除一个或者多个元素
- ZREM key member [member ...]
- 元素不存在,自动忽略
- 显示分值
- ZSCORE key member
- 增加或者减少分值
- ZINCRBY key increment member
- increment为负数就是减少
- 返回元素的排名(索引)
- ZRANK key member
- 返回元素的逆序排名
- ZREVRANK key member
- 返回指定索引区间元素
- ZRANGE key start stop [WITHSCORES]
- 如果score相同,则按照字典序lexicographical order 排列
- 默认按照score从小到大,如果需要score从大到小排列,使用ZREVRANGE
- 返回指定索引区间元素
- ZREVRANGE key start stop [WITHSCORES]
- 如果score相同,则按照字典序lexicographical order 的 逆序 排列
- 默认按照score从大到小,如果需要score从小到大排列,使用ZRANGE

- 返回指定分值区间元素
- ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
- 返回score默认属于[min,max]之间,元素按照score升序排列,score相同字典序
- LIMIT中offset代表跳过多少个元素,count是返回几个。类似于Mysql
- 使用小括号,修改区间为开区间,例如(5、(10、5)
- -inf和+inf表示负无穷和正无穷
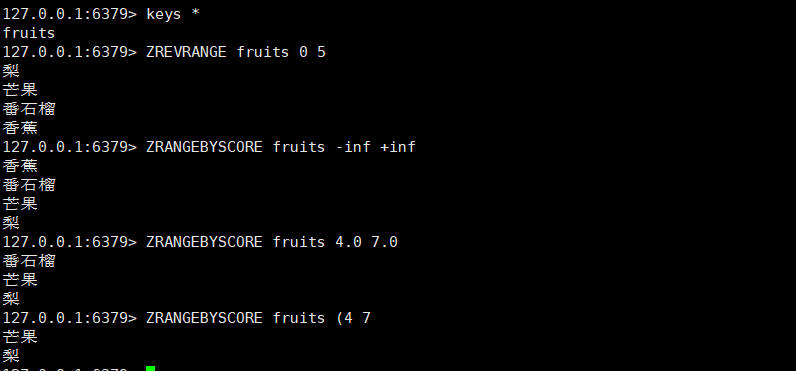
- 返回指定分值区间元素
- ZREVRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
- 返回score默认属于[min,max]之间,元素按照score降序排列,score相同字典降序
- LIMIT中offset代表跳过多少个元素,count是返回几个。类似于Mysql
- 使用小括号,修改区间为开区间,例如(5、(10、5)
- -inf和+inf表示负无穷和正无穷

- 移除指定排名范围的元素
- ZREMRANGEBYRANK key start stop
- 移除指定分值范围的元素
- ZREMRANGEBYSCORE key min max

- ZREMRANGEBYSCORE key min max
- 返回集合中元素个数
- ZCARD key

- ZCARD key
- 并集
- ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]
- numkeys指定key的数量,必须
- WEIGHTS选项,与前面设定的key对应,对应key中每一个score都要乘以这个权重
- AGGREGATE选项,指定并集结果的聚合方式
- SUM:将所有集合中某一个元素的score值之和作为结果集中该成员的score值
- MIN:将所有集合中某一个元素的score值中最小值作为结果集中该成员的score值
- MAX:将所有集合中某一个元素的score值中最大值作为结果集中该成员的score值

- 交集
- ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]
- numkeys指定key的数量,必须
- WEIGHTS选项,与前面设定的key对应,对应key中每一个score都要乘以这个权重
- AGGREGATE选项,指定并集结果的聚合方式
- SUM:将所有集合中某一个元素的score值之和作为结果集中该成员的score值
- MIN:将所有集合中某一个元素的score值中最小值作为结果集中该成员的score值
- MAX:将所有集合中某一个元素的score值中最大值作为结果集中该成员的score值

4 RDB
- 什么是持久化
- 将数据从掉电易失的内存存放到能够永久存储的设备上
- Redis为什么需要持久化
- 基于内存的
- 缓存服务器,需要吗?
- 内存数据库,需要吗?
- 消息队列,需要吗?
- Redis持久化方式
- RDB(Redis DB) hdfs: fsimage
- AOF(AppendOnlyFile) hdfs : edit logs 默认关闭的
4.1 Redis持久化-RDB
- RDB
- 在默认情况下,Redis 将数据库快照保存在名字为 dump.rdb的二进制文件中
- 方式:产生一个RDB:
- 1,阻塞方式:
- 客户端中执行save命令
- 2,非阻塞方式:(复杂度高?)
- bgsave
- 策略
- 自动:按照配置文件中的条件满足就执行BGSAVE
- save 60 1000,Redis要满足在60秒内至少有1000个键被改动,会自动保存一次
- 手动:客户端发起SAVE、BGSAVE命令
- SAVE命令
- redis > save
- 阻塞Redis服务,无法响应客户端请求
- 创建新的dump.rdb替代旧文件(覆盖 需要手动写脚本扫描目录)
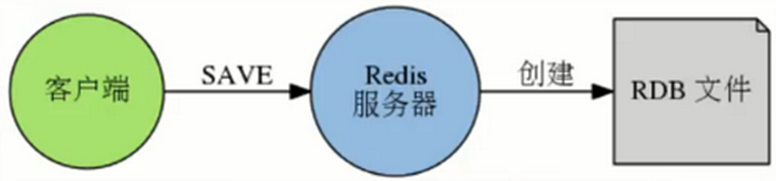
- BGSAVE命令
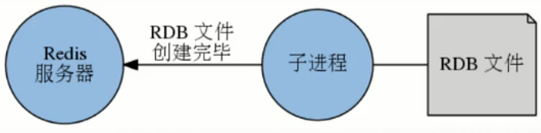
- redis > bgsave
- 非阻塞,Redis服务正常接收处理客户端请求
- Redis会fork()一个新的子进程来创建RDB文件,子进程处理完后会向父进程发送一个信号,通知它处理完毕
- 父进程用新的dump.rdb替代旧文件

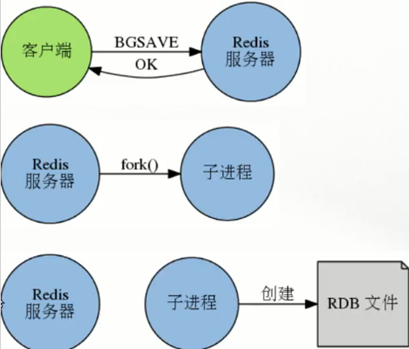
- SAVE 和 BGSAVE 命令
- SAVE不用创建新的进程,速度略快
- BGSAVE需要创建子进程,消耗额外的内存
- SAVE适合停机维护,服务低谷时段
- BGSAVE适合线上执行
- 优点
- 完全备份,不同时间的数据集备份可以做到多版本恢复(会覆盖 手动写脚本扫描目录拿走不同阶段备份,异地备份)
- 紧凑的单一文件,方便网络传输,适合灾难恢复
- 恢复大数据集速度较AOF快
- 缺点
- 会丢失最近写入、修改的而未能持久化的数据
- fork过程非常耗时,会造成毫秒级不能响应客户端请求
自动执行
本质上就是BGSAVE
默认配置
save 900 1
save 300 10
save 60 10000
dbfilename dump.rdb
dir /var/lib/redis/6379
只要上面三个条件满足一个,就自动执行备份。
创建RDB文件之后,时间计数器和次数计数器会清零。所以多个条件的效果不是叠加的
- 生产环境
- 创建一个定时任务cron job,每小时或者每天将dump.rdb复制到指定目录
- 确保备份文件名称带有日期时间信息,便于管理和还原对应的时间点的快照版本
- 定时任务删除过期的备份
- 如果有必要,跨物理主机、跨机架、异地备份
4.2 Redis持久化-AOF
- AOF
- Append only file,采用追加的方式保存
- 默认文件appendonly.aof
- 记录所有的写操作命令,在服务启动的时候使用这些命令就可以还原数据库
- 调整AOF持久化策略,可以在服务出现故障时,不丢失任何数据,也可以丢失一秒的数据。相对于RDB损失小得多



- AOF写入机制
- AOF方式不能保证绝对不丢失数据。默认关闭,一旦开启,则rdb不作为恢复的选择。
- 目前常见的操作系统中,执行系统调用write函数,将一些内容写入到某个文件里面时,为了提高效率,系统通常不会直接将内容写入硬盘里面,而是先将内容放入一个内存缓冲区(buffer)里面,等到缓冲区被填满,或者用户执行fsync调用和fdatasync调用时才将储存在缓冲区里的内容真正的写入到硬盘里,未写入磁盘之前,数据可能会丢失
- 写入磁盘的策略
- appendfsync选项,这个选项的值可以是always、everysec或者no
- Always:服务器每写入一个命令,就调用一次fdatasync,将缓冲区里面的命令写入到硬盘。这种模式下,服务器出现故障,也不会丢失任何已经成功执行的命令数据
- Everysec(默认):服务器每一秒重调用一次fdatasync,将缓冲区里面的命令写入到硬盘。这种模式下,服务器出现故障,最多只丢失一秒钟内的执行的命令数据
- No:服务器不主动调用fdatasync,由操作系统决定何时将缓冲区里面的命令写入到硬盘。这种模式下,服务器遭遇意外停机时,丢失命令的数量是不确定的
- 运行速度:always的速度慢,everysec和no都很快
- AOF重写机制
- AOF文件过大
- 合并重复的操作,AOF会使用尽可能少的命令来记录
- 重写过程
- fork一个子进程负责重写AOF文件
- 子进程会创建一个临时文件写入AOF信息
- 父进程会开辟一个内存缓冲区接收新的写命令
- 子进程重写完成后,父进程会获得一个信号,将父进程接收到的新的写操作由子进程写入到临时文件中
- 新文件替代旧文件
- 注:如果写入操作的时候出现故障导致命令写半截,可以使用redis-check-aof工具修复

- AOF重写触发的条件
- 手动:客户端向服务器发送BGREWRITEAOF命令
- 自动:配置文件中的选项,自动执行BGREWRITEAOF命令
- auto-aof-rewrite-min-size
,触发AOF重写所需的最小体积:只要在AOF文件的体积大于等于size时,才会考虑是否需要进行AOF重写,这个选项用于避免对体积过小的AOF文件进行重写 - auto-aof-rewrite-percentage
,指定触发重写所需的AOF文件体积百分比:当AOF文件的体积大于auto-aof-rewrite-min-size指定的体积,并且超过上一次重写之后的AOF文件体积的percent %时,就会触发AOF重写。(如果服务器刚刚启动不久,还没有进行过AOF重写,那么使用服务器启动时载入的AOF文件的体积来作为基准值)。将这个值设置为0表示关闭自动AOF重写
- auto-aof-rewrite-min-size
AOF重写配置项举例
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
appendonly no / yes
当AOF文件大于64MB时候,可以考虑重写AOF文件
只有当AOF文件的增量大于起始size的100%时(就是文件大小翻了一倍),启动重写
默认关闭,请开启
- 优点
- 写入机制,默认fysnc每秒执行,性能很好不阻塞服务,最多丢失一秒的数据
- 重写机制,优化AOF文件
- 如果误操作了(FLUSHALL等),只要AOF未被重写,停止服务移除AOF文件尾部FLUSHALL命令,重启Redis,可以将数据集恢复到 FLUSHALL 执行之前的状态 - 缺点
- 相同数据集,AOF文件体积较RDB大了很多
- 恢复数据库速度叫RDB慢(文本,命令重演)
5 Java操作

- 简单操作JedisTest.java
package com.tzy.jedis;
import org.junit.Test;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisTest {
//通过 java程序访问redis数据库
@Test
//获得单一的jedis对象操作数据库
public void test1(){
//获得会话(链接)对象
//ip是虚拟机的
Jedis jedis = new Jedis("192.168.246.130", 6379);
//获得数据
String username = jedis.get("username");
System.out.println(username);
//储存
jedis.set("addr", "四川");
System.out.println(jedis.get("addr"));
}
@Test
//通过jedis的poll获得jedis链接对象
public void test2(){
//创建池子配置
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxIdle(30);//最大闲置个数
poolConfig.setMinIdle(10);//最小闲置个数
poolConfig.setMaxTotal(50);//最大连接数
//创建一个jedis的连接池
JedisPool pool = new JedisPool(poolConfig, "192.168.246.130", 6379);
//从池子中获取redis的链接资源
Jedis jedis = pool.getResource();
jedis.set("xxx", "yyyy");//不能存对象,可以转成json字符串
System.out.println(jedis.get("xxx"));
//关闭资源
jedis.close();
pool.close();//真正的开发中不关
}
}
- 连接池解耦操作
redis.properties
redis.MaxIdle=30
redis.MinIdle=10
redis.MaxTotal=50
redis.url=192.168.246.130
redis.port=6379
- 简单封装的JedisPoolUtil.java
package com.tzy.jedis;
import java.io.IOException;
import java.io.InputStream;
import java.util.Properties;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisPoolUtil {
private static JedisPool pool = null;
static{
//加载配置资源
InputStream in = JedisPoolUtil.class.getClassLoader().getResourceAsStream("redis.properties");
Properties pro = new Properties();
try {
pro.load(in);
} catch (IOException e) {
e.printStackTrace();
}
//获得池子对象
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxIdle(Integer.parseInt(pro.get("redis.MaxIdle").toString()));//最大闲置个数
poolConfig.setMinIdle(Integer.parseInt(pro.get("redis.MinIdle").toString()));//最小闲置个数
poolConfig.setMaxTotal(Integer.parseInt(pro.get("redis.MaxTotal").toString()));//最大连接数
pool = new JedisPool(poolConfig, pro.get("redis.url").toString(),Integer.parseInt(pro.get("redis.port").toString()));
}
//获得jedis资源的方法
public static Jedis getJedis(){
return pool.getResource();
}
public static void main(String[] args) {
Jedis jedis = getJedis();
System.out.println(jedis.get("xxx"));
}
}

您的资助是我最大的动力!
金额随意,欢迎来赏!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号