Python基础(二)
1:模块
-
一般我们会使用包来管理模块
-
自己创建模块时要注意命名,不能和Python自带的模块名称冲突。例如,系统自带了sys模块,自己的模块就不可命名为sys.py,否则将无法导入系统自带的sys模块。

-
使用模块
-
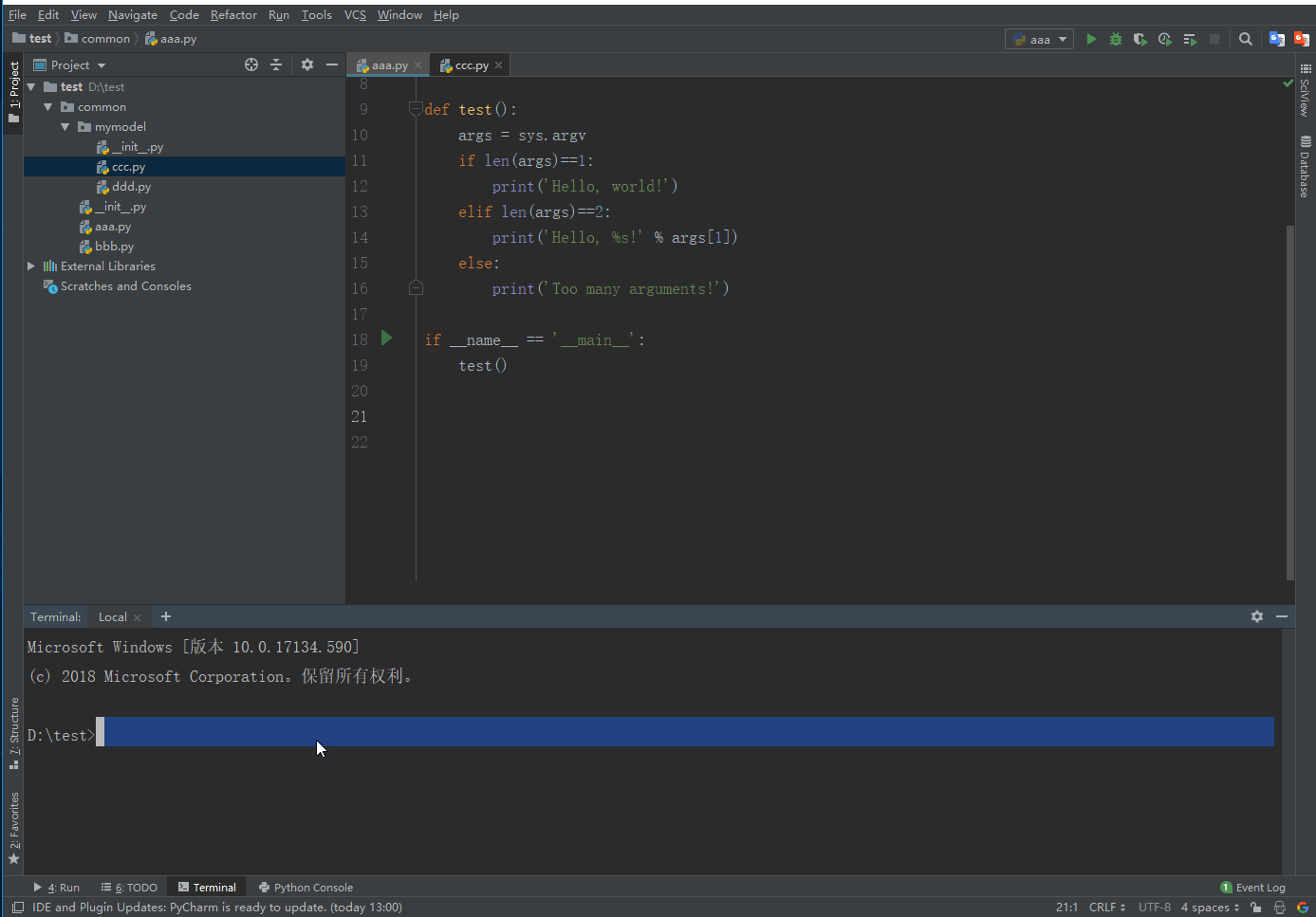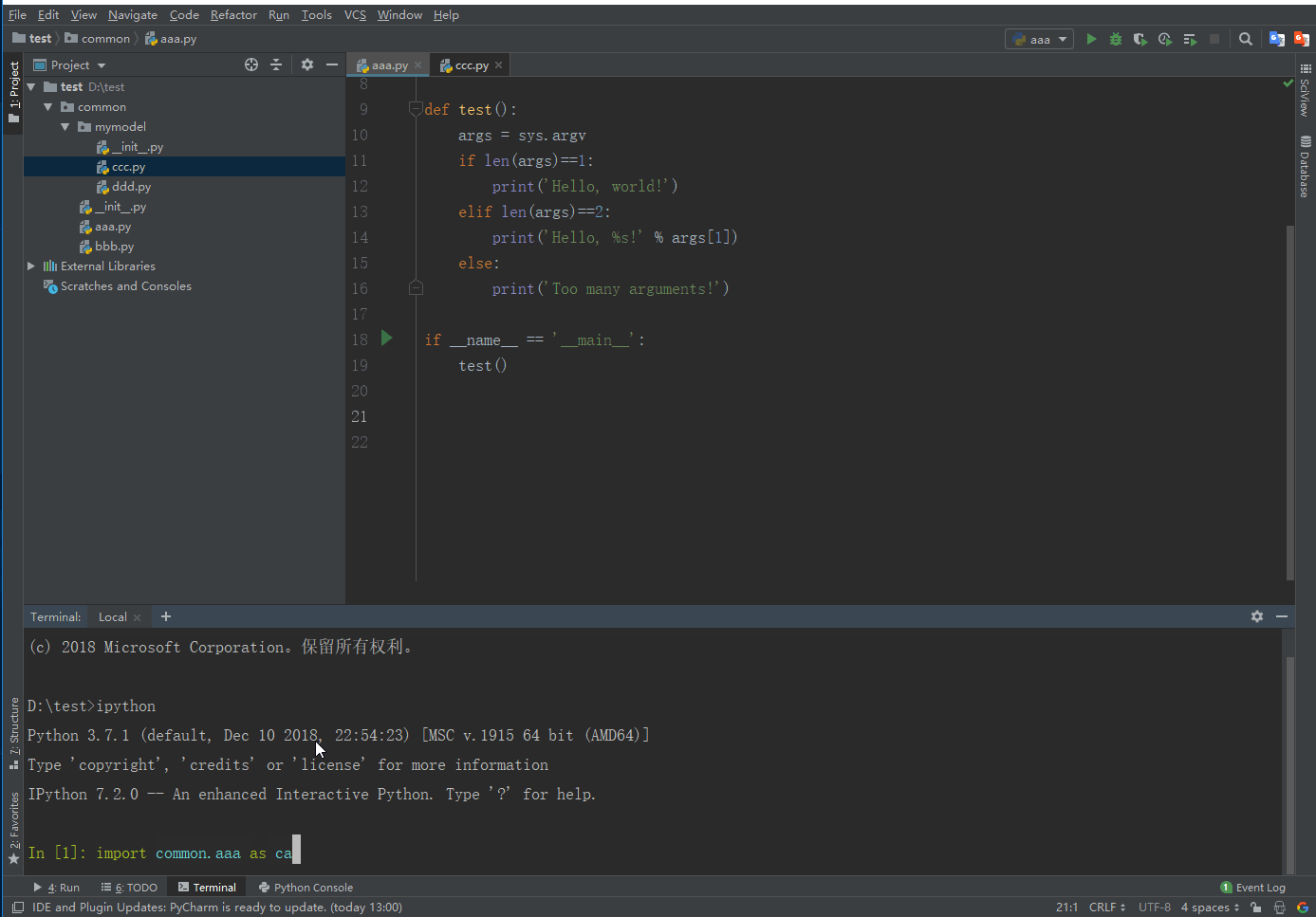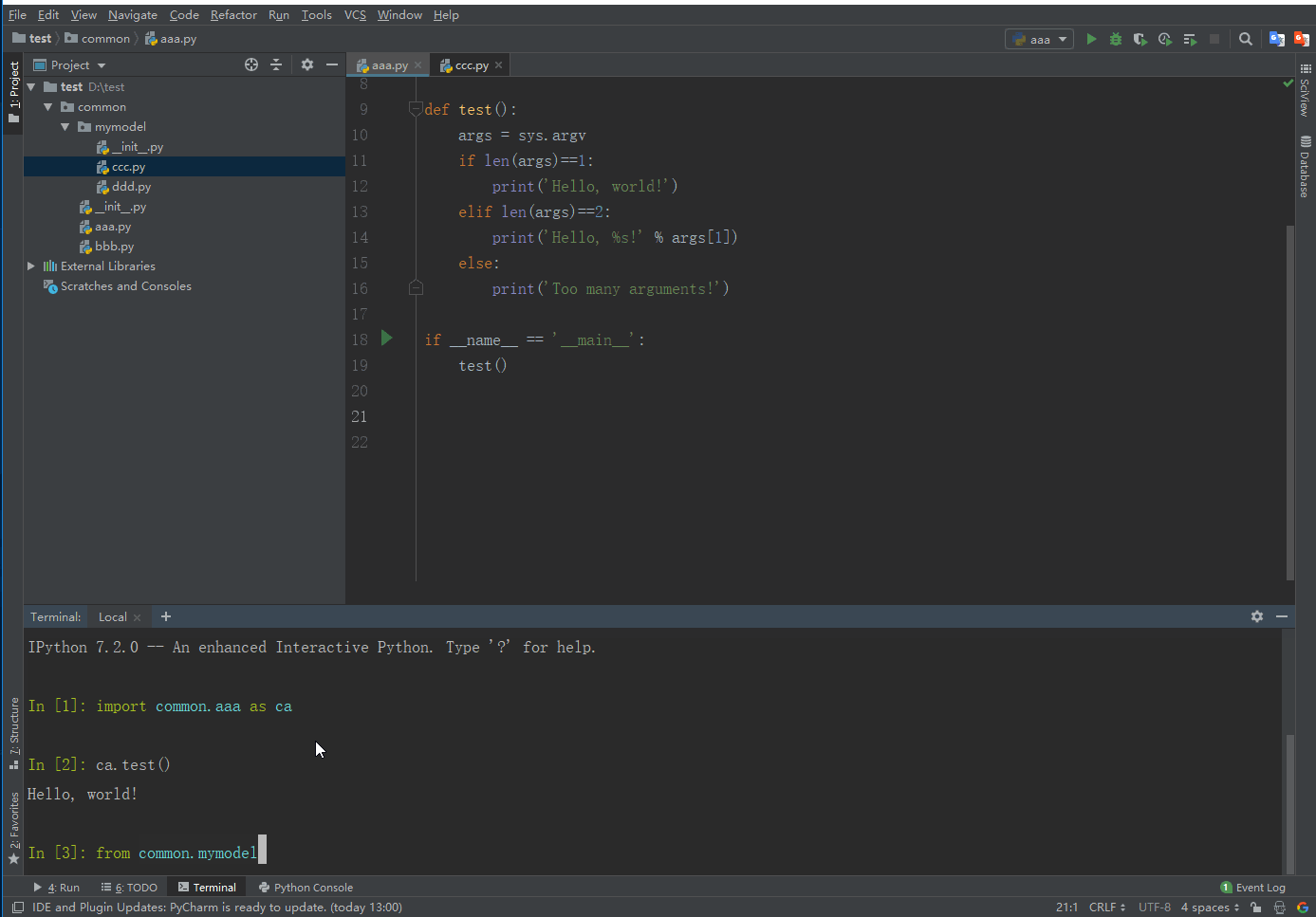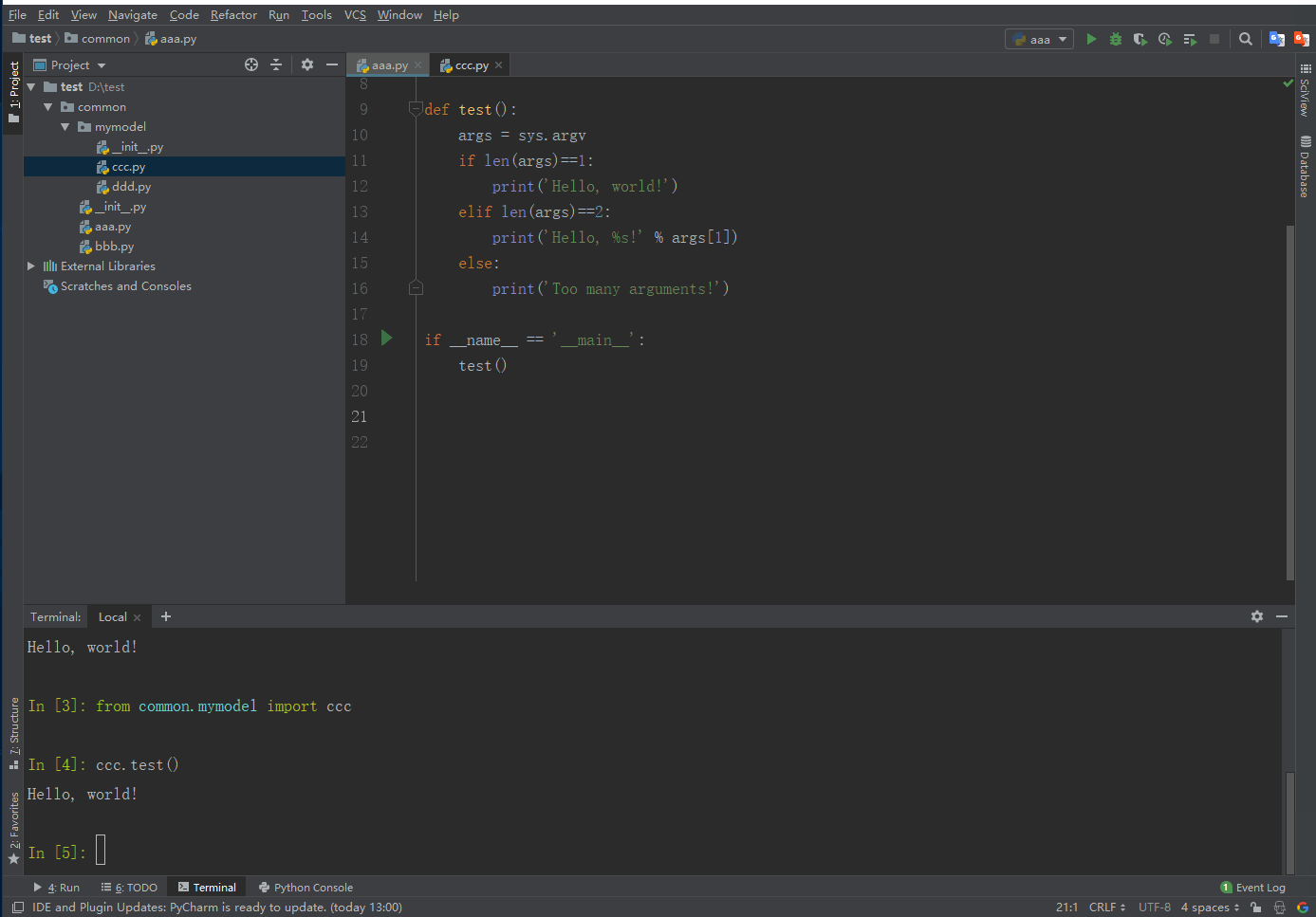
在aaa.py和ccc.py中添加如下代码
-

-
使用
import sys导入sys模块后- 我们就有了变量
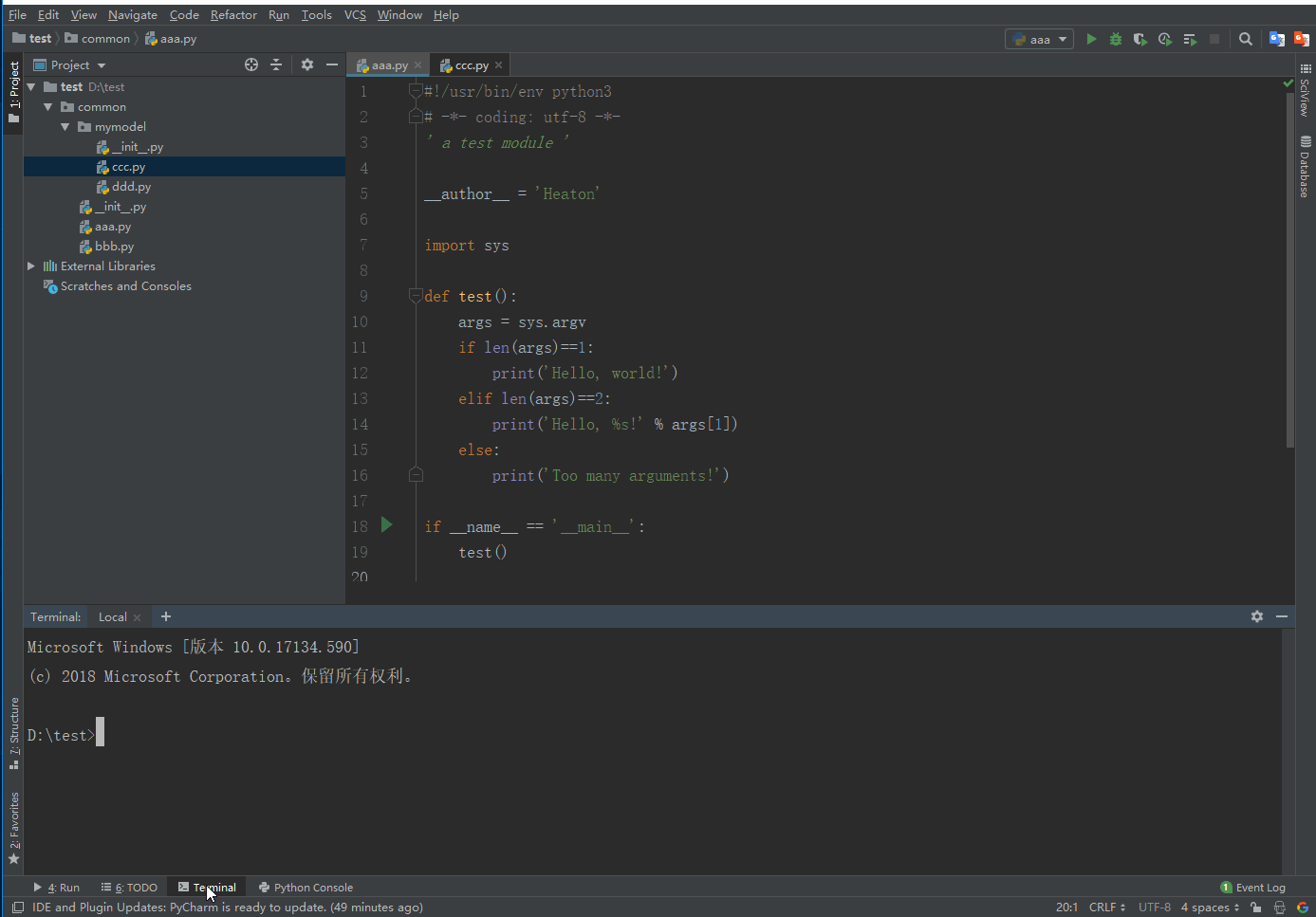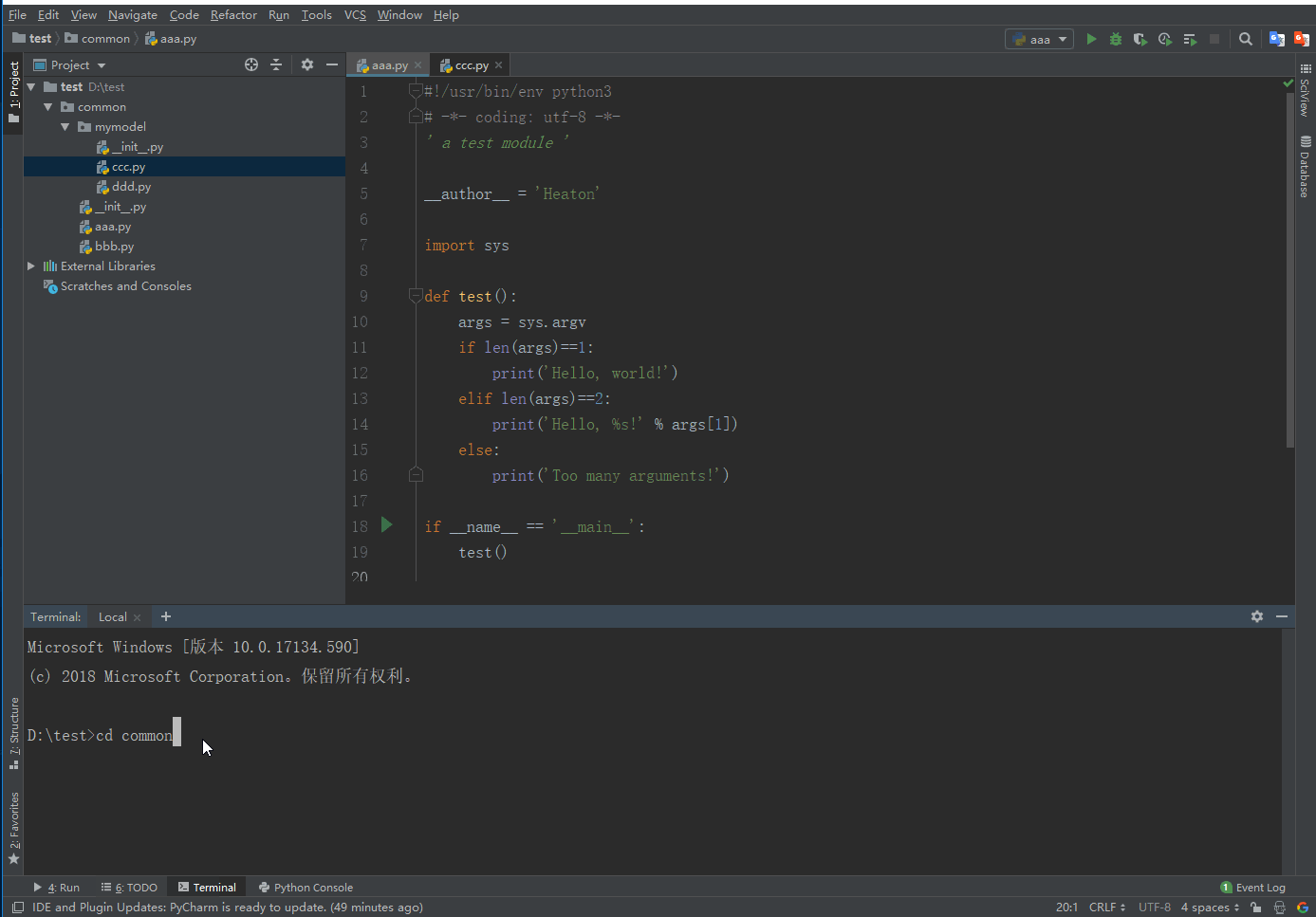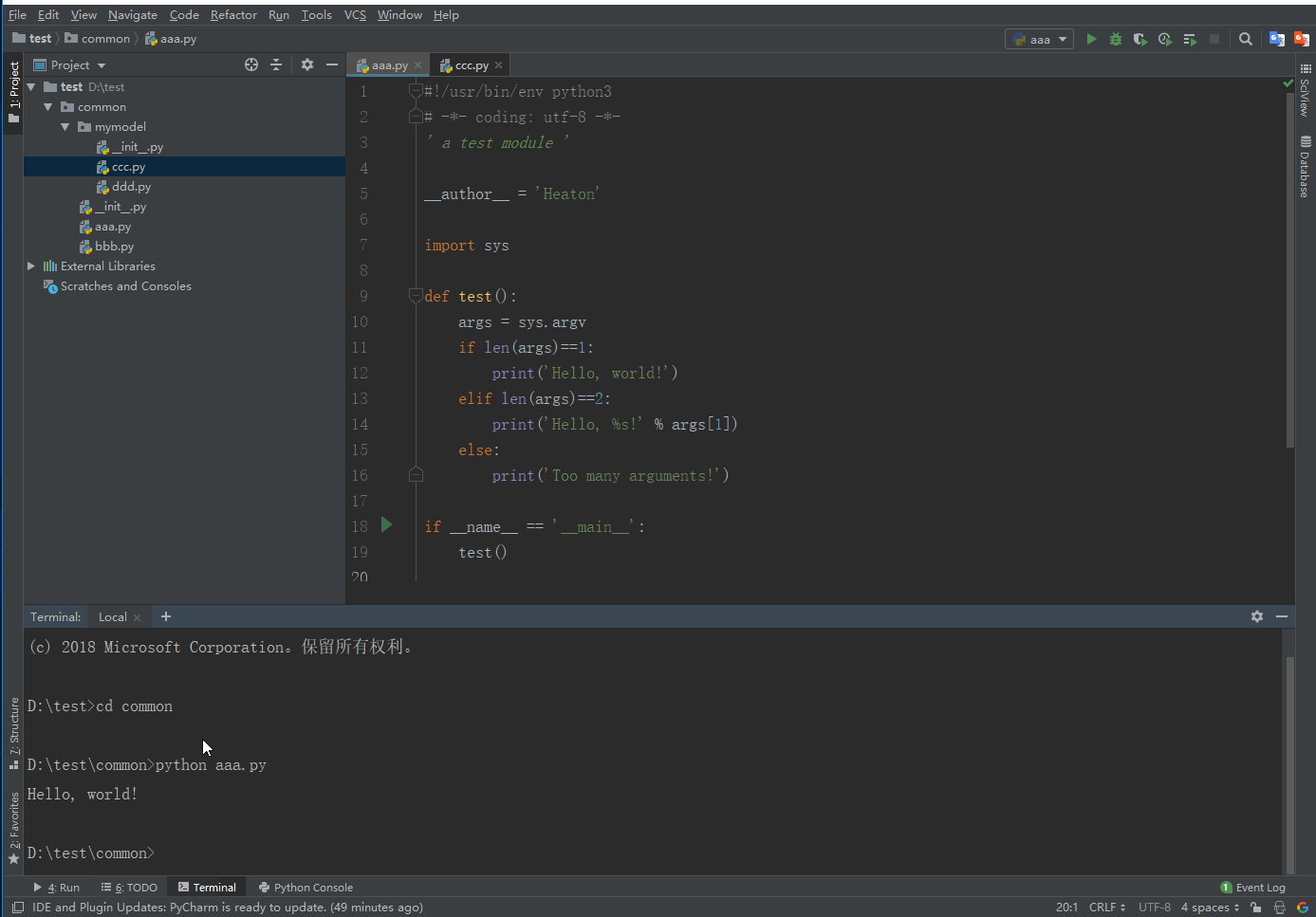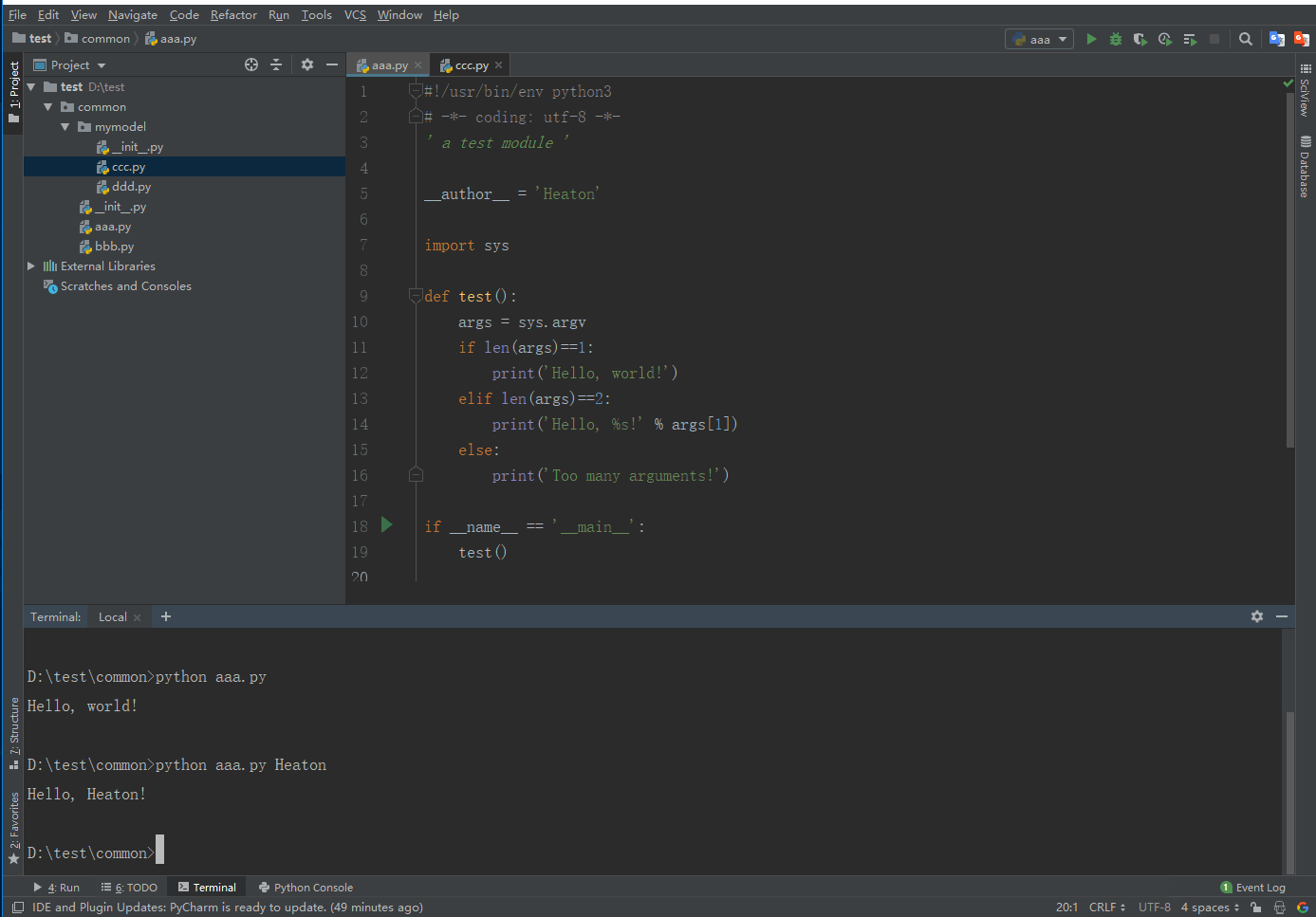
sys指向该模块,利用sys这个变量,就可以访问sys模块的所有功能。 sys模块有一个argv变量,用list存储了命令行的所有参数。argv至少有一个元素,因为第一个参数永远是该.py文件的名称,例如:- 运行
python aaa.py获得的sys.argv就是['aaa.py']; - 运行
python aaa.py Heaton获得的sys.argv就是['aaa.py', 'Heaton']。
- 运行
- 我们就有了变量
-
使用
if __name__ == '__main__':- 当我们在命令行运行模块文件时,Python解释器把一个特殊变量__name__置为__main__,而如果在其他地方导入该这个模块时,if判断将失败,因此,这种if测试可以让一个模块通过命令行运行时执行一些额外的代码,最常见的就是运行测试。
-
直接测试
-
模块测试
import Name as NewNamefrom ModelName import Name
2:日期和时间
时间time模块
- 每个时间戳都以自从1970年1月1日午夜(历元)经过了多长时间来表示。
- 如函数time.time()用于获取当前时间戳:

'''
时间API
'''
import time
print(time.time())
-时间元组
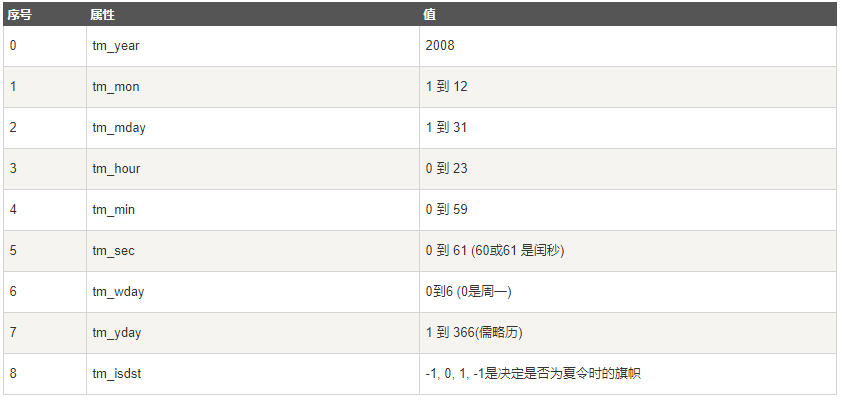

import time
localtime = time.localtime(time.time())
print("本地时间为 :", localtime)
- 格式化时间

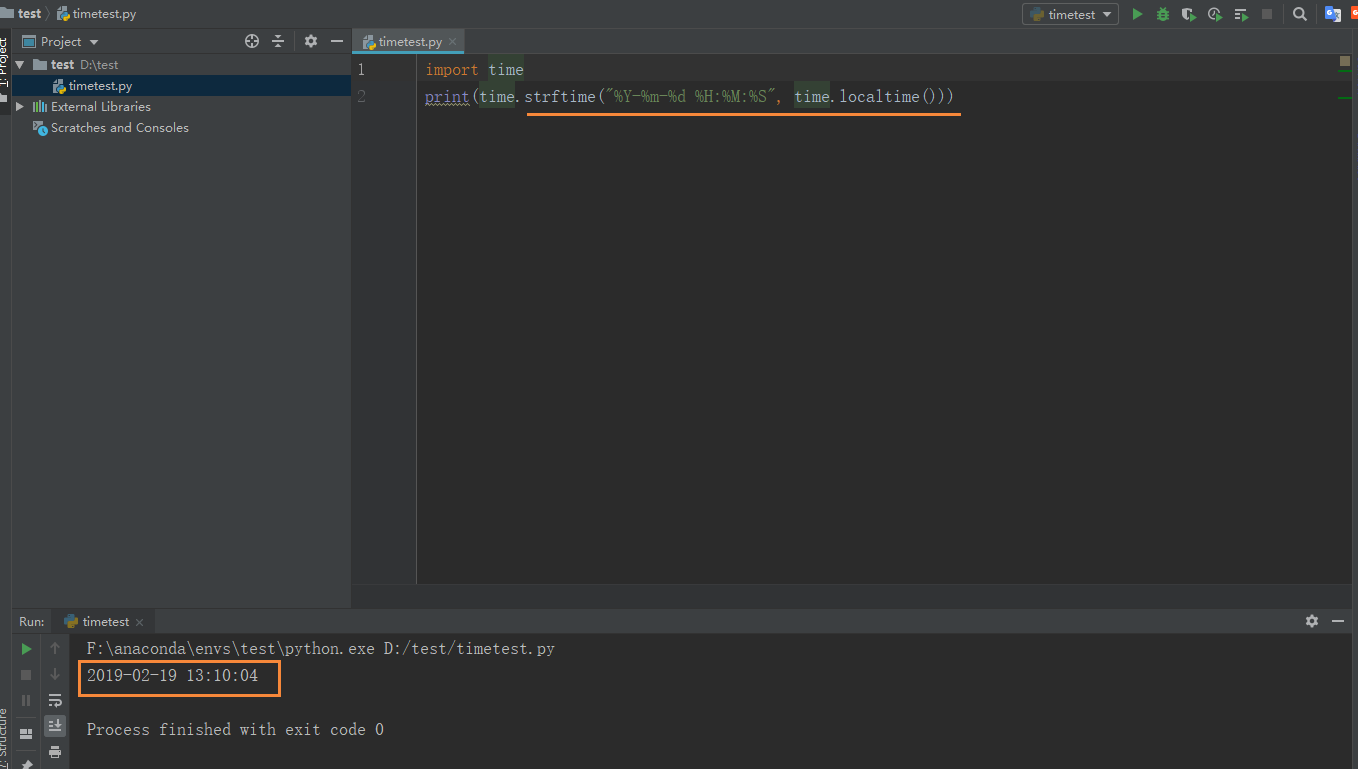
import time
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
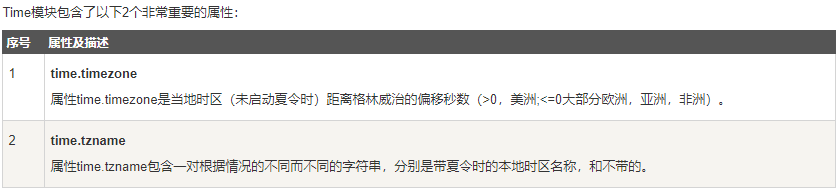
- time模块包含的方法

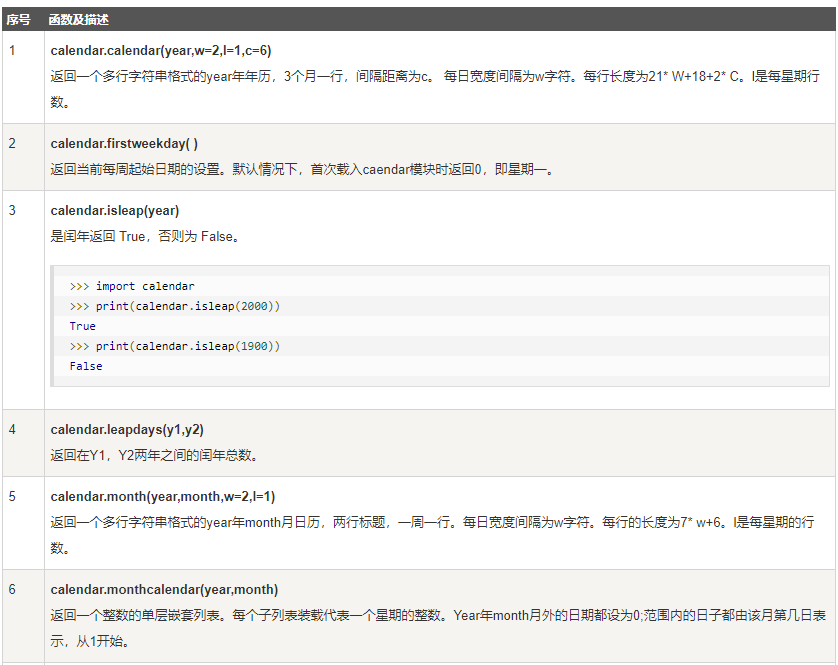
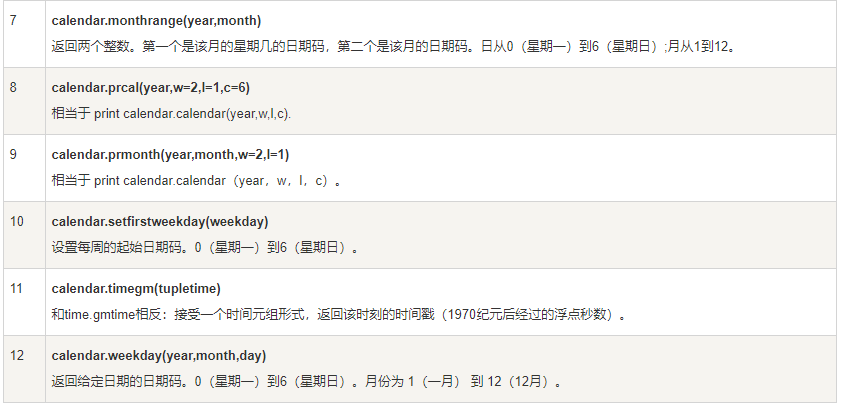
日历Calendar模块
- Calendar模块有很广泛的方法用来处理年历和月历,例如打印某月的月历:

import calendar
cal = calendar.month(2019, 1)
print("以下输出2016年1月份的日历:")
print(cal)
- 日历模块包含的方法
3:文件I/O
- 读文件

'''
文件IO-->读文件
'''
f = open('test.txt', 'r', encoding="utf8")
"""
文件不存在时会报异常信息如下:
Traceback (most recent call last):
File "D:/test/filetest/fileio.py", line 1, in <module>
f = open('/filetest/test.txt', 'r')
FileNotFoundError: [Errno 2] No such file or directory: '/filetest/test.txt'
"""
context = f.read()
print(context)
f.close()
- Python引入了with语句来自动帮我们调用close()方法:

'''
文件IO-->with读文件
'''
with open('test.txt', 'r', encoding="utf8") as f:
print(f.read())
- 写文件

'''
文件IO-->with写文件
'''
with open('test1.txt', 'w', encoding="utf8") as f:
f.write("Hello World")
-
模式说明



-
JSON


dumps()python对象转json字符串
loads()json字符串 转python对象
import json
d = dict(name='zhangsan', age=20, score=99)
ss = json.dumps(d)
print(ss)
new_obj = json.loads(ss)
print(new_obj)
print(type(ss))
print(type(new_obj))
- JSON 对象互转

import json
class Student(object):
def __init__(self, name, age, score):
self.name = name
self.age = age
self.score = score
s = Student('Bob', 20, 88)
json_str = json.dumps(s, default=lambda obj: obj.__dict__)
print(type(json_str))#<class 'str'>
print(json_str)#{"name": "Bob", "age": 20, "score": 88}
new_obj = json.loads(json_str, object_hook=lambda obj: Student(obj['name'],obj['age'],obj['score']))
print(type(new_obj))#<class '__main__.Student'>
print(new_obj)#<__main__.Student object at 0x0000019D09660470>
print("姓名:{},年龄:{},分数:{}".format(new_obj.name,new_obj.age,new_obj.score))#姓名:Bob,年龄:20,分数:88
4:面向对象
class后面紧接着是类名,即Student,类名通常是大写开头的单词,紧接着是(object),表示该类是从哪个类继承下来的,没有合适的继承类,就使用object类,这是所有类最终都会继承的类。- 定义好了Student类,就可以根据Student类创建出Student的实例,创建实例是通过类名+()实现的
- 由于类可以起到模板的作用,因此,可以在创建实例的时候,把一些我们认为必须绑定的属性强制填写进去。通过定义一个特殊的__init__方法(例子中是name和score)
- __init__方法的第一个参数永远是self,表示创建的实例本身,因此,在__init__方法内部,就可以把各种属性绑定到self,因为self就指向创建的实例本身。
- 有了__init__方法,在创建实例的时候,就不能传入空的参数了,必须传入与__init__方法匹配的参数,但self不需要传,Python解释器自己会把实例变量传进去
- 如果要让内部属性不被外部访问,可以把属性的名称前加上两个下划线__,在Python中,实例的变量名如果以__开头,就变成了一个私有变量(private),只有内部可以访问,外部不能访问。
'''
对象的使用
'''
# 无属性对象
class Student(object):
pass
bart = Student()
print(bart)#<__main__.Student object at 0x000001D144788278> 0x000001D144788278类的地址,每个类不同
# 绑定属性对象
class StudentOne(object):
def __init__(self, name, score):
self.name = name
self.score = score
def print_info(self):
print('%s: %s' % (self.name, self.score))
bart = StudentOne('zhangsan', 66)
bart.print_info()#zhangsan: 66
print(bart.name)#zhangsan
print(bart.score)#66
# 访问权限
class StudentTwo(object):
def __init__(self, name, score):
self.__name = name
self.__score = score
#如果外部代码要获取修改score怎么办?可以给Student类增加get_name和get_score这样的方法
def get_score(self):
return self.__score
def set_score(self, score):
if 0 <= score <= 100:
self.__score = score
else:
raise ValueError('bad score')
def print_score(self):
print('%s: %s' % (self.__name, self.__score))
bart = StudentTwo('lisi', 88)
#print(bart.__name)#AttributeError: 'StudentTwo' object has no attribute '__name'
print(bart.get_score())#88
#bart.set_score(101)#ValueError: bad score
bart.set_score(100)
print(bart.get_score())#100
- 继承和多态
- 在OOP程序设计中,当我们定义一个class的时候,可以从某个现有的class继承,新的class称为子类(Subclass),而被继承的class称为基类、父类或超类(Base class、Super class)
- 继承可以把父类的所有功能都直接拿过来,这样就不必重零做起,子类只需要新增自己特有的方法,也可以把父类不适合的方法覆盖重写。
- 动态语言的鸭子类型特点决定了继承不像静态语言那样是必须的。
#父类 动物
class Animal(object):
def run(self):
print('Animal is running...')
#子类 狗
class Dog(Animal):
pass
#子类 猫
class Cat(Animal):
def run(self):
print('Cat is running...')
'''
继承的好处
当子类和父类都存在相同的run()方法时,我们说,子类的run()覆盖了父类的run(),
在代码运行的时候,总是会调用子类的run()。这样,我们就获得了继承的另一个好处:多态。
'''
dog = Dog()
dog.run()#Animal is running...
cat = Cat()
cat.run()#Cat is running...
#判断类型
a = list() # a是list类型
b = Animal() # b是Animal类型
c = Dog() # c是Dog类型
d = Cat() # c是Dog类型
print(isinstance(a, list))#True
print(isinstance(b, Animal))#True
print(isinstance(c, Dog))#True
print(isinstance(c, Animal))#True
#体会多态的好处,一个函数通用
def run_twice(animal):
animal.run()
run_twice(b)#Animal is running...
run_twice(c)#Animal is running...
run_twice(d)#Cat is running...
'''
对于静态语言(例如Java)来说,如果需要传入Animal类型,
则传入的对象必须是Animal类型或者它的子类,否则,将无法调用run()方法。
对于Python这样的动态语言来说,则不一定需要传入Animal类型。
我们只需要保证传入的对象有一个run()方法就可以了。
'''
class Timer(object):
def run(self):
print('Start...')
run_twice(Timer())#Start...
#这就是动态语言的“鸭子类型”,它并不要求严格的继承体系,
# 一个对象只要“看起来像鸭子,走起路来像鸭子”,
# 那它就可以被看做是鸭子。
- 使用
@property和__slots__ - @property的实现比较复杂。把一个getter方法变成属性,只需要加上@property就可以了,此时,@property本身又创建了另一个装饰器@score.setter,负责把一个setter方法变成属性赋值,于是,我们就拥有一个可控的属性操作。
- 如果我们想要限制实例的属性怎么办?比如,只允许对Student实例添加
birth和age属性。使用__slots__ = ('_birth','_age')
class Student(object):
__slots__ = ('_birth','_age') # 用tuple定义允许绑定的属性名称,除此之外不能被使用
@property
def birth(self):
return self._birth
@birth.setter
def birth(self, value):
if not isinstance(value, int):
raise ValueError('birth must be an integer!')
if value < 1700 or value > 2019:
raise ValueError('birth must between 1700 ~ 2019!')
self._birth = value
#不给setter相当于保护age不能被赋值
@property
def age(self):
return 2019 - self._birth
s = Student()
s.birth = 1989
#s.birth = 999 #ValueError: birth must between 1700 ~ 2019!
#s.birth = "aa" #ValueError: birth must be an integer!
print(s.birth) #1989
#s.age = 15 #AttributeError: can't set attribute
print(s.age) #30
#s.name = "lala"#AttributeError: 'Student' object has no attribute 'name'
- 多重继承 MixIn的设计
- 只允许单一继承的语言(如Java)不能使用MixIn的设计。
- 假设我们要实现以下4种动物:
- Bat - 蝙蝠;
- Parrot - 鹦鹉;
- Ostrich - 鸵鸟。
- Dog - 狗狗;
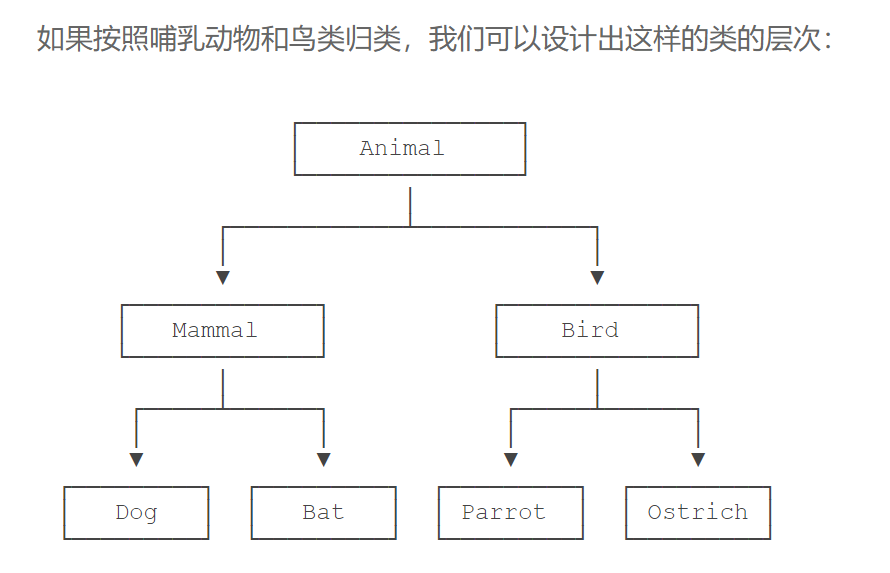
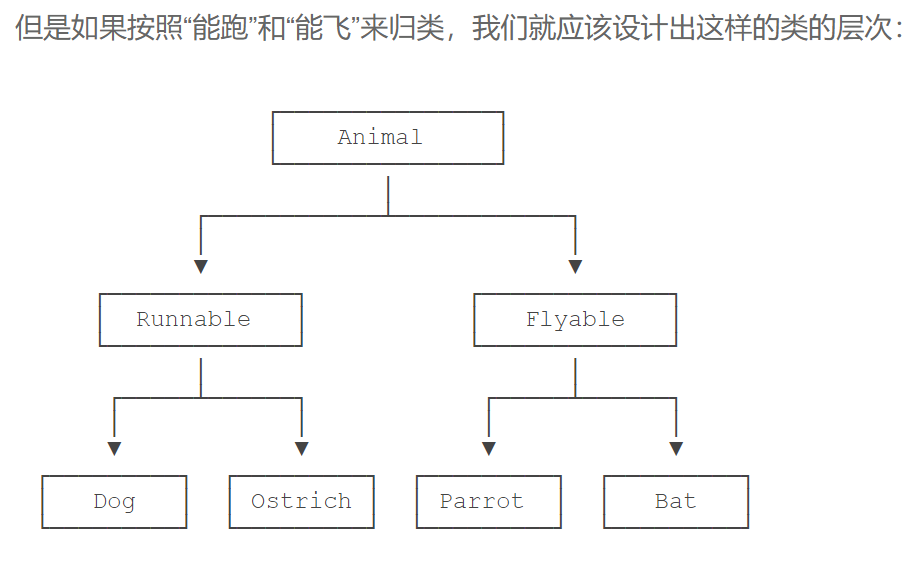

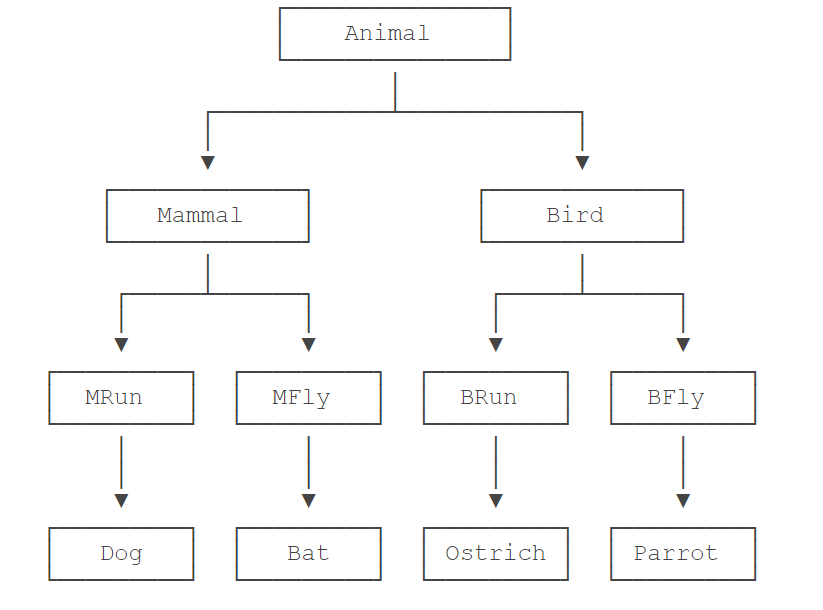
如果要再增加“宠物类”和“非宠物类”,这么搞下去,类的数量会呈指数增长,很明显这样设计是不行的。
正确的做法是采用多重继承。首先,主要的类层次仍按照哺乳类和鸟类设计:
# 大类:动物
class Animal(object):
pass
# 次类:哺乳和鸟
class Mammal(Animal):
pass
class Bird(Animal):
pass
# 次类:跑和飞
class RunnableMixIn(object):
def run(self):
print('Running...')
class FlyableMixIn(object):
def fly(self):
print('Flying...')
# 各种子类动物:狗 蝙蝠 鹦鹉 鸵鸟
class Dog(Mammal, RunnableMixIn):
pass
class Bat(Mammal, FlyableMixIn):
pass
class Parrot(Bird, FlyableMixIn):
pass
class Ostrich(Bird, RunnableMixIn):
pass
5:网络接口
- 基础网络包urllib
首先爬取数据就需要和网络进行交互。先看案例
import urllib.request as re # 导入python的网络模块
response = re.urlopen("https://www.baidu.com/") # 打开url数据
html = response.read() # 读取数据
print(html.decode("utf-8")) # 转码打印
- 猫奴案例
- 猫奴网站
# 版本1直接打开url路径
import urllib.request as re
response = re.urlopen("http://placekitten.com/g/500/600")
cat_img = response.read()
with open("cat_500_600.jpg", "wb") as f:
f.write(cat_img)
# 版本2打开request对象
import urllib.request as ure
req = ure.Request("http://placekitten.com/g/500/600")
response = ure.urlopen(req)
cat_img = response.read()
with open("cat_500_600.jpg", "wb") as f:
f.write(cat_img)


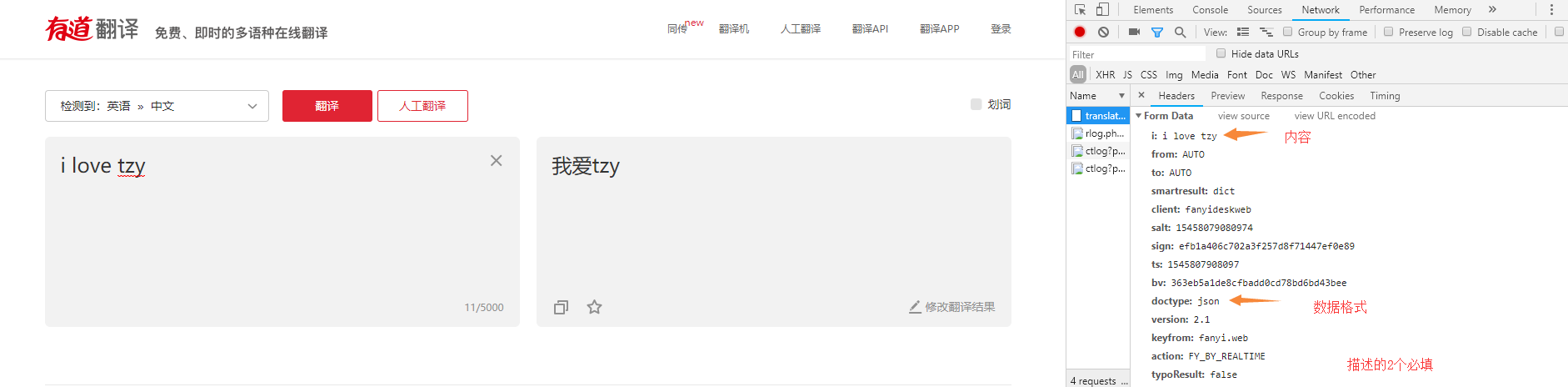
- 翻译案例
import urllib.request as ure
import urllib.parse as upa
import json
text = input("请输入您要翻译的英文:")
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
data = {}
data["from"] = "AUTO"
data["to"] = "AUTO"
data["i"] = text
data["doctype"] = "json"
data["version"] = "2.1"
data["keyfrom"] = "fanyi.web"
data["ue"] = "UTF-8"
data["typoResult"] = "false"
data = upa.urlencode(data).encode("utf-8")
response = ure.urlopen(url, data)
html = response.read().decode("utf-8")
# print(html)
# {"type":"EN2ZH_CN","errorCode":0,"elapsedTime":1,"translateResult":[[{"src":"I love tzy","tgt":"我爱tzy"}]]}
result = json.loads(html);
# print(type(result))#<class 'dict'>
print("翻译结果为:%s" % (result["translateResult"][0][0]["tgt"]))
从header中找到请求路径注意要去掉translate后面的 _0
- 翻译案例改版(防屏蔽一)
import urllib.request as ure
import urllib.parse as upa
import json
import time
while ("true"):
text = input("请输入您要翻译的英文q!为退出:")
if text.lower().strip() == "q!": # 不分大小写去首尾空格
break
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
head = {}
# 加入头部信息防止屏蔽
head[
"User-Agent"] = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"
data = {}
data["i"] = text
data["doctype"] = "json"
data = upa.urlencode(data).encode("utf-8")
req = ure.Request(url, data, head)
response = ure.urlopen(req)
html = response.read().decode("utf-8")
result = json.loads(html);
print("翻译结果为:%s" % (result["translateResult"][0][0]["tgt"]))
# 停顿5秒再次执行
time.sleep(5)
-
翻译案例改版(防屏蔽二:代理)
-
1.参数是一个dict(字典)
- proxy_support = urllib.request.ProxyHandler({ 代理ip地址 })
-
2.定制、创建一个opener
- opener = urllib.request.build_opener(proxy_support )
-
3.使用opener
- 安装opener: urllib.request.install_opener(opener)
- 调用opener: opener.open(url)
-
代理使用案例
import urllib.request
url = 'http://www.whatismyip.com.tw'
proxy_support = urllib.request.ProxyHandler({'http': '183.47.40.35:8088'})
opener = urllib.request.build_opener(proxy_support)
opener.addheaders = [('User-Agent',
'Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19')]
urllib.request.install_opener(opener)
response = urllib.request.urlopen(url)
html = response.read().decode('utf-8')
print(html)

- 常见 User-Agent 大全(自己在用)
window.navigator.userAgent
1) Chrome
Win7:
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1
2) Firefox
Win7:
Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0
3) Safari
Win7:
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50
4) Opera
Win7:
Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168 Version/11.50
5) IE
Win7+ie9:
Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; Tablet PC 2.0; .NET4.0E)
Win7+ie8:
Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)
WinXP+ie8:
Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; GTB7.0)
WinXP+ie7:
Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)
WinXP+ie6:
Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)
6) 傲游
傲游3.1.7在Win7+ie9,高速模式:
Mozilla/5.0 (Windows; U; Windows NT 6.1; ) AppleWebKit/534.12 (KHTML, like Gecko) Maxthon/3.0 Safari/534.12
傲游3.1.7在Win7+ie9,IE内核兼容模式:
Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E)
7) 搜狗
搜狗3.0在Win7+ie9,IE内核兼容模式:
Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)
搜狗3.0在Win7+ie9,高速模式:
Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.3 (KHTML, like Gecko) Chrome/6.0.472.33 Safari/534.3 SE 2.X MetaSr 1.0
8) 360
360浏览器3.0在Win7+ie9:
Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E)
9) QQ浏览器
QQ浏览器6.9(11079)在Win7+ie9,极速模式:
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.41 Safari/535.1 QQBrowser/6.9.11079.201
QQ浏览器6.9(11079)在Win7+ie9,IE内核兼容模式:
Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E) QQBrowser/6.9.11079.201
10) 阿云浏览器
阿云浏览器1.3.0.1724 Beta(编译日期2011-12-05)在Win7+ie9:
Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)
6:正则
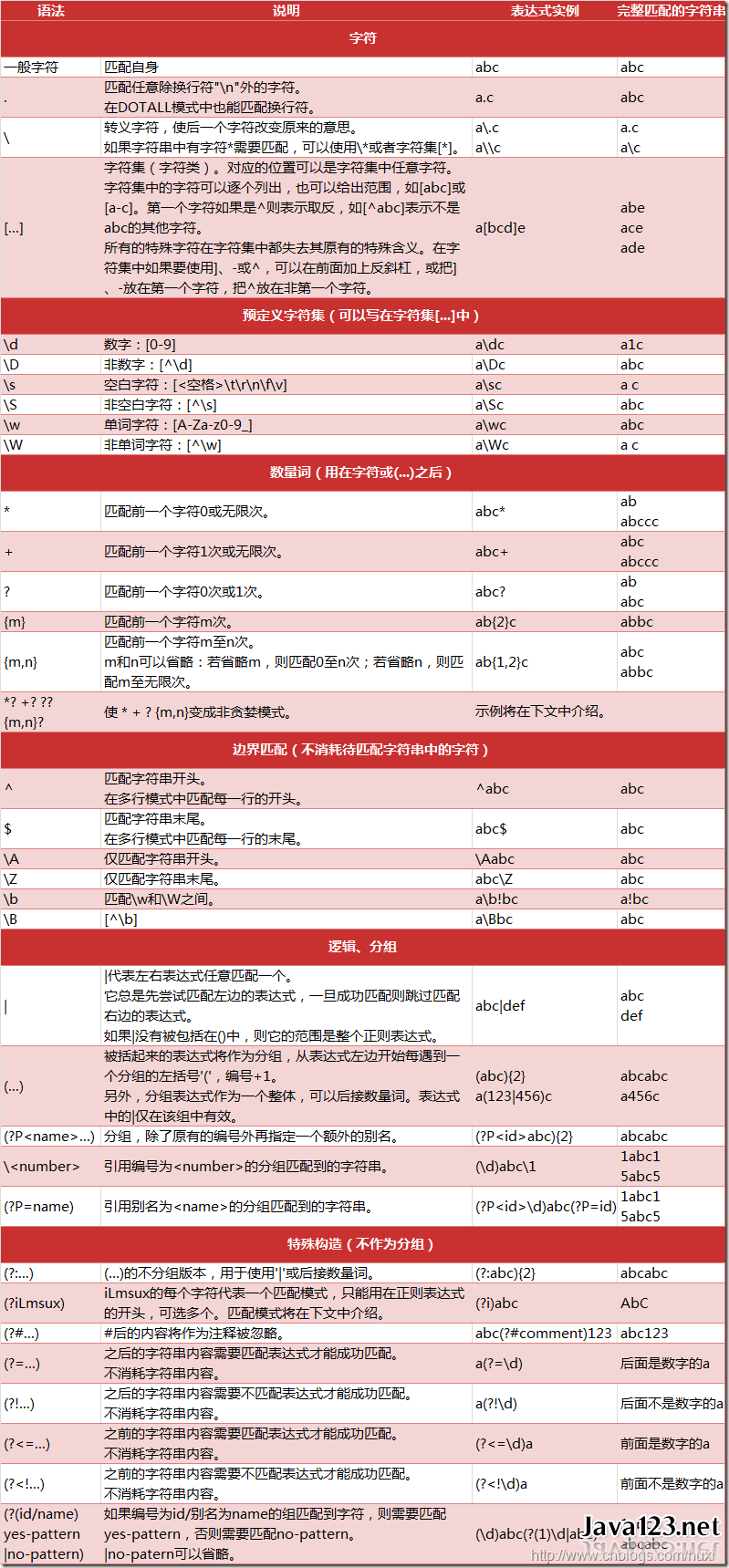
import re
a = re.search(r'tzy', 'I Love tzy') # 正则的使用
print(a) # <re.Match object; span=(7, 10), match='tzy'>
b = 'I Love tzy'.find('tzy') # str方法找字符串,特殊情况没有办法
print(b) # 7
c = re.search(r'.', 'I Love .tzy') # .代表除了换行的所有字符都可以
print(c) # <re.Match object; span=(0, 1), match='I'>
d = re.search(r'\.', 'I Love .tzy') # 转译.
print(d) # <re.Match object; span=(7, 8), match='.'>
e = re.search(r'\d', 'I Love .tzy123') # 匹配任何数字
print(e) # <re.Match object; span=(11, 12), match='1'>
f = re.search(r'\d\d\d', 'I Love .tzy123') # 匹配任何数字
print(f) # <re.Match object; span=(11, 14), match='123'>
g = re.search(r'[aeiouAEIOU]', 'I Love .tzy123') # 匹配aeiouAEIOU
print(g) # <re.Match object; span=(0, 1), match='I'>
h = re.search(r'[a-z]', 'I Love .tzy123') # 匹配a-z
print(h) # <re.Match object; span=(3, 4), match='o'>
i1 = re.search(r'[01]\d\d|2[0-4]\d|25[0-5]', '254')
# 匹配0-255的数,由于正则匹配的是字符串不能写成[0-255]:意思是0-2然后5和5,即[0,1,2,5]4个数字
i2 = re.search(r'[01]{0,1}\d{0,1}\d|2{0,1}[0-4]{0,1}\d|2{0,1}5{0,1}[0-5]', '555')
# 加上位数限定
print(i1) # <re.Match object; span=(0, 3), match='254'>
print(i2) # <re.Match object; span=(0, 2), match='55'>
j = re.search(r'\d\d\d\.\d\d\d\.\d\d\d\.\d\d\d', '555.168.110.110') # 匹配ip但是数字范围超过了255,而且位数也不行
print(j)
k = re.search(
r'(([01]{0,1}\d{0,1}\d|2{0,1}[0-4]{0,1}\d|2{0,1}5{0,1}[0-5])\.){3}([01]{0,1}\d{0,1}\d|2{0,1}[0-4]{0,1}\d|2{0,1}5{0,1}[0-5])',
'555.168.1.22')
# 匹配ip但是数字范围超过了255,而且位数也不行 (有bug) 小括号代表分组
print(k) # 错误结果<re.Match object; span=(1, 12), match='55.168.1.22'>
- 一、校验数字的表达式
数字:^[0-9]*$
n位的数字:^\d{n}$
至少n位的数字:^\d{n,}$
m-n位的数字:^\d{m,n}$
零和非零开头的数字:^(0|[1-9][0-9]*)$
非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$
带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})?$
正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
有两位小数的正实数:^[0-9]+(.[0-9]{2})?$
有1~3位小数的正实数:^[0-9]+(.[0-9]{1,3})?$
非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
非零的负整数:^\-[1-9][]0-9″*$ 或 ^-[1-9]\d*$
非负整数:^\d+$ 或 ^[1-9]\d*|0$
非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
非负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
- 二、校验字符的表达式
汉字:^[\u4e00-\u9fa5]{0,}$
英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
长度为3-20的所有字符:^.{3,20}$
由26个英文字母组成的字符串:^[A-Za-z]+$
由26个大写英文字母组成的字符串:^[A-Z]+$
由26个小写英文字母组成的字符串:^[a-z]+$
由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
可以输入含有^%&’,;=?$\”等字符:[^%&',;=?$\x22]+
禁止输入含有~的字符:[^~\x22]+
- 三、特殊需求表达式
Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?
InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
电话号码(“XXX-XXXXXXX”、”XXXX-XXXXXXXX”、”XXX-XXXXXXX”、”XXX-XXXXXXXX”、”XXXXXXX”和”XXXXXXXX):^($$\d{3,4}-)|\d{3.4}-)?\d{7,8}$
国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
身份证号(15位、18位数字):^\d{15}|\d{18}$
短身份证号码(数字、字母x结尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$
帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
日期格式:^\d{4}-\d{1,2}-\d{1,2}
一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
钱的输入格式:
有四种钱的表示形式我们可以接受:”10000.00″ 和 “10,000.00″, 和没有 “分” 的 “10000″ 和 “10,000″:^[1-9][0-9]*$
这表示任意一个不以0开头的数字,但是,这也意味着一个字符”0″不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧.下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
必须说明的是,小数点后面至少应该有1位数,所以”10.”是不通过的,但是 “10″ 和 “10.2″ 是通过的:^[0-9]+(.[0-9]{2})?$
这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
这样就允许用户只写一位小数。下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
备注:这就是最终结果了,别忘了”+”可以用”*”替代。如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
中文字符的正则表达式:[\u4e00-\u9fa5]
双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
空白行的正则表达式:\n\s*\r (可以用来删除空白行)
HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? /> (网上流传的版本太糟糕,上面这个也仅仅能部分,对于复杂的嵌套标记依旧无能为力)
首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
IP地址:\d+\.\d+\.\d+\.\d+ (提取IP地址时有用)
IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))

您的资助是我最大的动力!
金额随意,欢迎来赏!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号