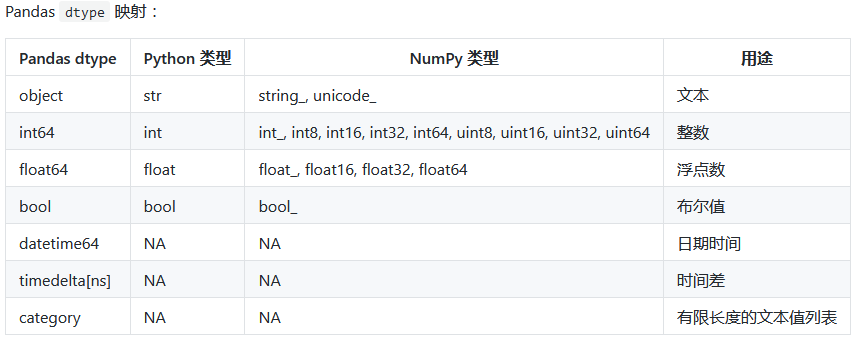
1.数据类型映射
![]()
2.过滤操作
sql中的where语句的功能非常丰富,常用关键包括 =,<>,>=,<=,>,<,in,not in,isnull,like,and,or等关键字,下面我们就来看看,如果是在pandas中该如何实现。
>>> import pandas as pd
>>> import numpy as np
df = pd.read_excel(r'D:/myExcel/1.xlsx')
>>> df = pd.read_excel(r'D:/myExcel/1.xlsx')
>>> df
id name score grade
0 a bog 45.0 A
1 c jiken 67.0 B
2 d bob 23.0 A
3 b jiken 34.0 B
4 f lucy NaN A
5 e tidy 75.0 B
1、==
即判断相等关系,和sql中的=类似
# 获取id中为'a'的行
>>> df[df['id'] =='a']
id name score grade
0 a bog 45.0 A
# 获取score中分数为45的行
>>> df[df['score'] == 45]
id name score grade
0 a bog 45.0 A
2、!=
即表明不相等的关系,和sql中的<>类似
# 获取id中不为'a'的行
>>> df[df['id'] !='a']
id name score grade
1 c jiken 67.0 B
2 d bob 23.0 A
3 b jiken 34.0 B
4 f lucy NaN A
5 e tidy 75.0 B
# 获取score中不等于45的行
>>> df[df['score'] != 45]
id name score grade
1 c jiken 67.0 B
2 d bob 23.0 A
3 b jiken 34.0 B
4 f lucy NaN A
5 e tidy 75.0 B
3、>,>=,<,<=
此和sql保持一致
# score需>= 45
>>> df[df['score'] >= 45]
id name score grade
0 a bog 45.0 A
1 c jiken 67.0 B
5 e tidy 75.0 B
# score需> 45
>>> df[df['score'] > 45]
id name score grade
1 c jiken 67.0 B
5 e tidy 75.0 B
# score小于45
>>> df[df['score'] < 45]
id name score grade
2 d bob 23.0 A
3 b jiken 34.0 B
# score小于等于45
>>> df[df['score'] <= 45]
id name score grade
0 a bog 45.0 A
2 d bob 23.0 A
3 b jiken 34.0 B
2.替换操作
# 假如表中有88,则88全部替换为99
df.replace({88:99})
3.替换df中某一行的特定值
# index代表行索引,2代表列的索引值为2
df.iloc[index, 2] = ""

 浙公网安备 33010602011771号
浙公网安备 33010602011771号