分布式图神经网络
分布式图神经网络
一、DGL中的实现
官网:https://docs.dgl.ai/en/latest/guide_cn/index.html
DGL是用于图结构深度学习的Python库,通过与主流的深度学习框架集成(包括Tensorflow、PyTorch、MXNet),能够实现从传统的张量运算到图运算的自由转换。DGL提供基于消息传递的编程模型来完成图上的计算,结合消息融合等优化技术使系统达到了比较好的性能。
DGL采用完全分布式的方法,可将数据和计算同时分布在一组计算资源中。DGL会将一张图划分为多张子图, 集群中的每台机器各自负责一张子图(分区)。为了并行化计算,DGL在集群所有机器上运行相同的训练脚本, 并在同样的机器上运行服务器以将分区数据提供给训练器。
对于训练脚本,DGL提供了分布式的API。它们与小批次训练的API相似。重点在于:1)初始化DGL的分布式模块,2)创建分布式图对象,以及 3)拆分训练集,并计算本地进程的节点。
import dgl
from dgl.dataloading import NeighborSampler
from dgl.distributed import DistGraph, DistDataLoader, node_split
import torch as th
# initialize distributed contexts
dgl.distributed.initialize('ip_config.txt')
th.distributed.init_process_group(backend='gloo')
# load distributed graph
g = DistGraph('graph_name', 'part_config.json')
pb = g.get_partition_book()
# get training workload, i.e., training node IDs
train_nid = node_split(g.ndata['train_mask'], pb, force_even=True)
DGL实现了一些分布式组件以支持分布式训练,下图显示了这些组件及它们间的相互作用。
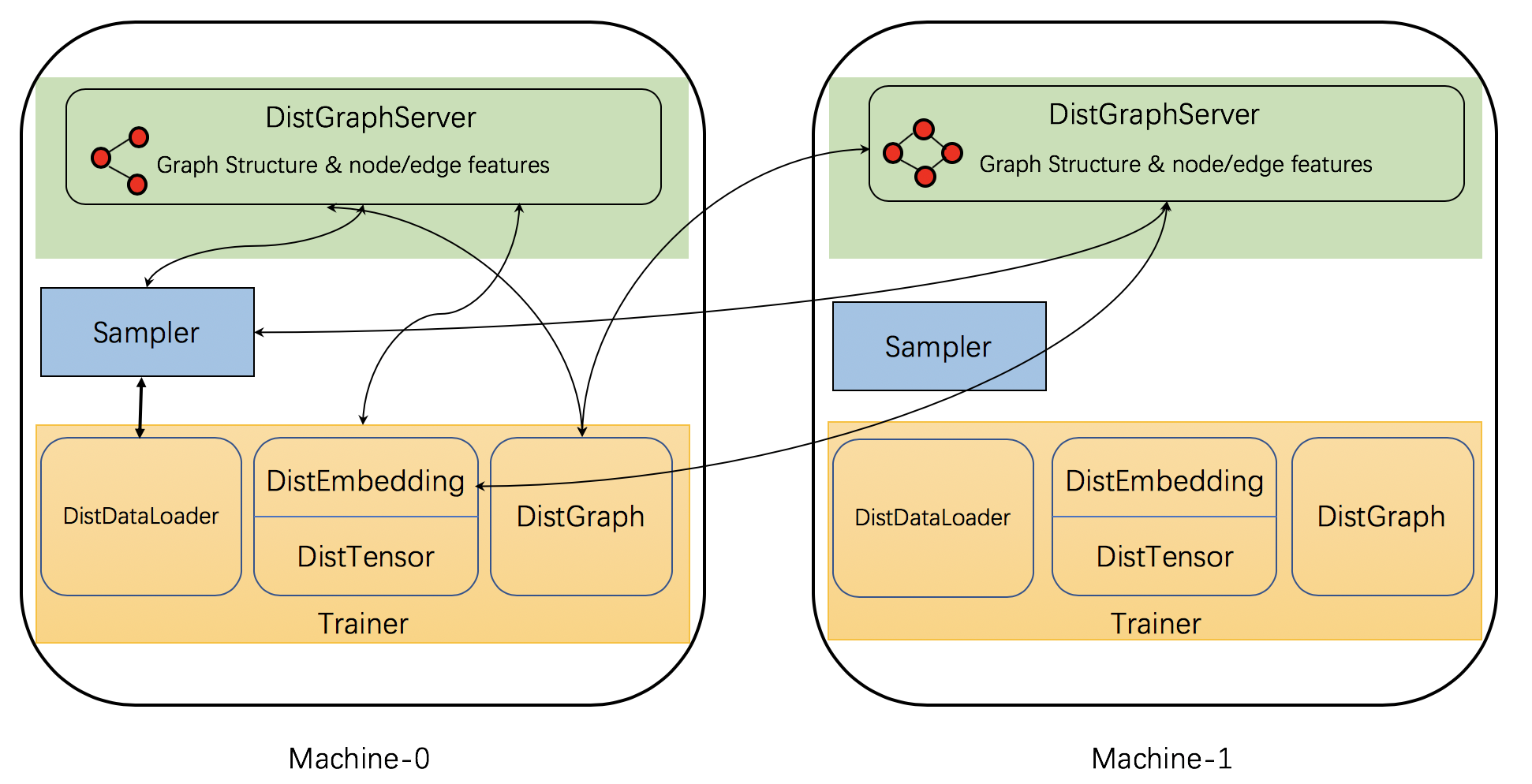
具体来说,DGL的分布式训练具有三种类型的交互进程: 服务器, 采样器 和 训练器。
- 服务器进程 在存储图分区数据(包括图结构和节点/边特征)的每台计算机上运行。它们提供采样、获取或更新节点/边特征等服务。 这些服务器一起工作以将图数据提供给训练器。注意,一台机器可能同时运行多个服务器进程,以并行化计算和网络通信。其中一个是 主服务器 ,负责数据加载,并通过共享内存与提供服务的 备份服务器 共享数据。
- 采样器进程 与服务器进行交互,并对节点和边采样以生成用于训练的小批次数据。
- 训练器进程 负责小批量的训练网络,包含多个与服务器交互的类。用
DistGraph来获取被划分的图分区数据, 用DistEmbedding和DistTensor来获取节点/边特征/嵌入,用DistDataLoader与采样器进行交互以获得小批次数据。
1. 数据预处理
DGL要求预处理图数据以进行分布式训练,这包括两个步骤:1)将一张图划分为多张子图(分区),2)为节点和边分配新的ID。 DGL提供了partition_graph()一个对内存DGLGraph对象进行分区的API以执行这两个步骤。该API支持随机划分和基于 Metis 的划分。Metis划分的好处在于, 它可以用最少的边分割以生成分区,从而减少了用于分布式训练和推理的网络通信。DGL使用最新版本的Metis, 并针对真实世界中具有幂律分布的图进行了优化。在图划分后,API以易于在训练期间加载的格式构造划分结果。
Note: 图划分API当前在一台机器上运行。 因此如果一张图很大,用户将需要一台大内存的机器来对图进行划分。 未来DGL将支持分布式图划分。
默认情况下,为了在分布式训练/推理期间定位节点/边,API将新ID分配给输入图的节点和边。 分配ID后,该API会相应地打乱所有节点数据和边数据。在训练期间,用户只需使用新的节点和边的ID。 与此同时,用户仍然可以通过 g.ndata['orig_id'] 和 g.edata['orig_id'] 获取原始ID。 其中 g 是 DistGraph 对象(详细解释,请参见:ref:guide-distributed-apis)。
DGL将图划分结果存储在输出目录中的多个文件中。输出目录里始终包含一个名为xxx.json的JSON文件,其中xxx是提供给划分API的图的名称。 JSON文件包含所有划分的配置。如果该API没有为节点和边分配新ID,它将生成两个额外的NumPy文件:node_map.npy 和 edge_map.npy。 它们存储节点和边ID与分区ID之间的映射。对于具有十亿级数量节点和边的图,两个文件中的NumPy数组会很大, 这是因为图中的每个节点和边都对应一个条目。在每个分区的文件夹内,有3个文件以DGL格式存储分区数据。 graph.dgl 存储分区的图结构以及节点和边上的一些元数据。node_feats.dgl 和 edge_feats.dgl 存储属于该分区的节点和边的所有特征。
import dgl
g = ... # create or load a DGLGraph object
dgl.distributed.partition_graph(g, 'mygraph', 2, 'data_root_dir')
将输出以下数据文件
data_root_dir/
|-- mygraph.json # JSON中的分区配置文件
|-- node_map.npy # 存储在NumPy数组中的每个节点的分区ID(可选)
|-- edge_map.npy # 存储在NumPy数组中的每个边的分区ID(可选)
|-- part0/ # 分区0的数据
|-- node_feats.dgl # 以二进制格式存储的节点特征
|-- edge_feats.dgl # 以二进制格式存储的边特征
|-- graph.dgl # 以二进制格式存储的子图结构
|-- part1/ # 分区1的数据
|-- node_feats.dgl
|-- edge_feats.dgl
|-- graph.dgl
第7.4 章 Advanced Graph Partitioning介绍了有关分区格式的更多详细信息。要将分区分发到集群,用户可以将数据保存在所有机器都可以访问的某个共享文件夹中,或者将元数据 JSON 以及相应的分区文件夹复制partX到第 X 台机器。
负载均衡
在对图进行划分时,默认情况下,Metis仅平衡每个子图中的节点数。根据当前的任务情况,这可能带来非最优的配置。 例如,在半监督节点分类的场景里,训练器会对局部分区中带标签节点的子集进行计算。 一个仅平衡图中节点(带标签和未带标签)的划分可能会导致计算负载不平衡。为了在每个分区中获得平衡的工作负载, 划分API通过在 dgl.distributed.partition_graph() 中指定 balance_ntypes 在每个节点类型中的节点数上实现分区间的平衡。用户可以利用这一点将训练集、验证集和测试集中的节点看作不同类型的节点。
以下示例将训练集内和训练集外的节点看作两种类型的节点:
dgl.distributed.partition_graph(g, 'graph_name', 4, '/tmp/test', balance_ntypes=g.ndata['train_mask'])
除了平衡节点的类型之外, dgl.distributed.partition_graph() 还允许通过指定 balance_edges 来平衡每个类型节点在子图中的入度。这平衡了不同类型节点的连边数量。
使用partition_graph()需要具有足够大 CPU RAM 的实例来保存整个图结构和特征,这对于具有数千亿条边或大特征的图可能不可行。因此DGL实现了并行数据准备管道。
并行数据准备管道
为了处理单机 CPU RAM 无法容纳的海量图数据,DGL 利用数据分块和并行处理来减少内存占用和运行时间。
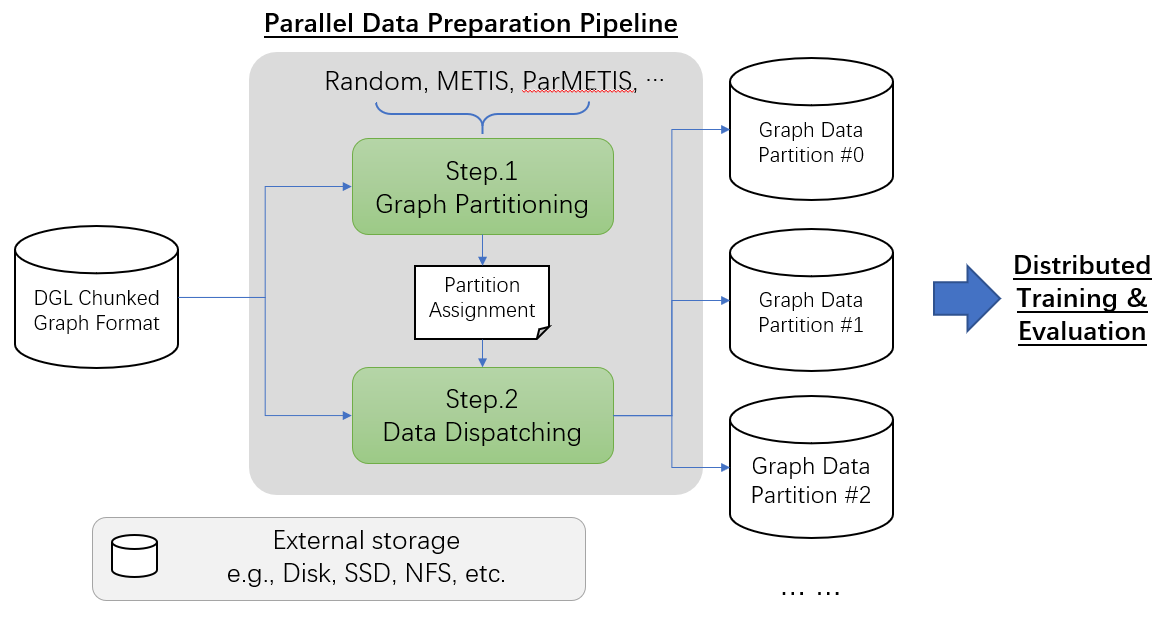
- 管道获取以 Chunked Graph Format 存储的输入数据,并生成数据分区、将其分派到目标机器。
- Step.1 Graph Partitioning:它计算每个分区的所有权并将结果保存为一组称为 partition assignment 的文件。为了加快这一步,一些算法(例如,ParMETIS)支持使用多台机器的并行计算。
- Step.2 Data Dispatching:给定分区分配,然后该步骤对图数据进行物理分区并将它们分派到用户指定的机器上。它还将图数据转换为适合分布式训练和评估的格式。
整个管道是模块化的,因此每个步骤都可以单独调用。例如,用户可以将 Step.1 替换为一些自定义的图分区算法,只要它正确生成分区分配文件。
2. 分布式计算的API
DGL 为初始化、分布式采样和工作负载拆分提供了三种分布式数据结构和各种 API。
DistGraph用于访问分布式存储图的结构和特征。DistTensor用于访问跨机器分区的节点/边的特征张量。DistEmbedding用于访问跨机器分区的可学习节点/边嵌入张量。
分布式采样
DGL提供了两个级别的API,用于对节点和边进行采样以生成小批次训练数据。 底层API要求用户编写代码以明确定义如何对节点层进行采样(例如,使用 dgl.sampling.sample_neighbors() )。 高层采样API为节点分类和链接预测任务实现了一些流行的采样算法(例如 NodeDataLoader 和 EdgeDataLoader )。
分布式采样模块遵循相同的设计,也提供两个级别的采样API。对于底层的采样API,它为 DistGraph 上的分布式邻居采样提供了 sample_neighbors()。另外,DGL提供了用于分布式采样的分布式数据加载器( DistDataLoader)。除了用户在创建数据加载器时无法指定工作进程的数量, 分布式数据加载器具有与PyTorch DataLoader相同的接口。其中的工作进程(worker)在 dgl.distributed.initialize() 中创建。
Note: 在 DistGraph 上运行 dgl.distributed.sample_neighbors() 时, 采样器无法在具有多个工作进程的PyTorch DataLoader中运行。主要原因是PyTorch DataLoader在每个训练周期都会创建新的采样工作进程, 从而导致多次创建和删除 DistGraph 对象。
分割数据集
用户需要分割训练集,以便每个训练器都可以使用自己的训练集子集。同样,用户还需要以相同的方式分割验证和测试集。
对于分布式训练和评估,推荐的方法是使用布尔数组表示训练、验证和测试集。对于节点分类任务, 这些布尔数组的长度是图中节点的数量,并且它们的每个元素都表示训练/验证/测试集中是否存在对应节点。 链接预测任务也应使用类似的布尔数组。
DGL提供了 node_split() 和 edge_split() 函数来在运行时拆分训练、验证和测试集,以进行分布式训练。这两个函数将布尔数组作为输入,对其进行拆分,并向本地训练器返回一部分。 默认情况下,它们确保所有部分都具有相同数量的节点和边。这对于同步SGD非常重要, 因为同步SGD会假定每个训练器具有相同数量的小批次。
下面的示例演示了训练集拆分,并向本地进程返回节点的子集。
train_nids = dgl.distributed.node_split(g.ndata['train_mask'])
二、PyG中的实现
官网:https://pytorch-geometric.readthedocs.io/en/latest/
pyG(PyTorch Geometric),是一个基于PyTorch构建的深度学习库,可以对非结构化数据进行建模和训练。该库利用专用CUDA内核实现了高性能训练。
Quiver是一个针对 PyG的GPU 优化分布式库。在运行 PyG 示例时,它可以通过 GPU 加速图形采样和特征聚合。
因为基于采样的图模型训练性能瓶颈主要是在图采样和特征提取上,Quiver核心观点是:
- 图采样是一个latency critical problem,高性能的采样核心在于通过大量并行掩盖访问延迟。
- 特征提取是一个bandwidth critical problem,高性能的特征提取在于优化聚合带宽。
但是目前只支持多GPU还没有推出分布式的

1. 图采样
Quiver中向用户提供UVA-Based(Unified Virtual Addressing Based)图采样算子,支持用户在图拓扑数据较大时选择将图存储在CPU内存中的同时使用GPU进行采样。这样不仅获得了远高于CPU采样的性能收益,同时能够处理的图的大小从GPU显存大小限制扩展到了CPU内存大小(一般远远大于GPU显存)。在ogbn-products和reddit上的两个数据集上进行采样性能测试显示,UVA-Based的采样性能远远高于CPU采样性能(CPU采样使用Pyg的采样实现为基线),衡量采样性能的指标为单位时间内的采样边数(Sampled Edges Per Second, SEPS)。在同样不需要存储图在GPU显存中的情况下,Quiver的采样在真实数据集上提供大约20倍的性能加速。

2. 图特征提取(Feature Collection)
Quiver提供了高吞吐的quiver.Feature用于进行特征提取。quiver.Feature的实现主要基于如下两个观察:
-
1 真实图往往具有幂律分布特性,少部分节点占据了整图大部分的连接数,而大部分基于图拓扑进行采样的算法,最终一个Epoch中每个节点被采样到的概率与该节点的连接数成正相关。我们在下面的表格中展示两个数据集中节点度高于整个图的平均节点度的点的数目,以及这些点的连接数占整个全图的连接数的比值。我们发现训练中少部分节点的特征将被高频访问。
![]()
-
2 一个AI Server中的各种访问传输带宽大小关系如下 GPU Global Memory > GPU P2P With NVLink > Pinned Memory > Pageble Memory。

考虑到上述的访问带宽层级关系以及图节点的访问不均匀性质,Quiver中的quiver.Feature根据用户配置的参数将特征进行自动划分存储在GPU显存以及CPU Pinned Memory中。并将热点数据存储在GPU,冷数据存储在CPU中(用户需要传入csr_topo参数),特征提取时使用GPU来进行统一访问。

三、PGL中的实现
官网:https://github.com/PaddlePaddle/PGL/blob/main/README.zh.md
PGL是由百度开发的基于PaddlePaddle的高效灵活的图学习框架。PGL实现了高度并行的图神经网络消息传递机制,并依托于自研的分布式图引擎以及大规模参数服务器PaddleFleet,可以支持十亿节点百亿边的超大规模图训练。分布式参数服务器PaddleFleet提供了一种高效的参数更新策略:GeoSSD,在全异步的条件下进行参数更新,降低了节点间通信对训练速度的影响。

分布式图存储以及分布式学习算法
在大规模的图网络学习中,通常需要多机图存储以及多机分布式训练。如下图所示,PGL提供一套大规模训练的解决方案,利用PaddleFleet(支持大规模分布式Embedding学习)作为参数服务器模块以及一套简易的分布式存储方案,可以轻松在MPI集群上搭建分布式大规模图学习方法。

四、Euler中的实现
官网:https://github.com/alibaba/euler
Euler由阿里妈妈工程平台团队与搜索广告算法团队开发,是集成了深度学习系统TensorFlow的基于CPU的分布式图神经网络框架,支持图分割和高效稳定的分布式训练,可以轻松支持数十亿点、数百亿边的计算规模。
该系统整体可以分为4层:最底层的分布式图引擎,GQL执行层,MessagePassing接口层,高层的图表示学习算法。

在底层图引擎部分,Euler采用了分布式存储的架构,整个图在引擎内部用哈希方法切分为多个子图,每个计算节点被分配一个或几个子图。在进行迭代图广播时,顶层操作被分解为多个对子图的操作,并由各个计算节点并行执行,充分利用了各个计算节点的计算能力。
异构图是很多复杂的业务场景必不可少的数据组织形式。为了支持异构图计算能力,底层存储按照不同的节点与边的类型分别组织。Euler-2.0还并提供了图上属性的多种索引结构,用于加速基于节点属性、边属性、邻居属性的过滤与采样。Euler-2.0在机制上支持更加丰富的异构图算法,为算法迭代创新提供更多便利。
五、Graph-Learn中的实现
官网:https://github.com/alibaba/graph-learn/blob/master/README_cn.md
Graph-Learn(原AliGraph)是面向大规模图神经网络的研发和应用而设计的一款分布式框架。 它从大规模图训练的实际问题出发,提炼和抽象了一套适合于常见图神经网络模型的编程范式, 并已经成功应用在阿里巴巴内部的诸如搜索推荐、网络安全、知识图谱等众多场景。
Graph-Learn建立在分布式环境中,因此整个图被划分并分别存储在不同的节点中。图分区的目标是最大程度地减少顶点在不同计算节点中的交叉边的数量。系统实现了4种内置的图形分区算法:METIS、顶点切割和边缘切割分区、二维分区、流式分区策略。
除此之外,为了进一步降低通信开销,Graph-Learn提出了一种在本地缓存重要顶点邻居的优化方法,但顶点邻居过多会导致存储成本增加。通过对顶点重要程度的度量,Graph-Learn可以在通信成本和存储成本之间做到很好的平衡。并且Graph-Learn证明了只需要缓存少量重要顶点即可实现通信成本的显著降低。

六、Angel Graph中的实现
官网:https://github.com/Angel-ML/angel
Angel Graph(原PSGraph)由腾讯TEG团队开发,使用Spark和PyTorch作为资源管理和计算平台,使用参数服务器架构作为分布式训练架构。Angel Graph通过参数服务器为Spark提供支持,以有效地训练数十亿规模的图数据,并将PyTorch集成到Spark中来实现神经网络的训练。Angel Graph由参数服务器、计算引擎和主节点构成。
参数服务器用于存储高维数据和模型,它支持不同的数据结构,除此之外,Angel Graph还为用户提供实现新数据结构的接口,支持按行索引和列索引的数据分区方式,提供不同的同步协议以控制工作进程之间的同步,以及实现多种常用运算符来操作参数服务器上的数据,每个参数服务器定期将本地数据分区存储到HDFS。计算引擎由Spark和PyTorch实现,用于存储数据、计算并创建参数服务器代理来管理Spark和参数服务器之间的数据通信。主节点负责资源分配、任务监视和故障恢复。

七、NeutronStar中的实现
官网:https://github.com/iDC-NEU/NeutronStarLite
是一种基于混合依赖管理的分布式图神经网络训练系统,该论文成果论文 NeutronStar: Distributed GNN Training with Hybrid Dependency Management发表在SIGMOD2022。
一个基于GPU加速的分布式图神经网络系统,在混合依赖处理策略基础之上。NeutronStar解耦了NN计算与图依赖处理操作,并提出一种灵活的自动微分框架。这样一来。NeutronStar可以使用现有GPU-优化的自动微分库来实现NN计算。此外,NeutronStar还实现了一系列优化来高效地管理依赖并调度计算任务。如chunk-based图划分,环形任务调度,无锁的并行消息队列,和通信计算重叠等等。 此外NeutronStar还提供pythonAPI以提供较好的易用性。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号