数据集格式转换:从VOC格式转YOLOv8格式(Dataset format conversion: from VOC format to YOLOv8 format)
本文以鸟巢检测数据集为例,展示如何把 voc 格式的数据集转换成 yolov8 格式数据集,本文将从数据集下载、数据集格式转换和数据集划分三个方面进行解说。
(1)数据集下载。
本次所使用的数据集是鸟巢检测数据集,该数据集共有200张图片,展示了在输电线上鸟巢的搭建情况,鸟类在这些线路杆塔上筑巢可能带来安全隐患,如引发短路事故。因此,及时检测并处理鸟巢至关重要。
数据集下载地址:https://aistudio.baidu.com/datasetdetail/110254
备注:百度飞浆的 AI Studio 数据集专栏中有很多现实场景的实用数据集,是个很好的数据集查找网址,建议收藏保存。
下载下来的数据集如下图所示:
(2)VOC 格式转 YOLOv8 格式。
代码实现:
1 import xml.etree.ElementTree as ET
2 import os
3 import re
4 from pathlib import Path
5 import shutil
6
7 file_save = "yolo_format"
8
9 # 判断是否存在保存文件,如果存在则删除文件
10 if os.path.exists(file_save):
11 shutil.rmtree(file_save)
12 # 新建文件
13 os.makedirs(file_save)
14
15 # 原始数据集标注文件路径
16 file_annotation = "E:\python_project\datasets\guojiadianwang_datasets\VOCdevkit\VOC2012\Annotations"
17
18 # 原始数据集标签
19 classes = ['ganta_02']
20
21 # 遍历所有标签文件
22 for i in os.listdir(file_annotation):
23
24 # 获取该文件最后一个/除后缀名以外的内容
25 p = Path(i)
26 name = p.stem
27
28 # 解析xml文件
29 tree = ET.parse(os.path.join(file_annotation, i))
30 root = tree.getroot() # 获取根节点
31
32 # 遍历子节点size
33 for size in root.iter('size'):
34 width = int(size.find('width').text) # 获取图片的宽度
35 height = int(size.find('height').text) # 获取图片的高度
36
37 # 遍历子节点object
38 all_content = ''
39 for obj in root.iter('object'):
40 cls = obj.find('name').text # 获取标签名
41 # 获取当前类别的id
42 cls_id = classes.index(cls)
43
44 # 获取VOC格式标签的坐标信息
45 xmlbox = obj.find('bndbox')
46 xmin = int(xmlbox.find('xmin').text)
47 ymin = int(xmlbox.find('ymin').text)
48 xmax = int(xmlbox.find('xmax').text)
49 ymax = int(xmlbox.find('ymax').text)
50
51 # 把VOC格式的坐标转换成YOLO格式坐标
52 x = (xmin+xmax)/2/width
53 y = (ymin+ymax)/2/height
54 w = (xmax-xmin)/width
55 h = (ymax-ymin)/height
56
57 # 保存当前标注框信息
58 one_content = '{} {:.4f} {:.4f} {:.4f} {:.4f}'.format(cls_id, x, y, w, h)
59 # 整合本张图像中所有标签信息
60 all_content = all_content + one_content + '\n'
61
62 # 移除字符串头尾的换行符
63 all_content = all_content.strip('\n')
64 # 新建和标签文件同名的txt文件
65 file = open(os.path.join(file_save, '{}.txt'.format(name)), 'w')
66 # 写入数据并关闭文件
67 print(all_content, file=file, flush=True)
代码运行结果:
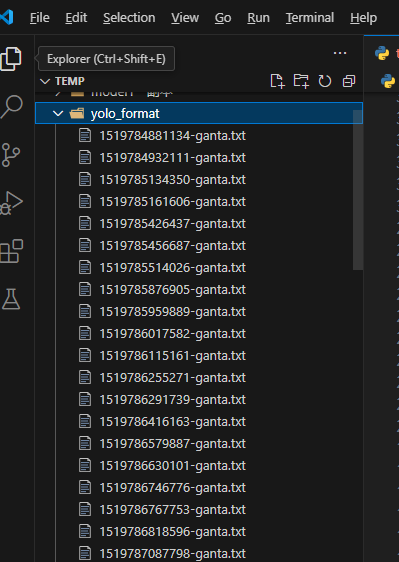
注意:原始数据标签 classes = ['ganta_02'] 的由来如果在下载绍数据集时候没有详细介绍,那么就需要我们通过代码实现获取,具体方法就是新建一个空集合,然后用 add 方法添加 obj.find('name').text 内容,最后通过集合的去重功能就可以得到标签的类型,具体主要代码如下:
data = set()
data.add(obj.find('name').text)
(3)数据集划分(这里就把数据集划分成训练集和测试集)。
代码实现:
import os
import shutil
import random
from pathlib import Path
# 原始图片路径
file_original_image = "E:\python_project\datasets\guojiadianwang_datasets\VOCdevkit\VOC2012\JPEGImages"
# 修改成yolov8格式后的标签路径
file_original_annotation = "yolo_format"
# 训练集数据存储路径
file_train = "train"
# 测试集数据存储路径
file_test = "test"
# 训练集所占比例
factor = 0.8
# 判断是否存在训练集存储路径文件,如果存在,则删除,然后新建训练集文件,训练集下的图像文件和训练集下的标签文件
if os.path.exists(file_train):
shutil.rmtree(file_train)
os.makedirs(file_train)
os.makedirs(os.path.join(file_train, "images"))
os.makedirs(os.path.join(file_train, "labels"))
# 判断是否存在测试集存储路径文件,如果存在,则删除,然后新建测试集文件,测试集下的图像文件和测试集下的标签文件
if os.path.exists(file_test):
shutil.rmtree(file_test)
os.makedirs(file_test)
os.makedirs(os.path.join(file_test, "images"))
os.makedirs(os.path.join(file_test, "labels"))
# 得到原始标签文件下的所有文件列表
datas = os.listdir(file_original_annotation)
# 得到数据集长度
num = len(datas)
# random.seed(1)
# 打乱数据集
random.shuffle(datas)
# 遍历所有标签文件
for i, j in enumerate(datas):
# 获取文件最后一个/除后缀名之外的内容,即文件名称
p = Path(j)
name = p.stem
# 获取该标签文件对应的图片
src_images = os.path.join(file_original_image, name + ".jpg")
# 获取该标签文件
src_labels = os.path.join(file_original_annotation, j)
# 判断是否是训练集,如果是则指定目的地文件目录文训练集存放图片和标签的路径,如果不是,那么久指定目的地文件目录为测试集存放图片和标签的路径
if i < num * factor:
dst_images = os.path.join(os.path.join(file_train), "images")
dst_labels = os.path.join(os.path.join(file_train), "labels")
else:
dst_images = os.path.join(os.path.join(file_test), "images")
dst_labels = os.path.join(os.path.join(file_test), "labels")
# 使用复制功能把图片从原始存放目录复制到目的地
shutil.copy(src_images, dst_images)
shutil.copy(src_labels, dst_labels)
pass
代码运行结果:
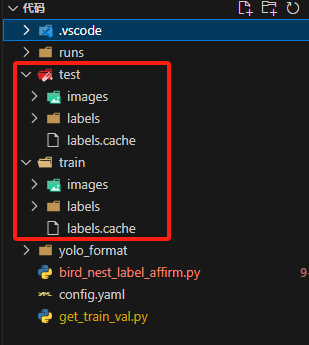
由此就可以实现把数据集从 VOC 格式转换成 YOLOv8 格式,并且也实现了数据集划分成训练集和测试集的过程。
数据集划分好之后,就可以使用 YOLOv8 对数据集进行目标检测,具体实现可参考 “yolov8 训练自定义数据集(windows+CPU)” 一文。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号