基于ResNet的花卉图片分类 —— tensorflow版(Flowers image classification based on ResNet——tensorflow)
最近看了《TensorFlow深度学习实战(微课视频版)》 —— 清华大学出版社一书中的 11 章节《基于ResNet的花卉图片分类》,觉得写的不错,是个关于ResNet的好例子,所以整理下,分享给大家~
本代码使用 Tensorflow 框架,搭建 ResNet50 模型,对花卉数据集 —— Oxford 102 Flowers 中的图片进行迁移学习,从而实现对花卉图片的分类任务。
1. 环境搭建
python==3.7
tensorflow==2.5.0
scipy==1.6.2
Pillow==6.2.0
joblib==1.0.1
本人使用的是 CPU 进行训练
2. 数据集
数据集网址:https://www.robots.ox.ac.uk/~vgg/data/flowers/102/
3. 划分数据集
获取数据集后,还要根据数据集的划分文件对数据集进行划分。Python urllib 库提供了 urlretrieve() 函数可以直接将远程数据下载到本地。可以使用 urlretrieve() 函数下载所需文件;然后把压缩的图片文件进行解压,并解析分类标记文件和数据集划分文件;再根据数据集划分文件把数据集分成训练集、验证集和测试集;最后,向不同类别的数据集中按图片所标识的花的种类分类存放图片文件。代码如下所示:
1 # encoding: utf-8
2 import os
3 from urllib.request import urlretrieve
4 import tarfile
5 from scipy.io import loadmat
6 from shutil import copyfile
7 import glob
8 import numpy as np
9
10
11 # 函数说明:按照分类(labels)拷贝未分组的图片到指定的位置
12 # Parameters:
13 # data_path - 数据存放目录
14 # labels - 数据对应的标签,需要按标签放到不同的目录
15 def copy_data_files(data_path, labels):
16 if not os.path.exists(data_path):
17 os.mkdir(data_path)
18
19 # 创建分类目录,该数据集一共有102个类别
20 for i in range(0, 102):
21 os.mkdir(os.path.join(data_path, str(i)))
22
23 for label in labels:
24 # 原图片路径
25 src_path = str(label[0])
26 # 目的图片路径
27 dst_path = os.path.join(data_path, label[1], src_path.split(os.sep)[-1])
28 copyfile(src_path, dst_path)
29
30
31 if __name__ == '__main__':
32 # 检查本地数据集目录是否存在,不存在则创建
33 data_set_path = "./data"
34 if not os.path.exists(data_set_path):
35 os.mkdir(data_set_path)
36
37 # 下载 102 Category Flower 数据集并解压(图片文件)
38 flowers_archive_file = "102flowers.tgz"
39 # 官网网址
40 flowers_url_frefix = "https://www.robots.ox.ac.uk/~vgg/data/flowers/102/"
41 flowers_archive_path = os.path.join(data_set_path, flowers_archive_file)
42 if not os.path.exists(flowers_archive_path):
43 print("正在下载图片文件...")
44 urlretrieve(flowers_url_frefix + flowers_archive_file, flowers_archive_path)
45 print("图片文件下载完成.")
46 print("正在解压图片文件...")
47 tarfile.open(flowers_archive_path).extractall(path=data_set_path)
48 print("图片文件解压完成.")
49
50 # 下载标识文件,标识不同文件的类别(标签文件)
51 flowers_labels_file = "imagelabels.mat"
52 flowers_labels_path = os.path.join(data_set_path, flowers_labels_file)
53 if not os.path.exists(flowers_labels_path):
54 print("正在下载标识文件...")
55 urlretrieve(flowers_url_frefix + flowers_labels_file, flowers_labels_path)
56 print("标识文件下载完成")
57 flower_labels = loadmat(flowers_labels_path)['labels'][0] - 1
58
59 # 下载数据集分类文件,包含训练集、验证集和测试集(数据集划分文件)
60 sets_splits_file = "setid.mat"
61 sets_splits_path = os.path.join(data_set_path, sets_splits_file)
62 if not os.path.exists(sets_splits_path):
63 print("正在下载数据集分类文件...")
64 urlretrieve(flowers_url_frefix + sets_splits_file, sets_splits_path)
65 print("数据集分类文件下载完成")
66 sets_splits = loadmat(sets_splits_path)
67
68 # 由于数据集分类文件中测试集数量比训练集多,所以进行了对调,并且把索引值-1,让它们从0开始
69 train_set = sets_splits['tstid'][0] - 1
70 valid_set = sets_splits['valid'][0] - 1
71 test_set = sets_splits['trnid'][0] - 1
72
73 # 获取图片文件名并找到图片对应的分类标识
74 image_files = sorted(glob.glob(os.path.join(data_set_path, 'jpg', '*.jpg')))
75 # image_labels的大小是[8189, 2],第一列是图片名称,第二列是花的标签
76 image_labels = np.array([i for i in zip(image_files, flower_labels)])
77
78 # 将训练集、验证集和测试集分别放在不同的目录下
79 print("正在进行训练集的拷贝...")
80 copy_data_files(os.path.join(data_set_path, 'train'), image_labels[train_set, :])
81 print("已完成训练集的拷贝,开始拷贝验证集...")
82 copy_data_files(os.path.join(data_set_path, 'valid'), image_labels[valid_set, :])
83 print("已完成验证集的拷贝,开始拷贝测试集...")
84 copy_data_files(os.path.join(data_set_path, 'test'), image_labels[test_set, :])
85 print("已完成测试集的拷贝,所有的图片下载和预处理工作已完成.")
86
处理好后的结果如下图所示:

4. 训练模型代码
1 import numpy as np
2 import os
3 import glob
4 import math
5 from os.path import join as join_path
6 import joblib
7 from tensorflow.keras import backend as K
8 from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
9 from tensorflow.keras.preprocessing.image import ImageDataGenerator
10 from tensorflow.keras.optimizers import Adam
11 from tensorflow.keras.applications.resnet50 import ResNet50
12 from tensorflow.keras.layers import (Input, Flatten, Dense, Dropout)
13 from tensorflow.keras.models import Model
14
15
16 # 函数说明:该函数用于重写 DirectoryIterator 的 next 函数,用于将 RGB 通道换成 BGR 通道
17 def override_keras_directory_iterator_next():
18 from keras.preprocessing.image import DirectoryIterator
19
20 original_next = DirectoryIterator.next
21
22 # 防止多次覆盖
23 if 'custom_next' in str(original_next):
24 return
25
26 def custom_next(self):
27 batch_x, batch_y = original_next(self)
28 batch_x = batch_x[:, ::-1, :, :]
29 return batch_x, batch_y
30
31 DirectoryIterator.next = custom_next
32
33
34 # 函数说明:创建 ResNet50 模型
35 # Parameters:
36 # classes - 所有的类别
37 # image_size - 输入图片的尺寸
38 # Returns:
39 # Model - 模型
40 def create_resnet50_model(classes, image_size):
41 # 利用 Keras 的 API 创建模型,并在该模型的基础上进行修改
42 # include_top:是否保留顶层的全连接网络;input_tensor: 可选,可填入 Keras tensor 作为模型的输入(即 layers.Input() 输出的 tensor)
43 # 权重下载地址:https://github.com/fchollet/deep-learning-models/releases/download/v0.1/resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5
44 # 注意,一定要使用v0.1版本,不能使用v0.2版本,不然会报错
45 base_model = ResNet50(include_top=False, input_tensor=Input(shape=image_size + (3,)),
46 weights="resnet50_weights_tf_dim_ordering_tf_kernels_notop_v0.1.h5")
47 num = 0
48 for layer in base_model.layers:
49 num = num + 1
50 layer.trainable = False
51 print("num = ", num)
52
53 x = base_model.output
54 x = Flatten()(x)
55 x = Dropout(0.5)(x)
56 output = Dense(len(classes), activation='softmax', name='predictions')(x)
57 return Model(inputs=base_model.input, outputs=output)
58
59
60 # 函数说明:根据每一类图片的数量不同给每一类图片附上权重
61 # Parameters:
62 # classes - 所有的类别
63 # dir - 图片所在的数据集类别的目录,可以是训练集或验证集
64 # Returns:
65 # classes_weight - 每一类的权重
66 def get_classes_weight(classes, dir):
67 class_number = dict()
68 # k = 0
69 # 获取每一类的图片数量
70 for class_name in classes:
71 # !!!原先错误代码,因为classed并不是按照自然顺序排序
72 # class_number[k] = len(glob.glob(os.path.join(dir, class_name, '*.jpg')))
73 # k += 1
74 class_number[int(class_name)] = len(glob.glob(os.path.join(dir, class_name, '*.jpg')))
75
76 # 计算每一类的权重
77 total = np.sum(list(class_number.values())) # 总图片数
78 max_samples = np.max(list(class_number.values())) # 最大的图片数量
79 mu = 1. / (total / float(max_samples))
80 keys = class_number.keys()
81 classes_weight = dict()
82 for key in keys:
83 # 约等于 ln( float(max_samples)/float(class_number[key]) )
84 score = math.log(mu * total / float(class_number[key]))
85 classes_weight[key] = score if score > 1. else 1.
86
87 return classes_weight
88
89
90 if __name__ == '__main__':
91 # 训练集、验证集、模型输出目录
92 train_dir = "./data/train"
93 valid_dir = "./data/valid"
94 output_dir = "./saved_model"
95
96 # 经过训练后的权重、模型、分类文件
97 fine_tuned_weights_path = join_path(output_dir, 'fine-tuned-resnet50-weights.h5')
98 weights_path = join_path(output_dir, 'model-weights.h5')
99 model_path = join_path(output_dir, 'model-resnet50.h5')
100 classes_path = join_path(output_dir, 'classes-resnet50')
101
102 # 创建输出目录
103 if not os.path.exists(output_dir):
104 os.mkdir(output_dir)
105
106 # 由于使用 tensorflow 作为 keras 的 backone,所以图片格式设置为 channels_last
107 # 修改 DirectoryIterator 的 next 函数,改变 GRB 通道顺序
108 # 设置图片数据格式,channels_last表示图片数据的通道在最后一个维度
109 K.set_image_data_format('channels_last')
110 override_keras_directory_iterator_next()
111
112 # 获取花卉数据类别(不同类别的图片放在不同的目录下,获取目录名即可)
113 # classes = sorted([o for o in os.listdir(train_dir) if os.path.isdir(os.path.join(train_dir, o))])
114 classes = sorted([o for o in os.listdir(train_dir) if os.path.isdir(os.path.join(train_dir, o))], key=int)
115
116 # 获取花卉训练和验证图片的数量
117 train_sample_number = len(glob.glob(train_dir + '/**/*.jpg'))
118 valid_sample_number = len(glob.glob(valid_dir + '/**/*.jpg'))
119
120 # 创建 Resnet50 模型
121 image_size = (224, 224)
122 model = create_resnet50_model(classes, image_size)
123
124 # 冻结前 fr_n 层
125 fr_n = 10
126 for layer in model.layers[:fr_n]:
127 layer.trainable = False
128 for layer in model.layers[fr_n:]:
129 layer.trainable = True
130
131 # 模型配置,使用分类交叉熵作为损失函数,使用 Adam 作为优化器,步长是 1e-5,并使用精确的性能指标
132 model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=1e-5), metrics=['accuracy'])
133
134 # 获取训练数据和验证数据的 generator
135 channels_mean = [103.939, 116.779, 123.68]
136 # otation_range: 整数。随机旋转的度数范围。
137 # shear_range: 浮点数。剪切强度(以弧度逆时针方向剪切角度)。
138 # zoom_range: 浮点数 或 [lower, upper]。随机缩放范围。如果是浮点数,[lower, upper] = [1-zoom_range, 1+zoom_range]。
139 # horizontal_flip: 布尔值。随机水平翻转。
140 image_data_generator = ImageDataGenerator(rotation_range=30., shear_range=0.2, zoom_range=0.2, horizontal_flip=True)
141 image_data_generator.mean = np.array(channels_mean, dtype=np.float32).reshape((3, 1, 1))
142 # 从文件夹中读取图像
143 # 第一个参数是 directory:目标文件夹路径,对于每一个类,该文件夹都要包含一个子文件夹。
144 # target_size:整数tuple,默认为(256, 256)。图像将被resize成该尺寸
145 # classes:可选参数,为子文件夹的列表,如['cat','dog'],默认为None。若未提供,则该类别列表将从directory下的子文件夹名称/结构自动推断。每一个
146 # 子文件夹都会被认为是一个新的类。(类别的顺序将按照字母表顺序映射到标签值)。
147 train_data = image_data_generator.flow_from_directory(train_dir, target_size=image_size, classes=classes)
148
149 image_data_generator = ImageDataGenerator()
150 image_data_generator.mean = np.array(channels_mean, dtype=np.float32).reshape((3, 1, 1))
151 valid_data = image_data_generator.flow_from_directory(valid_dir, target_size=image_size, classes=classes)
152
153 # 回调函数,用于在训练过程中输出当前进度和设置是否保存过程中的权重,以及早停的判断条件和输出
154 # 该回调函数将在每个epoch后保存模型到filepath
155 # 第一个参数是保存模型的路径;save_best_only:当设置为True时,将只保存在验证集上性能最好的模型
156 # save_weights_only:若设置为True,则只保存模型权重,否则将保存整个模型(包括模型结构,配置信息等)
157 # monitor:需要监视的值,通常为:val_acc 或 val_loss 或 acc 或 loss
158 model_checkpoint_callback = ModelCheckpoint(fine_tuned_weights_path, save_best_only=True, save_weights_only=True, monitor='val_loss')
159 # early stop是训练模型的过程中,避免过拟合,节省训练时间的一种非常场用的方法。
160 # verbose:是否输出更多的调试信息。
161 # patience: 在监控指标没有提升的情况下,epochs 等待轮数。等待大于该值监控指标始终没有提升,则提前停止训练。
162 # monitor: 监控指标,如val_loss
163 early_stopping_callback = EarlyStopping(verbose=1, patience=20, monitor='val_loss')
164
165 # 获取不同类别的权重
166 class_weight = get_classes_weight(classes, train_dir)
167 batch_size = 10.0
168 epoch_number = 50
169
170 print("开始训练...")
171 # 利用Python的生成器,逐个生成数据的batch并进行训练。生成器与模型将并行执行以提高效率。
172 # 该函数允许我们在CPU上进行实时的数据提升,同时在GPU上进行模型训练
173 model.fit(
174 train_data, # 生成器函数
175 # steps_per_epoch=train_sample_number / batch_size, # 每轮的步数,整数,当生成器返回 stesp_per_epoch次数据时,进入下一轮。
176 epochs=epoch_number, # 数据的迭代次数
177 validation_data=valid_data, # 验证集数据
178 validation_steps=valid_sample_number / batch_size, # 当validation_data为生成器时,本参数指定验证集的生成器返回次数
179 callbacks=[early_stopping_callback, model_checkpoint_callback],
180 class_weight=class_weight # 规定类别权重的字典,将类别映射为权重,常用于处理样本不均衡问题。
181 )
182 print("模型训练结束,开始保存模型..")
183 model.save(model_path)
184 model.save_weights(weights_path)
185 joblib.dump(classes, classes_path)
186 print("模型保存成功,训练任务全部结束.")
187 pass
注意:权重下载地址:https://github.com/fchollet/deep-learning-models/releases/download/v0.1/resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5
注意这里一定要使用v0.1版本,不能使用v0.2版本,不然会报错
本人跑了 50 个 epoch 就达到了 99.56% 的准确率
5. 预测模型结果代码
1 import os
2 import numpy as np
3 from tensorflow.keras.preprocessing import image
4 from tensorflow.keras.applications.imagenet_utils import preprocess_input
5 from train_copy import create_resnet50_model
6 from tensorflow.keras.models import load_model
7
8 if __name__ == '__main__':
9 # 需要预测的图片的位置
10 # predict_image_path = "./data/test/22/image_03399.jpg"
11 predict_image_path = "./data/test/74/image_02075.jpg"
12
13 # 图片预处理
14 image_size = (224, 224)
15 img = image.load_img(predict_image_path, target_size=image_size) # 此时导入的图片是PIL格式
16 img_array = np.expand_dims(image.img_to_array(img), axis=0) # 把图片转换成numpy
17 prepared_img = preprocess_input(img_array) # Preprocesses a tensor or Numpy array encoding a batch of images
18
19 # 获取花卉数据类别(不同类别的图片放在不同的目录下,获取目录名即可)
20 test_dir = "./data/test"
21 # classes = sorted([o for o in os.listdir(test_dir) if os.path.isdir(os.path.join(test_dir, o))])
22 classes = sorted([o for o in os.listdir(test_dir) if os.path.isdir(os.path.join(test_dir, o))], key=int)
23
24 # 创建模型并导入训练后的权重
25 # 两种方法:第一种导入模型权重
26 model = create_resnet50_model(classes, image_size)
27 model.load_weights("./saved_model/model-weights.h5")
28 # 另一种方法是导入整个模型
29 # model = load_model("./saved_model/model-resnet50.h5")
30
31 # 预测
32 out = model.predict(prepared_img)
33
34 top10 = out[0].argsort()[-10:][::-1]
35
36 class_indices = dict(zip(classes, range(len(classes))))
37 keys = list(class_indices.keys())
38 values = list(class_indices.values())
39
40 print("Top10 的分类及概率:")
41 for i, t in enumerate(top10):
42 print("class:", keys[values.index(t)], "probability:", out[0][t])
代码运行结果:
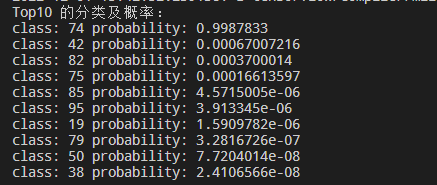
注意:根据数据集划分代码可知,test 文件下的文件序号名就是最终的类别,现在测试的是 test 74 文件中的内容,而最终的结果也是 74 类别排名第一,准确率高达99%,可知分类效果不错。
有问题的话欢迎大家多多指正~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号