yolov5 train.py 源码文件代码运行结果说明(Description of the running results of the source code file of yolov5)
在运行yolov5 train.py 源码文件时,产生了一些结果,以下对这些结果的来源进行详细分析。
本人代码运行环境 windows10 CPU 设置了epoch = 5
本人运行 train.py 代码的时候产生了如下文件:
接下来我们按照时间顺序,来分析下这些文件的来源出处。
1. weights 中的 best.pt 和 last.pt 文件代码来源
# 开始训练
for epoch in range(start_epoch, epochs): # epoch ---------------一个epoch开始---------------------------
callbacks.run('on_train_epoch_start')
model.train()
......
for i, (imgs, targets, paths, _) in pbar: # batch ---------------一个batch开始---------------------
......
# end batch -------------------一个batch结束---------------------------------------
# Scheduler 一个epoch训练结束后都要调整学习率(学习率衰减)group中三个学习率(pg0、pg1、pg2)每个都要调整
lr = [x['lr'] for x in optimizer.param_groups] # for loggers
scheduler.step()
# validation# DDP process 0 or single-GPU
if RANK in {-1, 0}:
......
if not noval or final_epoch:
......
# Save model
# if save 如果 没有不保存模型或者是最后一轮的epoch并且不进行超参数进化
if (not nosave) or (final_epoch and not evolve):
# --------------------->>>>
ckpt = {
'epoch': epoch,
'best_fitness': best_fitness,
'model': deepcopy(de_parallel(model)).half(),
'ema': deepcopy(ema.ema).half(),
'updates': ema.updates,
'optimizer': optimizer.state_dict(),
'wandb_id': loggers.wandb.wandb_run.id if loggers.wandb else None,
'opt': vars(opt),
'date': datetime.now().isoformat()}
# Save last, best and delete
# 保存模型,这里是model与ema都保存了的,还保存了epoch,results,optimizer等信息,
torch.save(ckpt, last) # 在weights文件夹下保存last.pt
if best_fitness == fi:
torch.save(ckpt, best) # 在weights文件夹下保存best.pt
# 如果规定了多少个epoch保存一下模型那么就要保存epochn.pt文件
if opt.save_period > 0 and epoch % opt.save_period == 0:
torch.save(ckpt, w / f'epoch{epoch}.pt')
del ckpt
callbacks.run('on_model_save', last, epoch, final_epoch, best_fitness, fi)
......
# end epoch -----------------一个epoch结束----------------------------------
last.pt : 训练完最后一个 epoch 所保存的模型文件
best.pt : 计算得到最好的 fi(fi是[P, R, mAP@.5, mAP@.5-.95]的一个加权值 = 0.1*mAP@.5 + 0.9*mAP@.5-.95)时保存的模型文件
2. hyp.yaml 和 opt.yaml 2个文件代码来源
1 # Save run settings
2 if not evolve:
3 # ------------------>>>>> 如果不使用进化训练,那么就保存hyp和opt两个参数文件
4 # yaml.safe_dump 函数是将一个python值转换为yaml格式文件
5 with open(save_dir / 'hyp.yaml', 'w') as f:
6 yaml.safe_dump(hyp, f, sort_keys=False)
7 with open(save_dir / 'opt.yaml', 'w') as f:
8 # vars() 函数返回对象object的属性和属性值的字典对象。
9 yaml.safe_dump(vars(opt), f, sort_keys=False)
hyp.yaml 是保存此次代码运行的超参数文件。
opt.yaml 是保存此次代码运行所设置的参数情况文件。
3. labels.jpg 和 labels_correlogram.jpg 图片代码来源
# Process 0
if RANK in {-1, 0}:
# --------------------->>>>>
# 加载验证集数据集
val_loader = create_dataloader(val_path,
imgsz,
batch_size // WORLD_SIZE * 2,
gs,
single_cls,
hyp=hyp,
cache=None if noval else opt.cache,
rect=True,
rank=-1,
workers=workers * 2,
pad=0.5,
prefix=colorstr('val: '))[0]
# 如果不使用断点继续训练
if not resume:
# ---------------------->>>>>
if plots:
# ---------------------->>>>>
# 可视化labels信息
# 画 labels_correlogram.jpg 和 labels.jpg(4个图像) 两张图片
plot_labels(labels, names, save_dir)
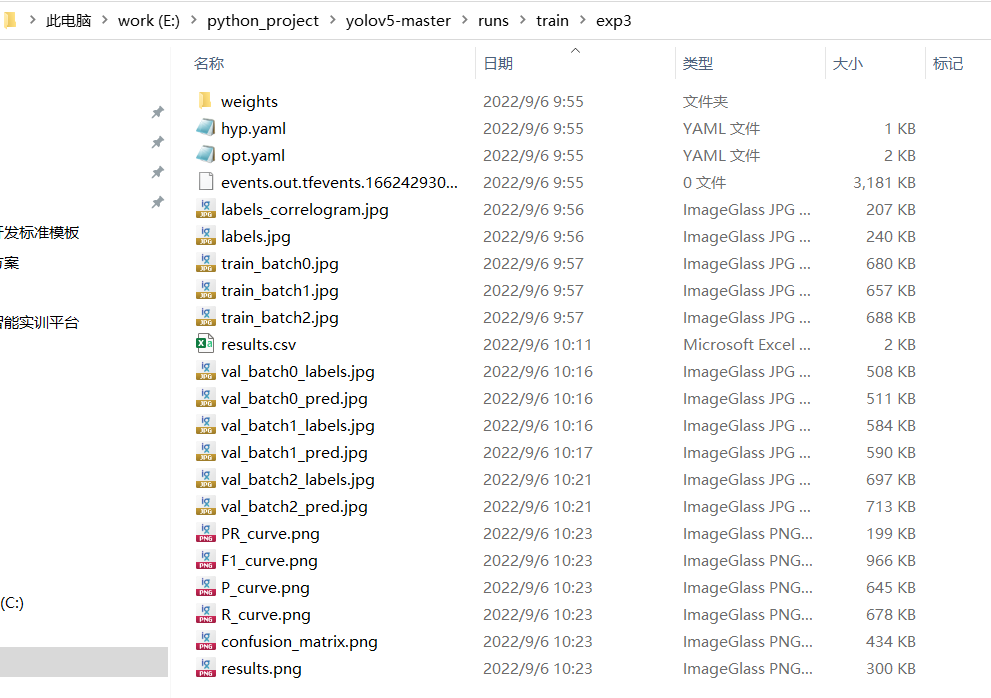
labels.jpg : 统计训练集数据每个类别数量直方图(左上角)、把所有框的x和y中心值设置在相同位置看每个训练集数据每个标签框的长宽情况(右上角)、绘制 x, y 变量直方图来显示数据集的分布(左下角)、绘制 width, height 变量直方图来显示数据集的分布(右下角)。
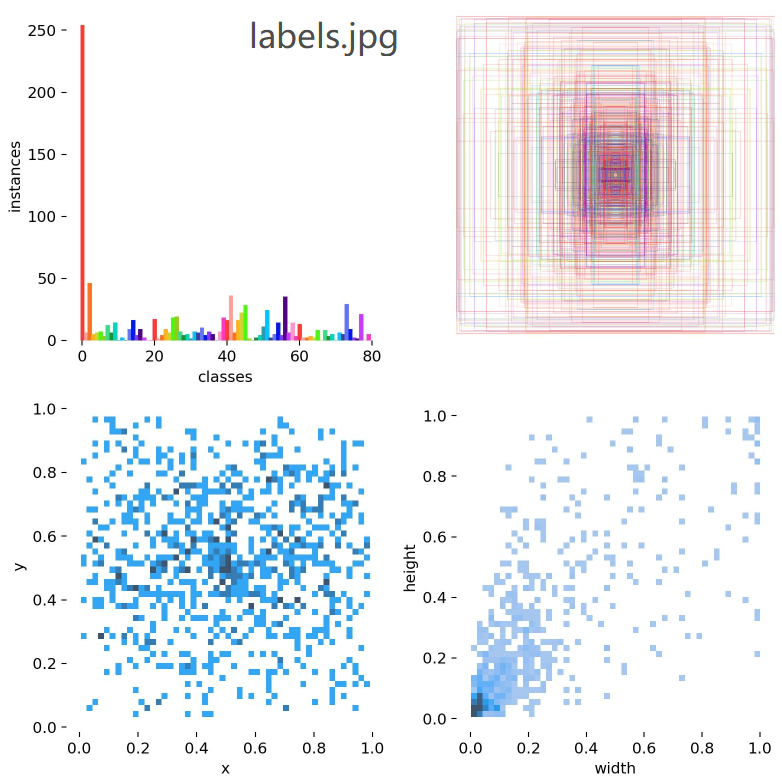
labels_correlogram.jpg : 汇总训练集数据的标签labels,并画出训练集数据标签 x, y, width, height 4个变量之间的关系图(线性或非线性,有无较为明显的相关关系)
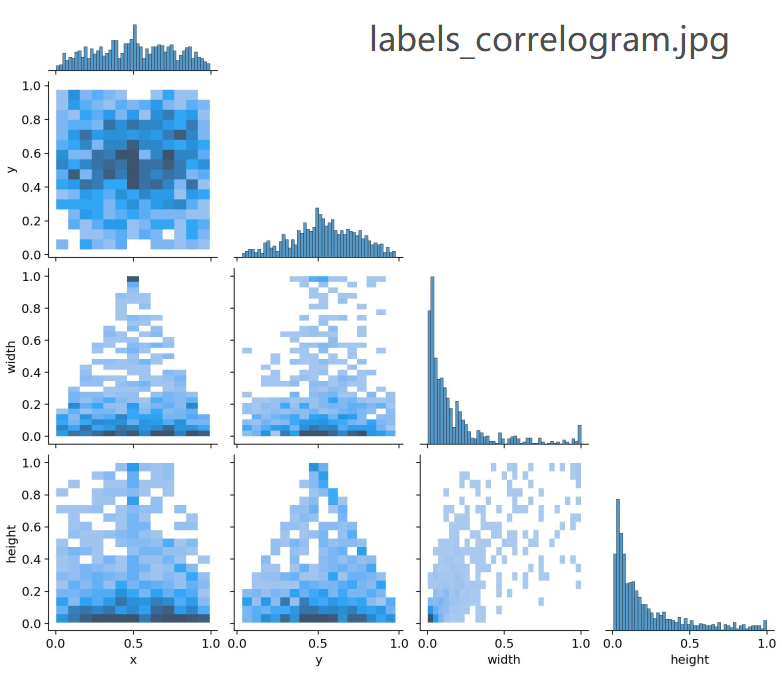
4. train_batch0.jpg , train_batch1.jpg , train_batch2.jpg 图片代码来源
for i, (imgs, targets, paths, _) in pbar: # batch -----------------一个batch开始---------------- ......
# Log # 打印Print一些信息 包括当前epoch、显存、损失(box、obj、cls、total)、当前batch的target的数量和图片的size等信息 if RANK in {-1, 0}: ...... callbacks.run('on_train_batch_end', ni, model, imgs, targets, paths, plots) # 这里保存train_batch.jpg图片 ...... # end batch ---------------一个batch结束---------------------------------
这些图片画出了第一个训练的 epoch 中这前三个 batch 训练模型所使用的训练集图片以及它的标签
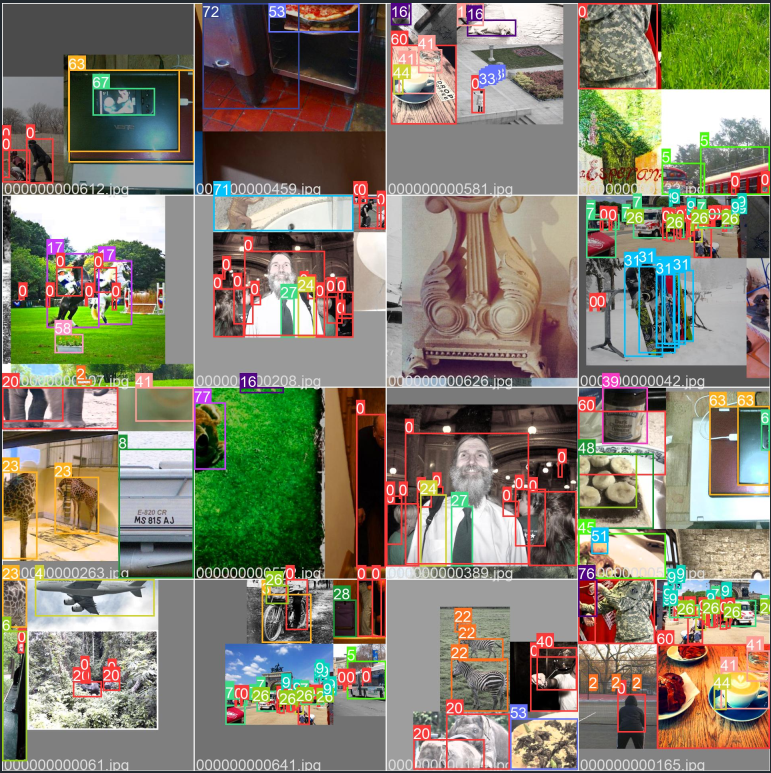


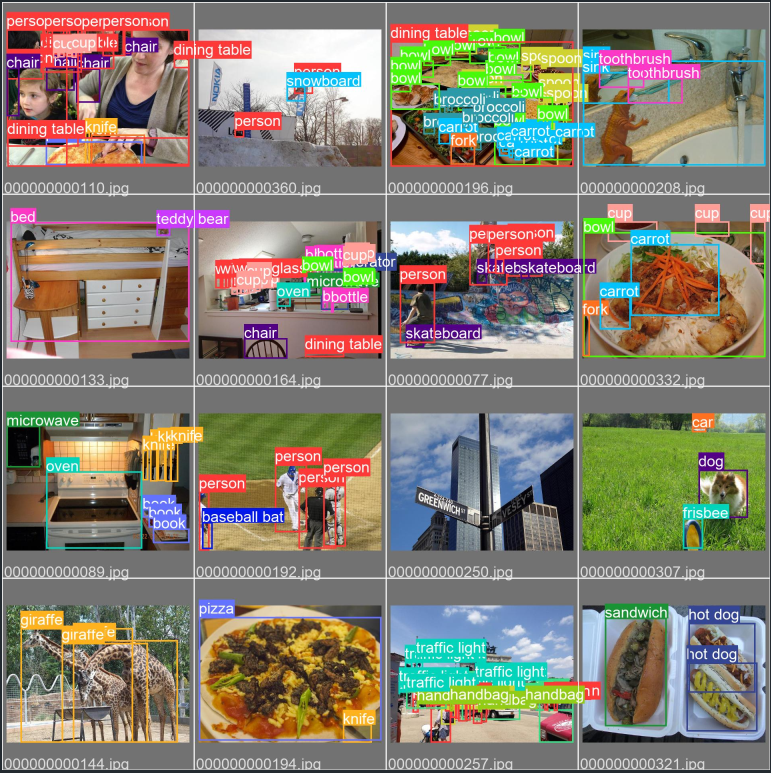
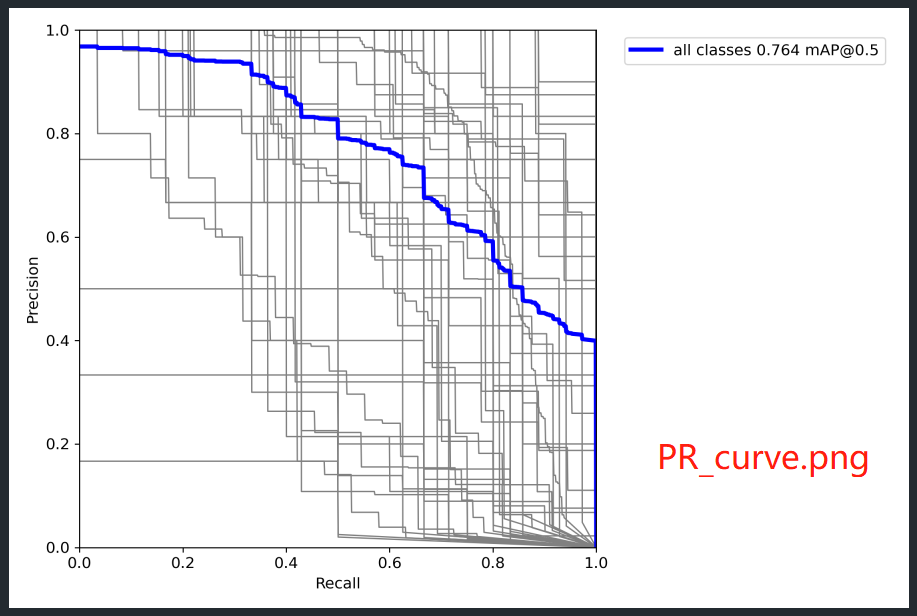
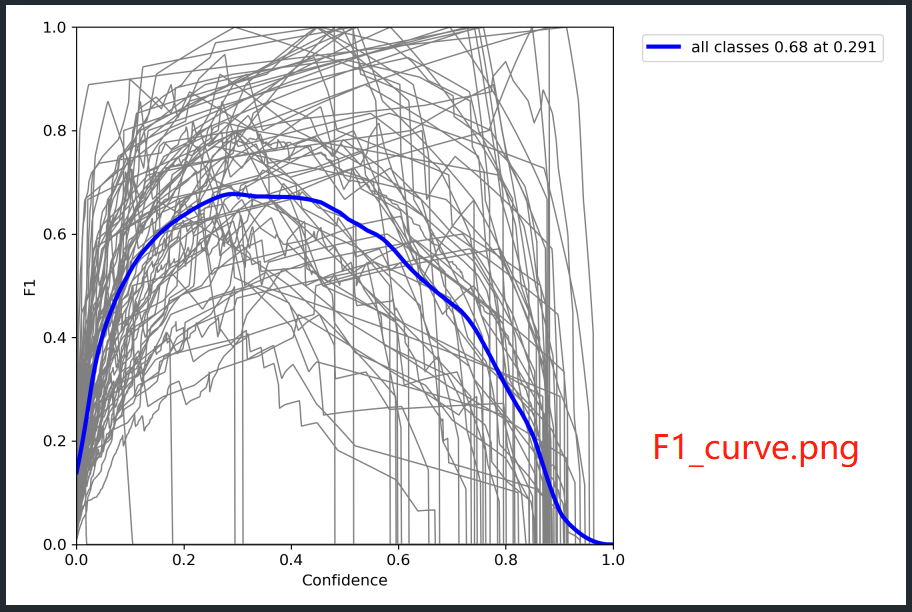
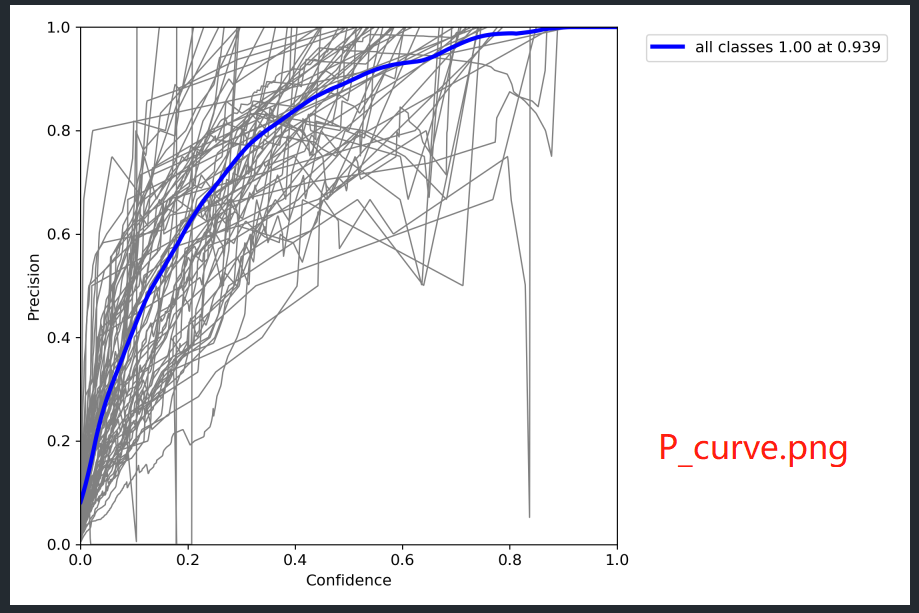
5. val_batch0_labels.jpg , val_batch0_pred.jpg , val_batch1_labels.jpg , val_batch1_pred.jpg , val_batch2_labels.jpg , val_batch2_pred.jpg , PR_curve.png , F1_curve.png , P_curve.png , R_curve.png , confusion_matrix.png 图片代码来源
# end training ----------------------------
if RANK in {-1, 0}:
LOGGER.info(f'\n{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.')
for f in last, best:
if f.exists():
# 模型训练完成后,strip—optimizer 函数将optimizer 从ckpt中去除.并对模型进行model.half()将Float32->Float16这样可以
# 减少模型大小, 提高inference速度
strip_optimizer(f) # strip optimizers
if f is best:
LOGGER.info(f'\nValidating {f}...')
results, _, _ = val.run(
data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
model=attempt_load(f, device).half(),
iou_thres=0.65 if is_coco else 0.60, # best pycocotools results at 0.65
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
save_json=is_coco,
verbose=True,
plots=plots, # 这时候这里为true就会画相关的结果图
callbacks=callbacks,
compute_loss=compute_loss) # val best model with plots
画这些图的代码在 train.py 文件中 val.run() 函数当中的如下代码:
@torch.no_grad()
def run(
......
):
......
pbar = tqdm(dataloader, desc=s, bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
for batch_i, (im, targets, paths, shapes) in enumerate(pbar):
......# Plot images
# val_batch_labels.jpg和val_batch_pred.jpg是在这里画的
if plots and batch_i < 3:
plot_images(im, targets, paths, save_dir / f'val_batch{batch_i}_labels.jpg', names) # labels
plot_images(im, output_to_target(out), paths, save_dir / f'val_batch{batch_i}_pred.jpg', names) # pred
callbacks.run('on_val_batch_end')
# Compute metrics
stats = [torch.cat(x, 0).cpu().numpy() for x in zip(*stats)] # to numpy
if len(stats) and stats[0].any():
# PR_curve.png F1_curve.png P_curve.png R_curve.png 四幅图像是在这里画的
tp, fp, p, r, f1, ap, ap_class = ap_per_class(*stats, plot=plots, save_dir=save_dir, names=names)
ap50, ap = ap[:, 0], ap.mean(1) # AP@0.5, AP@0.5:0.95
mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean()
......# Plots
if plots:
confusion_matrix.plot(save_dir=save_dir, names=list(names.values())) # confusion_matrix.png在这里保存
callbacks.run('on_val_end')
......return (mp, mr, map50, map, *(loss.cpu() / len(dataloader)).tolist()), maps, t
val_batch0_labels.jpg , val_batch0_pred.jpg , val_batch1_labels.jpg , val_batch1_pred.jpg , val_batch2_labels.jpg , val_batch2_pred.jpg 这6张图片分别是在训练完模型之后用对验证集数据进行验证的的原始标签图和预测结果图。





PR_curve.png , F1_curve.png , P_curve.png , R_curve.png , confusion_matrix.png 分别是对训练得到的模型结果的测评图。

6. results.csv 文件代码来源
# 开始训练
for epoch in range(start_epoch, epochs): # epoch -----------一个epoch开始---------------
......
for i, (imgs, targets, paths, _) in pbar: # batch -------------一个batch开始----------------
......
# end batch -----------------一个batch结束--------------------------------
# Scheduler 一个epoch训练结束后都要调整学习率(学习率衰减)group中三个学习率(pg0、pg1、pg2)每个都要调整
lr = [x['lr'] for x in optimizer.param_groups] # for loggers
scheduler.step()
# validation# DDP process 0 or single-GPU
if RANK in {-1, 0}:
......
if not noval or final_epoch:
# --------------------->>>>
# 验证的时候使用的是ema(指数移动平均 对模型的参数做平均)的模型
# results: [1] Precision 所有类别的平均precision(最大f1时)
# [1] Recall 所有类别的平均recall
# [1] map@0.5 所有类别的平均mAP@0.5
# [1] map@0.5:0.95 所有类别的平均mAP@0.5:0.95
# [1] box_loss 验证集回归损失, obj_loss 验证集置信度损失, cls_loss 验证集分类损失
# maps: [80] 所有类别的mAP@0.5:0.95
results, maps, _ = val.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
half=amp,
model=ema.ema,
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
plots=False, # 这里是False,所以不会画图
callbacks=callbacks,
compute_loss=compute_loss)
# Update best mAP 更新到最好的best_fitness 这里的best mAP其实是[P, R, mAP@.5, mAP@.5-.95]的一个加权值
# fi: [P, R, mAP@.5, mAP@.5-.95]的一个加权值 = 0.1*mAP@.5 + 0.9*mAP@.5-.95
fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
stop = stopper(epoch=epoch, fitness=fi) # early stop check
if fi > best_fitness:
best_fitness = fi
log_vals = list(mloss) + list(results) + lr
callbacks.run('on_fit_epoch_end', log_vals, epoch, best_fitness, fi) # result.csv 是在这里保存的
......
# end epoch -----------------一个epoch结束-------------------------------------
result.csv 里面存放的是每次epoch训练完之后得到的各项损失、精确度、mAP值、lr 等信息。

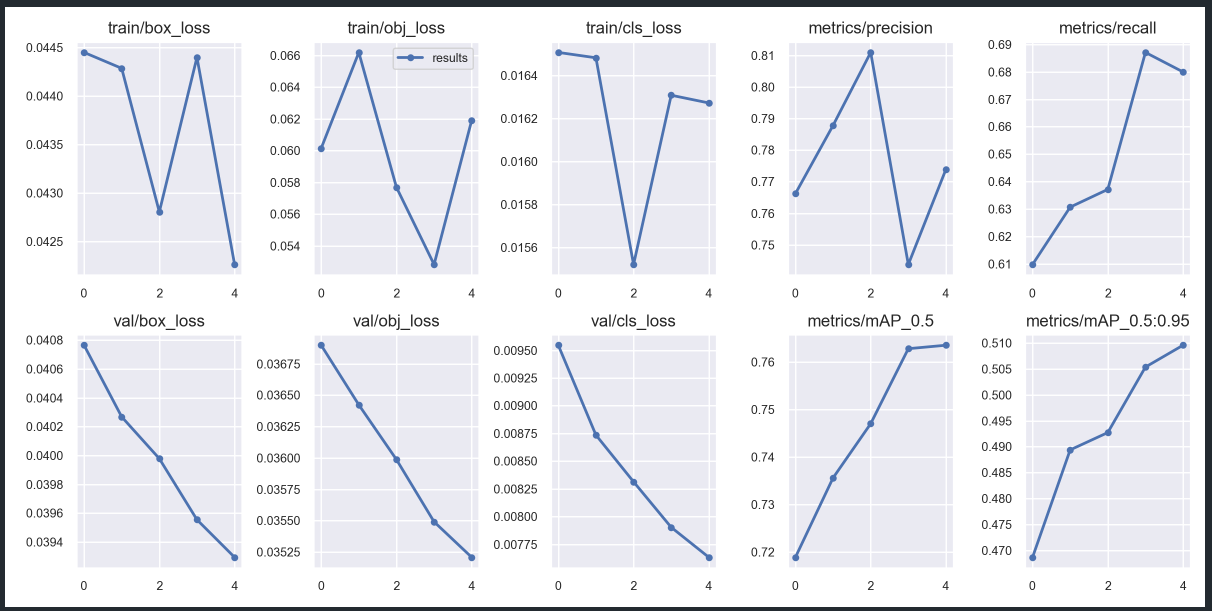
7. results.png 图片代码来源
# end training -----------------------------------------------------------------------------------------------------
if RANK in {-1, 0}:
......
callbacks.run('on_train_end', last, best, plots, epoch, results) # result.png是在这里画的
results.png 图片是画出 results.csv 文件中前10项数据图
至此,以上就是本人在运行 yolov5 的 train.py 并设置为epoch等于5的时候所生成的文件的解析,如果有错误欢迎大家批评指证~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号