数据清洗与预处理代码详解——德国信贷数据集(data cleaning and preprocessing - German credit datasets)
最近看了一本《Python金融大数据风控建模实战:基于机器学习》(机械工业出版社)这本书,看了其中第4章:数据清洗和预处理的内容,了解了代码,觉得写的不错,所以分享给大家。
1. 数据集
德国信贷数据集。官网地址 http://archive.ics.uci.edu/ml/datasets/Statlog+%28German+Credit+Data%29 。
该数据集包含 1000条样本数据,其中有20个标签变量('status_account', 'duration', 'credit_history', 'purpose', 'amount', 'svaing_account', 'present_emp', 'income_rate', 'personal_status', 'other_debtors', 'residence_info', 'property', 'age', 'inst_plans', 'housing', 'num_credits', 'job', 'dependents', 'telephone', 'foreign_worker')和1个结果变量('target')。
数据集以及说明我已经上传到网盘中的 “德国评分卡信贷数据集” 文件内:
链接:https://pan.baidu.com/s/1dNzrVkpsXtO7uXyrMxADhA?pwd=6611
提取码:6611
2. 代码思路
数据清洗和预处理的一般流程:
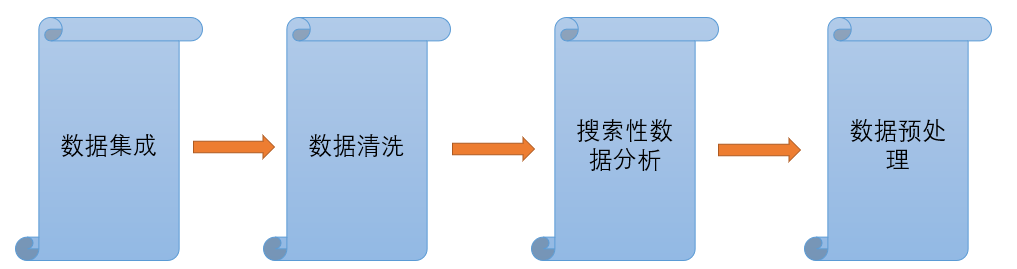
(1)数据集成:将多个数据源的数据构成一个统一的数据结构或数据表的过程。
(2)数据清洗:即清除“脏数据”的过程。数据清洗包括特殊字符清洗、数据格式转换、数据概念统一、数据类型转换和样本去冗余等。
(3)探索性数据分析(Exploratory Data Analysis,EDA)又称为描述性统计分析,是一种通过计算统计量、数据可视化等方法,快速了解原始数据的结构与规律的一种数据分析方法。
(4)数据预处理:对缺失值、异常值等“脏数据”进行处理的过程。
3. python代码详解(代码来自该书第四章内容),代码已经写了详细注释,该代码相对简单,只要认真走一遍就能看懂~
1 import os
2 import pandas as pd
3 import numpy as np
4 import time
5 import datetime
6 # missingno是缺失值可视化工具库
7 import missingno as msno
8 import warnings
9 warnings.filterwarnings("ignore") # 忽略警告
10 import matplotlib.pyplot as plt
11 import matplotlib
12 matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 用黑体显示中文
13 matplotlib.rcParams['axes.unicode_minus'] = False # 正常显示负号
14
15
16 # 数据读取
17 def data_read(data_path, file_name):
18
19 data_path_whole = os.path.join(data_path, file_name)
20 # header=None表示第一行不是列名
21 # delim_whitespace表示是否用空格为分隔符,如果为True,那么其他字符如,就不会被认为是分隔符
22 df = pd.read_csv(data_path_whole, delim_whitespace=True, header=None)
23 # 变量重命名
24 columns = ['status_account', 'duration', 'credit_history', 'purpose', 'amount', 'svaing_account', 'present_emp', 'income_rate', 'personal_status',
25 'other_debtors', 'residence_info', 'property', 'age', 'inst_plans','housing', 'num_credits', 'job', 'dependents', 'telephone', 'foreign_worker', 'target']
26 # 添加列标题
27 df.columns = columns
28 # 将标签变量由状态1,2转为0,1; 0表示好用户,1表示坏用户
29 df.target = df.target - 1
30
31 return df
32
33
34 # 离散变量与连续变量区分
35 def category_continue_separation(df, feature_names):
36 categorical_var = []
37 numerical_var = []
38 # 移除 "target" 标签
39 if 'target' in feature_names:
40 feature_names.remove('target')
41 # 先判断类型,如果是int或float就直接作为连续变量
42 # DataFrame的select_dtypes方法是返回具有指定数据类型的列
43 numerical_var = list(df[feature_names].select_dtypes(include=['int', 'float', 'int32', 'float32', 'int64', 'float64']).columns.values)
44 # 获取剩下的标签
45 categorical_var = [x for x in feature_names if x not in numerical_var]
46
47 return categorical_var, numerical_var
48
49
50 # 字符串末位随机添加符号
51 def add_str(x):
52 str_1 = ['%', ' ', '/t', '$', ';', '@']
53 str_2 = str_1[np.random.randint(0, high=len(str_1) - 1)]
54 return x + str_2
55
56
57 # 生成一列时间戳数据
58 def add_time(num, style="%Y-%m-%d"):
59 # time.mktime(t) 函数接收struct_time对象作为参数,返回用秒数来表示时间的浮点数。
60 # 它的参数t是 结构化的时间或者完整的9位元组元素
61 start_time = time.mktime((2010, 1, 1, 0, 0, 0, 0, 0, 0))
62 stop_time = time.mktime((2015, 1, 1, 0, 0, 0, 0, 0, 0))
63 re_time = []
64 for i in range(num):
65 rand_time = np.random.randint(start_time, stop_time)
66 # 将时间戳生成时间元组
67 # Python time localtime() 作用是格式化时间戳为本地的时间
68 date_touple = time.localtime(rand_time)
69 # Python time strftime() 函数接收以时间元组,并返回以可读字符串表示的当地时间,格式由参数 format 决定。
70 re_time.append(time.strftime(style, date_touple))
71 return re_time
72
73
74 # 获取行值
75 def add_row(df_temp, num):
76 # 生成num个随机值
77 index_1 = np.random.randint(low=0, high=df_temp.shape[0] - 1, size=num)
78 # loc为Selection by Label函数,即为按标签取数据,这里是获取数值标签的数据,这里的数值标签是行,所以就是获取这些行的值
79 return df_temp.loc[index_1]
80
81
82 if __name__ == '__main__':
83 # 获取当前文件路径
84 path_current = os.getcwd()
85 data_path = os.path.join(path_current, 'data')
86 file_name = 'german.csv'
87
88 # 读取数据
89 df = data_read(data_path, file_name)
90
91 # 区分离散变量与连续变量
92 feature_names = list(df.columns)
93 feature_names.remove('target')
94 categorical_var, numerical_var = category_continue_separation(df, feature_names)
95 # describe()函数就是返回数据结构的统计变量。其目的在于观察这一系列数据的范围、大小、波动趋势等等,为后面的模型选择打下基础。
96 # 统计值变量说明: count:数量统计,此列共有多少有效值; unipue:不同的值有多少个; std:标准差; min:最小值
97 # 25%:四分之一分位数; 50%:二分之一分位数; 75%:四分之三分位数; max:最大值; mean:均值
98 print(df.describe())
99
100 # ------------------------------- 数据清洗 --------------------------------- #
101 # 注入“脏数据”
102 # 变量status_account 随机加入特殊字符
103 # apply函数主要用于对DataFrame中的行或者列进行特定的函数计算。
104 df.status_account = df.status_account.apply(add_str)
105 # 添加两列时间格式的数据
106 df['apply_time'] = add_time(df.shape[0], "%Y-%m-%d")
107 df['job_time'] = add_time(df.shape[0], "%Y/%m/%d %H:%M:%S")
108 # 添加行冗余数据,即复制了几行的数据
109 df_temp = add_row(df, 10)
110 # pandas.concat()通常用来连接DataFrame对象
111 df = pd.concat([df, df_temp], axis=0, ignore_index=True)
112
113 # Pandas读取数据之后使用pandas的head()函数的时候,来观察一下读取的数据。head()函数只能读取前五行数据
114 print(df.head())
115
116 # 设置显示的最大列数,None表示列都要显示
117 pd.set_option('display.max_columns', 10)
118 print("---------------------------------------------")
119 print(df.head())
120 pd.set_option('display.max_columns', None)
121 print("---------------------------------------------")
122 print(df.head())
123
124 # ------------------ 特殊字符清洗 -------------- #
125 # 离散变量先看一下范围
126 print("特殊字符清洗之前:", df.status_account.unique())
127 df.status_account = df.status_account.apply(
128 lambda x: x.replace(' ', '').replace('%', '').replace('/t', '').replace('$', '').replace('@', '').replace(';', ''))
129 print("特殊字符清洗之后:", df.status_account.unique())
130
131 # ----------------- 时间格式统一 ----------------- #
132 # 统一为'%Y-%m-%d格式
133 df['job_time'] = df['job_time'].apply(lambda x: x.split(' ')[0].replace('/', '-'))
134 # 时间为字符串格式转为时间格式
135 df['job_time'] = df['job_time'].apply(lambda x: datetime.datetime.strptime(x, '%Y-%m-%d'))
136 df['apply_time'] = df['apply_time'].apply(lambda x: datetime.datetime.strptime(x, '%Y-%m-%d'))
137
138 # 样本去冗余
139 print("样本去冗余之前的形状 df.shape = ", df.shape)
140 # pandas中的drop_duplicates()函数是根据指定的字段对数据集进行去重处理
141 # 参数:subset根据指定的列名进行去重,默认整个数据集
142 # keep 可选{‘first’, ‘last’, False},默认first,即默认保留第一次出现的重复值,并删去其他重复的数据,False是指删去所有重复数据。
143 # inplace 是否对数据集本身进行修改,默认False布尔值参数,默认为 False 表示删除重复项后返回一个副本,若为 Ture 则表示直接在原数据上删除重复项。
144 df.drop_duplicates(subset=None, keep='first', inplace=True)
145 print("样本去冗余之后的形状 df.shape = ", df.shape)
146
147 # 假设订单id出现重复则去除冗余实例
148 print("按照订单id去除冗余之前 df.shape = ", df.shape)
149 df['order_id'] = np.random.randint(low=0, high=df.shape[0] - 1, size=df.shape[0])
150 df.drop_duplicates(subset=['order_id'], keep='first', inplace=True)
151 print("按照订单id去除冗余之后 df.shape = ", df.shape)
152
153 # 探索性分析
154 print(df[numerical_var].describe())
155
156 # --------------------- 添加缺失值 ------------------- #
157 # 数据清洗时,会将带某行删除,此时DataFrame或Series类型的数据不再是连续的索引,可以使用reset_index()重置索引。
158 # 在获得新的index,原来的index变成数据列,保留下来。不想保留原来的index,使用参数 drop=True
159 df.reset_index(drop=True, inplace=True)
160 print(df)
161 var_name = categorical_var + numerical_var
162 for i in var_name:
163 num = np.random.randint(low=0, high=df.shape[0] - 1)
164 # 从num中随机生成num个数
165 index_1 = np.random.randint(low=0, high=df.shape[0] - 1, size=num)
166 print("=============================================")
167 print("去重之前的 len(index_1) = ", len(index_1))
168 # 对数据进行去重
169 index_1 = np.unique(index_1)
170 print("去重之后的 len(index_1) = ", len(index_1))
171 df[i].loc[index_1] = np.nan
172
173 # 缺失值绘图
174 # 数据分析之前首先要保证数据集的质量,missingno库提供了一个灵活易用的可视化工具来观察数据缺失情况
175 # msno.bar是按列对空值进行简单可视化
176 msno.bar(df, labels=True, figsize=(10, 6), fontsize=10)
177
178 # !!!! 注意,绘制以下三种图都需要现剔除缺失值再绘制箱线图
179 # 对于连续数据绘制箱线图,观察是否有异常值
180 plt.figure(figsize=(10, 6)) # 设置图形尺寸大小
181 for j in range(1, len(numerical_var) + 1):
182 plt.subplot(2, 4, j)
183 df_temp = df[numerical_var[j - 1]][~df[numerical_var[j - 1]].isnull()]
184 # 绘制箱线图函数
185 # 箱线图在使用场景上最常见的是用于质量管理、人事测评、探索性数据分析等统计分析活动。
186 # (1)识别异常值。异常值是指数据中远离其他大部分值的数据。
187 # (2)判断偏态。偏态是指与正态分布相对,非对称分布的偏斜状态。若平均数大于众数,则为右偏态(正偏态);若平均数小于众数,则为左偏态(负偏态)。
188 # (3)评估数据集中程度。箱线图的宽度一定程度反映了数据的波动程度。因为箱线图包含中间50%的数据,若它越扁,则说明数据较为集中;若它越宽,则说明数据较为分散。
189 # 箱图是一中用于统计数据分布的统计图,也可以粗略地看出数据是否具有对称性,分布的分散程度等信息。箱图中的信息含义如下:
190 # 最下方的横线表示最小值, 最上方的横线表示最大值, 黑色空心圆圈表示异常值, 黑色实心圆圈表示极端值, 箱子由下四分位数、中值以及上四分位数组成
191 plt.boxplot(
192 df_temp,
193 notch=False, # 中位线处不设置凹陷
194 widths=0.2, # 设置箱体宽度
195 medianprops={'color': 'red'}, # 中位线设置为红色
196 boxprops=dict(color="blue"), # 箱体边框设置为蓝色
197 labels=[numerical_var[j - 1]], # 设置标签
198 whiskerprops={'color': "black"}, # 设置须的颜色,黑色
199 capprops={'color': "green"}, # 设置箱线图顶端和末端横线的属性,颜色为绿色
200 flierprops={'color': 'purple', 'markeredgecolor': "purple"} # 异常值属性,这里没有异常值,所以没表现出来
201 )
202 plt.show()
203
204 # ------------------------------- 查看数据分布 ------------------------------ #
205 # -------- 连续变量不同类别下的分布 ---------- #
206 for i in numerical_var:
207 # i = 'duration'
208 # 取非缺失值的数据
209 # isnull()函数,它可以用来判断数据是否缺失值,这里是获取没有缺失值的数据
210 df_temp = df.loc[~df[i].isnull(), [i, 'target']]
211 df_good = df_temp[df_temp.target == 0]
212 df_bad = df_temp[df_temp.target == 1]
213 # 计算统计量
214 valid = round(df_temp.shape[0] / df.shape[0] * 100, 2)
215 Mean = round(df_temp[i].mean(), 2)
216 Std = round(df_temp[i].std(), 2)
217 Max = round(df_temp[i].max(), 2)
218 Min = round(df_temp[i].min(), 2)
219 # 绘图
220 plt.figure(figsize=(10, 6))
221 fontsize_1 = 12
222 # 绘制直方图函数,其中 bins: 直方图的柱数,即要分的组数,默认为10;alpha: 透明度;
223 plt.hist(df_good[i], bins=20, alpha=0.5, label='好样本')
224 plt.hist(df_bad[i], bins=20, alpha=0.5, label='坏样本')
225 plt.ylabel(i, fontsize=fontsize_1)
226 plt.title('valid rate=' + str(valid) + '%, Mean=' + str(Mean) +', Std=' + str(Std) + ', Max=' + str(Max) + ', Min=' + str(Min))
227 plt.legend()
228 # 保存图片
229 file = os.path.join(path_current, 'plot_num', i + '.png')
230 plt.savefig(file)
231 plt.close(1)
232
233 # --------- 离散变量不同类别下的分布 --------- #
234 for i in categorical_var:
235 # i = 'status_account'
236 # 获取非缺失值数据
237 df_temp = df.loc[~df[i].isnull(), [i, 'target']]
238 df_bad = df_temp[df_temp.target == 1]
239 valid = round(df_temp.shape[0] / df.shape[0] * 100, 2)
240
241 bad_rate = []
242 bin_rate = []
243 var_name = []
244 for j in df[i].unique():
245
246 if pd.isnull(j):
247 df_1 = df[df[i].isnull()]
248 bad_rate.append(sum(df_1.target) / df_1.shape[0])
249 bin_rate.append(df_1.shape[0] / df.shape[0])
250 var_name.append('NA')
251 else:
252 df_1 = df[df[i] == j]
253 bad_rate.append(sum(df_1.target) / df_1.shape[0])
254 bin_rate.append(df_1.shape[0] / df.shape[0])
255 var_name.append(j)
256 df_2 = pd.DataFrame({'var_name': var_name, 'bin_rate': bin_rate, 'bad_rate': bad_rate})
257 # 绘图
258 plt.figure(figsize=(10, 6))
259 fontsize_1 = 12
260 # 绘制柱状图
261 plt.bar(np.arange(1, df_2.shape[0] + 1), df_2.bin_rate, 0.1, color='black', alpha=0.5, label='占比')
262 plt.xticks(np.arange(1, df_2.shape[0] + 1), df_2.var_name)
263 # 绘制折线图
264 plt.plot(np.arange(1, df_2.shape[0] + 1), df_2.bad_rate, color='green', alpha=0.5, label='坏样本比率')
265
266 plt.ylabel(i, fontsize=fontsize_1)
267 plt.title('valid rate=' + str(valid) + '%')
268 plt.legend()
269 # 保存图片
270 file = os.path.join(path_current, 'plot_cat', i + '.png')
271 plt.savefig(file)
272 plt.close(1)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号