数学不好也能看懂的线性回归推导
一. 一元线性回归
对于线性回归最简单的就是一元线性回归,我们先拿一元线性回归作为入门的例子,等理解了这个,对于多元线性回归也就好理解了,都是一样的道理(对不起大家字写的不好!)
1.1官方定义
百科的定义:线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。其表达形式为y = wx+b+e,e为误差服从均值为0的正态分布(此处我加上了偏置b,定义上是没有的,因为在最终的求解中我们需要求得b的解,所以是需要的。)。
一元线性函数:y = wx + b这个式子比较简单,相信大家在初高中都学过,就是由w、b控制二维空间中的一条直线.而y' = w'x + b' + e 就是我们根据样本数据拟合出来的一条直线,e为误差,实际上 y=y'.
1.2一元线性回归推导
(1)从误差着手: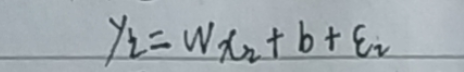 ----1
----1
式中ε为误差
由于误差服从正太分布(高斯分布),正太分布概率密度函数为: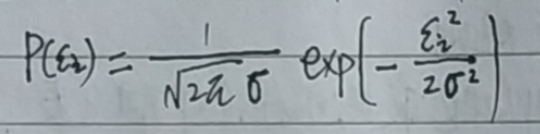 ----2
----2
(2)将1式代入2式:
(3)接下来就是使用最大似然估计来求解上式,但是在此之前先说一下概率密度函数和最大似然函数,不然很多同学、同志对这两步怎么来的和为什么要这么做不是很清楚。
归根结底我们要求得y-y'最小时w和b的值,换句话说就是求得误差最小时的w和b,公式2概率密度函数是一个均值为0的函数,因为误差均值为0,也就是关于y轴对称,如下图:
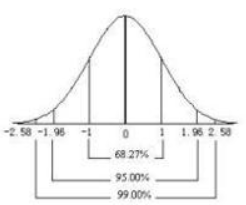
将1式代入2式后,现在变成了求解关于w、b的函数P(yi|xi;w,b)概率问题,其中P(yi|xi;w,b)yi、xi是已知量,而要求的是w,也就是w的值对应的是误差的概率值,我们希望误差越小越好,
由上图可知,误差越接近0概率越大,所以引出最大似然估计,就是求得所有样本的误差概率乘积最大,也就是误差最小,对应的w、b就是我们要求得的值。
似然函数为: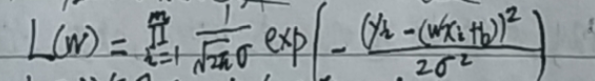
(4)为了方便计算转换成对数似然,因为可以将连乘转换为加法运算,并且两边同时取对数,不影响结果,m为样本个数:
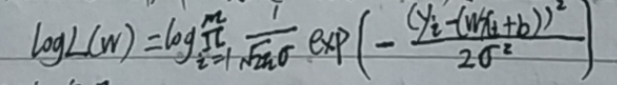
(5)化解上式:
(6)由于让似然函数越大越好,误差和也就越小,所以:
(7)又因为:
(8)所以分别对b、w进行求解偏导,然后导数为0时取得最小值解
对b求偏导:
对w求偏导: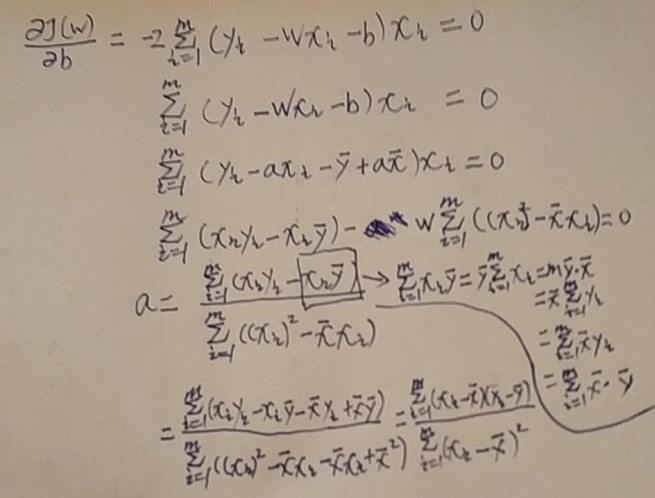
如上图,对w求偏导将b代入后很容易就求得结果,但是这种形式对于计算机矩阵计算来讲会增加复杂度,所以要对其进行转换,最终转换成了协方差的形式,其中涉及到一个转换的技巧 在方块中后的箭头进行了推导。
二. 多元线性回归
2.1 求解方式一正规方程求解
对于多元线性回归直接写到纸上进行拍照
第一种求解方式,正规方程解:

2.2 求解方式一正规方程求解
第二种求解方式,梯度下降:
最终写成了向量的形式:

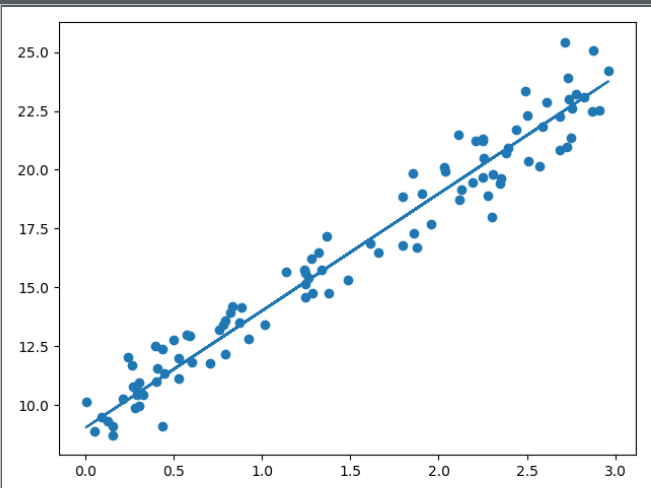
2.3 梯度下降求解Python实现
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 __author__ = 'zqf' 4 5 import numpy as np 6 import matplotlib.pyplot as plt 7 8 9 def j(x, y, theta): 10 """ 11 损失函数 12 :param x: 训练数据的x 13 :param y: 训练数据标签y 14 :param theta: 梯度值 array 15 :return: 损失值的平均值 16 """ 17 return np.sum((y - x.dot(theta)) ** 2) / len(x) 18 19 20 def dj(x, y, theta): 21 """ 22 梯度计算函数 23 :param x: 训练数据的x 24 :param y: 训练数据标签y 25 :param theta: 梯度值 array 26 :return: 梯度 27 """ 28 return x.T.dot(x.dot(theta) - y) * 2 / len(x) 29 30 31 def gradient_descent(initial_theta, epsilon, x, y, eta, max_iter): 32 """ 33 梯度下降计算 34 :param initial_theta: 初始化theta 35 :param epsilon: 损失最小阈值 36 :param x: 训练数据的x 37 :param y: 训练数据标签y 38 :param eta: 学习率 39 :param max_iter: 最大迭代次数 40 :return: 返回theta array(1, n+1),第一列为截距 41 """ 42 theta = initial_theta 43 i = 0 44 while i < max_iter: 45 gradient = dj(x, y, theta) 46 last_theta = theta 47 theta = theta - (eta * gradient) 48 if abs(j(x, y, theta) - j(x, y, last_theta)) < epsilon: 49 break 50 i += 1 51 return theta 52 53 54 if __name__ == '__main__': 55 train_X = 3 * np.random.random(size=100) 56 train_y = 5 * train_X + 9 + np.random.normal(size=100, scale=1) 57 train_X_b = np.hstack((np.ones([len(train_X), 1]), train_X.reshape(-1, 1))) 58 59 theta_ = gradient_descent(initial_theta=np.zeros(train_X_b.shape[1]), 60 epsilon=1e-4, 61 x=train_X_b, 62 y=train_y, 63 eta=0.01, 64 max_iter=1e8) 65 66 # 绘图 67 plt.scatter(train_X, train_y) 68 plt.plot(train_X, train_X * theta_[1:] + theta_[0]) 69 plt.show()