Golang的Map并发性能以及原理分析
1. golang map数据类型的问题
在Go 1.6之前, 内置的map类型是部分goroutine安全的,并发的读没有问题,并发的写可能有问题。自go 1.6之后, 并发地读写map会报错,这在一些知名的开源库中都存在这个问题,所以go 1.9之前的解决方案是额外绑定一个锁,封装成一个新的struct或者单独使用锁都可以。
2. map如何导致出现并发问题
golang官方的faq已经提到build-in的map不是线程(goroutine)安全的。
现在就基于这个场景,构建出一段示例代码
package main
func main() {
m := make(map[int]int)
go func() {
for {
_ = m[1]
}
}()
go func() {
for {
m[2] = 2
}
}()
select {}
}
上述这段的代码的意思也很好理解,俩goroutine,第一个goroutine负责不停的读取m这个map对象,而第二个goroutine在不停地往m这个map对象中不停的写入同一个数据。最后我们来运行一下这段代码看一下结果
go run main.go
fatal error: concurrent map read and map write
结果也是我们意料之中的事情,golang的build-in的map并不支持并发的读写操作。基于为什么会这样,这就和go的源码有关了,原因在于,在read的时候回去检查hashWriting标志,如果存在这个标志,就会出现并发错误。
设置完之后又会取消hashWriting这个标识。源码中会检查是不是有并发的写,删除键的时候,遍历的时候并发读写的问题。map的并发问题不是那么容易被发现,可以利用-race来检查。
3. Go 1.9之前的解决方案
很多时候我们会并发的使用mao对象,尤其是在一定的规模项目中,map总会保存goroutine共享的数据。go官方在那个时候给出了一个简单的解决方案。大家也肯定和官方想的一样,就是加锁。
var counter = struct{
sync.RWMutex
m map[string]int
}{m: make(map[string]int)}
设置一个struct,嵌入一个读写锁和一个map。
在读数据的时候加锁
counter.RLock()
n := counter.m["some_key"]
counter.RUnlock()
fmt.Println("some_key:", n)
写入的时候也加锁
counter.Lock()
counter.m["some_key"]++
counter.Unlock()
4. 现有的map并发安全的解决方案以及问题
| 实现方式 | 原理 | 适用场景 |
|---|---|---|
| map+Mutex | 通过Mutex互斥锁来实现多个goroutine对map的串行化访问 | 读写都需要通过Mutex加锁和释放锁,适用于读写比接近的场景 |
| map+RWMutex | 通过RWMutex来实现对map的读写进行读写锁分离加锁,从而实现读的并发性能提高 | 同Mutex相比适用于读多写少的场景 |
| sync.Map | 底层通分离读写map和原子指令来实现读的近似无锁,并通过延迟更新的方式来保证读的无锁化 | 读多修改少,元素增加删除频率不高的情况,在大多数情况下替代上述两种实现 |
map的容量问题
在Mutex和RWMutex实现的并发安全的map中map随着时间和元素数量的增加、删除,容量会不断的递增,在某些情况下比如在某个时间点频繁的进行大量数据的增加,然后又大量的删除,其map的容量并不会随着元素的删除而缩小,而在sync.Map中,当进行元素从dirty进行提升到read map的时候会进行重建,可能会缩容
5. sync map
1. 无锁读与读写分离
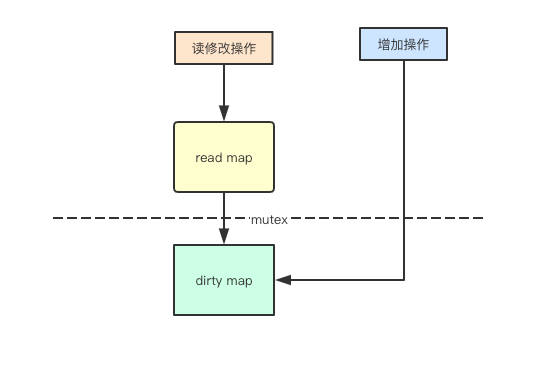
1. 读写分离
并发访问map读的主要问题其实是在扩容的时候,可能会导致元素被hash到其他的地址,那如果我的读的map不会进行扩容操作,就可以进行并发安全的访问了,而sync.map里面正是采用了这种方式,对增加元素通过dirty来进行保存
2. 无锁读
通过read只读和dirty写map将操作分离,其实就只需要通过原子指令对read map来进行读操作而不需要加锁了,从而提高读的性能
3. 写加锁与延迟提升
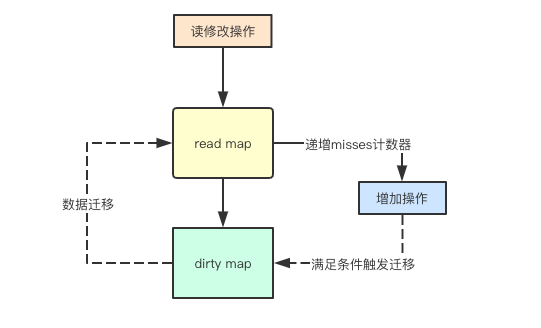
1. 写加锁
上面提到增加元素操作可能会先增加到dirty写map中,那针对多个goroutine同时写,其实就需要进行Mutex加锁了
2. 延迟提升
上面提到了read只读map和dirty写map, 那就会有个问题,默认增加元素都放在dirty中,那后续访问新的元素如果都通过 mutex加锁,那read只读map就失去意义,sync.Map中采用一直延迟提升的策略,进行批量将当前map中的所有元素都提升到read只读map中从而为后续的读访问提供无锁支持
2. 指针与惰性删除
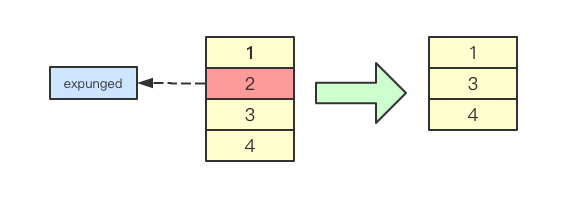
1. map里面的指针
map里面存储数据都会涉及到一个问题就是存储值还是指针,存储值可以让 map作为一个大的的对象,减轻垃圾回收的压力(避免扫描所有小对象),而存储指针可以减少内存利用,而sync.Map中其实采用了指针结合惰性删除的方式,来进行 map的value的存储
2. 惰性删除
惰性删除是并发设计中一中常见的设计,比如删除某个个链表元素,如果要删除则需要修改前后元素的指针,而采用惰性删除,则通常只需要给某个标志位设定为删除,然后在后续修改中再进行操作,sync.Map中也采用这种方式,通过给指针指向某个标识删除的指针,从而实现惰性删除
3. sync.map的特点
- 空间换时间,通过冗余的两个数据结构(read,dirty)实现加锁对性能的影响。
- 使用只读锁,避免读写冲突。
- 动态调整,miss次数多了之后,将dirty数据提升为read。
- double-checking。
- 延迟删除。删除一个key值只是打标记,只有在提升dirty的时候才清理的数据。
- 有限从read中读取,更新,删除,因为对read的读取都不需要锁。
4. 源代码解析

1. Map
type Map struct {
// 当涉及到dirty数据的操作的时候,需要使用这个锁
mu Mutex
// 一个只读的数据结构,因为只读,所以不会有读写冲突。
// 所以从这个数据中读取总是安全的。
// 实际上,实际也会更新这个数据的entries,如果entry是未删除的(unexpunged), 并不需要加锁。如果entry已经被删除了,需要加锁,以便更新dirty数据。
read atomic.Value // readOnly
// dirty数据包含当前的map包含的entries,它包含最新的entries(包括read中未删除的数据,虽有冗余,但是提升dirty字段为read的时候非常快,不用一个一个的复制,而是直接将这个数据结构作为read字段的一部分),有些数据还可能没有移动到read字段中。
// 对于dirty的操作需要加锁,因为对它的操作可能会有读写竞争。
// 当dirty为空的时候, 比如初始化或者刚提升完,下一次的写操作会复制read字段中未删除的数据到这个数据中。
dirty map[interface{}]*entry
// 当从Map中读取entry的时候,如果read中不包含这个entry,会尝试从dirty中读取,这个时候会将misses加一,
// 当misses累积到 dirty的长度的时候, 就会将dirty提升为read,避免从dirty中miss太多次。因为操作dirty需要加锁。
misses int
}
sync的Map的数据结构比较简单,只有四个字段,read、mu、dirty、misses。
它使用了冗余的数据结构read、dirty。dirty中会包含read中为删除的entries,新增加的entries会加入到dirty中。
2. Readonly
read的数据结构是
type readOnly struct {
m map[interface{}]*entry
amended bool // 如果Map.dirty有些数据不在其中的时候,这个值为true
}
只读map,对该map元素的访问不需要加锁,但是该map也不会进行元素的增加,元素会被先添加到dirty中然后后续再转移到read只读map中,通过atomic原子操作不需要进行锁操作。
amended指明Map.dirty中有readOnly.m未包含的数据,所以如果从Map.read找不到数据的话,还要进一步到Map.dirty中查找。
对Map.read的修改是通过原子操作进行的。
虽然read和dirty有冗余数据,但这些数据是通过指针指向同一个数据,所以尽管Map的value会很大,但是冗余的空间占用还是有限的。
3. entry
readOnly.m和Map.dirty存储的值类型是*entry,它包含一个指针p, 指向用户存储的value值。
type entry struct {
p unsafe.Pointer // *interface{}
}
entry是sync.Map中值得指针,如果当p指针指向expunged这个指针的时候,则表明该元素被删除,但不会立即从map中删除,如果在未删除之前又重新赋值则会重用该元素。
p的值
- nil: entry已被删除了,并且m.dirty为nil
- expunged: entry已被删除了,并且m.dirty不为nil,而且这个entry不存在于m.dirty中
- 其它: entry是一个正常的值
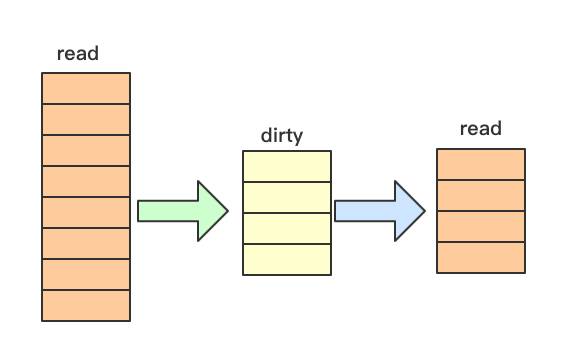
4. read map与dirty map的关系
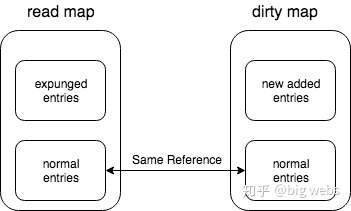
从上图中可以看出,read map 和 dirty map 中含有相同的一部分 entry,我们称作是 normal entries,是双方共享的。状态就是上面所说的p的值nil和unexpunged。
但是 read map 中含有一部分 entry 是不属于 dirty map 的,而这部分 entry 就是状态为 expunged 状态的 entry。而 dirty map 中有一部分 entry 也是不属于 read map 的,而这部分其实是来自 Store 操作形成的(也就是新增的 entry),换句话说就是新增的 entry 是出现在 dirty map 中的。这句话其实在文中已经是重复了好几次了,还是要请大家记住这一点,只要是添加的,就一定是添加到dirty map中。
现在可以了解read map 和 dirty map 的是什么了,那么还得理解一个重要的问题是: read map 和 dirty map 是用来干什么的,以及为什么这么设计?
第一个问题比较好回答,read map 是用来进行 lock free 操作的(其实可以读写,但是不能做删除操作,因为一旦做了删除操作,就不是线程安全的了,也就无法 lock free),而 dirty map 是用来在无法进行 lock free 操作的情况下,需要 lock 来做一些更新工作的对象。下面我们重点看看Load、Store、Delete、Range这四个方法,其它辅助方法可以参考这四个方法来理解。
5. Load

加载方法,也就是提供一个键key,查找对应的值value,如果不存在,通过ok反映:
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
// 1.首先从m.read中得到只读readOnly,从它的map中查找,不需要加锁
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// 2. 如果没找到,并且m.dirty中有新数据,需要从m.dirty查找,这个时候需要加锁
if !ok && read.amended {
m.mu.Lock()
// 双检查,避免加锁的时候m.dirty提升为m.read,这个时候m.read可能被替换了。
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
// 如果m.read中还是不存在,并且m.dirty中有新数据
if !ok && read.amended {
// 从m.dirty查找
e, ok = m.dirty[key]
// 不管m.dirty中存不存在,都将misses计数加一
// missLocked()中满足条件后就会提升m.dirty
m.missLocked()
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
return e.load()
}
这里有两个值的关注的地方。一个是首先从m.read中加载,不存在的情况下,并且m.dirty中有新数据,加锁,然后从m.dirty中加载。
二是这里使用了双检查的处理,因为在下面的两个语句中,这两行语句并不是一个原子操作
if !ok && read.amended {
m.mu.Lock()
}
虽然第一句执行的时候条件满足,但是在加锁之前,m.dirty可能被提升为m.read,所以加锁后还得再检查m.read,后续的方法中都使用了这个方法。
双检查的技术Java程序员非常熟悉了,单例模式的实现之一就是利用双检查的技术。
可以看到,如果我们查询的键值正好存在于m.read中,无须加锁,直接返回,理论上性能优异。即使不存在于m.read中,经过miss几次之后,m.dirty会被提升为m.read,又会从m.read中查找。所以对于更新/增加比较少的场景,加载存在的key很多的case,性能基本和无锁的map类似。
下面看看m.dirty是如何被提升为m.read的。 missLocked方法中可能会将m.dirty提升。
dirty到read map的迁移
Load的源码中有一个函数叫missLocked,这个函数比较重要,是关系dirty到read map迁移操作的,对着源码着重说一说。
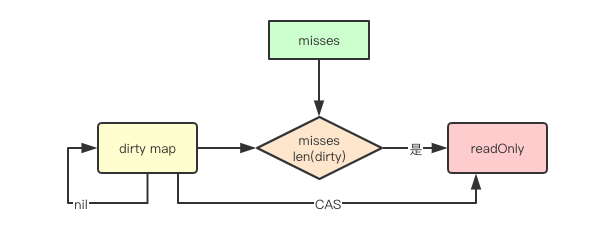
func (m *Map) missLocked() {
m.misses++
if m.misses < len(m.dirty) {
return
}
m.read.Store(readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}
上面的最后三行代码就是提升m.dirty的,很简单的将m.dirty作为readOnly的m字段,原子更新m.read。提升后m.dirty、m.misses重置, 并且m.read.amended为false。这种做法无疑是会提升read map的命中率。
当持续的从read访问穿透到dirty中后,就会触发一次从dirty到read的迁移,这也意味着如果我们的元素读写比差比较小,其实就会导致频繁的迁移操作,性能其实可能并不如rwmutex等实现。
6. store

这个方法是更新或者新增一个entry。
func (m *Map) Store(key, value interface{}) {
// 如果m.read存在这个键,并且这个entry没有被标记删除,尝试直接存储。
// 因为m.dirty也指向这个entry,所以m.dirty也保持最新的entry。
read, _ := m.read.Load().(readOnly)
if e, ok := read.m[key]; ok && e.tryStore(&value) {
return
}
// 如果`m.read`不存在或者已经被标记删除
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
if e, ok := read.m[key]; ok {
if e.unexpungeLocked() { //标记成未被删除
m.dirty[key] = e //m.dirty中不存在这个键,所以加入m.dirty
}
e.storeLocked(&value) //更新
} else if e, ok := m.dirty[key]; ok { // m.dirty存在这个键,更新
e.storeLocked(&value)
} else { //新键值
if !read.amended { //m.dirty中没有新的数据,往m.dirty中增加第一个新键
m.dirtyLocked() //从m.read中复制未删除的数据
m.read.Store(readOnly{m: read.m, amended: true})
}
m.dirty[key] = newEntry(value) //将这个entry加入到m.dirty中
}
m.mu.Unlock()
}
// 在刚初始化和将所有元素迁移到read中后,dirty默认都是nil元素,而此时如果有新的元素增加,则需要先将read map中的所有未删除数据先迁移到dirty中
func (m *Map) dirtyLocked() {
if m.dirty != nil {
return
}
read, _ := m.read.Load().(readOnly)
m.dirty = make(map[interface{}]*entry, len(read.m))
for k, e := range read.m {
if !e.tryExpungeLocked() {
m.dirty[k] = e
}
}
}
func (e *entry) tryExpungeLocked() (isExpunged bool) {
p := atomic.LoadPointer(&e.p)
for p == nil {
// 将已经删除标记为nil的数据标记为expunged
if atomic.CompareAndSwapPointer(&e.p, nil, expunged) {
return true
}
p = atomic.LoadPointer(&e.p)
}
return p == expunged
}
你可以看到,以上操作都是先从操作m.read开始的,不满足条件再加锁,然后操作m.dirty。
Store可能会在某种情况下(初始化或者m.dirty刚被提升后)从m.read中复制数据,如果这个时候m.read中数据量非常大,可能会影响性能。
read map到dirty map的迁移
着重的讲一下源码中的dirtyLocked函数
在刚初始化和将所有元素迁移到read中后,dirty默认都是nil元素,而此时如果有新的元素增加,则需要先将read map中的所有未删除数据先迁移到dirty中。
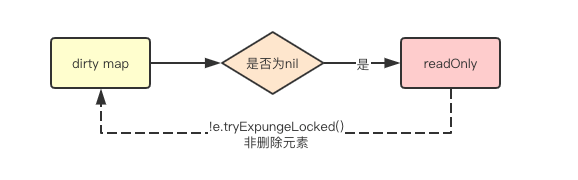
func (m *Map) dirtyLocked() {
if m.dirty != nil {
return
}
read, _ := m.read.Load().(readOnly)
m.dirty = make(map[interface{}]*entry, len(read.m))
for k, e := range read.m {
if !e.tryExpungeLocked() {
m.dirty[k] = e
}
}
}
7. Delete

删除一个键值。
func (m *Map) Delete(key interface{}) {
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
if !ok && read.amended {
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
delete(m.dirty, key)
}
m.mu.Unlock()
}
if ok {
e.delete()
}
}
同样,删除操作还是从m.read中开始, 如果这个entry不存在于m.read中,并且m.dirty中有新数据,则加锁尝试从m.dirty中删除。
注意,还是要双检查的。 从m.dirty中直接删除即可,就当它没存在过,但是如果是从m.read中删除,并不会直接删除,而是打标记:
func (e *entry) delete() (hadValue bool) {
for {
p := atomic.LoadPointer(&e.p)
// 已标记为删除
if p == nil || p == expunged {
return false
}
// 原子操作,e.p标记为nil
if atomic.CompareAndSwapPointer(&e.p, p, nil) {
return true
}
}
}
这里有一个比较有意思的地方,原子操作e.p标记为nil而不是expunged,其中的原因是啥,我也仔细的想了一想,在开篇的时候我给了一张read map和dirty map关系的图,unexpunged的entry是readmap有而dirtymap中没有的,而这个值执行CAS条件表明entry 既不是 nil 也不是 expunged 的,那么就是说这个 entry 必定是存在于 dirty map 中的,也就不能置成 expunged。
8. Range
因为for ... range map是内建的语言特性,所以没有办法使用for range遍历sync.Map, 但是可以使用它的Range方法,通过回调的方式遍历。
func (m *Map) Range(f func(key, value interface{}) bool) {
read, _ := m.read.Load().(readOnly)
// 如果m.dirty中有新数据,则提升m.dirty,然后在遍历
if read.amended {
//提升m.dirty
m.mu.Lock()
read, _ = m.read.Load().(readOnly) //双检查
if read.amended {
read = readOnly{m: m.dirty}
m.read.Store(read)
m.dirty = nil
m.misses = 0
}
m.mu.Unlock()
}
// 遍历, for range是安全的
for k, e := range read.m {
v, ok := e.load()
if !ok {
continue
}
if !f(k, v) {
break
}
}
}
9. Load Store Delete
Load Store Delete 的操作都基本描述完了,可以用下面的一张图用来总结一下:
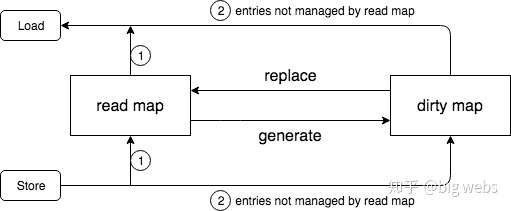
6. read map 和 dirty map 的设计分析
最核心和最基本的原因就是: 通过分离出 readonly 的部分,从而可以形成 lock free 的优化。
从上面的流程可以发现,对于 read map 中 entry 的操作是不需要 lock 的,但是为什么就能够保证这样的无锁操作是 thread-safe 的呢?
这是因为 read map 是 read-only 的,不过这里的 read-only 是指 entry 不会被删除,其实值是可以被更新,而值的更新是可以通过 CAS 操作保证 thread-safe 的,所以读者可以发现,即使在持有 lock 的时候,仍然需要 CAS 来对 read map 中的 entry 进行操作,此外对于 read map 本身的更新也是 通过 atomic 来操作的(在 missLocked 方法中)。
7 syncmap 的缺陷
其实通过上面的分析,了解了整个流程的话,读者会很容易理解这个 syncmap 的缺点:当需要不停地新增和删除的时候,会导致 dirty map 不停地更新,甚至在 miss 过多之后,导致 dirty 成为 nil,并进入重建的过程
8. 关于 lock free 的启发
lock free 会给并发的性能带了较高的提升,目前通过 syncmap 的代码分析,我们也对 lock free 有一些了解,下面会记录一下笔者从 syncmap 中得到的对 lock free 的一些理解。
9. BenchMark测试,用数据说话
1. map无锁并发读与map有锁并发读的性能差异
package lock_test
import (
"fmt"
"sync"
"testing"
)
var cache map[string]string
const NUM_OF_READER int = 40
const READ_TIMES = 100000
func init() {
cache = make(map[string]string)
cache["a"] = "aa"
cache["b"] = "bb"
}
func lockFreeAccess() {
var wg sync.WaitGroup
wg.Add(NUM_OF_READER)
for i := 0; i < NUM_OF_READER; i++ {
go func() {
for j := 0; j < READ_TIMES; j++ {
_, err := cache["a"]
if !err {
fmt.Println("Nothing")
}
}
wg.Done()
}()
}
wg.Wait()
}
func lockAccess() {
var wg sync.WaitGroup
wg.Add(NUM_OF_READER)
m := new(sync.RWMutex)
for i := 0; i < NUM_OF_READER; i++ {
go func() {
for j := 0; j < READ_TIMES; j++ {
m.RLock()
_, err := cache["a"]
if !err {
fmt.Println("Nothing")
}
m.RUnlock()
}
wg.Done()
}()
}
wg.Wait()
}
func BenchmarkLockFree(b *testing.B) {
b.ResetTimer()
for i := 0; i < b.N; i++ {
lockFreeAccess()
}
}
func BenchmarkLock(b *testing.B) {
b.ResetTimer()
for i := 0; i < b.N; i++ {
lockAccess()
}
}
上面的代码比较简单,BenchMark测试的就是俩函数,一个是lockFreeAccess,一个是lockAccess,这两个函数的区别就是lockFreeAccess是无锁的,lockAccess还是带锁的。
go test -bench=.
goos: darwin
goarch: amd64
pkg: go_learning/code/ch48/lock
BenchmarkLockFree-4 100 12014281 ns/op
BenchmarkLock-4 6 199626870 ns/op
PASS
ok go_learning/code/ch48/lock 3.245s
执行go test -bench=. 很明显的看出BenchmarkLockFree和BenchmarkLock,BenchmarkLockFree-4每次执行耗时是12014281纳秒,而BenchmarkLock-4 是199626870纳秒,两者明显就是相差了一个量级。
cpu差异
go test -bench=. -cpuprofile=cpu.prof
go tool pprof cpu.prof
Type: cpu
Time: Aug 10, 2020 at 2:27am (GMT)
Duration: 2.76s, Total samples = 6.62s (240.26%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 6.49s, 98.04% of 6.62s total
Dropped 8 nodes (cum <= 0.03s)
Showing top 10 nodes out of 34
flat flat% sum% cum cum%
1.57s 23.72% 23.72% 1.58s 23.87% sync.(*RWMutex).RLock (inline)
1.46s 22.05% 45.77% 1.47s 22.21% sync.(*RWMutex).RUnlock (inline)
1.40s 21.15% 66.92% 1.82s 27.49% runtime.mapaccess2_faststr
0.80s 12.08% 79.00% 0.80s 12.08% runtime.findnull
0.51s 7.70% 86.71% 2.07s 31.27% go_learning/code/ch48/lock_test.lockFreeAccess.func1
0.28s 4.23% 90.94% 0.28s 4.23% runtime.pthread_cond_wait
0.16s 2.42% 93.35% 0.16s 2.42% runtime.newstack
0.15s 2.27% 95.62% 0.15s 2.27% runtime.add (partial-inline)
0.11s 1.66% 97.28% 0.13s 1.96% runtime.(*bmap).keys (inline)
0.05s 0.76% 98.04% 3.40s 51.36% go_learning/code/ch48/lock_test.lockAccess.func1
很明显 lockAccess的cpu耗时3.40s,而lockFreeAccess的cpu耗时是2.07s。
2. 对比ConcurrentHashMap
如果熟悉Java的同学,可以对比一下java的ConcurrentHashMap的实现,在map的数据非常大的情况下,一把锁会导致大并发的客户端共争一把锁,Java的解决方案是shard, 内部使用多个锁,每个区间共享一把锁,这样减少了数据共享一把锁带来的性能影响。go的官方虽然没有提供类似Java的ConcurrentHashMap的实现,但是我也还是试着去尝试了下。
1. concurrent_map_benchmark_adapter.go
package maps
import "github.com/easierway/concurrent_map"
type ConcurrentMapBenchmarkAdapter struct {
cm *concurrent_map.ConcurrentMap
}
func (m *ConcurrentMapBenchmarkAdapter) Set(key interface{}, value interface{}) {
m.cm.Set(concurrent_map.StrKey(key.(string)), value)
}
func (m *ConcurrentMapBenchmarkAdapter) Get(key interface{}) (interface{}, bool) {
return m.cm.Get(concurrent_map.StrKey(key.(string)))
}
func (m *ConcurrentMapBenchmarkAdapter) Del(key interface{}) {
m.cm.Del(concurrent_map.StrKey(key.(string)))
}
func CreateConcurrentMapBenchmarkAdapter(numOfPartitions int) *ConcurrentMapBenchmarkAdapter {
conMap := concurrent_map.CreateConcurrentMap(numOfPartitions)
return &ConcurrentMapBenchmarkAdapter{conMap}
}
2. map_benchmark_test.go
package maps
import (
"strconv"
"sync"
"testing"
)
const (
NumOfReader = 100
NumOfWriter = 10
)
type Map interface {
Set(key interface{}, val interface{})
Get(key interface{}) (interface{}, bool)
Del(key interface{})
}
func benchmarkMap(b *testing.B, hm Map) {
for i := 0; i < b.N; i++ {
var wg sync.WaitGroup
for i := 0; i < NumOfWriter; i++ {
wg.Add(1)
go func() {
for i := 0; i < 100; i++ {
hm.Set(strconv.Itoa(i), i*i)
hm.Set(strconv.Itoa(i), i*i)
hm.Del(strconv.Itoa(i))
}
wg.Done()
}()
}
for i := 0; i < NumOfReader; i++ {
wg.Add(1)
go func() {
for i := 0; i < 100; i++ {
hm.Get(strconv.Itoa(i))
}
wg.Done()
}()
}
wg.Wait()
}
}
func BenchmarkSyncmap(b *testing.B) {
b.Run("map with RWLock", func(b *testing.B) {
hm := CreateRWLockMap()
benchmarkMap(b, hm)
})
b.Run("sync.map", func(b *testing.B) {
hm := CreateSyncMapBenchmarkAdapter()
benchmarkMap(b, hm)
})
b.Run("concurrent map", func(b *testing.B) {
superman := CreateConcurrentMapBenchmarkAdapter(199)
benchmarkMap(b, superman)
})
}
3. rw_map.go
package maps
import "sync"
type RWLockMap struct {
m map[interface{}]interface{}
lock sync.RWMutex
}
func (m *RWLockMap) Get(key interface{}) (interface{}, bool) {
m.lock.RLock()
v, ok := m.m[key]
m.lock.RUnlock()
return v, ok
}
func (m *RWLockMap) Set(key interface{}, value interface{}) {
m.lock.Lock()
m.m[key] = value
m.lock.Unlock()
}
func (m *RWLockMap) Del(key interface{}) {
m.lock.Lock()
delete(m.m, key)
m.lock.Unlock()
}
func CreateRWLockMap() *RWLockMap {
m := make(map[interface{}]interface{}, 0)
return &RWLockMap{m: m}
}
4. sync_map_benchmark_adapter.go
package maps
import "sync"
func CreateSyncMapBenchmarkAdapter() *SyncMapBenchmarkAdapter {
return &SyncMapBenchmarkAdapter{}
}
type SyncMapBenchmarkAdapter struct {
m sync.Map
}
func (m *SyncMapBenchmarkAdapter) Set(key interface{}, val interface{}) {
m.m.Store(key, val)
}
func (m *SyncMapBenchmarkAdapter) Get(key interface{}) (interface{}, bool) {
return m.m.Load(key)
}
func (m *SyncMapBenchmarkAdapter) Del(key interface{}) {
m.m.Delete(key)
}
1 . 读写量级一致,相差不多
benchmarkMap设置的是100次写和100次读
go test -bench=.
goos: darwin
goarch: amd64
pkg: go_learning/code/ch48/maps
BenchmarkSyncmap/map_with_RWLock-4 398 2780087 ns/op
BenchmarkSyncmap/sync.map-4 530 2173851 ns/op
BenchmarkSyncmap/concurrent_map-4 693 1505866 ns/op
PASS
ok go_learning/code/ch48/maps 4.709s
从结果上看基于Java的ConcurrentHashMap的性能更优异,其次是go的sync.map最后才是RWLock.
2. 读多写少
benchmarkMap设置的是10次写和100次读
go test -bench=.
goos: darwin
goarch: amd64
pkg: go_learning/code/ch48/maps
BenchmarkSyncmap/map_with_RWLock-4 630 1644799 ns/op
BenchmarkSyncmap/sync.map-4 2103 588642 ns/op
BenchmarkSyncmap/concurrent_map-4 1088 1140983 ns/op
PASS
ok go_learning/code/ch48/maps 6.286s
从结果上看go的sync.map的性能高于其他两个不是一点点,所以对于并发操作读多写少的情况下,sync.map是嘴合适的选择。
3. 读少写多
benchmarkMap设置的是100次写和10次读
go test -bench=.
goos: darwin
goarch: amd64
pkg: go_learning/code/ch48/maps
BenchmarkSyncmap/map_with_RWLock-4 788 1369344 ns/op
BenchmarkSyncmap/sync.map-4 650 1744666 ns/op
BenchmarkSyncmap/concurrent_map-4 2065 577972 ns/op
PASS
ok go_learning/code/ch48/maps 5.288s
从结果上看基于Java的ConcurrentHashMap的性能更优异,其次是RWLock最后才是sync.map.为什么sync.map会这么慢,在上面的分析中都有说明。

