
mysql 二
连表
什么是联表,为什么使用联表,如何编写使用联表的select语句。
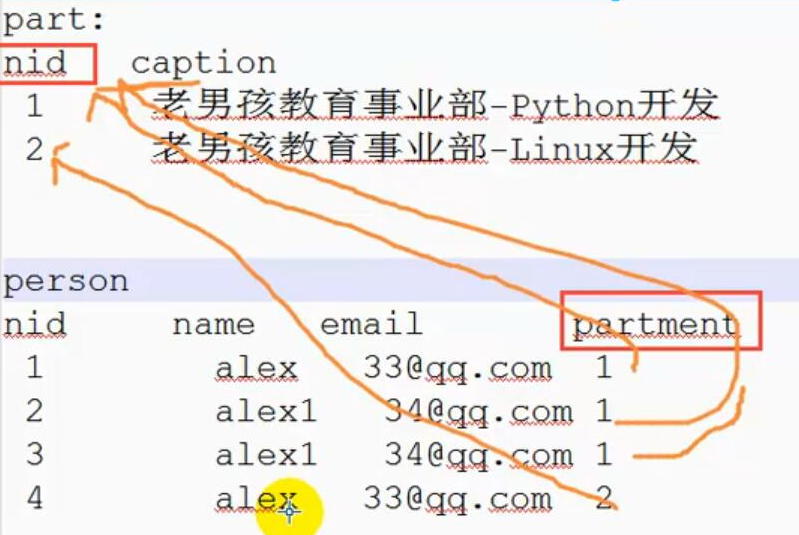
多表关联,一对多的关系。
将一张表分成两张表。
- 人为创建关联
- 约束
外键是另外一张表的主键。主表的栏位、与参考表栏位,对应类型相同。
1、MySQL中“键”和“索引”的定义相同,所以外键和主键一样也是索引的一种。不同的是MySQL会自动为所有表的主键进行索引,但是外键字段必须由用户进行明确的索引。用于外键关系的字段必须在所有的参照表中进行明确地索引,InnoDB不能自动地创建索引。
2、外键可以是一对一的,一个表的记录只能与另一个表的一条记录连接,或者是一对多的,一个表的记录与另一个表的多条记录连接。
3、如果需要更好的性能,并且不需要完整性检查,可以选择使用MyISAM表类型,如果想要在MySQL中根据参照完整性来建立表并且希望在此基础上保持良好的性能,最好选择表结构为innoDB类型。
4、外键的使用条件
- 两个表必须是InnoDB表,MyISAM表暂时不支持外键
- 外键列必须建立了索引,MySQL 4.1.2以后的版本在建立外键时会自动创建索引,但如果在较早的版本则需要显式建立;
- 外键关系的两个表的列必须是数据类型相似,也就是可以相互转换类型的列,比如int和tinyint可以,而int和char则不可以;
5、外键的好处:可以使得两张表关联,保证数据的一致性和实现一些级联操作。
一张表分成两张表(因为partment部分是重复的)
***相同数据出现多次绝对不是一件好事,这是关系型数据库设计的基础***
- 重复信息既浪费空间又浪费时间
- 如果信息变化,只需修改一次
- 如果有重复数据,很难保证每次输入的数据方式都相同,不一致的数据很难利用

create table part( nid int not null auto_increment primary key, caption varchar(32) not null ); create table person( nid int not null auto_increment, name varchar(32) not null, email varchar(32) not null, part_nid int not null, primary key (nid), constraint fk_person_part foreign key (part_nid) references part(nid) );

alter table person drop foreign key fk_person_part; #删除外键 alter table person add constraint fk_per_t1 foreign key (part_nid) references part(nid); #添加外键
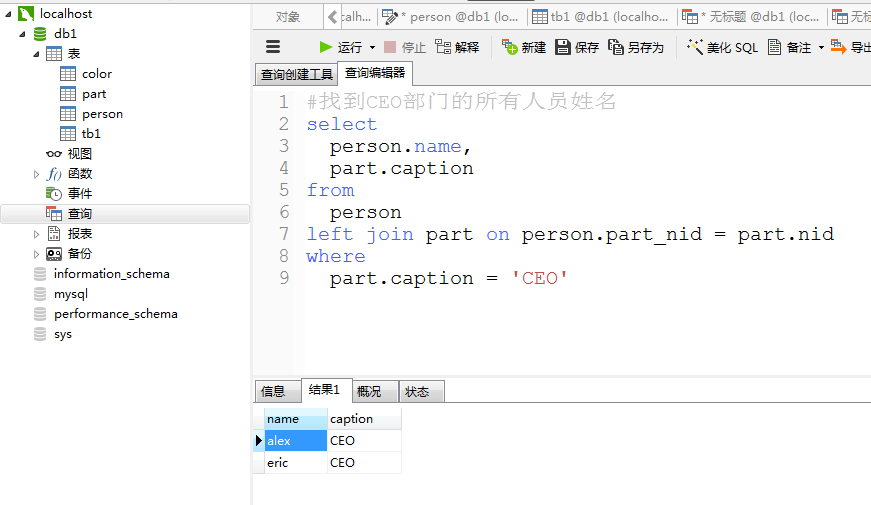
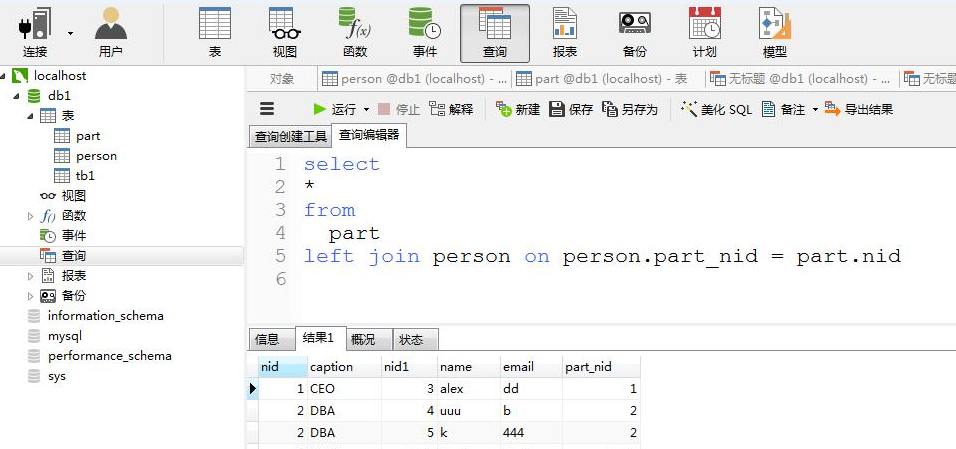
#找到CEO部门的所有人员姓名 select person.name, part.caption from person left join part on person.part_nid = part.nid where part.caption = 'CEO'
A left join B on a.xx = b.xx
#以A为主
#将A中所有数据罗列
#B,则只显示与A相应的数据
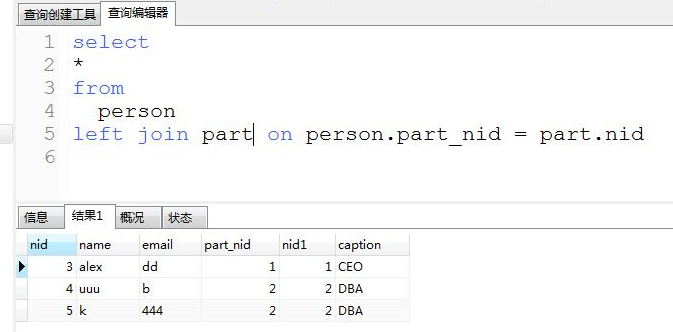
B left join A
A right join B == B left join A
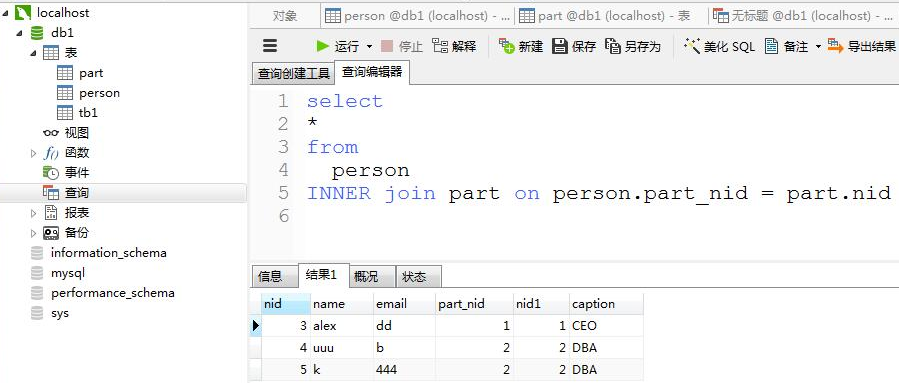
A inner join B
#自动忽略未建立关系的数据。
建立三张表
多对多 >>> 本质是双向的一对多关系
- 建立关系表
- 设置外键建立约束

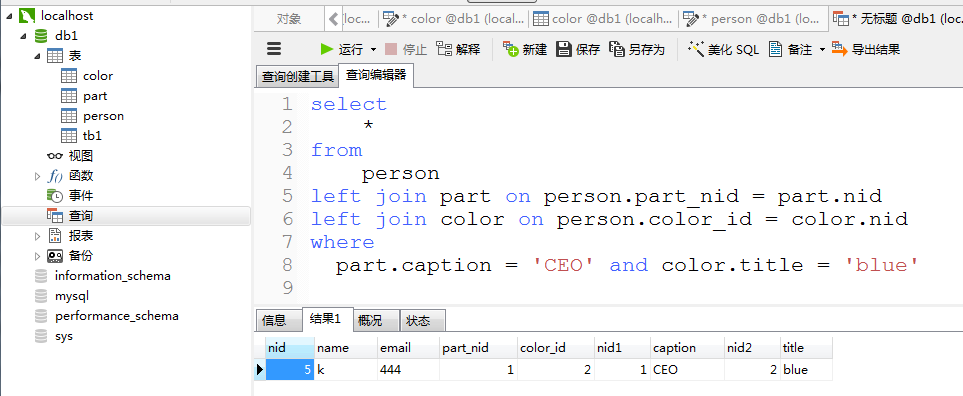

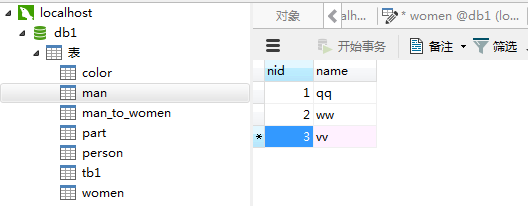
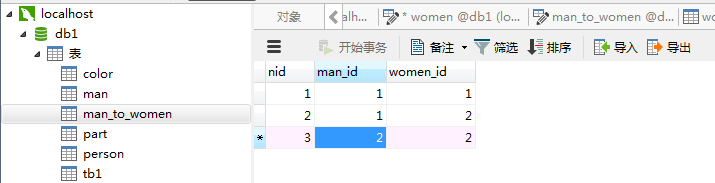
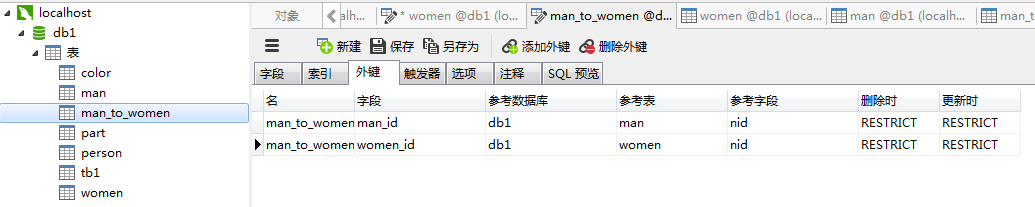
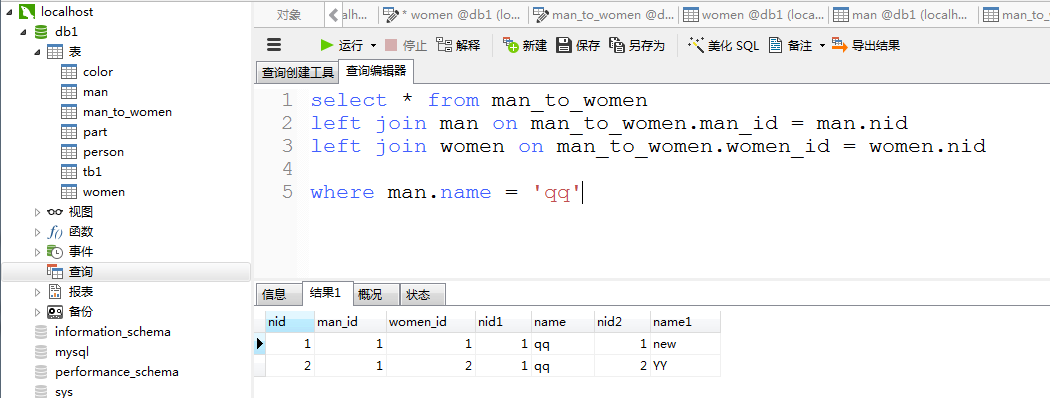
select * from man_to_women left join man on man_to_women.man_id = man.nid left join women on man_to_women.women_id = women.nid where man.name ='qq'
SQL注入
字符串拼接,会出现SQL注入
cursor.execute方法,无法注入
#***sql的注释 -- 两个减号 加空格*** def post(self, *args, **kwargs): username = self.get_argument('user', None) pwd = self.get_argument('pwd', None) print(username,pwd) # 创建连接 conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='db1') # 创建游标 cursor = conn.cursor() print(1231) # sql注入 前端 # user 的input: alex' or 1=1 -- ' # pwd 的input : 随便输入 temp = "select name from userinfo where name='%s' and password = '%s' " %(username, pwd) effect_row = cursor.execute(temp) result = cursor.fetchone() conn.commit() cursor.close() conn.close() if result: self.write('登录成功') else: self.write('登录失败') ##正确写法 effect_row = cursor.execute("select name from userinfo where name='%s' and password = '%s' " %(username, pwd),)

调试办法

视图
视图是一个虚拟表(非真实存在),其本质是【根据SQL语句获取动态的数据集,并为其命名】,用户使用时只需使用【名称】即可获取结果集,并可以将其当作表来使用。
- 将SQL语句封装
- 将结果集当成一张表操作
1、创建视图
用create view语句来创建
--格式:CREATE VIEW 视图名称 AS SQL语句
--格式:CREATE VIEW 视图名称 AS SQL语句 #因为man表和women表都有name字段,有冲突,所以要重命名 create view v1 as select man_to_women.nid,man.name as mname,women.name as wname from man_to_women left join man on man_to_women.man_id = man.nid left join women on man_to_women.man_id = women.nid where man.name = 'qq'

2、删除视图
用drop语句,其语法为 drop view viewname;
drop view v1;
3、修改视图
-- 格式:ALTER VIEW 视图名称 AS SQL语句 ALTER VIEW v1 AS SELET A.nid, B. NAME FROM A LEFT JOIN B ON A.id = B.nid LEFT JOIN C ON A.id = C.nid WHERE A.id > 2 AND C.nid < 5
4、使用视图
使用视图时,将其当作表进行操作即可,由于视图是虚拟表,所以无法使用其对真实表进行创建、更新和删除操作,仅能做查询用。
select * from v1
存储过程
存储过程是一个SQL语句集合,当主动去调用存储过程时,其中内部的SQL语句会按照逻辑执行。
存储过程就是为以后使用而保存的一条或多条SQL语句。
1、创建存储过程
2、删除存储过程
3、执行存储过程
##存储过程,类似函数 创建存储过程 create procedure proc_p1() #必须加括号,一般以proc_**来定义 begin select * from man; #写内容 end 调用: call proc_p1(); 删除: drop procedure proc_p1(); 修改: 可修改,但一般不修改,因为复杂,所以选择重写
规范严谨的写法
带参数的存储过程 delimiter $$ #SQL语句以分号为结束,此处声明以$$为结束 drop procedure if exists proc_p1; #检查语句 create procedure proc_p1(in i1 int) #i1参数 begin declare d1 int; # 申明局部变量 declare d2 int default 3; set d1 = i1 + d2; select * from man_to_women where nid > d1; end $$ #以$$结束 delimiter ; #恢复以分号为结束 #调用存储过程 call proc_p1(1);
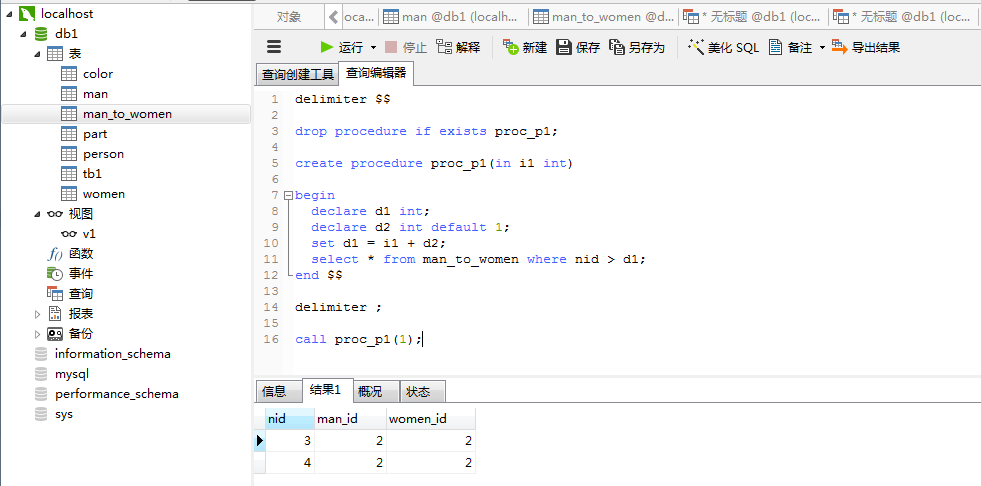
对于存储过程,可以接收参数,其参数有三类:
- in 仅用于传入参数用
- out 仅用于返回值用
- inout 既可以传入又可以当作返回值
delimiter $$ drop procedure if exists proc_p1; create procedure proc_p1( in i1 int, inout ii int, out i2 int ) begin declare d2 int default 1; set ii = ii + 1; select * from man; if i1 = 1 then set i2 = 100 + d2; elseif i1 = 2 then set i2 = 200 + d2; else set i2 = 1000 + d2; end if; end $$ delimiter ;
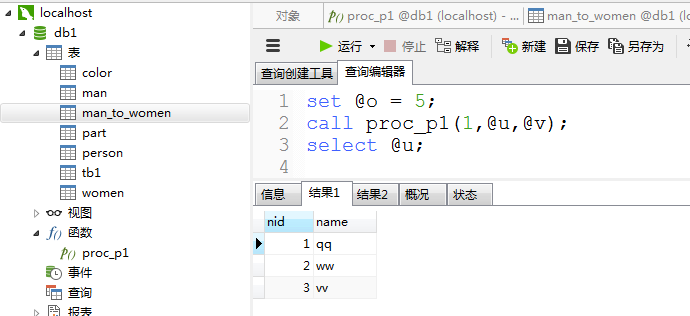
import pymysql conn = pymysql.connect(host='127.0.0.1',port=3306,user='root',passwd='***',db='db1') cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) #执行存储过程 row = cursor.callproc('proc_p1',(1,2,3)) #存储过程的查询结果 selc = cursor.fetchall() print(selc) #获取存储过程返回 effect_row = cursor.execute("select @_proc_p1_0, @_proc_p1_1, @_proc_p1_2") #取存储过程返回值 result = cursor.fetchone() print(result) conn.commit() cursor.close() conn.close()

delimiter $$ drop procedure if exists proc_p2; create procedure proc_p2() begin declare d2 int default 0; select man_id into d2 from man_to_women where nid = 3; select name from man where nid = d2; end$$ delimiter ; call proc_p2();

触发器
对某个表进行【增/删/改】操作的前后如果希望触发某个特定的行为时,可以使用触发器,触发器用于定制用户对表的行进行【增/删/改】前后的行为。
1、创建基本语法
全部语法如下
# 插入前 CREATE TRIGGER tri_before_insert_tb1 BEFORE INSERT ON tb1 FOR EACH ROW BEGIN ... END # 插入后 CREATE TRIGGER tri_after_insert_tb1 AFTER INSERT ON tb1 FOR EACH ROW BEGIN ... END # 删除前 CREATE TRIGGER tri_before_delete_tb1 BEFORE DELETE ON tb1 FOR EACH ROW BEGIN ... END # 删除后 CREATE TRIGGER tri_after_delete_tb1 AFTER DELETE ON tb1 FOR EACH ROW BEGIN ... END # 更新前 CREATE TRIGGER tri_before_update_tb1 BEFORE UPDATE ON tb1 FOR EACH ROW BEGIN ... END # 更新后 CREATE TRIGGER tri_after_update_tb1 AFTER UPDATE ON tb1 FOR EACH ROW BEGIN ... END 基本语法
delimiter $$ create trigger tri_before_insert_color before insert on color for each row begin insert into man(name) values('bird'); end $$ delimiter ;
delimiter $$ drop trigger if exists tri_before_insert_color $$ create trigger tri_before_insert_color before insert on color for each row begin insert into man(name) values(new.title); end $$ delimiter ;
delimiter $$ drop trigger if exists tri_before_del_color $$ create trigger tri_before_del_color before delete on color for each row begin insert into man(name) values(old.title); end $$ delimiter ;
特别的:NEW表示即将插入的数据行,OLD表示即将删除的数据行。
NEW 插入
old 删除
new old 更新
2、删除触发器
DROP TRIGGER tri_after_insert_tb1;
3、使用触发器
触发器无法由用户直接调用,而知由于对表的【增/删/改】操作被动引发的。
insert into tb1(num) values(666)
函数
select 执行
不能返回结果集
1、内置函数
CHAR_LENGTH(str) 返回值为字符串str 的长度,长度的单位为字符。一个多字节字符算作一个单字符。 对于一个包含五个二字节字符集, LENGTH()返回值为 10, 而CHAR_LENGTH()的返回值为5。 CONCAT(str1,str2,...) 字符串拼接 如有任何一个参数为NULL ,则返回值为 NULL。 CONCAT_WS(separator,str1,str2,...) 字符串拼接(自定义连接符) CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。 CONV(N,from_base,to_base) 进制转换 例如: SELECT CONV('a',16,2); 表示将 a 由16进制转换为2进制字符串表示 FORMAT(X,D) 将数字X 的格式写为'#,###,###.##',以四舍五入的方式保留小数点后 D 位, 并将结果以字符串的形式返回。若 D 为 0, 则返回结果不带有小数点,或不含小数部分。 例如: SELECT FORMAT(12332.1,4); 结果为: '12,332.1000' INSERT(str,pos,len,newstr) 在str的指定位置插入字符串 pos:要替换位置其实位置 len:替换的长度 newstr:新字符串 特别的: 如果pos超过原字符串长度,则返回原字符串 如果len超过原字符串长度,则由新字符串完全替换 INSTR(str,substr) 返回字符串 str 中子字符串的第一个出现位置。 LEFT(str,len) 返回字符串str 从开始的len位置的子序列字符。 LOWER(str) 变小写 UPPER(str) 变大写 LTRIM(str) 返回字符串 str ,其引导空格字符被删除。 RTRIM(str) 返回字符串 str ,结尾空格字符被删去。 SUBSTRING(str,pos,len) 获取字符串子序列 LOCATE(substr,str,pos) 获取子序列索引位置 REPEAT(str,count) 返回一个由重复的字符串str 组成的字符串,字符串str的数目等于count 。 若 count <= 0,则返回一个空字符串。 若str 或 count 为 NULL,则返回 NULL 。 REPLACE(str,from_str,to_str) 返回字符串str 以及所有被字符串to_str替代的字符串from_str 。 REVERSE(str) 返回字符串 str ,顺序和字符顺序相反。 RIGHT(str,len) 从字符串str 开始,返回从后边开始len个字符组成的子序列 SPACE(N) 返回一个由N空格组成的字符串。 SUBSTRING(str,pos) , SUBSTRING(str FROM pos) SUBSTRING(str,pos,len) , SUBSTRING(str FROM pos FOR len) 不带有len 参数的格式从字符串str返回一个子字符串,起始于位置 pos。带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于位置 pos。 使用 FROM的格式为标准 SQL 语法。也可能对pos使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的pos 字符,而不是字符串的开头位置。在以下格式的函数中可以对pos 使用一个负值。 mysql> SELECT SUBSTRING('Quadratically',5); -> 'ratically' mysql> SELECT SUBSTRING('foobarbar' FROM 4); -> 'barbar' mysql> SELECT SUBSTRING('Quadratically',5,6); -> 'ratica' mysql> SELECT SUBSTRING('Sakila', -3); -> 'ila' mysql> SELECT SUBSTRING('Sakila', -5, 3); -> 'aki' mysql> SELECT SUBSTRING('Sakila' FROM -4 FOR 2); -> 'ki' TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str) TRIM(remstr FROM] str) 返回字符串 str , 其中所有remstr 前缀和/或后缀都已被删除。若分类符BOTH、LEADIN或TRAILING中没有一个是给定的,则假设为BOTH 。 remstr 为可选项,在未指定情况下,可删除空格。 mysql> SELECT TRIM(' bar '); -> 'bar' mysql> SELECT TRIM(LEADING 'x' FROM 'xxxbarxxx'); -> 'barxxx' mysql> SELECT TRIM(BOTH 'x' FROM 'xxxbarxxx'); -> 'bar' mysql> SELECT TRIM(TRAILING 'xyz' FROM 'barxxyz'); -> 'barx' 部分内置函数
2、自定义函数
delimiter \\ create function f1( i1 int, i2 int) returns int BEGIN declare num int; set num = i1 + i2; return(num); END \\ delimiter ;
3、删除函数
drop function func_name;
4、执行函数
# 获取返回值 declare @i VARCHAR(32); select UPPER('alex') into @i; SELECT @i; # 在查询中使用 select f1(11,nid) ,name from tb2;
事务
事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性。
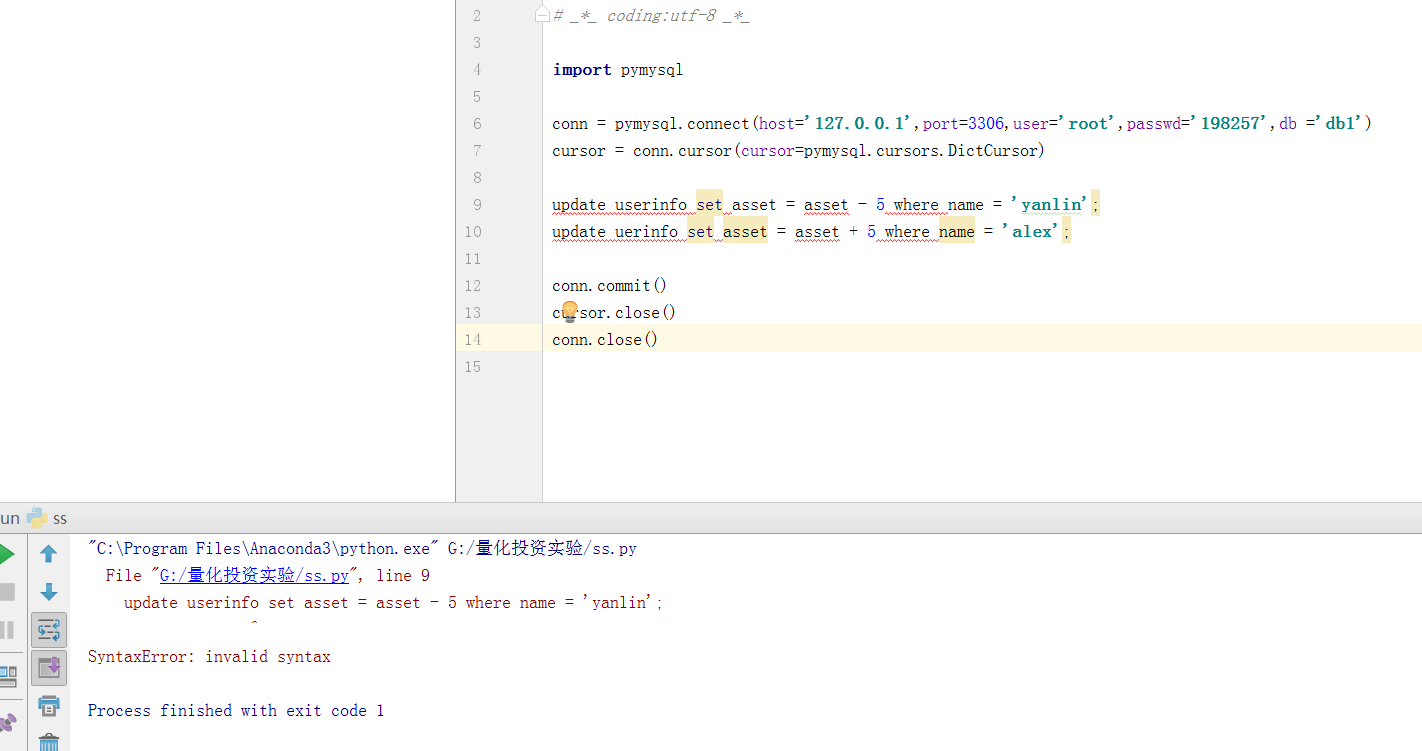
update userinfo set asset = asset - 5 where name = 'yanlin'; update uerinfo set asset = asset + 5 where name = 'alex'; update userinfo set asset = asset + 5 where name = 'alex'; delimiter $$ create PROCEDURE p1( OUT p_return_code tinyint ) BEGIN DECLARE exit handler for sqlexception BEGIN -- ERROR set p_return_code = 1; rollback; END; DECLARE exit handler for sqlwarning BEGIN -- WARNING set p_return_code = 2; rollback; END; START TRANSACTION; update userinfo set asset = asset - 5 where name = 'yanlin'; update uerinfo set asset = asset + 5 where name = 'alex'; COMMIT; -- SUCCESS set p_return_code = 0; END$$ delimiter ;
set @i =0;
call p1(@i);select @i;import pymysql conn = pymysql.connect(host='127.0.0.1',port=3306,user='root',passwd='198257',db ='db1') cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) update userinfo set asset = asset - 5 where name = 'yanlin'; update uerinfo set asset = asset + 5 where name = 'alex'; conn.commit() cursor.close() conn.close()
rollback 回滚
commit 提交
transaction 执行
动态执行SQL语句
传值必须是带@
@用户名变量
@@全局变量
prepare prod from 'select * from man where nid >?'; 编译SQL语句,并执行
delimiter $$ drop procedure if exists proc_sql $$ create procedure proc_sql() begin declare p1 int; set p1 = 4; set @p1 = p1; prepare prod from 'select * from man where nid >?'; execute prod using @p1; deallocate prepare prod; end $$ delimiter ;
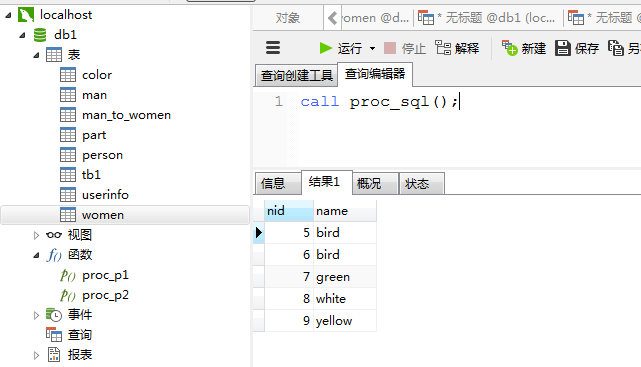
delimiter $$ drop procedure if exists proc_sql2 $$ create procedure proc_sql2( in strSQL varchar(128), in nid int ) begin set @p1 = nid; set @sqll = strSQL; prepare prod from @sqll; execute prod using @p1; deallocate prepare prod; end $$ delimiter ;

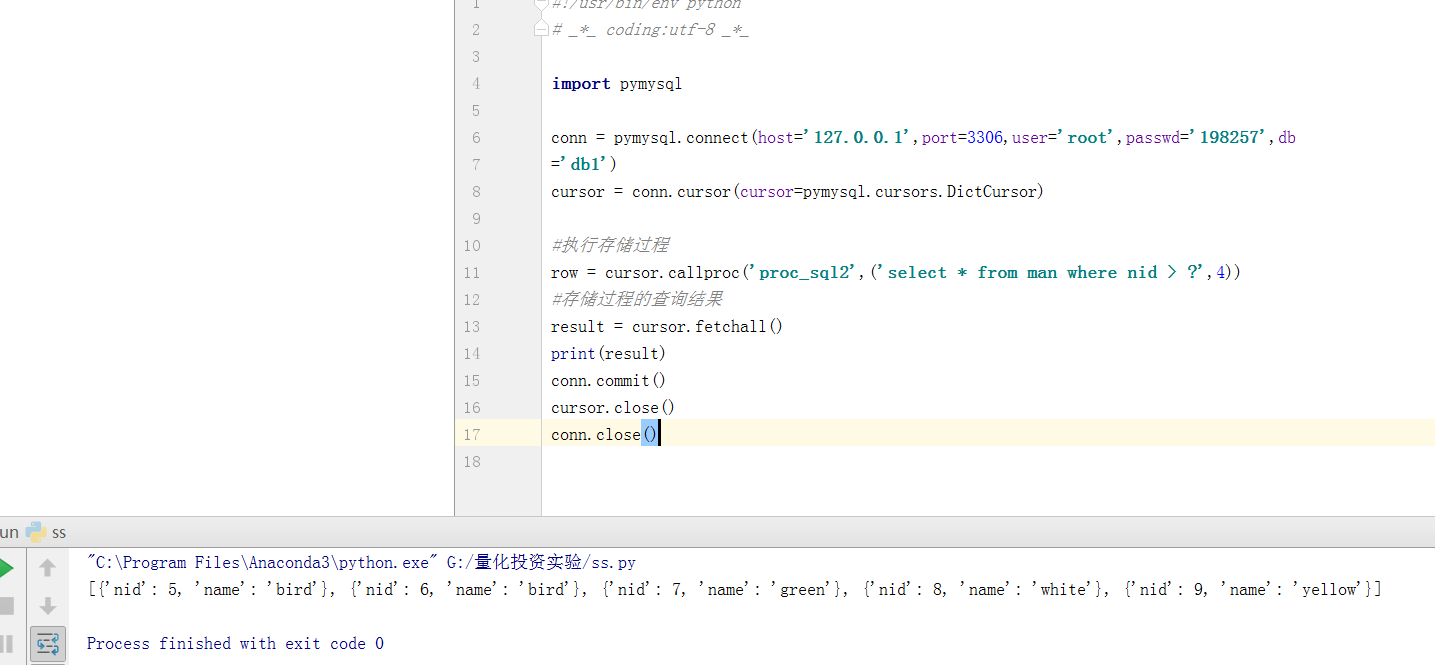
#!/usr/bin/env python # _*_ coding:utf-8 _*_ import pymysql conn = pymysql.connect(host='127.0.0.1',port=3306,user='root',passwd='198257',db ='db1') cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) #执行存储过程 row = cursor.callproc('proc_sql2',('select * from man where nid > ?',4)) #存储过程的查询结果 result = cursor.fetchall() print(result) conn.commit() cursor.close() conn.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号