
Pandas 自动分割汇总表写入到子表
https://mp.weixin.qq.com/s/XY1lS4mxEf7BTf8UnFmaFA
根据汇总表的分区字段自动填入指定的分区文件中:
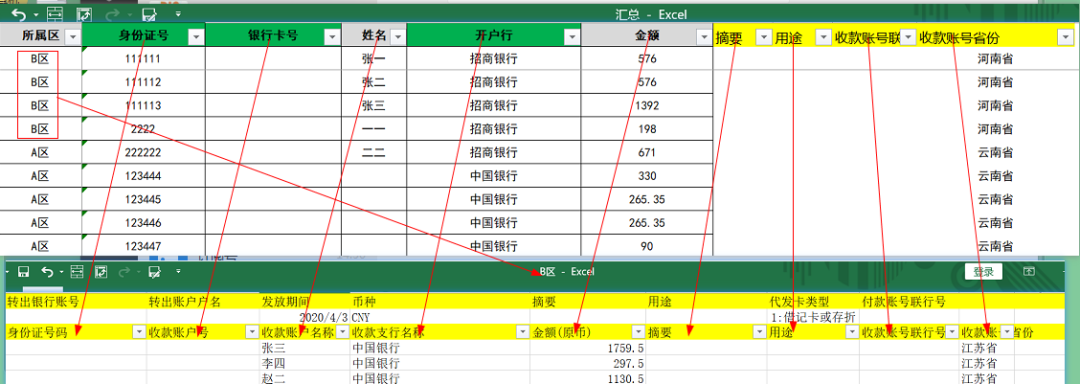
对于分区表的文件,例如A区.xlsx、B区.xlsx等,需要先将3行之后已经存在的数据删除后再进行写入。
B区.xlsx在自动填入后,结果如下:

其实初始需求非常简单,我们下面看看怎么做吧。
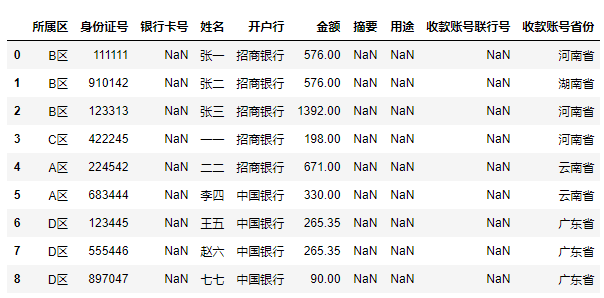
汇总表的数据情况
import pandas as pd
data = pd.read_excel("汇总.xlsx", sheet_name='明细')
data
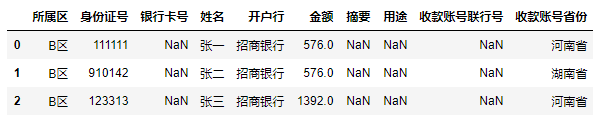
对于B区的数据如何写入呢?
筛选出准备写入B区的数据
df = data[data["所属区"] == "B区"] df
df = df.iloc[:, 1:] df.values.tolist()
[[111111, nan, '张一', '招商银行', 576.0, nan, nan, nan, '河南省'], [111112, nan, '张二', '招商银行', 576.0, nan, nan, nan, '湖南省'], [111113, nan, '张三', '招商银行', 1392.0, nan, nan, nan, '河南省']]
覆盖写入到对应的分区文件
workbook = load_workbook(filename="B区.xlsx")
sheet = workbook.active
先删除第4行之后的旧数据,预计1000行完全够用,具体数量根据自己的数据来大致估算。
sheet.delete_rows(idx=4, amount=1000)
然后再进行添加数据
for row in df.values.tolist():
sheet.append(row)
workbook.save(filename="B区.xlsx")
workbook.close()
查看名为B区的Excel:

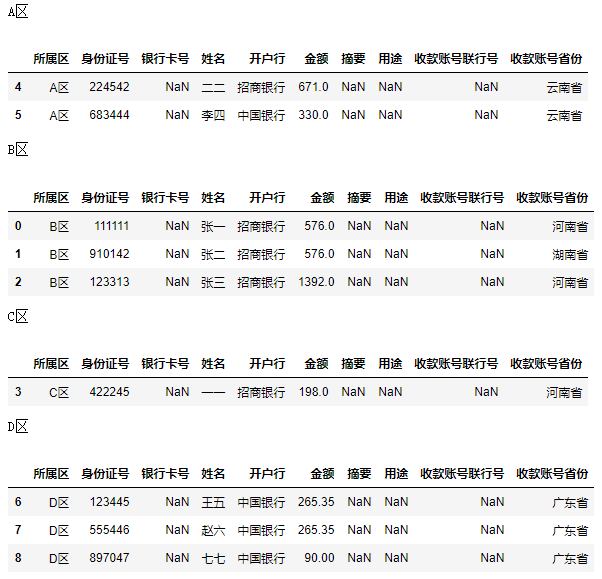
遍历分区字段的简单办法
for area, df in data.groupby('所属区'):
print(area)
display(df)
完整代码
data = pd.read_excel("汇总.xlsx", sheet_name='明细')
for area, df in data.groupby('所属区'):
print(area)
if os.path.exists(f"{area}.xlsx"):
workbook = load_workbook(filename=f"{area}.xlsx")
else:
print(f"{area}.xlsx不存在")
continue
sheet = workbook.active
df = df.iloc[:, 1:]
# 先删除第4行之后的旧数据,预计1000行完全够用
sheet.delete_rows(idx=4, amount=1000)
# 然后在进行添加数据
for row in df.values.tolist():
sheet.append(row)
print(row)
print(f"保存到{area}.xlsx文件中")
workbook.save(filename=f"{area}.xlsx")
workbook.close()
好了经过以上步骤,就成功完成任务了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号