# author: Roy.G
# 神经网络的隐藏层
# 通过大量数据训练,使模型泛化
import dataset
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D as a3d
def sigmoid(x):
return 1/(1+np.exp(-x))
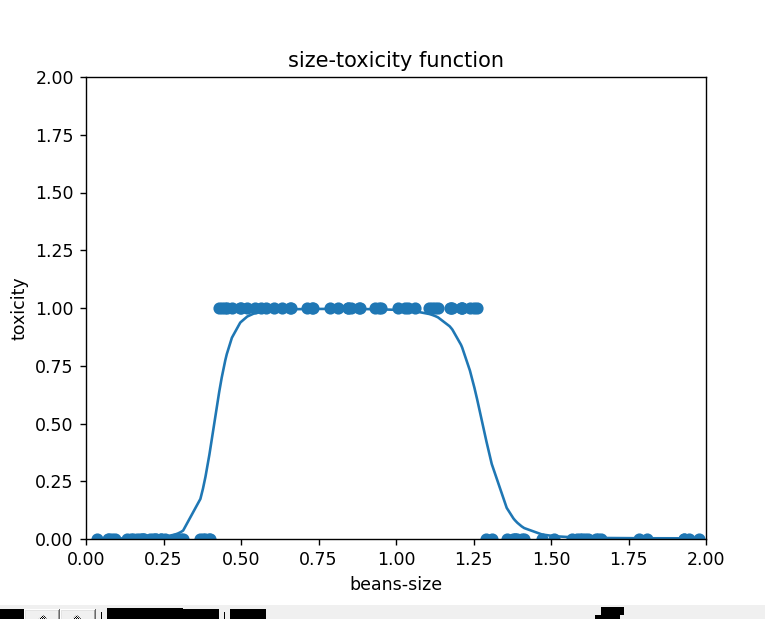
xs,ys=dataset.get_beans(100)
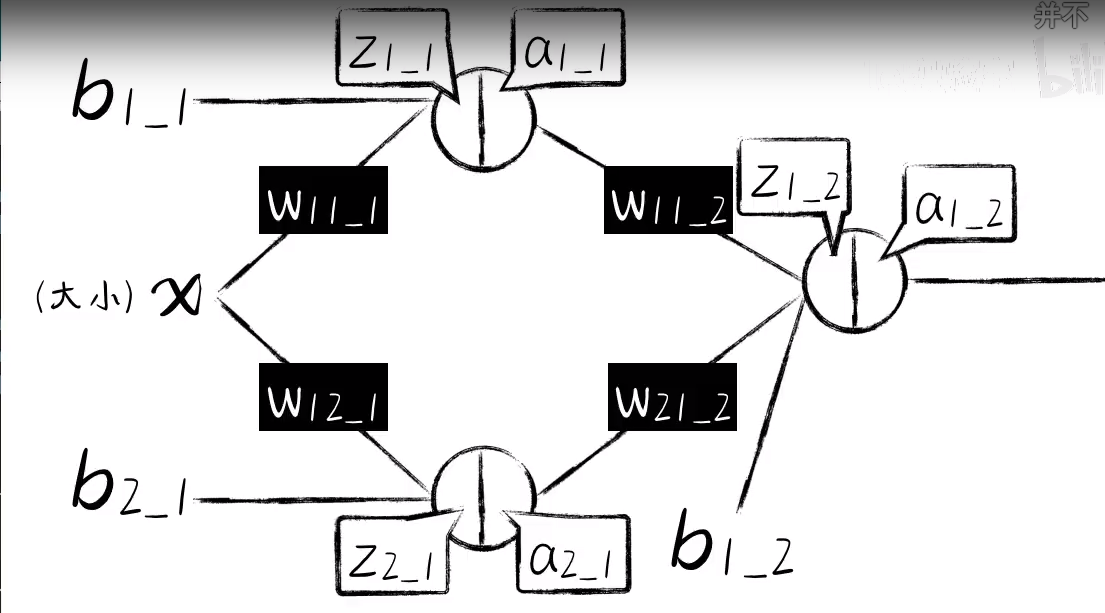
# 第一层,共两个神经元,w11 ,w12
w1_1_1=np.random.rand()
b1_1_1=np.random.rand()
# 第二个神经元
w1_2_1=np.random.rand()
b1_2_1=np.random.rand()
# 第二层神经元
w2_1_1=np.random.rand()
w2_1_2=np.random.rand()
b2_1_1=np.random.rand()
# 前向传播
def forward_propagation(xs):
#命名规则a1_1_1(第一层_第一个神经元_第一个参数)
# 神经元的够成,是由一元函数和激活函数构成,一元函数可以成为加权函数
# 第一层第一个神经元
z1_1_1 = w1_1_1*xs + b1_1_1
a1_1_1 = sigmoid(z1_1_1)
# 第一层第二个神经元
z1_2_1=w1_2_1*xs +b1_2_1
a1_2_1= sigmoid(z1_2_1)
# 第二层神经元
z2_1_1=w2_1_1*a1_1_1+w2_1_2*a1_2_1+b2_1_1
a2_1_1=sigmoid(z2_1_1)
return z1_1_1,a1_1_1,z1_2_1,a1_2_1,z2_1_1,a2_1_1
# z1_1_1,a1_1_1,z1_2_1,a1_2_1,z2_1_1,a2_1_1=forward_propagation(xs)
# plt.scatter(xs,ys)
# plt.plot(xs,a2_1_1)
# plt.show()
for k in range(5000):
for i in range(100):
x = xs[i]
y = ys[i]
z1_1_1,a1_1_1,z1_2_1,a1_2_1,z2_1_1,a2_1_1=forward_propagation(x)
e=(y-a2_1_1)**2
#反向传播
#第二个神经元对dz2_1_1求导
de_da2_1_1=-2*(y-a2_1_1)
da2_1_1_dz2_1_1=a2_1_1*(1-a2_1_1)
# 第二层神经元向对第二层的参数w,b求导
dz2_1_1_dw2_1_1 = a1_1_1
dz2_1_1_dw2_1_2 = a1_2_1
#第二层的神经元dw参数导数
de_dw2_1_1 = de_da2_1_1 * da2_1_1_dz2_1_1 * dz2_1_1_dw2_1_1
de_dw2_1_2 = de_da2_1_1 * da2_1_1_dz2_1_1 * dz2_1_1_dw2_1_2
# 第二层神经元b的倒数
dz2_1_1_db2_1_1=1
de_db2_1_1= de_da2_1_1 * da2_1_1_dz2_1_1 * dz2_1_1_db2_1_1
# 到这里,倒数是要进行调整的参数,下面我们要继续反向传播误差,到第一层
#对第一层第一个神经元的参数w,b进行求导
# 对dedw1_1_1求导
dz2_1_1_da1_1_1=w2_1_1
da_1_1_dz1_1_1=a1_1_1*(1-a1_1_1)
dz1_1_1_dw1_1_1=x
de_dw1_1_1=de_da2_1_1 * da2_1_1_dz2_1_1 * dz2_1_1_da1_1_1 * da_1_1_dz1_1_1 * dz1_1_1_dw1_1_1
# 对de_db1_1_1求导
dz1_1_1_db1_1_1=1
de_db1_1_1=de_da2_1_1 * da2_1_1_dz2_1_1 * dz2_1_1_da1_1_1 * da_1_1_dz1_1_1 * dz1_1_1_db1_1_1
#对第一层第二个神经元进行求导
#de_dw1_2_1求导
dz2_1_1_da1_2_1=w2_1_2
da1_2_1_dz1_2_1=a1_2_1*(1-a1_2_1)
dz1_2_1_dw1_2_1=x
de_dw1_2_1=de_da2_1_1*da2_1_1_dz2_1_1*dz2_1_1_da1_2_1*da1_2_1_dz1_2_1*dz1_2_1_dw1_2_1
# de对b1_2_1求导
dz1_2_1_db1_2_1=1
de_db1_2_1=de_da2_1_1*da2_1_1_dz2_1_1*dz2_1_1_da1_2_1*da1_2_1_dz1_2_1*dz1_2_1_db1_2_1
#对参数进行迭代
af=0.03
w1_1_1 = w1_1_1 - af * de_dw1_1_1
w1_2_1 = w1_2_1 - af * de_dw1_2_1
b1_1_1 = b1_1_1 - af * de_db1_1_1
b1_2_1 = b1_2_1 - af * de_db1_2_1
w2_1_1 = w2_1_1 - af * de_dw2_1_1
w2_1_2 = w2_1_2 - af * de_dw2_1_2
b2_1_1 = b2_1_1 - af * de_db2_1_1
# print('w111:',w1_1_1,'w1_1_1',w1_2_1,'b1_1_1',b1_1_1,'w2_1_1',w2_1_1,'w2_1_2',w2_1_2,'b2_1_1',b2_1_1)
if k%100 == 0:
plt.clf()
plt.scatter(xs,ys)
plt.title("size-toxicity function")
plt.xlabel("beans-size")
plt.ylabel("toxicity")
z1_1_1, a1_1_1, z1_2_1, a1_2_1, z2_1_1, a2_1_1 = forward_propagation(xs)
plt.xlim(0,2)
plt.ylim(0,2)
plt.plot(xs,a2_1_1)
plt.pause(0.001)