

位图法
2012-08-04 13:26 coodoing 阅读(1411) 评论(0) 编辑 收藏 举报判断集合中存在重复是常见编程任务之一,当集合中数据量比较大时我们通常希望少进行几次扫描,这时双重循环法就不可取了。位图法比较适合于这种情况,它的做法是按照集合中最大元素max创建一个长度为max+1的新数组,然后再次扫描原数组,遇到几就给新数组的第几位置上1。如遇到5就给新数组的第六个元素置1,这样下次再遇到5想置位时发现新数组的第六个元素已经是1了,这说明这次的数据肯定和以前的数据存在着重复。这种给新数组初始化时置零其后置一的做法类似于位图的处理方法故称位图法。它的运算次数最坏的情况为2N。如果已知数组的最大值即能事先给新数组定长的话效率还能提高一倍。Bloom filter可以看做是对bit-map的扩展。下面为利用位图法实现整形数组的排序代码。
1: public class BitmapSort {
2:
3: /**
4: * 使用位图法进行排序
5: * 找到最小值和最大值,申请位图数组,对应位赋值为1,最后依次输出。
6: * @param arr
7: */
8: public static void bitmapSort(int[] arr) {
9: int max = arr[0];
10: int min = max;
11: for (int i : arr) {
12: if (max < i) {
13: max = i;
14: }
15: if (min > i) {
16: min = i;
17: }
18: }
19: System.out.println("最大最小元素分别为:"+max + " " + min);
20:
21: int[] bitArr = new int[max - min + 1];
22: for (int i : arr) {
23: int index = i - min;
24: bitArr[index]++;
25: }
26:
27: System.out.println("bitmap后的数组元素为:");
28: for (int i : bitArr) {
29: System.out.print(i+" ");
30: }
31: System.out.println();
32:
33: int index = 0;
34: for (int i = 0; i < bitArr.length; i++) {
35: while (bitArr[i] > 0) {
36: arr[index] = i + min;
37: index++;
38: bitArr[i]--;
39: }
40: }
41: }
42:
43: public static void main(String[] args) {
44: int[] arr = { 1, 7, -3, 0, 0, 6, 6, 9, -11 };
45: bitmapSort(arr);
46: System.out.println("Bitmap排序后的结果:");
47: for (int i : arr) {
48: System.out.print(i + " ");
49: }
50: }
51: }
位图法存数据
Bit-map是用一个bit位来标记某个元素对应的Value, 而Key即是该元素。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。 在 8K 字节的内存空间内,如何存 unsigned short 类型数据?
一般做法:
定义一个数组: unsigned short arrNormal[4096]; 这样做,最多只能存 4K 个 unsigned short 数据。
利用位图法:
定义一个数组: unsigned char arrBit[4096]; 这样做,能存 4K*8=32K 个 unsigned short 数据。
写数据元素:计算待写入数据在 arrBit 存放的字节位置和位位置(字节 0~4095 ,位 0~7 )
比如首先写 1234 ,字节序: 1234/8 = 154; 比特位序: 1234 & 0b111 = 2 ,那么 1234 放在 arrBit 数组的下标为 154 处,把该字节的 2 号位( 0~7)置为 1。
字节位置: int nBytePos = 1234/8 = 154;
位位置: int nBitPos = 1234 & 7 = 2;
// 把数组下标为 154 的 第2 个bit位置为 1
unsigned short val = 1<<nBitPos;
arrBit[nBytePos] = arrBit[nBytePos] | val; // 写入 1234 得到 arrBit[154]=0b00000100
此时再写入 1236 ,
字节位置: int nBytePos = 1236/8 = 154;
位位置: int nBitPos = 1236 & 7 = 4
// 把数组下标为 154 的 第4 个bit位置为 1
val = 1<<nBitPos;
arrBit[nBytePos] = arrBit[nBytePos] | val; // 再写入 1236 得到 arrBit[154]=0b00010100
获取插入数据后的value值为:
1: int bytepos = data/8;
2: int bitpos = data&7;
3:
4: bitarr[bytepos] = bitarr[bytepos]|(1<<(7-bitpos));
5:
6: int i = bitarr[bytepos];
7: byte[] b = toByteArray(i, 4); //整型到字节
8:
9: System.out.println(Integer.toBinaryString(i));
1: byte[] toByteArray(int iSource, int iArrayLen) {
2: byte[] bLocalArr = new byte[iArrayLen];
3: for ( int i = 0; (i < 4) && (i < iArrayLen); i++) {
4: bLocalArr[i] = (byte)( iSource>>8*i & 0xFF );
5: }
6: return bLocalArr;
7: }
具体事例
结合上述代码,我们来看一个具体的例子。假设我们要对0-7内的5个元素(4,7,2,5,3)排序(这里假设这些元素没有重复)。那么我们就可以采用Bit-map的方法来达到排序的目的。要表示8个数,我们就只需要8个Bit(1Bytes),首先我们开辟1Byte的空间,将这些空间的所有Bit位都置为0(如下图:)
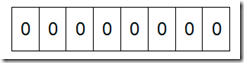
然后遍历这5个元素,首先第一个元素是4,那么就把4对应的位置为1(可以这样操作 p+(i/8)|(0×01<<(i%8)) 当然了这里的操作涉及到Big Endian 和 Little Endian的情况,这里默认为Big Endian ),因为是从零开始的,所以要把第五位置为一(如下图):
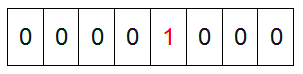
然后再处理第二个元素7,将第八位置为1,,接着再处理第三个元素,一直到最后处理完所有的元素,将相应的位置为1,这时候的内存的Bit位的状态如下:
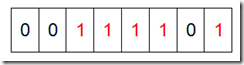
然后我们现在遍历一遍Bit区域,将该位是一的位的编号输出(2,3,4,5,7),这样就达到了排序的目的。
位图法的缺点:
1. 可读性差。
2. 位图存储的元素个数虽然比一般做法多,但是存储的元素大小受限于存储空间的大小。
位图存储性质:存储的元素个数等于元素的最大值。比如, 1K 字节内存,能存储 8K 个值大小上限为 8K 的元素。(元素值上限为 8K ,这个局限性很大!)比如,要存储最大值为 65535 的数,就必须要 65535/8=8K 字节的内存。导致了位图法根本不适合数组中元素差异较大的情况。{1,1000,1000000}
3. 位图对有符号类型数据的存储,需要 2 位来表示一个有符号元素。这会让位图能存储的元素个数,元素值大小上限减半。比如 8K 字节内存空间存储 short 类型(有符号short)数据只能存 8K*4=32K 个,元素值大小范围为 -32K~32K 。
big endian是指低地址存放最高有效字节(MSB),而little endian则是低地址存放最低有效字节(LSB)。
比如0x12345678在两种不同字节序中的存储顺序如下所示:
Big Endian
低地址 高地址
----------------------------------------->
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 12 | 34 | 56 | 78 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Little Endian
低地址 高地址
----------------------------------------->
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 78 | 56 | 34 | 12 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
