面试话痨(三)我会锁的四种配法,您配吗?
面试话痨系列是从技术广度的角度去回答面试官提的问题,适合萌新观看!
面试官,我知道一种在走路时不被锁绊倒的方法,你想听吗?
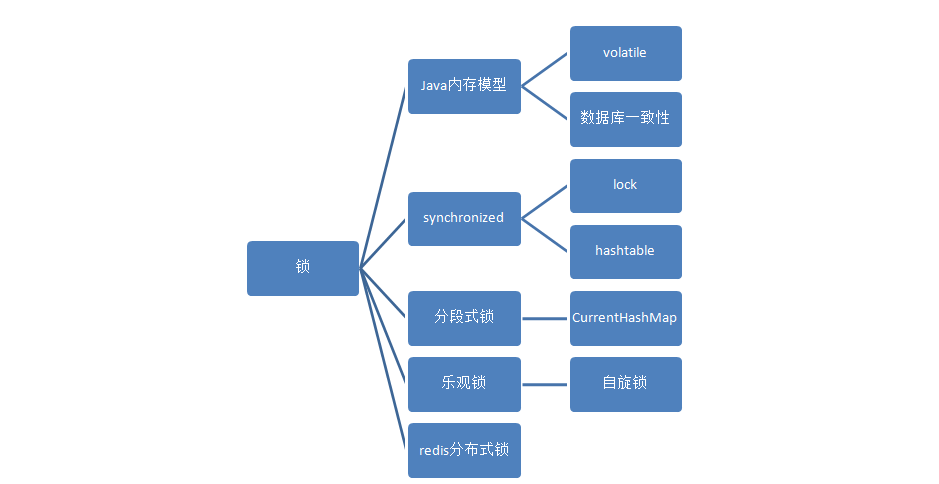
锁相关的知识,我们可以记住下面这个知识网,这样虽然不可能保证所有的问题都会,至少能开开心心的跟面试官聊个一瓶矿泉水的时间。
一、为啥要有多线程?
因为CPU太快了。CPU是一个电学组件,它在大部分时间的运算速度都是光速。而大部分的外接设备,如:
1. 打印机、音响、键盘、鼠标还停留在物理速度这一层。
2. 机械硬盘之所以叫机械,也是因为用了物理的磁头,读取数据时还需要用马达转动磁头。
3. 错综复杂的网络环境。
这些设备对于CPU来说太慢了。所以就有了CPU的时间片轮转制度。CPU可以处理完打印机的运算,接着再去处理其他的事,其他的事情处理完以后,再回来看打印机处理完没有。
二、如何支持多线程?(Java内存模型)
所以,支持多线程是必须的。Java内存模型体现了多线程的支持原理(Java内存模型和JVM内存模型不是一个东西,详细区分传送门:面试话痨(四)常量在哪里呀,常量在哪里)。
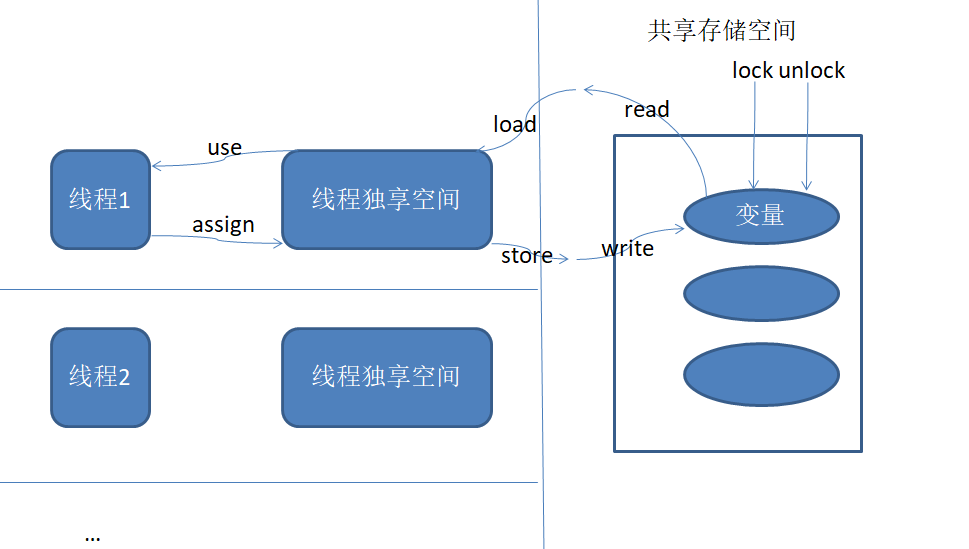
大体的操作流程是,从共享的存储空间中复制一份自己需要的数据到线程独享的工作空间,对该数据进行一系列的运算后,再覆盖掉共享空间中原本的数据。整个操作按顺序分为6个步骤:read,load,use,assign,store,write。另外还允许使用lock,unlock锁住共享空间中的数据,避免其他线程同时操作一个变量。这八个操作是最基础的不可拆分的操作,因此被称为原子操作。
在没有使用lock上锁的前提下,多个线程可以同时读取一个变量,然后在各自的空间中同时运算。这就是Java支持多线程的方式。
三、多线程会有啥问题?
就好像炒菜一样,如果几个人几个锅一起炒,难免会手忙脚乱出点错。出错的方式主要是三方面:
1. 不可见性。炒菜之前,我们不会每次都去确认酱油瓶中是否还有酱油,我们会根据上一次的使用经验默认还有酱油,然而这个酱油可能已经被别人用光了。专业术语就是,线程从共享内存中read出数据并load到独享的工作内存后,use都是直接使用工作内存中的数据,而不会去管共享内存中的数据是否已经被改变。如果其他线程同时修改了这个数据,那么就会造成多线程的错误。
2. 无序性。因为炒菜的过程中过于慌乱,可能会先下肉,下完肉才想起忘记加油。处理器也会调整指令的顺序,当然不是因为处理器慌乱,而是处理器本身的一种性能优化,被称做指令重排。我们小学时应该都做过一道数学题:已知小明写作业需要10分钟,淘米需要2分钟,煮饭需要30分钟,洗衣服需要10分钟,问小明做完这些事至少需要多少秒?我们会通过调整做事的顺序,让小明在尽量短的时间内,完成尽量多的事情。处理器在处理这8种原子操作时,也是会通过指令重排,在尽量短的时间内完成尽量多的事情。过度的指令重排可能就会造成多线程的错误。
3. 非原子性。假如你在做汤时需要加入大量的小米辣,你一次只拿的走一半,所以你先拿了一半,走到锅边,放入小米辣后再回来取另一半,在这个过程中另一半可能已经挪用或者替换了。在java内存模型中也会存在这种情况。基本的8种操作都是原子性的,但是他们操作大数据时,可能就会出现非原子性的问题。比如read一次只能从共享内存中读取32位的数据,而double和long占据了64位的空间,这时的读取就是非原子性的(很多虚拟机已经优化了这个问题,针对64位的long和double执行原子性的操作,但对于更大的数据对象,比如HashMap,它的读取还是非原子性的)。
四、如何解决多线程的问题?
三中已经指出了多线程可能存在的问题,那么反过来说,保证多线程的可见性、有序性、原子性就能保证线程的安全。
原子性是指操作是密不可分一次完成的,这属于放弃多线程去达到绝对的安全。有序性是指抑制处理器的指令重排,保证read、load、use、assign、store、write的读写顺序。至于可见性,我们这里需要着重讲一下:
有的人会认为,如果不同线程间对数据的修改是第一时间相互可见的,那就应该能保证每次想处理数据的都是最新的数据,那应该就没有多线程的问题了!
其实不对,可见的意思是 当你想看的时候,就能看见最新的值。“当你想看” 这是一个主动的过程,并不是一个被动接收的过程。也就是说别的线程修改完值后,并不会主动通知到其他线程。需要其他线程自己去获取最新的值。可见性只能保证每次线程想获取的值是最新的值,不能保证已经获取到的值会随着其他线程的修改而修改。
volitale就能保证操作的有序性和可见性,在一定程度上实现了多线程的安全。但要想完全确保线程安全,还得加锁。常用的加锁方式有 同一个服务内部使用synchronized、分段式锁、乐观锁,不同服务间可以使用分布式锁。
其实这个java内存模型没有想象的那么陌生,它跟我们用过的数据库没啥区别。共享的内存空间就是数据库服务器,每一个建立的数据库链接就是一个线程,我们的SELECT的语句就相当于是read+load,use和assign就是我们自己写的业务相关的逻辑语句,INSERT、UPDATE、DELETE就是store+write。同样数据库也需要保证数据的原子性、隔离性、持久性,最终实现一致性。数据库的锁跟java中的锁也如出一辙。比如将有索引的字段作为限制条件进行UPDATE时,只会锁住某些列,这相当于是分段式锁,另外数据库也有乐观锁悲观锁的概念。如果对数据库锁比较熟悉,在面试过程中可以使用类比的方法介绍java内存模型。面试官问:什么是java内存模型。你先回一句:java内存模型其实跟经常使用的数据库差不多。在大多数面试官眼中都是能加分的。毕竟再难的内存模型百度上也有,背1000个也不能代表什么,相互比对举一反三,才能证明你是一个有想法,会创新的人。
下面就讲讲四种常用的锁实现方式。
五、锁之间的差异
synchronized是最直接的加锁方式,被锁住的对象只能同时被一个线程进行读和写。hashtable就是通过synchronized实现的。和synchronized类似的还有个lock。他是一个接口类,和原子操作中的lock不是一个概念。他与synchronized的区别如下
| synchronized | lock | |
| 本质 | Java关键字 | 接口类 |
| 结束方式 | 执行完相应的代码,用完相应的变量后自动释放锁 | 需要调用unlock主动释放锁 |
| 是否公平 | 非公平锁 | 公平锁、非公平锁可设置 |
| 读写锁分离 | 未分离 | 允许锁读、锁写分别设置 |
| 锁的对象 | 类、对象、代码块 | 代码块 |
| 唤醒方式 | 随机唤醒一个线程或者唤醒全部 | 可唤醒指定线程 |
上段中提到了hashtable,相应的就能想到CurrentHashMap。CurrentHashMap使用了更合理的分段式锁,对性能进行了优化。注意下,所有的性能优化都可以归结为一句话:提高空间复杂度,降低时间复杂度,天下没有免费的午餐,你想得到一件东西的时候,就要付出另外一件东西。在jdk1.7中,CurrentHashMap就是在原来的数组+链表的基础上,再加了一层数组。第一层的数组用于将数据分成不同的段,每一个段上都维护一个单独的锁,这样就允许多个线程同时操作不同的段。集合的数据量越大,第一层的分段越多,性能提升就越明显。再往下的具体实现我觉得没必要再背了,因为你可能还没有背完,这个结构已经被改了。不信我们看jdk1.8。
我们都知道,jdk1.8中,HashMap已经被优化成了size>64并且在某个长度为8的链表上想要再添加的数据时,链表会被优化成红黑树,CurrentHashMap也改成了一样的结构。另外,分段式锁也被改成了乐观锁。
乐观锁顾名思义,重点就突出一个字:乐观。处理器乐观的觉得,这个数据不会被其他线程修改,所以会直接读取数据进行操作,操作完要写入的时候再去根据标识符,判断共享内存中的值是否真的没有被修改,没有的话就顺利插入。这里的标识符一般来说都是一个不断自增的版本号。
也有说如果直接使用一个反复被更改的0、1作为标识符,这样可能就会出现ABA(010)问题。即获取0后标识符被其他线程修改了两次,导致标识符又回到了最初的0,这时候值就会被直接插入,造成多线程问题。但是两种标识符并存的前提是,他们对比起来有不同的优缺点,因此能适用于不同的情况。在我看来,使用自增版本号只有优点,所以我觉得这个ABA问题应该只是个历史遗留知识点,应该没啥技术栈会出这种问题了。
如果乐观锁在插入时遇到了不乐观的情况怎么办?有种办法,就是重新拉取数据和版本号,重复进行一次乐观的计算以后再去对比版本号,如此反复,直到版本号没被其他线程改过以后,放入值。这个过程很像一个不停自旋的水涡,所以这种锁被叫做自旋锁,大名鼎鼎的CAS也就是这个原理。
根据自旋锁的原理,我们也能相应的总结出自旋锁适用的场景:读的线程多,写的线程少的场景。另外,自旋锁的原理挺简单的,建议自己在脑中想想怎么写一个支持自旋的类出来。
微服务多实例时也需要用到锁。比如微服务中有一个定时任务,启了多实例时,需要一个分布式锁去控制只让其中一个实例执行定时任务。我目前就用过redis的分布式锁。直接调用redisTemplate的setIfAbsent方法,返回true则表明插入成功获取到了锁,否则表明已有其他服务执行了该任务。记住setIfAbsent还提供了设置过期时间参数,一定要设置值,避免服务崩溃时造成死锁。
原创不易,转载请注明出处
本系列链接如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号