MySQL事务之MVCC、undo、redo、binlog、二阶段提交
前置概念
1.数据库中,数据在内存中叫data buffer,数据在磁盘上叫data file。
事务的日志也一样,在内存中叫log buffer,在磁盘上叫log file。
2.data buffer中的数据会在合适的时间 由存储引擎写入到data file。并不在事务提交时机制中。
3.checkpoint:
checkpoint是为了定期将db buffer的内容刷新到data file。
当遇到内存不足、db buffer已满等情况时,需要将db buffer中的内容/部分内容(特别是脏数据)转储到data file中。
在转储时,会记录checkpoint发生的”时刻“。在故障恢复时候,只需要redo/undo最近的一次checkpoint之后的操作。
一、redo log
1.概念
记录事务执行后的状态,用来恢复未写入磁盘的数据(data file)的已成功事务更新的数据。
例如某一事务的事务序号为T1,其对数据X进行修改,设X的原值是5,修改后的值为15,那么Redo日志为<T1, X, 15>。
大多数是物理日志。
2.作用
- 保证了事务的持久性。
- 数据库崩溃时回复。如:A字段本来=1,设置A字段=5,内存中的数据data buffer已经改了,redo log也刷入磁盘中了,事务也提交了,但是还没来及的把A字段=5刷到磁盘中,数据库就挂了,那再恢复了数据库看到的A字段就是=1,这时就用redo log来回放把A变成=5
3.流程
以一个事务为例
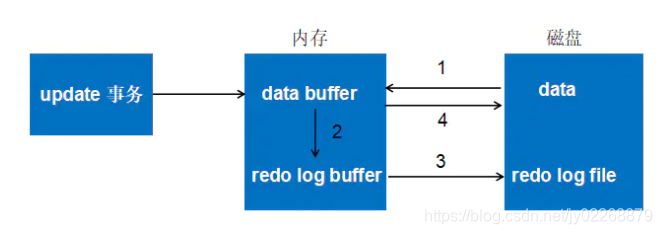
重点:
- 修改后做redo log记录。
- log buffer刷入磁盘后,才提交事务。
- 这种先持久化日志的策略叫做Write Ahead Log,即预写日志。
二、undo
1.概念
用于记录事务开始前的状态,用于事务失败时的回滚操作。
例如某一事务的事务序号为T1,其对数据X进行修改,设X的原值是5,修改后的值为15,那么Undo日志为<T1, X, 5>。
逻辑日志
重点:
- 修改前做undo log记录
- undo log刷入磁盘后,才提交事务。
2.作用
- 保证了事务的原子性(回滚)
- 实现MVCC
- 保证普通select快照读
3.UNDO LOG中分为两种类型
- INSERT_UNDO(INSERT操作),记录插入的唯一键值;
- UPDATE_UNDO(包含UPDATE及DELETE操作),记录修改的唯一键值以及old column记录。
4.举个undo redo合在一起的例子
假设有A、B两个数据,值分别是 1 和 2,在一个事务中先后把A设置为3,B设置为4。
- 事务开始
- 记录A=1到undo log buffer
- 修改A=3
- 记录A=3到redo log buffer
- 记录B=2到undo log buffer
- 修改B=4
- 记录B=4到redo log buffer
- 到log buffer全部刷入到磁盘中后才提交数据
这里有个点,log buffer 刷入到磁盘,并不是最后要提交事物了才来一次性全部刷入到磁盘。log buffer刷入到log file是在事务进行的时候就逐步在做了。
三、恢复
1.事务无法回滚,无法回放的情况 :
- innodb_flush_log_at_trx_commit=2时,将redo日志写入logfile后,为提升事务执行的性能,存储引擎并没有调用文件系统的sync操作,将日志落盘。如果此时宕机了,那么未落盘redo日志事务的数据是无法保证一致性的。
- undo日志同样存在未落盘的情况,可能出现无法回滚的情况。
2.未提交的事务和回滚了的事务也会记录Redo Log,因此在进行恢复时,这些事务要进行特殊的的处理。
有2种不同的恢复策略:
- A. 进行恢复时,只重做已经提交了的事务。
- B. 进行恢复时,重做所有事务包括未提交的事务和回滚了的事务。然后通过Undo Log回滚那些未提交的事务。
四、binlog
1.作用
- 1.用于主从复制,在主从复制中,从库利用主库上的binlog进行重播,实现主从同步。
- 2.用于数据库的基于时间点的还原。
2.内容
逻辑格式的日志。
- 记录的是执行过的事务中的sql语句和包括了执行的sql语句(增删改)反向的信息,
- 比如:delete对应着delete本身和其反向的insert;update对应着update执行前后的版本的信息;insert对应着delete和insert本身的信息。
3.产生
- 事务提交的时候一次性将事务中的sql语句(一个事物可能对应多个sql语句)按照一定的格式记录到binlog中。
- 这里与redo log很明显的差异就是redo log并不一定是在事务提交的时候刷新到磁盘,redo log是在事务开始之后就开始逐步写入磁盘。
- 开启了bin_log的情况下,对于较大事务的提交,可能会变得比较慢一些。
4.删除
- binlog的默认是保持时间由参数expire_logs_days配置,对于非活动的日志文件,在生成时间超过expire_logs_days配置的天数之后会被自动删除。
5.bin log与redo log的区别
- 1,作用不同:redo log是保证事务的持久性的,是事务层面的,binlog作为还原的功能,是数据库层面的(当然也可以精确到事务层面的),虽然都有还原的意思,但是其保护数据的层次是不一样的。
- 2,内容不同:redo log是物理日志,binlog是逻辑日志。这也导致恢复数据时候的效率不同,redo log效率高于binlog。
- 3,两者日志产生的时间,可以释放的时间,在可释放的情况下清理机制,都是完全不同的。
6.保证主从一致
为了保证主从复制时候的主从一致(当然也包括使用binlog进行基于时间点还原的情况),事务提交时,redo log和binlog的写入顺序,是要严格一致的,
MySQL通过两阶段提交过程来完成事务的一致性的,也即redo log和binlog的一致性的,理论上是先写redo log,再写binlog,两个日志都提交成功(刷入磁盘),事务才算真正的完成。
五、二阶段提交(事务的保证了一致性、主从复制的一致性)
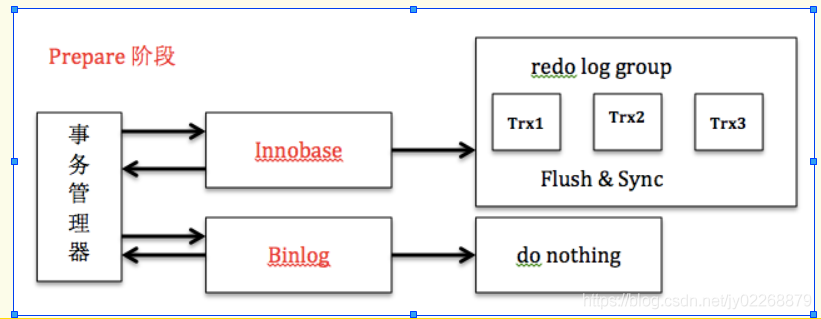
原理:
1.先进入commit prepare 阶段:事务中新生成的redo log 会被刷到磁盘,并将回滚段置为prepared状态。binlog不作任何操作。存储引擎写redo log
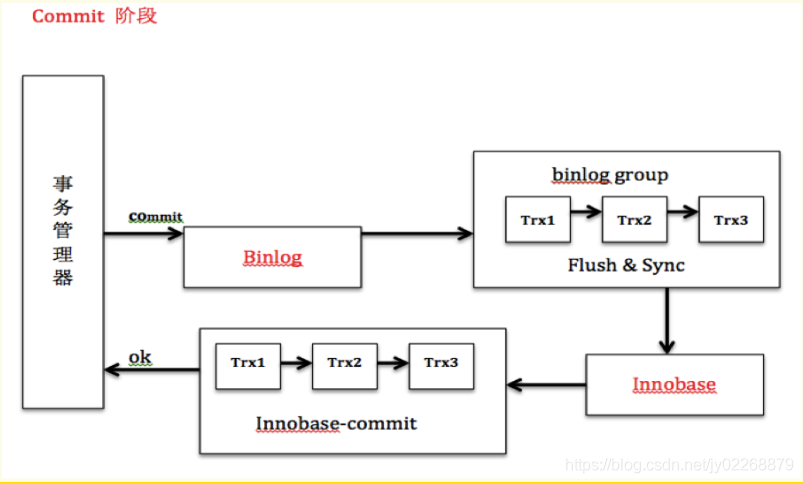
2.commit阶段:innodb释放锁,释放回滚段,设置redo log提交状态,binlog持久化到磁盘,然后存储引擎层提交。Server层写binlog
![]() 六、MVCC
六、MVCC
 六、MVCC
六、MVCC1.简介
MVCC的全称是“多版本并发控制”。这项技术使得InnoDB的事务隔离级别下执行一致性读操作有了保证。
换言之,就是为了查询一些正在被另一个事务更新的行,并且可以看到它们被更新之前的值。
MVCC由于其实现原理,只支持read committed和repeatable read隔离等级
2.作用:
- 1.增强并发性。这样的一来查询就不用等待另一个事务释放锁。
- 2.在RR可重复读的隔离级别中,保障了单纯的select(不会加锁)的“可重复读”特性
- 这项技术在数据库领域并不是普遍使用的,其它的数据库产品,以及mysql其它的存储引擎并不支持它。
3.快照读和当前读
- 快照读:读取的是快照版本,也就是历史版本。如:普通的SELECT
- 当前读:读取的是最新版本,如:UPDATE、DELETE、INSERT、SELECT ... LOCK IN SHARE MODE、SELECT ... FOR UPDATE是当前读。
4.锁定读
在一个事务中,标准的SELECT语句是不会加锁,但是有两种情况例外。
- SELECT ... LOCK IN SHARE MODE
- 给记录加设共享锁,这样一来的话,其它事务只能读不能修改,直到当前事务提交
- SELECT ... FOR UPDATE
- 给记录加排它锁,这种情况下跟UPDATE的加锁情况是一样的
5.一致性非锁定读
事务中的单纯、标准的select读是不加锁的。
而这个单纯的select不加锁的读就是一致性非锁定读
一致性非锁定读就是MVCC来保证的
consistent read(一致性读),InnoDB用多版本来提供查询数据库在某个时间点的快照。
Consistent read(一致性读)是READ COMMITTED和REPEATABLE READ隔离级别下普通SELECT语句默认的模式。
一致性读不会给它所访问的表加任何形式的锁,因此其它事务可以同时并发的修改它们。
6.实现机制
1.InnoDB会给数据库中的每一行增加三个隐藏字段,它们分别是DB_TRX_ID(事务ID)、DB_ROLL_PTR(回滚指针)、DB_ROW_ID(隐藏的ID)。每开启一个新事务,事务的版本号就会递增。

此时开启一个事务A,对该条数据做修改,在修改前该条数据会做undo log 相当于有了一个未修改的副本,修改后DB_ROLL_PT会指向那个未修改的副本
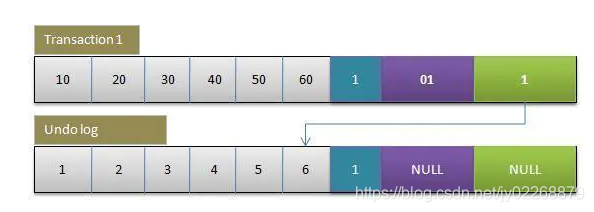
2.MVCC 在mysql 中的实现依赖的是 undo log 与 read view
- 1.undo log: undo log中记录的是数据表记录行的多个版本,也就是事务执行过程中的回滚段,其实就是MVCC 中的一行原始数据的多个版本镜像数据。
- 2.read view: 主要用来判断版本链中哪个版本是当前事务可见的。
7.read view
主要用来判断版本链中哪个版本是当前事务可见的。
需要注意的是,新建事务(当前事务)与正在内存中commit 的事务不在活跃事务链表中。
ReadView中主要包含4个比较重要的内容:
- m_ids:表示在生成ReadView时当前系统中活跃的读写事务的事务id列表。
- min_trx_id:表示在生成ReadView时当前系统中活跃的读写事务中最小的事务id,也就是m_ids中的最小值。
- max_trx_id:表示生成ReadView时系统中应该分配给下一个事务的id值。
- creator_trx_id:表示生成该ReadView的事务的事务id。
在mysql的innodb中,ReadView的判断方式:
- 如果被访问版本的trx_id属性值与ReadView中的creator_trx_id值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。
- 如果被访问版本的trx_id属性值小于ReadView中的min_trx_id值,表明生成该版本的事务在当前事务生成ReadView前已经提交,所以该版本可以被当前事务访问。
- 如果被访问版本的trx_id属性值大于ReadView中的max_trx_id值,表明生成该版本的事务在当前事务生成ReadView后才开启,所以该版本不可以被当前事务访问。
- 如果被访问版本的trx_id属性值在ReadView的min_trx_id和max_trx_id之间,那就需要判断一下trx_id属性值是不是在m_ids列表中,如果在,说明创建ReadView时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版本可以被访问。
事务隔离级别:读已提交和可重复读在ReadView的区别:
- 1.读已提交时,事务中,每次读都生成一个新的ReadView
- 2.可重复读时,事务中,第一次读生成一个ReadView,该事务中以后的读是使用的同一个ReadView,就是第一次读生成的那个ReadView
关于ReadView的详细介绍和例子
原文链接:https://blog.csdn.net/jy02268879/article/details/105580287
posted on 2021-12-08 17:09 1450811640 阅读(480) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号