
redis缓存问题与数据一致性问题
对于读多写少的高并发场景,我们会经常使用缓存来进行优化。比如说支付宝的余额展示功能,实际上99%的时候都是查询,1%的请求是变更,所以,我们在这样的场景下,可以加入缓存,用户->余额
1.Redis缓存与数据一致性问题
那么基于上面的这个出发点,问题就来了,当用户的余额发生变化的时候,如何更新缓存中的数据,也就是说。
- 我是先更新缓存中的数据再更新数据库的数据;
- 还是修改数据库中的数据再更新缓存中的数据;
数据库的数据和缓存中的数据如何达到一致性?首先,可以肯定的是,redis中的数据和数据库中的数据不可能保证事务性达到统一的,这个是毫无疑问的,所以在实际应用中,我们都是基于当前的场景进行权衡降低出现不一致问题的出现概率
更新缓存还是让缓存失效
更新缓存表示数据不但会写入到数据库,还会同步更新缓存; 而让缓存失效是表示只更新数据库中的数据,然后删除缓存中对应的key。那么这两种方式怎么去选择?这块有一个衡量的指标。
- 如果更新缓存的代价很小,那么可以先更新缓存,这个代价很小的意思是我不需要很复杂的计算去获得最新的余额数字。
- 如果是更新缓存的代价很大,意味着需要通过多个接口调用和数据查询才能获得最新的结果,那么可以先淘汰缓存。淘汰缓存以后后续的请求如果在缓存中找不到,自然去数据库中检索
先操作数据库还是先操作缓存
当客户端发起事务类型请求时,假设我们以让缓存失效作为缓存的的处理方式,那么又会存在两个情况,
- 先更新数据库再让缓存失效
- 先让缓存失效,再更新数据库
前面我们讲过,更新数据库和更新缓存这两个操作,是无法保证原子性的,所以我们需要根据当前业务的场景的容忍性来选择。也就是如果出现不一致的情况下,哪一种更新方式对业务的影响最小,就先执行影响最小的方案
- 最终一致性的解决方案
下图展示了,比如针对缓存失效为例子,第一个尝试去更新数据库,第二步尝试让缓存失效,如果第二步对个某个key的缓存失效,可以发送失败消息到mq中,然后自己消费mq的消息不断的重试让缓存失效,mq保证消息持久性和缓存和数据库的数据最终一致性。
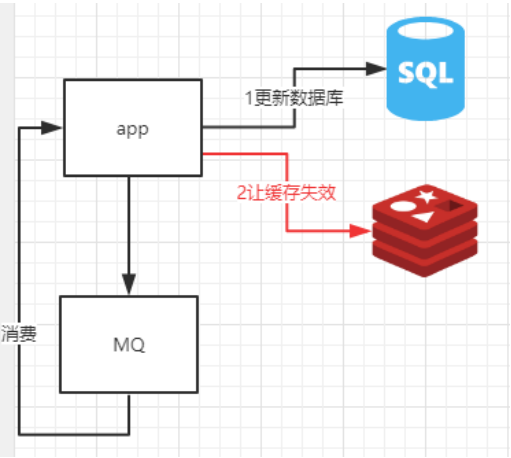

2.关于缓存雪崩的解决方案
当缓存大规模渗透在整个架构中以后,那么缓存本身的可用性讲决定整个架构的稳定性。那么接下来我们来讨论下缓存在应用过程中可能会导致的问题。
缓存雪崩
缓存雪崩是指设置缓存时采用了相同的过期时间,导致缓存在某一个时刻同时失效,或者缓存服务器宕机宕机导致缓存全面失效,请求全部转发到了DB层面,DB由于瞬间压力增大而导致崩溃。缓存失效导致的雪崩效应对底层系统的冲击是很大的。
解决方式
- 对缓存的访问,如果发现从缓存中取不到值,那么通过加锁或者队列的方式保证缓存的单进程操作,从而避免失效时并发请求全部落到底层的存储系统上;但是这种方式会带来性能上的损耗
- 将缓存失效的时间分散,降低每一个缓存过期时间的重复率
- 如果是因为缓存服务器故障导致的问题,一方面需要保证缓存服务器的高可用、另一方面,应用程序中可以采用多级缓存
缓存穿透
缓存穿透是指查询一个根本不存在的数据,缓存和数据源都不会命中。出于容错的考虑,如果从数据层查不到数据则不写入缓存,即数据源返回值为 null 时,不缓存 null。缓存穿透问题可能会使后端数据源负载加大,由于很多后端数据源不具备高并发性,甚至可能造成后端数据源宕掉
解决方式
- 如果查询数据库也为空,直接设置一个默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴。比如,”key” , “&&”。
在返回这个&&值的时候,我们的应用就可以认为这是不存在的key,那我们的应用就可以决定是否继续等待继续访问,还是放弃掉这次操作。如果继续等待访问,过一个时间轮询点后,再次请求这个key,如果取到的值不再是&&,则可以认为这时候key有值了,从而避免了透传到数据库,从而把大量的类似请求挡在了缓存之中。
- 根据缓存数据Key的设计规则,将不符合规则的key进行过滤
采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的BitSet中,不存在的数据将会被拦截掉,从而避免了对底层存储系统的查询压力
3.布隆过滤器
布隆过滤器是Burton Howard Bloom在1970年提出来的,一种空间效率极高的概率型算法和数据结构,主要用来判断一个元素是否在集合中存在。因为他是一个概率型的算法,所以会存在一定的误差,如果传入一个值去布隆过滤器中检索,可能会出现检测存在的结果但是实际上可能是不存在的,但是肯定不会出现实际上不存在然后反馈存在的结果。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
- bitmap
所谓的Bit-map就是用一个bit位来标记某个元素对应的Value,通过Bit为单位来存储数据,可以大大节省存储空间.所以我们可以通过一个int型的整数的32比特位来存储32个10进制的数字,那么这样所带来的好处是内存占用少、效率很高(不需要比较和位移)比如我们要存储5(101)、3(11)四个数字,那么我们申请int型的内存空间,会有32个比特位。这四个数字的二进制分别对应
从右往左开始数,比如第一个数字是5,对应的二进制数据是101, 那么从右往左数到第5位,把对应的二进制数据存储到32个比特位上。
第一个5就是 00000000000000000000000000101000
输入3时候 00000000000000000000000000001100
- 布隆过滤器原理
有了对位图的理解以后,我们对布隆过滤器的原理理解就会更容易了,仍然以前面提到的40亿数据为案例,假设这40亿数据为某邮件服务器的黑名单数据,邮件服务需要根据邮箱地址来判断当前邮箱是否属于垃圾邮件。原理如下
假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置位0。对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中
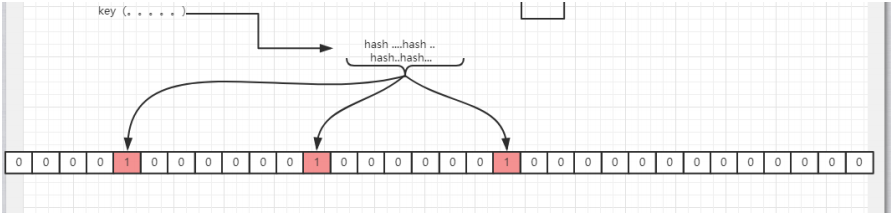

接下来按照该方法处理所有的输入对象,每个对象都可能把bitMap中一些白位置涂黑,也可能会遇到已经涂黑的位置,遇到已经为黑的让他继续为黑即可。处理完所有的输入对象之后,在bitMap中可能已经有相当多的位置已经被涂黑。至此,一个布隆过滤器生成完成,这个布隆过滤器代表之前所有输入对象组成的集合。
如何去判断一个元素是否存在bit array中呢? 原理是一样,根据k个哈希函数去得到的结果,如果所有的结果都是1,表示这个元素可能(假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1)存在。 如果一旦发现其中一个比特位的元素是0,表示这个元素一定不存在
至于k个哈希函数的取值为多少,能够最大化的降低错误率(因为哈希函数越多,映射冲突会越少),这个地方就会涉及到最优的哈希函数个数的一个算法逻辑

下面展示布隆过滤器的使用
首先添加maven依赖
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>20.0</version>
</dependency>
代码如下:
/**
* @Project: redis
* @description: 布隆过滤器
* @author: sunkang
* @create: 2019-01-12 19:22
* @ModificationHistory who when What
**/
public class BloomFilterDemo {
public static void main(String[] args) {
//插入的key为字符串,预计数据量为一百万,并且容错率为0.01
BloomFilter bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()),
1000000,0.01);
bloomFilter.put("sunkang");
System.out.println(bloomFilter.mightContain("sunkang"));
}
}作者:Mrsunup
链接:https://www.jianshu.com/p/4eaff0992f54
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
posted on 2021-12-02 10:35 1450811640 阅读(236) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号