浅入理解Kafa高性能设计
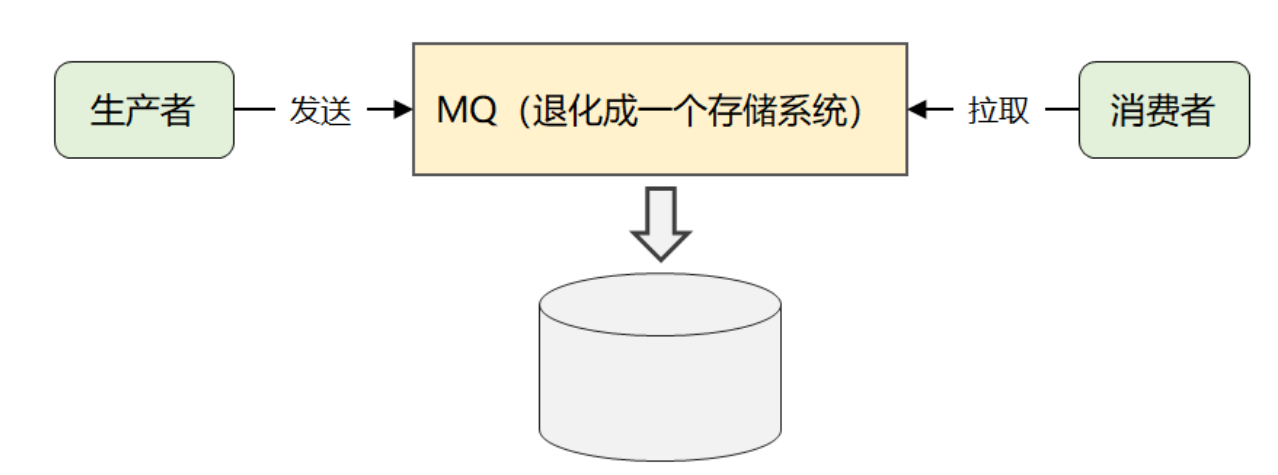
Kafa简单概括:支持海量消息生产消费的"存储系统"
MQ,没有花里胡哨功能,天生为日志流等消息,高并发,高性能,高可用三高均支持。
基于Topic发布订阅模型
Broker持久化存储
数据分片存储 Partition
Partition多副本解决高可用,一主多从,Leader负责读写,Follower仅用来做备份 等待leader宕机后选举
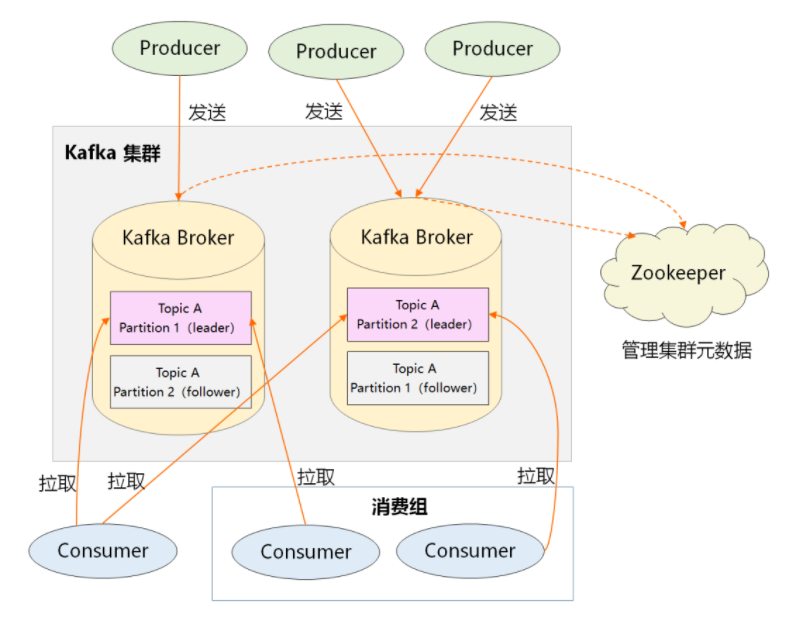
1、Producer:生产者,负责创建消息,然后投递到 Kafka 集群中,投递时需要指定消息所属的 Topic,同时确定好发往哪个 Partition。
2、Consumer:消费者,会根据它所订阅的 Topic 以及所属的消费组,决定从哪些 Partition 中拉取消息。
3、Broker:消息服务器,可水平扩展,负责分区管理、消息的持久化、故障自动转移等。
4、Zookeeper:负责集群的元数据管理等功能,比如集群中有哪些 broker 节点以及 Topic,每个 Topic 又有哪些 Partition 等。
Kafka为何要采用日志形式持久化? (为何不是K-V存储,或者数据库B+树的等结构)
1.crud很简单,没有update 没有复杂查询 没必要维护索引B+树这种数据结构,但是吞吐量大 需要大量追加写,所以需要顺序读写磁盘比较适合
2.数据量过大,不适用于内存存储
offset 完全可以设计成有序的(实际上是一个单调递增 long 类型的字段),
这样消息在日志文件中本身就是有序存放的了,我们便没必要为每个消息建 hash 索引了,
完全可以将消息划分成若干个 block块,只索引每个 block 第一条消息的 offset 即可,先根据大小关系找到 block,然后在 block 中顺序搜索,这便是 Kafka “稀疏索引” 的来源。
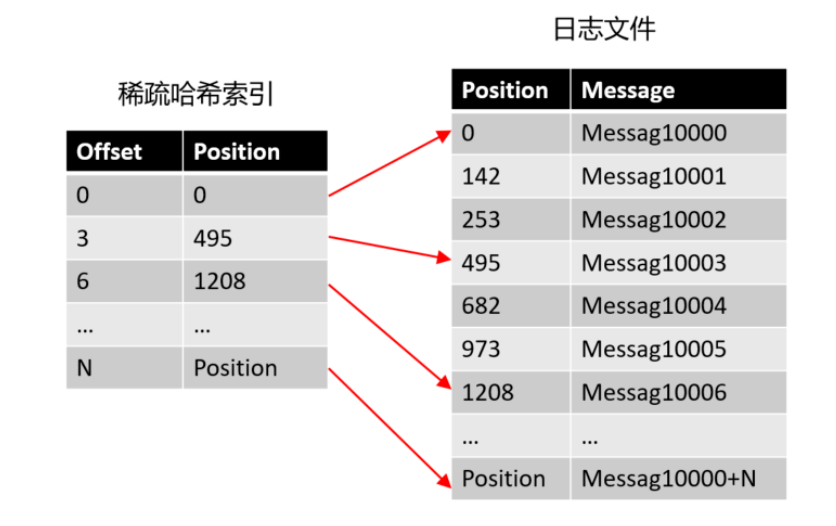
Append 追加写日志 + 稀疏的哈希索引,形成了 Kafka 最终的存储方案。
Kafka的存储结构
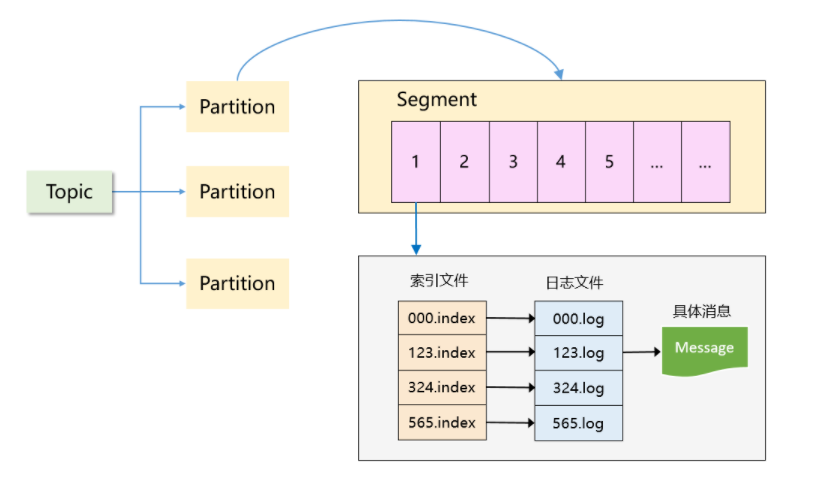
可以看到,Kafka 是一个「分区 + 分段 + 索引」的三层结构:
1、每个 Topic 被分成多个 Partition,Partition 从物理上可以理解成一个文件夹。
Partition 主要是为了解决 Kafka 存储上的水平扩展问题,如果一个 Topic 的所有消息都只存在一个 Broker,这个 Broker 必然会成为瓶颈。
因此,将 Topic 内的数据分成多个 Partition,然后分布到整个集群是很自然的设计方式。
2、每个 Partition 又被分成了多个 Segment,Segment 从物理上可以理解成一个「数据文件 + 索引文件」,这两者是一一对应的。
有了 Partition 之后,为什么还需要 Segment?如果不引入 Segment,一个 Partition 只对应一个文件,那这个文件会一直增大,势必造成单个 Partition 文件过大,查找和维护不方便。
此外,在做历史消息删除时,必然需要将文件前面的内容删除,不符合 Kafka 顺序写的思路。而在引入 Segment 后,则只需将旧的 Segment 文件删除即可,保证了每个 Segment 的顺序写。
Kafka为什么性能这么快?
Producer设计
1.批量发送消息 Kafka 采用了批量发送消息的方式,通过将多条消息按照分区进行分组,然后每次发送一个消息集合,从而大大减少了网络传输的 overhead(建立TCP连接损耗)
2.消息压缩 在批量发送的基础上,同时对多条消息进行压缩,能大幅减少数据量,从而更大程度提高网络传输率
3.紧凑方式序列化 Kafka 消息中的 Key 和 Value,都支持自定义类型,只需要提供相应的序列化和反序列化器即可。用户可以根据实际情况选用快速且紧凑的序列化方式(比如 ProtoBuf、Avro)来减少实际的网络传输量以及磁盘存储量,进一步提高吞吐量。
4.内存池复用 Producer一上来就会占用一个固定大小内存块,比如 64MB,然后划分成 M 个小内存块Batch 16k,按Batch块批量发送消息。 当需要创建一个新的 Batch 时,直接从内存池中取出一个 16 KB 的内存块即可,然后往里面不断写入消息
Broker设计
5.IO多路复用 基于Reactor 网络通信模型实现单线程监听大量连接
6.顺序写磁盘 Kafka 选用的是「日志文件」来存储消息,仅仅将消息追加到文件末尾即可 (磁盘顺序写的性能远远高于磁盘随机写,甚至高于内存随机写)
7.Page Cache Page Cache是操作系统提供的机制, 缓存的是最近会被使用的磁盘数据,最近访问的数据很可能接下来再访问到。而预读到 Page Cache 中的磁盘数据,依据是:数据往往是连续访问的。非常契合MQ这种消息中间件
8.分区分段存储 一个Topic对应多个partition,一个partition对应多个sagment。 同一个Topic下的partition可以存储在多台broker 大大提升每个Topic的吞吐量,同一个partation对应多个sagment文件,sagment文件支持顺序读写,删除旧sagment文件
9.稀疏索引 消息的 offset是一个单调递增 long 类型的字段,这样消息在日志文件中本身就是有序存放的了,便没必要为每个消息建 hash 索引,完全可以将消息划分成若干个 block,只索引每个 block 第一条消息的 offset 即可,先根据大小关系找到 block,然后在 block 中顺序搜索,这便是 Kafka “稀疏索引” 的设计思想。 当给定一个 offset 时,Kafka 采用的是二分查找来高效定位不大于 offset 的物理位移,然后找到目标消息。
10.mmap()读稀疏索引文件
11.sendfile()读磁盘文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号