

mysql底层存储及IO过程理解
InnoDB维护了一个逻辑空间叫表空间
向上对接开发者,向下对接物理文件
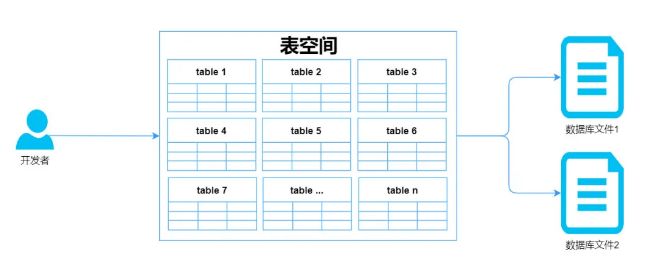
当创建表时,会自动为表创建一个对应表名的表空间,并在数据库目录下生成一个“表名.ibd”的表空间文件。
存储结构
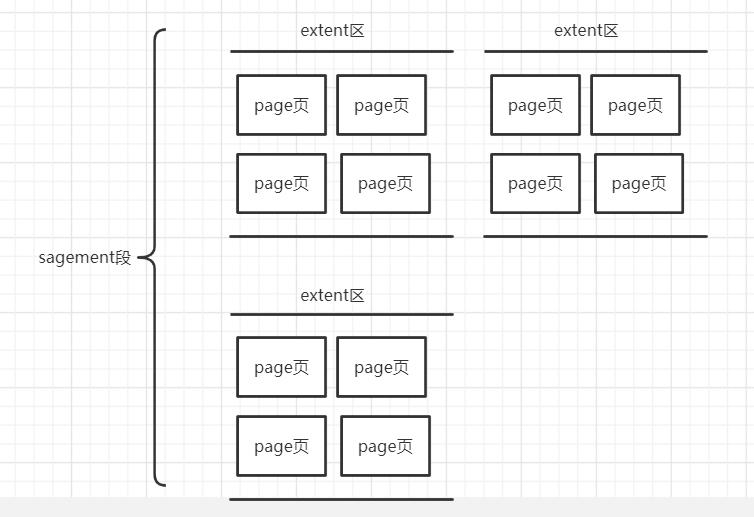
物理存储图 page页 extent区 sagement段 书页,一本书,一套书的关系
最小存储单元是页 , 一个页对应B+树一个节点
一个区包括多个页 ,一个段包括多个区
一个page默认大小16kb,区默认大小1M
页
1.innodb中io操作的最小单位。
2.每个页都有一个对应的从0开始的编号,这个编号叫做页号。因为表空间的数据文件会被划分成大小相等的页,所以知道页号,再根据文件的初始位置,就可以计算出页在磁盘中的准确地址。
3.一张表对应一个聚簇索引,而聚簇索引元数据中指定了root page的页号,因此Innodb引擎可以根据页号和页大小计算出索引B+树root page的准确地址,从而对整个表数据进行操作。
4.段、区都是为了管理空间的存储状态,为页分配空间服务,真正的查询只需要通过Page No和B+树中各级节点的关联关系就可以操作整个表物理空间上的数据。
从B+树索引来看
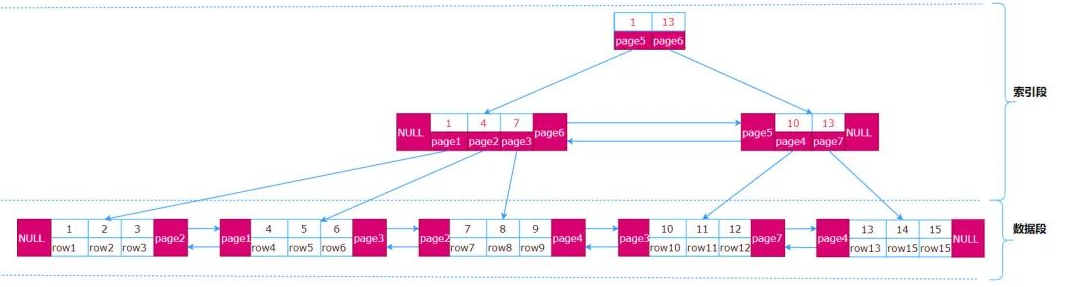
1.一个表的聚簇索引分为两个段,包含数据的叶子节点的数据段,不包含数据的节点的索引段
2.索引段的page存的是key+指针,数据段的page存的是数据行
3.一个page默认16k,一个索引段的page大约能存1170个索引指针(一个索引指针key占8字节,指针占6字节),
那么根节点就能保存1170*n个指针 (n为根节点的page数)
指向下一层1170*1170*n*m个节点 (m为每个节点平均page数)
指向下一层1170*1170*n*m*k个 叶子节点 (k为每个叶子节点平均page数)
每行数据如果占1k,那么每个叶子节点的page大约能存16条数据,一共就能存1170*1170*n*m*k*16条数据
所以 理论上三层高的B+树索引能存放超过几千万条数据
B+树索引磁盘IO次数
1.数据量小的话,直接把索引放到内存中,内存的O(logn)消耗是远远低于磁盘io的,所以可以忽略不计
2.对于普通二叉树,第一个步骤是二分,每次判断都是一次半数的数量级检索。假如有100W的数据,大概的时间复杂度是:log2N=1000000即N=20的节点获取,也就是磁盘I/O复杂度最大为O(20),二分的时间复杂度是O(log2N)。
3.一个4Kb的磁盘块将大致可以容纳250个下级指针,100万行目标记录(假设叶子节点也是只保存了id值,则一个非叶子节点下面也包括大概250个叶子节点)只需log250N=1000000即N=3的I/O次数,
充分提升了每次节点I/O带来的检索效用,时间复杂度是O(lognN),这里的n是非叶子结点的个数。
(实际上innodb的数据页大小是16kb,这个n会更大,那么对应的,io次数也会更少)
4.MySQL的InnoDB存储引擎在设计时是将根节点常驻内存的,也就是说查找某一键值的行记录时最多只需要1~3次磁盘I/O操作
为什么不要把主键设置为uuid?
插入效率低啊,为啥呢?
InnoDB默认使用主键建立聚簇索引,这种索引必须有逻辑顺序的啊,你用UUID这种无序的,每次新增数据是不是要按顺序找到相应的位置插入? (如果一个表没有申明主键和一个不为null的唯一索引,InnoDB将会自动增加一个6字节(48位)的整数列,被叫做行ID,聚集数据都是依靠这列的。这列既不能通过任何查询获取到也不能做像基于行复制的任何内部操作。)
新插入一行很可能底层page节点,索引节点都会插入一条。人都排好序了 你往中间插,那人家可能一个page16k都占满了,就为了你还得重新申请页 页扩容 分裂,
就像数组中间插值扩容一样,那效率能不低吗?
So 一般主键直接用自增的,方便排序 顺序插入,如果没设置主键 InnoDB默认用row id 来当主键索引,可别自己整个uuid当索引啊

