分布式事务解决方案
如果是简单的两个服务调用,可以将调用接口尽量写在最后, 如果被调用方接口正常,能保证调用方的其他处理都正常才会执行调用接口
当被调用方接口出现异常,调用方可以通过事务回滚;
方案一;2pc 两阶段提交 <数据库层面>
需要一个事务协调者
第一阶段 询问阶段,事务协调者挨个询问能否成功执行
第二阶段 提交阶段,如果其中一个服务失败了就全部回滚,之后再重试机制。 如果第一阶段所有服务都能成功则全部事务提交。
协调者是单点,可能出现单点故障,协调者故障会导致所有参与者处于阻塞状态,或者部分提交部分阻塞;
整体性能较差
3pc 在2pc的基础上
1.每个参与者具有超时时间,避免协调者故障所有参与者无限制阻塞
2.在2pc之前增加了一次询问阶段,判断各个参与者状态,是否可以完成事务,减少故障率,减少不必要的资源限制
方案二: TCC Try-Confirm-Cancel <业务层面>
Try是预留 将资源锁定限制住
Confirm是确认操作,就是正常操作
Cancel 是撤销操作,将之前的操作撤销
难点在于业务上的定义,对于所有服务的每⼀个操作你都需要定义三个动作分别对应 Try - Confirm - Cancel 。 因此 TCC 对业务的侵⼊较⼤和业务紧耦合,需要根据特定的场景和业务逻辑来设计相应的操作。
方案三:本地消息表
每个服务维护一个本地消息表,执行操作的同时往本地消息表里插入一条操作的记录,记录操作成功和失败。
会有后台任务定时去查看每个服务的本地消息表,筛选出来操作失败的记录,重新执行,或者选择回滚
本地消息表为了最终一致性,可以容忍短暂的不一致性
方案四:MQ实现消息事务
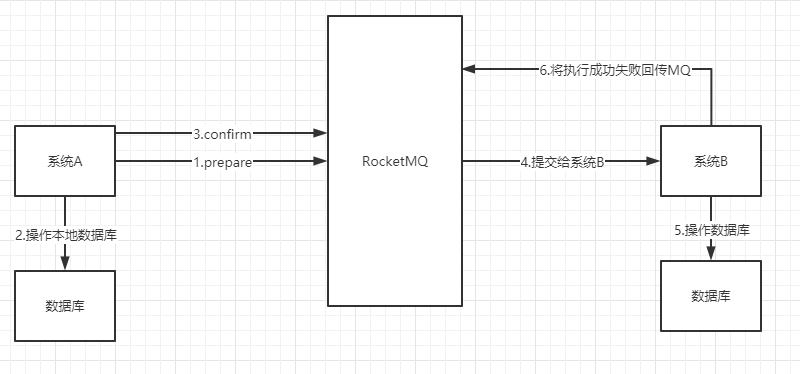
2PC 是⼀种强⼀致性事务,不过还是有数据不⼀致,阻塞等⻛险,⽽且只能⽤在数据库层⾯。
⽽ TCC 是⼀种补偿性事务思想,适⽤的范围更⼴,在业务层⾯实现,因此对业务的侵⼊性较⼤,每⼀ 个操作都需要实现对应的三个⽅法。
本地消息表、事务消息和最⼤努⼒通知其实都是最终⼀致性事务,因此适⽤于⼀些对时间不敏感的业务。
更多: https://mp.weixin.qq.com/s/BI6chM0qY5jMmdMW-Aha5g

 浙公网安备 33010602011771号
浙公网安备 33010602011771号