Zookeeper分布式服务协调
Zookeeper 使用场景:
1. 分布式协调 (用作服务注册中心)
2. 分布式锁
3. 元数据和配置管理
4. Zookeeper HA高可用场景,(通过Zookeeper实现主从自动切换)
Zookeeper服务注册中心集群原理
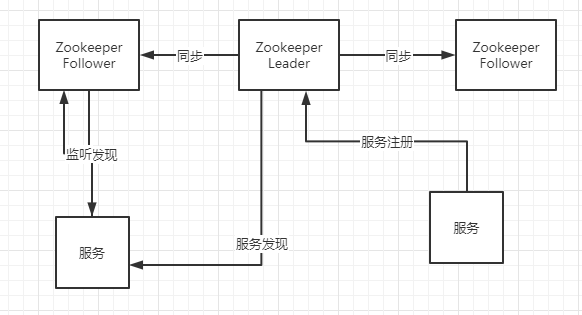
Zookeeper分为leader follower两种角色, 服务注册只能注册到leader,leader同步到所有follower。 follwoer只能读取服务列表 leader可读可写
Zookeeper采用推的形式通知服务注册变化 服务可以主动去Zookeeper监听服务列表 即时发现服务列表变化
Eureka是SpringCloud相配的服务注册中心,集群是peer-to-peer形式,每台机器地位相同,新注册到一台机器会同步到所有机器,每台机器均可读可写
CAP
C : 一致性 A : 可用性 P : 分区容错性
CP / AP
Zookeeper是CP 保证强一致性,如果leader挂了(leader还没有把最新的服务变化同步到所有follower) 在选举出新leader并同步最新服务变化之前 会暂时使整个zookeeper集群不可用
Eureka是 AP 保证可用性, 如果其中一台机器挂了(还没来及的将自己的服务变化同步给其他机器) 还是会保证其他所有机器可用,即时读到的服务注册列表可能不是最新的 ,慢慢等心跳检测,重新注册等机制重新恢复一致性
Zookeeper节点 ZNode 分为四种
持久节点: 默认的节点,创建节点的客户端与zookeeper断开连接 节点依然存在
持久节点顺序节点: 持久节点的基础上,根据创建节点的时间顺序编号
临时节点: 当创建节点的客户端与zookeeper断开则删除
临时顺序节点: 临时节点基础上加时间顺序编号
Zookeeper临时顺序节点做分布式锁原理:
zookeeper用临时节点解决掉死锁问题(前一个节点抢到锁之后宕机了,导致一直不能释放锁所有人都在等待)
zookeeper用顺序节点解决羊群效应(所有人都监听抢到锁的那个节点,当该节点释放锁一瞬间所有人都来争抢 造成羊群效应)
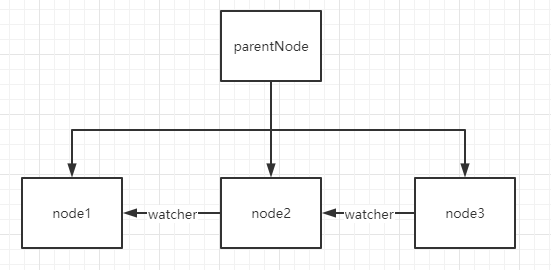
1. 创建parentNode 用做锁
2. 客户端想要获取锁 在parentNode下创建 node
3. 客户端每次判断自己创建的节点是否是时间顺序最靠前的节点,如果是 就获取了锁
4. 客户端发现自己的创建的节点不是最靠前 则向上一个节点注册watcher监听上一个节点,直到上一个节点释放锁

 浙公网安备 33010602011771号
浙公网安备 33010602011771号