实验目的
理解mapreduce的工作原理
理解Partitioner的书写方法
理解GroupingComparator的书写方法
实验原理
我们已经学习了hadoop的大部分基础知识,剩下的就是利用hadoop解决实际的业务问题。首先我们回顾一下mapreduce的工作过程:
数据通过InputFormat中定义的RecordReader读进来,然后以键值对的形式写出去,在map中进行处理,map处理完成后以键值对的形式写出,中途经过分区、分组、排序后,将key相同的value放进一个迭代器传给reduce,每个reduce任务处理的数据是key相同的一组value构成的的迭代器。
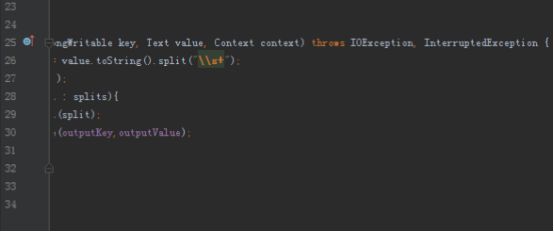
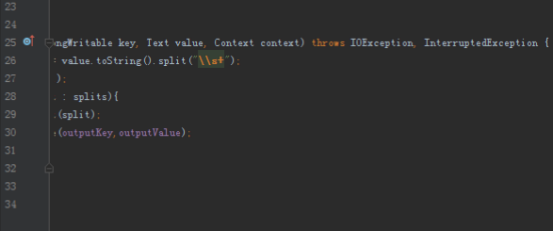
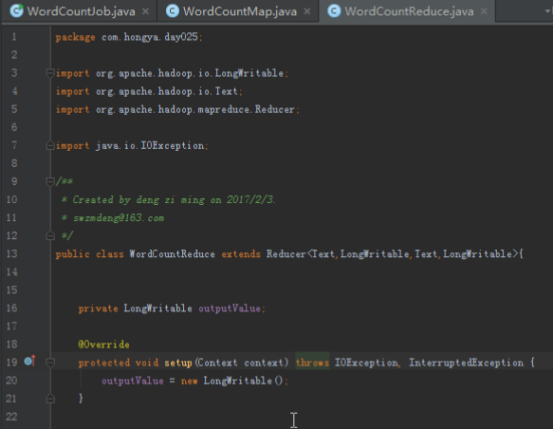
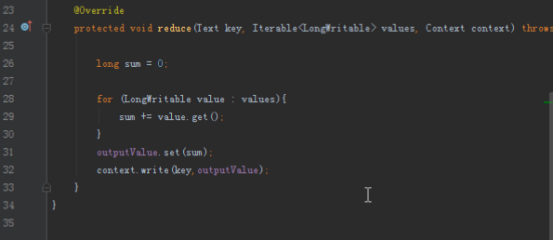
1.实现单词计数
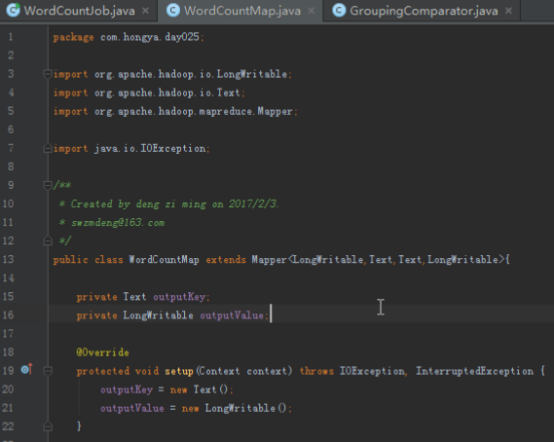
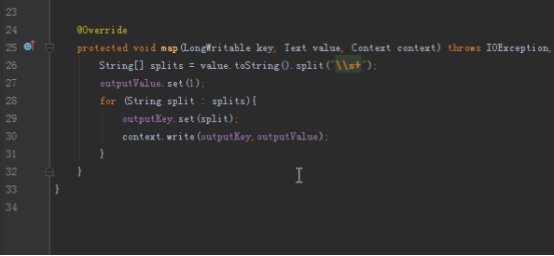
首先我们要实现单词计数的程序,首先map端将读入的数据分割成单词,然后以单词为key,1为value写出,reduce拿到的数据就是以单词为key,这个单词对应的所有的1组成的迭代器为value,我们将所有的value加起来就是这个单词的数量。
单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版"Hello World"。单词计数主要完成功能是:统计一系列文本文件中每个单词出现的次数,如下图所示:
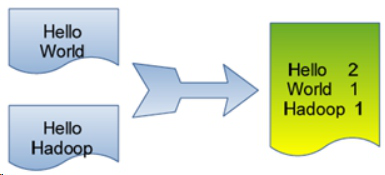
2.实现自定义分区
我们有时候希望能够按照自己的意愿合理分配每个reduce计算的单词,比如我想最后把所有的以字母A开头的单词单独输出,这时候就需要自定义分区,将key中以A开头的单词放进一个给定的reduce。自定义分区需要定义一个类,继承自Partitioner或者Partitioner的子类,实现getPartition方法,按照业务需求分配不同key分配到的reduce。
3.实现按照字母多少排序
统计单词个数业务不难,但是我们希望对结果进行排序输出。当然我们可以在程序执行结束以后使用shell、Python等工具进行排序,但是我们也可以直接使用mapreduce自带的排序组件,使用mapreduce自带的GroupingComparator能利用mapreduce框架帮我们排序。
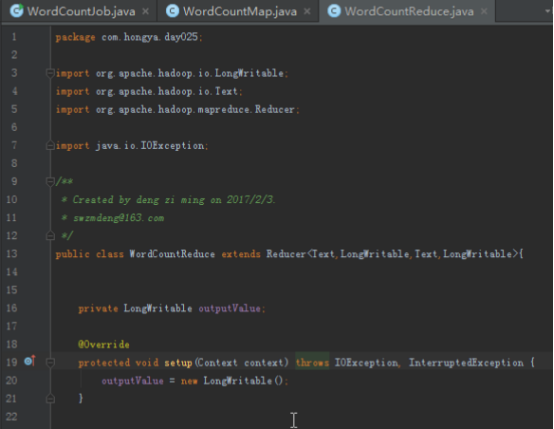
4.mapreduce的工作步骤
数据通过InputFormat中定义的RecorderReader读进来,然后以键值对的形式<key,value style="box-sizing: border-box;">传进map程序,map处理完成后以<key,value style="box-sizing: border-box;">的形式写出,传入哪个reduce根据自定义的Partitioner决定,传入每一个reducer的数据,key一样的键值对的value会放进一个迭代器,在这个判断key是否一样的就是根据自定义的GroupingComparator。会根据key的compare方法进行排序。
5.Partitioner的书写方法
我们自定义的Partitioner需要继承自一个Partitioner类,实现getPartition方法,getPartition的签名为:public abstract int getPartition(KEY key, VALUE value, int numPartitions),其中key和value是map程序写出的键值对,numPartitions是reduce的个数,通过程序代码设置,返回值就是reduce的index。
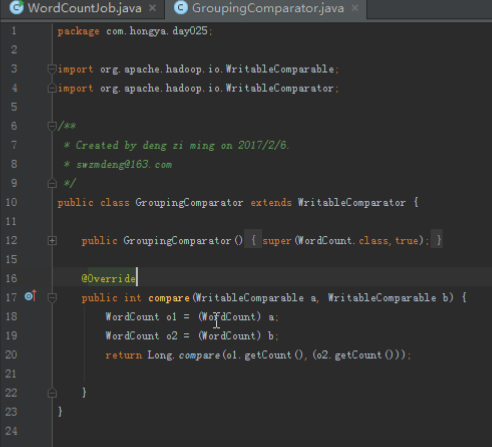
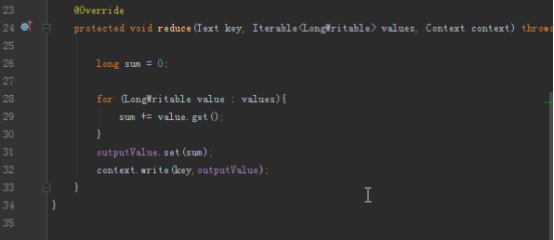
6.GroupingComparator的书写方法
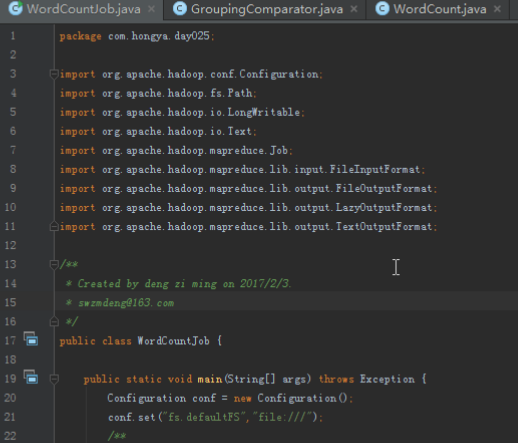
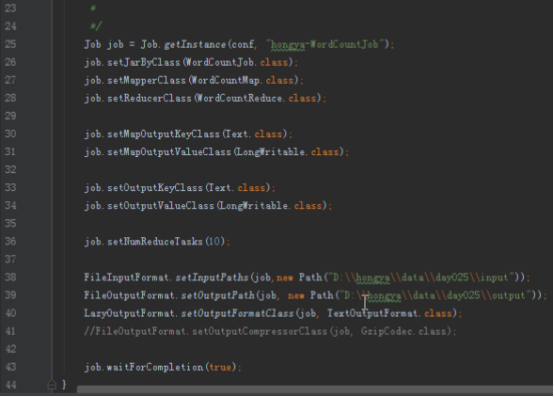
map输出的键值对中,key相同的value会被放进同一个迭代器,也就是按照key分组,而判断key是否相等的规则是我们通过GroupingComparator设置的,通过重写compare方法,就能修改判断逻辑。
实验环境
1.操作系统
服务器:Linux_Centos
操作机:Windows_7
服务器默认用户名:root,密码:123456
操作机默认用户名:hongya,密码:123456
2.实验工具
IntelliJ IDEA

IDEA全称IntelliJ IDEA,是java语言开发的集成环境,IntelliJ在业界被公认为最好的java开发工具之一,尤其在智能代码助手、代码自动提示、重构、J2EE支持、Ant、JUnit、CVS整合、代码审查、创新的GUI设计等方面的功能可以说是超常的。IDEA是JetBrains公司的产品,这家公司总部位于捷克共和国的首都布拉格,开发人员以严谨著称的东欧程序员为主。
优点:
1)最突出的功能自然是调试(Debug),可以对Java代码,JavaScript,JQuery,Ajax等技术进行调试。其他编辑功能抛开不看,这点远胜Eclipse。
2)首先查看Map类型的对象,如果实现类采用的是哈希映射,则会自动过滤空的Entry实例。不像Eclipse,只能在默认的toString()方法中寻找你所要的key。
3)其次,需要动态Evaluate一个表达式的值,比如我得到了一个类的实例,但是并不知晓它的API,可以通过Code Completion点出它所支持的方法,这点Eclipse无法比拟。
4)最后,在多线程调试的情况下,Log on console的功能可以帮你检查多线程执行的情况。
缺点:
1)插件开发匮乏,比起Eclipse,IDEA只能算是个插件的矮子,目前官方公布的插件不足400个,并且许多插件实质性的东西并没有,可能是IDEA本身就太强大了。
2)在同一页面中只支持单工程,这为开发带来一定的不便,特别是喜欢开发时建一个测试工程来测试部分方法的程序员带来心理上的不认同。
3)匮乏的技术文章,目前网络中能找到的技术支持基本没有,技术文章也少之又少。
4)资源消耗比较大,建个大中型的J2EE项目,启动后基本要200M以上的内存支持,包括安装软件在内,差不多要500M的硬盘空间支持。(由于很多智能功能是实时的,因此包括系统类在内的所有类都被IDEA存放到IDEA的工作路径中)。
特色功能:
智能选择
丰富的导航模式
历史记录功能
JUnit的完美支持
对重构的优越支持
编码辅助
灵活的排版功能
XML的完美支持
动态语法检测
代码检查等等。
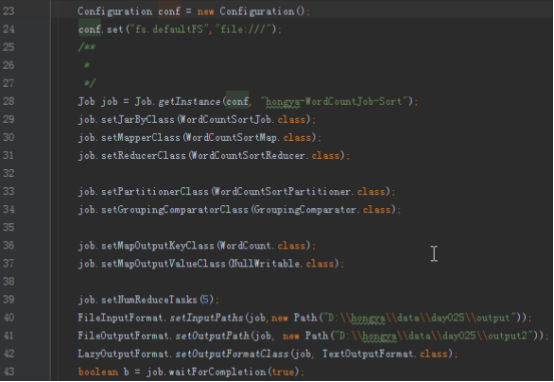
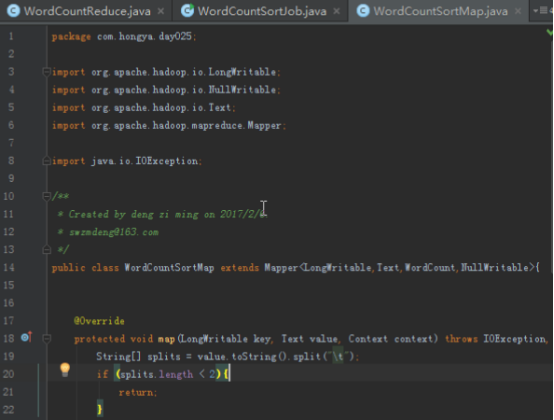
步骤1:自定义输出类
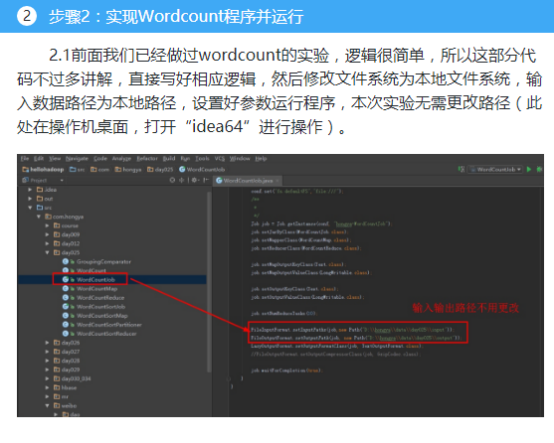
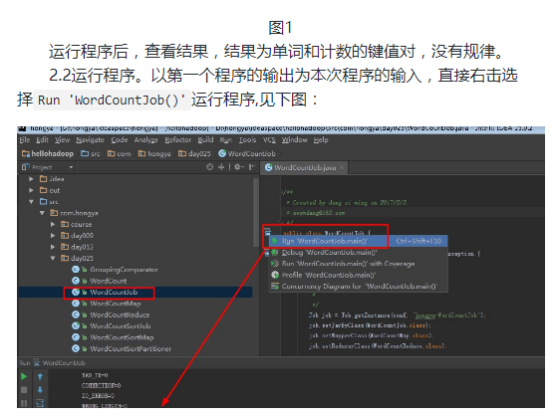
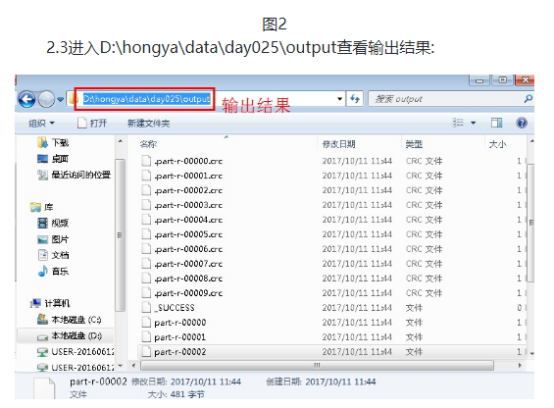
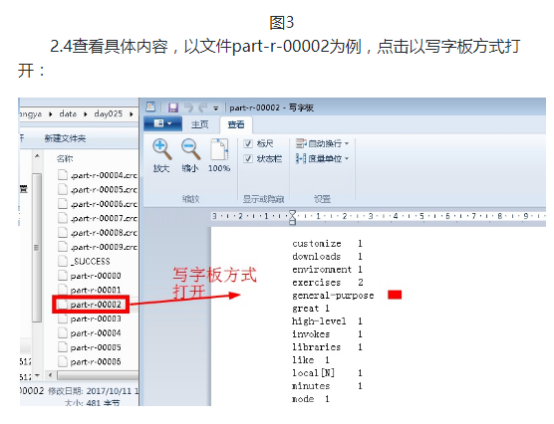
本次实验的代码放在包hellohadoop项目的com.hongya.day025下。我们可以进入D:/hongya/ideaspace/hellohadoop/src/com/hongya/day025查看源代码。
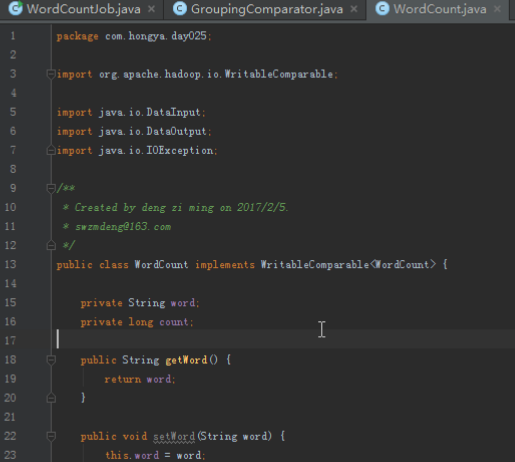
1.1我们需要排序,首先要定义自己的输出类,自定义输出类需要包含单词和计数,如下:
public class WordCount implements WritableComparable<WordCount> {
private String word;
private long count;
// getset方法、构造方法省略
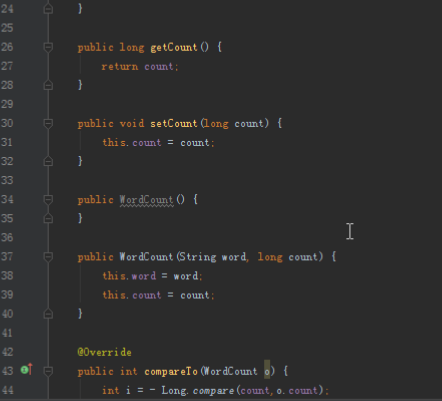
@Override
public int compareTo(WordCount o) {
int i = - Long.compare(count,o.count);
if (i != 0){
return i;
}
return word.compareTo(o.word);
}
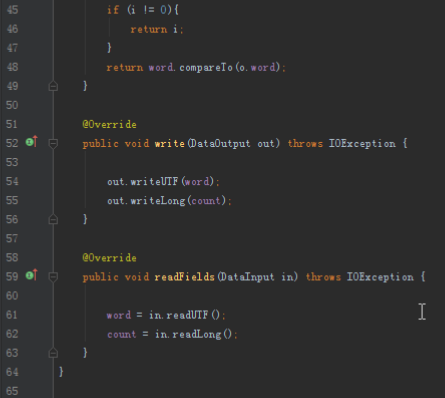
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(word);
out.writeLong(count);
}
@Override
public void readFields(DataInput in) throws IOException {
word = in.readUTF();
count = in.readLong();
}
我们需要实现compareTo方法,作为Reduce内部的排序方法,还要定义读写的方法
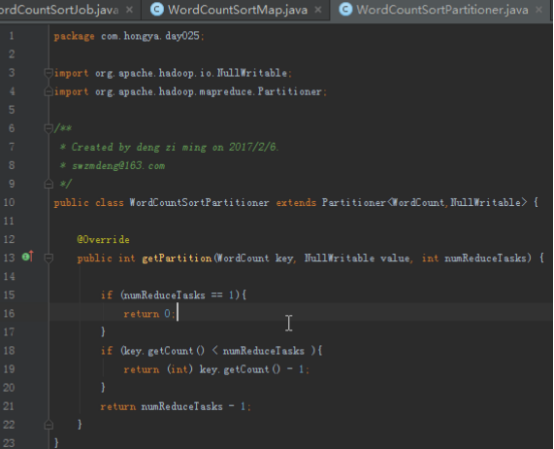
1.2自定义分区和分组,实现按照单词出现的次数排序。
我们想要map完成后的数据能够按照计数排序,因为排序只能在每一个reduce内部进行,所以我们需要输入到每一个reduce的数据不能是乱的。设计partition应该合理考虑这点,根据单词的计数进行分区。
@Override
public int getPartition(WordCount key, NullWritable value, int numReduceTasks) {
if (numReduceTasks == 1){
return 0;
}
if (key.getCount() < numReduceTasks){
return (int) key.getCount();
}
return numReduceTasks - 1;
}
首先判断reduce的数量,如果是1就不用计算,每个reduce只计算对应的count,当count比较大,全都给最后一个reduce计算,当然你可以自定义更好的分区方式。
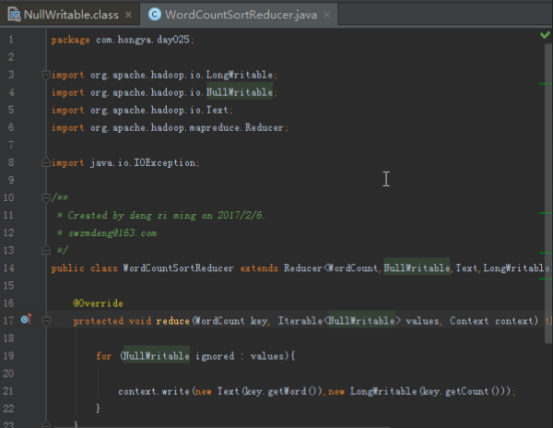
1.3自定义分组函数。
显然我们分组就是为了让所有计数一样的都进同一个组,所以逻辑就是只比较计数,忽略单词.
@Override
public int compare(WritableComparable a, WritableComparable b) {
WordCount o1 = (WordCount) a;
WordCount o2 = (WordCount) b;
return Long.compare(o1.getCount(),(o2.getCount()));
}