实验目的
熟悉hive和hbase的操作
熟悉hadoop、hbase、hive、zookeeper的关系
熟练大数据环境的搭建
学会分析日志排除问题
实验原理
1.hive整合hbase原理
前面大家已经了解了Hive和Hbase,Hive是一个mapreduce的客户端,把sql语句转化为mapreduce程序执行,同时提供了数据仓库技术。Hbase是一个非关系型数据库,数据存储的时候面向列,方便横向扩展,但是不方便进行关系查询和二级索引。有时候为了方便操作,需要用hive操作hbase进行复杂查询。
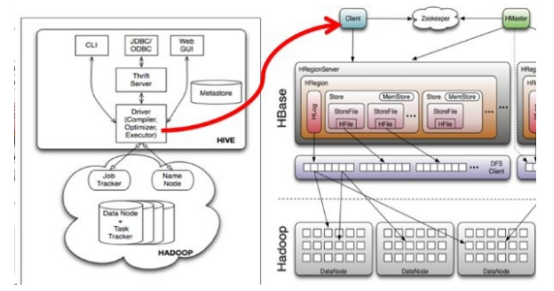
Hive与HBase整合的实现是利用两者本身对外的API接口互相进行通信,相互通信主要是依靠Hive的hive-hbase-handler-*.jar工具类,它负责Hbase和Hive进行通信的。我们整合hive与hbase后,hive的sql语句实际上会被转化为mapreduce程序,这个mapreduce程序操作的数据不是hdfs的数据而是hbase的数据。原理图如下:
2.hive操作hbase的用处
hive操作hbase的作用不仅仅是能够对hbase的数据进行二级索引和复杂查询,实际上,很多开源技术例如impala、spark sql,虽然提供自己的sql执行引擎,但是依然使用了hive的数据仓库技术,所以我们以后使用spark、impala操作hbase的数据最可靠的方式就是使用hive作为中间件,简单可靠。
3.hive整合hbase的注意事项
Hive读取HBase表,通过MR,本质是使用HiveHBaseTableInputFormat来读取数据,在getSplit()方法中对HBase表进行切分,切分原则是根据该表对应的HRegion,将每一个Region作为一个InputSplit,即该表有多少个Region,就有多少个MapTask,每个Region的大小由参数hbase.hregion.max.filesize控制,默认10G,这样会使得每个maptask处理的数据文件太大,maptask性能自然很差;
为HBase表预分配Region,使得每个Region的大小在合理的范围,并且控制key均匀分布在每个Region上之后,能大大提高效率,其本质上是Map数增加。
实验环境
1.操作系统
服务器:Linux_CentOS
操作机:Windows_7
服务器默认用户名:root,密码:123456
操作机默认用户名:hongya,密码:123456
2.实验工具
1.Xshell

Xshell是一个强大的安全终端模拟软件,它支持SSH1, SSH2, 以及Microsoft Windows 平台的TELNET 协议。Xshell 通过互联网到远程主机的安全连接以及它创新性的设计和特色帮助用户在复杂的网络环境中享受他们的工作。
Xshell可以在Windows界面下用来访问远端不同系统下的服务器,从而比较好的达到远程控制终端的目的。实验中我们用到XShell5,其新增功能有:
1.有效保护信息安全性;Xshell支持各种安全功能,如SSH1/SSH2协议,密码,和DSA和RSA公开密钥的用户认证方法,并加密所有流量的各种加密算法。重要的是要保持用户的数据安全与内置Xshell安全功能,因为像Telnet和Rlogin这样的传统连接协议很容易让用户的网络流量受到任何有网络知识的人的窃取。Xshell将帮助用户保护数据免受黑客攻击。
2.最好的终端用户体验;终端用户需要经常在任何给定的时间中运用多个终端会话,以及与不同主机比较终端输出或者给不同主机发送同一组命令。Xshell则可以解决这些问题。此外还有方便用户的功能,如标签环境,广泛拆分窗口,同步输入和会话管理,用户可以节省时间做其他的工作。
3.代替不安全的Telnet客户端;Xshell支持VT100,VT220,VT320,Xterm,Linux,Scoansi和ANSI终端仿真和提供各种终端外观选项取代传统的Telnet客户端。
4. Xshell在单一屏幕实现多语言;Xshell中的UTF-8在同类终端软件中是第一个运用的。用Xshell,可以将多种语言显示在一个屏幕上,无需切换不同的语言编码。越来越多的企业需要用到UTF-8格式的数据库和应用程序,有一个支持UTF-8编码终端模拟器的需求在不断增加。Xshell可以帮助用户处理多语言环境。 5. 支持安全连接的TCP/IP应用的X11和任意;在SSH隧道机制中,Xshell支持端口转发功能,无需修改任何程序,它可以使所有的TCP/IP应用程序共享一个安全的连接。
2.Hive

Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。另外一个是Windows注册表文件。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。 Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。
3.Hadoop

Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。 Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算
4.Hbase

HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
HBase–Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
步骤1:实验环境介绍
本次实验需要使用hbase和hive,自然也需要hadoop和zookeeper,我们提供安装好的zookeeper、hadoop、hive、hbase。xshell连接linux节点,进行以下操作。
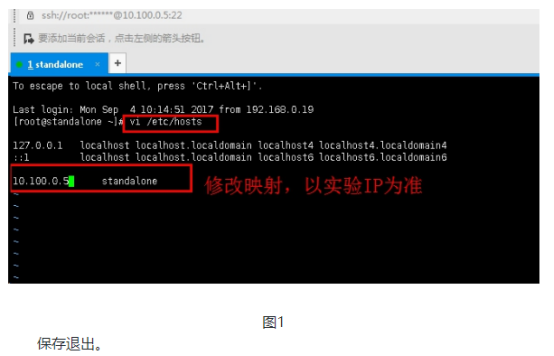
1.1使用xshell连接服务器,然后编辑文件/etc/hosts,
vi /etc/hosts


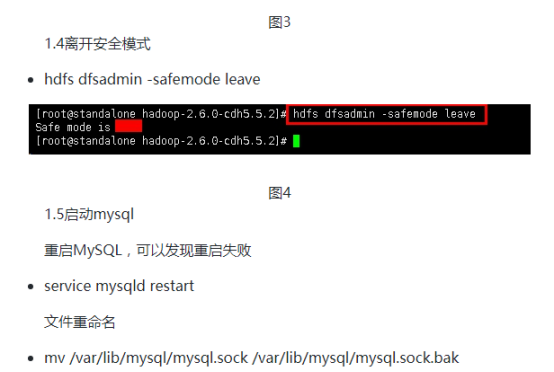
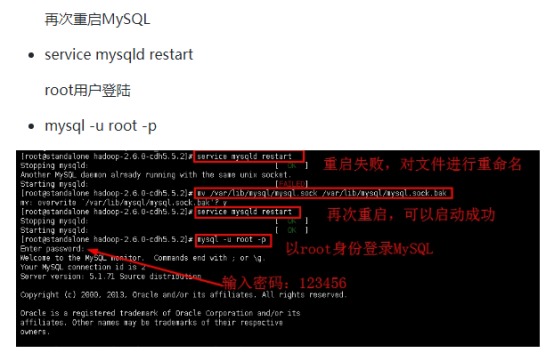
注意:步骤中开启MySQL服务失败,出现以下文字:“Another MySQL daemon already running with the same unix socket.” 这是一个MySQL错误提醒,其原因是多个MySQL进程使用了同一个socket,其解决方法有两个:一是使用命令"shutdown -h now"关机,然后在启动,进程就停止了。二是直接把mysql.sock文件重命名即可,也可以删除其文件。实验中我们选择重命名,然后就可以启动MySQL了。
步骤2:开启hive和zookeeper
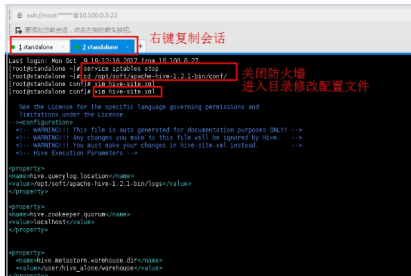
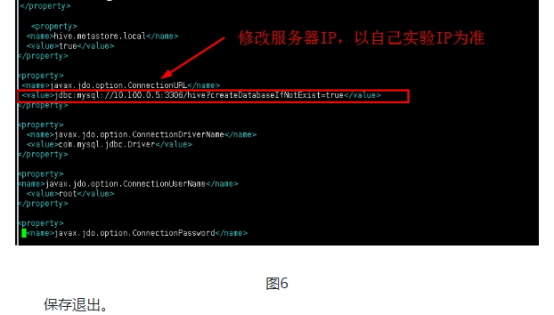
2.1右键复制会话,输入命令关闭防火墙,编辑hive-site.xml配置文件。
service iptables stop
cd /opt/soft/apache-hive-1.2.1-bin/conf/
修改IP节点
vim hive-site.xml
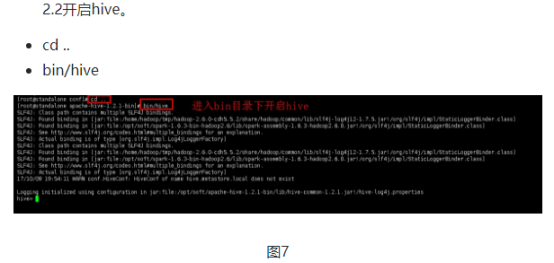
2.3再次右键复制会话,输入命令开启zookeeper。
cd /home/hadoop/tmp/soft/zookeeper-3.4.6/
bin/zkServer.sh start
bin/zkServer.sh status
jps

步骤3:开启hbase,创建表格
3.1右键复制会话,进入hbase目录,开启hbase,进入shell环境。
cd /opt/soft/hbase-1.2.4/
bin/start-hbase.sh
jps
bin/hbase shell
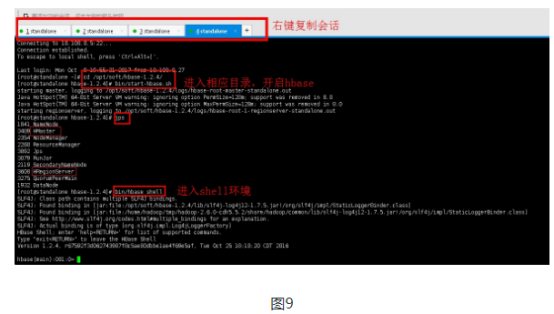
确保启动了hbase、hdfs、zookeeper,使用hbase shell启动hbase shell客户端后,就可以建表,插入数据。
3.2创建表格,插入数据。
查看列表
list
新建表hivetable1。注意不能和已有表重名。
create 'hivetable1',{NAME => 'f1',VERSIONS => 1},{NAME => 'f2',VERSIONS => 1},{NAME => 'f3',VERSIONS => 1}

插入数据:
put 'hivetable1','k1','f1:name','name'
put 'hivetable1','k1','f1:age','age'
put 'hivetable1','k1','f1:sex','sex'
put 'hivetable1','k2','f2:id','id'
put 'hivetable1','k2','f2:passwd','passwd'
put 'hivetable1','k3','f3:love','love'
获取数据:
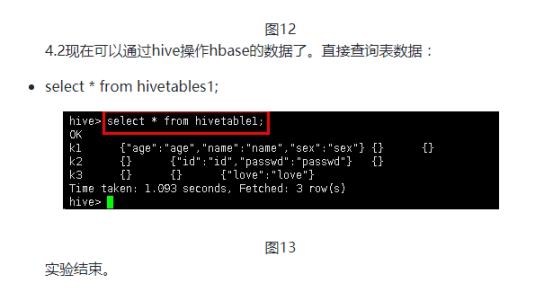
get 'hivetable1','k1','f1:name'

步骤4:创建hive表,关联hbase
4.1回到hive会话中,创建hive表。输入以下命令:
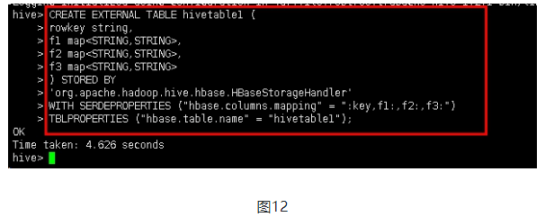
CREATE EXTERNAL TABLE hivetable1 (
rowkey string,
f1 map<STRING,STRING>,
f2 map<STRING,STRING>,
f3 map<STRING,STRING>
) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,f1:,f2:,f3:")
TBLPROPERTIES ("hbase.table.name" = "hivetable1");
其中,参数解释如下:
hbase.zookeeper.quorum:指定HBase使用的zookeeper集群,默认端口是2181,可以不指定,如果指定,格式为zkNode1:2222,zkNode2:2222,zkNode3:2222
zookeeper.znode.parent:指定HBase在zookeeper中使用的根目录
hbase.columns.mapping:Hive表和HBase表的字段映射关系,分别为:Hive表中第一个字段映射:key(rowkey),第二个字段映射列族f1,第三个字段映射列族f2,第四个字段映射列族f3
hbase.table.name:HBase中表的名字