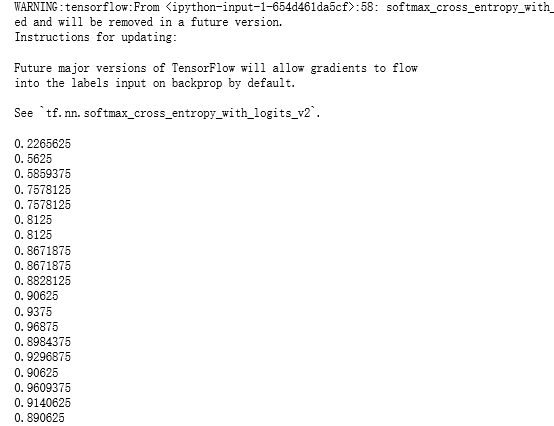
#加载TF并导入数据集 import tensorflow as tf from tensorflow.contrib import rnn from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("E:\\MNIST_data\\", one_hot=True) #设置训练的超参数,学习率 训练迭代最大次数,输入数据的个数 learning_rate= 0.001 #(learning_rate) training_iters = 100000 batch_size = 128 # 神经网络参数 n_inputs = 28 #输出层的n n_steps = 28 # 长度 n_hidden = 128 # 隐藏层的神经元个数 n_classes = 10 # MNIST的分类类别 (0-9) # 定义输出数据及其权重 # 输入数据的占位符 x = tf.placeholder("float", [None, n_steps, n_inputs]) y = tf.placeholder("float", [None, n_classes]) # 定义权重 weights ={ 'in': tf.Variable(tf.random_normal([n_inputs, n_hidden])), 'out': tf.Variable(tf.random_normal([n_hidden, n_classes])) } biases = { 'in': tf.Variable(tf.random_normal([n_hidden,])), 'out': tf.Variable(tf.random_normal([n_classes, ])) } #定义RNN模型 def RNN(X, weights, biases): #把输入的X转化成X (128 batch * 28 steps ,28 inputs) X = tf.reshape(X,[-1,n_inputs]) # 进入隐藏层 # X_in = (128 batch * 28 steps ,28 hidden) X_in = tf.matmul(X,weights['in']) + biases['in'] # X_in = (128 batch * 28 steps ,28 hidden) X_in=tf.reshape(X_in,[-1,n_steps,n_hidden]) #采用LSTM循环神经网络单元 basic LSTM Cell lstm_cell = tf.contrib.rnn.BasicLSTMCell(n_hidden, forget_bias=1.0,state_is_tuple=True) # 初始化为0 lstm 单元 由 h_cell,h_state两部分组成 init_state=lstm_cell.zero_state(batch_size,dtype=tf.float32) # dynamic_rnn接受张量(batch ,steps,inputs)或者(steps,batch,inputs) 作为X_in outputs,final_state=tf.nn.dynamic_rnn(lstm_cell,X_in,initial_state=init_state,time_major=False) results=tf.matmul(final_state[1], weights['out']) + biases['out'] return results #定义损失函数和优化器,采用AdamOptimizer优化器 pred=RNN(x,weights,biases) cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y)) train_op= tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) # 定义模型预测结果及准确率计算方法 correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1)) accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) # 训练模型及评估模型 # 定义一个会话,启动图,每20次输出一次准确率 with tf.Session() as sess: sess.run(tf.global_variables_initializer()) step = 0 # 训练,达到最大迭代次数 while step * batch_size < training_iters: batch_xs, batch_ys = mnist.train.next_batch(batch_size) # Reshape data to get 28 seq of 28 elements batch_xs = batch_xs.reshape((batch_size, n_steps, n_inputs)) sess.run(train_op, feed_dict={x: batch_xs, y: batch_ys}) if step % 20 == 0: print(sess.run(accuracy,feed_dict={x:batch_xs, y:batch_ys})) step +=1