|
|
|
|
|
|
#K-NN分类
import os
import sys
import time
import operator
import cx_Oracle
import numpy as np
import pandas as pd
import tensorflow as tf
conn=cx_Oracle.connect('doctor/admin@localhost:1521/tszr')
cursor = conn.cursor()
#获取数据集
def getdata(surgery,surgeryChest):
sql = "select feature1,feature2,feature3,feature4,feature5,trainLable \
from menzhenZ where surgery='%s' and surgeryChest='%s'" % (surgery,surgeryChest)
cursor.execute(sql)
rows = cursor.fetchall()
dataset = []
lables = []
for row in rows:
temp = []
temp.append(row[0])
temp.append(row[1])
temp.append(row[2])
temp.append(row[3])
temp.append(row[4])
dataset.append(temp)
lables.append(row[5])
return np.array(dataset),np.array(lables)
def gettestdata(surgery,surgeryChest):
sql = "select feature1,feature2,feature3,feature4,feature5,trainLable from \
testZ where surgery='%s' and surgeryChest='%s'" % (surgery,surgeryChest)
cursor.execute(sql)
rows = cursor.fetchall()
testdataset = []
testlables = []
for row in rows:
temp = []
temp.append(row[0])
temp.append(row[1])
temp.append(row[2])
temp.append(row[3])
temp.append(row[4])
testdataset.append(temp)
testlables.append(row[5])
return np.array(testdataset),np.array(testlables)
#K-NN分类
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = np.tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
#归一化
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = np.zeros(np.shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - np.tile(minVals, (m,1))
normDataSet = normDataSet/np.tile(ranges, (m,1))
return normDataSet, ranges, minVals
erace = []
accuc = []
t = []
#启动和检测模型
def datingClassTest():
datingDataMat,datingLabels = getdata("外科","胸外科")
normMat, ranges, minVals = autoNorm(datingDataMat)
testdataset,testlables = gettestdata("外科","胸外科")
testnormMat, testranges, testminVals = autoNorm(testdataset)
errorCount = 0.0
start = time.time()
for j in [3,5,7,9,11,13]:
for i in range(np.shape(testnormMat)[0]):
classifierResult = classify0(testnormMat[i,:],normMat,datingLabels,j)
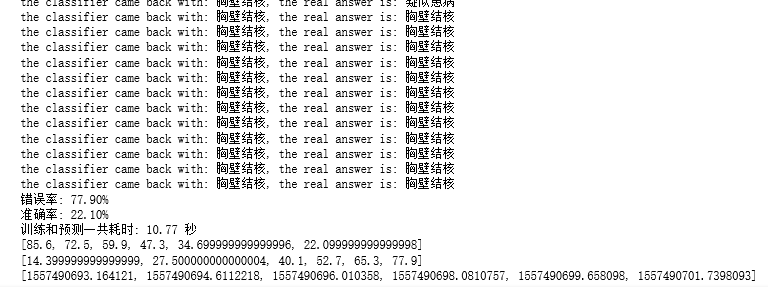
print("the classifier came back with: %s, the real answer is: %s" % (classifierResult, testlables[i]))
if (classifierResult != testlables[i]):
errorCount += 1.0
end = time.time()
t.append(end)
erace.append(errorCount/float(np.shape(testnormMat)[0])*100)
accuc.append((1.0-errorCount/float(np.shape(testnormMat)[0]))*100)
print("错误率: %.2f%%" % (errorCount/float(np.shape(testnormMat)[0])*100))
print("准确率: %.2f%%" % ((1.0-errorCount/float(np.shape(testnormMat)[0]))*100))
print("训练和预测一共耗时: %.2f 秒" % (end-start))
datingClassTest()
print(accuc)
print(erace)
print(t)
![]()
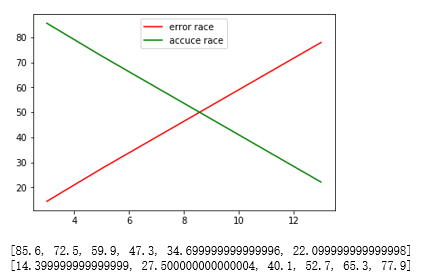
#探索不同的K值对算法的影响
import matplotlib.pyplot as plt
x = [3,5,7,9,11,13]
plt.plot(x,erace,c='r')
plt.plot(x,accuc,c='g')
plt.legend(['error race','accuce race'],loc=9)
plt.show()
print(accuc)
print(erace)
![]()
#决策树
import os
import sys
import time
import operator
import cx_Oracle
import numpy as np
import pandas as pd
from math import log
import tensorflow as tf
conn=cx_Oracle.connect('doctor/admin@localhost:1521/tszr')
cursor = conn.cursor()
#获取数据集
def getdata(surgery,surgeryChest):
sql = "select feature1,feature2,feature3,feature4,feature5,trainLable from menzhenZ where surgery='%s' and surgeryChest='%s'" % (surgery,surgeryChest)
cursor.execute(sql)
rows = cursor.fetchall()
dataset = []
for row in rows:
temp = []
temp.append(row[0])
temp.append(row[1])
temp.append(row[2])
temp.append(row[3])
temp.append(row[4])
temp.append(row[5])
dataset.append(temp)
lables = []
lables.append("呼吸急促")
lables.append("持续性脉搏加快")
lables.append("畏寒")
lables.append("血压降低")
lables.append("咳血")
return dataset,lables
def gettestdata(surgery,surgeryChest):
sql = "select feature1,feature2,feature3,feature4,feature5,trainLable from testZ where surgery='%s' and surgeryChest='%s'" % (surgery,surgeryChest)
cursor.execute(sql)
rows = cursor.fetchall()
testdataset = []
testlables = []
for row in rows:
temp = []
temp.append(row[0])
temp.append(row[1])
temp.append(row[2])
temp.append(row[3])
temp.append(row[4])
testdataset.append(temp)
testlables.append(row[5])
return testdataset,testlables
#计算熵值
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2)
return shannonEnt
#按照给定特征划分数据集
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
#选择最好的属性
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
#统计机制
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
#创建决策树
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
temp = []
for i in labels:
if i != labels[bestFeat]:
temp.append(i)
labels = temp
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree
#使用决策树模型分类
def classify(inputTree,featLabels,testVec):
for i in inputTree.keys():
firstStr = i
break
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
key = testVec[featIndex]
valueOfFeat = secondDict[key]
if isinstance(valueOfFeat, dict):
classLabel = classify(valueOfFeat, featLabels, testVec)
else: classLabel = valueOfFeat
return classLabel
#启动和检测模型
def datingClassTest():
dataSet,labels = getdata("外科","胸外科")
myTree = createTree(dataSet,labels)
testdataset,testlables = gettestdata("外科","胸外科")
errorCount = 0.0
start = time.time()
for i in range(np.shape(testdataset)[0]):
classifierResult = classify(myTree,labels,testdataset[i])
print("the classifier came back with: %s, the real answer is: %s" % (classifierResult, testlables[i]))
if (classifierResult != testlables[i]):
errorCount += 1.0
end = time.time()
print("错误率: %.2f%%" % (errorCount/float(np.shape(testdataset)[0])*100))
print("准确率: %.2f%%" % ((1.0-errorCount/float(np.shape(testdataset)[0]))*100))
print("训练和预测一共耗时: %.2f 秒" % (end-start))
datingClassTest()
![]()
#选取前600条记录生成并打印决策树
dataSet,labels = getdata("外科","胸外科")
dataSet = dataSet[0:600]
labels = labels[0:600]
myTree = createTree(dataSet,labels)
print(myTree)
![]()
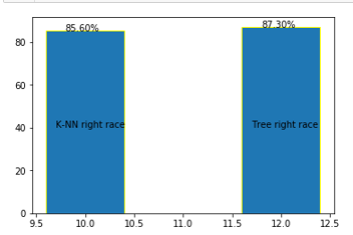
#比较K-NN算法与决策树算法的优劣
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x = np.array([10,12])
y = [85.6,87.3]
plt.bar(x,y,edgecolor='yellow')
for i,j in zip(x,y):
plt.text(i-0.2,j-0.2,'%.2f%%' % j)
plt.text(9.7,40,'K-NN right race')
plt.text(11.7,40,'Tree right race')
plt.show()
![]()
#使用神经网络探索数据集
import sys
import os
import time
import operator
import cx_Oracle
import numpy as np
import pandas as pd
import tensorflow as tf
conn=cx_Oracle.connect('doctor/admin@localhost:1521/tszr')
cursor = conn.cursor()
#one-hot编码
def onehot(labels):
n_sample = len(labels)
n_class = max(labels) + 1
onehot_labels = np.zeros((n_sample, n_class))
onehot_labels[np.arange(n_sample), labels] = 1
return onehot_labels
#获取数据集
def getdata(surgery,surgeryChest):
sql = "select feature1,feature2,feature3,feature4,feature5,trainLable from menzhen where surgery='%s' and surgeryChest='%s'" % (surgery,surgeryChest)
cursor.execute(sql)
rows = cursor.fetchall()
dataset = []
lables = []
for row in rows:
temp = []
temp.append(row[0])
temp.append(row[1])
temp.append(row[2])
temp.append(row[3])
temp.append(row[4])
dataset.append(temp)
if(row[5]==3):
lables.append(0)
elif(row[5]==6):
lables.append(1)
else:
lables.append(2)
dataset = np.array(dataset)
lables = np.array(lables)
dataset = dataset.astype(np.float32)
labless = onehot(lables)
return dataset,labless
#获取测试数据集
def gettestdata(surgery,surgeryChest):
sql = "select feature1,feature2,feature3,feature4,feature5,trainLable from test where surgery='%s' and surgeryChest='%s'" % (surgery,surgeryChest)
cursor.execute(sql)
rows = cursor.fetchall()
testdataset = []
testlables = []
for row in rows:
temp = []
temp.append(row[0])
temp.append(row[1])
temp.append(row[2])
temp.append(row[3])
temp.append(row[4])
testdataset.append(temp)
if(row[5]==3):
testlables.append(0)
elif(row[5]==6):
testlables.append(1)
else:
testlables.append(2)
testdataset = np.array(testdataset)
testlables = np.array(testlables)
testdataset = testdataset.astype(np.float32)
testlabless = onehot(testlables)
return testdataset,testlabless
dataset,labless = getdata("外科","胸外科")
testdataset,testlables = gettestdata("外科","胸外科")
dataset = dataset[0:100]
labless = labless[0:100]
x_data = tf.placeholder("float32", [None, 5])
y_data = tf.placeholder("float32", [None, 3])
weight = tf.Variable(tf.ones([5, 3]))
bias = tf.Variable(tf.ones([3]))
#使用softmax激活函数
y_model = tf.nn.softmax(tf.matmul(x_data, weight) + bias)
#y_model = tf.nn.relu(tf.matmul(x_data, weight) + bias)
# loss = tf.reduce_sum(tf.pow((y_model - y_data), 2))
#使用交叉熵作为损失函数
loss = -tf.reduce_sum(y_data*tf.log(y_model))
# train_step = tf.train.GradientDescentOptimizer(1e-4).minimize(loss)
#使用AdamOptimizer优化器
train_step = tf.train.AdamOptimizer(1e-4).minimize(loss)
#train_step = tf.train.MomentumOptimizer(1e-4,0.9).minimize(loss)
#评估模型
correct_prediction = tf.equal(tf.argmax(y_model, 1), tf.argmax(y_data, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
start = time.time()
for _ in range(10):
for i in range(int(len(dataset)/100)):
sess.run(train_step, feed_dict={x_data:dataset[i:i+100,:], y_data:labless[i:i+100,:]})
print("模型准确率",sess.run(accuracy, feed_dict={x_data:testdataset , y_data:testlables}))
end = time.time()
print("模型训练和测试公耗时:%.2f 秒" % (end-start))
![]()
#加深一层神经网络
import sys
import os
import time
import operator
import cx_Oracle
import numpy as np
import pandas as pd
import tensorflow as tf
conn=cx_Oracle.connect('doctor/admin@localhost:1521/tszr')
cursor = conn.cursor()
#one-hot编码
def onehot(labels):
n_sample = len(labels)
n_class = max(labels) + 1
onehot_labels = np.zeros((n_sample, n_class))
onehot_labels[np.arange(n_sample), labels] = 1
return onehot_labels
#获取数据集
def getdata(surgery,surgeryChest):
sql = "select feature1,feature2,feature3,feature4,feature5,trainLable from menzhen where surgery='%s' and surgeryChest='%s'" % (surgery,surgeryChest)
cursor.execute(sql)
rows = cursor.fetchall()
dataset = []
lables = []
for row in rows:
temp = []
temp.append(row[0])
temp.append(row[1])
temp.append(row[2])
temp.append(row[3])
temp.append(row[4])
dataset.append(temp)
if(row[5]==3):
lables.append(0)
elif(row[5]==6):
lables.append(1)
else:
lables.append(2)
dataset = np.array(dataset)
lables = np.array(lables)
dataset = dataset.astype(np.float32)
labless = onehot(lables)
return dataset,labless
def gettestdata(surgery,surgeryChest):
sql = "select feature1,feature2,feature3,feature4,feature5,trainLable from test where surgery='%s' and surgeryChest='%s'" % (surgery,surgeryChest)
cursor.execute(sql)
rows = cursor.fetchall()
testdataset = []
testlables = []
for row in rows:
temp = []
temp.append(row[0])
temp.append(row[1])
temp.append(row[2])
temp.append(row[3])
temp.append(row[4])
testdataset.append(temp)
if(row[5]==3):
testlables.append(0)
elif(row[5]==6):
testlables.append(1)
else:
testlables.append(2)
testdataset = np.array(testdataset)
testlables = np.array(testlables)
testdataset = testdataset.astype(np.float32)
testlabless = onehot(testlables)
return testdataset,testlabless
dataset,labless = getdata("外科","胸外科")
testdataset,testlables = gettestdata("外科","胸外科")
dataset = dataset[0:100]
labless = labless[0:100]
x_data = tf.placeholder("float32", [None, 5])
y_data = tf.placeholder("float32", [None, 3])
weight1 = tf.Variable(tf.ones([5, 20]))
bias1 = tf.Variable(tf.ones([20]))
y_model1 = tf.matmul(x_data, weight1) + bias1
#加深一层神经网络
weight2 = tf.Variable(tf.ones([20, 3]))
bias2 = tf.Variable(tf.ones([3]))
y_model = tf.nn.softmax(tf.matmul(y_model1, weight2) + bias2)
loss = tf.reduce_sum(tf.pow((y_model - y_data), 2))
# loss = -tf.reduce_sum(y_data*tf.log(y_model))
#train_step = tf.train.GradientDescentOptimizer(1e-4).minimize(loss)
train_step = tf.train.AdamOptimizer(1e-4).minimize(loss)
# train_step = tf.train.MomentumOptimizer(1e-4,0.9).minimize(loss)
correct_prediction = tf.equal(tf.argmax(y_model, 1), tf.argmax(y_data, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
start = time.time()
for _ in range(10):
for i in range(int(len(dataset)/100)):
sess.run(train_step, feed_dict={x_data:dataset[i:i+100,:], y_data:labless[i:i+100,:]})
print("模型准确率",sess.run(accuracy, feed_dict={x_data:testdataset , y_data:testlables}))
end = time.time()
print("模型训练和测试公耗时:%.2f 秒" % (end-start))
![]()
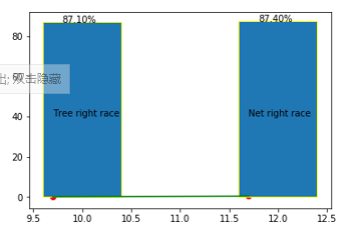
#比较决策树与神经网络的优劣
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x = np.array([10,12])
y = [87.1,87.4]
plt.bar(x,y,edgecolor="yellow")
for i,j in zip(x,y):
plt.text(i-0.2,j-0.2,"%.2f%%" % j)
plt.text(9.7,40,"Tree right race")
plt.text(11.7,40,"Net right race")
plt.scatter([9.7,11.7],[0.05,0.36],c="r")
plt.plot([9.7,11.7],[0.05,0.36],c="g")
plt.show()
![]()
#统计各种算法处理模型数据
K-NN算法:
当K取[3,5,7,9,11,13]时,对应的:
准确率:[85.6, 72.6, 60.0, 47.4, 34.8, 22.299999999999996]
总耗时:[1554119134.435363, 1554119136.6192698,
1554119138.846019, 1554119141.2507513, 1554119143.4782736, 1554119145.5415804]
决策树:
准确率: 87.10%
训练和预测一共耗时: 0.05 秒
神经网络设计:
1 最小二乘法 softmax GradientDescentOptimizer 模型
模型准确率 0.874
模型训练和测试公耗时:0.16 秒
2 最小二乘法 softmax AdamOptimizer 模型
模型准确率 0.874
模型训练和测试公耗时:0.19 秒
3 最小二乘法 softmax MomentumOptimizer 模型
模型准确率 0.874
模型训练和测试公耗时:0.18 秒
4 最小二乘法 relu GradientDescentOptimizer 模型
模型准确率 0.874
模型训练和测试公耗时:0.17 秒
5 最小二乘法 relu AdamOptimizer 模型
模型准确率 0.874
模型训练和测试公耗时:0.15 秒
6 最小二乘法 relu MomentumOptimizer 模型
模型准确率 0.006
模型训练和测试公耗时:0.19 秒
7 交叉熵 softmax GradientDescentOptimizer 模型
模型准确率 0.874
模型训练和测试公耗时:0.09 秒
8 交叉熵 softmax AdamOptimizer 模型
模型准确率 0.874
模型训练和测试公耗时:0.08 秒
9 交叉熵 softmax MomentumOptimizer 模型
模型准确率 0.874
模型训练和测试公耗时:0.06 秒
10 交叉熵 relu GradientDescentOptimizer 模型
模型准确率 0.874
模型训练和测试公耗时:0.08 秒
11 交叉熵 relu AdamOptimizer 模型
模型准确率 0.874
模型训练和测试公耗时:0.08 秒
12 交叉熵 relu MomentumOptimizer 模型
模型准确率 0.874
模型训练和测试公耗时:0.09 秒
从上面的12种神经网络设计模型中可以看出:最小二乘法 relu MomentumOptimizer 模型
的准确率只有0.006,所以这种模型的设计是失败的。
a = [0.874]*10
print(a)
#计算成功的各种神经网络模型的准确率与耗时的比值:
a = [0.874]*11
b = [0.16,0.19,0.18,0.17,0.15,0.09,0.08,0.06,0.08,0.09,0.09]
c = []
for i in range(len(a)):
c.append(a[i]/b[i])
for i in range(len(c)):
print("准确率与耗时的比值:%.4f" % (c[i]))
![]()
![]()
#K-NN算法
#当K取3、5、7、9、11、13时的准确率饼图分布显示
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
acc = [85.6, 72.6, 60.0, 47.4, 34.8, 22.2]
labels = ['K-3','K-5','K-7','K-9','K-11','K-13']
plt.pie(acc,labels=labels,shadow=True,startangle=90,autopct='%1.4f%%')
plt.axis('equal')
plt.title('K-NN',fontsize=25)
plt.show()
![]()
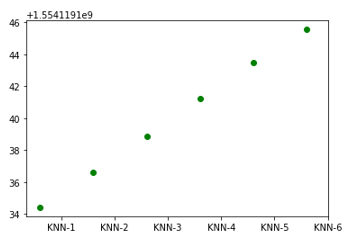
#K-NN算法耗时散点图
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
x = np.array([1,2,3,4,5,6])
z = np.array([1554119134.435363, 1554119136.6192698,1554119138.846019,
1554119141.2507513, 1554119143.4782736, 1554119145.5415804])
plt.scatter(x,z,c='g')
plt.xticks(x+0.4,['KNN-1','KNN-2','KNN-3','KNN-4','KNN-5','KNN-6'])
plt.show()
![]()
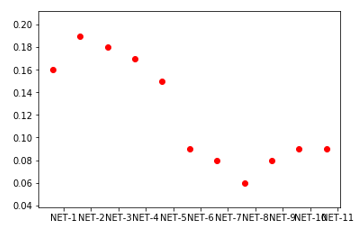
#神经网络算法对应各种有用的模型设计耗时曲线图
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
x = np.array([1,2,3,4,5,6,7,8,9,10,11])
z = np.array([0.16,0.19,0.18,0.17,0.15,0.09,0.08,0.06,0.08,0.09,0.09])
plt.scatter(x,z,c='r')
plt.xticks(x+0.4,['NET-1','NET-2','NET-3','NET-4','NET-5',
'NET-6','NET-7','NET-8','NET-9','NET-10','NET-11'])
plt.show()
![]()
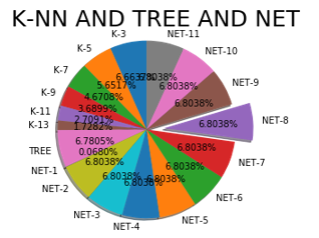
#K-NN、决策树以及神经网络算法对比
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
acc = [85.6, 72.6, 60.0, 47.4, 34.8, 22.2,87.10,0.874,
87.4,87.4,87.4,87.4,87.4,87.4,87.4,87.4,87.4,87.4]
labels = ['K-3','K-5','K-7','K-9','K-11','K-13','TREE',
'NET-1','NET-2','NET-3','NET-4','NET-5','NET-6','NET-7',
'NET-8','NET-9','NET-10','NET-11']
explode = [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0.2,0,0,0]
plt.pie(acc,labels=labels,explode=explode,shadow=True,startangle=90,autopct='%1.4f%%')
plt.axis('equal')
plt.title('K-NN AND TREE AND NET',fontsize=25)
plt.show()
![]()
发表于
2019-05-13 23:22
吴裕雄
阅读( 1744)
评论()
收藏
举报
|
|