import numpy as np import matplotlib.pyplot as plt from sklearn.datasets.samples_generator import make_blobs def create_data(centers,num=100,std=0.7): ''' 生成用于聚类的数据集 :param centers: 聚类的中心点组成的数组。如果中心点是二维的,则产生的每个样本都是二维的。 :param num: 样本数 :param std: 每个簇中样本的标准差 :return: 用于聚类的数据集。是一个元组,第一个元素为样本集,第二个元素为样本集的真实簇分类标记 ''' X, labels_true = make_blobs(n_samples=num, centers=centers, cluster_std=std) return X,labels_true # 用于产生聚类的中心点 centers=[[1,1],[2,2],[1,2],[10,20]] # 产生用于聚类的数据集 X,labels_true=create_data(centers,1000,0.5) # X,labels_true = create_data(centers,num=100,std=0.7) # print(X,labels_true) print(len(X)) print(len(labels_true))
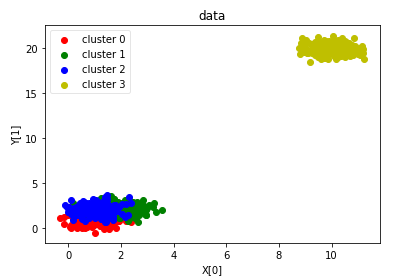
def plot_data(*data): ''' 绘制用于聚类的数据集 ''' X,labels_true=data labels=np.unique(labels_true) fig=plt.figure() ax=fig.add_subplot(1,1,1) # 每个簇的样本标记不同的颜色 colors='rgbyckm' for i,label in enumerate(labels): position=labels_true==label ax.scatter(X[position,0],X[position,1],label="cluster %d"%label,color=colors[i%len(colors)]) ax.legend(loc="best",framealpha=0.5) ax.set_xlabel("X[0]") ax.set_ylabel("Y[1]") ax.set_title("data") plt.show() plot_data(X,labels_true) # 绘制用于聚类的数据集