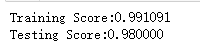
import numpy as np import matplotlib.pyplot as plt from sklearn import neighbors, datasets from sklearn.model_selection import train_test_split def load_classification_data(): # 使用 scikit-learn 自带的手写识别数据集 Digit Dataset digits=datasets.load_digits() X_train=digits.data y_train=digits.target # 进行分层采样拆分,测试集大小占 1/4 return train_test_split(X_train, y_train,test_size=0.25,random_state=0,stratify=y_train) #KNN分类KNeighborsClassifier模型 def test_KNeighborsClassifier(*data): X_train,X_test,y_train,y_test=data clf=neighbors.KNeighborsClassifier() clf.fit(X_train,y_train) print("Training Score:%f"%clf.score(X_train,y_train)) print("Testing Score:%f"%clf.score(X_test,y_test)) # 获取分类模型的数据集 X_train,X_test,y_train,y_test=load_classification_data() # 调用 test_KNeighborsClassifier test_KNeighborsClassifier(X_train,X_test,y_train,y_test)
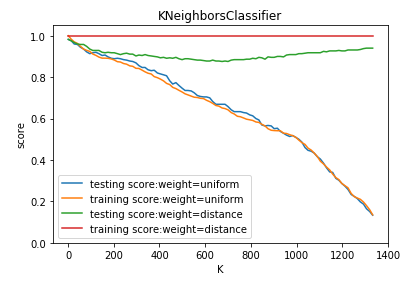
def test_KNeighborsClassifier_k_w(*data): ''' 测试 KNeighborsClassifier 中 n_neighbors 和 weights 参数的影响 ''' X_train,X_test,y_train,y_test=data Ks=np.linspace(1,y_train.size,num=100,endpoint=False,dtype='int') weights=['uniform','distance'] fig=plt.figure() ax=fig.add_subplot(1,1,1) ### 绘制不同 weights 下, 预测得分随 n_neighbors 的曲线 for weight in weights: training_scores=[] testing_scores=[] for K in Ks: clf=neighbors.KNeighborsClassifier(weights=weight,n_neighbors=K) clf.fit(X_train,y_train) testing_scores.append(clf.score(X_test,y_test)) training_scores.append(clf.score(X_train,y_train)) ax.plot(Ks,testing_scores,label="testing score:weight=%s"%weight) ax.plot(Ks,training_scores,label="training score:weight=%s"%weight) ax.legend(loc='best') ax.set_xlabel("K") ax.set_ylabel("score") ax.set_ylim(0,1.05) ax.set_title("KNeighborsClassifier") plt.show() # 获取分类模型的数据集 X_train,X_test,y_train,y_test=load_classification_data() # 调用 test_KNeighborsClassifier_k_w test_KNeighborsClassifier_k_w(X_train,X_test,y_train,y_test)
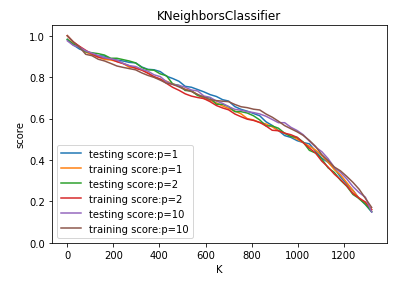
def test_KNeighborsClassifier_k_p(*data): ''' 测试 KNeighborsClassifier 中 n_neighbors 和 p 参数的影响 ''' X_train,X_test,y_train,y_test=data Ks=np.linspace(1,y_train.size,endpoint=False,dtype='int') Ps=[1,2,10] fig=plt.figure() ax=fig.add_subplot(1,1,1) ### 绘制不同 p 下, 预测得分随 n_neighbors 的曲线 for P in Ps: training_scores=[] testing_scores=[] for K in Ks: clf=neighbors.KNeighborsClassifier(p=P,n_neighbors=K) clf.fit(X_train,y_train) testing_scores.append(clf.score(X_test,y_test)) training_scores.append(clf.score(X_train,y_train)) ax.plot(Ks,testing_scores,label="testing score:p=%d"%P) ax.plot(Ks,training_scores,label="training score:p=%d"%P) ax.legend(loc='best') ax.set_xlabel("K") ax.set_ylabel("score") ax.set_ylim(0,1.05) ax.set_title("KNeighborsClassifier") plt.show() # 获取分类模型的数据集 X_train,X_test,y_train,y_test=load_classification_data() # 调用 test_KNeighborsClassifier_k_p test_KNeighborsClassifier_k_p(X_train,X_test,y_train,y_test)