import matplotlib.pyplot as plt from sklearn import datasets,naive_bayes from sklearn.model_selection import train_test_split # 加载 scikit-learn 自带的 digits 数据集 def load_data(): ''' 加载用于分类问题的数据集。这里使用 scikit-learn 自带的 digits 数据集 ''' digits=datasets.load_digits() return train_test_split(digits.data,digits.target,test_size=0.25,random_state=0,stratify=digits.target) def show_digits(): ''' 绘制 digits 数据集。这里只是绘制数据集中前 25 个样本的图片。 ''' digits=datasets.load_digits() fig=plt.figure() print("vector from images 0:",digits.data[0]) for i in range(25): ax=fig.add_subplot(5,5,i+1) ax.imshow(digits.images[i],cmap=plt.cm.gray_r, interpolation='nearest') plt.show() show_digits()

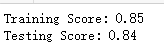
#高斯贝叶斯分类器GaussianNB模型 def test_GaussianNB(*data): X_train,X_test,y_train,y_test=data cls=naive_bayes.GaussianNB() cls.fit(X_train,y_train) print('Training Score: %.2f' % cls.score(X_train,y_train)) print('Testing Score: %.2f' % cls.score(X_test, y_test)) # 产生用于分类问题的数据集 X_train,X_test,y_train,y_test=load_data() # 调用 test_GaussianNB test_GaussianNB(X_train,X_test,y_train,y_test)