
import time
a = time.time()
print(a)
b = time.localtime()
print(b)
c = time.strftime("%Y-%m-%d %X",time.localtime())
print(c)
d = time.mktime(time.localtime())
print(d)
e = time.strftime("%Y-%m-%d %X",time.localtime(1544103564.0))
print(e)

import datetime
import numpy as np
import pandas as pd
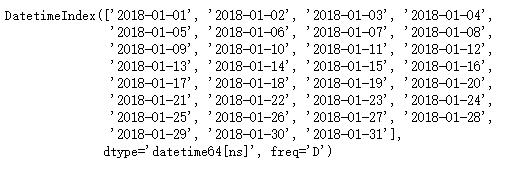
a = pd.date_range(datetime.datetime(2018,1,1),periods=31)
print(a)
import datetime
import numpy as np
import pandas as pd
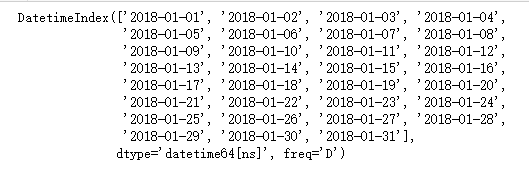
a = pd.date_range("2018-1-1",periods=31)
print(a)
import datetime
import numpy as np
import pandas as pd
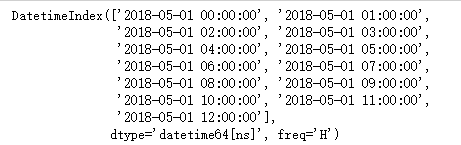
a = pd.date_range("2018-5-1 00:00","2018-5-1 12:00",freq="H")
print(a)
import datetime
import numpy as np
import pandas as pd
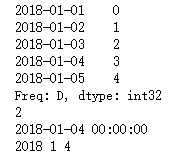
ts1 = pd.Series(np.arange(31),index=pd.date_range("2018-1-1",periods=31))
print(ts1.head())
print(ts1["2018-1-3"])
print(ts1.index[3])
a = ts1.index[3].year
b = ts1.index[3].month
c = ts1.index[3].day
print(a,b,c)
import datetime
import numpy as np
import pandas as pd
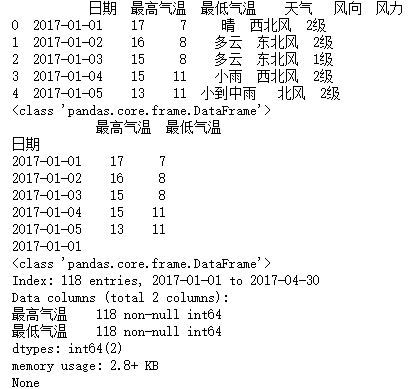
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\pandas data\\hz_weather.csv")
print(data.head())
df = data[["日期","最高气温","最低气温"]].set_index("日期")
print(type(df))
print(df.head())
print(df.index[0])
print(df.info())
import datetime
import numpy as np
import pandas as pd
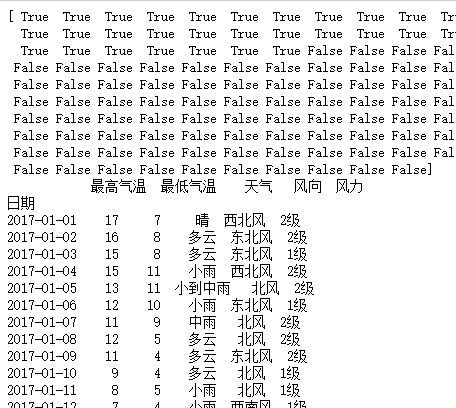
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\pandas data\\hz_weather.csv")
df = data.set_index("日期")
a = np.array(df.index) < "2017-02-01"
print(a)
b = df[(df.index >= "2017-01-01")&(df.index < "2017-02-01")]
print(b)
print(b.info())
import datetime
import numpy as np
import pandas as pd
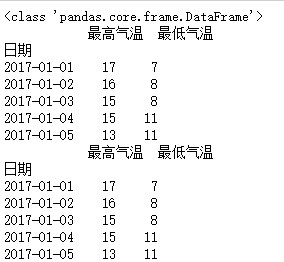
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\pandas data\\hz_weather.csv")
df = data.set_index("日期")
df = data[["日期","最高气温","最低气温"]].set_index("日期")
print(type(df))
print(df.head())
a = df.groupby(level=0).mean()
print(a.head())
%matplotlib inline
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
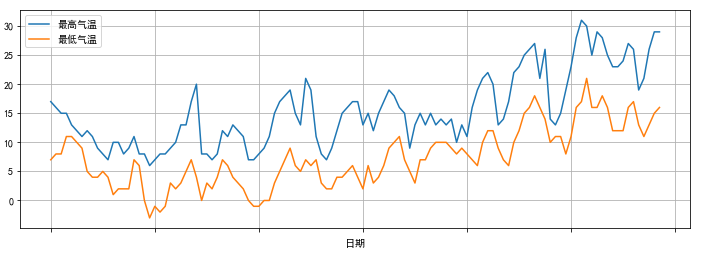
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\pandas data\\hz_weather.csv")
df = data.set_index("日期")
df = data[["日期","最高气温","最低气温"]].set_index("日期")
fig,ax = plt.subplots(1,1,figsize=(12,4))
df.plot(ax=ax)
plt.grid()
# ax.set_xticklabels(df.index.values)
# ax.set_xlabel(df.index.values)
plt.show()
import numpy as np
import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\pandas data\\european_cities.csv")
print(np.shape(data))
print(data.head())
print(type(data.Population[0]))

import numpy as np
import pandas as pd
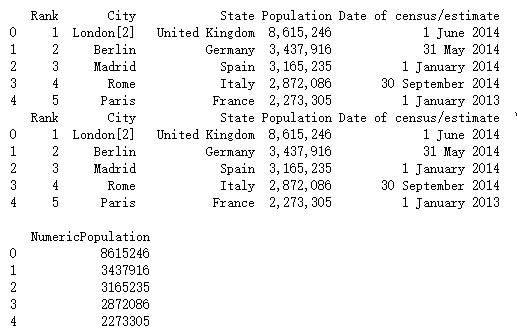
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\pandas data\\european_cities.csv")
print(data.head())
data["NumericPopulation"] = data.Population.apply(lambda x:int(x.replace(",","")))
print(data.head())
import numpy as np
import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\pandas data\\european_cities.csv")
a = data["State"].values[:3]
print(a)
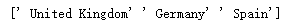
import numpy as np
import pandas as pd
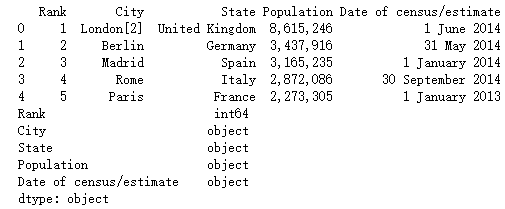
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\pandas data\\european_cities.csv")
data["State"] = data["State"].apply(lambda x:x.strip())
print(data.head())
print(data.dtypes)
import numpy as np
import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\pandas data\\getlinks.csv")
print(data.head())
a = data.link.str.extract("(\d+)")
print(a)
b = data.link.str.extract("(.*)/(\d+)")
print(b)

import numpy as np
import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\pandas data\\getlinks.csv")
print(data.head())
b = data.link.str.extract("(?P<URL>.*)/(?P<ID>\d+)")
print(b)

