BUAA_2022面向对象_第一单元总结
O、写在前面
总的来说,第一单元尽管涵盖了面向对象这个名词的大多数含义,但事实上其难度跨度并不大,更多的是给予我们一定的时间来适应这门课的一些特征。根据我自己的理解,这门课最为重要的两个特征为:合作共赢、崇尚设计。
崇尚设计:当我们在强调层次架构的时候我们在强调什么?其本质,还是设计。面向对象以对象为单位,与之相随的有八大设计原则,其难点在此,但其魅力亦在此。如何减少耦合性,如何满足单一职责、开闭原则等设计理念是至关重要的,不论是漏洞查找,还是程序拓展,亦或是局部重构,都需要一个灵活明了的架构。往往从一开始的第一次作业,就决定了本单元的艰难与否,这与架构是分不开的。
一、关于三次作业
为何对上述两个特征印象如此深刻,那必定是我吃过这俩的亏。在第一次作业时,尝试采取递归下降的方式进行解析,但是由于“没想好就动手”,在倒数第一天遇到de不出来的bug,四处翻找也没能在杂乱的设计中找到一个合理的bug解释,无奈只能临时跳转预解析。另外,也是犯了闭门造车的老毛病,递归下降的算法没有理解透彻,写的时候只是根据浅显的认识加以模仿,导致后续debug的时候没有一个明确的思维指引。而之后,权衡其他课程的时间,终究没能选择重构。
1.1 存储方式选择
言归正传,既然走上预解析的不归路,那就暂且不谈解析方法,而专注于存储方式与化简技巧吧。下面附上最终三次作业的UML图。
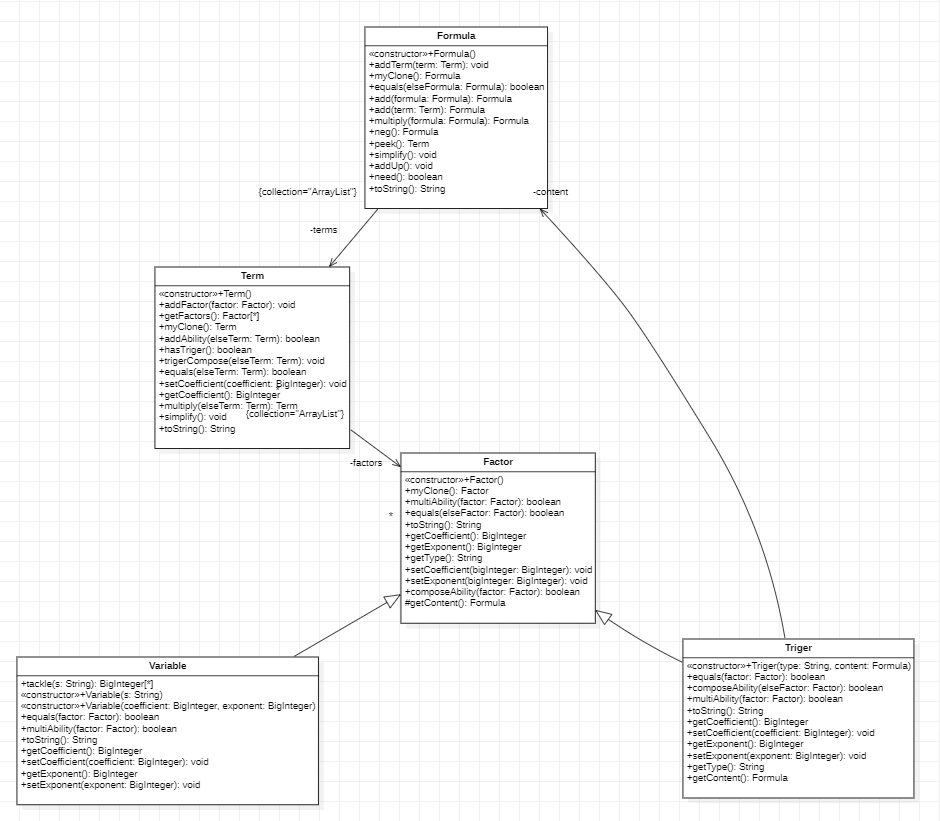
对于存储方法,广泛使用的有两种:寻求一般形式、(递归)建树。下面对这两种进行详尽的分析。
1.1.1 寻求一般形式
这对于第一次作业是再简单不过了,没有sin和cos的干扰,我们需要考虑的范围仅仅是多项式环F[x]。在该范围中,一个多项式可以仅仅用指数、系数构成的节点链接而成,于是很容易想到利用一系列带两个属性:coefficient、exponent,的term来存储整个多项式结构。对于简单的合并操作,加法比较exponent然后操作coefficient,乘法coefficient相乘、exponent相加,几乎没有任何难点。
第二次作业增加了sin和cos,如果在寻求一般形式,则形式如下:
仍可以采用单个term的形式存取这一个一般形式。其优点显而易见,即架构尤其简单,只需要将term进行相加即可;其缺点也非常明显,即在这一个term类中,需要实现x、sin、cos这三者的计算操作,这直接引起讨论的情况数大大增加,不论是代码量还是出bug概率都大幅提升。
如果拿单一职责与开闭原则来比对,由于一个类实现几乎全部计算,显然不满足单一职责;另外,三角函数和多项式项集合在一起,如果另加其他函数,则需要在每种分支结构中添加新的分支,显然也不满足开闭原则。因此,这样的构思是完全面向问题设计,如果再继续拓展下去,重构不可避免。
1.1.2 (递归)建树
至于为什么在递归外加括号,想必大家也很清楚。可以说,在第三次允许嵌套之后,递归存储的方法成为“首选”方法。运算式本身就是一个多层嵌套结构,其本质,也是一个类似b+树的结构:非叶子节点——多元运算符;叶子结点——基本运算单位。因此只要这个树建好了,就可以通过后序遍历,递归进行:获取操作对象(子节点),获取操作符(本节点),得到本节点的运算结果,最终就能在根节点获取全部的运算结果。
第一单元作业全部采用BNF形式化描述,其递归描述的方式为我们直接提供了递归存储的思路。于是很容易就能构建出上面UML图的架构:顶层formula表征只定义了加法的多项式,子类term表征只定义了乘法的多项式,而factor则表征乘法的单元对象,即a*x^b与三角函数,而在三角函数中又用content存储顶层的formula,由此构成递归存储结构。
这样存储的优点:具有灵活性和可拓展性,并且对化简友好。相较于一般形式的方法,递归存储方式将表达式结构划分为一个个小的要素,可以分别定义各要素之间的运算,这样为履行单一职责提供了天然条件;另外对要素进行了分类,因此添加其他运算单位时可以作为新的类,并继续定义此类与其他运算单元的交互方法(运算)。有关化简下面会谈到。
1.2 复杂度分析
下面是使用idea圈复杂度分析插件MatricsReloader的分析结果
| aim.Formula | 4.384615384615385 | 10.0 | 57.0 |
|---|---|---|---|
| aim.Term | 3.8461538461538463 | 13.0 | 50.0 |
| aim.Parser | 3.75 | 12.0 | 30.0 |
| aim.Variable | 2.1 | 8.0 | 21.0 |
| Main | 2.0 | 2.0 | 2.0 |
| aim.Triger | 1.8181818181818181 | 6.0 | 20.0 |
| aim.Factor | 1.1666666666666667 | 3.0 | 14.0 |
| Total | 194.0 | ||
| Average | 2.8529411764705883 | 7.714285714285714 | 27.714285714285715 |
这是排序后的类复杂度评估结果,可见,Formula类由于几乎所有运算都需要从该类开始,并且下述的几个主要方法都以该类为顶层展开,Term紧跟其后,可以说,有这样的结果是不言而喻的。
| aim.Term.toString() | 38.0 | 5.0 | 16.0 | 16.0 |
|---|---|---|---|---|
| aim.Formula.simplify() | 21.0 | 1.0 | 9.0 | 10.0 |
| aim.Parser.parser() | 15.0 | 1.0 | 8.0 | 12.0 |
| aim.Term.trigerCompose(Term) | 14.0 | 1.0 | 10.0 | 10.0 |
| aim.Formula.add(Formula) | 13.0 | 5.0 | 8.0 | 9.0 |
| aim.Formula.equals(Formula) | 12.0 | 7.0 | 5.0 | 8.0 |
| aim.Term.addAbility(Term) | 12.0 | 7.0 | 4.0 | 8.0 |
| aim.Formula.need() | 11.0 | 6.0 | 8.0 | 10.0 |
| aim.Triger.toString() | 11.0 | 3.0 | 6.0 | 6.0 |
| aim.Variable.toString() | 11.0 | 4.0 | 7.0 | 8.0 |
| aim.Formula.add(Term) | 10.0 | 4.0 | 6.0 | 6.0 |
| aim.Term.simplify() | 9.0 | 3.0 | 7.0 | 7.0 |
| aim.Parser.isTerm(String) | 8.0 | 5.0 | 6.0 | 7.0 |
| aim.Term.multiply(Term) | 8.0 | 4.0 | 5.0 | 5.0 |
| aim.Factor.equals(Factor) | 7.0 | 3.0 | 3.0 | 5.0 |
| aim.Formula.multiply(Formula) | 7.0 | 2.0 | 5.0 | 6.0 |
| aim.Triger.multiAbility(Factor) | 6.0 | 4.0 | 4.0 | 4.0 |
| aim.Formula.toString() | 5.0 | 4.0 | 5.0 | 5.0 |
| aim.Formula.addUp() | 4.0 | 1.0 | 4.0 | 4.0 |
| aim.Parser.getTwoOperator(String[]) | 4.0 | 1.0 | 5.0 | 5.0 |
| aim.Triger.composeAbility(Factor) | 4.0 | 1.0 | 7.0 | 7.0 |
| aim.Variable.tackle(String) | 4.0 | 1.0 | 4.0 | 4.0 |
| aim.Term.hasTriger() | 3.0 | 3.0 | 1.0 | 3.0 |
| aim.Triger.equals(Factor) | 3.0 | 2.0 | 5.0 | 5.0 |
| aim.Variable.equals(Factor) | 3.0 | 2.0 | 3.0 | 3.0 |
| aim.Parser.computeNeg(String[]) | 2.0 | 1.0 | 2.0 | 2.0 |
| aim.Parser.computePos(String[]) | 2.0 | 1.0 | 2.0 | 2.0 |
| aim.Parser.computeTriger(String[]) | 2.0 | 1.0 | 2.0 | 2.0 |
| Main.main(String[]) | 1.0 | 1.0 | 2.0 | 2.0 |
| aim.Factor.myClone() | 1.0 | 1.0 | 2.0 | 2.0 |
| aim.Formula.myClone() | 1.0 | 1.0 | 2.0 | 2.0 |
| aim.Formula.neg() | 1.0 | 1.0 | 2.0 | 2.0 |
| aim.Term.equals(Term) | 1.0 | 1.0 | 2.0 | 2.0 |
| aim.Term.myClone() | 1.0 | 1.0 | 2.0 | 2.0 |
| aim.Factor.Factor() | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Factor.composeAbility(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Factor.getCoefficient() | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Factor.getContent() | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Factor.getExponent() | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Factor.getType() | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Factor.multiAbility(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Factor.setCoefficient(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Factor.setExponent(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Factor.toString() | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Formula.Formula() | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Formula.addTerm(Term) | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Formula.peek() | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Parser.Parser(List) | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Parser.makeFormula(String[]) | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Term.Term() | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Term.addFactor(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Term.getCoefficient() | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Term.getFactors() | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Term.setCoefficient(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Triger.Triger(String, Formula) | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Triger.getCoefficient() | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Triger.getContent() | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Triger.getExponent() | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Triger.getType() | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Triger.setCoefficient(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Triger.setExponent(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Variable.Variable(BigInteger, BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Variable.Variable(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Variable.getCoefficient() | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Variable.getExponent() | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Variable.multiAbility(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Variable.setCoefficient(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| aim.Variable.setExponent(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Total | 255.0 | 123.0 | 203.0 | 225.0 |
| Average | 3.75 | 1.8088235294117647 | 2.985294117647059 | 3.3088235294117645 |
经过排序可以发现,复杂度最高的一个是term的toString方法,这是由于优化输出的需要,必定会在toString中进行完备的讨论。譬如,系数为0或1的情况,指数为0或1的情况,有三角函数或没三角函数等等,这样一来,嵌套if的层数增多,加上factor的复杂度,才导致如上结果。另外,我每次调用化简方法simplify都是在toString前调用,因此也会增加其复杂度。排名第二的formula的simplify(化简)方法,也是由于多次遍历元素导致的复杂度上升。除此之外,圈复杂度高的方法基本都是“判断类”方法,这类方法需要进行大量比较,对于第二种存储方式,由于其“深度”加深,因此在遍历比较的时候需要多层嵌套的循环,这自然也是其复杂度高的原因。
因此在设计的时候尽可能减少if嵌套与循环嵌套是减少圈复杂度的关键方法。
1.3 bug分析
按理来说,预解析是不该有bug的,但是这动手比脑子块的老毛病让我在写代码的时候总是“先下手为强”,最终不得不“拆东墙补西墙”,下次一定多多注意。
前两次作业我确实采取第一种存储方式,第一次由于提交匆忙,有一处的String转Biginteger仍采用的是long过渡的形式,导致这一个bug被六个人围攻,着实不该,此处姑且不谈。着重谈谈第二次作业遇到的天坑。
1.2.1 浅克隆与深克隆
惭愧的是,在我写第二次作业之前,就有了解讨论区吴佬发起的讨论,但是在实际运用的时候,还是由于理解不深导致致命bug。沿用了第一次的架构,我一直都没有考虑这个问题。加法乘法运算,我一开始采用的是自存储的方式,即
这两种计算的结构都是直接修改A,之前在作业一中,由于Biginteger的不可变特性,这个漏洞没有显现,但是在作业二中操作对象变为定义的类,因此在多次进行上述操作的时候,这致命的bug才会逐渐浮现。可以看出,这个bug的关键在于,如果A存储结果,那么B必须不可变,即除了方法内不能更改B,上述运算形式还必须具有方向性,绝对不可以B.multiply(A)。
针对这个bug,我在第三次作业重构中采取:每种运算都用一个新的对象来存储。这对加法而言好说,但是乘法还是自存储更为方便(毕竟依据一个个factor重新设置term着实没必要),因此我采用先将A进行克隆,然后再与B进行乘法,将结果加入到另一个预先设定好的容器中。对于clone,我是通过在各类中统一定义了myClone方法,利用Serializable接口利用序列化克隆实现的。
1.2.2 toString
如果采用第一种存储方式,那么toString一定需要小心,因为如果只定义了term、并且还有化简想法的我们,就会如上面复杂度分析那般所言。众多if嵌套就必须考虑全面,否则就会出错。另外一个bug集中的地方是化简的部分,提交最后一版的时候由于化简算法不够成熟,存在些许bug而最终选择简单化简的一版。从这里可以看出,复杂度更高的模块,其出bug的概率也越大,上面分析到的其很大一部分原因是由于大量if嵌套与循环嵌套,这正是我们debug需要注意的地方。
在某些方面来看,在term中toString,不如分散到factor中进行toString,这也是第三次作业重构的一大原因。
1.4 化简分析
第三次作业着重化简,我的架构在上面的UML图中十分显然,之前也说过这样的架构对化简友好,这里就详细谈谈其优点。
化简的关键点有二:能否化简、如何化简。
我的设计中将二者分开实现,“能否化简”用\#Ability的形式定义方法,而化简操作,则直接在toString中调用。
1.4.1 简单长度化简
对于基本的长度化简此处做简单概括。
首先是合并操作,加法的系数合并,乘法的指数合并,以及有0的时候的消除合并操作。当然,对于x**2转化为x*x就不必多说了。需要说明,这里需要考虑到消除合并时,子类列表为空的情况,譬如formula的terms列表里,由于系数全消为0而全被移除列表,导致terms.size()==0,这种情况需要特判。
其次是顺序移动操作,讲正数提到表达式开头可以省去一个符号的长度。
最后是三角函数括号的化简,对于有符号整数与x幂次的情况,sin和cos中不需要两层括号的,这可以通过一个need函数判断是否要加括号来实现。
1.4.2 三角函数合并化简
三角函数的平方和:我的做法是,在formula层级遍历term,寻找每对term中可能可以相加的指数为2的三角函数,利用一个composeAbility方法进行判断,如果可以,则对sin边消除sin^2成分,而对cos这一边,系数需要减去sin那一边的系数。
二倍角操作:在单个term中进行搜索,同样记录可能可以合并的三角函数,利用doubleAbility方法进行判断,如果可以,则消除cos成分,并令系数除以2(前提是系数为2的倍数,因为本次作业不支持小数),令sin内content的系数double。
二、关于hack经历
只能说从提心吊胆到心平气和。最初对自己的设计确实有所不自信,一方面来源于对java语言本身的不熟悉,担心有语言特性上的bug,另一方面还是自己架构的设计问题,缺乏此类经验,没有想得特别清楚。从最开始被hack5、6次,到最后0/20的hack结果,不仅体现了代码架构逻辑的进步,也说明了我的设计方法信心的积攒。
对于我hack别人,第一次兢兢业业下载别人的代码进行阅读,用数据驱动来发现存在的bug,然后针对bug进行hack。之后两次的hack,都是借助数据生成器,初此之外,加上自己能想到的边界数据来进行测试。只能说,星期天需要处理的作业有点多,留给hack的时间着实不多。。。
总体而言,所遇见的bug集中在两个方面:
-
扩展后的成分没有考虑到老的特殊情况。譬如前导零、带符号的指数、数据范围(未用biginteger)等等,以及最终结果为0或1的输出情况处理。
-
扩展后的乘法,即sin、cos分别存在的两个多项式之间的乘法或乘方。一般来说这是由于合并的结果。
基本上,如果提交前在这几个方面多多测试,在配以几个较为复杂的测试样例,在hack途中可能出现bug的概率不大(前提是架构明确。。。)
三、心得体会
在小组讨论过程中,我们组尤其讨论了撰写博客的意义所在,其中一大讨论结果就是“积累经验”。经验一次看似一笔带过般简单,但事实上却浓缩着整个大脑的抽象工作。它负责将我们所学的知识串联起来,并抽象成一块块有关系有结构的树型知识链,尽管日后我们不一定记得详细的知识点,但是却能联想到这方面的主要思想和易出错点,知识点忘了可以重新查找,但是“经验”在未来做项目时扮演者极其重要的角色。当然,这样说并不意味着知识点不重要,能记住知识点固然更好,只不过我认为经验更为重要。
经过这三周的学习,最大的收获还是文前所言的两个课程特征,这也是课程对我们提出的要求。如何能在一周为数不多的大段时间内,从设计到实现一个解决问题的方案,不仅考验知识,更是考验能力。我们需要合作,我们不仅要有自己的想法,更要善于学习他人想法,并在此过程中改善自己的想法,这样才能锻炼出短时间内得出最佳方案的能力;我们需要想清楚再动手,这个阶段才是最耗费时间的,如果将架构设计好之后,bug会少,重构会少,可谓一劳永逸。
希望下一单元能搞定这两方面的问题!



