大数据 Spark 架构
一.Spark的产生背景起源
1.spark特点
1.1轻量级快速处理
Saprk允许传统的hadoop集群中的应用程序在内存中已100倍的速度运行即使在磁盘上也比传统的hadoop快10倍,Spark通过减少对磁盘的io达到性能上的提升,他将中间处理的数据放到内存中,spark使用了rdd(resilient distributed datasets)数据抽象
这允许他在内存中存储数据,所以减少了运行时间
1.2 易于使用
spark支持多种语言。Spark允许java,scala python 及R语言,允许shell进行交互式查询
1.3 支持复杂的查询
除了简单的map和reduce操作之外,Spark还支持filter、foreach、reduceByKey、aggregate以及SQL查询、流式查询等复杂查询。Spark更为强大之处是用户可以在同一个工作流中无缝的搭配这些功能,例如Spark可以通过Spark Streaming(1.2.2小节对Spark Streaming有详细介绍)获取流数据,然后对数据进行实时SQL查询或使用MLlib库进行系统推荐,而且这些复杂业务的集成并不复杂,因为它们都基于RDD这一抽象数据集在不同业务过程中进行转换,转换代价小,体现了统一引擎解决不同类型工作场景的特点。
1.4 实时的流处理
对比maprduce只能处理离线数据。Spark还能支持实时的流计算,spark streaming 主要用来对数据进行实时的处理,yarn的nodemanger统一调度管理很厉害,在yarn产生后hadoop也可以整合资源进行实时的处理
2.时事产物
2.1 mapreduce产生时磁盘廉价,因此许多设计收回考虑到内存的使用,而spark产生时内存相对廉价,对计算速度有所要求,因此spark的产生是基于内存计算的框架结构mapreduce需要写复杂的程序进行计算,
二.Spark架构
1.spark的体系结构
Spark的体系结构不同于Hadoop的mapreduce 和HDFS ,Spark主要包括spark core和在spark core的基础上建立的应用框架sparkSql spark Streaming MLlib GraphX;
Core库主要包括上下文(spark Context)抽象的数据集(RDD),调度器(Scheduler),洗牌(shuffle) 和序列化器(Seralizer)等。Spark系统中的计算,IO,调度和shuffle等系统的基本功能都在其中
在Core库之上就根据业务需求分为用于交互式查询的SQL、实时流处理Streaming、机器学习Mllib和图计算GraphX四大框架hdfs迄今是不可替代的
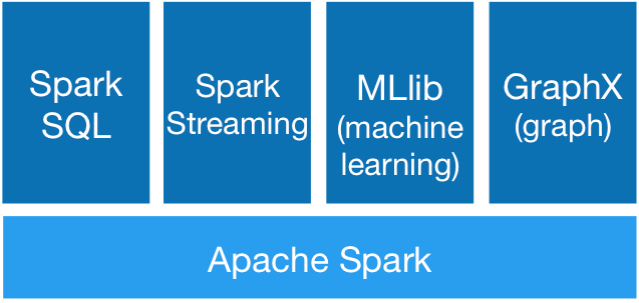
Spark架构组成图

一.Hive和spark对sql支持的对比
Hive创建数据库 创建表 true
|
验证策略 |
脚本 |
Hive |
Spark-sql |
|
创建库 删除库 |
Create database lvhou_hive Create database lvhou_spark Dorp database lvhou_hive Dorp database lvhou_spark |
True |
True |
|
创建表 删除表 |
Use lvhou_hive Create table hive_test(a string,b string) Use lvhou_spark Create table spark_test(a string,b string) Drop table hive_test Drop table spark_test
|
True |
True |
|
CTAS |
Create table lvhou_test as selec * from lvhou_test1;
|
true |
false |
|
Insert
|
Insert into lvhou_hive values(‘hhah’,’heheh’) |
true |
false |
|
insert |
Insert into lvhou_spark value(‘12’.’32’),(‘asd’,’asdf’) |
True |
false |
|
Select |
Select * from lvhou_hive Select * from lvhou_spark |
True |
True
|
|
Select in |
|
|
|
|
|
|
|
|
|
Select子查询 in 两条数据
not in 两条数据 |
select * from test1 where a,b in (select a,b from test2 where a = 'aa');
select * from test1 where a,b not in (select a,b from test2 where a = 'aa');
|
falese |
false |
|
Select union查询 union all |
select * from test union all select * from test0;(合一) select * from test union select * from test0;(去重) |
true |
false |
|
Select union 3查询 union all
|
select * from (select * from test union select * from test0) a;
select a from (select * from test union all select * from test0) a; |
false |
False |
|
Select exit not exit |
select * from test t where exists(select * from test0 t0 where t0.a = t.a); select * from lv_test where exists(select * tfrom test t where lv_test.a = t.a); |
True |
False |
|
update |
update test1 set b = 'abc' where a = 'aa'; update test1 set a = 'abc';
Update test1 set b = 'abc'; |
True |
False |
|
delete |
delete from test1 where a = 'aa'; delete from test1; |
True |
False |
|
TRUNCATE TABLE
|
Truncate table test; |
True |
False |
|
Alter |
alter table test1 add columns (d string); alter table test drop a; alter table test rename a to a1;
|
True |
False |
|
索引 |
create index index_a on table test(a) as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild; |
True |
False |
|
INTERSECT 交集 |
select a from test INTERSECT select a from test0; |
False |
False |
|
EXCEPT
|
select a from test EXCPEPT select a from test0; |
False |
False |
|
Minus 返回第一个结果中不同的 |
select a from test minus select a from test0; |
False |
False |
|
order by 排序 |
select a from test order by a desc;
|
True |
False |
|
sort by 排序 |
select a,b from test sort by b desc; |
True |
False |
|
distribute by
|
select a,b from test distribute by a; |
True |
False |
|
distribute by + sort by |
select a,b from test distribute by a sort by b asc; |
True |
False |
|
cluster by
|
select a,b from test cluster by a;
|
True |
False |
|
trim(string a) 去空格 |
select trim(' aaa ') from test00; |
True |
True
|
|
substr(string A,int start,int len) 截取字符串 |
select substr('abcdefg',3,2) from test;
select substr('abcdefg',-3,2) from test; |
True |
True |
|
like
|
select * from test where a like '%a%'; |
True |
False |
|
Count
|
select count(*) from test00;
select count(distinct *) from test00; |
True |
False |
|
Sum
|
select sum(c) from test00;
select sum(distinct c) from test00; |
True |
False |
|
Avg
|
select avg(c) from test00 select avg(distinct c) from test00 |
True |
False |
|
Min
|
select min(distinct c) from test00; |
True |
False |
|
Max
|
select max(distinct c) from test00; |
True |
False |
|
group by
|
select a from test00 group by a ; select a,sum(c) from test00 group by a; select a,avg(c) from test00 group by a; |
True |
False |
|
Hiving
|
select a,avg(c) as ac from test00 group by a having ac=1; |
True |
False |
|
load |
load data local inpath '/tmp/qichangjian/test01.txt' overwrite into table test_load; |
True |
False |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号