hadoop flume 架构及监控的部署
1 Flume架构解释
Flume概念
Flume是一个分布式 ,可靠的,和高可用的,海量的日志聚合系统
支持在系统中定制各类的数据发送方
用于收集数据
提供简单的数据提取能力
并写入到各种接受方
Flume 特点
1 可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别 的可靠性保障,所有的数据以event为单位传输,从强到弱依次分别为:end-to-end(
收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败, 可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Best effort(数据发送到接收方后,不会进行确认)
2可扩展性
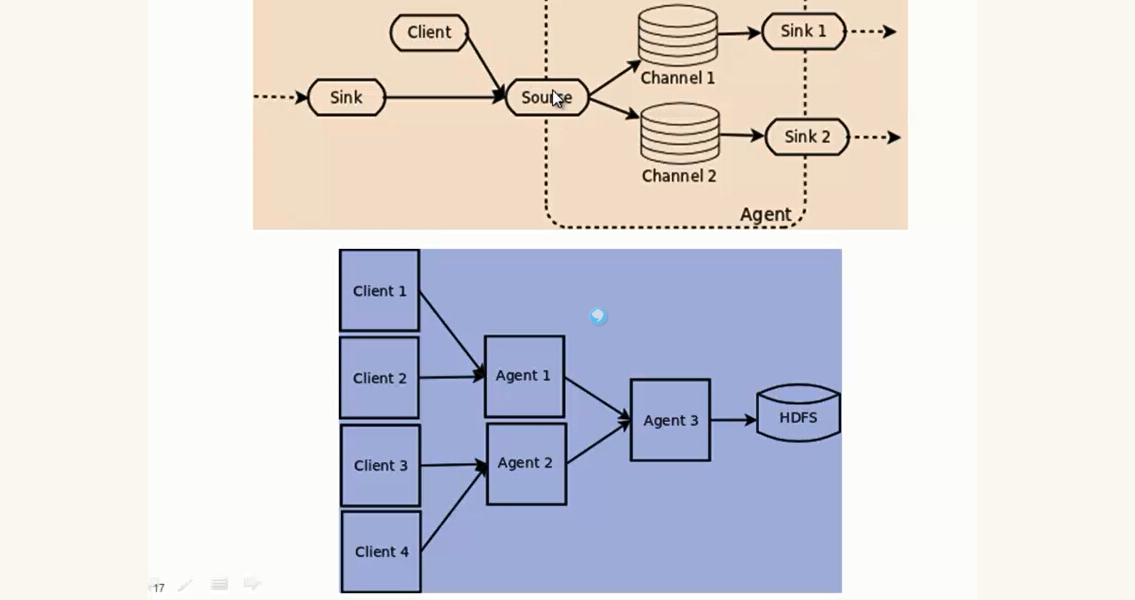
Flume采用了三层架构,分别为agent,collector和storage,每一层均可以水平扩展。其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个(使用ZooKeeper进行管理和负载均衡),这就避免了单点故障问题。
3 可管理性
所有agent和colletor由master统一管理,这使得系统便于维护。多master情况,Flume利用ZooKeeper和gossip,保证动态配置数据的一致性。用户可以在master上查看各个数据源或者数据流执行情况,且可以对各个数据源配置和动态加载。Flume提供了web 和shell script command两种形式对数据流进行管理。
Flume ng 的架构
Flume NG核心概念
Flume的架构主要有一下几个核心概念:
1、Event:一个数据单元,带有一个可选的消息头。
2、Flow:Event从源点到达目的点的迁移的抽象。
3、Client:操作位于源点处的Event,将其发送到Flume Agent。
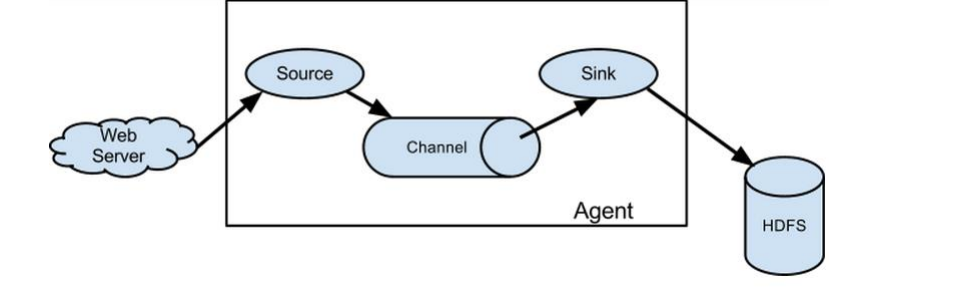
4、Agent:一个独立的Flume进程,包含组件Source、Channel、Sink。
1)、Source:用来消费传递到该组件的Event。
2)、Channel:中转Event的一个临时存储,保存有Source组件传递过来的Event。
3)、Sink:从Channel中读取并移除Event,将Event传递到Flow Pipeline中的下一个Agent(如果有的话)或者数据持久化。
2监控
修改文件
/usr/hdp/2*/flume/config
flume.env文件
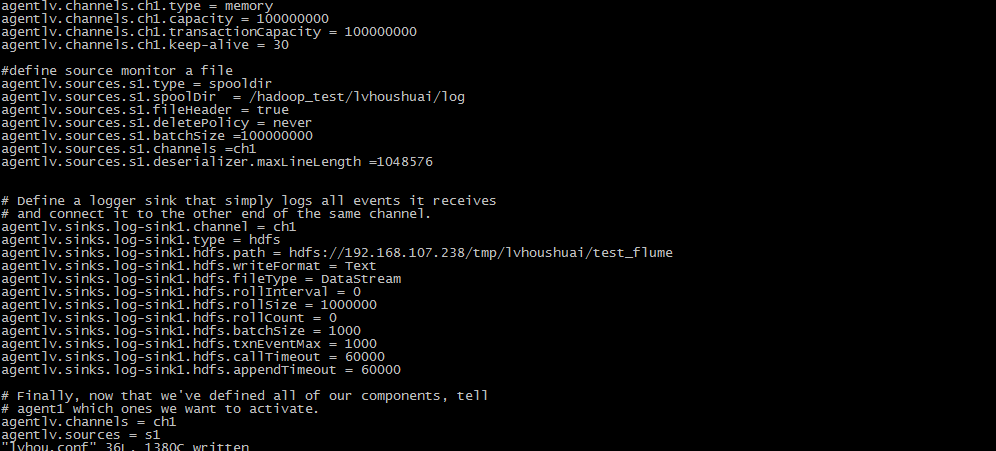
1监控的配置文件
2创建对应的目录及修改权限
Mkdir ****
3启动监控

4向监控目录执行操作



 浙公网安备 33010602011771号
浙公网安备 33010602011771号