给jdk写注释系列之jdk1.6容器(11)-Queue之ArrayDeque源码解析
前面讲了Stack是一种先进后出的数据结构:栈,那么对应的Queue是一种先进先出(First In First Out)的数据结构:队列。
对比一下Stack,Queue是一种先进先出的容器,它有两个口,从一个口放入元素,从另一个口获取元素。如果把栈比作一个木桶,那么队列就是一个管道。
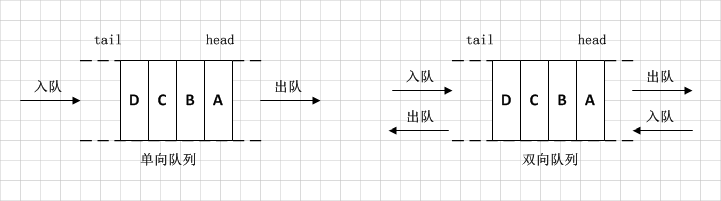
是不是很容易理解,因为队列有两个口,一个负责入队另一个负责出队,所以会有先进先出的效果。
当然我们说ArrayDeque是一个双向队列,队列的两个口都可以入队和出队操作。再进一步说,其实ArrayDeque可以说成是一个双向循环队列,是不是和链表的分类很像,为什么这么说呢,我们下面会具体分析。
1.定义
1 public class ArrayDeque<E> extends AbstractCollection<E> 2 implements Deque<E>, Cloneable, Serializable
从ArrayDeque的定义可以看到,它继承AbstractCollection,实现了Deque,Cloneable,Serializable接口。不知道看到这里你会不会发现什么,Deque接口我们在LinkedList中见过,LinkedList也是实现Deque接口的。我们说过Deque是一个双端队列,它实现于Queue接口,什么是双端队列呢,就是在队列的同一端即可以入队又可以出队,所以Deque即可以作为队列又可以作为栈使用。但是今天这里是讲Queue队列,所以就只看单向队列的一些原理和实现。
来看下Queue接口:
1 public interface Queue<E> extends Collection<E> { 2 // 增加一个元素到队尾,如果队列已满,则抛出一个IIIegaISlabEepeplian异常 3 boolean add(E e); 4 // 添加一个元素到队尾并返回true,如果队列已满,则返回false 5 boolean offer(E e); 6 // 移除并返回队列头部的元素,如果队列为空,则抛出一个NoSuchElementException异常 7 E remove(); 8 // 移除并返问队列头部的元素,如果队列为空,则返回null 9 E poll(); 10 // 返回队列头部的元素,如果队列为空,则抛出一个NoSuchElementException异常 11 E element(); 12 // 返问队列头部的元素,如果队列为空,则返回null 13 E peek(); 14 }
看到Queue的定义,有没有发现它和Stack的方法是非常相似的。
但是ArrayDeque并不是一个固定大小的队列,每次队列满了就会进行扩容,除非扩容至超过int的边界,才会抛出异常。所以这里的add和offer几乎是没有区别的。
2.底层存储
当然从ArrayDeque的命名就可以看出他的底层是用数组实现的(而LinkedList则是用链表实现的队列),来主要看一下ArrayDeque。
1 // 底层用数组存储元素 2 private transient E[] elements; 3 // 队列的头部元素索引(即将pop出的一个) 4 private transient int head; 5 // 队列下一个要添加的元素索引 6 private transient int tail; 7 // 最小的初始化容量大小,需要为2的n次幂 8 private static final int MIN_INITIAL_CAPACITY = 8;
这里需要注意的是MIN_INITIAL_CAPACITY,这个初始化容量必须为2的n次幂。为什么必须要是2的n次幂呢,还记得HashMap中我们的分析吗,HashMap也要求其底层数组的初始容量必须为2的n次幂,还记得当时是基于什么原因吗?不记得话,那就返回去看一下《 给jdk写注释系列之jdk1.6容器(4)-HashMap源码解析》。那么ArrayDeque这里又是基于什么考虑呢,我们下面再看。
而tail不是最后一个元素的索引,是下一个要添加的元素索引,也就是最后一个元素+1。
3.构造方法
1 /** 2 * 默认构造方法,数组的初始容量为16 3 */ 4 public ArrayDeque() { 5 elements = (E[]) new Object[16]; 6 } 7 8 /** 9 * 使用一个指定的初始容量构造一个ArrayDeque 10 */ 11 public ArrayDeque( int numElements) { 12 allocateElements(numElements); 13 } 14 15 /** 16 * 构造一个指定Collection集合参数的ArrayDeque 17 */ 18 public ArrayDeque(Collection<? extends E> c) { 19 allocateElements(c.size()); 20 addAll(c); 21 } 22 23 /** 24 * 分配合适容量大小的数组,确保初始容量是大于指定numElements的最小的2的n次幂 25 */ 26 private void allocateElements(int numElements) { 27 int initialCapacity = MIN_INITIAL_CAPACITY; 28 // 找到大于指定容量的最小的2的n次幂 29 // Find the best power of two to hold elements. 30 // Tests "<=" because arrays aren't kept full. 31 // 如果指定的容量小于初始容量8,则执行一下if中的逻辑操作 32 if (numElements >= initialCapacity) { 33 initialCapacity = numElements; 34 initialCapacity |= (initialCapacity >>> 1); 35 initialCapacity |= (initialCapacity >>> 2); 36 initialCapacity |= (initialCapacity >>> 4); 37 initialCapacity |= (initialCapacity >>> 8); 38 initialCapacity |= (initialCapacity >>> 16); 39 initialCapacity++; 40 41 if (initialCapacity < 0) // Too many elements, must back off 42 initialCapacity >>>= 1; // Good luck allocating 2 ^ 30 elements 43 } 44 elements = (E[]) new Object[initialCapacity]; 45 }
看到这里,我相信很多人又看不懂了(包括我),但是我们可以来仔细分析一下,回想一下我们在HashMap中分析过的,2的n次幂和2的n次幂-1的二进制是什么样子的呢,再来看一下:
2^n转换为二进制是什么样子呢:
2^1 = 10 2^2 = 100 2^3 = 1000 2^n = 1(n个0)
再来看下2^n-1的二进制是什么样子的:
2^1 - 1 = 01 2^2 - 1 = 011 2^3 - 1 = 0111 2^n - 1 = 0(n个1)
看下代码initialCapacity++是什么意思呢,就是说initialCapity+1之后才是2的n次幂,那么此时的initialCapacity是什么呢?就是上面的2^n - 1(initialCapacity + 1 = 2^n),也就是说我怎么做到使initialCapacity为2^n - 1呢,那就上面的4次">>>"和"|"操作了。
">>>"是无符号右移,意思就是将一个操作数转换为二进制后,将后n位移除,高位补0。举个例子:11的二进制1101,11 >>> 2就是:(1)将后两位01移除,(2)高位补0,最后得0011。
"|"是按位或操作,意思是把两个操作数分别转换为二进制,如果两个操作数的位都有1则为1,全为0则为0,举个例子:两个数8和9的二进制分别为1000和1001,1000 | 1001 = 1001。
理解了">>>"和"|"操作后,再来看下上面代码中的4个">>>"和"|"是什么意思,">>>"将一个数低位变为1,"|"后,最后整个数的二进制都变为1。
举个例子:如果initialCapacity=9,9转换为二进制为:1001,那么经过第一轮>>>1后为:100,然后1001 | 100 = 1101;经过第二轮>>>2后变为:0011,然后1101 | 0011 = 1111,1111转换为10进制+1后等于16(2^4),到此经过这一系列的操作就完成获取大于指定容量最小的2的n次幂。如果给定的initialCapacity够大的话,最终将变为1111111111111111111111111111111(31位1),当然最后为了防止溢出(initialCapacity<0),将initialCapacity右移1位变成2的30次方,那么什么时候initialCapacity会小于0呢,那就是当initialCapacity作为int值<<1越界后。
其实在HashMap中也有这么一个目的的操作,只不过其代码不是这么实现的,它是通过一个循环,每次循环只右移1位。来回忆一下:
1 // 确保容量为2的n次幂,是capacity为大于initialCapacity的最小的2的n次幂 2 int capacity = 1; 3 while (capacity < initialCapacity) 4 capacity <<= 1;
那么这两种方法有什么区别呢?HashMap中的这种写法更容量理解,而ArrayDeque中的效果更高(最多经过4次位移和或操作+1次加一操作)。
4.入队(添加元素到队尾)
1 /** 2 * 增加一个元素,如果队列已满,则抛出一个IIIegaISlabEepeplian异常 3 */ 4 public boolean add(E e) { 5 // 调用addLast方法,将元素添加到队尾 6 addLast(e); 7 return true; 8 } 9 10 /** 11 * 添加一个元素 12 */ 13 public boolean offer(E e) { 14 // 调用offerLast方法,将元素添加到队尾 15 return offerLast(e); 16 } 17 18 /** 19 * 在队尾添加一个元素 20 */ 21 public boolean offerLast(E e) { 22 // 调用addLast方法,将元素添加到队尾 23 addLast(e); 24 return true; 25 } 26 27 /** 28 * 将元素添加到队尾 29 */ 30 public void addLast(E e) { 31 // 如果元素为null,咋抛出空指针异常 32 if (e == null) 33 throw new NullPointerException(); 34 // 将元素e放到数组的tail位置 35 elements[tail ] = e; 36 // 判断tail和head是否相等,如果相等则对数组进行扩容 37 if ( (tail = (tail + 1) & ( elements.length - 1)) == head) 38 // 进行两倍扩容 39 doubleCapacity(); 40 }
这里,( (tail = (tail + 1) & ( elements.length - 1)) == head)这句代码是关键,为什么会这样写呢。正常的添加元素后应该是将tail+1对不对,但是队列的删除和添加是不在同一端的,什么意思呢,我们画个图看一下。
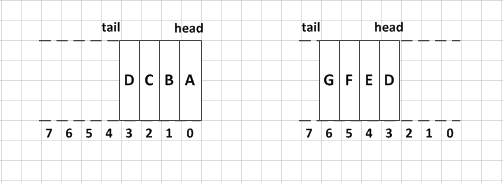
我们假设队列的初始容量是8,初始队列添加了4个元素A、B、C、D,分别在数组0、1、2、3的下标位置,如左图,此时的head对应数组下标0,tail对应数组下标4。当队列经过一系列的入队和出队后,就会变成右图的样子,此时的head对应数组下标3,tail对应数组下标7 。那么问题来了,如果这个时候再增加一个元素到数组下标7的位置,此时理论上tail+1=8,也就是已经越界,需要对数组进行扩容了,但是我们看下数组0、1、2的位置由于出队操作,这三个位置是空的,如果此时就进行扩容会造成空间的浪费。
我们回想一下ArrayList为了减少空间浪费,它是怎么做的呢,是通过数组copy,每次删除元素都会将被删除元素索引后面位置的元素向前移动一位。但是这样做又造成了效率不高。
怎么办呢,能不能换一种思路,我们可以把数组想象成为一个首尾相连的"环",数组的第一个位置索引0的位置和数组的最后一个位置索引length-1的位置是挨在一起的(还记得双向链表吗?)。需要注意的是head不是数组的第一个位置索引0,tail也不是数组的最后一个位置索引length-1,head和tail实际上是一个指针,随着出队和入队操作不断的移动。如果tail移动到length-1之后,如果数组的第一个位置0没有元素,那么需要将tail指向0,依次向后指向。此时当tail如果等于head的时候会有两种情况,一个是空队列,另一个就是队列将要满了(只有tail处还有空位置),只要判断队列将要满了的时候,就进行数组扩容。
再来回忆下2的n次幂和2的n次幂-1转换成二进制后的样子:
2^n转换为二进制是什么样子呢:
2^1 = 10 2^2 = 100 2^3 = 1000 2^n = 1(n个0)
再来看下2^n-1的二进制是什么样子的:
2^1 - 1 = 01 2^2 - 1 = 011 2^3 - 1 = 0111 2^n - 1 = 0(n个1)
会发现什么,如果(2^n) & (2^n-1) = 0对不对,举个例子,2^3=8和2^3 - 1=7,8和7的二进制分别为1000和0111,1000 | 0111 = 0000,也就是0嘛。
现在再来看这段代码( (tail = (tail + 1) & ( elements.length - 1)) == head)是不是开始理解了,(tail + 1) & ( elements.length - 1),当tail等于length-1的时候也就是(2^n) & (2^n-1),此时将结果0赋值给tail,也就是这个时候tail指向了0,印证了前面我们的说法。那么如果tail不是数组的最后一个位置的索引的时候呢,比如tail=5,那么5 & ( elements.length - 1)实际上就等于5对不对,因为tail永远不会大于length的,所以当tail不等于length-1的时候,(tail + 1) & ( elements.length - 1)的结果就是tail+1(我们在HashMap中分析过h & (2^n - 1)就相当于h % 2^n)。
所以从这里看,我们就可以将ArrayDeque看做是一个双向循环队列,之所以这里用"看做"这个词,是因为这里只是代码逻辑上"环",而非存储结构上的"环"。
至此,我们终于明白( (tail = (tail + 1) & ( elements.length - 1)) == head) 这句代码的意义,我们再来总结下这句代码的效果:(1)将tail+1操作,(2)如果tail+1已经越界,则将tail赋值为0,(3)当tail和head指向同一个索引时,则说明需要进行扩容。既然是需要扩容,那么我们就来看看具体是怎么扩容的吧。
1 /** 2 * 数组将要满了的时候(tail==head)将,数组进行2倍扩容 3 */ 4 private void doubleCapacity() { 5 // 验证head和tail是否相等 6 assert head == tail; 7 int p = head ; 8 // 记录数组的长度 9 int n = elements .length; 10 // 计算head后面的元素个数,这里没有采用jdk中自带的英文注释right,是因为所谓队列的上下左右,只是我们看的方位不同而已,如果上面画的图,这里就应该是left而非right 11 int r = n - p; // number of elements to the right of p 12 // 将数组长度扩大2倍 13 int newCapacity = n << 1; 14 // 如果此时长度小于0,则抛出IllegalStateException异常,什么时候newCapacity会小于0呢,前面我们说过了int值<<1越界 15 if (newCapacity < 0) 16 throw new IllegalStateException( "Sorry, deque too big" ); 17 // 创建一个长度是原数组大小2倍的新数组 18 Object[] a = new Object[newCapacity]; 19 // 将原数组head后的元素都拷贝值新数组 20 System. arraycopy(elements, p, a, 0, r); 21 // 将原数组head前的元素都拷贝到新数组 22 System. arraycopy(elements, 0, a, r, p); 23 // 将新数组赋值给elements 24 elements = (E[])a; 25 // 重置head为数组的第一个位置索引0 26 head = 0; 27 // 重置tail为数组的最后一个位置索引+1((length - 1) + 1) 28 tail = n; 29 }
这里需要清除,为什么要进行两次数组copy,当然是因为数组被head分成了两段。。。后面有元素,前面也有元素。。。
5.出队(移除并返回队头元素)
1 /** 2 * 移除并返回队列头部的元素,如果队列为空,则抛出一个NoSuchElementException异常 3 */ 4 public E remove() { 5 // 调用removeFirst方法,移除队头的元素 6 return removeFirst(); 7 } 8 9 /** 10 * @throws NoSuchElementException {@inheritDoc} 11 */ 12 public E removeFirst() { 13 // 调用pollFirst方法,移除并返回队头的元素 14 E x = pollFirst(); 15 // 如果队列为空,则抛出NoSuchElementException异常 16 if (x == null) 17 throw new NoSuchElementException(); 18 return x; 19 } 20 21 /** 22 * 移除并返问队列头部的元素,如果队列为空,则返回null 23 */ 24 public E poll() { 25 // 调用pollFirst方法,移除并返回队头的元素 26 return pollFirst(); 27 } 28 29 public E pollFirst() { 30 int h = head ; 31 // 取出数组队头位置的元素 32 E result = elements[h]; // Element is null if deque empty 33 // 如果数组队头位置没有元素,则返回null值 34 if (result == null) 35 return null; 36 // 将数组队头位置置空,也就是删除元素 37 elements[h] = null; // Must null out slot 38 // 将head指针往前移动一个位置 39 head = (h + 1) & (elements .length - 1); 40 // 将队头元素返回 41 return result; 42 }
pollFirst中的 (h + 1) & (elements . length - 1)相比已经不用再具体解释了吧,不懂的看看上面的解释吧,当然这是为了处理临界的情况。
6.返回队头元素(不删除)
1 /** 2 * 返回队列头部的元素,如果队列为空,则抛出一个NoSuchElementException异常 3 */ 4 public E element() { 5 // 调用getFirst方法,获取队头的元素 6 return getFirst(); 7 } 8 9 /** 10 * @throws NoSuchElementException {@inheritDoc} 11 */ 12 public E getFirst() { 13 // 取得数组head位置的元素 14 E x = elements[head ]; 15 // 如果数组head位置的元素为null,则抛出异常 16 if (x == null) 17 throw new NoSuchElementException(); 18 return x; 19 } 20 21 /** 22 * 返回队列头部的元素,如果队列为空,则返回null 23 */ 24 public E peek() { 25 // 调用peekFirst方法,获取队头的元素 26 return peekFirst(); 27 } 28 29 public E peekFirst() { 30 // 取得数组head位置的元素并返回 31 return elements [head]; // elements[head] is null if deque empty 32 }
到此,ArrayDeque作为Queue的操作方法,我们就分析完了,主要的难点则在于要把ArrayDeque看成一个双向循环队列,head和tail指针是如何移动的,又是如果做到"环"的,如果还不是很明白一定要对照图解多看几遍,并动手做一下位移和或操作。
当然ArrayDeque作为一个双向队列还有一些Deque特有的方法,以及作为Stack的一些方法,这里我们就不多看了,有兴趣的话,可以自己尝试着分析下,由于底层是数组,其他一些操作理解起来还是很简单的,不太懂的可以去回忆下《 给jdk写注释系列之jdk1.6容器(1)-ArrayList源码解析》。
当然我们说的ArrayDeque和LinkedList都是简单队列(既非线程安全,又非阻塞),在java的并发包java.util.concurrent包中还有两种队列,并发队列ConcurrentLinkedQueue和阻塞队列BlockingQueue。这两种我们在今后分析java并发包的时候会仔细进行分析。
Queue之ArrayDeque 完!
参见:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号