CS231n Lecture2-Image Classification学习笔记
一、Image Classification
Challenges
- 原始图像表示是三维亮度值数组
- Viewpoint variation(角度变化)
- Scale variation(尺寸变化)
- Deformation(变形)
- Occlusion(遮挡)
- Illumination condition(光照条件)
- Background clutter(背景干扰)
- Intra-class variation(内部同类变化)

Data-driven approach
- 这里提到的是依靠数据驱动的方法,这并不是直接创造一个算法不需要数据集,直接可以分类,而是基于训练的数据集,我们输入包含很多图片的各种类别的数据集,然后学习其中的相关性,编程一个分类器,最后要评估,就把要测试的数据送进分类器,输出类别。
二、K-nearest neighbor
1. Nearest Neighbor Classifier简介
-
不像CNN(卷积神经网络),它是不需要训练的,而是直接基于数据集,进行分类的一个算法,所以预测的时候花费的时间比较长。
-
原理: 根据要预测的数据,直接与数据集所有的样本进行比较,然后选出最相似的样本,该样本的label即为预测的label。而评估它们相似的指标分为两种,这里一种是L1 distance, 即曼哈顿距离,这里应用直接是矩阵向量对应位置上元素相减。还有一种是L2 distance,即欧式距离 对应属性上相减后平方再求和最后,开根号。
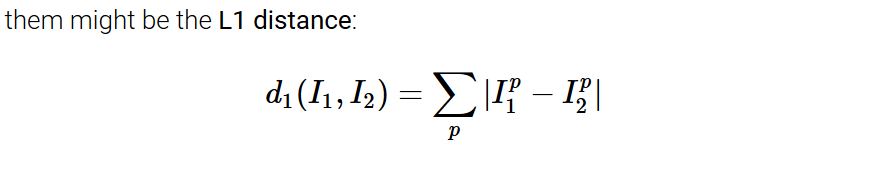
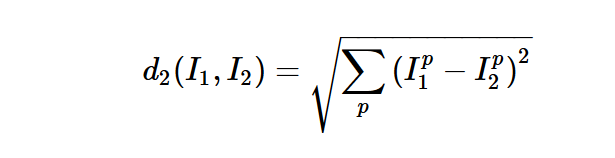
-
L1 VS. L2: 如何选择这两种距离作为评价指标?L2 distance 是更适用于中等变化的,可以说是更加的敏感对于数据的变化。
2. K-nearest Neighbor Classifier
- 在最邻近算法的基础上稍加修改,不再是在数据集中寻找最相似的那个样本,而是选择最相似的K个样本,然后看这K个样本的标签总数最多的那个,就代表预测的结果。

3. How to deal with Dataset
- train set、validation set、test set区别: 训练集是前期用于模型训练的数据,决定着模型的基本基调,而验证集严格意义上来讲也是训练集的一部分,因为是在训练集上划分出一小部分(一般的10%-30%),这部分前期不参与训练的过程,然后最后等训练结束后,用于模型调优,进行训练查看模型的好坏。至于测试集,是严格意义上不能用于训练的,只能用于评估模型的准确率。也就是最后的时刻才能够使用。如果用于训练,会overfit,也就是过拟合,泛化能力降低。
- Cross-validation: 当出现数据集比较小的时候,会使用一种超参数调整方法,即交叉验证,把训练集划分为K等分,然后迭代K次进行验证,求平均看模型的效果。但是一般会避免,缺点就是计算花费较大。

4. Pros and Cons of Nearest Neighbor classifier
- 优点: 简单,容易操作实现,不需要训练时间
- 缺点: 需要花费很多的计算资源,测试时间较长。
- 适用: 最近邻分类器,适用于处理低维的数据。对于多维数据不适合,像图片的处理分类。
5. Applying KNN in Practice
- 数据预处理,针对于数据特征归一化
- 如果数据是高维数据,可以考虑降维(PCA)
- 划分随机训练集,一般70~90%用于训练,其余用于验证集。这一部分取决于有多少超参数,如果超参数很多,验证集划分应该要大些。甚至可以使用交叉验证。
- 选择合适的K和distance type
三、Linear Classification
1.Introduction
- 线性分类器有两个主要的组成部分,一个是score function,用于匹配原始数据的分数,另一个是loss function,用于确保预测的分数结果与真实标签一致。
- 不在像原来的KNN,这里是通过score function把数据的有用信息保存下来,存储于参数中,这样在预测的时候,不在需要原来的数据集了,直接可以用于预测,这样就解决了KNN,实时处理需要消耗巨大计算资源的问题。
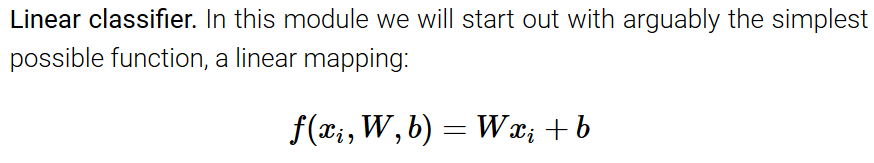
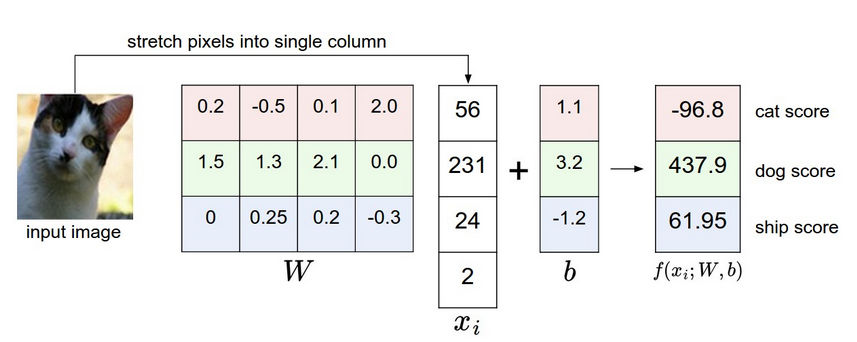
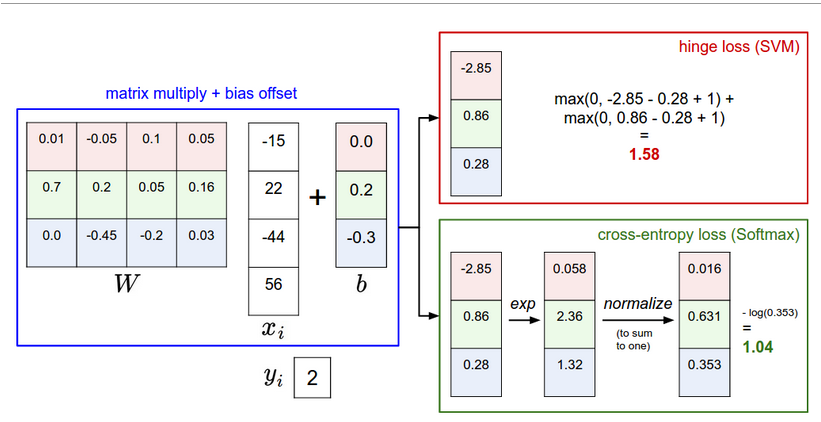
2. Interpret a linear classifier
-
有权重W和偏量b,本质W是一个矩阵,每一行对应着一个类别,有多少行就有多少类别,然后对于输入数据,一般拉成一行向量vector,最后使用内积或点积,再加上偏量,输出每个类别的分数。
-
也有一个小技巧,就是把偏量b,放到输入的数据中,也就是vector多加一个元素1,然后权重的矩阵多加一列。这样处理就变成了一个Matrix操作即可。

-
图片的预处理,也就会把所有数据减去数据的均值,用于集中数据center your data。
-
内积(inner product)和点积(dot product)是一个意思,就是矩阵乘法相当于。不是乘积,乘积是对应元素直接相乘。
3. Loss function
-
Multiclass Support Vector Machine(SVM), 实际是使用Max(0, ~),查看真实样本分数与其他的分数差固定在0 ~ delta内,设置一个固定的delt。损失函数通过对训练集的预测来量化我们的误差。
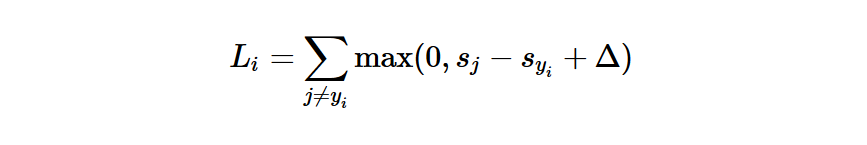
-
Regularization,注意,正则化函数不是数据的函数,它只是基于权值,我们发现在支持向量机中包含L2惩罚会导致有效的最大保证边界性。
-
我们现在要做的就是找出使损失最小化的权重。
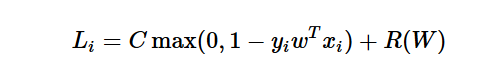

4. Practical Considerations
-
Setting Delta, 设置delta = 1.0 可以在任何情况下使用。然后正则化系数关乎的是正则化损失,也就是对权值W的影响,还有一个参数是关乎数据损失的,他们两个参数存着这权衡。

-
Relation to Binary Support Vector Machine, 这是存在二分类问题上,也就是只有两类类别。
5. Softmax classifier
-
loss function,和前面的SVM的学习使一样的,但是损失函数有所不同,把原来的hinge loss换成了cross-entropy loss,即交叉熵损失函数。
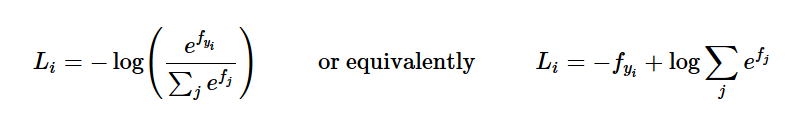
-
SVM vs. Softmax, 本质上讲是因为损失函数的不同导致了两者的不同,SVM计算出来的是每个目标的分数,支持向量机不关心局部特征,不关心每个目标的得分细节,但是Softmax计算出来的是每个类别的概率。