data100(fa20) Lab 4 note
Lab 4 note
Question1
1a
为了了解每个“进攻”有多少个子类别,将calls_by_cvlegend_and_offense设置为一个多索引序列,其中数据首先在CVLEGEND上索引,然后在OFFENSE上索引,数据等于数据库中匹配各自的CVLEGEND和OFFENSE的进攻次数。例如,calls_by_cvlegend_and_offense["LARCENY", "THEFT FROM PERSON"]应该返回24。
这题我一开始想用数据透视表,但这样的结果会是一个DataFrame,不符合题目要求。
题目要求多层索引,应该是一种类似树的结构,使用数据透视表将会出现大量 NA 值。
结合所学,如下图所示,这里可以用groupby。

思路:先用CVLEGEND对数据进行分组,然后选取OFFENSE得到子Series,接着使用value_counts()进行统计。
代码:
calls_by_cvlegend_and_offense = calls.groupby(['CVLEGEND'])['OFFENSE'].value_counts()
calls_by_cvlegend_and_offense
Question 1b
在下面的单元格中,将answer1b设置为一个字符串列表,该列表对应于OFFENSE在CVLEGEND为LARCENY时的可能值。您可以手动输入答案,也可以创建一个自动提取名称的表达式。
answer1b = list(calls_by_cvlegend_and_offense["LARCENY"].index)
answer1b
Question 2
CVLEGEND中有最多犯罪事件的五种犯罪类型是什么?你可能需要使用value_counts来找到答案。将结果保存到' answer2 '中,作为一个字符串列表。提示:Series类的keys方法可能有用。
answer2 = list(calls["CVLEGEND"].value_counts()[:5].keys())
answer2
Question 3
Question 3a
在calls dataframe中添加一个新的列Day,该列包含字符串weekday(例如。'Sunday')在CVDOW中获取相应的值。例如,如果CVDOW的前3个值是[3,6,0],那么Day列的前3个值应该是["Wednesday", "Saturday", "Sunday"]。提示: 尝试在calls["CVDOW"]上使用Series.map函数。你能把它分配给新列calls["Day"]吗?
关键就是使用map函数。
days = ["Sunday", "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday"]
day_indices = range(7)
indices_to_days_dict = dict(zip(day_indices, days)) # Should look like {0:"Sunday", 1:"Monday", ..., 6:"Saturday"}
calls["Day"] = calls["CVDOW"].map(indices_to_days_dict)
calls.head()
Question 3b
现在让我们看看EVENTTM列,它指示事件的时间。由于它包含小时和分钟信息,让我们提取小时信息,并在“calls”数据框架中创建一个名为“hour”的新列。你应该用“int”来节省时间。
提示: 您的代码应该只需要一行
这题我一开始看漏了题目,用了calls["EVENTTM"].str.slice(start=0, stop=2),得到的是字符串,尽管可以转为int,但是肯定不优雅。
正确做法是利用panda处理日期。
calls['Hour'] = pd.to_datetime(calls["EVENTTM"]).dt.hour
calls.head()
Question 3c
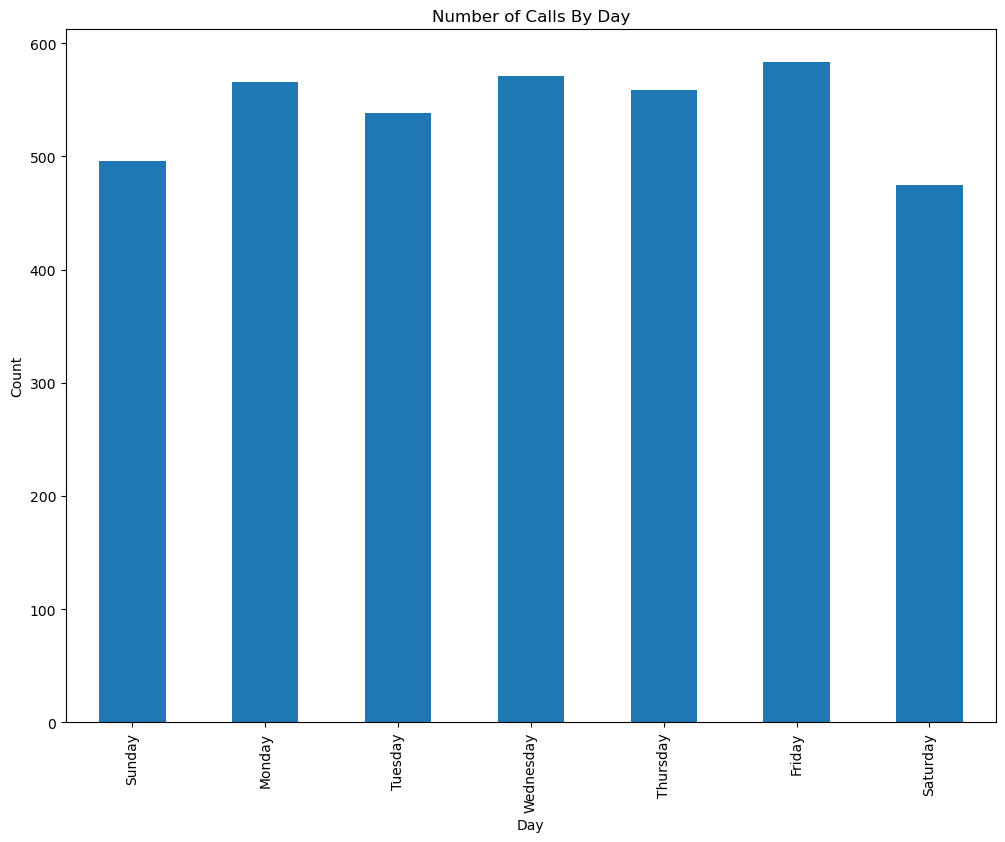
使用pandas,构建一个垂直条形图,其中包含按一周中的星期几排序的一周中每天的调用次数(表中的条目)。' Sunday ', ' Monday ',…)。请确保你的坐标轴被标记了,并且你的绘图被命名了。每天应该有大约500个电话。
这里可以用列表作为索引处理条形图横轴的显示顺序。然后模仿文档开头的例子即可。
coolIndex = days
# draw the bar plot
ax = calls.groupby("Day")["CASENO"].agg(lambda x: x.shape[0])[coolIndex].plot(kind='bar')
ax.set_ylabel("Count")
ax.set_xlabel("Day")
ax.set_title("Number of Calls By Day");
# Leave this for grading purposes
ax_3c = plt.gca()
Question 3d
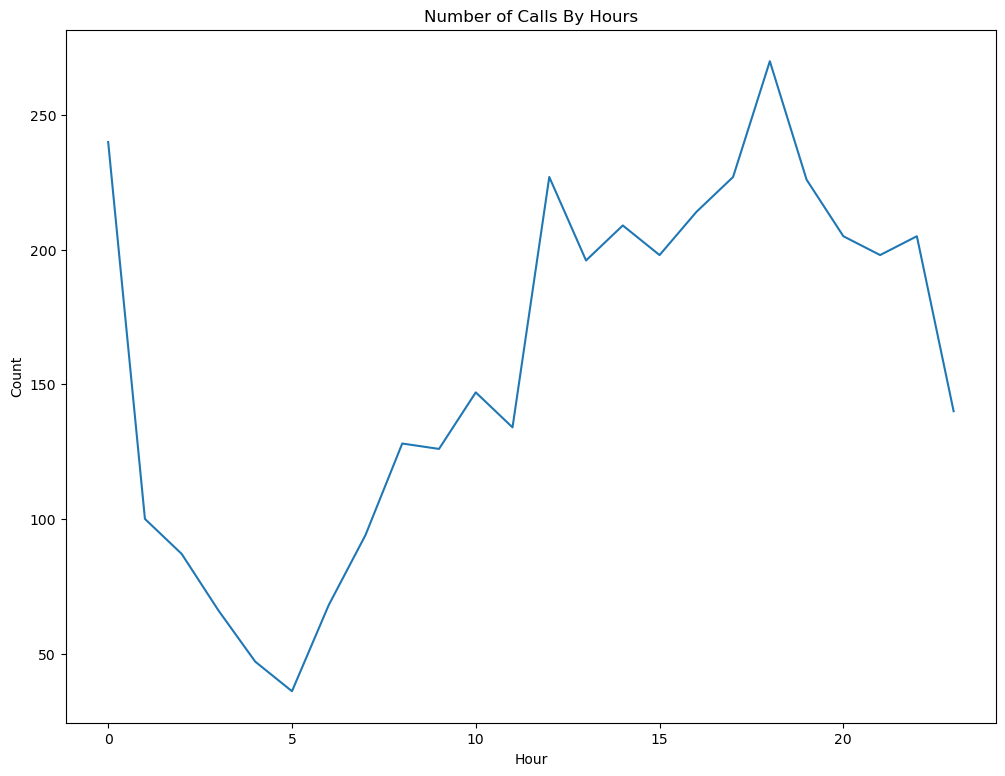
使用pandas,构建一个折线图,其中包含一天中按时间排序的每个小时的调用次数(表中的条目)。请在您的回答中使用提供的变量“小时”。请确保你的坐标轴被标记了,并且你的绘图被命名了。
hours = list(range(24))
ax = calls.groupby("Hour")['CASENO'].count()[hours].plot(kind="line")
ax.set_ylabel("Count")
ax.set_xlabel("Hour")
ax.set_title("Number of Calls By Hours");
# Leave this for grading purposes
ax_3d = plt.gca()
Question 4
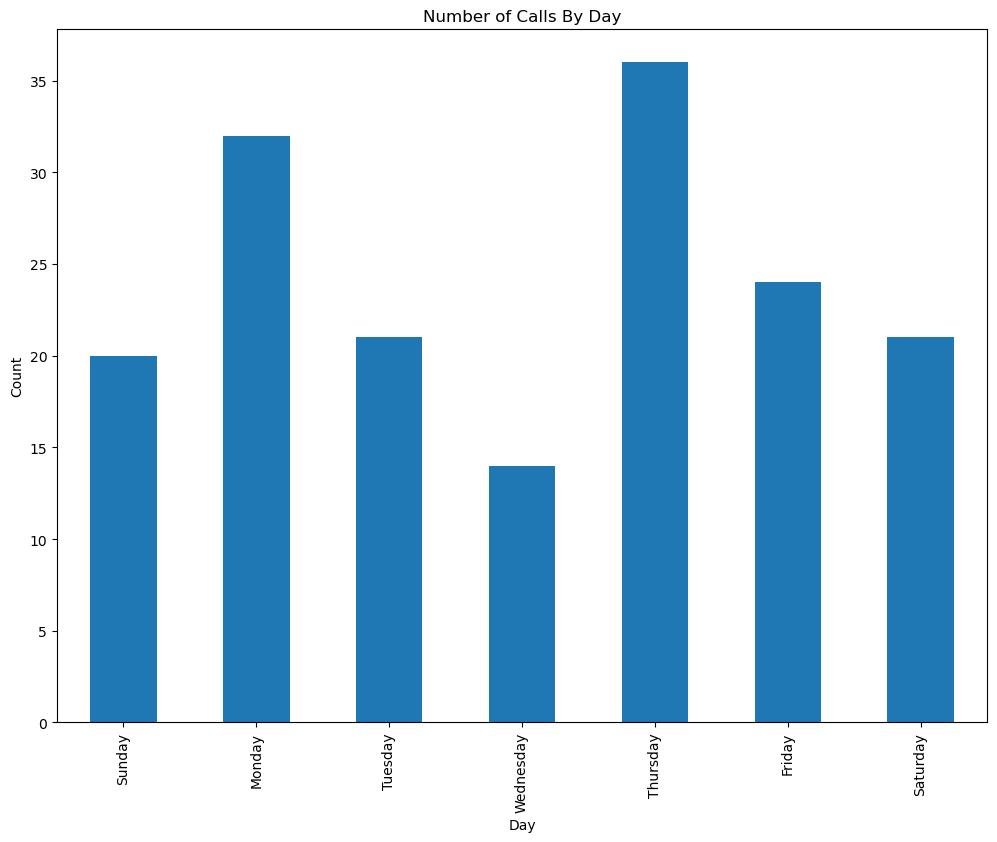
使用pandas创建一个垂直条形图,显示一周中每天报告的抢劫案总数,同样是从周日开始按天数排序。请在回答中使用提供的变量filtered。
Hint: This should be very similar to Question 3b
类似 Question1 使用group搭配函数。
filtered = calls[calls["CVLEGEND"] == "ROBBERY"]
ax = filtered.groupby("Day")["CASENO"].count()[days].plot(kind="bar")
ax.set_ylabel("Count")
ax.set_xlabel("Day")
ax.set_title("Number of Calls By Day");
# Leave this for grading purposes
ax_4a = plt.gca()
Question 5
在下面的单元格中,生成一个箱线图,以CVLEGEND值分解每个犯罪事件的小时数。要构建此图,请使用DataFrame的箱线图文档。为了更好的可读性,你可能需要旋转CVLEGEND标签。
看看你的图表,哪一种犯罪类型的四分位数范围最大?将结果以字符串形式输入到answer5中。
学习文档中的示范代码:
df = pd.DataFrame(np.random.randn(10, 2),
columns=['Col1', 'Col2'])
df['X'] = pd.Series(['A', 'A', 'A', 'A', 'A',
'B', 'B', 'B', 'B', 'B'])
boxplot = df.boxplot(by='X')
得到类似的画法:
calls.boxplot(column="Hour", by="CVLEGEND", rot= 80);
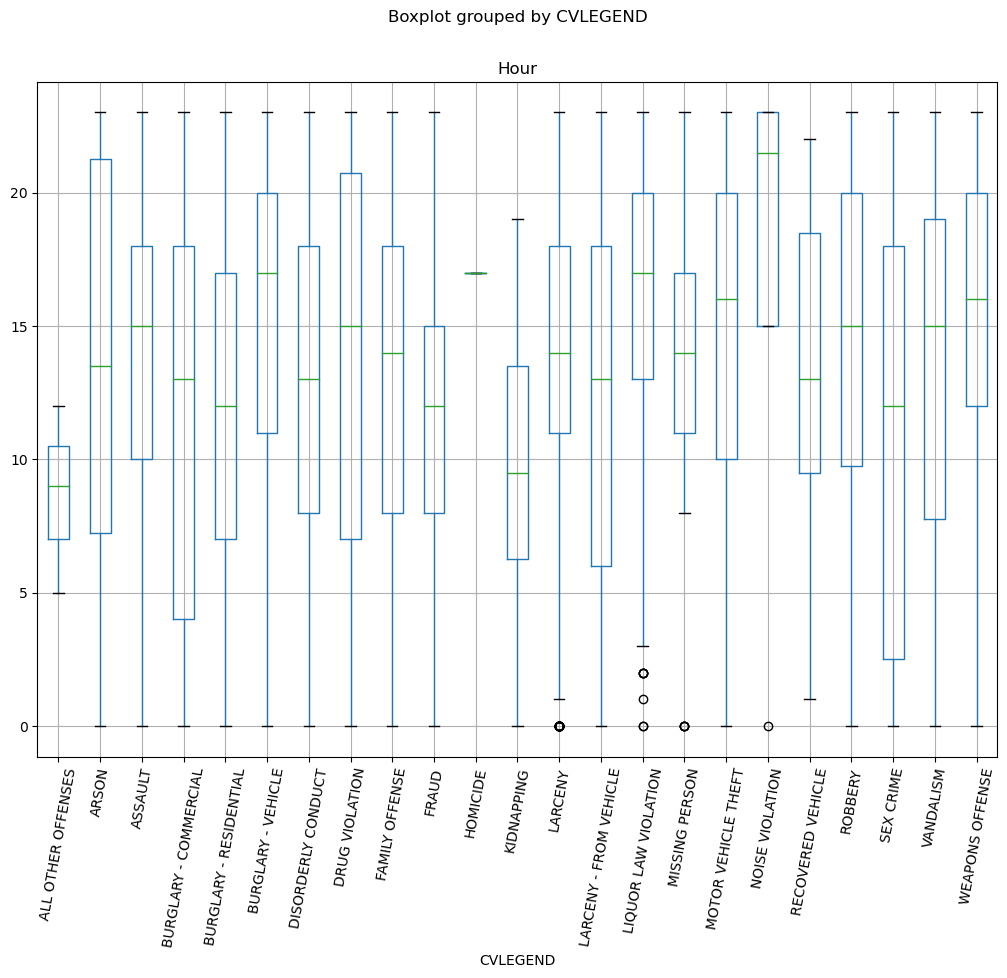
这里有些瑕疵,由于字符串长度比较长,使用rot参数时,可能会出现错位。
四分位即箱子的长度,可以大概看出答案是"SEX CRIME"
总结
在本 lab 中,主要练习的一下两个方面:
- 使用 panda 进行数据筛选,重组使之易于分析。
- 运用了 groupby, map, value_counts 等方法。
- 根据数据绘制图像进行分析
- 运用柱形图,折线图,箱型图等对数据的分布进行分析。
Tips
Plot 的使用方法
ax = calls['CVLEGEND'].value_counts().plot(kind='barh')
ax.set_ylabel("Crime Category")
ax.set_xlabel("Number of Calls")
ax.set_title("Number of Calls By Crime Type");
ax2 = plt.gca()
检查数据是否符合预期(发生在伯克利)
在查看字段的含义之前,下面的单元格将通过对City和State列进行分组来验证所有发生在Berkeley的事件。您应该看到,我们的所有数据都属于一个组。
calls.groupby(["City","State"]).count()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号