XCTF - Reverse 全关卡笔记
XCTF - Reverse
TODO: 补挂掉的图片
参考:
XCTF—WriteUp
对LOWORD, HIWORD, LOBYTE, HIBYTE的理解
C++ 学习——char * ,char a[ ],char ** ,char *a[] 的区别
第一题:simple-unpack
0x01.查壳和程序的详细信息
照着套路扔到PEID中查看信息
无果,想起可能是linux的ELF可执行文件,扔到exeinfo中,

发现有upx壳。
注:windows下的文件是PE文件,Linux/Unix下的文件是ELF文件
0x02.UPX 脱壳

upx -d 即可对upx壳进行脱壳
0x03.载入IDA

还是从main函数开始分析,结果我们再右侧发现了意外惊喜
运行程序,输入我们看到的flag:flag{Upx_1s_n0t_a_d3liv3r_c0mp4ny}

本writeup参考来自:吉林省信睿网络,https://blog.csdn.net/xiao__1bai/article/details/119395006
第二题: logmein
0x01.查壳和查看程序的详细信息

发现程序是一个ELF文件,将其放入Linux环境中进行分析

发现程序是64位的,使用静态分析工具IDA进行分析
0x02.IDA

从main函数开始分析,使用F5查看伪代码

发现main函数的整个运算逻辑
先是,将指定字符串复制到v8
s是用户输入的字符串,先进行比较长度,如果长度比v8小,则进入sub_4007c0函数

可以看出输出字符串Incorrect password,然后,退出
如果长度大于或等与v8则进入下面的循环
看到判断如果输入的字符串和经过运算后的后字符串不等,则进入sub_4007c0,输出Incorrect password,
如果想得,则进入sub_4007f0函数

证明输入的字符串就是flag
接下来写脚本
0x03.Write EXP
我们的目标是计算
v8 = ":\"AL_RT^L*.?+6/46";
v7 = 28537194573619560LL;
v6 = 7;
for ( i = 0; i < strlen(s); ++i )
{
s[i] = (char)(*((_BYTE *)&v7 + i % v6) ^ v8[i]) )
}
首先要理解这个表达式:
(_BYTE *)&v7是字节型指针,其中BYTE可以理解为unsigned char, 一个字节存储8位无符号数,储存的数值范围为0-255。而一开始v7是一个long long 类型的整数,因此这里需要将其转换为字符串。(_BYTE *)&v7相当于将v7转化为字符数组(串)的首元素的地址,str_v7[0]。
然后(_BYTE *)&v7 + i % v6 // v6 = 7,i = 0,1,...则依次代表v7的前v6个元素的地址,自然*((_BYTE *)&v7 + i % v6)就代表循环遍历字符数组v7的前v6个元素,也就是str_v7[i % v6]。
然后的异或,转换类型,应该不必多说,只是需要注意不同环境下实现方式的不同。
接下来将详细探讨如何将long long 型v7转化为字符串
方法一:手动转换
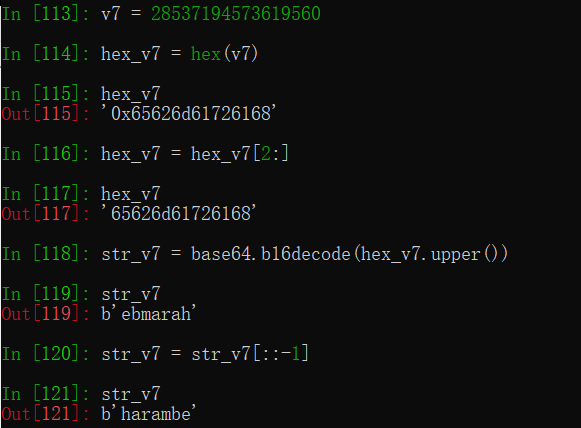
方法二:010editior
先将v7转换为16进制,然后在010editior里按CTRL + shift + v,然后再想办法翻转
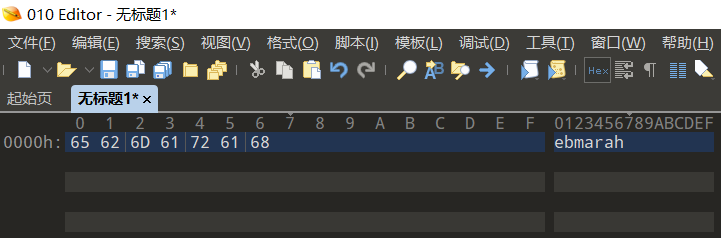
为什么要翻转呢?
先将v7的值转化为16进制。v7=0x65626d61726168。

如图所示,x86架构,v7在栈中是小端存储,即字节序是little-endian,所以v7的高位数据放在高址,低位数组放在低址。
最后是将计算开始那个表示式
方法一:利用python
v6 = 7
v7 = "harambe"
v8 = ":\"AL_RT^L*.?+6/46"
for i in range(len(v8)):
x = chr(ord(v7[i % v6]) ^ ord(v8[i]))
print(x, end = '')
# ord():是将字符串转换为ascii格式,为了方便运算
# chr():是将ascii转换为字符串
方法二:利用C语言(最优雅,简单,甚至不用管v7的字符串是什么)
#include<stdio.h>
#include<string.h>
#include<windows.h> //这头文件和(BYTE*)是第一次见,学着吧
const char v8[] = ":\"AL_RT^L*.?+6/46";
const long long int v6 = 7;
// 注意由于v6和v7要一起进行运算,因此v6也得开long long
const long long v7 = 0x65626D61726168LL;
int main(void){
for(int i = 0; i < strlen(v8); i ++ ){
char x = (char)(*((BYTE *)&v7 + i % v6) ^ v8[i]);
printf("%c", x);
}
return 0;
}
参考文章:
https://blog.csdn.net/qq_43394612/article/details/84839170
XCTF - Writeup
第三题:insanity
思路一:
IDA后shift + F12
思路二:
查看伪代码,发现是先设置随机数再输出strs里面的一个字符串,于是可以双击strs看看里面都有什么

第四题:getit
0x01.查壳
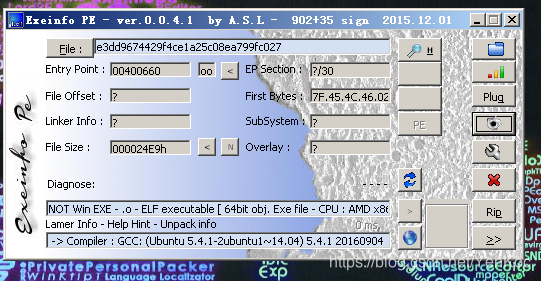
是linux的文件。没加壳
0x02.拖入ida
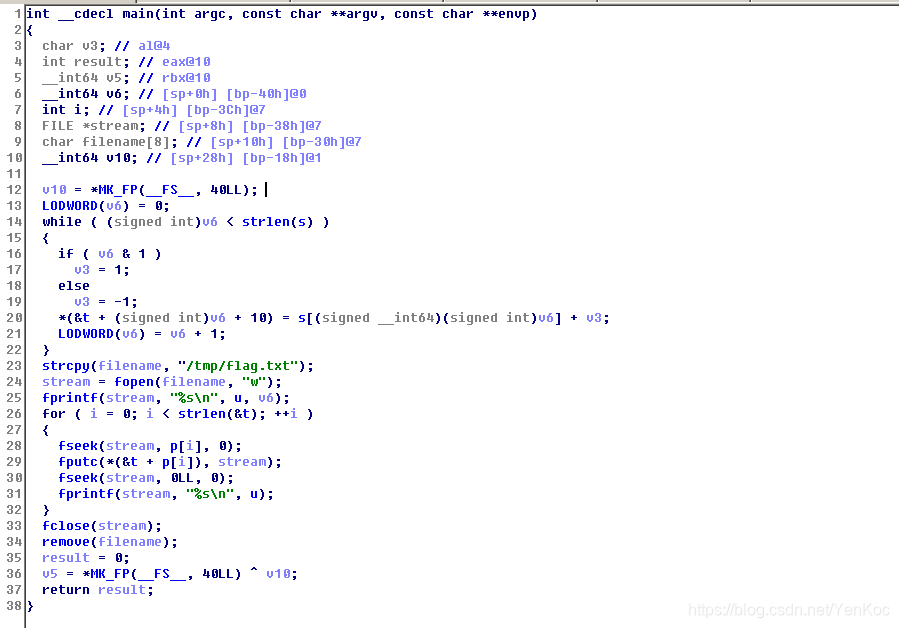
中间对部分生成了一个字符串,然后将它写入文件中,经过四个f函数,最后又把文件删掉了,因此我们什么都看不到。
百度可知,那几个f函数的作用是把原来的数据覆盖掉。
思路一:在四个f函数之前设置断点,查看相关数据。
0x03:GDB:我们这时候通过IDA查看汇编代码

然后我们向下追踪,追踪到for循环的位置,因为,flag是在这里存入文件的,所以,我们可以在内存中找到正要存储的字符串

我们将鼠标指向strlen(),在下面可以看到汇编所在的地址,然后我们根据大概的地址去看汇编代码

可以看到这是调用strlen()函数的汇编指令
我们通过上一个图片,可以知道经过for()的判断条件后,还要进行一步fseek函数,所以,根据汇编代码,可以确定jnb loc_4008B5就是fseek()函数,那么,mov eax,[rbp+var_3C]肯定就是最后要得到的flag了
0x04.GDB:这里我们用linux下的动态调试工具gdb进行动态调试
这里介绍一下,对gdb进行强化的两个工具peda和pwndbg,这两个工具可以强化视觉效果,可以更加清楚的显示堆栈,内存,寄存机的情况
先加载程序

然后,用b 下断点

然后,运行 R

这里我们可以看出,程序停止在0x400832的位置,然后,要被移动的字符串在RDX的位置
注:
这里介绍一下一下RDX,RDX存的是i/0指针,0x6010e0,这个位置存的字符串是最后的flag:SharifCTF{b70c59275fcfa8aebf2d5911223c6589}
以为这里涉及的是程序读写函数,所以涉及的就是i/o指针
另外也可以就直接在strlen处设置断掉,效果如下:
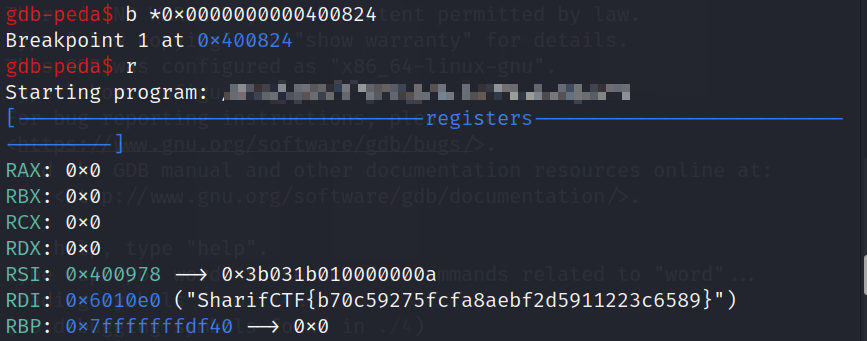
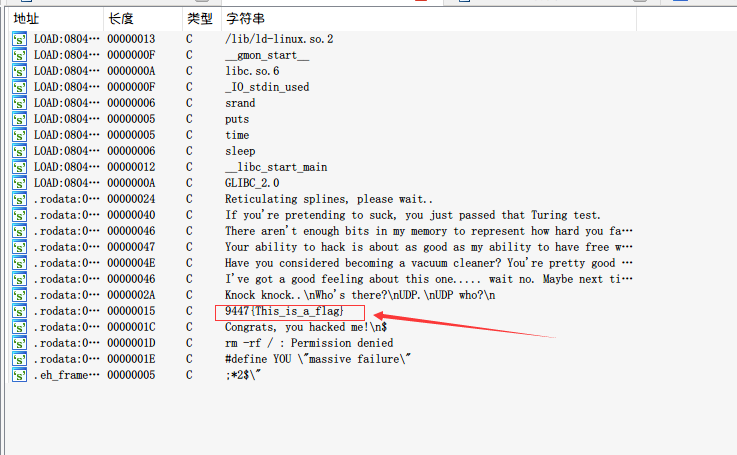
所以我们能得到最后的flag: SharifCTF{b70c59275fcfa8aebf2d5911223c6589}
本writeup参考来自:吉林省信睿网络
思路二:用代码实现伪代码中的生成字符串的功能
#include<stdio.h>
int main(void)
{
char s[] = "c61b68366edeb7bdce3c6820314b7498";
int v6 = 0;
while ( v6 < strlen(s) )
{
int v3;
if ( v6 & 1 )
v3 = 1;
else
v3 = -1;
char x = s[v6] + v3;
v6 ++ ;
printf("%c", x);
}
return 0;
}
结果为:b70c59275fcfa8aebf2d5911223c6589
然后再和SharifCTF{}进行拼接
(这是在IDA中,通过shift + F12发现的)。
值得注意的是 t 中存放的是harictf{??????????????????}. 开始t字符串初始化是'0x53',即S,可能有某种奇怪的规则吧。
第五题:python-trade
0x01.下载附件

注:
python文件在被import运行的时候会在同目录下编译一个pyc的文件(为了下次快速加载),这个文件可以和py文件一样使用,但无法阅读和修改;python工具支持将pyc文件反编译为py文件(可能会存在部分文件无法反编译)。
支持的python版本:1.0、 1.1、 1.3、 1.4、 1.5、 1.6、 2.0、 2.1、 2.2、 2.3、 2.4、 2.5、 2.6、 2.7、 3.0、 3.1、 3.2、 3.3、 3.4、 3.5、 3.6、 3.7、 3.8、 3.9、 3.10。
0x02.在线Python反编译
#!/usr/bin/env python
# visit https://tool.lu/pyc/ for more information
# Version: Python 2.7
import base64
def encode(message):
s = ""
for i in message:
x = ord(i) ^ 32
x = x + 16
s += chr(x)
return base64.b64encode(s)
correct = "XlNkVmtUI1MgXWBZXCFeKY+AaXNt"
flag = ""
print "Input flag:"
flag = raw_input()
if encode(flag) == correct:
print "correct"
else:
print "wrong"
这是生成的py文件
然后,对这个文件的运算逻辑进行逆向
0x03.写EXP
#!/usr/bin/env python
import base64
ori = "XlNkVmtUI1MgXWBZXCFeKY+AaXNt"
ori = base64.b64decode(ori)
ans = ""
for i in ori:
ans += chr((ord(i) - 16) ^ 32)
print(ans)
先对字符串进行b64decode,然后,再进行xor运算得到最后的flag:nctf{d3c0mpil1n9_PyC}
本writeup参考来自:吉林省信睿网络
第六题:re1
思路一:IDA静态分析
IDA F5查看伪代码

这是整个main函数的运算逻辑
可以看到一个关键的字符串,print(aFlag),那么证明这就是输入正确flag,然后,会输出aFlag证明你的flag正确,然后,继续往上分析,可以看到v3的值,是由strcmp()决定的,比较v5和输入的字符串,如果一样就会进入后面的if判断,所以,我们继续往上分析,看看哪里又涉及v5,可以看到开头的_mm_storeu_si128(),对其进行分析发现它类似于memset(),将xmmword_413E34的值赋值给v5,所以,我们可以得到正确的flag应该在xmmword_413E34中,然后,我们双击413E34进行跟进

可以看到一堆十六进制的数
这时,我们使用IDA的另一个功能 R ,能够将十进制的数转换为字符串。

根据小端存储的规则可以得到flag
但是不知道为什么不同IDA分析出来的伪代码差别比较大,本题我是用IDA pro7.6做的,而IDA pro 6.8则不行,连main函数都找不到,奇怪。
思路二:Ollydbg中文搜索
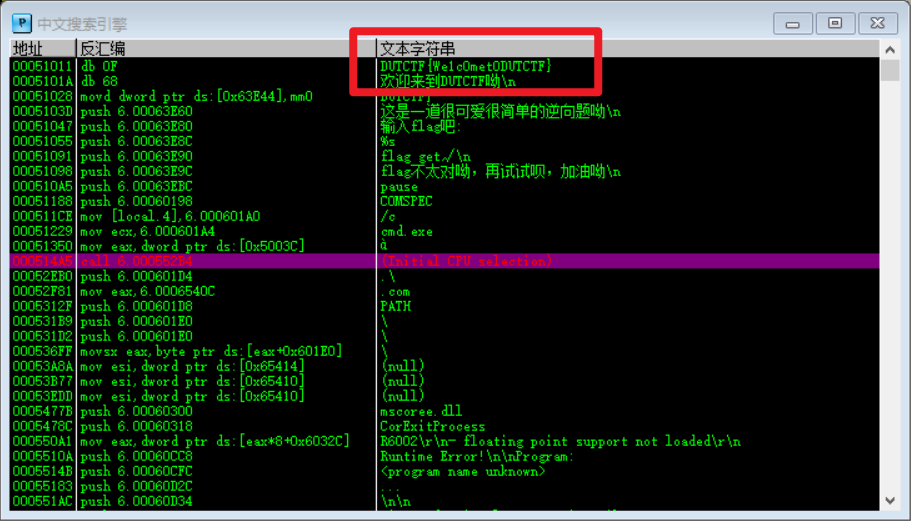
这种思路我觉得比较碰巧,类似的用010editor打开也能看到类似的字符串,不过OD可能更容易发现一点
但是不知道为什么IDA的shift + F12 看不到
第七题:game(TODO)
第八题:Hello,CTF
0x01.运行程序

输入正确的flag,才会显示正确
0x02.查壳

是32位的程序,并且是Microsoft Visual C++编译,而且没有加壳
0x03.IDA

照旧,依旧先从main开始分析,然后,对main函数进行F5查看伪代码
int __cdecl main(int argc, const char **argv, const char **envp)
{
int i; // ebx
char v4; // al
int result; // eax
int v6; // [esp+0h] [ebp-70h]
int v7; // [esp+0h] [ebp-70h]
char Buffer[2]; // [esp+12h] [ebp-5Eh] BYREF
char v9[20]; // [esp+14h] [ebp-5Ch] BYREF
char v10[32]; // [esp+28h] [ebp-48h] BYREF
__int16 v11; // [esp+48h] [ebp-28h]
char v12; // [esp+4Ah] [ebp-26h]
char v13[36]; // [esp+4Ch] [ebp-24h] BYREF
strcpy(v13, "437261636b4d654a757374466f7246756e");// 将字符串复制到v13的位置
while ( 1 )
{
memset(v10, 0, sizeof(v10));
v11 = 0;
v12 = 0;
sub_40134B(aPleaseInputYou, v6);
scanf("%s", v9); // 输入一个字符串
if ( strlen(v9) > 0x11 ) // 输入的字符串长度不能大于17(0x11)
break;
for ( i = 0; i < 17; ++i )
{
v4 = v9[i];
if ( !v4 )
break;
sprintf(Buffer, "%x", v4);// Buffer的定义:char Buffer[2];猜测是将v4以十六进制的形式输出到Buffer中
strcat(v10, Buffer); // 拼接v10, Buffer
}
if ( !strcmp(v10, v13) ) // 最后,进行比较,看输入的字符串是否和v10的字符串相等,如果相等,则说明输入了正确的flag
sub_40134B(aSuccess, v7);
else
sub_40134B(aWrong, v7);
}
sub_40134B(aWrong, v7);
result = --Stream._cnt;
if ( Stream._cnt < 0 )
return _filbuf(&Stream);
++Stream._ptr;
return result;
}
0x04.将字符串转换为十六进制
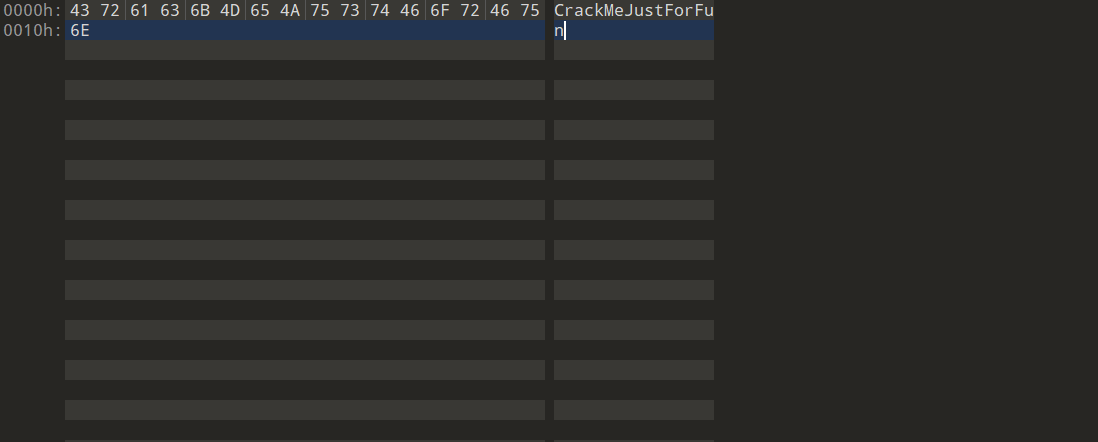
得到了最后的flag是:CrackMeJustForFun
第九题:open - source
#include <stdio.h>
#include <string.h>
int main(int argc, char *argv[]) {
if (argc != 4) {
printf("what?\n");
//exit(1);
}
unsigned int first = atoi(argv[1]); // argv[1] = 51966
if (first != 0xcafe) {
printf("you are wrong, sorry.\n");
exit(2);
}
unsigned int second = atoi(argv[2]);
if (second % 5 == 3 || second % 17 != 8) {
printf("ha, you won't get it!\n");
exit(3);
}
if (strcmp("h4cky0u", argv[3])) { // argv[3] = h4cky0u
printf("so close, dude!\n");
exit(4);
}
printf("Brr wrrr grr\n");
unsigned int hash = first * 31337 + (second % 17) * 11 + strlen(argv[3]) - 1615810207;
printf("Get your key: ");
printf("%x\n", hash);
return 0;
}
逐个分析即可。
#include<stdio.h>
#include<string.h>
int main(void){
unsigned int first = 51966; // 0xcafe(16) →51966(10)
unsigned int second; // 25
for (unsigned int i = 0; ;i ++ ){
if (i % 5 != 3 && i % 17 == 8){
second = i;
// printf("%d\n", (second % 17) * 11); // 88
break;
}
}
char argv[10] = "h4cky0u";
unsigned int hash = first * 31337 + (second % 17) * 11 + strlen(argv) - 1615810207;
printf("Get your key: ");
printf("%x\n", hash);
return 0;
}
第十题:no-strings-attached
法一:动态分析
0x01.查壳和查看程序的详细信息

说明程序是ELF文件,32位
这个软件要放在Linux下执行,值得注意的是,我的Linux是64位的,一开始显示找不到文件,原因是没有安装32位的编译环境,在网上查找相关教程后才能运行。
0x02.使用静态分析工具IDA进行分析
int __cdecl main(int argc, const char **argv, const char **envp)
{
setlocale(6, &locale);
banner();
prompt_authentication();
authenticate();
return 0;
}
一个一个分析
setlocale
看名字像初始化,看了代码也看不出什么
banner()
int banner()
{
unsigned int v0; // eax
v0 = time(0);
srand(v0);
wprintf((int)&unk_80488B0);
rand();
return wprintf((int)&unk_8048960);
}
出现了wprintf()函数,我们可以康康输出了什么
双击&unk_80488B0(其它地址也是)
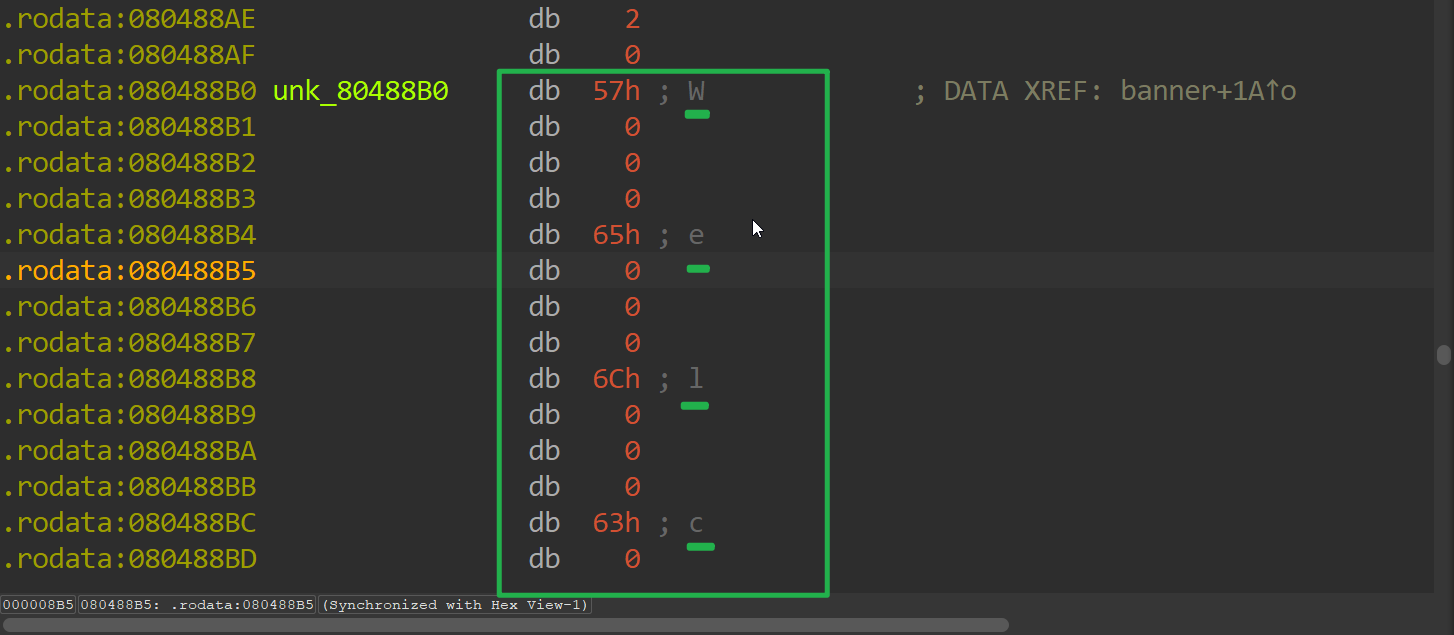
可以看到一个一个的字母,我们用IDA python来输出,运行以下脚本
// IDA python 查看 wprintf();的内容
addr = here();
ans = ""
for i in range(50):
ans += get_bytes(addr + i * 4, 1).decode(errors='ignore')
print(ans)
可以得到banner()中输出了"Welcome to cyber malware control software.","Currently tracking %d bots worldwide"
prompt_authentication();
同理可以发现,这个函数输出了“Please enter authentication details:”
还没有一些实质性的操作
authenticate()
void authenticate()
{
int ws[8192]; // [esp+1Ch] [ebp-800Ch] BYREF
wchar_t *s2; // [esp+801Ch] [ebp-Ch]
s2 = decrypt((wchar_t *)&s, (wchar_t *)&dword_8048A90);//decrypt:加密
if ( fgetws(ws, 0x2000, stdin) ) // 从标准输入流输入
{
ws[wcslen(ws) - 1] = 0; // 谜之操作
if ( !wcscmp(ws, s2) ) // 对比字符串
wprintf((int)&unk_8048B44); // Success! Welcome back!
else
wprintf((int)&unk_8048BA4); // Access denied!
}
free(s2);
}
分析可得,这段代码是将我们的输入与s2进行对比,因此我们不妨先把s2找出来
0x03.GDB动态调试
首先我们在authenticate()中查看decrypt函数
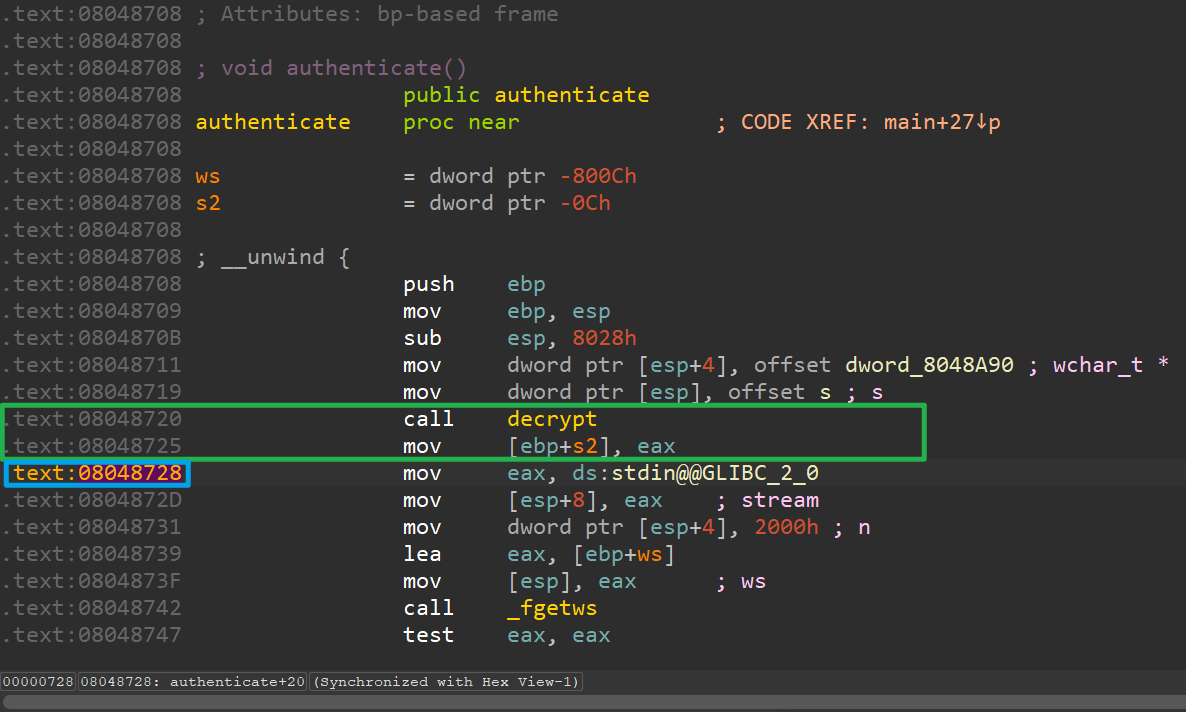
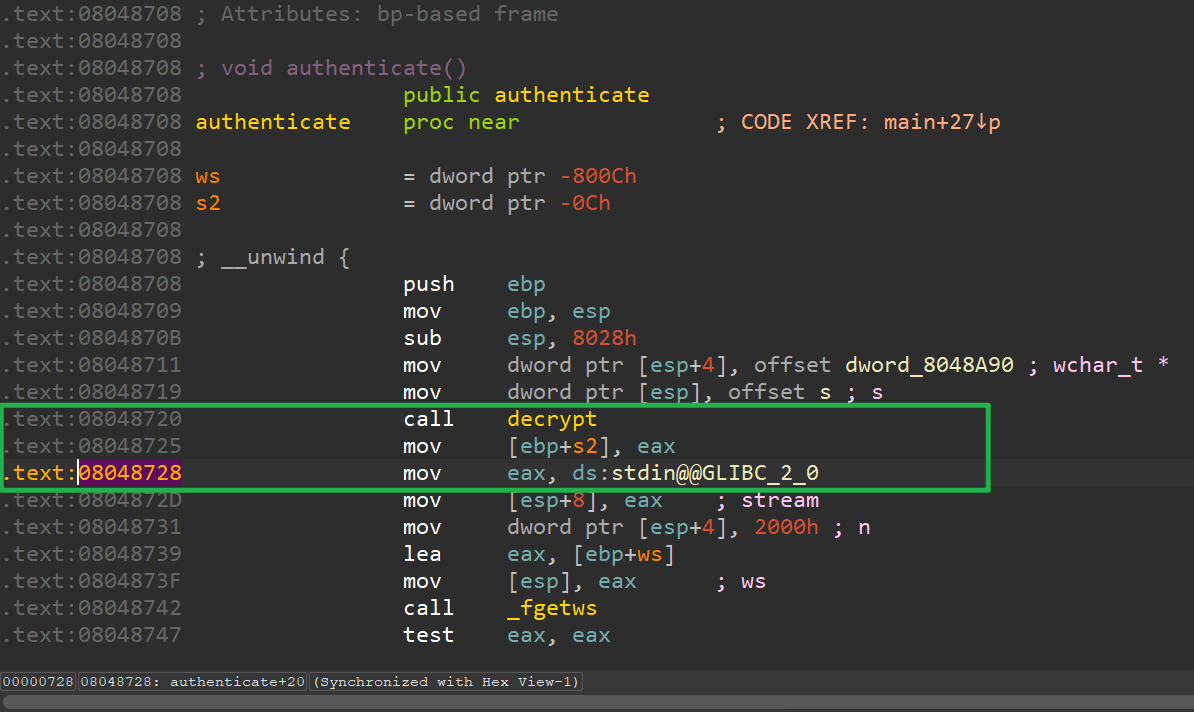
它应该往eax写入了返回结果,我们待会重点关注。
用GDB调试,我在蓝色的地方设置了断点,然后运行,最后查看eax寄存器(以字符串形式输出)
gdb hhh
b *0x08048728
r
x/6sw $eax
最后一步详见:【原创】GDB之examine命令(即x命令)详解
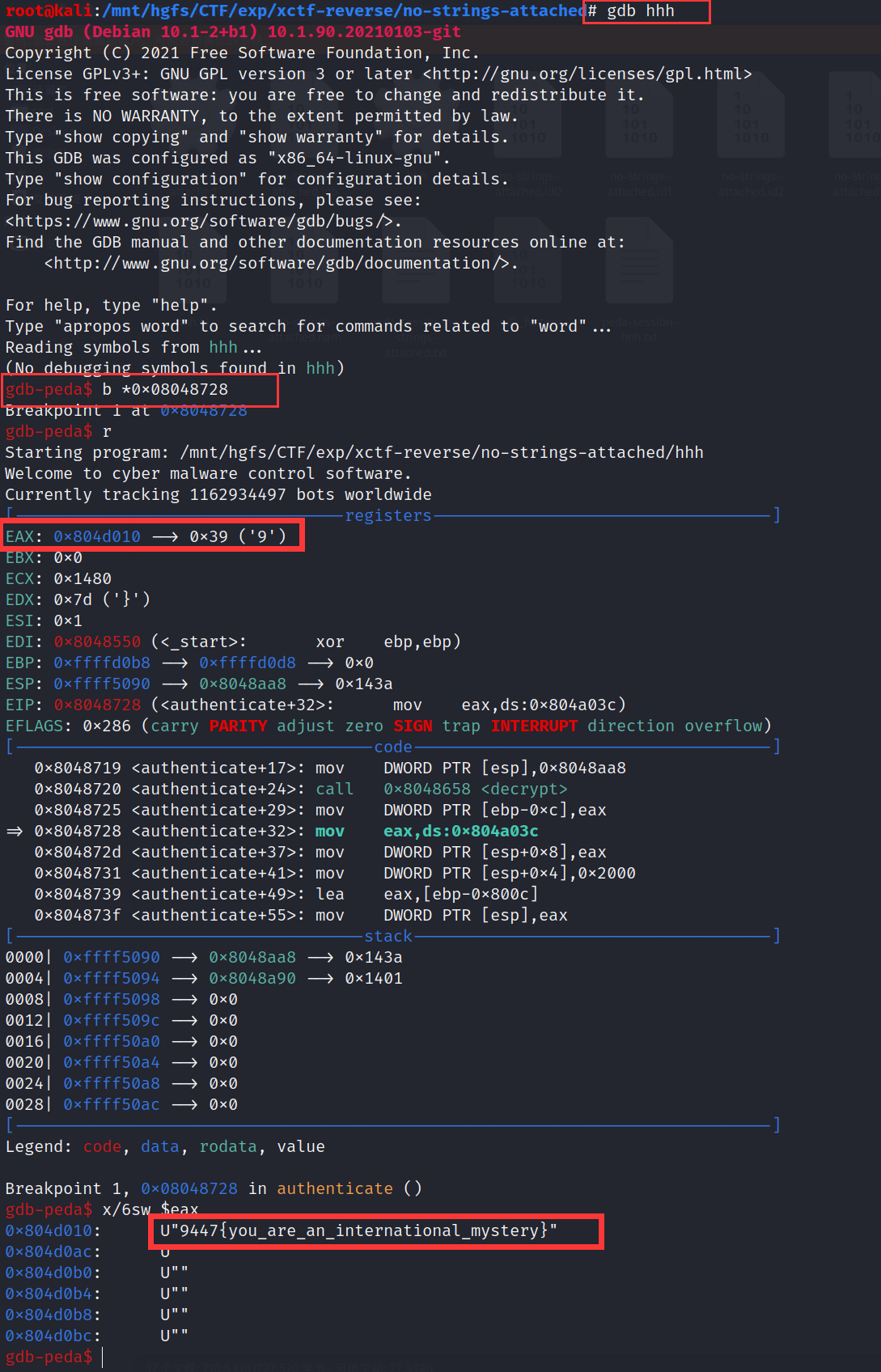
得到flag:9447{you_are_an_international_myster
法二:静态分析
由s2 = decrypt((wchar_t *)&s, (wchar_t *)&dword_8048A90);知,我们可以分析s与dword_8048A90这两个数组的值,然后模拟一遍decrypt()函数,则有可能得到答案
字符串s
脚本法:67;zqxcfsgbes`kqxjspdxnppdpdn{vxjs{
Shift + E法
另一个字符串
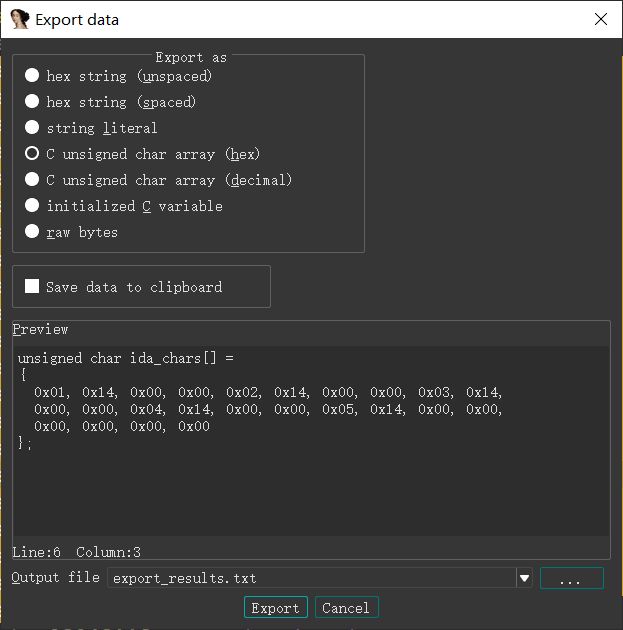
注意:两个参数的类型都是wchar_t 类型(长度16位或32位,本机32位,4字节)由于有大量的0,所以不能用char类型的数组,否则读到第三位直接结束。此外,删除后面4 个字节的0,因为字符串的结尾默认加0。
ps: wchar_t是C/C++的字符类型,是一种扩展的存储方式。wchar_t类型主要用在国际化程序的实现中,但它不等同于unicode编码。unicode编码的字符一般以wchar_t类型存储。——百度百科
#include<stdio.h>
#include<string.h>
int main(void)
{
unsigned char s[] =
{
0x3A, 0x14, 0x00, 0x00, 0x36, 0x14, 0x00, 0x00, 0x37, 0x14,
0x00, 0x00, 0x3B, 0x14, 0x00, 0x00, 0x80, 0x14, 0x00, 0x00,
0x7A, 0x14, 0x00, 0x00, 0x71, 0x14, 0x00, 0x00, 0x78, 0x14,
0x00, 0x00, 0x63, 0x14, 0x00, 0x00, 0x66, 0x14, 0x00, 0x00,
0x73, 0x14, 0x00, 0x00, 0x67, 0x14, 0x00, 0x00, 0x62, 0x14,
0x00, 0x00, 0x65, 0x14, 0x00, 0x00, 0x73, 0x14, 0x00, 0x00,
0x60, 0x14, 0x00, 0x00, 0x6B, 0x14, 0x00, 0x00, 0x71, 0x14,
0x00, 0x00, 0x78, 0x14, 0x00, 0x00, 0x6A, 0x14, 0x00, 0x00,
0x73, 0x14, 0x00, 0x00, 0x70, 0x14, 0x00, 0x00, 0x64, 0x14,
0x00, 0x00, 0x78, 0x14, 0x00, 0x00, 0x6E, 0x14, 0x00, 0x00,
0x70, 0x14, 0x00, 0x00, 0x70, 0x14, 0x00, 0x00, 0x64, 0x14,
0x00, 0x00, 0x70, 0x14, 0x00, 0x00, 0x64, 0x14, 0x00, 0x00,
0x6E, 0x14, 0x00, 0x00, 0x7B, 0x14, 0x00, 0x00, 0x76, 0x14,
0x00, 0x00, 0x78, 0x14, 0x00, 0x00, 0x6A, 0x14, 0x00, 0x00,
0x73, 0x14, 0x00, 0x00, 0x7B, 0x14, 0x00, 0x00, 0x80, 0x14,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x53, 0x00, 0x00, 0x00,
0x75, 0x00, 0x00, 0x00, 0x63, 0x00, 0x00, 0x00, 0x63, 0x00,
0x00, 0x00, 0x65, 0x00, 0x00, 0x00, 0x73, 0x00, 0x00, 0x00,
0x73, 0x00, 0x00, 0x00, 0x21, 0x00, 0x00, 0x00, 0x20, 0x00,
0x00, 0x00, 0x57, 0x00, 0x00, 0x00, 0x65, 0x00, 0x00, 0x00,
0x6C, 0x00, 0x00, 0x00, 0x63, 0x00, 0x00, 0x00, 0x6F, 0x00,
0x00, 0x00, 0x6D, 0x00, 0x00, 0x00, 0x65, 0x00, 0x00, 0x00,
0x20, 0x00, 0x00, 0x00, 0x62, 0x00, 0x00, 0x00, 0x61, 0x00,
0x00, 0x00, 0x63, 0x00, 0x00, 0x00, 0x6B, 0x00, 0x00, 0x00,
0x21, 0x00, 0x00, 0x00, 0x0A, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x41, 0x00, 0x00, 0x00, 0x63, 0x00, 0x00, 0x00,
0x63, 0x00, 0x00, 0x00, 0x65, 0x00, 0x00, 0x00, 0x73, 0x00,
0x00, 0x00, 0x73, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
0x64, 0x00, 0x00, 0x00, 0x65, 0x00, 0x00, 0x00, 0x6E, 0x00,
0x00, 0x00, 0x69, 0x00, 0x00, 0x00, 0x65, 0x00, 0x00, 0x00,
0x64, 0x00, 0x00, 0x00, 0x21, 0x00, 0x00, 0x00, 0x0A, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x01, 0x1B, 0x03, 0x3B, 0x50, 0x00, 0x00, 0x00, 0x09, 0x00,
0x00, 0x00, 0x88, 0xF8, 0xFF, 0xFF, 0x6C, 0x00, 0x00, 0x00,
0x1C, 0xFA, 0xFF, 0xFF, 0x90, 0x00, 0x00, 0x00, 0x5B, 0xFA,
0xFF, 0xFF, 0xB0, 0x00, 0x00, 0x00, 0x70, 0xFA, 0xFF, 0xFF,
0xD0, 0x00, 0x00, 0x00, 0x20, 0xFB, 0xFF, 0xFF, 0xF4, 0x00,
0x00, 0x00, 0xC1, 0xFB, 0xFF, 0xFF, 0x14, 0x01, 0x00, 0x00,
0xF8, 0xFB, 0xFF, 0xFF, 0x34, 0x01, 0x00, 0x00, 0x68, 0xFC,
0xFF, 0xFF, 0x70, 0x01, 0x00, 0x00, 0x6A, 0xFC, 0xFF, 0xFF,
0x84, 0x01, 0x00, 0x00
};
unsigned char a2[] =
{
0x01, 0x14, 0x00, 0x00, 0x02, 0x14, 0x00, 0x00, 0x03, 0x14,
0x00, 0x00, 0x04, 0x14, 0x00, 0x00, 0x05, 0x14, 0x00, 0x00,
};
int v4 = 0;
int ans[1000] = {};
for (int i = 0; i < 150; i ++ ){
ans[i] = s[i] - a2[i % 20]; // 两个循环可以简化成一个
if(ans[i]) printf("%c", ans[i]); // 不加if,会出现大量空格
}
return 0;
}
运行得到flag:9447{you_are_an_international_myster
本文参考:XCTF-writeup
第十一题 :csaw2013reversing2
0x01:查壳
0x02: 思路一:静态分析
这里我用不同版本的IDA会生成不同的反汇编代码,其中v6的更容易读懂,这里我们选择v6,但是二者要结合在一起看。
main函数的反汇编代码
int __cdecl __noreturn main(int argc, const char **argv, const char **envp)
{
int v3; // ecx@1
LPVOID lpMem; // [sp+8h] [bp-Ch]@1 // 在v7中,它是char *类型的
HANDLE hHeap; // [sp+10h] [bp-4h]@1
hHeap = HeapCreate(0x40000u, 0, 0);
lpMem = HeapAlloc(hHeap, 8u, MaxCount + 1); // 看不懂,应该是赋一个初始值
memcpy_s(lpMem, MaxCount, &unk_409B10, MaxCount); // 类似strcpy,将字符串unk_409B10到地址lpMem处
if ( sub_40102A() || IsDebuggerPresent() ) // 看名字可以猜测,有代码防止Debugger,动态调试要注意,我们静态调试就不管了
{
__debugbreak(); // 看名字可以猜测,运行到这里就会退出
sub_401000(v3 + 4, (int)lpMem); // 这是一段被“保护”的代码,可以猜测是生成flag的函数,另外第一个参数没有起作用
ExitProcess(0xFFFFFFFF); // 看名字可以猜测,运行到这里也会退出
}
MessageBoxA(0, (LPCSTR)lpMem + 1, "Flag", 2u);// 结合名字可以知道,应该是输出Flag
HeapFree(hHeap, 0, lpMem);
HeapDestroy(hHeap);
ExitProcess(0);
}
main函数的逻辑大概是:
- 定义一个字符指针lpMen,往该地址写入字符串unk_409B10
- 如果经过几个检测debug的函数,将lpMen作为参数,调用生成Flag的函数
- 退出程序(这段要修改)
- 如果没有生成flag,就输出flag
很明显,如果是动态调试,那就得各种绕过,但我们现在只要关注生成flag的函数即可。
sub_401000(v3 + 4, (int)lpMem)函数的反汇编代码
unsigned int __fastcall sub_401000(int a1, int a2) // 传入两个整数型参数
{
int v2; // esi
unsigned int v3; // eax
unsigned int v4; // ecx
unsigned int result; // eax
v2 = dword_409B38; // 给v2赋值一个dword值的地址
v3 = a2 + 1 + strlen((const char *)(a2 + 1)) + 1;
v4 = 0;
result = ((strlen((const char *)(a2 + 1))) >> 2) + 1;
if ( result ) // 结合下文猜测result是控制范围的
{
do
*(_DWORD *)(a2 + 4 * v4++) ^= v2; // 最重要的一行
while ( v4 < result );
}
return result;
}
这段代码主要是各种运算,我们要解决一些概念问题,整个问题就迎刃而解:
-
lpMem的值的问题
传入的第二个参数是a2 = (int)lpMem,但是lpMem是一个地址,而地址那段代码又看不懂,不知道lpMem具体是什么。而代码中又要用到a2,这该怎么处理?
经过分析可以发现,lpMem的值不会影响我们解题,因为其中可能造成影响的a2被消去了,下面具体分析涉及到lpMem的语句。
首先是lpMem的初始化,第一行我们看不懂,但是经查阅,第二行的作用类似strcpy,将地址unk_409B10处开始的字符串复制到地址lpMem处,复制的元素是SourceSize个
lpMem = (CHAR *)HeapAlloc(hHeap, 8u, SourceSize + 1); memcpy_s(lpMem, SourceSize, &unk_409B10, SourceSize);然后在传入参数时,令a2 = (int)lpMem
具体使用a2时,有三处。
第一处:
v3 = a2 + 1 + strlen((const char *)(a2 + 1)) + 1;第二处:
result = ((v3 - (a2 + 2)) >> 2) + 1;第三处:
*(_DWORD *)(a2 + 4 * v4++) ^= v2;这里有两种用法,一种是把a2当作整数,另一种又把a2变成了指针。
对于后者,这样的操作等价于对一个字符串进行操作,与具体的值无关。
对于前者,我们可以发现它只影响v3和result的取值。对于v3,我们无法得知具体的值,后面只有求result时要用到。那我们就具体分析result,我们惊讶地发现,计算result时,a2被消掉了,因此我们可以计算出result的值,其它地方也用不到v3,至此我们可以放心的说a2对我们不会造成影响。
所以我们可以直接定义一个字符数组:
unsigned char lpMem[] = //lpMem { 0xBB, 0xCC, 0xA0, 0xBC, 0xDC, 0xD1, 0xBE, 0xB8, 0xCD, 0xCF, 0xBE, 0xAE, 0xD2, 0xC4, 0xAB, 0x82, 0xD2, 0xD9, 0x93, 0xB3, 0xD4, 0xDE, 0x93, 0xA9, 0xD3, 0xCB, 0xB8, 0x82, 0xD3, 0xCB, 0xBE, 0xB9, 0x9A, 0xD7, 0xCC, 0xDD }; -
_DWORD类型,理解*(_DWORD *)(a2 + 4 * v4++) ^= v2;
经查阅,它的定义是
A dword, which is short for "double word," is a data type definition that is specific to Microsoft Windows. When defined in the file windows.h, a dword is an unsigned, 32-bit unit of data. It can contain an integer value in the range 0 through 4,294,967,295.
它占有相当4个字节/char的空间,这段代码的含义应该是对a2所指向的地址处的Dword类型进行操作,即和v2所指向的Dword(v2被定义为int,但作用却是指针)进行异或。
具体来说,v2处的定义是
v2 = dword_409B38;,这就是一个dword的地址,点进去可以看到它的值是0DDCCAABBh或者写成c代码unsigned char v2[] ={ 0xBB, 0xAA, 0xCC, 0xDD };然后是异或,两个Dword怎么异或?
应该可以使用windows.h来进行相关操作。
这里我们可以把dword当作4个char来操作,即让我们上面定义的lpMem数组的每一个元素,轮换着和v2进行异或
-
result的值的问题
int a2 = (int)lpMem; int v3 = a2 + 1 + strlen(lpMem + 1) + 1; int result = ((v3 - (a2 + 2)) >> 2) + 1; printf("\n%u", result);计算可得result是9,也就是遍历一遍lpMem,所以对于char型的lpMem,范围就是36
0x03: 编写脚本生成flag
于是最终代码如下
#include<stdio.h>
int main(void)
{
unsigned char lpMem[] = //lpMem
{
0xBB, 0xCC, 0xA0, 0xBC, 0xDC, 0xD1, 0xBE, 0xB8, 0xCD, 0xCF,
0xBE, 0xAE, 0xD2, 0xC4, 0xAB, 0x82, 0xD2, 0xD9, 0x93, 0xB3,
0xD4, 0xDE, 0x93, 0xA9, 0xD3, 0xCB, 0xB8, 0x82, 0xD3, 0xCB,
0xBE, 0xB9, 0x9A, 0xD7, 0xCC, 0xDD
};
unsigned char v2[] =
{
0xBB, 0xAA, 0xCC, 0xDD
};
unsigned char ans[100];
for (int i = 0; i < 36 ; i ++ )
{
ans[i] = (lpMem[i]) ^ v2[i % 4];
printf("%c", ans[i]);
}
return 0;
}
输出是 flag{reversing_is_not_that_hard!}
其它思路
参考文章:https://blog.csdn.net/weixin_43784056/article/details/103655968
第十二题:maze
0x01.查壳和详细信息

可以看到程序是ELF文件,64位
0x02:IDA静态分析
拖入IDA,F5查看main函数
p.s.右键数字,可以把数字转换成字符
__int64 __fastcall main(int a1, char **a2, char **a3)
{
__int64 v3; // rbx
int v4; // eax
char v5; // bp
char v6; // al
const char *v7; // rdi
unsigned int v9; // [rsp+0h] [rbp-28h] BYREF
int v10[9]; // [rsp+4h] [rbp-24h] BYREF
v10[0] = 0;
v9 = 0;
puts("Input flag:");
scanf("%s", &s1); // s1 是我们输入的字符串,也就是flag了
if ( strlen(&s1) != 24 || strncmp(&s1, "nctf{", 5uLL) || *(&byte_6010BF + 24) != '}' ) // 开头是“nctf{”,字符串长度是24,减去nctf{},还剩18个字符
{
LABEL_22:
puts("Wrong flag!");
exit(-1);
}
v3 = 5LL;
if ( strlen(&s1) - 1 > 5 ) // 长度得大于6
{
while ( 1 )
{
v4 = *(&s1 + v3); // 即'{'之后的字符,转换为整数(ASCII)
v5 = 0;
if ( v4 > 78 ) // N(78)
{
if ( (unsigned __int8)v4 == 79 ) // 'O'
{
v6 = sub_400650(v10); // int v1 = (*a1)--; return v1 > 0; 返回v10指向的值是否为正,并且让v10指向的元素减一
goto LABEL_14;
}
if ( (unsigned __int8)v4 == 111 ) // 'o'
{
v6 = sub_400660(v10); // int v1 = *a1 + 1; *a1 = v1; return v1 < 8; 让v10指向的值加一,然后判断其是否小于8
goto LABEL_14;
}
}
else
{
if ( (unsigned __int8)v4 == 46 ) // '.'
{
v6 = sub_400670(&v9); // int v1 = (*a1)--; return v1 > 0; 返回v9是否为正,并且让v9减一
goto LABEL_14;
}
if ( (unsigned __int8)v4 == 48 ) // '0'
{
v6 = sub_400680(&v9); // int v1 = *a1 + 1; *a1 = v1; return v1 < 8; 先让v9加一,然后再判断其是否小于8
LABEL_14:
v5 = v6;
}
}
if ( !(unsigned __int8)sub_400690(asc_601060, (unsigned int)v10[0], v9) ) // 状态检测
goto LABEL_22;
if ( ++v3 >= strlen(&s1) - 1 )
{
if ( v5 )
break;
LABEL_20:
v7 = "Wrong flag!";
goto LABEL_21;
}
}
}
if ( asc_601060[8 * v9 + v10[0]] != '#' ) // 8 * v9 + v10[0] 得是 36
goto LABEL_20;
v7 = "Congratulations!";
LABEL_21:
puts(v7);
return 0LL;
}
程序逻辑
-
输入一个字符串,要求开头是“nctf{”,字符串长度是24,最后一个字符是'}'
-
对字符串的每一个字符依次进行if判断,v4只能是
{'O', 'o', '.', '0'}的其中一个。在判断的同时有以下操作- 会改变两个量:v9,v10[0]。变化是加一或者减一。
- 会对v9,v10[0]的值的范围进行一个判断,将结果储存在v6(v5)中
-
判断结束后,会用
sub_400690函数判断v10[0], v9的值是否合法,不合法则退出程序 -
当遍历完最后一个元素时,v5也会作为状态判断的标准,通过之后则退出遍历
-
最后以一个判断语句,判断v9,v10[0]是否符合要求,符合则输出Congratulations,说明我们输入了正确的flag。
其中sub_400690函数的作用是,判断数组asc_601060的特定元素,是否为指定元素
0x03.模拟代码
#include<iostream>
using namespace std;
const char pos[5] = {'O', 'o', '.', '0'};
const int len = 18;
char ans[19];
unsigned char a1[] =
{
0x20, 0x20, 0x2A, 0x2A, 0x2A, 0x2A, 0x2A, 0x2A, 0x2A, 0x20,
0x20, 0x20, 0x2A, 0x20, 0x20, 0x2A, 0x2A, 0x2A, 0x2A, 0x20,
0x2A, 0x20, 0x2A, 0x2A, 0x2A, 0x2A, 0x20, 0x20, 0x2A, 0x20,
0x2A, 0x2A, 0x2A, 0x20, 0x20, 0x2A, 0x23, 0x20, 0x20, 0x2A,
0x2A, 0x2A, 0x20, 0x2A, 0x2A, 0x2A, 0x20, 0x2A, 0x2A, 0x2A,
0x20, 0x20, 0x20, 0x20, 0x20, 0x2A, 0x2A, 0x2A, 0x2A, 0x2A,
0x2A, 0x2A, 0x2A, 0x2A, 0x00
};
bool check (unsigned char* a1, int a2, int a3)
{
char result; // rax
result = *(unsigned char *)(a1 + a2 + 8LL * a3);
bool x = ((result == 32) || (result == 35)); // 32 是空格(0x20),35 是'#'(0x23)
return x;
}
void dfs(int n, int v9, int v10){
if (n == len){
if (v10 <= 0 || v10 >= 8 || v9 <= 0 || v9 >= 8) return;
if (8 * v9 + v10 != 36) return;
for (int i = 0; i < len; i ++ ) printf("%c", ans[i]);
printf("\n");
return;
}
if (!check(a1, v10, v9)) return;
ans[n] = pos[0];
dfs(n + 1, v9, v10 - 1);
ans[n] = pos[1];
dfs(n + 1, v9, v10 + 1);
ans[n] = pos[2];
dfs(n + 1, v9 - 1, v10);
ans[n] = pos[3];
dfs(n + 1, v9 + 1, v10);
/*
意识到这是个迷宫之后,可以将z代码修改如下
const char dx[4] = {0, 0, -1, 1};
const char dy[4] = {-1, 1, 0, 0};
for (int i = 0; i < 4; i ++ ){
ans[n] = pos[i];
dfs(n + 1, v9 + dx[i], v10 + dy[i]);
}
*/
return;
}
int main(void){
dfs(0, 0, 0);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号