Kaggle 初体验:Titanic 数据集调试记录
学习了一些机器学习的算法,总想找个地方用一用试一试。上网搜索了一番,发现了 Kaggle 这个网站,是各种企业举办机器学习竞赛的地方。Kaggle 上有一个入门级的数据集,要我们通过分析泰坦尼克号上乘客的信息,来判断他们是否获救。
Andrew Ng 的课程里提过一个模型调试的方法,就是先用尽量快的方式搞出一个能跑的模型,然后再慢慢调整。既然是一个二分类问题,那 logistic regression 自然是最简单直接的方法。我们先用 logistic regression 尝试一下。
据说在开始跑模型之前,数据分析比较重要。既然提供的特征里有数值型的信息和非数值型的信息,那我们就先给数值型的信息算一个相关系数,非数值型的信息画一个直方图看看...
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
train_data = pd.read_csv('train.csv')
train_numeric = train_data[['Pclass', 'Age', 'SibSp', 'Parch', 'Fare']]
test_data = pd.read_csv('test.csv')
test_numeric = test_data[['Pclass', 'Age', 'SibSp', 'Parch', 'Fare']]
train_data.sample(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 239 | 240 | 0 | 2 | Hunt, Mr. George Henry | male | 33.0 | 0 | 0 | SCO/W 1585 | 12.2750 | NaN | S |
| 855 | 856 | 1 | 3 | Aks, Mrs. Sam (Leah Rosen) | female | 18.0 | 0 | 1 | 392091 | 9.3500 | NaN | S |
| 689 | 690 | 1 | 1 | Madill, Miss. Georgette Alexandra | female | 15.0 | 0 | 1 | 24160 | 211.3375 | B5 | S |
train_data.describe()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
从这里可以看出训练数据并不是非常完整,特别是 Age 和 Cabin 两类数据均有缺失。如果这两种数据不是很重要就先放弃吧,如果比较重要稍后再想办法。
train_numeric.corrwith(train_data['Survived'])
Pclass -0.338481
Age -0.077221
SibSp -0.035322
Parch 0.081629
Fare 0.257307
dtype: float64
可以看出,数值型数据中与是否获救比较相关的有 Pclass 和 Fare,初步考虑把这两项特征提供给模型进行参数训练。
sns.barplot(x = 'Sex', y = 'Survived', data = train_data)
plt.show()
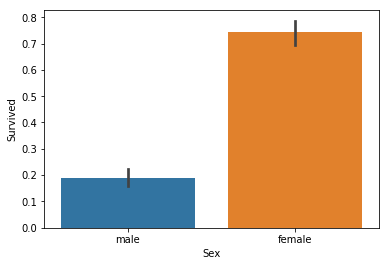
果然性别和是否获救是非常相关的,获救者大部分都是女性。我们甚至可以考虑把所有女性都输出“获救”,男性都输出“不获救”,看看能够获得多少分...
predict = pd.DataFrame({'PassengerId': test_data['PassengerId'], 'Survived': np.where(test_data['Sex'] == 'female', 1, 0)})
predict.to_csv('predict.csv', index = False)
把这个 predict.csv 交到 Kaggle 上面,竟然获得了 0.76555 分...看起来还行,不过排名大概在 80% 的位置- -还是先给自己一个小目标,把模型调到前 50% 吧...
继续来看非数值型的数据:
sns.barplot(x = 'Embarked', y = 'Survived', data = train_data)
plt.show()
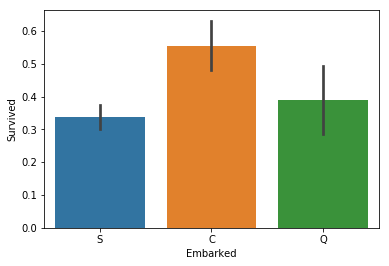
上船的港口看起来相关性就没有那么强了,不过从 C 上船的乘客获救率还是明显高于其它两个港口,也把这个特征给模型试试看。
现在我们大致选出了 Pclass、Fare、Sex 和 Embarked 四种特征,这些特征暂时还没有缺失的数据,可以先不考虑缺失数据填充的问题。不过在训练模型之前,还需要整理一下数据,大概要做这些事情:
- 数据要放缩到 [-1, 1] 的范围里,利于参数的训练;
- 非数值型的数据要变成向量,不能用 1、2、3 什么的代替(除非有大小关系),否则容易引入本不存在的顺序关系,可能会导致训练误差。
Pclass 这个特征虽然也可以说有顺序关系吧(可以认为一等舱小于二等舱什么的),但我觉得还是使用向量更符合逻辑一些...
def prepare_data(data):
ret = [
pd.DataFrame((data['Fare'] - data['Fare'].min()) / (data['Fare'].max() - data['Fare'].min())),
pd.get_dummies(data['Pclass'], prefix = 'Pclass'),
pd.get_dummies(data['Sex'], prefix = 'Sex'),
pd.get_dummies(data['Embarked'], prefix = 'Embarked')
]
return pd.concat(ret, axis = 1)
train_x = prepare_data(train_data)
train_y = train_data['Survived']
train_x.sample(3)
| Fare | Pclass_1 | Pclass_2 | Pclass_3 | Sex_female | Sex_male | Embarked_C | Embarked_Q | Embarked_S | |
|---|---|---|---|---|---|---|---|---|---|
| 459 | 0.015127 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
| 17 | 0.025374 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 |
| 508 | 0.043966 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
我们用 logistic regression 来试试看,用 k-fold (k = 10) 来看训练准确率。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold
def get_training_accuracy(model, train_x, train_y):
ret = 0
kf = KFold(n_splits = 10)
for train_index, test_index in kf.split(train_x):
model.fit(train_x.loc[train_index], train_y.loc[train_index])
ret += model.score(train_x.loc[test_index], train_y.loc[test_index])
return ret / 10
model = LogisticRegression()
get_training_accuracy(model, train_x, train_y)
0.77217228464419485
准确率不是非常可观...但是毕竟是刚刚开始的模型,先看看能在 Kaggle 上拿多少分...
写代码的时候发现测试数据里有一个人没有 Fare...只好先用 0 补进去。
def gen_predict(model, train_x, train_y, test_x):
model.fit(train_x, train_y)
predict = model.predict(test_x)
predict = pd.DataFrame({'PassengerId': test_data['PassengerId'], 'Survived': predict})
predict.to_csv('predict.csv', index = False)
test_x = prepare_data(test_data)
test_x['Fare'].fillna(0, inplace = True)
gen_predict(model, train_x, train_y, test_x)
结果只得了 0.74641 分,比只按性别判断的分数还低...不过和用 k-fold 测出来的准确率还是差不多的。是时候分析一下原因了...
首先模型非常明显地 underfit 了,因为连训练集上的准确率都不会很高...我们来看看能否调整某些特征,或者挖掘更多特征来提高训练集上的准确率。
首先看到 Fare 的信息。从 describe 方法输出的信息可以看到,绝大部分乘客的 Fare 都不会很大。然而由于 Fare 的最大值较大,所以经过我们的线性缩放以后,绝大部分乘客的 Fare 都不会超过 0.1。这会不会对模型的训练造成影响呢?我们来对 Fare 取对数再放缩试试...
train_data['Fare'] = train_data['Fare'].apply(np.log1p)
train_x = prepare_data(train_data)
model = LogisticRegression()
get_training_accuracy(model, train_x, train_y)
0.77217228464419463
没有什么变化...再看看 sklearn 的手册,我看到了一个参数 C,就是正则项的参数的倒数,默认值为 1.0。既然现在还是 underfit 的状态,这个参数应该不会很需要,改成一个很大的值试一下...
model = LogisticRegression(C = 1e100)
get_training_accuracy(model, train_x, train_y)
0.77439450686641687
还是没什么变化...
没什么头绪的时候我去看了看泰坦尼克号的 wiki,倒是发现了一些信息。
首先是 wiki 里有这样一句话“在船的左舷,二副 Lightoller 命令救生船只载妇女和儿童,这种死板做法使得很多救生艇没装够人就放下。在右舷,一副 Murdoch 则在妇女优先逃生之后允许男性登艇。所以,在右舷获救的人数比在左舷获救的多。”
其次是 wiki 里有一张生还比例表,是按照“儿童/男性/女性”和“头/二/三等舱”分类的:
| 儿童 | 女子 | 男子 | |
|---|---|---|---|
| 头等舱 | 83% | 97% | 33% |
| 二等舱 | 100% | 86% | 8% |
| 三等舱 | 34% | 46% | 16% |
| 船员 | N/A | 87% | 22% |
这两条信息告诉我们:乘客在船中的位置,以及乘客的性别和“是否儿童”是较为关键的信息。看来对样本背景信息的了解也很重要嘛...
再次观察训练数据集提供的特征,乘客在船中的位置除了舱等之外,Cabin 这条特征应该也能表示。不过 Cabin 是以“字母+数字”的形式表示的,字母应该表示船舱的类别,应该只需要把“字母”的信息留下就好。没有 Cabin 的乘客统一把 Cabin 设为 X。
train_data['Cabin'].fillna('X', inplace = True)
train_data['Cabin'] = train_data['Cabin'].apply(lambda s: s[0])
sns.barplot(x = 'Cabin', y = 'Survived', data = train_data)
plt.show()
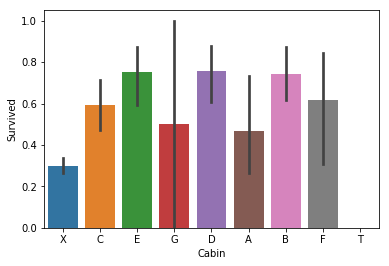
不同类别的船舱获救率的确是有区别的。我们再尝试增加一个组合特征,表示一名乘客的舱等 + 性别/年龄这个特性。由于部分乘客年龄未知,我们暂时认为他们不是儿童,如果还需改进再想办法。我们暂时认为 12 岁以下的人是儿童。
def gen_sex_pclass(data):
res = []
for index, row in data.iterrows():
if row['Age'] <= 12:
s = 'c'
elif row['Sex'] == 'male':
s = 'm'
else:
s = 'f'
s += str(row['Pclass'])
res.append(s)
data['SexPclass'] = pd.Series(res)
gen_sex_pclass(train_data)
sns.barplot(x = 'SexPclass', y = 'Survived', data = train_data)
plt.show()
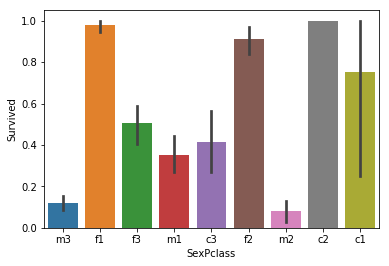
从图上看,这个组合特征和是否获救的确非常相关。我们将这两种特征也提供给模型,看看能否提高准确率。
def prepare_data(data):
gen_sex_pclass(data)
data['Cabin'].fillna('X', inplace = True)
data['Cabin'] = data['Cabin'].apply(lambda s: s[0])
ret = [
pd.DataFrame((data['Fare'] - data['Fare'].min()) / (data['Fare'].max() - data['Fare'].min())),
pd.get_dummies(data['Pclass'], prefix = 'Pclass'),
pd.get_dummies(data['Sex'], prefix = 'Sex'),
pd.get_dummies(data['Embarked'], prefix = 'Embarked'),
pd.get_dummies(data['Cabin'], prefix = 'Cabin'),
pd.get_dummies(data['SexPclass'], prefix = 'SexPclass')
]
return pd.concat(ret, axis = 1)
train_x = prepare_data(train_data)
model = LogisticRegression()
get_training_accuracy(model, train_x, train_y)
0.81483146067415735
准确率的确提高了一些!快提交到 Kaggle 上试试看...
def fit_features(data, goal):
return pd.DataFrame(data, columns = goal.columns).fillna(0)
test_x = prepare_data(test_data)
test_x = fit_features(test_x, train_x)
gen_predict(model, train_x, train_y, test_x)
获得了 0.77033 分,虽然提升不是很大,但是好歹也是有些提升的...还能不能挖掘一些新的特征呢?
剩下还有 Name, Ticket, SibSp 和 Parch 这四条特征没有利用,另外 Age 由于数据缺失可能没有利用充分。简单看了一下数据,感觉 Ticket 这个特征很难利用,暂时还是放在一边;Name 这个特征虽然是字符串,但是每个人都有 Mr.,Miss. 等头衔,可能会对模型训练有帮助。我们把每个人的头衔提取出来,看看它们和是否获救有没有什么关系。
def gen_title(data):
res = []
for index, row in data.iterrows():
lst = row['Name'].split()
for s in lst:
if s[-1] == '.':
res.append(s[:-1])
break
data['Title'] = pd.Series(res)
gen_title(train_data)
train_data['Title'].value_counts()
Mr 517
Miss 182
Mrs 125
Master 40
Dr 7
Rev 6
Mlle 2
Major 2
Col 2
Mme 1
Ms 1
Sir 1
Jonkheer 1
Capt 1
Countess 1
Lady 1
Don 1
Name: Title, dtype: int64
统计里出现了一些不常见的头衔,我们统一用一个 Rare 来替换。
def gen_title(data):
res = []
for index, row in data.iterrows():
lst = row['Name'].split()
for s in lst:
if s[-1] == '.':
if s[:-1] == 'Mlle':
res.append('Miss')
elif s[:-1] == 'Mme':
res.append('Mrs')
elif s[:-1] == 'Ms':
res.append('Miss')
elif s[:-1] == 'Lady':
res.append('Miss')
elif s[:-1] == 'Sir':
res.append('Mr')
elif s[:-1] != 'Mr' and s[:-1] != 'Miss' and s[:-1] != 'Mrs' and s[:-1] != 'Master' and s[:-1] != 'Dr' and s[:-1] != 'Rev':
res.append('Rare')
else:
res.append(s[:-1])
break
data['Title'] = pd.Series(res)
gen_title(train_data)
sns.barplot(x = 'Title', y = 'Survived', data = train_data)
plt.show()
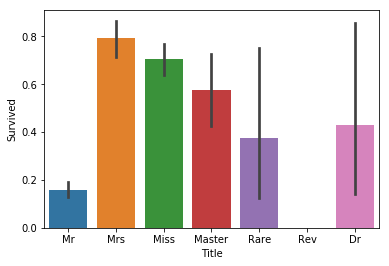
def prepare_data_3(data):
gen_sex_pclass(data)
gen_title(data)
data['Cabin'].fillna('X', inplace = True)
data['Cabin'] = data['Cabin'].apply(lambda s: s[0])
ret = [
pd.DataFrame((data['Fare'] - data['Fare'].min()) / (data['Fare'].max() - data['Fare'].min())),
pd.get_dummies(data['Pclass'], prefix = 'Pclass'),
pd.get_dummies(data['Sex'], prefix = 'Sex'),
pd.get_dummies(data['Embarked'], prefix = 'Embarked'),
pd.get_dummies(data['Cabin'], prefix = 'Cabin'),
pd.get_dummies(data['SexPclass'], prefix = 'SexPclass'),
pd.get_dummies(data['Title'], prefix = 'Title')
]
return pd.concat(ret, axis = 1)
train_x = prepare_data_3(train_data)
model = LogisticRegression()
get_training_accuracy(model, train_x, train_y)
0.82044943820224725
正确率又有所提高,我们试着提交到 Kaggle...
test_x = prepare_data_3(test_data)
test_x = fit_features(test_x, train_x)
gen_predict(model, train_x, train_y, test_x)
仍然只有 0.77033 分...
现在看来最大的希望应该就是 Age,但是 Age 主要的问题是有数据缺失...先按性别把当前 Age 已知的数据画成 distribution plot 看一看(上图为男性,下图为女性)
facet = sns.FacetGrid(train_data, hue = 'Survived', row = 'Sex', aspect = 3)
facet.map(sns.kdeplot, 'Age')
facet.set(xlim = (0, train_data['Age'].max()))
facet.add_legend()
plt.show()
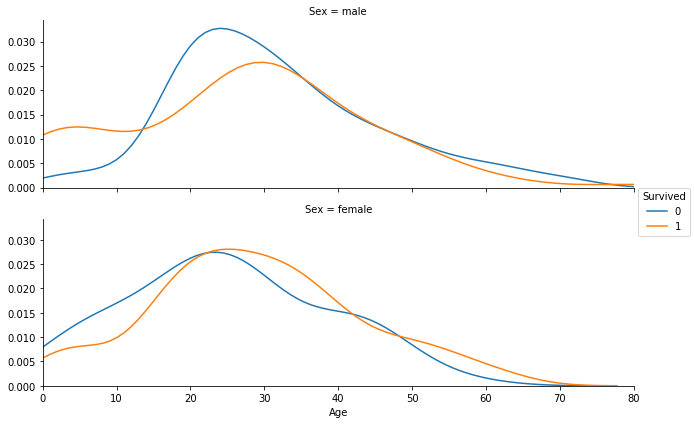
虽然女性是否获救的分布曲线看起来区别不是很大,但是 30 岁以前的男性是否获救的分布曲线还是有较大差距的。可以考虑对 30 岁以前每 5 岁分一个 bin,30 岁以后每 10 岁分一个 bin,把年龄转化为类别提供给模型。我们考虑添加“性别 + 年龄”这个特征。
既然要使用 Age 的数据,就得把缺失数据补上。我们先从简单的开始,先简单给年龄未知的人分一个 Unknown 的类别。
def gen_sex_age(data):
bins = [5, 10, 15, 20, 25, 30, 40, 50, 60, 100]
res = []
for index, row in data.iterrows():
if row['Sex'] == 'male':
s = 'm_'
else:
s = 'f_'
for b in bins:
if row['Age'] <= b:
s += str(b)
break
else:
s += 'unknown'
res.append(s)
data['SexAge'] = pd.Series(res)
def prepare_data_4(data):
gen_sex_pclass(data)
gen_sex_age(data)
gen_title(data)
data['Cabin'].fillna('X', inplace = True)
data['Cabin'] = data['Cabin'].apply(lambda s: s[0])
ret = [
pd.DataFrame((data['Fare'] - data['Fare'].min()) / (data['Fare'].max() - data['Fare'].min())),
pd.get_dummies(data['Pclass'], prefix = 'Pclass'),
pd.get_dummies(data['Sex'], prefix = 'Sex'),
pd.get_dummies(data['Embarked'], prefix = 'Embarked'),
pd.get_dummies(data['Cabin'], prefix = 'Cabin'),
pd.get_dummies(data['SexPclass'], prefix = 'SexPclass'),
pd.get_dummies(data['SexAge'], prefix = 'SexAge'),
pd.get_dummies(data['Title'], prefix = 'Title')
]
return pd.concat(ret, axis = 1)
train_x = prepare_data_4(train_data)
model = LogisticRegression()
get_training_accuracy(model, train_x, train_y)
0.81259675405742815
准确率反而降低了,看来直接使用 unknown 替换进去的效果并不好...我们来看看能不能通过其它特征来推断出年龄未知乘客的年龄。先看一下年龄和其它数值型特征的相关度。
train_numeric.corrwith(train_data['Age'])
Pclass -0.369226
Age 1.000000
SibSp -0.308247
Parch -0.189119
Fare 0.096067
dtype: float64
可以看到,Pclass、SibSp 和 Parch 与 Age 的相关度较大。不过 Pclass 是一个 [1, 3] 的整数,SibSp 和 Parch 也都是 [1, 8] 的整数,根据我们之前学习的最大似然估计法等知识,如果 Age 的由这三类特征的某种高斯分布决定,那么每类特征的组合最有可能的 Age 值应该是平均数。所以,我们把每一类 (Pclass, SibSp, Parch) 这样三元组的平均 Age 算出来,作为缺失 Age 的补充值。
def guess_age(data, goal):
age = {}
size = {}
for index, row in goal.iterrows():
k = str(row['Pclass']) + '_' + str(row['SibSp']) + '_' + str(row['Parch'])
if pd.isnull(row['Age']):
continue
if k not in age.keys():
age[k] = row['Age']
size[k] = 1
else:
age[k] += row['Age']
size[k] += 1
for k in age.keys():
age[k] /= size[k]
for index, row in data.iterrows():
if not pd.isnull(row['Age']):
continue
k = str(row['Pclass']) + '_' + str(row['SibSp']) + '_' + str(row['Parch'])
if k not in age.keys():
continue
data.loc[index, 'Age'] = age[k]
train_data_age = train_data
guess_age(train_data_age, train_data)
train_x = prepare_data_4(train_data_age)
model = LogisticRegression()
get_training_accuracy(model, train_x, train_y)
0.81033707865168536
虽然不知道怎么回事这个 k-fold 测出来的准确率又低了- -还是先放到 Kaggle 上试一试...
test_data_age = test_data
guess_age(test_data_age, train_data)
test_x = prepare_data_4(test_data)
test_x = fit_features(test_x, train_x)
gen_predict(model, train_x, train_y, test_x)
分数又变回了 0.76555- -这样看来可能 Age 这个特征不太行...
据说在什么方法都想不到的时候,可以试一下组合模型,也就是 bagging 或者 boosting。我们就来用之前那个表现“最好”的模型试一试 bagging...
from sklearn.ensemble import BaggingClassifier
train_x = prepare_data_3(train_data)
model = BaggingClassifier(LogisticRegression(), n_estimators = 200)
get_training_accuracy(model, train_x, train_y)
0.82268414481897634
准确率好像的确上升了一些,提交到 Kaggle 上试试看...
test_x = prepare_data_3(test_data)
test_x = fit_features(test_x, train_x)
gen_predict(model, train_x, train_y, test_x)
获得了 0.77511 分,第 4704 名,离 50% 的小目标比较接近了- -不如最后我们来试一下大名鼎鼎的随机森林...感觉就像决策树 + Bagging...
from sklearn.ensemble import RandomForestClassifier
train_x = prepare_data_3(train_data)
model = RandomForestClassifier(n_estimators = 200)
print(get_training_accuracy(model, train_x, train_y))
test_x = prepare_data_3(test_data)
test_x = fit_features(test_x, train_x)
gen_predict(model, train_x, train_y, test_x)
0.805892634207
0.74641 分,不过没怎么调参,也在预料之内- -
最后的最后再来试试(不调参的)SVM...?
from sklearn.svm import SVC
train_x = prepare_data_3(train_data)
model = SVC()
print(get_training_accuracy(model, train_x, train_y))
test_x = prepare_data_3(test_data)
test_x = fit_features(test_x, train_x)
gen_predict(model, train_x, train_y, test_x)
0.793558052434
一下子就 0.78468 分了,变成了 3646 名,达成了 50% 的小目标。SVM 还是强啊...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号