学习笔记:并查集
并查集
并查集被很多 认为是最简洁而优雅的数据结构之一,主要用于解决一些 元素分组 的问题。它管理一系列 不相交的集合,并支持两种操作:
- 合并:把两个不相交的集合合并为一个集合。
- 查询:查询两个元素是否在同一个集合中。
先来看看并查集最直接的一个应用场景:亲戚问题。
洛谷P1551 亲戚
题目背景
若某个家族人员过于庞大,要判断两个是否是亲戚,确实还很不容易,现在给出某个亲戚关系图,求任意给出的两个人是否具有亲戚关系。
题目描述
规定: 和 是亲戚, 和 是亲戚,那么 和 也是亲戚。如果 , 是亲戚,那么 的亲戚都是 的亲戚, 的亲戚也都是 的亲戚。
输入格式
第一行:三个整数 ,(),分别表示有 个人, 个亲戚关系,询问 对亲戚关系。
以下 行:每行两个数 ,,,表示 和 具有亲戚关系。
接下来 行:每行两个数 ,询问 和 是否具有亲戚关系。
输出格式
行,每行一个
Yes或No。表示第 个询问的答案为“具有”或“不具有”亲戚关系。
这其实是一个很有现实意义的问题。我们可以建立模型,把所有人划分到若干个不相交的集合中,每个集合里的人彼此是亲戚。为了判断两个人是否为亲戚,只需看它们是否属于同一个集合即可。因此,这里就可以考虑用并查集进行维护了。
简单并查集
并查集的重要思想在于,用集合中的一个元素代表集合。有这样一个有趣的比喻,把集合比喻成 狗帮,而代表元素则是 狗王。接下来我们利用这个比喻,看看并查集是如何运作的。
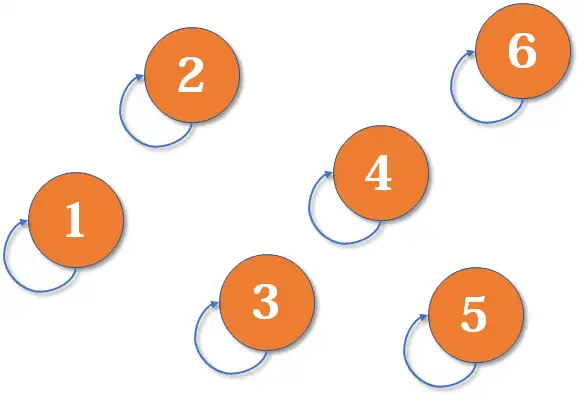
最开始,所有狗狗各自为战。他们各自的狗王自然就是自己(对于只有一个元素的集合,代表元素自然是唯一的那个元素)。
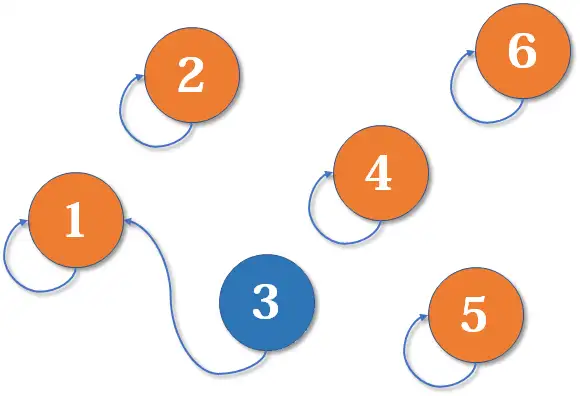
现在 号和 号比武,假设 号赢了(这里具体谁赢暂时不重要),那么 号就认 号作帮主(合并 号和 号所在的集合, 号为代表元素)。
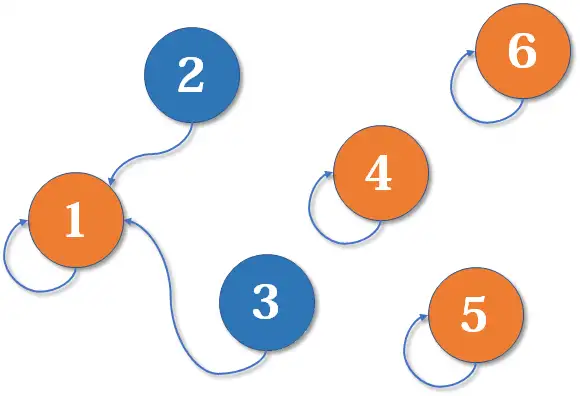
现在 号想和 号比武(合并 号和 号所在的集合),但 号表示,别跟我打,让我狗王来收拾你(合并代表元素)。不妨设这次又是 号赢了,那么 号也认 号做狗王。
现在我们假设 、、 号也进行了一番狗帮合并,局势变成下面这样:
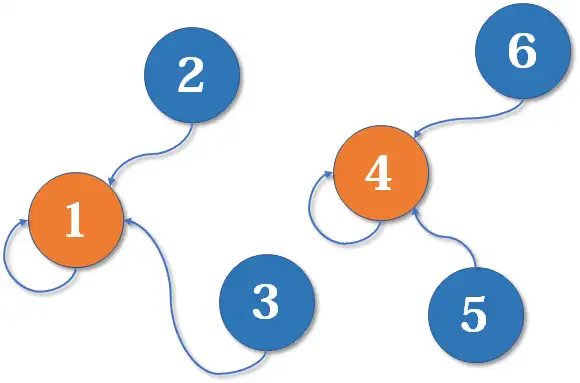
现在假设 号想与 号比,跟刚刚说的一样,喊狗王 号和 号出来打一架。 号胜利后, 号认 号为帮主,当然他的下属也都是跟着投降了。
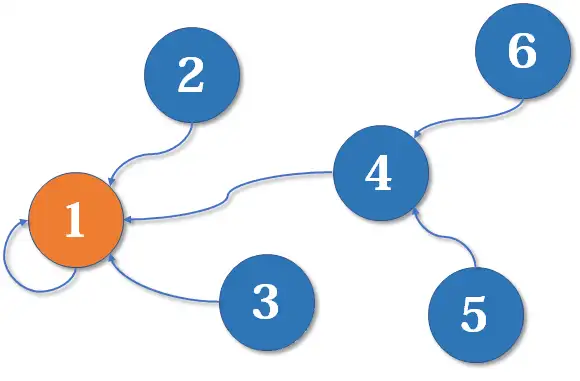
好了,比喻结束了。如果你有一点图论基础,相信你已经觉察到,这是一个 **树 **状的结构,要寻找集合的代表元素,只需要一层一层往上寻找 父节点(图中箭头所指的圆),直达树的 根节点(图中橙色的圆)即可。根节点的父节点是它自己。我们可以直接把它画成一棵树:
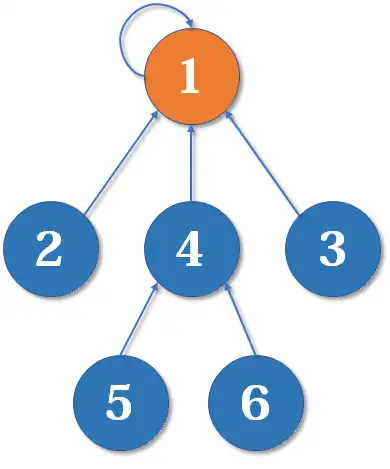
(好像有点像个火柴人?)
用这种方法,我们可以写出最简单版本的并查集代码。
初始化
int f[MAXN];
for(int i = 1 ; i <= n ; i ++)f[i] = i;
假如有编号为 的 个元素,我们用一个数组 f[] 来存储每个元素的父节点(因为每个元素有且只有一个父节点,所以这是可行的)。一开始,我们先将它们的父节点设为自己。
查询
int find(int x){
if(fa[x] == x)return x;
else return find(fa[x]);
}
我们用递归的写法实现对代表元素的查询:一层一层访问父节点,直至根节点(根节点的标志就是父节点是本身)。要判断两个元素是否属于同一个集合,只需要看它们的根节点是否相同即可。
合并
void merge(int i, int j){
fa[find(i)] = find(j);
}
合并操作也是很简单的,先找到两个集合的代表元素,然后将前者的父节点设为后者即可。当然也可以将后者的父节点设为前者,这里暂时不重要。本文末尾会给出一个更合理的比较方法。
路径压缩并查集
最简单的并查集效率是比较低的。例如,来看下面这个场景:
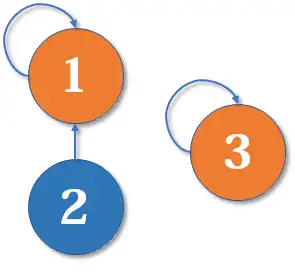
现在我们要 merge(2,3),于是从 找到 ,f[1]=3,于是变成了这样:

然后我们又找来一个元素 ,并需要执行 merge(2,4):
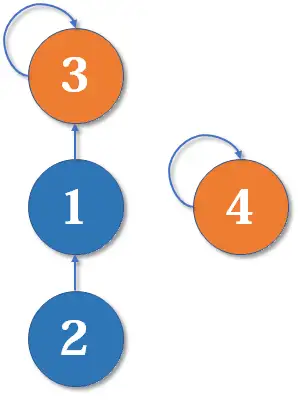
从 找到 ,再找到 ,然后 f[3]=4,于是变成了这样:

大家应该有感觉了,这样可能会形成一条长长的 链,随着链越来越长,我们想要从底部找到根节点会变得越来越难。
怎么解决呢?我们可以使用 路径压缩 的方法。既然我们只关心一个元素对应的 根节点,那我们希望每个元素到根节点的路径尽可能短,最好只需要一步,像这样:

其实这说来也很好实现。只要我们在查询的过程中,**把沿途的每个节点的父节点都设为根节点 **即可。下一次再查询时,我们就可以省很多事。这用递归的写法很容易实现:
合并
int find(int x){
if(x == f[x])return x;
else return f[x] = find(f[x]);
}
注意赋值运算符 = 的优先级没有三元运算符 ? : 高,这里要加括号。
路径压缩优化后,并查集的时间复杂度已经比较低了,绝大多数不相交集合的合并查询问题都能够解决。然而,对于某些时间卡得很紧的题目,我们还可以进一步优化。
按秩合并并查集
有些人可能有一个误解,以为路径压缩优化后,并查集始终都是一个 菊花图。但其实,由于路径压缩只在查询时进行,也只压缩一条路径,所以并查集最终的结构仍然可能是比较复杂的。例如,现在我们有一棵较复杂的树需要与一个单元素的集合合并:
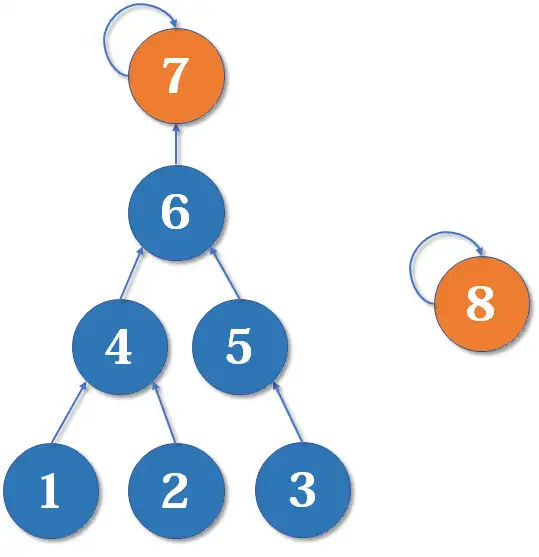
假如这时我们要 merge(7,8),如果我们可以选择的话,是把 的父节点设为 好,还是把 的父节点设为 好呢?
当然是后者。因为如果把 的父节点设为 ,会使树的 深度 加深,原来的树中每个元素到根节点的距离都变长了,之后我们寻找根节点的路径也就会相应变长。虽然我们有路径压缩,但路径压缩也是会消耗时间的。而把 的父节点设为 ,则不会有这个问题,因为它没有影响到不相关的节点。
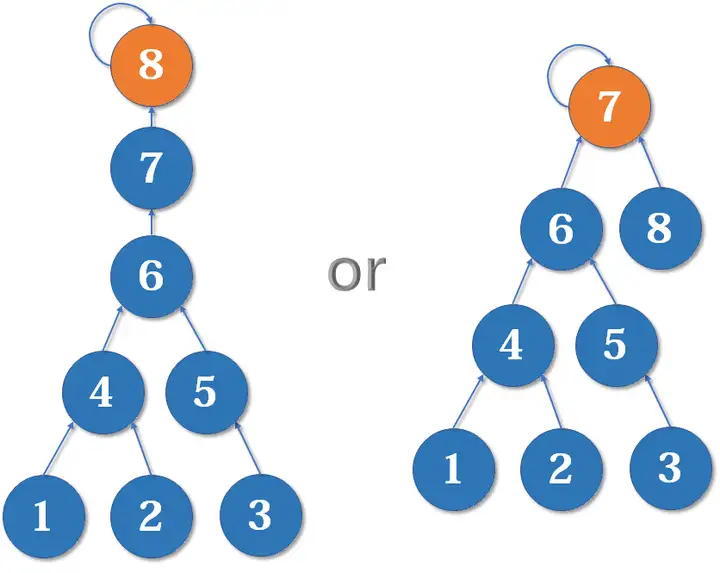
这启发我们:我们应该把简单的树往复杂的树上合并,而不是相反。因为这样合并后,到根节点距离变长的节点个数比较少。
我们用一个数组 rnk[] 记录每个根节点对应的树的深度(如果不是根节点,其 rnk 相当于以它作为根节点的 子树 的深度)。一开始,把所有元素的 rnk (秩)设为 。合并时比较两个根节点,把 rnk 较小者往较大者上合并。
路径压缩和按秩合并如果一起使用,时间复杂度接近 ,但是很可能会破坏 rnk 的准确性。
初始化
int f[MAXN];
for(int i = 1 ; i <= n ; i ++)f[i] = i;
for(int i = 1 ; i <= n ; i ++)rnk[i] = 1;
合并
void merge(int i, int j){
int x = find(i), y = find(j);
if(rnk[x] <= rnk[y])fa[x] = y;
else fa[y] = x;
if(rnk[x] == rnk[y] && x != y)
rnk[y]++;
}
为什么深度相同,新的根节点深度要 ?如下图,我们有两个深度均为 的树,现在要 merge(2,5):
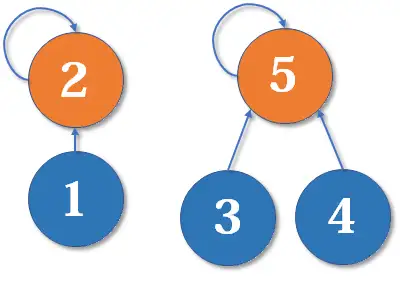
这里把 的父节点设为 ,或者把 的父节点设为 ,其实没有太大区别。我们选择前者,于是变成这样:
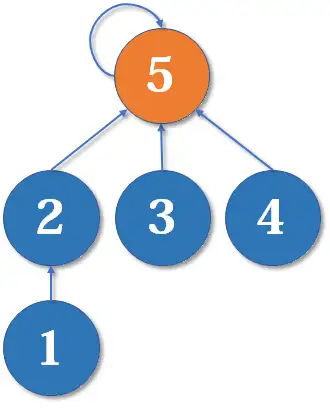
显然树的深度增加了 。另一种合并方式同样会让树的深度 。
种类并查集
引入
一般的并查集,维护的是具有连通性、传递性的关系,例如亲戚的亲戚是亲戚。有时候,我们要维护另一种关系:敌人的敌人是朋友。种类并查集就是为了解决这个问题而诞生的。
实现
洛谷P1525 [NOIP2010 提高组] 关押罪犯
题目描述
S 城现有两座监狱,一共关押着 名罪犯,编号分别为 。他们之间的关系自然也极不和谐。很多罪犯之间甚至积怨已久,如果客观条件具备则随时可能爆发冲突。我们用“怨气值”(一个正整数值)来表示某两名罪犯之间的仇恨程度,怨气值越大,则这两名罪犯之间的积怨越多。如果两名怨气值为 的罪犯被关押在同一监狱,他们俩之间会发生摩擦,并造成影响力为 的冲突事件。
每年年末,警察局会将本年内监狱中的所有冲突事件按影响力从大到小排成一个列表,然后上报到 S 城 Z 市长那里。公务繁忙的 Z 市长只会去看列表中的第一个事件的影响力,如果影响很坏,他就会考虑撤换警察局长。
在详细考察了 名罪犯间的矛盾关系后,警察局长觉得压力巨大。他准备将罪犯们在两座监狱内重新分配,以求产生的冲突事件影响力都较小,从而保住自己的乌纱帽。假设只要处于同一监狱内的某两个罪犯间有仇恨,那么他们一定会在每年的某个时候发生摩擦。
那么,应如何分配罪犯,才能使 Z 市长看到的那个冲突事件的影响力最小?这个最小值是多少?
输入格式
每行中两个数之间用一个空格隔开。第一行为两个正整数 ,分别表示罪犯的数目以及存在仇恨的罪犯对数。接下来的 行每行为三个正整数 ,表示 号和 号罪犯之间存在仇恨,其怨气值为 。数据保证 ,且每对罪犯组合只出现一次。
输出格式
共 行,为 Z 市长看到的那个冲突事件的影响力。如果本年内监狱中未发生任何冲突事件,请输出
0。
其实很容易想到,这里可以 贪心,把所有矛盾关系 从大到小 排个序,然后尽可能地把矛盾大的犯人关到不同的监狱里,直到不能这么做为止。这看上去可以用并查集维护,但是有一个问题:我们得到的信息,不是哪些人应该在 相同 的监狱,而是哪些人应该在 不同 的监狱。这怎么处理呢?这个题其实有很多做法(例如二分图匹配之类的)。但这里,我们介绍使用种类并查集的做法。
我们开一个 **两倍大小 **的并查集。例如,假如我们要维护 个元素的并查集,我们改为开 个单位的空间:

我们用 维护朋友关系(就这道题而言,是指关在同一个监狱的狱友),用 维护敌人关系(这道题里是指关在不同监狱的仇人)。现在假如我们得到信息: 和 是敌人,应该怎么办?
我们merge(1, 2+n), merge(1+n, 2),对于 个编号为 的元素, 是它的敌人。所以这里的意思就是: 是 的敌人, 是 的敌人。
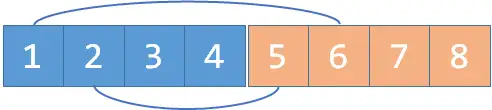
现在假如我们又知道 和 是敌人,我们merge(2, 4+n), merge(2+n, 4);:
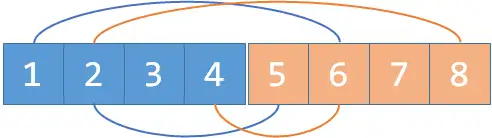
发现了吗,敌人的敌人就是朋友, 和 是敌人, 和 也是敌人。所以这里, 和 通过 这个元素 间接 地连接起来了。这就是种类并查集工作的原理。
代码如下:
#include <iostream>
#include <algorithm>
#define MAXN 20005
#define MAXM 100005
using namespace std;
int f[MAXN], rnk[MAXN];
struct data{
int a, b, w;
bool friend operator<(data &a, data &b){
return a.w > b.w;
}
}a[MAXM];
int read(){
int t = 1, x = 0;char ch = getchar();
while(!isdigit(ch)){if(ch == '-')t = -1;ch = getchar();}
while(isdigit(ch)){x = (x << 1) + (x << 3) + (ch ^ 48);ch = getchar();}
return x * t;
}
void write(int x){
if(x < 0){putchar('-');x = -x;}
if(x >= 10)write(x / 10);
putchar(x % 10 ^ 48);
}
int find(int x){
if(f[x] == x)return x;
else return f[x] = find(f[x]);
}
int query(int a, int b){
if(find(a) == find(b))return true;
else return false;
}
void merge(int a, int b){
int x = find(a), y = find(b);
if(rnk[x] >= rnk[y])f[y] = x;
else f[x] = y;
if(rnk[x] == rnk[y] && x != y)rnk[x]++;
}
int main(){
int n = read(), m = read();
for(int i = 1 ; i <= (n << 1) ; i ++)f[i] = i;
for(int i = 1 ; i <= (n << 1) ; i ++)rnk[i] = 1;
for(int i = 1 ; i <= m ; i ++)
a[i].a = read(),a[i].b = read(),a[i].w = read();
sort(a + 1, a + m + 1);
for(int i = 1 ; i <= m ; i ++){
if(query(a[i].a, a[i].b) == true){
write(a[i].w);putchar('\n');
break;
}else{
merge(a[i].a, a[i].b + n);
merge(a[i].b, a[i].a + n);
if(i == m - 1)puts("0");
}
}
return 0;
}
种类并查集可以维护 敌人的敌人是朋友 这样的关系,这种说法不够准确。较为本质地说,种类并查集(包括普通并查集)维护的是一种 循环对称 的关系。
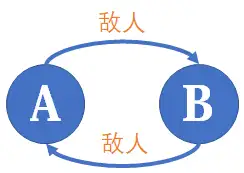
所以如果是三个及以上的集合,只要每个集合都是等价的,且集合间的每个关系都是等价的,就能够用种类并查集进行维护。
可撤销并查集
引入
一般的并查集只能够加边而不能删边,于是就有了可撤销并查集,这种并查集同时支持加边和删边操作。
可撤销并查集只可以按照加入的时间从后到前撤销加边操作。
可撤销并查集常用于一些连通性问题,并且很多时候会调整处理的顺序,只要按照上述撤销顺序撤销边即可。
实现
可撤销在有时可以通过改变加入顺序中途撤销求解问题。那又怎么做呢?路径压缩会改变树的形态,所以只用按秩合并(按子树大小合并,小的那颗合并到大的上面去),单次时间复杂度为 级别,因为对于每个节点来说,深度最多是 级别的。
具体的,我们会把所有加入的边压入一个栈,然后当什么时候要撤销时不断从栈顶弹出一条边,撤销掉。而至于具体的撤销步骤,我们假设此边原来是把 连向 ,那么我们直接把 的父亲设为 本身,因为在合并两个集合时是把两个端点都执行了一遍找祖先的操作,所以 必定作为其原集合的祖先。我们再把 的子树大小减去一个 的子树大小,那么就还原成功了。
那么对于一条边为什么一定要是有顺序的撤销呢?如果不是按出栈的顺序撤销,那么必定有比他晚一些连边的集合的大小没法维护,所以必须按出栈顺序撤销。
int cnt = 0, top = 0;
int f[MAXN], rnk[MAXN], stk[MAXN];
void insert(){ // 插入
cnt++;f[cnt] = cnt;rnk[cnt] = 1;
}
int find(int x){ // 查询
if(f[x] == x)return x;
else return find(f[x]);
}
void merge(int x, int y){ // 合并
x = find(x);y = find(y);
if(x == y)return;
else{
if(rnk[x] < rnk[y])swap(x, y);
top++;stk[top] = y;f[y] = x;rnk[x] += rnk[y];
}
}
void del(){ // 撤销
if(top == 0)return;
else{
int t = stk[top];top--;
rnk[f[t]] -= rnk[t];f[t] = t;
}
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!