学习笔记:树链剖分
树链剖分
引入
简单来说,树链剖分就是通过某种方式将一棵树划分为几条链,再利用数据结构来维护树上路径。
具体地讲,可以将树上的任意一条路径划分为不超过 条连续的链,每条链上的点深度互不相同(即是自底向上的一条链,链上所有点的 LCA 为链的一个端点),并且保证划分出的每条链上的节点 DFS 序连续,因此可以方便地用一些维护序列的数据结构(如线段树、树状数组)来维护树上路径的信息。
维护树上路径
首先来看一道树链剖分的板子题。
题目描述
如题,已知一棵包含 个结点的树(连通且无环),每个节点上包含一个数值,需要支持以下操作:
-
1 x y z,表示将树从 到 结点最短路径上所有节点的值都加上 。 -
2 x y,表示求树从 到 结点最短路径上所有节点的值之和。 -
3 x z,表示将以 为根节点的子树内所有节点值都加上 。 -
4 x表示求以 为根节点的子树内所有节点值之和。
思路
我们给出一些定义:
定义 重子节点 表示其子节点中子树最大的子结点。如果有多个子树最大的子结点,取其一。如果没有子节点,就无重子节点。
定义 轻子节点 表示剩余的所有子结点。
从这个结点到重子节点的边为 重边。
到其他轻子节点的边为 轻边。
若干条首尾衔接的重边构成 重链。
把落单的结点也当作重链,那么整棵树就被剖分成若干条重链。
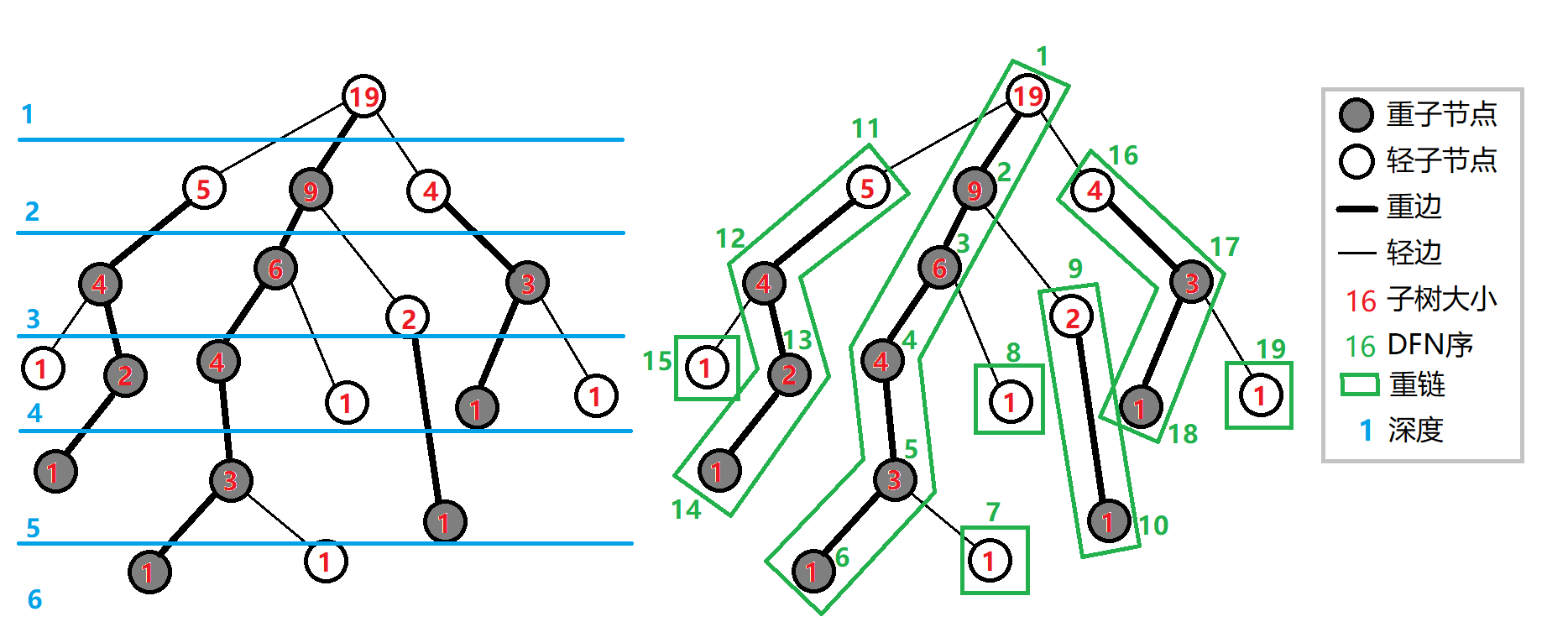
至于具体做法的话,我们考虑进行两次 dfs。
第一个 DFS 记录每个结点的父节点(father)、深度(deep)、子树大小(size)、重子节点(hson)。
void dfs1(int now, int fat, int deep){
dep[now] = deep;siz[now] = 1;fa[now] = fat;int maxson = -1;
for(int i = head[now] ; i != 0 ; i = e[i].nxt){
int v = e[i].to;
if(v != fat){
dfs1(v, now, deep + 1);siz[now] += siz[v];
if(siz[v] > maxson){
maxson = siz[v];son[now] = v;
}
}
}
}
第二个 DFS 记录所在链的链顶(top,应初始化为结点本身)、重边优先遍历时的 DFS 序(dfn)、DFS 序对应的节点权值。
void dfs2(int now, int fat, int top){
dfn[now] = ++tot;wt[tot] = w[now];vis[now] = top;
if(son[now] != 0){
dfs2(son[now], now, top);
for(int i = head[now] ; i != 0 ; i = e[i].nxt){
int v = e[i].to;
if(v != fat && v != son[now])dfs2(v, now, v);
}
}
}
以下为代码实现。
我们先给出一些定义:
- 表示节点 在树上的父亲。
- 表示节点 在树上的深度。
- 表示节点 的子树的节点个数。
- 表示节点 的重儿子。
- 表示节点 所在重链的顶部节点(深度最小)。
- 表示节点 的 DFS 序,也是其在线段树中的编号。
- 表示 DFS 序所对应的节点权值。
我们进行两遍 DFS 预处理出这些值,其中第一次 DFS 求出 ,,,,第二次 DFS 求出 ,,。
现在回顾一下我们要处理的问题:
- 处理任意两点间路径上的点权和。
- 处理一点及其子树的点权和。
- 修改任意两点间路径上的点权。
- 修改一点及其子树的点权。
1、当我们要处理任意两点间路径时: 设所在链顶端的深度更深的那个点为 点。
- 加上 点到 所在链顶端 这一段区间的点权和。
- 把 跳到 所在链顶端的那个点的上面一个点。
不停执行这两个步骤,直到两个点处于一条链上,这时再加上此时两个点的区间和即可。

这时我们注意到,我们所要处理的所有区间均为连续编号(新编号),于是想到线段树,用线段树处理连续编号区间和,每次查询的时间复杂度为 。
2、处理一点及其子树的点权和:
想到记录了每个非叶子节点的子树大小(含它自己),并且每个子树的新编号都是连续的。
于是直接线段树区间查询即可。
时间复杂度为 。
代码
#include <iostream>
#define MAXN 100005
#define MAXM 100005
int n, m, r, p, u, v;
int op, x, y, z;
int w[MAXN], wt[MAXN];
struct edge{int to, nxt;}e[MAXN << 1];
int head[MAXN], cnt;
int tree[MAXN << 2], mark[MAXN << 2];
int dep[MAXN], siz[MAXN], son[MAXN], fa[MAXN];
int dfn[MAXN], vis[MAXN];
int tot, ans;
int read(){
int t = 1, x = 0;char ch = getchar();
while(!isdigit(ch)){if(ch == '-')t = -1;ch = getchar();}
while(isdigit(ch)){x = (x << 1) + (x << 3) + (ch ^ 48);ch = getchar();}
return x * t;
}
void write(int x){
if(x < 0){putchar('-');x = -x;}
if(x >= 10)write(x / 10);
putchar(x % 10 + '0');
}
void pushup(int node){tree[node] = tree[node << 1] + tree[node << 1 | 1];tree[node] %= p;}
void pushdown(int node, int len){
if(mark[node] != 0){
tree[node << 1] += mark[node] * (len - (len >> 1));tree[node << 1] %= p;
mark[node << 1] += mark[node];mark[node << 1] %= p;
tree[node << 1 | 1] += mark[node] * (len >> 1);tree[node << 1 | 1] %= p;
mark[node << 1 | 1] += mark[node];mark[node << 1 | 1] %= p;
mark[node] = 0;
}
}
void build(int node, int left, int right){
if(left == right){tree[node] = wt[left];return;}
int mid = left + right >> 1;
build(node << 1, left, mid);build(node << 1 | 1, mid + 1, right);
pushup(node);
}
void update(int node, int left, int right, int l, int r, int k){
if(l <= left && r >= right){
tree[node] += k * (right - left + 1);tree[node] %= p;
mark[node] += k;mark[node] %= p;
return;
}
pushdown(node, right - left + 1);int mid = left + right >> 1;
if(l <= mid)update(node << 1, left, mid, l, r, k);
if(r > mid)update(node << 1 | 1, mid + 1, right, l, r, k);
pushup(node);
}
void query(int node, int left, int right, int l, int r){
if(l <= left && r >= right){ans += tree[node];ans %= p;return;}
pushdown(node, right - left + 1);int mid = left + right >> 1;
if(l <= mid)query(node << 1, left, mid, l, r);
if(r > mid)query(node << 1 | 1, mid + 1, right, l, r);
}
void add(int u, int v){e[++cnt].to = v;e[cnt].nxt = head[u];head[u] = cnt;}
void swap(int &a, int &b){a ^= b ^= a ^= b;}
void dfs1(int now, int fat, int deep){
dep[now] = deep;siz[now] = 1;fa[now] = fat;int maxson = -1;
for(int i = head[now] ; i != 0 ; i = e[i].nxt){
int v = e[i].to;
if(v != fat){
dfs1(v, now, deep + 1);siz[now] += siz[v];
if(siz[v] > maxson){
maxson = siz[v];son[now] = v;
}
}
}
}
void dfs2(int now, int fat, int top){
dfn[now] = ++tot;wt[tot] = w[now];vis[now] = top;
if(son[now] != 0){
dfs2(son[now], now, top);
for(int i = head[now] ; i != 0 ; i = e[i].nxt){
int v = e[i].to;
if(v != fat && v != son[now])dfs2(v, now, v);
}
}
}
void updtree(int x, int y, int z){
z %= p;
while(vis[x] != vis[y]){
if(dep[vis[x]] < dep[vis[y]])swap(x, y);
update(1, 1, n, dfn[vis[x]], dfn[x], z);
x = fa[vis[x]];
}
if(dep[x] > dep[y])swap(x, y);
update(1, 1, n, dfn[x], dfn[y], z);
}
int quetree(int x, int y){
int res = 0;
while(vis[x] != vis[y]){
if(dep[vis[x]] < dep[vis[y]])swap(x, y);
ans = 0;query(1, 1, n, dfn[vis[x]], dfn[x]);
res += ans;res %= p;x = fa[vis[x]];
}
if(dep[x] > dep[y])swap(x, y);
ans = 0;query(1, 1, n, dfn[x], dfn[y]);
res += ans;res %= p;
return res;
}
void updson(int x, int z){update(1, 1, n, dfn[x], dfn[x] + siz[x] - 1, z);}
int queson(int x){ans = 0;query(1, 1, n, dfn[x], dfn[x] + siz[x] - 1);return ans;}
int main(){
n = read();m = read();r = read();p = read();
for(int i = 1 ; i <= n ; i ++)w[i] = read();
for(int i = 1 ; i < n ; i ++){u = read();v = read();add(u, v);add(v, u);}
dfs1(r, 0, 1);dfs2(r, 0, r);build(1, 1, n);
for(int i = 1 ; i <= m ; i ++){op = read();
if(op == 1){x = read();y = read();z = read();updtree(x, y, z);}
if(op == 2){x = read();y = read();write(quetree(x, y));putchar('\n');}
if(op == 3){x = read();z = read();updson(x, z);}
if(op == 4){x = read();write(queson(x));putchar('\n');}
}return 0;
}
LCA
不断向上跳重链,当跳到同一条重链上时,深度较小的结点即为 LCA。
向上跳重链时需要先跳所在重链顶端深度较大的那个。
#include <iostream>
#define MAXN 500005
using namespace std;
int n, m, s, x, y;
struct edge{int to, nxt;}e[MAXN << 1];
int head[MAXN], cnt = 1;
int son[MAXN], fa[MAXN], dep[MAXN], siz[MAXN];
int dfn[MAXN], vis[MAXN], tot;
int read(){
int t = 1, x = 0;char ch = getchar();
while(!isdigit(ch)){if(ch == '-')t = -1;ch = getchar();}
while(isdigit(ch)){x = (x << 1) + (x << 3) + (ch ^ 48);ch = getchar();}
return x * t;
}
void write(int x){
if(x < 0){putchar('-');x = -x;}
if(x >= 10)write(x / 10);
putchar(x % 10 ^ 48);
}
void add(int u, int v){
cnt++;e[cnt].to = v;e[cnt].nxt = head[u];head[u] = cnt;
cnt++;e[cnt].to = u;e[cnt].nxt = head[v];head[v] = cnt;
}
void dfs1(int now, int fat, int deep){
fa[now] = fat;siz[now] = 1;dep[now] = deep;int maxson = -1;
for(int i = head[now] ; i != 0 ; i = e[i].nxt){
int v = e[i].to;
if(v != fat){
dfs1(v, now, deep + 1);
siz[now] += siz[v];
if(siz[v] > maxson)
maxson = siz[v],son[now] = v;
}
}
}
void dfs2(int now, int fat, int top){
tot++;dfn[now] = tot;vis[now] = top;
if(son[now] != 0)dfs2(son[now], now, top);
for(int i = head[now] ; i != 0 ; i = e[i].nxt){
int v = e[i].to;
if(v != fat && v != son[now])
dfs2(v, now, v);
}
}
int lca(int x, int y){
while(vis[x] != vis[y]){
if(dep[vis[x]] >= dep[vis[y]])x = fa[vis[x]];
else y = fa[vis[y]];
}
if(dep[x] < dep[y])return x;
else return y;
}
int main(){
n = read();m = read();s = read();
for(int i = 1 ; i < n ; i ++)
x = read(),y = read(),add(x, y);
dfs1(s, 0, 1);dfs2(s, 0, s);
for(int i = 1 ; i <= m ; i ++)
x = read(),y = read(),write(lca(x, y)),putchar('\n');
return 0;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!