
先验分布:(三)Dirichlet分布的应用——LDA模型
LDA(Latent Dirichlet Allocation)模型是Dirichlet分布的实际应用。
在自然语言处理中,LDA模型及其许多延伸主要用于文本聚类、分类、信息抽取和情感分析等。
例如,我们要对许多新闻按主题进行分类。目前用的比较多的方法是:假设每篇新闻都有一个主题,然后通过分析新闻的文本(即组成新闻的词),推导出新闻属于某些主题的可能性,这样就可以按照可能性大小将新闻分类了。
而LDA模型,就是用于分析新闻文本,推导出新闻属于某些主题可能性的这一过程。
为了做到这点,LDA模型有如下假设:
1、每个文本均有若干个主题,比如60%是体育、40%是娱乐;
2、每个主题都有一系列词语,这些词语反映了该主题(或者说常用词),比如在体育主题下,运动员、比赛、比分、冠军等词出现的频率比较高;
3、每个文本的生成过程是:选取主题 → 从该主题下选取词语 → 词语形成文本。
在实际应用中,我们得到(或看到)的是由词语形成的文本,为了将文本分类,我们必须根据文本倒推主题,即算出该文本下可能有什么主题。这跟文本的生成过程刚好是相反的。
现在假设,一个文本共有N个词:
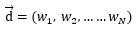
一共有K个主题:
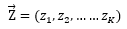
一共有V个词语作为词汇表(主题共用,只是不同主题中词的出现机会不同):
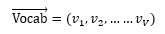
下面我们用刚才提到的文本生成过程来表示这个文本是怎样形成的:

过程是这样的:
1、先(通过某种方式)抽取位置1的词(也就是文本的第一个词)的主题,比如z2,即第二个主题;
2、该主题下有相应的词汇分布(即每个词都有其出现机会),在该主题下(通过某种方式)抽取位置1的词,比如抽到V3,即词汇表中的第三个词;
3、重复上述两部,对位置2、位置3直到位置N的词进行抽取。这样就形成了一个文本,比如上表的文本按顺序从1到N的词就是:
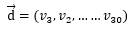
上述过程中的"通过某种方式"就是LDA模型的关键。由于我们事先不知道文本的主题分布,按照贝叶斯派的做法,我们只能先主观或根据经验人为设定文本的主题分布,比如体育60%,娱乐40%。这就涉及到之前文章所说的先验概率分布了。
同理,我们事先也不知道特定主题下词汇的分布,不妨也先主观或根据经验人为设定该主题下词汇的分布,即先验概率分布。
而这两种先验概率,服从Dirichlet分布:
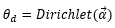
这是一个文本的主题的分布,也就是说,不同文本的主题分布不同,如果语料有M篇文本,则应该有M个Dirichlet分布。其中:
α是文本主题先验分布的超参数,是一个K维向量,对应K个主题,可以将第k个分量看成是影响第k个主题出现概率的参数。
同理,某主题的词的先验分布为:

这是一个主题的词的分布,也就是说,不同主题的词的分布不同,如果有K个主题,则应该有K个Dirichlet分布。其中:
β是主题的词的先验分布的超参数,是一个V维向量,对应V个词汇,可以将第v个分量看成是影响第v个词出现概率的参数。
我们的目的是通过现象(看到的文本),倒推各文本的主题分布和各主题的词分布,根据这两个结果就可以将文本分类了。倒推的原理和可行性在之前的文章已有讨论,在此不表。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号